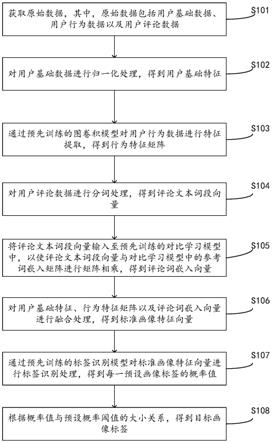
1.本发明涉及分布式边缘学习领域,特别涉及一种针对层次化模型训练框架的聚合频率控制方法。
背景技术:
2.越来越多的边缘设备接入到互联网,如移动电话、物联网设备等,这些设备产生丰富的数据信息。由于通信成本的高昂和数据隐私的保护,直接将大量的数据从数据源传输到云数据中心进行机器学习训练是不现实的。为了解决这个挑战,边缘智能应运而生,它指在尽可能靠近数据源的地方运行ai算法的范例,其数据是在设备上创建的。在边缘智能领域,现有的模型训练框架有联邦学习(h.mcmahan,e.moore,d.ramage et al.,“communication efficient learning of deep networks from decentralized data,”in aistats,2017.)和local sgd(stich,sebastian u..“local sgd converges fast and communicates little.”arxiv abs/1805.09767(2019):n.pag.),系统中所有节点被逻辑上分为训练节点和聚合节点,训练节点并行地进行一定次数的本地训练后,把模型参数或梯度发送给聚合节点,聚合节点负责聚合各个训练节点发送过来的参数,并将更新后的参数下发给各个训练节点,再迭代地进行以上步骤。这种集中式的模型训练框架有以下缺点:有些训练节点因为计算资源受限且工作负载大,进行本地更新的速度非常慢,称为掉队者,影响整个训练的收敛速率。另外,因为训练节点到聚合节点的通信带宽受限,会影响传输效率,称为通信的瓶颈。集中式的模型训练框架还会面临单点故障问题,当中心节点出现故障会影响整个训练的进行。
3.为了解决集中式模型训练框架的缺点,层次化的模型训练框架应运而生,如e-tree learning,hierarchical federated learning(hfl)等等。这些层次化的模型训练框架采用了一个“树形”的聚合结构,其中叶子节点作为训练节点负责本地训练,非叶子节点作为聚合节点负责模型聚合。“树形”结构,包括树的层数和节点分组是根据网络拓扑和数据分布构建的,能够适用于包括动态的多跳网络的任何基础结构。
4.在层次化的模型训练框架中,最有挑战性和最重要的问题是优化“树形”结构中每一个边缘节点的聚合频率。边缘计算环境具有以下特征:第一,边缘设备具备一定的计算能力和存储能力,其大小可以不同,从传感器、家庭网关、小型的服务器到带有多个服务器机架的微型数据中心,这些设备具有不同的计算能力和存储能力,这使得边缘环境下的边缘设备具有计算资源异构的特点;第二,边缘设备之间的通信链路上的网络资源异构,各链路可获得的带宽是异构并且受限的;第三,边缘设备之间具有的数据量不同以及数据是非独立同分布的,因为设备归属于某个用户,其数据分布往往是差异极大的,而且由于受到用户群体、地域关联等隐私影响,这些设备的数据分布往往都是有关联的。在层次化的模型训练框架中,现有的通信方法都是采用强同步的通信方式,要求同一层的所有节点以同样的步调进行训练或聚合。这种强同步的通信方式不适用于异构的边缘环境,因为各个节点进行训练或聚合的速度不同,如果要完全以同样的步调训练,各个节点之间需要彼此等待,造成
计算资源的浪费,甚至会影响训练收敛和模型精度。
5.在节点聚合频率控制方面,现有的工作,例如parallel mini-batch sgd,local sgd,federated learning,和hfl(liu,lumin et al.“client-edge-cloud hierarchical federated learning.”icc2020-2020ieee international conference on communications(icc)(2020):1-6.)采用强同步的通信方式,即在同一层的节点具有相同的聚合频率,聚合节点负责周期性地计算模型参数的带权平均值。如图1所示,这种通信方式的缺点是,训练速度快的节点需要等待其他节点训练完,才能继续往下推进,这会造成训练速度快的节点的资源浪费。这种强同步的通信方式不适用于异构的边缘环境。为了解决这个问题,e-tree learning和pr-sgd(yu,hao et al.“parallel restarted sgd with faster convergence and less communication:demystifying why model averaging works for deep learning.”aaai(2019).)采用了弱同步的通信方式,它允许各个训练节点具有不同的聚合频率。它提出允许速度快的节点进行更多轮的本地更新和模型聚合,以最大化地利用资源和减少节点的等待时间。但是,这些工作缺少实验验证弱同步这种通信方式的有效性,以及缺少对每个节点的聚合频率进行量化的方法。
