关于利用光流的预测细化的方法和装置
1.相关申请的交叉引用
2.本技术基于2019年7月10日提交的临时申请第62/872,700号和2019年7月12日提交的临时申请第62/873,837号并要求享有其优先权,上述申请的全部内容通过引用并入本文以用于所有目的。
技术领域
3.本公开涉及视频编解码和压缩。更具体地,本公开涉及关于在通用视频编解码(vvc)标准中研究的两种帧间预测工具(即,利用光流的预测细化(prof)和双向光流(bdof))的方法和装置。
背景技术:
4.可以使用各种视频编解码技术来压缩视频数据。根据一种或多种视频编解码标准执行视频编解码。例如,视频编解码标准包括通用视频编解码(vvc)、联合探索测试模型(jem)、高效视频编解码(h.265/hevc)、高级视频编解码(h.264/avc)、运动图像专家组(mpeg)编解码等。视频编解码通常使用预测方法(例如,帧间预测、帧内预测等),这些预测方法利用视频图像或序列中存在的冗余。视频编解码技术的一个重要目标是将视频数据压缩成使用较低比特率的形式,同时避免或最小化视频质量的下降。
技术实现要素:
5.本公开的示例提供了用于视频编解码中的运动矢量预测的方法和装置。
6.根据本公开的第一方面,提供了一种用于解码视频信号的双向光流(bdof)和利用光流的预测细化(prof)的统一方法。解码器可以将视频块划分为多个非重叠视频子块,其中,多个非重叠视频子块中的至少一个非重叠视频子块可以与两个运动矢量相关联。解码器可以获得与多个非重叠视频子块中的至少一个非重叠视频子块的两个运动矢量相关联的第一参考图片i
(0)
和第二参考图片i
(1)
。按照显示顺序,第一参考图片i
(0)
可以在当前图片之前并且第二参考图片i
(1)
可以在当前图片之后。解码器可以从第一参考图片i
(0)
中的参考块获得视频子块的第一预测样本i
(0)
(i,j)。i和j可以表示一个样本基于当前图片的坐标。解码器可以从第二参考图片i
(1)
中的参考块获得视频子块的第二预测样本i
(1)
(i,j)。解码器可以获得第一预测样本i
(0)
(i,j)和第二预测样本i
(1)
(i,j)的水平梯度值和垂直梯度值。当视频块不是以仿射模式编码时,解码器可以基于bdof获得视频子块中的样本的运动细化。当视频块是以仿射模式编码时,解码器可以基于prof获得视频子块中的样本的运动细化。解码器然后可以基于运动细化获得视频块的预测样本。
7.根据本公开的第二方面,提供了一种用于解码视频信号的bdof和prof的方法。该方法可以包括在解码器处获得与视频块相关联的第一参考图片i
(0)
和第二参考图片i
(1)
。按照显示顺序,第一参考图片i
(0)
可以在当前图片之前并且第二参考图片i
(1)
可以在当前图片之后。该方法还可以包括在解码器处从第一参考图片i
(0)
中的参考块获得视频块的第一预
测样本i
(0)
(i,j)。i和j表示一个样本基于当前图片的坐标。该方法可以包括在解码器处从第二参考图片i
(1)
中的参考块获得视频块的第二预测样本i
(1)
(i,j)。该方法还可以包括通过解码器接收至少一个标志。该至少一个标志可以由编码器在序列参数集(sps)中用信号通知,并且用信号通知是否针对当前视频块启用bdof和prof。该方法可以包括在解码器处并且当至少一个标志是启用时,当视频块不是以仿射模式编码时,应用bdof以基于第一预测样本i
(0)
(i,j)和第二预测样本i
(1)
(i,j)导出视频块的运动细化。该方法可以另外包括在解码器处并且当至少一个标志是启用时,当视频块是以仿射模式编码时,应用prof以基于第一预测样本i
(0)
(i,j)和第二预测样本i
(1)
(i,j)导出视频块的运动细化。该方法还可以包括在解码器处基于运动细化获得视频块的预测样本。
8.根据本公开的第三方面,提供了一种用于解码视频信号的计算设备。该计算设备可以包括一个或多个处理器、存储能够由一个或多个处理器执行的指令的非暂时性计算机可读存储器。一个或多个处理器可以被配置为将视频块划分为多个非重叠视频子块。多个非重叠视频子块中的至少一个非重叠视频子块可以与两个运动矢量相关联。一个或多个处理器还可以被配置为获得与多个非重叠视频子块中的至少一个非重叠视频子块的两个运动矢量相关联的第一参考图片i
(0)
和第二参考图片i
(1)
。按照显示顺序,第一参考图片i
(0)
可以在当前图片之前并且第二参考图片i
(1)
可以在当前图片之后。一个或多个处理器还可以被配置为从第一参考图片i
(0)
中的参考块获得视频子块的第一预测样本i
(0)
(i,j)。i和j表示一个样本基于当前图片的坐标。一个或多个处理器还可以被配置为从第二参考图片i
(1)
中的参考块获得视频子块的第二预测样本i
(1)
(i,j)。一个或多个处理器还可以被配置为获得第一预测样本i
(0)
(i,j)和第二预测样本i
(1)
(i,j)的水平梯度值和垂直梯度值。一个或多个处理器还可以被配置为当视频块不是以仿射模式编码时,基于bdof获得视频子块中的样本的运动细化。一个或多个处理器还可以被配置为在视频块是以仿射模式编码时,基于prof获得视频子块中的样本的运动细化。一个或多个处理器还可以被配置为基于运动细化获得视频块的预测样本。
9.根据本公开的第四方面,提供了一种其中存储有指令的非暂时性计算机可读存储介质。当该指令由装置的一个或多个处理器执行时,该指令可以使装置执行在解码器处获得与视频块相关联的第一参考图片i
(0)
和第二参考图片i
(1)
。按照显示顺序,第一参考图片i
(0)
可以在当前图片之前并且第二参考图片i
(1)
可以在当前图片之后。指令还可以使装置执行在解码器处从第一参考图片i
(0)
中的参考块获得视频块的第一预测样本i
(0)
(i,j)。i和j表示一个样本基于当前图片的坐标。指令还可以使装置执行在解码器处从第二参考图片i
(1)
中的参考块获得视频块的第二预测样本i
(1)
(i,j)。指令还可以使装置执行通过解码器接收至少一个标志。至少一个标志可以由编码器在sps中用信号通知,并且用信号通知是否针对当前视频块启用bdof和prof。该指令还可以使装置执行在解码器处并且当至少一个标志是启用时,当视频块不是以仿射模式编码时,应用bdof以基于第一预测样本i
(0)
(i,j)和第二预测样本i
(1)
(i,j)导出视频块的运动细化。指令还可以使装置执行在解码器处并且当至少一个标志是启用时,当视频块是以仿射模式编码时,应用prof以基于第一预测样本i
(0)
(i,j)和第二预测样本i
(1)
(i,j)导出视频块的运动细化。该指令还可以使该装置执行在解码器处基于运动细化获得视频块的预测样本。
附图说明
10.并入本说明书中并构成本说明书一部分的附图示出了与本公开一致的示例,并且与描述一起用于解释本公开的原理。
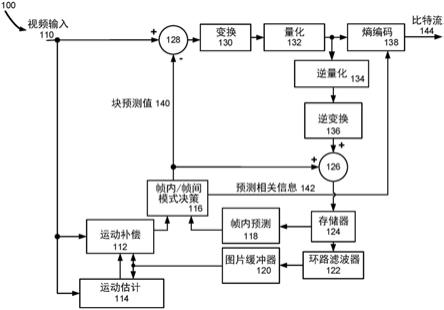
11.图1是根据本公开的示例的编码器的框图。
12.图2是根据本公开的示例的解码器的框图。
13.图3a是示出根据本公开的示例的多类型树结构中的块分区的图。
14.图3b是示出根据本公开的示例的多类型树结构中的块分区的图。
15.图3c是示出根据本公开的示例的多类型树结构中的块分区的图。
16.图3d是示出根据本公开的示例的多类型树结构中的块分区的图。
17.图3e是示出根据本公开的示例的多类型树结构中的块分区的图。
18.图4是根据本公开的示例的bdof模型的示意图。
19.图5a是根据本公开的示例的仿射模型的图示。
20.图5b是根据本公开的示例的仿射模型的图示。
21.图6是根据本公开的示例的仿射模型的图示。
22.图7是根据本公开的示例的prof的图示。
23.图8是根据本公开的示例的bdof的工作流。
24.图9是根据本公开的示例的prof的工作流。
25.图10是根据本公开的示例的用于解码视频信号的bdof和prof的统一方法。
26.图11是根据本公开的示例的用于解码视频信号的bdof和prof的方法。
27.图12是根据本公开的示例的用于双向预测的prof的工作流的图示。
28.图13是根据本公开的bdof和prof过程的流水线阶段的图示。
29.图14是根据本公开的bdof的梯度导出方法的图示。
30.图15是根据本公开的prof的梯度导出方法的图示。
31.图16a是根据本公开的示例的针对仿射模式导出模板样本的图示。
32.图16b是根据本公开的示例的针对仿射模式导出模板样本的图示。
33.图17a是根据本公开的示例的针对仿射模式排他地启用prof和lic的图示。
