1.本发明涉及分布式计算技术领域,尤其是涉及一种算力中心化的短距离运算托管系统及运行方法。
背景技术:
2.如今电子设备的数量是超乎想象的,多数设备因为其用途的限制,运算能力非常有限,但也存在一部分数量多但占比不大设备(极少的占比垄断了极多的算力),因其用途具有良好的运算性能。
3.例如:
4.近年来智能家居领域蓬勃发展,越来越多的嵌入式设备出现在了智能家居电气设备中。这些嵌入式设备往往具有良好的运算性能,可以对用户的复杂操作进行响应。但是,在实际的应用场景中,智能家居设备往往是数量较多的,而每一个设备都具有良好性能的嵌入式设备,虽保证了设备的稳定可靠,但带来了极大的算力冗余。多数情况下这些设备的算力都是闲置的,实际应用到高性能运算的部分较少。即便如此,用户仍需为每一个设备买单,造成了应用场景下算力过分闲置、算力过分冗余的情况。
5.在要求严格的工业领域,电气设备的芯片都采用最小资源化的设计原则,即满足最小性能使用要求即可。这样的设计负责工程中的各项设计原则,但在功能扩展升级时带来了极大的困难。往往因为功能上的升级,即需要电气设备执行更复杂的操作,而嵌入式芯片不再满足该操做的运算性能,这时则需要对整体进设计行较大的改动才能实现对性能进行扩展。
6.因此,实现算力资源均衡以及算力互联成为一项亟待解决的技术问题。
技术实现要素:
7.本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种实现算力资源均衡以及算力互联算力中心化的短距离运算托管系统及运行方法。
8.本发明的目的可以通过以下技术方案来实现:
9.一种算力中心化的短距离运算托管系统,该系统包括:
10.子节点:连接终端设备,进行数据收集及终端设备的电气控制;
11.算力中心节点:为众多子节点所共享,用于接收子节点的数据计算请求、进行数据计算并返回至对应的子节点。
12.优选地,所述的子节点和算力中心节点采用socket通信结构。
13.优选地,该系统适用于局域网范围内。
14.优选地,共享算力中心节点的子节点数量最大值为n
max
:
[0015][0016]
其中,x为单位时间内平均完成请求次数,w
max
为系统对响应时间的等待上限值,λ
为系统单位时间内运算请求次数。
[0017]
一种算力中心化的短距离运算托管系统的运行方法,包括如下步骤:
[0018]
步骤s1:子节点收集数据,进行数据汇总,与算力中心节点建立连接;
[0019]
步骤s2:确认连接建立成功后,子节点将需要托管的计算提交至算力中心节点;
[0020]
步骤s3:算力中心节点根据子节点的提交的信息进行计算,将结果转换为对应的操作返回给子节点;
[0021]
步骤s4:子节点在收到运算结果后,将结果映射至对应的电气操作控制终端设备运行。
[0022]
优选地,当多个子节点进行并发计算请求时,采用经典排队模型进行并发请求处理。
[0023]
优选地,并发请求处理的过程为:
[0024]
s11、子节点i的请求传输并等待进入请求队列,传输时间为t1,进入请求队列的等待时间为t2;
[0025]
s12、请求从请求队列到达算力中心节点,时间为t3;
[0026]
s13、该请求在算力中心节点进行处理,处理时间为t4;
[0027]
s14、处理后的响应信息进入响应队列并等待前面消息传输完成,响应信息进入响应队列的时间为t5,在响应队列中等待前面消息传输完成的时间为t6;
[0028]
s15、响应信息从响应队列中到达子节点,传输时间为t7;
[0029]
s17、子节点作为终端设备的上位机,将控制指令传输至终端设备,传输时间为t8。
[0030]
优选地,步骤s1中子节点与算力中心节点建立连接时基于token进行身份认证。
[0031]
优选地,基于token进行身份认证的具体过程为:
[0032]
子节点请求算力中心节点时携带一个带有时间标记的token,该token由算力中心节点第一次接收到该子节点的请求时修改并返还;
[0033]
当该节点的信息在算力中心节点的数据库中有记录时,则判定该token为合法,并设置过期时间为24小时,过期后的token需要重新生成。