技术实现要素:
6.为了解决上述问题,本发明提供一种针对层次化模型训练框架的聚合频率控制方法。本发明将考虑在层次化的模型聚合框架下,采用弱同步的通信方式,针对边缘环境资源异构的特点,对边缘节点的聚合频率进行优化,目标是提高节点的资源利用率,训练的收敛速率及模型精度。因此,本发明设计了基于异构资源的聚合频率控制方法,该方法能够充分利用节点的资源。此外,在该方法的基础上提出在训练模型的过程中,自适应地调整节点频率以减少因节点聚合频率相差太大带来的精度下降。
7.本发明至少通过如下技术方案之一实现。
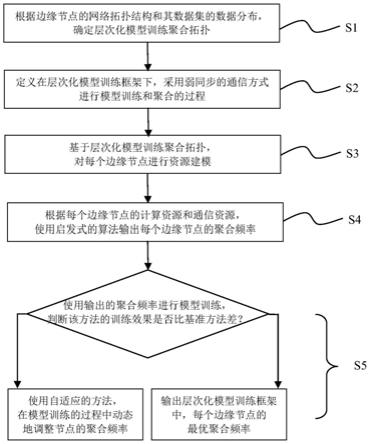
8.一种针对层次化模型训练框架的聚合频率控制方法,其特征在于,包括以下步骤:
9.s1、根据边缘节点的网络拓扑结构和其数据集的数据分布,确定层次化模型训练聚合拓扑,边缘节点以树的形式连接,叶子节点负责进行本地更新,非叶子节点负责模型聚合;
10.s2、定义在层次化模型训练框架下进行模型训练和聚合的过程;
11.s3、基于层次化模型训练聚合拓扑,对每个边缘节点进行资源建模;
12.s4、根据每个边缘节点的计算资源和通信资源,使用启发式的算法输出每个边缘节点的聚合频率;
13.s5、使用输出的聚合频率在层次化模型训练框架下进行模型训练,判断该方法的训练效果是否比基准方法差,如果比基准方法好,则步骤s4的输出为每个边缘节点的最优聚合频率;如果比基准方法差,则使用自适应的方法,在模型训练的过程中动态地调整节点的聚合频率。
14.进一步地,所述步骤s1具体为:
15.s101、使用节点分组算法,根据物理网络拓扑、边缘节点所拥有的资源以及其数据分布,将同一层次的边缘节点分成不同的小组,组内的边缘节点会进行模型聚合;
16.s102、找出每一组节点的中心节点,所述中心节点负责模型聚合,组内的所有节点
作为其孩子节点;孩子节点在本地进行模型训练或模型聚合,并将聚合后的模型参数传输给中心节点进行模型聚合,中心节点聚合完成后将聚合后的模型参数下发给中心节点的所有子孙节点,此步骤中,每一个分组节点构成一颗子树;
17.s103、把步骤s102中构建的子树作为新的节点,形成新的网络拓扑结构,以进行进一步的分组,在新的网络拓扑结构中,步骤s102构建的子树的根节点是网络拓扑中的一个顶点;重复进行步骤s101和步骤s102,对子树进行分组,并形成新的子树结构,直到最终只剩下一颗子树,该子树就是最终确定的层次化模型训练聚合拓扑。
18.进一步地,步骤s2是在层次化模型训练框架下采用弱同步的通信方式进行模型训练和聚合的过程:
19.根据网络拓扑和数据分布,边缘节点组织成树的形状,其中叶子节点作为训练节点进行本地更新,非叶子节点作为聚合节点进行模型聚合;若一个边缘节点拥有更多的资源,则该边缘节点既是训练节点,也是聚合节点;一个节点拥有更多的资源,指的是在同一分组内连接同一个父节点的孩子节点进行本地计算和模型传输所花费的时间比其他节点少;
20.整个模型训练过程,按照层次化的模型训练聚合拓扑,自底向上地进行训练,分为本地更新和模型聚合两个步骤;对于本地更新,叶子节点i并行地进行轮本地更新;接着,叶子节点把本地训练后得到的模型参数上传给其父节点p;对于模型聚合,父节点p接收到其所有孩子节点的模型参数后,计算所有节点模型参数的带权平均和,并把聚合后的模型参数下发给其所有的子孙节点;当聚合节点进行轮的模型聚合后,聚合节点把更新的模型参数发送给其父节点进行模型聚合;整个训练过程,递归地自下往上,直到根节点进行完一轮的全局聚合,并把聚合的模型参数下发给其所有的子孙节点,此时根节点完成一轮全局聚合,即为一轮模型训练,其中,表示在树形结构的第h层且其父节点是p的边缘节点i的聚合频率值;当h=1时,表示边缘节点i的本地更新频率,节点i是训练节点负责本地更新;当1《h时,表示边缘节点i的模型聚合频率,节点是聚合节点负责模型聚合。
21.进一步地,本地模型参数ωi(ki)的更新遵循以下方式:
22.当时,在树形结构第一层的边缘节点进行本地更新,并且更新其本地模型参数:
[0023][0024]
其中,ki表示节点i进行第ki轮本地更新,表示节点i进行第ki轮本地更新时的学习率,表示神经网络反向传播时损失函数的梯度大小;层次化模型训练聚合拓扑呈树形结构,其中叶子节点进行本地更新,即每个叶子节点使用其本地的数据集,对本地模型进行梯度计算,并根据规则更新模型参数;叶子节点进行一定轮次的本地更新后,会把本地模型参数传输给其父节点进行聚合;本地模型参数ωi(ki)指的是每个叶子节点,利用其本地数据集对本地模型进行更新后,传输给其父节点的模型参数;当叶子节点的祖先节点进行完一轮的模型聚合后,也会将聚合后的模型参数下发给该叶子节点,并且更新该叶子节点的本地模型参数ωi(ki);
[0025]
当时,在树形结构第二层的边缘节点进行模型聚合,公式为:
[0026][0027]
其中,c
p,h
表示在树形结构的第h层的节点p的孩子节点集合;di表示节点i的本地数据集;|d