34.图17b是根据本公开的示例的针对仿射模式联合地启用prof和lic的图示。
35.图18a是示出根据本公开的示例的所提出的应用于16
×
16bdof cu的填充方法的图。
36.图18b是示出根据本公开的示例的所提出的应用于16
×
16bdof cu的填充方法的图。
37.图18c是示出根据本公开的示例的所提出的应用于16
×
16bdof cu的填充方法的图。
38.图18d是示出根据本公开的示例的所提出的应用于16
×
16bdof cu的填充方法的图。
39.图19是示出根据本公开的示例的与用户接口耦合的计算环境的图。
具体实施方式
40.现在将详细参考示例性实施例,其示例在附图中示出。以下描述参考附图,其中除
非另有说明,否则不同附图中相同的数字表示相同或相似的元件。以下示例性实施例的描述中阐述的实现方式并不代表与本公开一致的所有实现方式。相反,它们仅仅是与如所附权利要求中叙述的本公开相关的方面一致的装置和方法的示例。
41.本公开中使用的术语仅用于描述特定实施例的目的,并不旨在限制本公开。如在本公开和所附权利要求中使用的,除非上下文另有明确指示,否则单数形式“一(a)”、“一个(an)”和“该(the)”旨在也包括复数形式。还应理解,本文使用的术语“和/或”旨在表示并包括关联列出项目中的一个或多个的任何或所有可能的组合。
42.应当理解,尽管在本文中可以使用术语“第一”、“第二”、“第三”等来描述各种信息,但是该信息不应受这些术语的限制。这些术语仅用于将一类信息与另一类信息区分开来。例如,在不脱离本公开的范围的情况下,第一信息可以称为第二信息;类似地,第二信息也可以称为第一信息。如本文所使用的,根据上下文,术语“如果”可以理解为表示“当
……
时(when)”、或“在
……
后(upon)”、或“响应于判断”。
43.hevc标准的第一版本于2013年10月完成,与上一代视频编解码标准h.264/mpeg avc相比,它提供了大约50%的比特率节省或等效的感知质量。尽管hevc标准比其前代提供了显著的编解码改进,但有证据表明,使用附加的编解码工具可以实现与hevc相比更高的编解码效率。在此基础上,vceg和mpeg都开始了针对未来视频编解码标准化的新编解码技术的探索工作。itu-tvecg和iso/iec mpeg于2015年10月成立了联合视频探索团队(jvet),以开始对可以实现对编解码效率的显著提高的先进技术进行重大研究。jvet通过在hevc测试模型(hm)之上整合几个附加的编解码工具来维护称为联合探索模型(jem)的参考软件。
44.2017年10月,itu-t和iso/iec发布了关于具有超越hevc能力的视频压缩的联合征集提案(cfp)。2018年4月,在第10次jvet会议上收到并评估了23份cfp回复,表明压缩效率比hevc提高了约40%。基于这样的评估结果,jvet启动了新项目来开发新一代视频编解码标准,该标准称为通用视频编解码(vvc)。同月,建立了称为vvc测试模型(vtm)的参考软件代码库,用于演示vvc标准的参考实现。
45.与hevc一样,vvc建立在基于块的混合视频编解码框架之上。
46.图1示出了用于vvc的基于块的视频编码器的总体图。具体地,图1示出了典型的编码器100。编码器100具有视频输入110、运动补偿112、运动估计114、帧内/帧间模式决策116、块预测值140、加法器128、变换130、量化132、预测相关信息142、帧内预测118、图片缓冲器120、逆量化134、逆变换136、加法器126、存储器124、环路滤波器122、熵编码138和比特流144。
47.在编码器100中,视频帧被分区成多个视频块以用于处理。对于每个给定视频块,基于帧间预测方法或帧内预测方法形成预测。
48.预测残差从加法器128发送到变换130,预测残差表示当前视频块(视频输入110的一部分)与其预测值(块预测值140的一部分)之间的差。然后变换系数从变换130发送到量化132以用于熵减少。然后将量化系数馈送到熵编码138以生成压缩的视频比特流。如图1所示,来自帧内/帧间模式决策116的预测相关信息142(例如,视频块分区信息、运动矢量(mv)、参考图片索引和帧内预测模式)也通过熵编码138被馈送并保存到已压缩比特流144中。已压缩比特流144包括视频比特流。
49.在编码器100中,还需要与解码器相关的电路以便重建像素以用于预测。首先,通
过逆量化134和逆变换136重建预测残差。该重建的预测残差与块预测值140组合以生成当前视频块的未滤波的重建像素。
50.空间预测(或“帧内预测”)使用来自与当前视频块相同的视频帧中的已经编码的相邻块(称为参考样本)的样本的像素来预测当前视频块。
51.时间预测(也称为“帧间预测”)使用来自已编码的视频图片的重建像素来预测当前视频块。时间预测减少了视频信号中固有的时间冗余。给定编码单元(cu)或编码块的时间预测信号通常由一个或多个mv用信号通知,这些mv指示当前cu与其时间参考之间的运动的量和方向。此外,如果支持多个参考图片,则附加地发送一个参考图片索引,其用于标识时间预测信号来自参考图片存储装置中的哪个参考图片。
52.运动估计114接收视频输入110和来自图片缓冲器120的信号,并且将运动估计信号输出到运动补偿112。运动补偿112接收视频输入110、来自图片缓冲器120的信号以及来自运动估计114的运动估计信号,并且将运动补偿信号输出到帧内/帧间模式决策116。
53.在执行空间和/或时间预测之后,编码器100中的帧内/帧间模式决策116例如基于率失真优化方法选择最佳预测模式。然后从当前视频块中减去块预测值140,并且使用变换130和量化132将得到的预测残差去相关。得到的量化残差系数由逆量化134进行逆量化并由逆变换136进行逆变换,以形成重建残差,然后将重建残差加回预测块以形成cu的重建信号。此外,在重建cu被放入图片缓冲器120的参考图片存储装置并用于对未来的视频块进行编码之前,可以将环路滤波122(例如,去块滤波器、样本自适应偏移(sao)和/或自适应环路滤波器(alf))应用于重建cu。为了形成输出视频比特流144,编码模式(帧间或帧内)、预测模式信息、运动信息和量化残差系数都被发送到熵编码单元138以被进一步压缩和打包以形成比特流。
54.图1给出了通用的基于块的混合视频编码系统的框图。输入视频信号被逐块(称为编码单元(cu))处理。在vtm-1.0中,一个cu可以达到128
×
128像素。然而,与仅基于四叉树对块进行分区的hevc不同,在vvc中,一个编码树单元(ctu)被分割为cu,以适应基于四叉树/二叉树/三叉树的不同局部特性。此外,去除了hevc中多分区单元类型的概念,即,vvc中不再存在cu、预测单元(pu)和变换单元(tu)的分离;相反,每个cu始终用作预测和变换两者的基本单元,而不进行进一步分区。在多类型树结构中,一个ctu首先按四叉树结构分区。然后,每个四叉树叶节点可以按二叉树和三叉树结构进一步分区。
55.如图3a、图3b、图3c、图3d和图3e中所示,存在五种分割类型,四元分区、水平二元分区、垂直二元分区、水平三元分区和垂直三元分区。
56.图3a示出了图示根据本公开的多类型树结构中的块四元分区的图。
57.图3b示出了图示根据本公开的多类型树结构中的块垂直二元分区的图。
58.图3c示出了图示根据本公开的多类型树结构中的块水平二元分区的图。
59.图3d示出了图示根据本公开的多类型树结构中的块垂直三元分区的图。
60.图3e示出了图示根据本公开的多类型树结构中的块水平三元分区的图。
61.在图1中,可以执行空间预测和/或时间预测。空间预测(或“帧内预测”)使用来自同一视频图片/条带中的已经编码的相邻块的样本(称为参考样本)的像素来预测当前视频块。空间预测减少了视频信号中固有的空间冗余。时间预测(也称为“帧间预测”或“运动补偿预测”)使用来自已经编码的视频图片的重建像素来预测当前视频块。时间预测减少了视
频信号中固有的时间冗余。给定cu的时间预测信号通常由一个或多个运动矢量(mv)表示,mv指示当前cu与其时间参考之间的运动的量和方向。此外,如果支持多个参考图片,则附加地发送一个参考图片索引,其用于标识时间预测信号来自参考图片存储装置中的哪个参考图片。在空间和/或时间预测之后,编码器中的模式决策块选择最佳预测模式,例如,基于率失真优化方法。然后从当前视频块中减去预测块;并且对预测残差使用变换进行去相关并进行量化。对量化残差系数进行逆量化和逆变换,以形成重建残差,然后将重建残差加回预测块,以形成cu的重建信号。此外,在将重建cu放入参考图片存储库中并用于对未来的视频块进行编码之前,可以将环路滤波(例如,去块滤波器、样本自适应偏移(sao)和自适应环路滤波器(alf))应用于重建cu。为了形成输出视频比特流,编码模式(帧间或帧内)、预测模式信息、运动信息和量化残差系数都被送到熵编码单元以被进一步压缩和打包以形成比特流。
