本发明涉及数据查询领域,尤其涉及一种XML文档分布式查询方法及系统。
背景技术
XML作为信息交换和存储标准被广泛应用,XML数据处理的相关技术蓬勃发展。XML查询是XML数据处理关键应用,而XPath求值是XML查询的核心部分。XML数据通常采用文档形式存储,XML文档需要通过XML解析以获得查询处理所需的数据。由于各种应用领域中产生的XML数据量正变得越来越大,XML文档从几GB到上百GB,以至于单机系统难以有效处理甚至无法处理。
XML文档具有严格的嵌套格式约束,需要通过解析才能加以利用。相较于传统的关系型结构化数据,XML数据的半结构特点使得解析和查询操作均变得复杂。大规模XML数据在分布式计算环境中的处理,面临着可行性和性能优化方面的巨大挑战。XML半结构化以嵌套方式组织,难以划分处理,然而划分又是适应分布计算的前提条件;而XML查询的核心XPath求值支持复杂的结构查询处理,拥有丰富的查询语义,重写为分布式查询计划难度很大。
当前大数据应用大量采用MapReduce计算框架,以适应多机分布处理优势。然而MapRedcue无法直接有效地处理嵌套复杂数据,需要进一步转换。此外,由于XML处理的复杂性,存在大量迭代操作,采用多次MapReduce分布式计算方式难以保证良好性能。另外一方面,目前存在的XML数据划分大多采用预先处理方式,对XML数据的划分过程实质上采用了串行处理,无法充分利用分布式计算的优势进行XML解析。而综合考虑XML处理过程中的XML解析和XML查询的分布式整体解决方案尚有待发展。
技术实现要素:
为了解决上述问题,本发明提出了一种XML文档分布式查询方法及系统。
具体方案如下:
一种XML文档分布式查询方法,包括以下步骤:
S1:接收输入的XML文档和XPath查询表达式;
S2:采用分布式方式对XML文档进行分片解析,以获得各分片对应的分片树;
S3:根据各分片对应的分片树获取各分片树对应的区间编码和关系索引;
S4:根据XPath查询表达式进行查询原语重写,以获得查询原语序列;
S5:通过查询原语序列对各分片分别采用基于关系索引的原语求值方式进行求值,以获得各分片对应的局部求值结果;
S6:对各分片按XPath查询表达式对应的主路径进行求值,以获得各分片对应的预求值结果;
S7:基于XPath查询表达式对应的各分路径和各分片树汇总后的残点信息,计算各分路径对应的过滤条件;
S8:对各分路径对应的过滤条件进行汇总和合并;
S9:通过合并后的过滤条件对预求值结果进行过滤,将过滤结果与局部求值结果进行合并后得到最终查询结果。
进一步的,步骤S2中分片树的获取过程包括以下步骤:
S201:在协调机上加载XML文档,并将XML文档划分为多个分片后,将各分片分别发送至不同的工作机;
S202:工作机接收到分片后,对该分片进行XML解析,以获得该分片对应的文档树集合和XML节点的初始化调整信息,将初始化调整信息发送回协调机;
初始化调整信息包括被分割到其它分片的不可配对标签序列信息、节点的层次值信息和子树的结束位置列表信息;
S203:协调机接收到所有分片的初始化调整信息后,进行节点信息合并处理,并将合并处理后的调整结果信息发送回各工作机;
节点信息合并用于对各分片的节点信息进行全局性调整,全局性调整包括调整节点的id值和层次值;
S204:工作机接收到调整结果信息后,按照调整结果信息对步骤S202中XML解析的结果进行调整,并在调整后提取对应分片包含的残点信息发送回协调机;
S205:协调机接收到所有分片包含的残点信息后进行汇总,并根据汇总后的残点信息向各工作机发送所需的残点信息;
S206:工作机接收到残点信息后,将接收到的残点信息按文档序添加到文档树上,将添加后的结果作为分片树。