p,h
|表示在树形结构的第h层的节点p,其所有孩子节点共有的本地数据集数量;表示在树形结构的第h层且其父节点是p的边缘节点i,进行模型聚合后的模型参数;
[0028]
当时,在树形结构第h层的边缘节点进行模型聚合,公式为:
[0029][0030]
其中,h表示层次化模型训练聚合拓扑(树形结构)的层数,表示聚合节点p
h-2
进行模型聚合后的模型参数,这个聚合节点p
h-2
在树形结构的第h层,且其父节点为p
h-1
;表示在树形结构的第h层的节点p
h-2
的孩子节点集合;d
i,h-1
表示在树形结构的第h-1层的节点i,其所有孩子节点共有的本地数据集;表示聚合节点i进行模型聚合后的模型参数,这个聚合节点i在树形结构的第h-1层,且其父节点为p
h-2
;
[0031]
对于祖先节点为p
h-2
的所有叶子节点,这些叶子节点的模型参数更新为
[0032]
当时,在树形结构的第h层的根节点进行全局聚合,并把聚合后的模型参数下发给其所有的子孙节点,全局聚合的公式为:
[0033][0034]
其中,ω
t
表示在第t轮模型训练的全局模型参数,对于每一个叶子节点,它们的模型参数更新为ω
t
;n表示网络拓扑中边缘节点的数量,d表示网络拓扑中所有边缘节点的本地数据集。
[0035]
进一步地,所述步骤s3对每个边缘节点进行资源建模,包括以下步骤:
[0036]
s301、对于计算资源,在批处理大小、学习率确定的情况下,进行预训练,获得每个边缘节点进行一轮本地更新所需的平均时间其中i表示边缘节点的序号,p是边缘节点i的父节点;预训练的实验条件跟正式的模型训练相同,包括边缘设备所分配的计算和通信资源,预训练的实验条件所拥有的数据集,进行机器学习训练的批量大小、学习率相同;
[0037]
s302、对于通信资源,评估节点间传输时间:
[0038][0039]
其中,b
i,j
表示边缘节点i和节点j间的网络带宽,d表示传输的模型大小。
[0040]
进一步地,步骤s4中,使用启发式的算法输出每个边缘节点的聚合频率其中,i表示边缘节点的序号,且边缘节点在树中的父节点是p,h表示边缘节点在树的层级,确定
在树形结构中每个边缘节点的聚合频率,包括以下步骤:
[0041]
s401、以连接到同一父节点的边缘节点为一组,比较组内边缘节点的资源异构程度;
[0042]
s402、找到每一组节点中的掉队者,即在本地计算和模型传输中花费最长时间的节点,并将掉队者的聚合频率设置为1;
[0043]
s403、计算组内其他边缘节点的聚合频率;
[0044]
s404、在树形结构,自底向上递归地计算每一组边缘节点的聚合频率;
[0045]
s405、设置根节点的聚合频率,即为模型训练的轮数。
[0046]
进一步地,步骤s401中,将边缘节点的资源异构映射到时间的维度以比较组内边缘节点的资源异构程度,具体包括以下步骤:
[0047]
a、对于训练节点,节点i的资源指的是节点i进行一轮本地更新所花费的平均时间和节点i跟其父节点进行模型传输的时间;当节点的父节点是其本身,传输时间的值为0;
[0048]
b、对于聚合节点,节点j的资源指的是节点j进行一轮模型聚合的平均时间和节点j跟其父节点进行模型传输的时间;一轮模型聚合的时间包括聚合节点j进行聚合的时间以及聚合节点j的孩子节点中,进行相应本地更新或模型聚合和模型传输所花费最长的时间;
[0049]
c、计算树形结构中所有边缘节点所拥有的资源,包括计算时间和通信时间之和计算结果其中i表示序号为i的节点,且在树的第h层。
[0050]
进一步地,掉队者是从组中找到所拥有的资源最少的节点,即从中找到最大值其中边缘节点m即为掉队者,p1为边缘节点m的父节点;为了减少掉队者对组内训练效果的影响,将掉队者m的聚合频率设置为其中h表示节点m在树形结构的第h层。
[0051]
进一步地,对于同一组内,除了掉队者外,其他节点的聚合频率为:
[0052]
对于训练节点,计算公式为:
[0053]
对于聚合节点,计算公式为:
[0054]
其中表示组中找到所拥有的资源最少的节点,边缘节点m为掉队者,节点p1为节点m的父节点;表示从节点i传输模型参数到节点p所需的传输时间;表示节点i进行一轮本地更新所花费的平均时间,也称为计算时间,其中节点p为节点i的父节点。
[0055]
进一步地,在层次化的模型训练框架下,模型训练的过程中动态地调整节点的聚合频率,包括以下步骤:
[0056]
a、根据实时的训练效果,确定开始调整节点聚合频率的时间点t0;在时间点t0模型精度比基准方法在时间点t0时的模型精度低,且低于阈值;
[0057]
b、确定在训练过程中调整聚合频率的时间间隔t0;
[0058]
c、使用以下更新规则调整训练节点的聚合频率:
[0059][0060]
其中,表示在时间点t0的学习率,表示在时间点t0的训练损失函数值,表示步骤s4输出的每个边缘节点的聚合频率,τn表示在训练过程中,第n次调整节点聚合频率的频率值。
[0061]