62.图2示出了用于vvc的视频解码器的总体框图。具体地,图2示出了典型的解码器200框图。解码器200具有比特流210、熵解码212、逆量化214、逆变换216、加法器218、帧内/帧间模式选择220、帧内预测222、存储器230、环路滤波器228、运动补偿224、图片缓冲器226、预测相关信息234和视频输出232。
63.解码器200类似于位于图1的编码器100中的重建相关部分。在解码器200中,传入的视频比特流210首先通过熵解码212进行解码,以导出量化系数水平和预测相关信息。然后通过逆量化214和逆变换216处理量化系数水平以获得重建预测残差。在帧内/帧间模式选择器220中实现的块预测值机制被配置为基于已解码预测信息来执行帧内预测222或运动补偿224。通过使用求和器218将来自逆变换216的重建预测残差与块预测值机制生成的预测输出相加来获得一组未滤波的重建像素。
64.重建块在被存储在用作参考图片存储库的图片缓冲器226中之前可以进一步经过环路滤波器228。图片缓冲器226中的重建视频可以被发送以驱动显示设备,以及用于预测未来的视频块。在环路滤波器228开启的情况下,对这些重建像素执行滤波操作以导出最终的重建视频输出232。
65.图2给出了基于块的视频解码器的总体框图。视频比特流首先在熵解码单元处进行熵解码。编码模式和预测信息被发送到空间预测单元(如果是帧内编码)或时间预测单元(如果是帧间编码)以形成预测块。残差变换系数被发送到逆量化单元和逆变换单元以重建残差块。然后将预测块和残差块相加。重建块在被存储在参考图片存储库中之前可以进一步经过环路滤波。然后将参考图片存储库中的重建视频发送出去以驱动显示设备,并且用于预测未来的视频块。
66.通常,除了进一步扩展和/或增强了几个模块之外,在vvc中应用的基本帧间预测技术保持与hevc相同。特别地,对于所有先前的视频标准,当编码块为单向预测的时,一个编码块只能与一个单一的mv相关联,或者当编码块为双向预测的时,一个编码块只能与两个mv相关联。由于传统的基于块的运动补偿的这种限制,在运动补偿之后,小运动仍然可以保留在预测样本内,从而对运动补偿的整体效率产生负面影响。为了改进mv的粒度和精度两者,目前针对vvc标准研究了两种基于光流的逐样本细化方法,即,针对仿射模式的双向光流(bdof)和利用光流的预测细化(prof)。下面简要回顾这两种帧间编解码工具的主要技术方面。
67.双向光流
68.在vvc中,应用bdof来细化双向预测编码块的预测样本。具体地,如图4所示,bdof是在使用双向预测时在基于块的运动补偿预测之上执行的逐样本运动细化。
69.图4示出了根据本公开的bdof模型的图示。
70.每个4
×
4子块的运动细化(v
x
,vy)通过如下操作来计算:当在围绕子块的一个6
×
6窗口ω内应用bdof之后,最小化l0和l1预测样本之间的差。具体地,(v
x
,vy)的值导出为
[0071][0072]
其中是向下取整函数;clip3(min,max,x)是在[min,max]范围内裁剪一个给定值x的函数;符号》》表示逐位右移运算;符号《《表示逐位左移运算;th
bdof
是用于防止由于不规则的局部运动引起的传播误差的运动细化阈值,其等于1《《max(5,bit-depth-7).,其中bit-depth是内部比特深度。在(1)中,
[0073]
s1、s2、s3、s5和s6的值计算为
[0074][0075]
其中
[0076][0077]
其中i
(k)
(i,j)是列表k中预测信号的坐标(i,j)处的样本值,k=0,1,其以中高精度(即,16比特)生成;和是样本的水平梯度和垂直梯度,其是通过直接计算该样本的两个相邻样本之间的差获得的,即
[0078][0079]
基于(1)中导出的运动细化,cu的最终双向预测样本是通过基于光流模型沿运动轨迹对l0/l1预测样本进行插值来计算的,如下所示
[0080][0081]
其中shift和o
offset
是被应用于组合l0和l1预测信号以用于双向预测的右移值和偏移值,分别等于15-bit-depth和1<<(14-bit-depth) 2
·
(1<<13)。基于上述比特深度控制方法,保证整个bdof过程的中间参数的最大比特深度不超过32比特,而乘法的最大输入在15比特以内,即,对于bdof实现,一个15比特乘法器是足够的。
[0082]
仿射模式
[0083]
在hevc中,仅平移运动模型被应用于运动补偿预测。而在现实世界中,有很多种运动,例如,放大/缩小、旋转、透视运动和其他不规则运动。在vvc中,通过用信号通知用于每个帧间编码块的一个标志以指示是平移运动还是仿射运动模型被应用于帧间预测来应用仿射运动补偿预测。在当前的vvc设计中,对于一个仿射编码块支持两种仿射模式,包括4参数仿射模式和6参数仿射模式。
[0084]
4参数仿射模型具有以下参数:分别用于水平方向和垂直方向的平移运动的两个参数,用于缩放运动的一个参数和用于两个方向的旋转运动的一个参数。水平缩放参数等于垂直缩放参数。水平旋转参数等于垂直旋转参数。为了更好地适应运动矢量和仿射参数,在vvc中,这些仿射参数被转换成位于当前块的左上角和右上角的两个mv(也称为控制点运动矢量(cpmv))。如图5a和图5b中所示,块的仿射运动场由两个控制点mv(v0,v1)描述。
[0085]
图5a示出了根据本公开的4参数仿射模型的图示。
[0086]
图5b示出了根据本公开的4参数仿射模型的图示。
[0087]
基于控制点运动,一个仿射编码块的运动场(v
x
,vy)被描述为
[0088][0089]
6参数仿射模式具有以下参数:分别用于水平方向和垂直方向的平移运动的两个参数,水平方向上用于缩放运动的一个参数和用于旋转运动的一个参数,垂直方向上用于缩放运动的一个参数和用于旋转运动的一个参数。6参数仿射运动模型在三个cpmv处使用三个mv进行编码。
[0090]
图6示出了根据本公开的6参数仿射模型的图示。
[0091]
如图6所示,一个6参数仿射块的三个控制点位于该块的左上角、右上角和左下角。左上控制点处的运动与平移运动有关,右上控制点处的运动与水平方向的旋转和缩放运动有关,而左下控制点处的运动与垂直方向的旋转和缩放运动有关。与4参数仿射运动模型相比,6参数的水平方向的旋转和缩放运动可能与垂直方向的那些运动不同。假设(v0,v1,v2)是图6中当前块的左上角、右上角和左下角的mv,每个子块的运动矢量(v
x
,vy)使用控制点处的三个mv导出为:
[0092][0093]
针对仿射模式的利用光流的预测细化
[0094]
为了改进仿射运动补偿精度,在当前的vvc中正在研究prof,其基于光流模型细化了基于子块的仿射运动补偿。具体地,在执行基于子块的仿射运动补偿之后,通过基于光流方程导出的一个样本细化值修改一个仿射块的亮度预测样本。详细地,prof的操作可以概括为以下四个步骤:
[0095]
步骤一:执行基于子块的仿射运动补偿,以使用在针对4参数仿射模型的(6)中和针对6参数仿射模型的(7)中导出的子块mv来生成子块预测i(i,j)。
[0096]
步骤二:将每个预测样本的空间梯度g
x
(i,j)和gy(i,j)计算为
[0097]gx
(i,j)=(i(i 1,j)-i(i-1,j))>>(max(2,14-bit-depth)-4)
ꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0098]gy
(i,j)=(i(i,j 1)-i(i,j-1))>>(max(2,14-bit-depth)-4)
[0099]
为了计算梯度,需要在一个子块的每一侧生成预测样本的一个附加的行/列。为了减少存储器带宽和复杂度,将扩展边界上的样本从参考图片中最近的整数像素位置复制,以避免附加的插值过程。
[0100]
步骤三:通过下式计算亮度预测细化值
[0101]
δi(i,j)=g
x
(i,j)*δv
x
(i,j) gy(i,j)*δvy(i,j)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)其中,δv(i,j)是针对样本位置(i,j)计算的像素mv(由v(i,j)表示)与像素(i,j)所位于的子块的子块mv之间的差。另外,在当前的prof设计中,在对原始预测样本添加预测细化后,进行一次裁剪运算,以将细化后的预测样本的值裁剪到15比特以内,即