进一步的,步骤S206中添加残点信息时,残点的文档序排在原有文档树的节点之前。
进一步的,步骤S7中过滤条件求取时使用值链进行条件数据操作;值链为用于记录线性分支路径的条件值序列,序列中的元素为待过滤点或查询返回项,序列中元素的首项为第1个待过滤残点位置;末项为查询返回项或最后1个待过滤残点位置。
进一步的,步骤S5-S7中局部求值结果、预求值结果和过滤条件均通过工作机获得,工作机将局部求值结果、预求值结果和过滤条件发送回协调机后,协调机根据接收到的局部求值结果、预求值结果和过滤条件进行步骤S8和S9的操作。
进一步的,步骤S8中合并时的顺序规则是末级的谓词先合并,从后往前逐一处理各谓词。
进一步的,步骤S9中还包括对合并后的最终查询结果进行去重和排序处理。
一种XML文档分布式查询系统,包括集群的协调机和多个工作机,所述协调机和工作机均包括处理器、存储器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现本发明实施例上述的方法的步骤。
本发明采用如上技术方案,可在分布式XPath求值时充分进行数据局部化,避免工作机之间的通信;提供一站式方案,支持XML大型数据的即席(Ad-hoc)查询,支持XPath的自动分布式处理。
附图说明
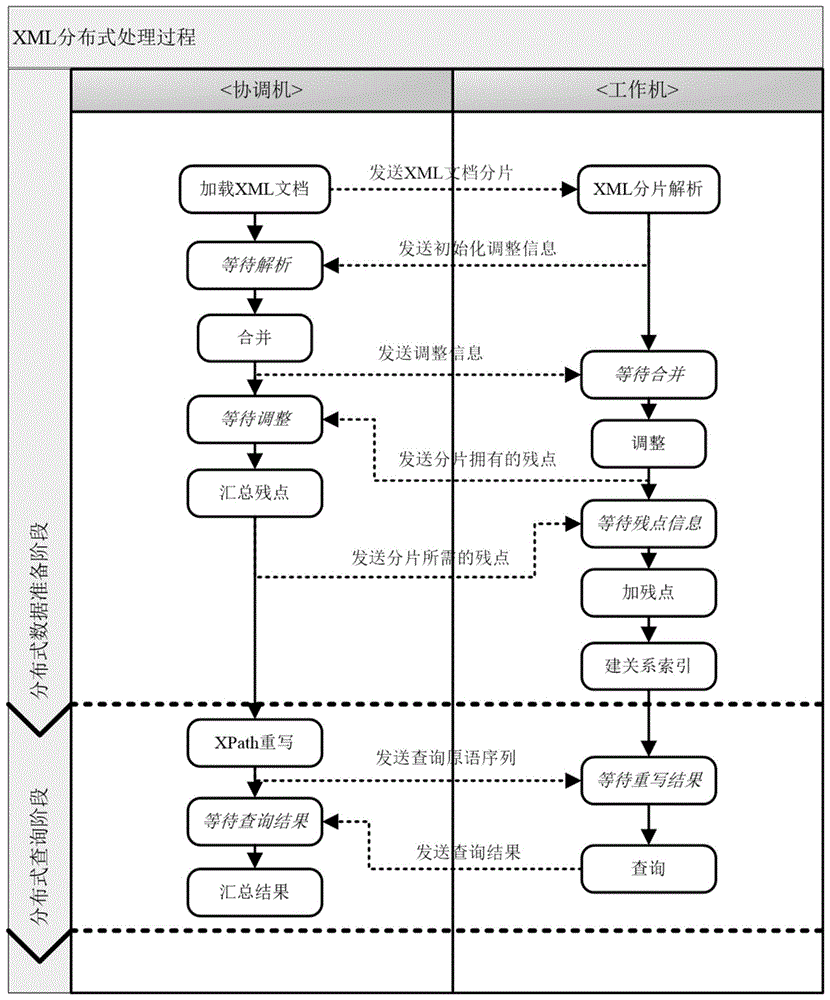
图1所示为本发明实施例一中XML分布式处理时的交互过程图。
图2所示为本发明实施例一中XML分布式处理的整体流程图。
图3所示为本发明实施例一中输入的XML文档示意图。
图4所示为本发明实施例一中分布式计算集群部署图。
图5所示为本发明实施例一中XML文档对应的文档树及分割情况图。
图6所示为本发明实施例一中XML分片2对应的分片树示意图。
图7所示为本发明实施例一中输入的XPath查询表达式对应的查询树示意图。
具体实施方式
为进一步说明各实施例,本发明提供有附图。这些附图为本发明揭露内容的一部分,其主要用以说明实施例,并可配合说明书的相关描述来解释实施例的运作原理。配合参考这些内容,本领域普通技术人员应能理解其他可能的实施方式以及本发明的优点。
现结合附图和具体实施方式对本发明进一步说明。
实施例一:
本发明实施例提供了一种XML文档分布式查询方法,参考图1和图2所示,所述方法包括以下步骤:
S1:接收输入的XML文档和XPath查询表达式。
该实施例中输入的XML文档如图3所示,输入的XPath查询表达式为“//A[/G]//B[//T[/D]/F][//U/V][//M]//K/S[//N]//E”,该查询表达式是个包含嵌套多谓词的复杂查询,其主要查询步包括求子孙轴操作(//)、求孩子轴操作(/)和谓词求值([])。
S2:采用分布式方式对XML文档进行分片解析,以获得各分片对应的分片树。
该实施例中采用的分布式方式通过集群的协调机和多个工作机进行,参考如图4所示的具体交互方式,分片树的获取过程包括以下步骤:
S201:在协调机上加载XML文档,并将XML文档划分为多个分片后,将各分片分别发送至不同的工作机。
该实施例中分片的数量由工作机的数量决定,优选设定为与工作机的数量相等。如图3所示,将XML文档按虚线划分为3个分片。
S202:工作机接收到XML文档格式的分片后,对该分片进行XML解析,以获得该分片对应的文档树集合和XML节点的初始化调整信息,将初始化调整信息发送回协调机。