与现有技术相比,本发明具有以下有益效果:
[0062]
本发明提出一种针对层次化模型训练框架的聚合频率控制方法,能够最大化节点资源的利用率、减少速度较快的训练节点的等待时间、加快模型的收敛速度以及提高模型最终的收敛精度。为了寻找一种折中的通信方式平衡同步和异步通信的优缺点,本发明根据边缘环境资源异构的特点,控制各个边缘节点的聚合频率,以充分利用节点的资源。此外,为了减少因频率相差太大带来的精度损失,本发明提出了在训练模型的过程中,动态地调整节点的聚合频率,以进一步优化节点的通信频率。
附图说明
[0063]
图1是实施例异构环境下,节点以强同步的通信方式进行模型训练的示意图;
[0064]
图2是实施例一种针对层次化模型训练框架的聚合频率控制方法的流程图;
[0065]
图3是实施例网络拓扑图;
[0066]
图4是实施例根据网络拓扑图建立层次化模型训练的过程图;
[0067]
图5是实施例展示在图4b的三层模型训练框架下进行一轮模型训练的示意图。
具体实施方式
[0068]
下面结合实施例及各个附图对本发明作进一步详细的描述,但本发明的实施不限于此。
[0069]
实施例1
[0070]
如图2所示的一种针对层次化模型训练框架的聚合频率控制方法,包括以下步骤:
[0071]
一种针对层次化模型训练框架的聚合频率控制方法,包括以下步骤:
[0072]
s1、根据边缘节点的网络拓扑结构和其数据集的数据分布,确定层次化模型训练聚合拓扑,边缘节点以“树”的形式连接,叶子节点负责进行本地更新,非叶子节点负责模型聚合;拥有异构资源的边缘节点相互连接,形成网络拓扑g=(v,e),其中,g表示非完全连接的无向图,e表示边缘节点之间的网络连接,边上的权重代表网络通信带宽;
[0073]
s2、定义在层次化模型训练框架下,采用弱同步的通信方式进行模型训练和聚合的过程;
[0074]
s3、基于层次化模型训练聚合拓扑,对每个边缘节点进行资源建模,来衡量边缘节点之间资源的异构程度;
[0075]
s4、根据每个边缘节点的计算资源和通信资源,使用启发式的算法输出每个边缘节点的聚合频率其中,i表示边缘节点的序号,且其在树中的父节点是p,h表示边缘节点在树的层级;
[0076]
s5、使用输出的聚合频率进行模型训练,判断该方法的训练效果是否比基准方法
差,如果比基准方法好,则步骤s4输出的,是每个边缘节点的最优聚合频率;如果比基准方法差,则使用自适应的方法,在模型训练的过程中动态地调整节点的聚合频率,以加快模型收敛速度以及提高模型收敛精度。
[0077]
边缘节点具有资源异构的特点,包括:计算资源异构,边缘节点拥有不同的cpu资源;数据量异构,边缘节点的本地数据集的大小不同以及进行梯度下降的批处理大小也不同;通信资源异构,边缘节点之间连接的通信资源是不同的。
[0078]
实施例2
[0079]
作为优选的例子,步骤s1可以采用以下步骤确定层次化模型训练聚合拓扑:
[0080]
s101、使用节点分组算法,根据物理网络拓扑、边缘节点所拥有的资源以及其数据分布,将同一层次的边缘节点分成不同的小组,组内的边缘节点会进行模型聚合;
[0081]
所述节点分组算法,会将网络距离相近的边缘节点分为一组,且组间节点的数据分布尽可能相近,组内节点所含有的标签类别数尽可能多。
[0082]
s102、找出每一组节点的中心节点,所述中心节点负责模型聚合,组内的所有节点作为其孩子节点;孩子节点在本地进行模型训练或模型聚合,并将聚合后的模型参数传输给中心节点进行模型聚合,中心节点聚合完成后将聚合后的模型参数下发给中心节点的所有子孙节点,此步骤中,每一个分组节点构成一颗子树。
[0083]
找到每一组的中心节点的公式为:
[0084][0085]
其中,d
i,j
表示边缘节点i到节点j的通信带宽,k
i,h
表示在树结构的第h层的第i组。
[0086]
s103、把步骤s102中构建的子树作为新的节点,形成新的网络拓扑结构,以进行进一步的分组,在新的网络拓扑结构中,步骤s102构建的子树的根节点是网络拓扑中的一个顶点;重复进行步骤s101和步骤s102,对子树进行分组,并形成新的子树结构,直到最终只剩下一颗子树,该子树就是最终确定的层次化模型训练聚合拓扑。
[0087]
作为另一优选的实施例,所述步骤s2具体可以为:在层次化模型训练框架下进行模型训练和聚合的过程为:根据网络拓扑和数据分布,边缘节点组织成“树”的形状,其中叶子节点作为训练节点进行本地更新,非叶子节点作为聚合节点进行模型聚合。若一个边缘节点拥有更多的资源,则该边缘节点既是训练节点,也是聚合节点;一个节点拥有更多的资源,指的是在同一分组内连接同一个父节点的孩子节点进行本地计算和模型传输所花费的时间比其他节点少。
[0088]
