1.本发明涉及信息安全技术领域,尤其涉及一种涉税风险企业识别方法及装置。
背景技术:
2.随着金税三期税收管理信息系统的全面上线,税务大数据时代已经到来。金税三期税收管理信息系统中采集了大量的纳税人身份信息、资产信息、开票信息等信息,使得纳税人的经营行为更加透明。
3.目前,国家及地方税局稽查部门对于涉税异常企业的监控主要通过项目分析法、指标分析法以及人工经验等方法进行,不仅需要耗费大量的时间和人力成本,而且根据经验判断的依据存在不确定性,因此,识别与涉税异常企业相关联的企业是否也存在涉税风险的识别效率及准确率较低。
4.因此,如何提高根据已知涉税异常企业识别涉税风险企业的识别效率及准确率是现有技术中亟待解决的技术问题之一。
技术实现要素:
5.为了解决现有技术中根据涉税异常企业识别与其相关联的涉税风险企业的识别效率及准确率较低的问题,本发明实施例提供了一种涉税风险企业识别方法及装置。
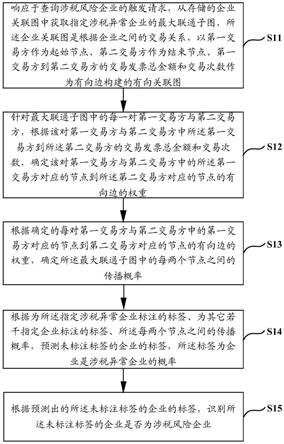
6.第一方面,本发明实施例提供了一种涉税风险企业识别方法,包括:
7.响应于查询涉税风险企业的触发请求,从存储的企业关联图中获取指定涉税异常企业的最大联通子图,所述企业关联图是根据企业之间的交易关系,以第一交易方作为起始节点、第二交易方作为结束节点、第一交易方到第二交易方的交易发票总金额和交易次数作为有向边构建的有向关联图,所述最大联通子图表征与所述指定涉税异常企业具有联通关系的最大集合;
8.针对所述最大联通子图中的每一对第一交易方与第二交易方,根据该对第一交易方与第二交易方中所述第一交易方到所述第二交易方的交易发票总金额和交易次数,确定该对第一交易方与第二交易方中的所述第一交易方对应的节点到所述第二交易方对应的节点的有向边的权重,所述有向边的权重表征第一交易方与第二交易方的关系紧密度;
9.根据确定的每对第一交易方与第二交易方中的第一交易方对应的节点到第二交易方对应的节点的有向边的权重,确定所述最大联通子图中的每两个节点之间的传播概率;
10.根据为所述指定涉税异常企业标注的标签、为其它若干指定企业标注的标签、所述每两个节点之间的传播概率,预测未标注标签的企业的标签,所述标签为企业是涉税异常企业的概率;
11.根据预测出的所述未标注标签的企业的标签,识别所述未标注标签的企业是否为涉税风险企业。
12.本发明实施例中提供的涉税风险企业识别方法,计算机设备响应于查询涉税风险
企业的触发请求,从存储的企业关联图中获取指定涉税异常企业的最大联通子图,所述企业关联图是根据企业之间的交易关系,以第一交易方作为起始节点、第二交易方作为结束节点、第一交易方到第二交易方的交易发票总金额和交易次数作为有向边构建的有向关联图,所述最大联通子图表征与所述指定涉税异常企业具有联通关系的最大集合,针对最大联通子图中的每一对第一交易方与第二交易方,根据该对第一交易方与第二交易方中所述第一交易方到所述第二交易方的交易发票总金额和交易次数,确定该对第一交易方与第二交易方中的所述第一交易方对应的节点到所述第二交易方对应的节点的有向边的权重,所述有向边的权重表征第一交易方与第二交易方的关系紧密度,进而,根据确定的每对第一交易方与第二交易方中的第一交易方对应的节点到第二交易方对应的节点的有向边的权重,确定最大联通子图中的每两个节点之间的传播概率,根据为指定涉税异常企业标注的标签、为其它若干指定企业标注的标签、以及每两个节点之间的传播概率,预测未标注标签的企业的标签,其中,所述标签为企业是涉税异常企业的概率,进而,根据预测出的未标注标签的企业的标签,识别未标注标签的企业是否为涉税风险企业,相比于现有技术,本发明实施例中,根据企业间的交易关系构建有向企业关联图,记录企业间的关联关系,通过在企业关联图中查找已知涉税异常企业的最大联通子图,可以快速查找到与已知涉税异常企业具有关联关系的其它各个企业,进而,根据最大联通子图中的每一对第一交易方与第二交易方中的第一交易方到第二交易方的交易发票总金额和交易次数,确定每对第一交易方与第二交易方中的第一交易方对应的起始节点到第二交易方对应的结束节点之间的有向边的权重,作为表征第一交易方与第二交易方的关系紧密度的衡量指标,并根据每对第一交易方与第二交易方中的第一交易方对应的起始节点到第二交易方对应的结束节点之间的边的权重,确定最大联通子图中的每两个节点之间的传播概率,基于每两个节点之间的传播概率以及已标注标签的企业的标签,根据标签传播算法预测未标注标签的企业的标签,即:预测未标注标签的企业是涉税异常企业的概率,以识别未标注标签的企业是否为涉税风险企业,该算法复杂度低且分类效果好,节省了大量后续基于人工经验、分析来判断与已知涉税异常企业关联的企业是否具有涉税风险的时间,提高了识别与已知涉税异常企业相关的企业是否为涉税风险企业的识别效率与准确率。
13.较佳地,针对所述最大联通子图中的每一对第一交易方与第二交易方,根据该对第一交易方与第二交易方中所述第一交易方到所述第二交易方的交易发票总金额和交易次数,确定该对第一交易方与第二交易方中的所述第一交易方对应的节点到所述第二交易方对应的节点的有向边的权重,具体包括:
14.针对所述最大联通子图中的每一对第一交易方与第二交易方,分别将所述第一交易方到所述第二交易方的交易发票总金额以及所述交易次数进行预处理;
15.分别将预处理后的所述第一交易方到所述第二交易方的交易发票总金额和预处理后的交易次数进行归一化处理;
16.根据归一化的预处理后的所述第一交易方到所述第二交易方的交易发票总金额和归一化的预处理后的交易次数,确定所述第一交易方对应的节点到所述第二交易方对应的节点的有向边的权重。
17.较佳地,将所述第一交易方到所述第二交易方的交易发票总金额进行预处理,具体包括:
18.通过以下公式对第一交易方到第二交易方的交易发票总金额进行预处理:
[0019][0020]
其中,表示预处理后的第一交易方到第二交易方的交易发票总金额;
[0021]
fpje
se
表示第一交易方到第二交易方的交易发票总金额;
[0022]
fpje表示fpje
se
的全集,max(fpje)表示所述最大联通子图中所有交易方所产生的交易发票总金额的全集中的最大值;以及
[0023]
通过以下公式对第一交易方到第二交易方的交易次数进行预处理:
[0024][0025]
其中,表示预处理后的第一交易方到第二交易方的交易次数;
[0026]
count
se
表示第一交易方到第二交易方的交易次数;
[0027]
count表示count
se
的全集,max(count)表示所述最大联通子图中的所有交易方所产生的交易次数的全集中的最大值。
[0028]
较佳地,将预处理后的所述第一交易方到所述第二交易方的交易发票总金额进行归一化处理,具体包括:
[0029]
通过以下公式将预处理后的第一交易方到第二交易方的交易发票总金额进行归一化处理:
[0030][0031]
其中,表示归一化的预处理后的第一交易方到第二交易方的交易发票总金额;以及
[0032]
通过以下公式将预处理后的第一交易方到第二交易方的交易次数进行归一化处理:
[0033][0034]
其中,表示归一化的预处理后的第一交易方到第二交易方的交易次数。
[0035]
较佳地,根据归一化的预处理后的所述第一交易方到所述第二交易方的交易发票总金额和归一化的预处理后的交易次数,确定所述第一交易方对应的节点到所述第二交易方对应的节点的有向边的权重,具体包括:
[0036]
通过以下公式确定所述第一交易方对应的节点到所述第二交易方对应的节点的有向边的权重:
[0037][0038]
其中,ω表示所述第一交易方对应的节点到所述第二交易方对应的节点的有向边
的权重。
[0039]
较佳地,根据确定的每对第一交易方与第二交易方中的第一交易方对应的节点到第二交易方对应的节点的有向边的权重,确定所述最大联通子图中的每两个节点之间的传播概率,具体包括:
[0040]
通过以下公式确定所述最大联通子图中的每两个节点之间的传播概率:
[0041][0042]
其中,t
ij
表示节点j到节点i的传播概率;
[0043]
ω
ij
表示节点i到节点j的有向边的权重;
[0044]
n为所述最大联通子图中的节点总数。
[0045]
较佳地,根据为所述指定涉税异常企业标注的标签、为其它若干指定企业标注的标签、所述每两个节点之间的传播概率,预测未标注标签的企业的标签,具体包括:
[0046]
定义矩阵y∈(l u)*c={y
i,c
},其中,l为已标注标签的企业的数量,u为未标注标签的企业的数量,c表示企业所属的类别矩阵,c={1,0},当c=1时,表示为涉税异常企业,当c=0时,表示为涉税信用企业,y
i,c
表示节点i为类别c的概率;
[0047]
根据所述每两个节点之间的传播概率组成传播概率矩阵;并根据以下步骤执行标签传播,直至收敛:
[0048]
每个节点按照其周围节点到该节点的传播概率将周围节点传播的标注值按权重相加,并更新到自己的概率分布,得到y
t
=t
×yt-1
,其中,t≥1,y
t
表示第t次更新后的矩阵y,y
t-1
表示第t次更新前一次的矩阵y;
[0049]
重置矩阵y中已标注的各企业的标签,限定已标注的数据,把已标注的数据的概率分布重新赋值为初始值。
[0050]
较佳地,根据预测出的所述未标注标签的企业的标签,识别所述未标注标签的企业是否为涉税风险企业,具体包括:
[0051]
当确定预测出的所述未标注标签的企业是涉税异常企业的概率大于或等于预设阈值时,确定所述未标注标签的企业为涉税风险企业;
[0052]
当确定预测出的所述未标注标签的企业是涉税异常企业的概率小于所述预设阈值时,确定所述未标注标签的企业为涉税信用企业。
[0053]
第二方面,本发明实施例提供了一种涉税风险企业识别装置,包括:
[0054]
获取单元,用于响应于查询涉税风险企业的触发请求,从存储的企业关联图中获取指定涉税异常企业的最大联通子图,所述企业关联图是根据企业之间的交易关系,以第一交易方作为起始节点、第二交易方作为结束节点、第一交易方到第二交易方的交易发票总金额和交易次数作为有向边构建的有向关联图,所述最大联通子图表征与所述指定涉税异常企业具有联通关系的最大集合;
[0055]
第一确定单元,用于针对所述最大联通子图中的每一对第一交易方与第二交易方,根据该对第一交易方与第二交易方中所述第一交易方到所述第二交易方的交易发票总金额和交易次数,确定该对第一交易方与第二交易方中的所述第一交易方对应的节点到所述第二交易方对应的节点的有向边的权重,所述有向边的权重表征第一交易方与第二交易方的关系紧密度;
[0056]
第二确定单元,用于根据确定的每对第一交易方与第二交易方中的第一交易方对应的节点到第二交易方对应的节点的有向边的权重,确定所述最大联通子图中的每两个节点之间的传播概率;
[0057]
标签预测单元,用于根据为所述指定涉税异常企业标注的标签、为其它若干指定企业标注的标签、所述每两个节点之间的传播概率,预测未标注标签的企业的标签,所述标签为企业是涉税异常企业的概率;
[0058]
识别单元,用于根据预测出的所述未标注标签的企业的标签,识别所述未标注标签的企业是否为涉税风险企业。
[0059]
较佳地,所述第一确定单元,具体用于针对所述最大联通子图中的每一对第一交易方与第二交易方,分别将所述第一交易方到所述第二交易方的交易发票总金额以及所述交易次数进行预处理;分别将预处理后的所述第一交易方到所述第二交易方的交易发票总金额和预处理后的交易次数进行归一化处理;根据归一化的预处理后的所述第一交易方到所述第二交易方的交易发票总金额和归一化的预处理后的交易次数,确定所述第一交易方对应的节点到所述第二交易方对应的节点的有向边的权重。
[0060]
较佳地,所述第一确定单元,具体用于通过以下公式对第一交易方到第二交易方的交易发票总金额进行预处理:
[0061][0062]
其中,表示预处理后的第一交易方到第二交易方的交易发票总金额;
[0063]
fpje
se
表示第一交易方到第二交易方的交易发票总金额;
[0064]
fpje表示fpje
se
的全集,max(fpje)表示所述最大联通子图中的所有交易方所产生的交易发票总金额的全集中的最大值;以及
[0065]
通过以下公式对第一交易方到第二交易方的交易次数进行预处理:
[0066][0067]
其中,表示预处理后的第一交易方到第二交易方的交易次数;
[0068]
count
se
表示第一交易方到第二交易方的交易次数;
[0069]
count表示count
se