初始化调整信息包括被分割到其它分片的不可配对标签序列信息、节点的level值信息和子树的结束位置列表信息。例如,第2分片解析后获得的文档树集合为{子树1(节点F,id=0),子树2(节点K,id=1;节点S,id=2;节点N,id=3)}。注意到此时获得的节点信息中的节点ID值和节点level值是该节点所在的子树内的相对值;节点的开始和结束位置是该节点在XML分片中的位置。节点信息中的标签名tagName以哈希表形式独立存储以便于查询。获得的初始化调整信息包括不可配对标签序列{尾标签T,头标签K,头标签S}、节点的level值信息{节点F的level=0,节点K的level=0,节点S的level=1,节点N的level=2}和子树的结束位置列表{子树1结束位置,子树2结束位置}。
S203:协调机接收到所有分片的初始化调整信息后,进行节点信息合并处理,并将合并处理后的调整结果信息发送回各工作机。
由于各分片解析的结果相互独立,未考虑全局情况,节点信息合并的作用是根据获得的各分片的初始化调整信息进行节点信息的全局性调整。调整结果是获得全局的节点id值,全局的节点level值。对于来自分片2的调整结果是{节点F的id=6,level=4;节点K的id=7,level=3;节点S的id=8,level=4;节点N的id=9,level=5}。
S204:工作机接收到调整结果信息后,按照调整结果信息对步骤S202中XML解析的结果进行调整,并在调整后提取对应分片内的残点信息发送回协调机。
该实施例中调整用于使所有节点获得全局的id值、level值、节点在文档的开始位置和结束位置信息。
在XML文档划分时,存在被分割的节点,它们的节点信息分布到不同的分片里,这种被分割的节点称为残点。从分片的角度看,这种节点不在当前分片的解析中获得,但起到逻辑上连接到原文档树的根节点的作用,残点是和具体分片有关的概念。图5是图3文档对应的文档树,其中填充灰底色的节点是残点。
需要注意的是,该步骤提取的残点信息已经属于全局信息。例如分片2发送的残点是本分片含有的节点K和节点S。
S205:协调机接收到所有分片包含的残点信息后进行汇总,并根据汇总后的残点信息向各工作机发送所需的残点信息。
各工作机发送所需的残点信息为各工作机对应分片的文档树形成分片树所需的残点信息。该实施例中汇总后的残点信息为残点列表{R,A,B,T,K,S},残点信息R、A、B和T发送给分片2所在的工作机,残点信息R、A、B、K和S发送给分片3所在的工作机。需要注意的是,分片1不需要添加残点,所以不需要发送残点信息到分片1所在的工作机。
S206:工作机接收到残点信息后,将接收到的残点信息按文档序添加到文档树上,将添加后的结果作为分片树。
分片树是指添加了残点信息后,形成的一棵以原文档树的根节点为根,包含分片中所有节点的完整文档树。例如分片2对应的分片树如图6所示,该分片的残点是节点R、A、B和T。为了便于描述,与残点相对应的是完点,表示该节点没有被分割,而是完整地存在于某个分片中。例如图5中不带底色的节点G、D、F和N等为完点。
需要注意的是,添加残点信息时,残点的文档序排在原有文档树的节点之前。
S3:根据各分片对应的分片树获取各分片树对应的区间编码和关系索引。
该实施例中各分片树对应的区间编码和关系索引的获取工作在各工作机上进行。
XML数据的区间编码用于纪录XML节点信息,形式如6元组εu<id,nodeType,tagName,begin,end,level>所示,其中,id表示节点id值;nodeType表示节点类型,考虑最常用的节点类型为元素和属性这两种XML节点,因此nodeType∈{ELEMENT,ATTRIBUTE},ELEMENT表示元素,ATTRIBUTE表示属性;tagName表示节点的标签名;begin表示节点在文档中的开始位置;end表示节点在文档中的结束位置;level表示节点的层次值。
XML数据的关系索引为对XML节点之间的有效关系进行记录的存储结构,用元组形式进行表示,如<u,v,ru→v>,表示节点u和节点v的唯一的有效关系类型值为r,r∈{DS,CH,AT},其中DS、CH、AT分别代表子孙关系、孩子关系、属性关系。