[0102]
ir(i,j)=i(i,j) δi(i,j)
[0103]
ir(i,j)=clip3(-2
14
,2
14-1,ir(i,j))
[0104]
其中i(i,j)和ir(i,j)分别是位置(i,j)处的原始预测样本和细化后的预测样本。
[0105]
图7示出了根据本公开的针对仿射模式的prof过程。
[0106]
因为仿射模型参数和相对于子块中心的像素位置在子块之间没有改变,所以δv(i,j)可以针对第一子块来计算,并且重用于同一cu中的其他子块。令δx和δy为从样本位置(i,j)到样本所属子块的中心的水平偏移和垂直偏移,δv(i,j)可以导出为
[0107][0108]
基于仿射子块mv导出方程(6)和(7),可以导出mv差δv(i,j)。具体地,对于4参数仿射模型,
[0109][0110]
对于6参数仿射模型,
[0111][0112]
其中,(v
0x
,v
0y
)、(v
1x
,v
1y
)、(v
2x
,v
2y
)是当前编码块的左上、右上和左下控制点mv,w和h是块的宽度和高度。在现有的prof设计中,mv差δv
x
和δvy总是以1/32像素的精度导出。
[0113]
局部光照补偿
[0114]
局部光照补偿(lic)是用于解决存在于时间相邻图片之间的局部光照变化的问题的编解码工具。将一对权重和偏移参数应用于参考样本以获得一个当前块的预测样本。通用数学模型如下
[0115]
p[x]=α*pr[x v] β
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(11)
[0116]
其中,pr[x v]是运动矢量v指示的参考块,[α,β]是参考块的对应的一对权重和偏移参数,并且p[x]是最终预测块。使用最小线性均方误差(llmse)算法基于当前块的模板(即,相邻重建样本)和模板的参考块(使用当前块的运动矢量导出)来估计该对权重和偏移参数。通过最小化模板样本与模板的参考样本之间的均方差,可以如下导出α和β的数学表示
[0117][0118][0119]
其中,i表示模板中的样本数。pc[xi]是当前块的模板的第i个样本,并且pr[xi]是基于运动矢量v的第i个模板样本的参考样本。
[0120]
除了应用于针对每个预测方向(l0或l1)最多包含一个运动矢量的常规帧间块之外,lic还应用于仿射模式编码的块,其中一个编码块被进一步分割为多个较小的子块,并且每个子块可以与不同的运动信息相关联。为了针对仿射模式编码块的lic导出参考样本,如图16a和图16b所示,一个仿射编码块的顶部模板中的参考样本是使用顶部子块行中的每个子块的运动矢量来取得的,而左侧模板中的参考样本是使用左侧子块列中的子块的运动矢量来取得的。之后,应用与(12)中所示的相同的llmse导出方法,以基于复合模板导出lic参数。
[0121]
图16a示出了根据本公开的用于针对仿射模式导出模板样本的图示。图示包含cur frame 1620和cur cu 1622。cur frame 1620是当前帧。cur cu 1622是当前编码单元。
[0122]
图16b示出了用于针对仿射模式导出模板样本的图示。图示包含ref frame 1640、col cu 1642、a ref 1643、b ref 1644、c ref 1645、d ref 1646、e ref 1647、f ref 1648和g ref 1649。ref frame1640是参考帧。col cu 1642是同位编码单元。a ref 1643、b ref 1644、c ref 1645、d ref 1646、e ref 1647、f ref 1648和g ref 1649是参考样本。
[0123]
本公开中使用的术语仅用于描述示例性示例的目的,而不旨在限制本公开。如在本公开和所附权利要求中使用的,除非上下文另有明确指示,否则单数形式“一(a)”、“一个(an)”和“该(the)”旨在也包括复数形式。还应理解,除非上下文另有明确指示,否则本文使
用的术语“或”和“和/或”旨在表示并包括关联列出项目中的一个或多个的任何或所有可能组合。
[0124]
应当理解,虽然术语“第一”、“第二”、“第三”等可以包括在本文中用于描述各种信息,但信息不应受这些术语的限制。这些术语仅用于将一类信息与另一类信息区分开来。例如,在不脱离本公开的范围的情况下,第一信息可以包括称为第二信息;类似地,第二信息也可以称为第一信息。如本文所使用的,根据上下文,术语“如果”可以理解为表示“当
……
时(when)”或“在
……
后(upon)”或“响应于”。
[0125]
贯穿本说明书以单数或复数形式对“一个示例”、“示例”、“示例性示例”等的引用意味着结合示例描述的一个或多个特定特征、结构或特性包括在本公开的至少一个示例中。因此,贯穿本说明书各处以单数或复数形式出现的短语“在一个示例中”或“在示例中”、“在示例性示例中”等不一定都指代同一示例。此外,一个或多个示例中的特定特征、结构或特性可以包括以任何合适的方式组合。
[0126]
当前的bdof、prof和lic设计
[0127]
虽然prof可以提高仿射模式的编码效率,但其设计仍可以进一步改进。特别是考虑到prof和bdof两者都建立在光流概念之上,因此非常希望尽可能协调prof和bdof的设计,以使得prof可以最大限度地利用bdof的现有逻辑来促进硬件实现。基于这种考虑,在本公开中标识出了当前prof和bdof设计之间的交互的以下低效率。
[0128]
如“针对仿射模式的利用光流的预测细化”部分中描述的,在公式(8)中,梯度的精度是基于内部比特深度确定的。另一方面,mv差(即,δv
x
和δvy)总是以1/32像素的精度导出。相应地,基于公式(9),导出的prof细化的精度取决于内部比特深度。然而,与bdof类似,prof应用于处于中高比特深度(即,16比特)的预测样本值之上,以便保持更高的prof导出精度。因此,无论内部编码比特深度如何,prof导出的预测细化的精度都应与中等预测样本的精度(即,16比特)相匹配。换言之,现有prof设计中mv差和梯度的表示比特深度并不完全匹配从而导出相对于预测样本精度(即,16比特)的准确预测细化。同时,基于公式(1)、(4)和(8)的比较,现有prof和bdof使用不同的精度来表示样本梯度和mv差。如前面指出的,这种不统一的设计对于硬件来说是不期望的,因为现有bdof逻辑不能被重用。
[0129]
如“针对仿射模式的利用光流的预测细化”部分中讨论的,当一个当前仿射块是双向预测的时,prof单独地应用于列表l0和l1中的预测样本;然后,对增强后的l0和l1预测信号进行平均,以生成最终的双向预测信号。相反,不是针对每个预测方向单独地导出prof细化,而是bdof一次导出预测细化,然后将其应用于增强组合的l0和l1预测信号。图8和图9(下面描述)比较了当前bdof和prof用于双向预测的工作流。在实际的编解码器硬件流水线设计中,通常为每个流水线阶段指派不同的主要编码/解码模块,使得可以并行处理更多的编码块。然而,由于bdof和prof工作流之间的差异,这可能会导致难以拥有一个可以由bdof和prof共享的相同流水线设计,这对于实际编解码器实现是不友好的。
[0130]
图8示出了根据本公开的bdof的工作流。工作流800包括l0运动补偿810、l1运动补偿820和bdof 830。l0运动补偿810例如可以是来自先前参考图片的运动补偿样本的列表。先前参考图片是视频块中的当前图片之前的参考图片。l1运动补偿820例如可以是来自下一个参考图片的运动补偿样本的列表。下一个参考图片是视频块中当前图片之后的参考图片。bdof 830从l1运动补偿810和l1运动补偿820中获取运动补偿样本并输出预测样本,如
以上关于图4所描述的。
[0131]
图9示出了根据本公开的现有prof的工作流。工作流900包括l0运动补偿910、l1运动补偿920、l0 prof 930、l1 prof 940和平均960。l0运动补偿910例如可以是来自先前参考图片的运动补偿样本的列表。先前参考图片是视频块中当前图片之前的参考图片。例如,l1运动补偿920可以是来自下一个参考图片的运动补偿样本的列表。下一个参考图片是视频块中当前图片之后的参考图片。l0 prof 930从l0运动补偿910中获取l0运动补偿样本并输出运动细化值,如以上关于图7所描述的。l1 prof 940从l1运动补偿920中获取l1运动补偿样本并输出运动细化值,如以上关于图7所描述的。平均960对l0 prof 930和l1 prof 940的运动细化值输出取平均。