的全集,max(count)表示所述最大联通子图中的所有交易方所产生的交易次数的全集中的最大值。
[0070]
较佳地,所述第一确定单元,具体用于通过以下公式将预处理后的第一交易方到第二交易方的交易发票总金额进行归一化处理:
[0071][0072]
其中,表示归一化的预处理后的第一交易方到第二交易方的交易发票总金额;以及
[0073]
通过以下公式将预处理后的第一交易方到第二交易方的交易次数进行归一化处
理:
[0074][0075]
其中,表示归一化的预处理后的第一交易方到第二交易方的交易次数。
[0076]
较佳地,所述第一确定单元,具体用于通过以下公式确定所述第一交易方对应的节点到所述第二交易方对应的节点的有向边的权重:
[0077][0078]
其中,ω表示所述第一交易方对应的节点到所述第二交易方对应的节点的有向边的权重。
[0079]
较佳地,所述第二确定单元,具体用于通过以下公式确定所述最大联通子图中的每两个节点之间的传播概率:
[0080][0081]
其中,t
ij
表示节点j到节点i的传播概率;
[0082]
ω
ij
表示节点i到节点j的有向边的权重;
[0083]
n为所述最大联通子图中的节点总数。
[0084]
较佳地,所述标签预测单元,具体用于定义矩阵y∈(l u)*c={y
i,c
},其中,l为已标注标签的企业的数量,u为未标注标签的企业的数量,c表示企业所属的类别矩阵,c={1,0},当c=1时,表示为涉税异常企业,当c=0时,表示为涉税信用企业,y
i,c
表示节点i为类别c的概率;
[0085]
根据所述每两个节点之间的传播概率组成传播概率矩阵;并根据以下步骤执行标签传播,直至收敛:
[0086]
每个节点按照其周围节点到该节点的传播概率将周围节点传播的标注值按权重相加,并更新到自己的概率分布,得到y
t
=t
×yt-1
,其中,t≥1,y
t
表示第t次更新后的矩阵y,y
t-1
表示第t次更新前一次的矩阵y;
[0087]
重置矩阵y中已标注的各企业的标签,限定已标注的数据,把已标注的数据的概率分布重新赋值为初始值。
[0088]
较佳地,所述识别单元,具体用于当确定预测出的所述未标注标签的企业是涉税异常企业的概率大于或等于预设阈值时,确定所述未标注标签的企业为涉税风险企业;当确定预测出的所述未标注标签的企业是涉税异常企业的概率小于所述预设阈值时,确定所述未标注标签的企业为涉税信用企业。
[0089]
本发明提供的涉税风险企业识别装置的技术效果可以参见上述第一方面或第一方面的各个实现方式的技术效果,此处不再赘述。
[0090]
第三方面,本发明实施例提供了一种计算机设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述程序时实现本发明所述的涉税风险企业识别方法。
[0091]
第四方面,本发明实施例提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现本发明所述的涉税风险企业识别方法中的步骤。
[0092]
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
附图说明
[0093]
此处所说明的附图用来提供对本发明的进一步理解,构成本发明的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
[0094]
图1为本发明实施例提供的涉税风险企业识别方法的一个应用场景示意图;
[0095]
图2为本发明实施例提供的涉税风险企业识别方法的实施流程示意图;
[0096]
图3为本发明实施例提供的构建企业关联图的实施流程示意图;
[0097]
图4为本发明实施例提供的一个示例性企业关联图;
[0098]
图5为本发明实施例提供的确定最大联通子图中每一对销方与购方中的销方对应的节点到购方对应的节点的有向边的权重的实施流程示意图;
[0099]
图6为sigmoid函数图像示意图;
[0100]
图7为本发明实施例提供的识别未标注标签的企业是否为涉税风险企业的实施流程示意图;
[0101]
图8为本发明实施例提供的涉税风险企业识别装置的结构示意图;
[0102]
图9为本发明实施例提供的计算机设备的结构示意图。
具体实施方式
[0103]
为了解决现有技术中根据涉税异常企业识别与其相关联的涉税风险企业的识别效率及准确率较低的问题,本发明实施例提供了一种涉税风险企业识别方法及装置。
[0104]
首先参考图1,其为本发明实施例提供的涉税风险企业识别方法的一个应用场景示意图,可以包括终端110和计算机设备120,当需要查询涉税风险企业时,例如计算机设备120接收到终端110发送的涉税风险企业查询请求时,计算机设备120可以根据涉税风险企业查询请求将识别的涉税风险企业返回至终端110。在另一个应用场景中,计算机设备120也可以自动触发查询涉税风险企业,例如,可以设置计算机设备120每间隔预设时间自动执行本发明实施例中提供的涉税风险企业识别方法中的步骤识别涉税风险企业;也可以由管理人员触发查询涉税风险企业的请求,计算机设备120响应于该触发请求,执行本发明实施例中提供的涉税风险企业识别方法中的步骤识别涉税风险企业。
[0105]
计算机设备120可以是独立的物理服务器或终端,也可以是提供云服务器、云数据库、云存储等基础云计算服务的云服务器。终端110可以但不限于为:智能手机、平板电脑、笔记本电脑、台式计算机等。计算机设备120和终端110可以通过网络进行连接,本发明实施例对此不作限定。
[0106]
基于上述应用场景,下面将参照附图2~图6更详细地描述本发明的示例性实施例,需要注意的是,上述应用场景仅是为了便于理解本发明的精神和原理而示出,本发明的实施方式在此不受任何限制。相反,本发明的实施方式可以应用于适用的任何场景。
[0107]
以下结合说明书附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明,并且在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
[0108]
如图2所示,其为本发明实施例提供的涉税风险企业识别方法的实施流程示意图,该涉税风险企业识别方法可以应用于上述的计算机设备120中,可以包括以下步骤:
[0109]
s11、响应于查询涉税风险企业的触发请求,从存储的企业关联图中获取指定涉税异常企业的最大联通子图,所述企业关联图是根据企业之间的交易关系,以第一交易方作为起始节点、第二交易方作为结束节点、第一交易方到第二交易方的交易发票总金额和交易次数作为有向边构建的有向关联图。
[0110]
具体实施时,计算机设备响应于查询涉税风险企业的触发请求,从存储的企业关联图中获取指定涉税异常企业的最大联通子图,其中,所述最大联通子图表征与所述指定涉税异常企业具有联通关系的最大集合,第一交易方为销方,第二交易方为购方。
[0111]
本发明实施例中,涉税异常企业可以为开具异常发票的企业,或者应用异常发票抵扣税款的抵扣企业,其中,报税不通过或者已报税完成但被税务机关追查的发票,均可视为异常发票,本发明实施例对此不作限定。涉税风险企业指存在一定几率为开启异常发票或者应用异常发票抵扣税款的企业。
[0112]
具体地,计算机设备按照如图3所示的流程构建企业关联图,可以包括以下步骤:
[0113]
s21、获取企业交易数据,所述企业交易数据包括销方到购方的交易发票总金额和交易次数。
[0114]
具体实施时,计算机设备从金税三期税收管理信息系统中获取企业交易数据,所述企业交易数据可以但不限于包括以下数据:企业信息、销方到购方的交易发票总金额、销方到购方的交易次数(即销方到购方的交易总次数),其中,企业信息包括企业名称、企业代码等信息。本发明实施例中的发票可以但不限于为增值税发票。
[0115]
s22、根据企业之间的交易关系,以销方作为起始节点、购方作为结束节点、销方到购方的交易发票总金额和交易次数作为有向边,构建企业关联图。
[0116]
具体实施时,计算机设备根据企业之间的购销关系,以销方作为起始节点、购方作为结束节点、销方到购方的交易发票总金额和交易次数作为有向边,构建有向企业关联图。
[0117]
具体地,可以使用start_point表示起始节点;使用end_point表示结束节点;使用fpje
se
表示起始节点(start_point)到结束节点(end_point)这一方向的交易发票总金额,即销方到购方的交易发票总金额,其中,s表示销方(start_point)的缩写,e表示购方(end_point)的缩写;使用count
se
表示起始节点到结束节点这一方向的交易次数,即销方到购方的交易总次数。
[0118]
如图4所示,其为本发明实施例提供的一个示例性企业关联图,具有购销关系的每两个企业中销方到购方的交易发票总金额与交易次数如表1所示:
[0119]
表1
[0120]
start_pointend_pointfpjecounta企业b企业288067a企业c企业155039b企业g企业331050
b企业h企业479088c企业a企业45501c企业e企业299021c企业f企业280010d企业a企业508095d企业k企业885098e企业f企业243072e企业d企业403073g企业h企业909076g企业f企业7330100h企业i企业899042h企业j企业895022k企业j企业792059m企业n企业1000100o企业m企业200020o企业n企业300037
[0121]
由图4可知,企业关联图为由销方指向购方组成的有向关联图,如表1所示,以a企业与c企业为例,当a企业为销方、c企业为购方时,a企业到c企业的交易发票总金额为1550元,a企业到c企业的交易次数为39次,当c企业为销方、a企业为购方时,c企业到a企业的交易发票总金额为4550元,c企业到a企业的交易次数为1次。
[0122]
假设图4中的a企业为指定涉税异常企业,即a企业为已知的涉税异常企业,a企业的最大联通子图为除m企业、n企业和o企业之外的其它各企业的连接图,即由a企业、b企业、c企业、d企业、e企业、f企业、g企业、h企业、i企业、j企业和k企业组成的联通子图,a企业的最大联通子图中,a企业外的各企业均与a企业具有直接或者间接的关联。
[0123]
s12、针对最大联通子图中的每一对第一交易方与第二交易方,根据该对第一交易方与第二交易方中第一交易方到第二交易方的交易发票总金额和交易次数,确定该对第一交易方与第二交易方中的第一交易方对应的节点到第二交易方对应的节点的有向边的权重。
[0124]
具体实施时,计算机设备针对最大联通子图中每一对销方与购方,根据该对销方与购方中的销方到购方的交易发票总金额和交易次数,确定该对销方与购方中的销方对应的(起始)节点到购方对应的(结束)节点的有向边的权重,其中,边的权重表征销方与购方的关系紧密度。
[0125]
具体地,按照如图5所示的步骤确定最大联通子图中的每一对销方与购方中的销方对应的节点到购方对应的节点的有向边的权重,可以包括以下步骤:
[0126]
s31、针对最大联通子图中的每一对销方与购方,分别将所述销方到购方的交易发票总金额以及交易次数进行预处理。
[0127]
具体实施时,针对最大联通子图中的每一对销方与购方,通过以下公式对销方到购方的交易发票总金额进行预处理:
[0128][0129]
其中,表示预处理后的销方与购方之间的交易发票总金额,s表示销方(即第一交易方)(start_point)的缩写,e表示购方(即第二交易方)(end_point)的缩写;
[0130]
fpje
se
表示销方到购方的交易发票总金额;
[0131]
fpje表示fpje
se
的全集,max(fpje)表示所述最大联通子图中所有交易方所产生的交易发票总金额的全集中的最大值,即:max(fpje)表示所述最大联通子图中的每对销方与购方中销方到购方的交易发票总金额中的最大值。
[0132]
并通过以下公式对销方到购方的交易次数进行预处理:
[0133][0134]
其中,表示预处理后的第一交易方到第二交易方的交易次数;
[0135]
count
se
表示第一交易方到第二交易方的交易次数;
[0136]
count表示count
se
的全集,max(count)表示所述最大联通子图中的所有交易方所产生的交易次数的全集中的最大值,即:max(count)表示所述最大联通子图中的每对销方与购方中销方到购方的交易次数中的最大值。
[0137]