[0034]
优选地,所述的token采用非对称加密的方式生成。
[0035]
与现有技术相比,本发明具有如下优点:
[0036]
(1)本发明提出了一种算力中心化的模式,将性能计算的部分提交至算力中心处理,组成一种分布式系统,降低终端设备节点的运算性能,将算力资源中心化,以达到降低算力冗余以及终端设备成本的目的。
[0037]
(2)本发明系统可适用于智能家居领域、工业领域,解决算力资源不均衡以及算力互联的问题。
附图说明
[0038]
图1为本发明一种算力中心化的短距离运算托管系统的整体框架图;
[0039]
图2为发明所采用的socket通信结构,即子节点与算力中心节点的通信模型;
[0040]
图3为本发明在子节点并发访问算力中心时的系统时间模型;
[0041]
图4为本发明在处理身份认证时的流程图;
[0042]
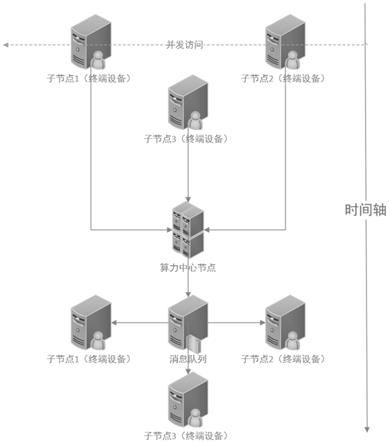
图5是本发明在实际应用场景中的拓扑结构。
具体实施方式
[0043]
下面结合附图和具体实施例对本发明进行详细说明。注意,以下的实施方式的说明只是实质上的例示,本发明并不意在对其适用物或其用途进行限定,且本发明并不限定于以下的实施方式。
[0044]
实施例
[0045]
本发明主要针对现阶段存在的算力资源不均衡以及算力互联的问题。如今电子设备的数量是超乎想象的,多数设备因为其用途的限制,运算能力非常有限,但也存在一部分数量多但占比不大设备(极少的占比垄断了极多的算力),因其用途具有良好的运算性能。这类设备普遍存在使用不均衡的情况,例如,某公司可能会因为某天的突发性能运算而购置大量服务器,但大多数时间高性能服务器集群处在空载的状态,针对该现象,目前的解决方案是:由云服务器厂商集中购置服务器,为需要进行突发运算的企业提供托管服务。显然针对企业来说,这是有效的解决方案,但对普通用户来讲是难以操作的。
[0046]
因此,如图1所示,本实发明提供了一种算力中心化的短距离运算托管系统,该系统适用于局域网范围内,包括:
[0047]
子节点:连接终端设备,进行数据收集及终端设备的电气控制;
[0048]
算力中心节点:为众多子节点所共享,用于接收子节点的数据计算请求、进行数据计算并返回至对应的子节点。
[0049]
子节点和算力中心节点采用socket通信结构,如图2所示。
[0050]
例如出现以下场景:当用户处在卧室时,试图通过语音的方式打开空调,但“智慧家庭中枢”在客厅。那么解决方案有以下几种:(1)通过大声喊话的方式,或是在“智慧家庭中枢”内安装昂贵的麦克风阵列,让中枢捕捉到我的语音指令(2)在空调内安装性能出色的芯片以处理语音数据(3)购买具有红外功能的手机,且手机可以随时接收语音指令。这几种方式在逻辑上是非常可行的,但在实际工程中具有非常大的局限性。即便是人们愿意为“智能家居”多花很多钱,但给一个没有屏幕的设备匹配另一个设备对普通用户来讲,也是很头疼的事情。面对此类情况,我们也可以考虑将复杂运算移交给“算力中心”(将相对复杂的代码托管运行在此处的“算力中心”中,传输关键参数),经计算后再将结果返回给运算能力弱的设备。例如在上述案例中,由被操作的设备接受语音指令,再将语音指令传输至所依托的算力较强的设备中进行运算与分析,将计算结果返回给被操作的设备。
[0051]
在上述过程中,可以体现出算力中心化的特征,但又区别于现有的诸如云计算的远距离传输。在类似的过程中,远距离的数据传输往往会带来不可预知的数据丢失问题(尤其是无线传输),所以带来的是更宽的带宽需求,例如目前具有发展前景的“云桌面电脑”,其需求的高带宽中,有一定的延迟与带宽需求是来自丢包后补包的过程,其不稳定程度往往取决于距离带来的未知因素。
[0052]
以智能家居这个例子来说,为减少延迟以及增加数据的可靠性,应采取短距离通信的方式,将原本运行在诸如“空调”上的程序,托管运行在“算力中心”。对算力再次进行分配,减少算力空置,降低均匀布置算力带来的不必要成本。
[0053]