[0132]
1)对于bdof和prof两者,需要针对当前编码块内的每个样本计算梯度,这要求在块的每一侧上生成预测样本的一个附加的行/列。为了避免样本插值的附加的计算复杂度,块周围的扩展区域中的预测样本被直接从整数位置的参考样本进行复制(即,没有插值)。然而,根据现有的设计,选择不同位置的整数样本来生成bdof和prof的梯度值。具体地,对于bdof,使用位于预测样本左侧(对于水平梯度)和预测样本上方(对于垂直梯度)的整数参考样本;对于prof,最接近预测样本的整数参考样本用于梯度计算。与比特深度表示问题类似,这种非统一梯度计算方法对于硬件编解码器实现也是不期望的。
[0133]
2)如前面指出的,prof的动机是补偿每个样本的mv与在该样本所属的子块的中心处导出的子块mv之间的小的mv差。根据目前的prof设计,prof总是在一个编码块由仿射模式预测时被调用。然而,如公式(6)和(7)所指示的,一个仿射块的子块mv是从控制点mv导出的。因此,当控制点mv之间的差相对小时,每个样本位置处的mv应该是一致的。在这种情况下,由于应用prof的益处可能非常有限,因此在考虑性能/复杂度权衡时可能不值得进行prof。
[0134]
对bdof、prof和lic的改进
[0135]
在本公开中,提供了改进和简化现有prof设计以促进硬件编解码器实现的方法。尤其是,要特别注意协调bdof和prof的设计,以最大限度地与prof共享现有的bdof逻辑。总体上,本公开中提出的技术的主要方面总结如下。
[0136]
1)为了改进prof的编码效率,同时实现一个更统一的设计,提出了一种方法来统一由bdof和prof使用的样本梯度和mv差的表示比特深度。
[0137]
2)为了便于硬件流水线设计,提出了将prof的工作流与bdof的工作流相协调以用于双向预测。具体地,与单独地针对l0和l1导出预测细化的现有prof不同,所提出的方法导出预测细化一次,该预测细化应用于组合的l0和l1预测信号。
[0138]
3)提出了两种方法来协调整数参考样本的导出以计算由bdof和prof使用的梯度值。
[0139]
4)为了降低计算复杂度,提出了提前终止方法以在满足某些条件时自适应地禁用用于仿射编码块的prof过程。
[0140]
prof梯度和mv差的改进的比特深度表示设计
[0141]
如“问题陈述”部分中分析的,当前prof中的mv差和样本梯度的表示比特深度未对齐来导出准确的预测细化。此外,bdof和prof之间样本梯度和mv差的表示比特深度不一致,这对硬件不友好。在本部分中,通过将bdof的比特深度表示方法扩展到prof,提出了一种改
进的比特深度表示方法。具体地,在所提出的方法中,每个样本位置处的水平梯度和垂直梯度计算为
[0142][0143]
另外,假设δx和δy是从一个样本位置到样本所属的子块的中心的、以1/4像素精度表示的水平偏移和垂直偏移,则样本位置处的对应prof mv差导出为
[0144][0145]
其中dmvbits是bdof过程使用的梯度值的比特深度,即,dmvbits=max(5,(bit-depth-7)) 1。在公式(13)和(14)中,c、d、e和f是基于仿射控制点mv导出的仿射参数。具体地,对于4参数仿射模型,
[0146][0147]
对于6参数仿射模型,
[0148][0149]
其中,(v
0x
,v
0y
)、(v
1x
,v
1y
)、(v
2x
,v
2y
)是当前编码块的左上、右上和左下控制点mv,其以1/16像素精度表示,并且w和h是块的宽度和高度。
[0150]
在上述讨论中,如公式(13)和(14)所示,应用一对固定的右移来计算梯度和mv差的值。在实践中,可以将不同的逐位右移应用于(13)和(14)实现梯度和mv差的各种表示精度,以在中等计算精度和内部prof导出过程的比特宽度之间进行不同的权衡。例如,当输入视频包含大量噪声时,导出的梯度可能无法可靠地表示每个样本处的真实局部水平/垂直梯度值。在这种情况下,使用更多比特来表示mv差相比于梯度更有意义。另一方面,当输入视频显示稳定运动时,仿射模型导出的mv差应该非常小。如果是这样,使用高精度mv差不能提供附加的益处来提高导出的prof细化的精度。换言之,在这种情况下,使用更多的比特来表示梯度值更有利。基于上述考虑,在本公开的一个实施例中,下面提出了一种用于针对prof计算梯度和mv差的通用方法。具体地,假设每个样本位置处的水平梯度和垂直梯度是通过对相邻预测样本的差应用na次右移来计算的,即
[0151][0152]
样本位置处的对应的prof mv差δv(x,y)应计算为
[0153]
[0154]
其中,δx和δy是以1/4像素准确度表示的、从一个样本位置到样本所属的子块的中心的水平偏移和垂直偏移,并且c、d、e和f是是基于1/16像素仿射控制点mv导出的仿射参数。最后,样本的最终prof细化计算为
[0155]
δi(i,j)=(g
x
(i,j)*δv
x
(i,j) gy(i,j)*δvy(i,j) 1)>>1
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(17)
[0156]
在本公开的另一个实施例中,如下提出了另一种prof比特深度控制方法。在该方法中,每个样本位置处的水平梯度和垂直梯度仍然如(18)中通过对相邻预测样本的差值应用na比特右移来计算。样本位置处的对应的prof mv差应计算为:
[0157]
δv
x
(i,j)=(c*δx d*δy)>>(14-na)
[0158]
δvy(i,j)=(e*δx f*δy)>>(14-na)
[0159]
此外,为了将整个prof导出保持在适当的内部比特深度,对导出的mv差应用裁剪,如下:
[0160]
δv
x
(i,j)=clip3(-limit,limit,δv
x
(i,j))
[0161]
δvy(i,j)=clip3(-limit,limit,δvy(i,j))
[0162]
其中limit是等于的阈值,并且clip3(min,max,x)是一个函数,它在[min,max]的范围内对给定值x进行裁剪。在一个示例中,nb的值设置为2
max(5,bit-depth-7)
。最后,样本的prof细化计算为
[0163]
δi(i,j)=g
x
(i,j)*δv
x
(i,j) gy(i,j)*δvy(i,j)
[0164]
用于双向预测的bdof和prof的经协调的工作流
[0165]
如前面讨论的,当一个仿射编码块被双向预测时,当前prof以单边方式应用。更具体地,prof样本细化是单独导出的,并且应用于列表l0和l1中的预测样本。之后,分别来自列表l0和l1的细化预测信号被平均以生成块的最终双向预测信号。这与bdof设计形成对比,在bdof设计中样本细化被导出并应用于双向预测信号。bdof和prof的双向预测工作流之间的这种差异可能对实际编解码器流水线设计不友好。
[0166]
为了便于硬件流水线设计,根据本公开的一种简化方法用于修改prof的双向预测过程,使得两种预测细化方法的工作流协调。具体地,不是针对每个预测方向单独地应用细化,而是所提出的prof方法基于列表l0和l1的控制点mv一次导出预测细化;然后将导出的预测细化应用于组合的l0和l1预测信号以提高质量。具体地,基于公式(14)中导出的mv差,通过所提出的方法将一个仿射编码块的最终双向预测样本计算为
[0167][0168]
其中,shift和o
offset
是应用于组合l0和l1预测信号以用于双向预测的右移值和偏移值,其分别等于(15-bit-depth)和1<<(14-bit-depth) (2<<13)。此外,如(18)所示,在所提出的方法中去除了现有prof设计中的裁剪运算(如(9)所示)。
[0169]
图12示出了根据本公开的当应用所提出的双向预测prof方法时的prof过程的图示。prof过程1200包括l0运动补偿1210、l1运动补偿1220和双向预测prof 1230。l0运动补偿1210例如可以是来自先前参考图片的运动补偿样本的列表。先前参考图片是视频块中当前图片之前的参考图片。l1运动补偿1220例如可以是来自下一个参考图片的运动补偿样本
的列表。下一个参考图片是视频块中当前图片之后的参考图片。如上面描述的,双向预测prof 1230从l1运动补偿1210和l1运动补偿1220中获取运动补偿样本并输出双向预测样本。