整个模型训练,遵循自底向上的训练规则,分为本地更新和模型聚合两个步骤。对于本地更新,叶子节点i并行地进行轮本地更新,目的是最小化本地的损失函数;接着,叶子节点把本地训练后得到的模型参数上传给其父节点p。对于模型聚合,父节点p接收到其所有孩子节点的模型参数后,计算所有节点模型参数的带权平均和,并把聚合后的模型参数下发给其所有的子孙节点;当聚合节点进行轮的模型聚合后,聚合节点把更新的模型参数发送给其父节点进行模型聚合;整个训练过程,递归地自下往上,直到根节点进行完一轮的全局聚合,并把聚合的模型参数下发给其所有的子孙节点,此时根节点完成一轮
全局聚合,即为一轮模型训练。其中,表示在树形结构的第h层且其父节点是p的边缘节点i的聚合频率值;当h=1时,表示边缘节点i的本地更新频率,节点i是训练节点负责本地更新;当1《h时,表示边缘节点i的模型聚合频率,节点是聚合节点负责模型聚合。
[0089]
在“树”形的模型训练聚合拓扑中,由于边缘节点之间计算资源、数据集的大小不同,每个边缘节点进行一轮本地更新或模型聚合所花费的时间是不同的。因此,为了减少训练速度快的节点的等待时间以及降低其资源的浪费,连接同一个父节点的孩子节点具有不同的聚合频率也就是它们拥有不同的本地更新或模型聚合频率。
[0090]
层次化模型训练框架下,采用弱同步的通信方式进行训练,本地模型参数ωi(ki)的更新遵循以方式:
[0091]
当时,在树形结构第一层的边缘节点进行本地更新,并且更新其本地模型参数:
[0092][0093]
其中,ki表示节点i进行第ki轮本地更新,表示节点i进行第ki轮本地更新时的学习率,表示神经网络反向传播时损失函数的梯度大小;层次化模型训练聚合拓扑呈“树”形结构,其中叶子节点进行本地更新,即每个叶子节点使用其本地的数据集,对本地模型进行梯度计算,并根据规则更新模型参数;叶子节点进行一定轮次的本地更新后,会把本地模型参数传输给其父节点进行聚合;因此,本地模型参数ωi(ki)指的是每个叶子节点,利用其本地数据集对本地模型进行更新后,传输给其父节点的模型参数;当叶子节点的祖先节点进行完一轮的模型聚合后,也会将聚合后的模型参数下发给该叶子节点,并且更新该叶子节点的本地模型参数ωi(ki)。
[0094]
当时,在树形结构第二层的边缘节点进行模型聚合,公式为:
[0095][0096]
其中,c
p,h
表示在树形结构的第h层的节点p的孩子节点集合;di表示节点i的本地数据集;|d
p,h
|表示在树形结构的第h层的节点p,其所有孩子节点共有的本地数据集数量;表示在树形结构的第h层且其父节点是p的边缘节点i,进行模型聚合后的模型参数;
[0097]
当时,在树形结构第h层的边缘节点进行模型聚合,公式为:
[0098][0099]
其中,h表示层次化模型训练聚合拓扑(树形结构)的层数,表示聚合节点p
h-2
进行模型聚合后的模型参数,这个聚合节点p
h-2
在树形结构的第h层,且其父节点为p
h-1
;表示在树形结构的第h层的节点p
h-2
的孩子节点集合;d
i,h-1
表示在树形结构的第h-1
层的节点i,其所有孩子节点共有的本地数据集;表示聚合节点i进行模型聚合后的模型参数,这个聚合节点i在树形结构的第h-1层,且其父节点为p
h-2
;
[0100]
对于祖先节点为p
h-2
的所有叶子节点,这些叶子节点的模型参数更新为
[0101]
当时,在树形结构的第h层的根节点进行全局聚合,并把聚合后的模型参数下发给其所有的子孙节点,全局聚合的公式为:
[0102][0103]
其中,ω
t
表示在第t轮模型训练的全局模型参数,对于每一个叶子节点,它们的模型参数更新为ω
t
;n表示网络拓扑中边缘节点的数量,d表示网络拓扑中所有边缘节点的本地数据集;
[0104]
所述步骤s3对每个边缘节点进行资源建模,包括以下步骤:
[0105]
s301、对于计算资源,cpu能力和数据集的大小是影响边缘节点进行本地计算的时间的主要因素;在批处理大小、学习率确定的情况下,进行预训练,获得每个边缘设备进行一轮本地更新所需的平均时间其中i表示边缘节点的序号,p是边缘节点i的父节点;预训练的实验条件跟正式的模型训练相同,包括边缘设备所分配的计算和通信资源,预训练的实验条件所拥有的数据集,进行机器学习训练的批量大小、学习率相同;唯一不相同的是,预训练只进行少轮模型训练,目的是测量出每个边缘设备进行一轮本地更新所需的时间;而正式的训练,需要进行多轮的模型训练,模型才能达到收敛;预训练和正式训练都遵循上述所约定的模型训练过程。
[0106]
s302、对于通信资源,网络带宽是影响边缘节点间传输时间的主要因素。评估节点间传输时间:
[0107][0108]
其中,b
i,j
表示边缘节点i和节点j间的网络带宽,d表示传输的模型大小。
[0109]
所述步骤s4具体为:
[0110]
s401、以连接到同一父节点的边缘节点为一组,比较组内边缘节点的资源异构程度;步骤s401将边缘节点的资源异构映射到时间的维度,其描述如下:
[0111]
a、对于训练节点,节点i的资源指的是节点i进行一轮本地更新所花费的平均时间和节点i跟其父节点进行模型传输的时间;需要注意的是,当节点的父节点是其本身,传输时间的值为0;
[0112]