具体实施时,由于不同的具有交易关系的销方与购方,销方到购方的交易次数和交易发票总金额的数据差异较大,本发明实施例中采用sigmoid函数分别将交易次数和交易发票总额进行归一化,sigmoid函数具有严格单调,以(0,0.05)中心对称,值域范围在(0,1)的特点,sigmoid函数具体如下:
[0138][0139]
sigmoid函数图像如图6所示,由于当x值超出[-5,5]的范围后,函数值f(x)基本上没有变化,值非常接近,因此,在本发明中将x的范围控制在[-5,5]之内,因此,在对销方到购方的交易次数、销方到购方的交易发票总金额分别进行归一化之前,分别将销方到购方的交易次数、销方到购方的交易发票总金额进行上述预处理,以使得销方到购方的交易次数、销方到购方的交易发票总金额的取值范围控制在[-5,5]之内,进而,在分别将预处理后的销方到购方的交易发票总金额和预处理后的销方到购方的交易次数根据sigmoid函数分别进行归一化处理。
[0140]
s32、分别将预处理后的所述销方到所述购方的交易发票总金额和预处理后的交易次数进行归一化处理。
[0141]
具体实施时,通过以下公式将预处理后的销方到购方的交易发票总金额进行归一化处理:
[0142][0143]
其中,表示归一化的预处理后的销方到购方的交易发票总金额。
[0144]
通过以下公式将预处理后的销方到购方的交易次数进行归一化处理:
[0145][0146]
其中,表示归一化的预处理后的销方到购方的交易次数。
[0147]
s33、根据归一化的预处理后的所述销方到所述购方的交易发票总金额和归一化的预处理后的交易次数,确定所述销方对应的节点到所述购方对应的节点的有向边的权重。
[0148]
具体实施时,针对最大联通子图中的每一对销方与购方,通过以下公式确定销方与购方中的销方对应的节点到购方对应的节点的有向边的权重:
[0149][0150]
其中,ω表示所述销方对应的节点到所述购方对应的节点的有向边的权重。
[0151]
仍延续上例,如表2所示,其为最大联通子图中每一对具有购销关系的企业预处理后的销方到购方的交易发票总金额、预处理后的销方到购方的交易次数、归一化的预处理后的销方到购方的交易发票总金额、归一化的预处理后的销方到购方的交易次数、销方对应的节点到购方对应的节点之间的有向边的权重的对应关系表。
[0152]
表2
[0153]
[0154][0155]
需要说明的是,根据上述权重计算公式计算出的是最大联通子图中具有购销关系的销方对应的节点到购方对应的节点这一方向上的边的权重,本发明实施例中,将无购销关系的任两个企业中销方对应的节点到购方对应的节点的有向边的权重设置为0,例如,a企业对应的节点到a企业对应的节点的边的权重(记为ω
11
)为0,a企业对应的节点到d企业对应的节点的边的权重(记为ω
12
)为0,a企业对应的节点到e企业对应的节点的边的权重(记为ω
15
)为0,
……
,b企业对应的节点到a企业对应的节点的边的权重(记为ω
21
)为0
……
等,此处不作赘述。
[0156]
s13、根据确定的每对第一交易方与第二交易方中的第一交易方对应的节点到第二交易方对应的节点的有向边的权重,确定所述最大联通子图中的每两个节点之间的传播概率。
[0157]
具体实施时,针对所述最大联通子图中的每对销方与购方,通过以下公式确定所述最大联通子图中的每两个节点之间的传播概率:
[0158][0159]
其中,t
ij
(即t(j
→
i))表示节点j到节点i的传播概率,即:节点j的标签传播到节点i的标签的概率;
[0160]
ω
ij
表示节点i到节点j的有向边的权重;
[0161]
n为所述最大联通子图中的节点总数;
[0162]
表示节点i到所述最大联通子图中每一节点的有向边的权重的总和。
[0163]
仍延续上例,如表3所示,其为最大联通子图中的每两个企业对应的节点之间的传播概率表:
[0164]
表3
[0165][0166][0167]
则由上述最大联通子图中的每两个企业对应的节点之间的传播概率组成的传播概率矩阵为t=(t
ij
),i=1~11,j=1~11。
[0168]
s14、根据为所述指定涉税异常企业标注的标签、为其它若干指定企业标注的标签、所述每两个节点之间的传播概率,预测未标注标签的企业的标签,所述标签为企业是涉税异常企业的概率。
[0169]
具体实施时,计算机设备根据为所述指定涉税异常企业标注的标签、为其它若干指定企业标注的标签、所述最大联通子图的每两个节点之间的传播概率,预测未标注标签的企业的标签,所述标签为企业是涉税异常企业的概率。
[0170]
具体地,可以按照以下步骤预测未标注标签的企业的标签:
[0171]
步骤一、定义矩阵y∈(l u)*c={y
i,c
},其中,l为已标注标签的企业的数量,u为未标注标签的企业的数量,c表示企业所属的类别矩阵,c={1,0},当c=1时,表示企业的类别为涉税异常企业,当c=0时,表示企业的类别为涉税信用企业,y
i,c
表示节点i为类别c的概率,l<<u。本发明实施例中,同一个企业为涉税异常企业的概率和为涉税信用企业的概率之和为1。
[0172]
具体实施时,将为所述指定涉税异常企业标注的标签和为其它若干指定企业标注的标签作为标记数据,并对未标注标签的企业的标签进行初始化,将所述未标注标签的企业的标签设置为设定值。
[0173]
仍延续上例,已知最大联通子图中的a企业为涉税异常企业,h企业为涉税异常企业,则对a企业标注标签:y
1,c
=p(c=1)=1,y
1,c
=p(c=0)=0,即:a企业为涉税异常企业的概率为1,a企业为涉税信用企业的概率为0,对h企业标注标签:y
1,c
=p(c=1)=0,y
1,c
=p(c=0)=1,即:h企业为涉税异常企业的概率为0,a企业为涉税信用企业的概率为1,根据已标注标签的企业a企业和b企业的标签作为输入,预测b企业、c企业、d企业、e企业、f企业、g企业、i企业、j企业和k企业的标签,也就是预测b企业、c企业、d企业、e企业、f企业、g企业、i企业、j企业和k企业分别为涉税异常企业的概率和为涉税信用企业的概率,由于已标注标签的企业为a企业和h企业两个,未标注标签的企业的个数为9,则定义的矩阵y中,l的值为2,u的值为9,并对未标注标签的各企业的标签进行初始化,将各未标注标签的企业的标签设置为0.5,即可以将各未标注标签的企业为涉税异常企业的概率和为涉税信用企业的概率分别设置为0.5,这样,矩阵y则由表4中的各标注值组成,矩阵y的第i行表示节点i的标注概率:
[0174]
表4
[0175]
节点y
i,c
:p(c=1)y
i,c
:p(c=0)a企业10b企业0.50.5c企业0.50.5d企业0.50.5e企业0.50.5f企业0.50.5g企业0.50.5h企业01i企业0.50.5j企业0.50.5k企业0.50.5
[0176]
即矩阵y为:
[0177]
步骤二、根据所述最大联通子图的每两个节点之间的传播概率组成传播概率矩阵。
[0178]
具体实施时,仍延续上例,由上述最大联通子图中的每两个企业对应的节点之间的传播概率组成的传播概率矩阵t即表3中各元素组成的矩阵t。
[0179]
进而,循环步骤三和步骤四执行标签传播,直至收敛:
[0180]
步骤三、每个节点按照其周围节点到该节点的传播概率将周围节点传播的标注值按权重相加,并更新到自己的概率分布,得到y
t
=t
×yt-1
,其中,t≥1,y
t
表示第t次更新后的矩阵y,y
t-1
表示第t次更新前一次的矩阵y。
[0181]
具体实施时,每个节点按照其周围节点到该节点的传播概率将周围节点传播的标注值按每一节点与其周围节点之间的边的权重相加,并更新到自己的概率分布,得到y
t
=t
×yt-1
,其中,t≥1,y
t
表示第t次更新后的矩阵y,y
t-1
表示第t次更新前一次的矩阵y,其中,t=1时,y
t-1
为初始设置的矩阵y。
[0182]
具体实施时,将步骤一中的矩阵y与步骤二中的传播概率矩阵t相乘,更新矩阵y:y
←
t
×
y。
[0183]
步骤四、重置矩阵y中已标注的各企业的标签,限定已标注的数据,把已标注的数据的概率分布重新赋值为初始值。
[0184]
重复执行步骤三和步骤四,直至y收敛。
[0185]
标签传播算法描述:
[0186]
在标签传播算法中,(x1,y1),
……
,(x
l
,y
l
)表示已标注的数据;
[0187]yl
=(y1,
……
,y
l
)∈(1,
……
,c)代表已标注数据的类别,c已知,且存在与标签数据中;
[0188]
(x
l 1
,y
l 1
),
……
,(x
l u
,y
l u
)代表未标注的数据;
[0189]yu
={y
l 1
,
……
,y
l u
}:没有标签,满足l<<u,即有标签的数据数量远小于无标签的数据数量;
[0190]
x={x1,
……
,x
l u
}∈rd;
[0191]
标签传播算法描述的问题即为:从x和y
l
去预测yu。
[0192]
具体实施时,将更新后的矩阵y中已标注企业的标签即a企业和h企业的标签置为初始值,即:将更新后的矩阵y中a企业对应的行(即第1行)重新赋值为:1,0,将h企业对应的行(即第8行)赋值为0,1,之后,再执行步骤三,直至收敛。收敛后得到的各节点的标签如表5
所示:
[0193]
表5
[0194]
节点y
i,c
:p(c=1)y
i,c
:p(c=0)a企业10b企业01c企业0.430.57d企业0.9560.044e企业0.4010.599f企业01g企业01h企业01i企业01j企业01k企业01
[0195]
根据表5可知,未标注标签的各企业中,b企业、f企业、g企业、h企业、i企业、j企业和k企业为涉税异常企业的概率均为0,c企业为涉税异常企业的概率为0.43,d企业为涉税异常企业的概率为0.956,e企业为涉税异常企业的概率为0.401。
[0196]
本发明实施例中,通过交易双方中销方到购方的交易发票总金额和交易次数计算交易双方中销方对应起始节点到购方对应的结束节点的有向边的权重,利用标签传播算法预测未标注标签的企业为涉税异常企业的概率时,利用通过上述方式计算出的有向边的权重来计算每两个节点之间的传播概率,相比于现有技术,上述计算边的权重的方式使得企业间的关系紧密度的计算更加精确,进而,使得在进行标签传播的过程中,预测未标注标签的准确度更高,从而,提高了识别涉税风险企业的准确率。
[0197]
s15、根据预测出的所述未标注标签的企业的标签,识别所述未标注标签的企业是否为涉税风险企业。
[0198]
具体实施时,按照如图7所示的步骤识别未标注标签的企业是否为涉税风险企业,可以包括以下步骤:
[0199]
s41、当确定预测出的未标注标签的企业是涉税异常企业的概率大于或等于预设阈值时,确定所述未标注标签的企业为涉税风险企业。
[0200]
具体实施时,预设阈值可以根据实际情况自行设置,例如,可以但不限于设置为0.6,本发明实施例对此不作限定。
[0201]
s42、当确定预测出的未标注标签的企业是涉税异常企业的概率小于所述预设阈值时,确定所述未标注标签的企业为涉税信用企业。
[0202]
假设预设阈值为0.6,则上例中,d企业即为涉税风险企业。
[0203]
本发明实施例中提供的涉税风险企业识别方法,计算机设备响应于查询涉税风险企业的触发请求,从存储的企业关联图中获取指定涉税异常企业的最大联通子图,所述企业关联图是根据企业之间的交易关系,以第一交易方作为起始节点、第二交易方作为结束节点、第一交易方到第二交易方的交易发票总金额和交易次数作为有向边构建的有向关联图,所述最大联通子图表征与所述指定涉税异常企业具有联通关系的最大集合,针对最大