[0170]
图12示出了当应用所提出的双向预测prof方法时对应的prof过程。prof过程1200包括l0运动补偿1210、l1运动补偿1220和双向预测prof 1230。l0运动补偿1210例如可以是来自先前参考图片的运动补偿样本的列表。先前参考图片是视频块中当前图片之前的参考图片。l1运动补偿1220例如可以是来自下一个参考图片的运动补偿样本的列表。下一个参考图片是视频块中当前图片之后的参考图片。如上面描述的,双向预测prof 1230从l1运动补偿1210和l1运动补偿1220中获取运动补偿样本并输出双向预测样本。
[0171]
为了展示所提出的用于硬件流水线设计的方法的潜在益处,图13示出了一个示例来说明当应用bdof和所提出的prof两者时的流水线阶段。在图13中,一个帧间块的解码过程主要包括三个步骤:
[0172]
1)解析/解码编码块的mv并取得参考样本。
[0173]
2)生成编码块的l0和/或l1预测信号。
[0174]
3)当编码块是通过一种非仿射模式预测的时,基于bdof对生成的双向预测样本执行逐样本细化;或当编码块是通过仿射模式预测的时,基于prof对生成的双向预测样本执行逐样本细化。
[0175]
图13示出了根据本公开的当应用bdof和所提出的prof两者时的示例流水线阶段的图示。图13展示了所提出的硬件流水线设计方法的潜在益处。流水线阶段1300包括解析/解码mv并取得参考样本1310、运动补偿1320、bdof/prof 1330。流水线阶段1300将对视频块blk0、bkl1、bkl2、bkl3和blk4进行编码。每个视频块将从解析/解码mv并取得参考样本1310开始,并且依次移动到运动补偿1320,然后是运动补偿1320、bdof/prof 1330。这意味着直到blk0移动到运动补偿1320,blk0才会在流水线阶段1300过程中开始。随着时间从t0到t1、t2、t3和t4,对于所有阶段和视频块都是如此。
[0176]
在图13中,一个帧间块的解码过程主要包括三个步骤:
[0177]
第一,解析/解码编码块的mv并取得参考样本。
[0178]
第二,生成编码块的l0和/或l1预测信号。
[0179]
第三,当编码块是通过一种非仿射模式预测的时,基于bdof对生成的双向预测样本执行逐样本细化;或当编码块是通过仿射模式预测的时,基于prof对生成的双向预测样本执行逐样本细化。
[0180]
如图13所示,在应用所提出的协调方法后,bdof和prof两者直接应用于双向预测样本。考虑到bdof和prof应用于不同类型的编码块(即,bdof应用于非仿射块,而prof应用于仿射块),这两种编解码工具不能同时调用。因此,它们对应的解码过程可以通过共享相同的流水线阶段来进行。这比现有的prof设计更高效,在现有的prof设计中,由于bdof和prof的不同的双向预测工作流,因此很难为bdof和prof两者指派相同的流水线阶段。
[0181]
在上述讨论中,所提出的方法仅考虑了bdof和prof的工作流的协调。然而,根据现有设计,两种编解码工具的基本操作单元以不同的大小执行。具体地,对于bdof,一个编码块被分割成多个大小为ws×hs
的子块,其中ws=min(w,16)且hs=min(h,16),其中w和h是编码块的宽度和高度。bodf操作(例如,梯度计算和样本细化导出)是针对每个子块独立执行
的。另一方面,如前面描述的,仿射编码块被划分为4
×
4子块,其中每个子块被指派基于4参数或6参数仿射模型导出的一个单独的mv。因为prof只适用于仿射块,它的基本运算单位是4
×
4的子块。与双向预测工作流问题类似,对于prof使用与bdof不同的基本操作单元大小对硬件实现也是不友好的,并且使得bdof和prof难以共享整个解码过程的相同流水线阶段。为了解决这样的问题,在一个实施例中,提出将仿射模式的子块大小对齐为与bdof的子块大小相同。具体地,根据所提出的方法,当一个编码块通过仿射模式编码时,它将被分割成大小为ws×hs
的子块,其中ws=min(w,16)且hs=min(h,16),其中w和h是编码块的宽度和高度。每个子块被指派一个单独的mv,并且被视为一个独立的prof操作单元。值得一提的是,独立的prof操作单元确保在其之上执行prof操作,而无需参考来自相邻prof操作单元的信息。具体地,将一个样本位置处的prof mv差计算为样本位置处的mv与样本所在的prof操作单元的中心处的mv之间的差;prof导出使用的梯度是通过沿每个prof操作单元填充样本来计算的。所提出的方法实现的益处主要包括以下方面:1)简化的流水线架构,具有统一的基本操作单元大小以用于运动补偿和bdof/prof细化两者;2)减少的存储器带宽使用,这是由于仿射运动补偿的子块大小扩大;3)降低的分数样本插值的每样本计算复杂度。
[0182]
还应该提到的是,由于使用所提出的方法降低了计算复杂度(即,第3项),可以去除用于仿射编码块的现有6抽头插值滤波器约束。相反,用于非仿射编码块的默认8抽头插值也用于仿射编码块。在这种情况下,总体计算复杂度仍然可以与现有的prof设计(即,基于具有6抽头插值滤波器的4
×
4子块)相媲美。
[0183]
针对bdof和prof的梯度导出的协调
[0184]
如前面描述的,bdof和prof两者计算当前编码块内的每个样本的梯度,其访问该块的每一侧上的预测样本的一个附加行/列。为了避免附加的插值复杂度,块边界周围的扩展区域中的所需预测样本直接从整数参考样本中复制。然而,正如“问题陈述”部分中所指出的,不同位置处的整数样本用于计算bdof和prof的梯度值。
[0185]
为了实现更统一的设计,下面提出两种方法来统一bdof和prof使用的梯度导出方法。在第一种方法中,提出将prof的梯度导出方法对齐为与bdof的梯度导出方法相同。具体地,通过第一种方法,用于生成扩展区域中的预测样本的整数位置是通过对分数样本位置进行向下取整来确定的,即,选择的整数样本位置位于分数样本位置的左侧(对于水平梯度)和分数样本位置上方(对于垂直梯度)。
[0186]
在第二种方法中,提出将bdof的梯度导出方法对齐为与prof的梯度导出方法相同。更详细地,当应用第二种方法时,最接近预测样本的整数参考样本用于梯度计算。
[0187]
图14示出了根据本公开的使用bdof的梯度导出方法的示例。在图14中,空白圆圈表示整数位置处的参考样本,三角形表示当前块的分数预测样本,而灰色圆圈表示用于填补当前块的扩展区域的整数参考样本。
[0188]
图15示出了根据本公开的使用prof的梯度导出方法的示例。在图15中,空白圆圈表示整数位置处的参考样本,三角形表示当前块的分数预测样本,而灰色圆圈表示用于填补当前块的扩展区域的整数参考样本。
[0189]
图14和图15分别示出了在应用第一种方法(图12)和第二种方法(图13)时用于导出bdof和prof的梯度的对应整数样本位置。在图14和图15中,空白圆圈表示整数位置处的参考样本,三角形表示当前块的分数预测样本,而有图案的圆圈表示用于填补当前块的扩
展区域以进行梯度导出的整数参考样本。
[0190]
另外,根据现有bdof和prof设计,预测样本填充是以不同的编码级别进行的。具体地,对于bdof,填充沿每个sbwidth
×
sbheight子块的边界应用,其中sbwidth=min(cuwidth,16)且sbheight=min(cuheight,16)。cuwidth和cuheight是一个cu的宽度和高度。另一方面,prof的填充始终应用于4
×
4子块级别。在上面的讨论中,仅在bdof和prof之间统一了填充方法,而填充子块大小仍然不同。这对于实际的硬件实现也不友好,考虑到需要为bdof和prof的填充过程实现不同的模块。为了实现一种更统一的设计,提出统一bdof和prof的子块填充大小。在本公开的一个实施例中,提出以4
×
4级别应用bdof的预测样本填充。具体地,通过该方法,首先将cu划分为多个4
×
4的子块;在对每个4
×
4子块进行运动补偿之后,通过复制对应的整数样本位置来填充沿顶部/底部和左侧/右侧边界的扩展样本。
[0191]
图18a、图18b、图18c和图18d示出了将所提出的填充方法应用于一个16
×
16bdof cu的一个示例,其中虚线表示4
×
4子块边界,而灰色带表示每个4
×
4子块的填充样本。
[0192]
图18a示出了根据本公开的所提出的应用于16
×
16bdof cu的填充方法,其中虚线表示左上4
×
4子块边界1820。