b、对于聚合节点,节点j的资源指的是节点j进行一轮模型聚合的平均时间和节点j跟其父节点进行模型传输的时间;需要注意的是,一轮模型聚合的时间包括聚合节点j进行聚合的时间以及聚合节点j的孩子节点中,进行相应本地更新或模型聚合和模型传输所花费最长的时间;
[0113]
c、计算树形结构中所有边缘节点所拥有的资源,也就是计算时间和通信时间之和,结果用表示,其中i表示序号为i的节点,且在树形结构的第h层;
[0114]
s402、找到每一组节点中的掉队者,即拥有资源最少的节点,并将掉队者的聚合频
率设置为1。从组中找到本地计算和模型传输中花费最长时间的节点,即从中找到最大值其中边缘节点m即为掉队者,p1为边缘节点m的父节点;另外,为了减少掉队者对组内训练效果的影响,将掉队者m的聚合频率设置为其中h表示节点m在第h层。
[0115]
s403、计算组内其他边缘节点的聚合频率。对于同一组内,除了掉队者外,其他节点的聚合频率的计算为:
[0116]
对于训练节点,计算公式为:
[0117]
对于聚合节点,计算公式为:
[0118]
其中表示组中找到所拥有的资源最少的节点,边缘节点m为掉队者,节点p1为节点j和节点m的父节点,节点j为节点i的父节点;表示从节点i传输模型参数到节点p所需的传输时间;表示节点i进行一轮本地更新所花费的平均时间,也称为计算时间,其中节点p为节点i的父节点;此计算方法能够最大化边缘节点的利用率。
[0119]
s404、在“树”形结构,自底向上递归地计算每一组边缘节点的聚合频率;
[0120]
s405、设置根节点的聚合频率,即为模型训练的轮数。
[0121]
所述步骤s5包括以下步骤:
[0122]
s501、使用步骤s4输出的聚合频率,进行模型训练;
[0123]
s502、判断步骤s501的训练效果是否比基准方法要差。其中,基准方法指的是在同样的层次化模型训练框架中,使用强同步的通信方式进行模型训练,即在“树”形结构中,每个边缘节点的聚合频率都设置为1;判断步骤s501的训练效果是否比基准方法要差的情形是,步骤s501的模型训练收敛速度和最终的收敛精度比基准方法要快、要高。
[0124]
s503、如果是,则使用自适应的方法,在模型训练的过程中动态地调整节点的聚合频率,具体为:
[0125]
a、根据实时的训练效果,确定开始调整节点聚合频率的时间点t0;这个时间点指步骤s501在t0时间点的模型精度比基准方法在t0时的模型精度低,且低于某个阈值;
[0126]
b、确定在训练过程中调整聚合频率的时间间隔t0,这个时间间隔可以手动设置;
[0127]
c、使用以下更新规则来调整训练节点的聚合频率:
[0128][0129]
其中,η
t
表示在时间点t的学习率,表示在时间点t0的训练损失函数值,表示步骤s4输出的每个边缘节点的聚合频率,τn表示在训练过程中,第n次调整节点聚合频率的频率值;需要注意的是,步骤s503只适应地调整“树”形结构中,叶子节点(即训练节点)的聚合频率值。
[0130]
s504、如果不是,则步骤s4输出的结果就是层次化模型训练框架中每个边缘节点
的最优聚合频率。
[0131]
实施例3
[0132]
作为另一优选的实施例,如图1和图3所示,使用拥有异构资源的5个边缘节点作为例子,对本发明的一种针对层次化模型训练框架的聚合频率控制方法,进行详细说明,具体步骤如下:
[0133]
s1、根据边缘节点的网络拓扑结构和其数据集的数据分布,确定层次化模型训练聚合拓扑,边缘节点以“树”的形式连接,叶子节点负责进行本地更新,非叶子节点负责模型聚合;
[0134]
图3为网络拓扑图,在图中,拥有异构资源的5个边缘节点相互连接,形成网络拓扑g=(v,e),其中,每个边缘节点vi可用三元组表示其所拥有的资源{cpu,data size,data distribution},如{2cores,1400datasets,5classes}表示边缘节点vi分配了2核的cpu,本地数据集共有1400个训练样本,数据集中共有5种类型的标签;边缘节点之间的网络连接情况可以用三元组表示,如{v1,v2,500bps}表示节点v1与v2相连,并且通信带宽为500bps。
[0135]
需要说明的是,在实际的边缘环境中,无法准确地得知每个边缘节点的数据分布,只能通过在同等条件下进行模型训练,根据训练模型的精度来评估边缘节点的数据分布情况。
[0136]
图4为根据网络拓扑图(图3)建立层次化模型训练框架的过程,其中图4a为建立层次化模型训练框架的中间过程,图4b为最终的层次化模型训练拓扑。
[0137]
s101、使用节点分组算法,根据物理网络拓扑、边缘节点所拥有的资源以及其数据分布,将同一层次的边缘节点分成不同的小组,组内的边缘节点会进行模型聚合;
[0138]