联通子图中的每一对第一交易方与第二交易方,根据该对第一交易方与第二交易方中所述第一交易方到所述第二交易方的交易发票总金额和交易次数,确定该对第一交易方与第二交易方中的所述第一交易方对应的节点到所述第二交易方对应的节点的有向边的权重,所述有向边的权重表征第一交易方与第二交易方的关系紧密度,进而,根据确定的每对第一交易方与第二交易方中的第一交易方对应的节点到第二交易方对应的节点的有向边的权重,确定最大联通子图中的每两个节点之间的传播概率,根据为指定涉税异常企业标注的标签、为其它若干指定企业标注的标签、以及每两个节点之间的传播概率,预测未标注标签的企业的标签,其中,所述标签为企业是涉税异常企业的概率,进而,根据预测出的未标注标签的企业的标签,识别未标注标签的企业是否为涉税风险企业,相比于现有技术,本发明实施例中,根据企业间的交易关系构建有向企业关联图,记录企业间的关联关系,通过在企业关联图中查找已知涉税异常企业的最大联通子图,可以快速查找到与已知涉税异常企业具有关联关系的其它各个企业,进而,根据最大联通子图中的每一对第一交易方与第二交易方中的第一交易方到第二交易方的交易发票总金额和交易次数,确定每对第一交易方与第二交易方中的第一交易方对应的起始节点到第二交易方对应的结束节点之间的有向边的权重,作为表征第一交易方与第二交易方的关系紧密度的衡量指标,并根据每对第一交易方与第二交易方中的第一交易方对应的起始节点到第二交易方对应的结束节点之间的边的权重,确定最大联通子图中的每两个节点之间的传播概率,基于每两个节点之间的传播概率以及已标注标签的企业的标签,根据标签传播算法预测未标注标签的企业的标签,即:预测未标注标签的企业是涉税异常企业的概率,以识别未标注标签的企业是否为涉税风险企业,该算法复杂度低且分类效果好,节省了大量后续基于人工经验、分析来判断与已知涉税异常企业关联的企业是否具有涉税风险的时间,提高了识别与已知涉税异常企业相关的企业是否为涉税风险企业的识别效率与准确率。
[0204]
基于同一发明构思,本发明实施例还提供了一种涉税风险企业识别装置,由于上述涉税风险企业识别装置解决问题的原理与涉税风险企业识别方法相似,因此上述装置的实施可以参见方法的实施,重复之处不再赘述。
[0205]
如图8所示,其为本发明实施例提供的涉税风险企业识别装置的结构示意图,可以包括:
[0206]
获取单元51,用于响应于查询涉税风险企业的触发请求,从存储的企业关联图中获取指定涉税异常企业的最大联通子图,所述企业关联图是根据企业之间的交易关系,以第一交易方作为起始节点、第二交易方作为结束节点、第一交易方到第二交易方的交易发票总金额和交易次数作为有向边构建的有向关联图,所述最大联通子图表征与所述指定涉税异常企业具有联通关系的最大集合;
[0207]
第一确定单元52,用于针对所述最大联通子图中的每一对第一交易方与第二交易方,根据该对第一交易方与第二交易方中所述第一交易方到所述第二交易方的交易发票总金额和交易次数,确定该对第一交易方与第二交易方中的所述第一交易方对应的节点到所述第二交易方对应的节点的有向边的权重,所述有向边的权重表征第一交易方与第二交易方的关系紧密度;
[0208]
第二确定单元53,用于根据确定的每对第一交易方与第二交易方中的第一交易方对应的节点到第二交易方对应的节点的有向边的权重,确定所述最大联通子图中的每两个
节点之间的传播概率;
[0209]
标签预测单元54,用于根据为所述指定涉税异常企业标注的标签、为其它若干指定企业标注的标签、所述每两个节点之间的传播概率,预测未标注标签的企业的标签,所述标签为企业是涉税异常企业的概率;
[0210]
识别单元55,用于根据预测出的所述未标注标签的企业的标签,识别所述未标注标签的企业是否为涉税风险企业。
[0211]
较佳地,所述第一确定单元52,具体用于针对所述最大联通子图中的每一对第一交易方与第二交易方,分别将所述第一交易方到所述第二交易方的交易发票总金额以及所述交易次数进行预处理;分别将预处理后的所述第一交易方到所述第二交易方的交易发票总金额和预处理后的交易次数进行归一化处理;根据归一化的预处理后的所述第一交易方到所述第二交易方的交易发票总金额和归一化的预处理后的交易次数,确定所述第一交易方对应的节点到所述第二交易方对应的节点的有向边的权重。
[0212]
较佳地,所述第一确定单元52,具体用于通过以下公式对第一交易方到第二交易方的交易发票总金额进行预处理:
[0213][0214]
其中,表示预处理后的第一交易方到第二交易方的交易发票总金额;
[0215]
fpje
se
表示第一交易方到第二交易方的交易发票总金额;
[0216]
fpje表示fpje
se
的全集,max(fpje)表示所述最大联通子图中的所有交易方所产生的交易发票总金额的全集中的最大值;以及
[0217]
通过以下公式对第一交易方到第二交易方的交易次数进行预处理:
[0218][0219]
其中,表示预处理后的第一交易方到第二交易方的交易次数;
[0220]
count
se
表示第一交易方到第二交易方的交易次数;
[0221]
count表示count
se
的全集,max(count)表示所述最大联通子图中的所有交易方所产生的交易次数的全集中的最大值。
[0222]
较佳地,所述第一确定单元52,具体用于通过以下公式将预处理后的第一交易方到第二交易方的交易发票总金额进行归一化处理:
[0223][0224]
其中,表示归一化的预处理后的第一交易方到第二交易方的交易发票总金额;以及
[0225]
通过以下公式将预处理后的第一交易方到第二交易方的交易次数进行归一化处理:
[0226][0227]
其中,表示归一化的预处理后的第一交易方到第二交易方的交易次数。
[0228]
较佳地,所述第一确定单元52,具体用于通过以下公式确定所述第一交易方对应的节点到所述第二交易方对应的节点的有向边的权重:
[0229][0230]
其中,ω表示所述第一交易方对应的节点到所述第二交易方对应的节点的有向边的权重。
[0231]
较佳地,所述第二确定单元53,具体用于通过以下公式确定所述最大联通子图中的每两个节点之间的传播概率:
[0232][0233]
其中,t
ij
表示节点j到节点i的传播概率;
[0234]
ω
ij
表示节点i到节点j的有向边的权重;
[0235]
n为所述最大联通子图中的节点总数。
[0236]
较佳地,所述标签预测单元,具体用于定义矩阵y∈(l u)*c={y
i,c
},其中,l为已标注标签的企业的数量,u为未标注标签的企业的数量,c表示企业所属的类别矩阵,c={1,0},当c=1时,表示为涉税异常企业,当c=0时,表示为涉税信用企业,y
i,c
表示节点i为类别c的概率;
[0237]
根据所述每两个节点之间的传播概率组成传播概率矩阵;并根据以下步骤执行标签传播,直至收敛:
[0238]
每个节点按照其周围节点到该节点的传播概率将周围节点传播的标注值按权重相加,并更新到自己的概率分布,得到y
t
=t
×yt-1
,其中,t≥1,y
t
表示第t次更新后的矩阵y,y
t-1
表示第t次更新前一次的矩阵y;