[0193]
图18b示出了根据本公开的所提出的应用于16
×
16bdof cu的填充方法,其中虚线表示右上4
×
4子块边界1840。
[0194]
图18c示出了根据本公开的所提出的应用于16
×
16bdof cu的填充方法,其中虚线表示左下4
×
4子块边界1860。
[0195]
图18d示出了根据本公开的所提出的应用于16
×
16bdof cu的填充方法,其中虚线表示右下4
×
4子块边界1880。
[0196]
图10示出了根据本公开的用于解码视频信号的bdof和prof的统一方法。例如,该方法可以应用于解码器。
[0197]
在步骤1010中,解码器可以将视频块划分为多个非重叠视频子块。多个非重叠视频子块中的至少一个非重叠视频子块可以与两个运动矢量相关联。
[0198]
在步骤1012中,解码器可以获得与多个非重叠视频子块中的至少一个非重叠视频子块的两个运动矢量相关联的第一参考图片i
(0)
和第二参考图片i
(1)
。按照显示顺序,第一参考图片i
(0)
在当前图片之前并且第二参考图片i
(1)
在当前图片之后。
[0199]
在步骤1014中,解码器可以从第一参考图片i
(0)
中的参考块获得视频子块的第一预测样本i
(0)
(i,j)。i和j可以表示一个样本基于当前图片的坐标。
[0200]
在步骤1016中,解码器可以从第二参考图片i
(1)
中的参考块获得视频子块的第二预测样本i
(1)
(i,j)。
[0201]
在步骤1018中,解码器可以获得第一预测样本i
(0)
(i,j)和第二预测样本i
(1)
(i,j)的水平梯度值和垂直梯度值。
[0202]
在步骤1020中,当视频块不是以仿射模式编码时,解码器可以基于bdof获得视频子块中的样本的运动细化。
[0203]
在步骤1022中,当视频块是以仿射模式编码时,解码器可以基于prof获得视频子块中的样本的运动细化。
[0204]
在步骤1024中,解码器可以基于运动细化获得视频块的预测样本。
[0205]
启用/禁用bdof、prof和dmvr的高级别信令语法
[0206]
在现有的bdof和prof设计中,在sps中用信号通知两个不同的标志来单独地控制两种编解码工具的启用/禁用。然而,由于bdof和prof之间的相似性,更希望通过一个相同的控制标志从高级别启用和/或禁用bdof和prof。基于这样的考虑,在sps处引入了一个新的标志,称为sps_bdof_prof_enabled_flag,如表1所示。如表1所示,bdof的启用和禁用仅依赖于sps_bdof_prof_enabled_flag。当标志等于1时,启用bdof以对序列中的视频内容进行编解码。否则,当sps_bdof_prof_enabled_flag等于0时,将不应用bdof。另一方面,除了sps_bdof_prof_enabled_flag,sps级别仿射控制标志(即,sps_affine_enabled_flag)也用于有条件地启用和禁用prof。当标志sps_bdof_prof_enabled_flag和sps_affine_enabled_flag两者都等于1时,针对以仿射模式编码的所有编码块启用prof。当标志sps_bdof_prof_enabled_flag等于1并且sps_affine_enabled_flag等于0时,禁用prof。
[0207]
图11示出了根据本公开的用于解码视频信号的bdof和prof的方法。例如,该方法可以应用于解码器。
[0208]
在步骤1110中,解码器可以获得与视频块相关联的第一参考图片i
(0)
和第二参考图片i
(1)
。按照显示顺序,第一参考图片i
(0)
在当前图片之前并且第二参考图片i
(1)
在当前图片之后。
[0209]
在步骤1112中,解码器可以从第一参考图片i
(0)
中的参考块获得视频块的第一预测样本i
(0)
(i,j)。i和j可以表示一个样本基于当前图片的坐标。
[0210]
在步骤1114中,解码器可以从第二参考图片i
(1)
中的参考块获得视频块的第二预测样本i
(1)
(i,j)。
[0211]
在步骤1116中,解码器可以接收至少一个标志。该至少一个标志由编码器在sps中用信号通知,并且用信号通知是否针对当前视频块启用bdof和prof。
[0212]
在步骤1118中,当至少一个标志是启用时,当视频块是以仿射模式编码时,解码器可以应用prof以基于第一预测样本i
(0)
(i,j)和第二预测样本i
(1)
(i,j)导出视频块的运动细化。
[0213]
在步骤1120中,解码器可以基于被应用于视频块的bdof来获得视频块中的样本的运动细化。
[0214]
在步骤1122中,解码器可以基于运动细化获得视频块的预测样本。
[0215]
表1带有所提出的bdof/prof启用/禁用标志的修改后的sps语法表
[0216]
[0217][0218]
sps_bdof_prof_enabled_flag指定是否启用双向光流和利用光流的预测细化。当sps_bdof_prof_enabled_flag等于0时,双向光流和利用光流的预测细化两者都被禁用。当sps_bdof_prof_enabled_flag等于1且sps_affine_enabled_flag等于1时,双向光流和利用光流的预测细化两者都被启用。否则(sps_bdof_prof_enabled_flag等于1且sps_affine_enabled_flag等于0),启用双向光流,而禁用利用光流的预测细化。
[0219]
sps_bdof_prof_dmvr_slice_preset_flag指定何时在条带级别用信号通知标志slice_disable_bdof_prof_dmvr_flag。当标志等于1时,语法slice_disable_bdof_prof_dmvr_flag针对引用当前序列参数集的每个条带来用信号通知。否则(当sps_bdof_prof_dmvr_slice_present_flag等于0时),语法slice_disabled_bdof_prof_dmvr_flag将不会在条带级别用信号通知。当标志没有用信号通知时,它被推断为0。
[0220]
除了上述sps bdof/prof语法之外,还提出在条带级别引入另一个控制标志,即,引入slice_disable_bdof_prof_dmvr_flag以用于禁用bdof、prof和dmvr。sps标志sps_bdof_prof_dmvr_slice_present_flag(其在dmvr或bdof/prof sps级别控制标志中的任一个为真时在sps中用信号通知)用于指示slice_disable_bdof_prof_dmvr_flag的存在。如果存在,则用信号通知slice_disable_bdof_dmvr_flag。表2示出了在应用提出的语法之后的修改后的条带头语法表。
[0221]
表2带有所提出的bdof/prof启用/禁用标志的修改后的sps语法表
[0222][0223]
基于控制点mv差提前终止prof
[0224]
根据当前的prof设计,prof总是在通过仿射模式预测一个编码块时被调用。然而,如公式(6)和(7)所示,一个仿射块的子块mv是从控制点mv导出的。因此,当控制点mv之间的差相对小时,每个样本位置处的mv应该是一致的。在这种情况下,应用prof的益处可能非常有限。因此,为了进一步降低prof的平均计算复杂度,提出基于在一个4
×
4子块内的逐样本mv与逐子块mv之间的最大mv差,自适应地跳过基于prof的样本细化。因为一个4
×
4子块内的样本的prof mv差的值关于子块中心对称,所以最大水平和垂直prof mv差可以基于公式(10)计算为
[0225][0226]
根据当前公开,可以在确定mv差小到足以跳过prof过程时使用不同的度量。
[0227]
在一个示例中,基于公式(19),当绝对最大水平mv差和绝对最大垂直mv差之和不大于一个预定义阈值时,可以跳过prof过程,即
[0228][0229]
在另一示例中,当和的最大值不大于阈值时,可以跳过prof过程。
[0230][0231]
其中max(a,b)是返回输入值a和b之间的较大值的函数。
[0232]
除了以上两个示例之外,当前公开的精神还适用于使用其他度量来确定mv差是否足够小以跳过prof过程的情况。
[0233]
在上述方法中,基于mv差的幅值跳过prof。另一方面,除了mv差之外,还基于一个运动补偿块中每个样本位置处的局部梯度信息计算prof样本细化。对于包含较少高频细节的预测块(例如,平坦区域),梯度值往往很小,因此导出的样本细化的值应该很小。考虑到这一点,根据当前公开的另一实施例,提出仅将prof应用于包含足够高频信息的块的预测样本。