在此技术基础上,可以达到对各类受限于成本空间等因素的低性能设备进行性能扩展,甚至是在部署了算力中心后,就近使用共有(私有)的算力资源来满足例如只有屏幕、简单的低功耗微控制器、电池的设备进行复杂操作。亦或是实现对算力中心的更换,在不停
机更换微控制器的情况下,为原本功能简单(受限于soc)的机械提供性能的扩展等。
[0054]
该系统主要意图将子设备(运算性能较弱但需要执行复杂程序的设备)的工作量繁重的部分代码运行在算力中心中(代码托管),利用通信技术,子设备唤醒算力中心,并要求算力中心执行该段代码,传输需要的参数。算力中心收到参数后开始执行该段代码,并将运算结果返回到子设备中,也可以由算力中心唤醒子设备,将具有复杂运算的参数经过处理后作为参数传输给子设备,以达到扩展子设备的性能。其实现方法在于规律地将复杂运算的程序模块“拆分”,将该程序模块“安置”在算力中心中,通过传输参数的方式使其共同工作。
[0055]
本发明针对物联网方向,意在实现算力互联的m2m模式。不同于现阶段传感器汇聚数据至数据中心的模式,且摆脱了低功耗这一设计需求的限制。可在子节点算力薄弱的情况下仍保证子节点可处理较为复杂的数据,降低了智能家居场景下子节点的硬件成本,以及在一定程度上对难以更改硬件设备的工业物联网提供了扩展功能。
[0056]
1、并发请求处理
[0057]
在满足了应用使用需求后,还需要进一步分析系统在多点并发访问时的处理性能,从定量角度分析系统性能的制约因素,从而推断出系统瓶颈,针对瓶颈进行优化与设置,以达到提升系统性能及使用体验的目的。
[0058]
在该系统的计算模式中,可以使用经典排队模型对系统性能进行分析与量化。系统事件模型如图2所示,响应时间为子节点发送运算请求到收到请求响应的时间差。设子节点i的请求到达请求队列的传输时间为t1,请求进入队列的等待时间为t2,请求从队列中到达运算功能模块的时间为t3,该请求在运算功能模块的处理时间为t4,消息从能模块到响应队列的时间为t5,在响应队列中等待前面消息传输完成的时间为t6,响应从响应队列中到达子节点的时间为t7,而子节点作为终端电气设备的上位机,讲控制指令传输至终端电气设备的时间为t8。
[0059]
则一次完整通讯的传输时间为t
t
=t1 t2 t3 t4 t5 t6 t7 t8。t
t
与网络情况、所执行的电气设备控制指令复杂情况有关。在不同情况下,t
t
较为固定,不具有较大的随机性,故可视为t
t
为定值。
[0060]
则在一次完整通讯中的等待时间为tw=t2 t4 t6。子节点i的消息队列i为子节点i所独享,故在响应队列中等待前面消息传输完成的时间为t6为0。可得tw=t2 t4。等待时间与算力中心的运算性能情况直接相关,即与负载率负相关。系统负载率越高,tw的时间就越长。
[0061]
综上所述,一次完整通讯的响应时间主要决定于网络环境、算力中心系统负载情况。而负载情况决定于单位时间内发送请求的子节点数量。
[0062]
由于单位时间内有多少子节点需要访问中心节点是随机的、前后状态不相关的,故可将运算消息请求近似看作泊松流。在这里,假设单位时间内运算请求次数为λ,单位时间内的请求次数服从分布:x~p(λ)。
[0063]
若应用场景中,存在n个相互独立的子节点终端设备,每个设备单位时间内平均发送运算请求λi次,则算力中心处理的请求次数服从:
[0064]
[0065]
假设算力中心完成运算托管的时间服从指数分布,且在单位时间内平均完成条运算请求,则该概率密度为:
[0066]
f(t)=xe-xt
,t>0
ꢀꢀꢀ
(2)
[0067]
这里界定消息队列的长度仅受系统内存的限制,而算力中心会搭载较大的内存,考虑到消息的长度通常在3kb以下,故可视为消息队列的长度不受限制。由此可得该系统请求响应服从m/m/1排队系统模型,平均系统响应时间为:
[0068][0069]
(3)中,可以用nλ表示,只有x>nλ时,消息请求队列的平均长度才是一个有限值,请求响应时间才可以表示成一个有限值,否则平均队列长度会出现趋于无限的情况,从而导致等待响应时间也趋于无限,最终导致应答等待不到结果,从而导致消息队列出现无响应的情况。