[0239]
重置矩阵y中已标注的各企业的标签,限定已标注的数据,把已标注的数据的概率分布重新赋值为初始值。
[0240]
较佳地,所述识别单元55,具体用于当确定预测出的所述未标注标签的企业是涉税异常企业的概率大于或等于预设阈值时,确定所述未标注标签的企业为涉税风险企业;当确定预测出的所述未标注标签的企业是涉税异常企业的概率小于所述预设阈值时,确定所述未标注标签的企业为涉税信用企业。
[0241]
基于同一技术构思,本发明实施例还提供了一种计算机设备600,参照图9所示,计算机设备600用于实施上述方法实施例记载的涉税风险企业识别方法,该实施例的计算机设备600可以包括:存储器601、处理器602以及存储在所述存储器中并可在所述处理器上运行的计算机程序,例如涉税风险企业识别程序。所述处理器执行所述计算机程序时实现上述各个涉税风险企业识别方法实施例中的步骤,例如图2所示的步骤s11。或者,所述处理器执行所述计算机程序时实现上述各装置实施例中各模块/单元的功能,例如51。
[0242]
本发明实施例中不限定上述存储器601、处理器602之间的具体连接介质。本技术实施例在图9中以存储器601、处理器602之间通过总线603连接,总线603在图9中以粗线表示,其它部件之间的连接方式,仅是进行示意性说明,并不引以为限。所述总线603可以分为地址总线、数据总线、控制总线等。为便于表示,图9中仅用一条粗线表示,但并不表示仅有一根总线或一种类型的总线。
[0243]
存储器601可以是易失性存储器(volatile memory),例如随机存取存储器(random-access memory,ram);存储器601也可以是非易失性存储器(non-volatile memory),例如只读存储器,快闪存储器(flash memory),硬盘(hard disk drive,hdd)或固态硬盘(solid-state drive,ssd)、或者存储器601是能够用于携带或存储具有指令或数据结构形式的期望的程序代码并能够由计算机存取的任何其他介质,但不限于此。存储器601可以是上述存储器的组合。
[0244]
处理器602,用于实现如图2所示的一种涉税风险企业识别方法,包括:
[0245]
所述处理器602,用于调用所述存储器601中存储的计算机程序执行如图2中所示的步骤s11、响应于查询涉税风险企业的触发请求,从存储的企业关联图中获取指定涉税异常企业的最大联通子图,所述企业关联图是根据企业之间的交易关系,以第一交易方作为起始节点、第二交易方作为结束节点、第一交易方到第二交易方的交易发票总金额和交易次数作为有向边构建的有向关联图,步骤s12、针对最大联通子图中的每一对第一交易方与第二交易方,根据该对第一交易方与第二交易方中所述第一交易方到所述第二交易方的交易发票总金额和交易次数,确定该对第一交易方与第二交易方中的所述第一交易方对应的节点到所述第二交易方对应的节点的有向边的权重,步骤s13,根据确定的每对第一交易方与第二交易方中的第一交易方对应的节点到第二交易方对应的节点的有向边的权重,确定所述最大联通子图中的每两个节点之间的传播概率,步骤s14、根据为所述指定涉税异常企业标注的标签、为其它若干指定企业标注的标签、所述每两个节点之间的传播概率,预测未标注标签的企业的标签,所述标签为企业是涉税异常企业的概率,和步骤s15、根据预测出的所述未标注标签的企业的标签,识别所述未标注标签的企业是否为涉税风险企业。
[0246]
本技术实施例还提供了一种计算机可读存储介质,存储为执行上述处理器所需执行的计算机可执行指令,其包含用于执行上述处理器所需执行的程序。
[0247]
在一些可能的实施方式中,本发明提供的涉税风险企业识别方法的各个方面还可以实现为一种程序产品的形式,其包括程序代码,当所述程序产品在计算机设备上运行时,所述程序代码用于使所述计算机设备执行本说明书上述描述的根据本发明各种示例性实施方式的涉税风险企业识别方法中的步骤,例如,所述计算机设备可以执行如图2中所示的步骤s11、响应于查询涉税风险企业的触发请求,从存储的企业关联图中获取指定涉税异常企业的最大联通子图,所述企业关联图是根据企业之间的交易关系,以第一交易方作为起始节点、第二交易方作为结束节点、第一交易方到第二交易方的交易发票总金额和交易次数作为有向边构建的有向关联图,步骤s12、针对最大联通子图中的每一对第一交易方与第二交易方,根据该对第一交易方与第二交易方中所述第一交易方到所述第二交易方的交易发票总金额和交易次数,确定该对第一交易方与第二交易方中的所述第一交易方对应的节点到所述第二交易方对应的节点的有向边的权重,步骤s13,根据确定的每对第一交易方与第二交易方中的第一交易方对应的节点到第二交易方对应的节点的有向边的权重,确定所
述最大联通子图中的每两个节点之间的传播概率,步骤s14、根据为所述指定涉税异常企业标注的标签、为其它若干指定企业标注的标签、所述每两个节点之间的传播概率,预测未标注标签的企业的标签,所述标签为企业是涉税异常企业的概率,和步骤s15、根据预测出的所述未标注标签的企业的标签,识别所述未标注标签的企业是否为涉税风险企业。
[0248]
本领域内的技术人员应明白,本发明的实施例可提供为方法、装置、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
[0249]
本发明是参照根据本发明实施例的方法、设备(装置)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0250]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0251]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0252]
尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例做出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
[0253]
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。