某个节点u的关系索引是指该节点和与该节点存在(DS、CH或AT)有效关系的所有XML文档序后续节点v的关系索引集合。对于图3的文档案例的解析结果文档树如图5所示,其中,按文档序第3个节点的区间编码为<2,ELEMENT,‘G’,28,32,2>,第8个节点的区间编码为<7,ELEMENT,‘K’,176,334,3>;第3个节点对应的关系索引为{<>},第8个节点对应的关系索引为{<7,8,CH>,<7,9,DS>,<7,10,DS>}。
由于分片树是以原文档树的树根为根的完整树,且完成了必要的调整,在此基础上可以直接进行关系索引的创建。若u,v为采用区间编码的XML节点,对于孩子、子孙和属性的节点关系求取的基本规则分别如下:
①(u,v)=‘CH’if(u.begin<v.begin)∧(v.begin<u.end)∧(u.level=v.level-1)∧(v.nodeType=ELEMENT)
②(u,v)=‘DS’if(u.begin<v.begin)∧(v.begin<u.end)∧(u.level≠v.level-1)∧(v.nodeType=ELEMENT)
③(u,v)=‘AT’if(u.begin<v.begin)∧(v.begin<u.end)∧(u.level=v.level-1)∧(v.nodeType=ATTRIBUTE)
规则②中,由于两节点之间只存储一个关系,而语义上DS包含有CH,因此,建索引时考虑加了u.level≠v.level-1这个约束条件。当求取DS关系时,在查询原语设计时包含了CH的信息。为了优化处理,增加一个辅助关系‘NN’表示节点间没有关系。关系索引的构建过程中需要进行关系求取计算,利用节点的区间编码和节点关系求取规则计算两两节点之间的关系;然后把关系值存储到关系索引中。
S4:根据XPath查询表达式进行查询原语重写,以获得查询原语序列。
例如步骤S1输入的XPath查询表达式重写后的查询原语序列如下:
1:input1←GetDescendant(input0,‘A’);
2:input2←GetChild(input1,‘G’);
3:input3←FilterInput1ByInput2(input1,input2);
4:input4←GetDescendant(input3,‘B’);
5:input5←GetDescendant(input4,‘T’);
6:input6←GetChild(input5,‘D’);
7:input7←FilterInput1ByInput2(input5,input6);
8:input8←GetChild(input7,‘F’);
9:input9←FilterInput1ByInput2(input4,input8);
……(略)
其中input0、input1...是当前上下文的XML节点序列;GetDescendant是求子孙原语;GetChild是求孩子原语;FilterInput1ByInput2是谓词过滤原语。这些求值原语基于关系索引进行求值。
S5:通过查询原语序列对各分片分别采用基于关系索引的原语求值方式进行求值,以获得各分片对应的局部求值结果。
该实施例中对于步骤S1输入的XPath查询表达式的局部求值结果为空。
S6:对各分片按XPath查询表达式对应的主路径进行求值,以获得各分片对应的预求值结果。
主路径是指包含返回查询项的分路径。针对XPath查询表达式“//A[/G]//B[//T[/D]/F][//U/V][//M]//K/S[//N]//E”,最终返回的查询项是E,因此主路径为//A//B//K/S//E。
该实施例中,主路径在分片3获得的预计算结果为节点E;在其他分片获得的预计算结果为空。