由于节点v1和节点v2的网络距离相近(节点间通信带宽比较大),且两个节点的本地数据集共有8种类型的标签,假设节点v1和节点v2的数据集所含的标签不重合,故将节点v1和节点v2分为一组;由于节点v3、v4和v5的网络距离相近,且三个节点的本地数据集共有8种类型的标签(组间节点的数据分布尽可能相近,组内节点所含有的标签类别数尽可能多),假设v3、v4和v5的数据集所含的标签不重合,故将节点v3、v4和v5分为一组。因此,根据图3的网络拓扑图,可将节点分为两个组,分别为c1={v1,v2}和c2={v3,v4,v5}。
[0139]
s102、找出每一组节点的中心节点,这个中心节点负责模型聚合,组内的其他节点(包括中心节点)作为其孩子节点。孩子节点会在本地进行模型训练或模型聚合,并将其模型参数传输给中心节点进行模型聚合,中心节点聚合完成后将聚合后的模型参数下发给其所有的孩子节点。
[0140]
当组内只有两个节点时,拥有更多的计算资源的节点作为中心节点,如组c1中只有两个节点,其中节点v1拥有4核的cpu,节点v2拥有2核的cpu,节点1具备更强的计算能力,因此,组c1的中心节点为v1。
[0141]
当组内的节点数大于两个时,找到的中心节点应满足,该中心节点距离同一组内的其它节点的网络距离之和是最小的,或该中心节点跟同一组内的其他节点的网络带宽之和是最大的。对于小组c2:
[0142][0143]
[0144][0145]
因此,组c2的中心节点为v3,其跟同一组其他节点的网络带宽之和是最大的。
[0146]
确定每一组的中心节点后,每一个小组可以连接成“树”形结构,中心节点作为父节点,小组内的所有节点作为孩子节点,中心节点既为父节点,也为孩子节点。
[0147]
s103、自底向上逐层地找到所有分组的中心节点,直到找到层次化模型训练框架的根节点为止。
[0148]
如图4a所示,步骤s202形成了两棵树,把这两棵树看成新的“边缘节点”重复步骤s201和s202。目前,只剩下两个“边缘节点”,将这两个节点分为一组为c3。根据s202,节点v1拥有更多的cpu资源,因此,组c3中心节点为v1。将节点v1作为父节点,连接两棵树。到此,层次化模型训练聚合拓扑形成,如图4b所示。
[0149]
s2、定义在层次化模型训练框架下,采用弱同步的通信方式进行模型训练和聚合的过程。
[0150]
以图4b为例,“树”形结构有三层,共有5个叶子节点。叶子节点作为训练节点负责模型训练,非叶子节点作为聚合节点负责模型聚合。其中,在“树”的第一层,训练节点1和训练节点2为一组,它们的父节点为聚合节点1,由聚合节点1进行模型聚合;训练节点3、训练节点4和训练节点5为一组,它们的父节点为聚合节点3;在“树”的第二层,聚合节点1和聚合节点3为一组,它们的父节点为聚合节点1,由根节点1进行全局模型聚合。
[0151]
由于边缘节点具有资源异构的特点,采用弱同步的通信方式进行模型训练和聚合,也就是说连接到同一个父节点的孩子节点具有不同的聚合频率图5展示在图4b的三层模型训练框架下进行一轮模型训练的过程。因为具有不同的资源,叶子节点1到5进行不同次数的本地更新,分别是和次,才把模型参数上传给它们的父节点1和3。由于叶子节点1和3,它们的父节点是它们本身,因此它们的传输时间为0。对于在“树”结构的第二层的节点,聚合节点1和3在传输模型参数给它们的父节点1之前,会分别进行和次的模型聚合。根节点1负责全局聚合,并把更新的模型参数下发给其所有子孙节点。到此,我们认为一轮模型训练结束。根据根节点的聚合频率进行相应轮数的全局聚合。
[0152]
s3、基于层次化模型训练聚合拓扑,对每个边缘节点进行资源建模,来衡量边缘节点之间资源的异构程度;
[0153]
需要说明的是,在实际的环境中是无法准确地获取边缘节点的资源信息的,因此本发明通过预训练和理论计算,将边缘节点的所拥有的资源映射为计算时间或通信时间。
[0154]
s301、对于计算资源,cpu能力和数据集的大小是影响边缘节点进行本地计算的时间的主要因素;在批处理大小、学习率等确定的情况下,进行预训练,获得每个边缘设备进行一轮本地更新所需的平均时间其中i表示边缘节点的序号,p是边缘节点i的父节点;假设,通过预训练,图4b的边缘节点所对应的进行一轮本地更新的时间为假设,通过预训练,图4b的边缘节点所对应的进行一轮本地更新的时间为
[0155]
s302、对于通信资源,网络带宽是影响边缘节点间传输时间的主要因素。评估节点
间传输时间的公式为:其中,b
i,j
表示边缘节点i和节点j间的网络带宽,d表示传输的模型大小。假设d为1000bit,通过理论计算,图4b的边缘节点之间所对应的传输时间为
[0156]
s4、根据每个边缘节点的计算资源和通信资源,使用启发式的算法输出每个边缘节点的聚合频率其中,i表示边缘节点的序号,且其在树中的父节点是p,h表示边缘节点在树的层级;
[0157]
以图4b的层次化模型训练框架为例,自底向上递归地计算每一组边缘节点的聚合频率;
[0158]
首先,计算叶子节点(第一层)的本地更新频率:
[0159]