[0234]
可以使用不同的度量来确定块是否包含足够的高频信息,使得值得针对该块调用prof过程。在一个示例中,基于预测块内样本的梯度的平均幅值(即,绝对值)做出决策。当平均幅值小于一个阈值时,则预测块被分类为平坦区域,并且不应当应用prof;否则,预测块被认为包含足够的高频细节,其中prof仍然适用。在另一示例中,可以使用预测块内样本的梯度的最大幅值。如果最大幅值小于一个阈值,则针对该块跳过prof。在又一示例中,预测块的最大样本值和最小样本值之间的差imax-imin可以用于确定prof是否适用于该块。如果这样的差值小于阈值,则针对该块跳过prof。值得注意的是,本公开的精神也适用于使用一些其他度量来确定给定块是否包含足够的高频信息的情况。
[0235]
处理针对仿射模式的prof和lic之间的交互
[0236]
因为当前块的相邻重建样本(即,模板)被lic用于导出线性模型参数,所以一个lic编码块的解码取决于其相邻样本的完全重建。由于这种相互依赖性,对于实际的硬件实现,lic需要在重建阶段执行,在重建阶段中相邻重建样本变得可用于lic参数导出。因为块重建必须顺序执行(即,一个接一个),吞吐量(即,每单位时间可以并行完成的工作量)是在将其他编解码方法联合地应用于lic编码块时要考虑的一个重要问题。在本部分中,提出了两种方法来处理当针对仿射模式启用prof和lic两者时的交互。
[0237]
在本公开的第一实施例中,提出了针对一个仿射编码块排他地应用prof模式和lic模式。如前面讨论的,在现有设计中,prof在不用信号通知的情况下隐含地应用于所有仿射块,同时在编码块级别用信号通知或继承一个lic标志以指示是否将lic模式应用于一个仿射块。根据本公开的方法,提出了基于一个仿射块的lic标志的值有条件地应用prof。当标志等于1时,通过基于lic权重和偏移调整整个编码块的预测样本,仅应用lic。否则(即,lic标志等于0),prof应用于仿射编码块,以基于光流模型细化每个子块的预测样本。
[0238]
图17a示出了基于所提出的方法的解码过程的一个示例流程图,其中不允许同时应用prof和lic。
[0239]
图17a示出了根据本公开的基于所提出的方法的解码过程的图示,其中不允许prof和lic。解码过程1720包括lic标志是否启用1722步骤、lic 1724和prof 1726。lic标志是否启用1722是判断lic标志是否被置位并根据该判断进行下一步的步骤。如果lic标志被置位,则lic 1724是lic的应用。如果lic标志未被置位,则prof 1726是prof的应用。
[0240]
在本公开的第二实施例中,提出了在prof之后应用lic来生成一个仿射块的预测样本。具体地,在完成基于子块的仿射运动补偿后,基于prof样本细化对预测样本进行细化;然后,通过将一对权重和偏移(如从模板及其参考样本导出的)应用于经prof调整的预测样本来进行lic,以获得块的最终预测样本,示为
[0241]
p[x]=α*(pr[x v] δi[x]) β
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(22)
[0242]
其中,pr[x v]是运动矢量v所指示的当前块的参考块;α和β是lic权重和偏移;p[x]是最终的预测块;δi[x]是在(17)中导出的prof细化。
[0243]
图17b示出了根据本公开的解码过程的图示,其中应用prof和lic。解码过程1760包括仿射运动补偿1762、lic参数导出1764、prof 1766和lic样本调整1768。仿射运动补偿1762应用仿射运动并且是lic参数导出1764和prof 1766的输入。应用lic参数导出1764以导出lic参数。prof 1766是正在应用prof。lic样本调整1768是lic权重和偏移参数正在与prof组合。
[0244]
图17b示出了当应用第二方法时的示例性解码工作流。如图17b所示,因为lic使用模板(即,相邻重建样本)来计算lic线性模型,所以只要相邻重建样本变得可用,就可以立即导出lic参数。这意味着可以同时进行prof细化和lic参数导出。
[0245]
lic权重和偏移(即,α和β)以及prof细化(即,δi[x])通常是浮点数。对于友好的硬件实现,这些浮点数运算通常被实现为与一个整数值的乘法,然后是多个比特的右移运算。在现有的lic和prof设计中,由于这两个工具是单独设计的,因此在两个阶段分别应用n
lic
比特和n
prof
比特的两次不同右移。
[0246]
根据本公开的第三实施例,为了改进在将prof和lic联合地应用于仿射编码块的
情况下的编码增益,提出以高精度应用基于lic的样本调整和基于prof的样本调整。这是通过将它们的两个右移操作合二为一并在最后应用它以导出当前块的最终预测样本(如(12)所示)来完成的。
[0247]
可以使用包括一个或多个电路的装置来实施上述方法,这些电路包括专用集成电路(asic)、数字信号处理器(dsp)、数字信号处理设备(dspd)、可编程逻辑器件(pld)、现场可编程门阵列(fpga)、控制器、微控制器、微处理器或其他电子组件。该装置可以与其他硬件或软件组件组合地使用电路来执行上述方法。上面公开的每个模块、子模块、单元或子单元可以至少部分地使用一个或多个电路来实现。
[0248]
图19示出了与用户接口1960耦合的计算环境1910。计算环境1910可以是数据处理服务器的一部分。计算环境1910包括处理器1920、存储器1940和i/o接口1950。
[0249]
处理器1920典型地控制计算环境1910的整体操作,例如,与显示、数据采集、数据通信和图像处理相关联的操作。处理器1920可以包括一个或多个处理器以执行指令来执行上述方法中的步骤中的所有或一些步骤。此外,处理器1920可以包括促进处理器1920与其他组件之间的交互的一个或多个模块。处理器可以是中央处理单元(cpu)、微处理器、单片机、gpu等。
[0250]
存储器1940被配置为存储各种类型的数据以支持计算环境1910的操作。存储器1940可以包括预定软件1942。这种数据的示例包括用于在计算环境1910上操作的任何应用或方法的指令、视频数据集、图像数据等。存储器1940可以通过使用任何类型的易失性或非易失性存储器设备或其组合来实现,例如,静态随机存取存储器(sram)、电可擦除可编程只读存储器(eeprom)、可擦除可编程只读存储器(eprom)、可编程只读存储器(prom)、只读存储器(rom)、磁存储器、闪速存储器、磁盘或光盘。
[0251]
i/o接口1950提供处理器1920与外围接口模块(例如,键盘、点击轮、按钮等)之间的接口。按钮可以包括但不限于主页按钮、开始扫描按钮和停止扫描按钮。i/o接口1950可以与编码器和解码器耦合。
[0252]
在一些实施例中,还提供了一种非暂时性计算机可读存储介质,其包括多个程序,例如包括在存储器1940中,可由处理器1920在计算环境1910中执行,以用于执行上述方法。例如,非暂时性计算机可读存储介质可以是rom、ram、cd-rom、磁带、软盘、光数据存储设备等。
[0253]
非暂时性计算机可读存储介质已经在其中存储了用于由具有一个或多个处理器的计算设备执行的多个程序,其中多个程序在由一个或多个处理器执行时使计算设备执行上述运动预测方法。
[0254]
这里,计算环境1910可以用一个或多个专用集成电路(asic)、数字信号处理器(dsp)、数字信号处理设备(dspd)、可编程逻辑器件(pld)、现场可编程门阵列(fpga)、图形处理单元(gpu)、控制器、微控制器、微处理器或其他电子组件来实现,以用于执行上述方法。
[0255]
本公开的描述是为了说明的目的而呈现的,而并不旨在穷举或限制本公开。许多修改、变化和替代实现方式对于受益于前述描述和相关联的附图中呈现的教导的本领域普通技术人员将是显而易见的。
[0256]
选择和描述这些示例是为了解释本公开的原理并使本领域的其他技术人员能够
理解本公开的各种实现方式,并且最好地利用具有适合于预期的特定用途的各种修改的基本原理和各种实现方式。因此,应当理解,本公开的范围不限于所公开的实现方式的具体示例,并且修改和其他实现方式旨在包括在本公开的范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。