S7:基于XPath查询表达式对应的各分路径和各分片汇总后的残点信息,计算各分路径对应的过滤条件。
分路径是指从查询树中的根项到叶子项之间形成的线性查询路径。针对XPath查询表达式“//A[/G]//B[//T[/D]/F][//U/V][//M]//K/S[//N]//E”,其分路径包括://A/G、//A//B//T/D、//A//B//T/F、//A//B//U/V、//A//B//M、//A//B//K/S//N和//A//B//K/S//E。
步骤S205中汇总后的残点信息为残点列表{R,A,B,T,K,S}。
在XPath谓词求值时的输入节点称为待过滤点,而其他情况的输入节点为非待过滤点。若待过滤点是残点,则称其为待过滤残点。例如对图5的XML文档树进行查询,对于谓词查询表达式//B[],在进行谓词求值时,输入的节点B为待过滤点。对于步骤S1输入的XPath查询表达式,待过滤点包括A、B、T和S输入节点。由于按图5进行分片,使得节点B为残点,因此该节点为待过滤残点。步骤S1输入的XPath查询表达式采用XPath查询树表示如图7所示。
过滤条件求取时使用了值链进行条件数据操作。值链指用于记录线性分支路径的条件值序列,序列中的元素为待过滤点或查询返回项,序列中元素的首项为第1个待过滤残点位置;末项为查询返回项(对于主路径)或者最后1个待过滤残点位置(对于其他分路径)。值链的记录形式为<vn-1,vn-2,…,v0>,对应的节点从v0到vn-1对应的节点序为递增顺序。
S8:对各分路径对应的过滤条件进行汇总和合并。
汇总时按分路径进行汇总。
合并时需要按序进行,合并的顺序规则是末级的谓词先合并,从后往前逐一处理各谓词。
S9:通过合并后的过滤条件对预求值结果进行过滤,将过滤结果与局部求值结果进行合并后得到最终查询结果。
该实施例中由于步骤S5-S7中的局部求值结果、预求值结果和过滤条件均通过工作机获得,因此,进行步骤S8和S9时,首先需要工作机将局部求值结果、预求值结果和过滤条件发送回协调机,协调机根据接收到的局部求值结果、预求值结果和过滤条件进行步骤S8和S9的操作。
进一步的,由于合并后得到的最终查询结果可能包含重复结果,因此还需要对其进行去重和排序处理。
用步骤S1输入的XPath查询表达式“//A[/G]//B[//T[/D]/F][//U/V][//M]//K/S[//N]//E”对图5的XML文档树进行查询的实例来说明过滤条件的求取和汇总及合并过程。
(1)过滤条件的求取
在各分路径过滤条件求取过程中,记录对应的待过滤点{//A,//A//B,//A//B//T,//A//B//K/S},再和解析时获得的残点列表{R,A,B,T,K,S}对照,即可获得待过滤残点信息{A,B,T,S}。
①:求取//A/G过滤条件,由于A为待过滤点,G为非待过滤点,记录值链<A>。
②:求取//A//B//T/D过滤条件,由于A、B和T为待过滤点,而D为非待过滤点,记录值链<T,B,A>。值链中相同条件仅需要记录一个值链即可,假设获得值链有<t0,b0,a0>,<t0,b0,a0>,<t1,b0,a0>和<t2,b1,a1>,由于存在相同的T(即有相同节点t0),最后保留的值链为<t0,b0,a0>,<t1,b0,a0>和<t2,b1,a1>。具体过程如下:
求取A//B时,返回值链<B,A>;
求取B//T时,返回值链<T,B,A>;
求取T/D时,返回值链<T,B,A>。
③:求取//A//B//T/F过滤条件,记录值链<T,B,A>。
④:求取//A//B//K/S//N过滤条件,由于A、B和S为待过滤点,而K,N为非待过滤点。需要记录值链<S,B,A>。具体过程如下:
求取A//B时,返回值链<B,A>;