s401、比较组内边缘节点的资源异构程度,即计算组内每个边缘节点所拥有的资源,结果用表示,其中i表示序号为i的节点,且在“树”的第i层;对于训练节点,节点i的资源指的是节点i进行一轮本地更新所花费的平均时间和节点i跟其父节点进行模型传输的时间;需要注意的是,当节点的父节点是其本身,传输时间的值为0;
[0160]
因此,对于小组c1={v1,v2},组内的边缘节点所拥有的资源可表示为},组内的边缘节点所拥有的资源可表示为对于小组c2={v3,v4,v5},组内的边缘节点所拥有的资源可表示为需要注意的是,边缘节点所拥有的资源越多,进行一次本地计算和通信的时间就越短。
[0161]
s402、找到每一组节点中的掉队者,即拥有资源最少的节点,并将掉队者的聚合频率设置为1。对于小组c1={v1,v2},掉队者为节点v2,因为它是组内进行本地计算和模型传输花费时间最长的节点,其所花费的时间为为了减少掉队者对组内训练效果的影响,将节点v2的频率设置为对于小组c2={v3,v4,v5},掉队者为节点v4,其所花费的时间为将节点v4的频率设置为
[0162]
s403、计算组内其他边缘节点的聚合频率。对于同一组内,除了掉队者外,其他节点的聚合频率的计算公式为:其中边缘节点m为掉队者,节点p1为节点j和节点m的父节点,节点j为节点i的父节点。因此,对于小组c1={v1,v2},节点v1的聚合频率对于小组c2={v3,v4,v5},节点v3的聚合频率的聚合频率节点v5的聚合频率
[0163]
根据s402和s403,能够得出图4b树结构第一层所有节点的聚合频率,分别为根据s402和s403,能够得出图4b树结构第一层所有节点的聚合频率,分别为
[0164]
接着,计算非叶子节点(第二层)的模型聚合频率:
[0165]
s401、比较组内边缘节点的资源异构程度,即计算组内每个边缘节点所拥有的资
源,结果用表示,其中i表示序号为i的节点,且在“树”的第h层;对于聚合节点,节点j的资源指的是节点j进行一轮模型聚合的平均时间和节点j跟其父节点进行模型传输的时间;需要注意的是,一轮模型聚合的时间包括聚合节点j进行聚合的时间以及聚合节点j的孩子节点中,进行相应本地更新或模型聚合和模型传输所花费最长的时间;由于节点进行聚合的时间很短,可忽略不计;
[0166]
由于第二层只有两个节点,将这两个节点分组,表示为小组c3={c1,c2}。因此,对于小组c3={c1,c2},组内的边缘节点所拥有的资源可表示为},组内的边缘节点所拥有的资源可表示为
[0167]
s402、找到每一组节点中的掉队者,即拥有资源最少的节点,并将掉队者的聚合频率设置为1。对于小组c3={c1,c2},掉队者为组c2中的父节点v3,因为它是组内进行模型聚合和模型传输花费时间最长的节点,其所花费的时间为为了减少掉队者对组内训练效果的影响,将第二层的节点v3的频率设置为
[0168]
s403、计算组内其他边缘节点的聚合频率。对于同一组内,除了掉队者外,其他节点的聚合频率的计算公式为:其中边缘节点m为掉队者,节点p1为节点j和节点m的父节点,节点j为节点i的父节点。因此,对于小组c3={c1,c2},树的第二层节点v1的聚合频率
[0169]
根据s402和s403,能够得出图4b树结构第二层所有节点的聚合频率,分别为根据s402和s403,能够得出图4b树结构第二层所有节点的聚合频率,分别为
[0170]
最后,根据s405,设置根节点的聚合频率,即为模型训练的轮数
[0171]
s5、使用输出的聚合频率进行模型训练,判断该方法的训练效果是否比基准方法差,如果比基准方法好,则s4输出的,是每个边缘节点的最优聚合频率;如果比基准方法差,则使用自适应的方法,在模型训练的过程中动态地调整节点的聚合频率;
[0172]
s501、使用步骤s4输出的聚合频率,进行模型训练;
[0173]
s502、判断步骤s501的训练效果是否比基准方法要差;
[0174]
s503、如果是,则使用自适应的方法,在模型训练的过程中动态地调整节点的聚合频率,具体为:
[0175]
a、根据实时的训练效果,确定开始调整节点聚合频率的时间点t0=500s;这个时间点指步骤s501在t0时间点的模型精度比基准方法在t0时的模型精度低,且低于某个阈值;需要说明的是,这一步其实就是在判断步骤s501的训练效果是否比基准方法要差。
[0176]
b、确定在训练过程中调整聚合频率的时间间隔t0=100s,这个时间间隔可以手动设置;
[0177]
c、使用以下更新规则来调整训练节点的聚合频率:
[0178][0179]
其中,η
t
表示在时间点t的学习率,表示在时间点t0的训练损失函数值,表示步骤s4输出的每个边缘节点的聚合频率,τn表示在训练过程中,第n次调整节点聚合频率的频率值;需要注意的是,步骤s503只自适应地调整“树”形结构中,叶子节点(即训练节点)的聚合频率值。
[0180]
s504、如果不是,则s4输出的结果就是层次化模型训练框架中每个边缘节点的最优聚合频率;
[0181]
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。