[0070]
根据以上条件的限制,算力中心的运算能力为一个定值,所以x<nλ条件必须被满足。如果n非常大,而λ必须足够小。该结论表示的实际应用含义是,子节点数量较多时,子节点的单位时间内请求强度不能太高。反而言之,子节点数量较少时,单位时间内的请求强度则允许较大。
[0071]
当x>>nλ时,wq迅速增大,假定系统对响应时间的等待上限值为w
max
,终端节点的位置以及类型决定了请求强度,算力中心的运算性能决定了运算能力。请求强度与运算性能可以通过统计与测算得到,由此可推得:
[0072][0073]
当子节点数量超过n
max
时,则会通过提示等方式,告知使用者更新算力中心设备,提升算力中心的性能从而提高系统允许的最大子节点数量。同时,请求强度会随着算力中心的软件功能迭代而更新,功能越多时,单位内请求强度则越大。
[0074]
2、身份认证
[0075]
由于无线的通信方式存在不可避免的被广播性,算力中心接收到的广播信息中可能包含未与算力中心绑定的通讯请求,甚至可能出现非法的算力侵占现象。针对此问题,本系统引用了身份认证的方式。
[0076]
这种方式可以看作是一个登录系统。子节点请求算力中心时,会携带一个带有时间标记的token。该token由算力中心第一次接收到该节点请求时修改并返还。当该节点的信息在数据库中有记录时,则判定该token为合法,并设置过期时间为24小时,过期后的token需要重新生成。生成时采用非对称加密的方式,子节点接收到返还的合法token后,也会在本地保留此token信息,避免非法的算力中心对子节点进行控制。
[0077]
基于以上分析,本实施例一种算力中心化的短距离运算托管系统的运行方法,包括如下步骤:
[0078]
步骤s1:子节点收集数据,进行数据汇总,与算力中心节点建立连接;
[0079]
步骤s2:确认连接建立成功后,子节点将需要托管的计算提交至算力中心节点;
[0080]
步骤s3:算力中心节点根据子节点的提交的信息进行计算,将结果转换为对应的
操作返回给子节点;
[0081]
步骤s4:子节点在收到运算结果后,将结果映射至对应的电气操作控制终端设备运行。
[0082]
优选地,当多个子节点进行并发计算请求时,采用经典排队模型进行并发请求处理。
[0083]
并发请求处理的过程如图3所示,具体为:
[0084]
s11、子节点i的请求传输并等待进入请求队列,传输时间为t1,进入请求队列的等待时间为t2;
[0085]
s12、请求从请求队列到达算力中心节点,时间为t3;
[0086]
s13、该请求在算力中心节点进行处理,处理时间为t4;
[0087]
s14、处理后的响应信息进入响应队列并等待前面消息传输完成,响应信息进入响应队列的时间为t5,在响应队列中等待前面消息传输完成的时间为t6;
[0088]
s15、响应信息从响应队列中到达子节点,传输时间为t7;
[0089]
s17、子节点作为终端设备的上位机,将控制指令传输至终端设备,传输时间为t8。
[0090]
步骤s1中子节点与算力中心节点建立连接时基于token进行身份认证,基于token进行身份认证的具体如图4所示,具体为:
[0091]
子节点请求算力中心节点时携带一个带有时间标记的token,该token由算力中心节点第一次接收到该子节点的请求时修改并返还;
[0092]
当该节点的信息在算力中心节点的数据库中有记录时,则判定该token为合法,并设置过期时间为24小时,过期后的token需要重新生成。
[0093]
token采用非对称加密的方式生成。
[0094]
图5本发明在实际应用场景中的拓扑结构,有发送用户指令至子节点,子节点向算力中心节点请求运算托管,算力中心节点运算结束中给出响应信息并返回至子节点,从而子节点控制对应终端设备的运行。
[0095]
上述实施方式仅为例举,不表示对本发明范围的限定。这些实施方式还能以其它各种方式来实施,且能在不脱离本发明技术思想的范围内作各种省略、置换、变更。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。