求取B//K时,返回值链<K,B,A>;
求取K/S时,返回值链<S,B,A>;
求取S//N时,返回值链<S,B,A>。
⑤:求取//A//B//K/S//E过滤条件,由于E为返回项,记录值链<E,S,B,A>。
⑥:求取//A//B//U/V过滤条件,记录值链<B,A>。
⑦:求取//A//B//M过滤条件,记录值链<B,A>。
(2)过滤条件的汇总
对某个线性路径,对来自各块的结果进行汇总:
如对②的汇总,只要记录不同的T,即对相同的T进行合并,获得<T,B,A>;
如对⑤的汇总,只要记录不同的S,即对相同的S进行合并,获得<S,B,A>;
如对⑥的汇总,只要记录不同的B,即对相同的B进行合并,获得<B,A>。
(3)过滤条件的合并:
⑧:②∩T③,获得同T的<B,A>,即T同时存在于②和③,注意同T必同B和同A。
⑨:④∩S⑤,获得同S的<E,B,A>,注意同S必同B和同A。由于E为最后结果,要保留。
⑩:⑧∩B⑨∩B⑥∩B⑦,获得同B的<E,A>,注意同B必同A。
⑩∩A①,获得最终的过滤条件的值链<E,A>。
根据最终过滤条件对预求值结果进行过滤,获得查询结果{E}。由于本实施例上述示例中的局部求值结果为空,不需要合并操作;由于该示例仅有一个结果,不需要除重和排序操作。
该实施例中在协调机和工作机上分别部署相应的处理程序,以同步等待方式,通过通信协调完成分布式计算。从整体的功能框架角度,协调机处理的主要处理逻辑用算法形式描述如算法1(a)所示;工作机处理的主要处理逻辑用算法形式描述如算法1(b)所示。
算法1(a):协调机处理逻辑
输入:XML文档数据及查询
输出:XML查询结果
1:Sync{//同步开始
2://发送XML分片给各个工作机
3:wait;//等待
4:MakeJoin();//合并
5:wait;//等待
6:CollectAllVNodeDetailPart();//汇总残节点信息
7://发送查询请求
8:wait;//等待
9:CollectAllQueryResult();//汇总查询结果
10:}//同步结束
11:
算法1(b):工作机处理逻辑
1:Sync{//同步开始
2:wait;//等待
3:ParseBlock();//进行XML分片解析
4:wait;//等待
5:AdjustBlock();//调整
6:wait;//等待
7:AddVNode();//加残点
8:CreateRelationIndex();//创建关系索引
9:wait;//等待
10:DoQuery();//进行查询
11:}//同步结束
本发明实施例采用可支持XML任意分片的解析方式进行分布式XML解析;采用基于关系索引进行高效的导航式XPath求值,关系索引的创建以分布式方式完成;采用预计算判别分布式XPath求值方法,可在分布式XPath求值时充分进行数据局部化,避免工作机之间的通信;提供一站式方案,支持XML大型数据的即席查询,支持XPath的自动分布式处理。
实施例二:
本发明还提供一种XML文档分布式查询系统,包括集群的协调机和多个工作机,所述协调机和工作机均包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现本发明实施例一的上述方法实施例中的步骤。
进一步地,作为一个可执行方案,所述协调机和工作机可以是桌上型计算机、笔记本、掌上电脑及云端服务器等计算设备。
尽管结合优选实施方案具体展示和介绍了本发明,但所属领域的技术人员应该明白,在不脱离所附权利要求书所限定的本发明的精神和范围内,在形式上和细节上可以对本发明做出各种变化,均为本发明的保护范围。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。