一种基于lstm的重介质选煤过程精煤质量多步预测方法
技术领域
1.本发明涉及质量预测领域,具体为一种基于lstm的重介质选煤过程精煤质量多步预测方法。
背景技术:
2.据统计,我国2020年co2排放量约为103亿吨,其中92%的co2排放量来自煤炭、石油和天然气(约为95亿吨)。而我国“富煤、缺油、少气”的能源结构特点,决定了未来相当长一段时间内煤炭仍是我国的重要战略能源和物资,其绿色开发和清洁利用是实现我国“双碳”目标的重要环节。选煤作为煤炭洁净利用的源头和基础,是加快调整能源结构、增加清洁能源供应的重要手段,评价其分选过程的指标之一就是精煤灰分的稳定性。因此,精煤质量——灰分的在线预测判断十分重要。
3.目前应用较多的煤炭分选方法为重介质选煤,重介选煤过程涉及多个处理单元、多种产品类型,包含多层面、多时空时间序列的过程大数据。近年来,随着人工智能的强势崛起,重介选煤厂中各个环节产生的不同时间、不同阶段的大数据被处理后以期能够指导实际生产。申请号为:cn201910900555.4的发明专利:一种重介分选过程智能控制系统及方法提供了一种重介分选过程智能控制系统及方法,利用煤炭的分选特性解决了现有分选密度设定依赖经验的程度较大的问题,但该专利未涉及使用现有的大数据处理精煤灰分预测的领域。同时,在重介质选煤的实际生产过程中,精煤在线灰分仪的测量精度受多种影响因素的制约与影响,使得其测量结果波动较大,难以反映实际精煤质量。
技术实现要素:
4.一、发明目的:
5.针对上述现有技术,提出一种基于lstm(long short-term memory)的重介质选煤过程精煤质量多步预测方法,高精度的实现重介质选煤精煤灰分的实时和多步预测。
6.二、技术方案:
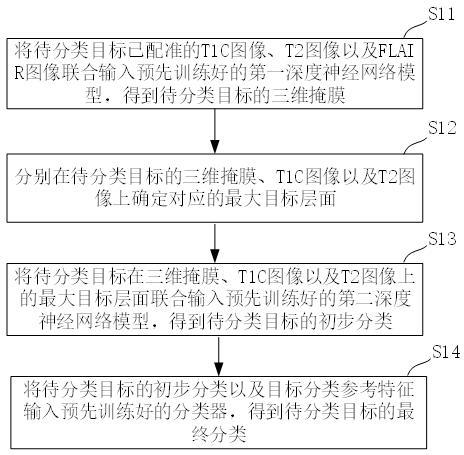
7.一种基于lstm的重介质选煤过程精煤质量多步预测方法,包括以下步骤:
8.步骤1:采集与选煤生产相关的传感器在线数据,如皮带秤量、灰分仪量、悬浮液密度、液位计值、压力计值等,形成按天存储的历史数据库。
9.步骤2:分析历史数据库中所采集变量与待预测变量精煤灰分(jm_ash)之间是否存在某种依存关系,进行相关分析(correlation analysis),通过pearson相关系数的大小判定各变量与目标灰分的相关程度,进而去掉一部分无意义数据列,对得到的的数据进行质量检测,空缺值预处理。采用meancompleter补齐算法,对相邻两个时刻点检测值求平均,得到缺失点的值,将原始数据中的缺失数据进行补齐。
10.步骤3:再进行数据清洗,将经处理后的数据,重组成按连续生产班组存储的历史数据。如2019年5月13日20:00点开始生产,2019年5月14日8:00停机的数据合并为一组连续生产数据。
11.步骤4:计算时序步长时间t。
12.步骤5:选取一个生产组进行时间序列重组,
13.步骤6:对每个连续生产班组数据进行时间重构后,合并成待训练的预测数据集,得到多维输入矩阵x和二维输出矩阵y。
14.步骤7:对输入矩阵x和输出矩阵y中的数据列进行归一化处理,以消除各变量阈值变化较大对模型预测产生的影响。
15.步骤8:将经过时间序列重组、归一化处理后的输入矩阵x和目标变量矩阵y进行划分,80%用于训练,20%用于测试。
16.步骤9:模型搭建,构建多层lstm神经网络。
17.步骤10:模型训练,通过train loss和test loss的值和趋势调整步骤11的网络结构,
18.步骤11,保存模型及模型权重文件于本地。
19.步骤12:获取新的生产数据作为验证集,根据步骤3-9对输入变量进行预处理,带入上步保存的模型进行输出预测。
20.步骤13:选取均方根误差rmse和复判定系数r2来对预测误差进行评价,其中均方根误差表达式为:复判定系数表达式为:经模型仿真预测得到预测的精煤灰分值与真实的精煤灰分值间的rmse值为0.2416。r2值为0.8032。
21.步骤14:将上述数据处理方法与优化模型,应用于选煤厂生产环节的精煤质量预测,当预测的产品质量精煤灰分jm_ash发生较大波动时,需及时调整控制变量,稳定产品质量。
22.优选的,步骤(2)去除不相关数据种类的方法包括判断数据种类中各类数据与待预测变量精煤灰分jm_ash之间是否存在依存关系,进行相关分析correlation analysis,通过pearson相关系数的大小判定各变量与目标灰分的相关程度,去除相关程度小的数据种类。
23.优选的,步骤(2)中空缺值预处理包括采用meancompleter补齐算法,对相邻两个采样检测值求平均,得到缺失点的值,将数据中的缺失数据进行补齐;
24.优选的,所述传感器数值为0的情况包括开停机过渡数据、停机检修异常数据。
25.优选的,对每个生产组数据,原煤皮带秤开始带煤时间与精煤皮带秤产生数据的时间差,取平均值后作为选煤生产系统的煤流分选运输停滞时间t。
26.优选的,步骤(5)中时间重构的方法包括对二维矩阵x
n(a,6)
进行时间重构,当时间为t时,则将二维矩阵x
n(a,6)
重构为含有t-(t-1)、t-(t-2)
……
t-1、t的三维矩阵x
n(a,6,t)
;对待预测变量:jm_ash值y
n(a)
进行时间重构为t、t 1、t 2
……
t (t-1)的二维数据y
n(a,t)
。
27.优选的,步骤(9)构建多层lstm神经网络时,为防止模型的过拟合,增强模型的适用性,增加多级遗忘层。
28.优选的,步骤(1)-(14)均通过计算机程序完成,所述的程序存储于计算机可读存储介质中。
(t-2)
……
t-1、t的生产数据的三维数据x
n(a,6,t)
。对待预测变量:jm_ash值y
n(a)
进行时间重构为t、t 1、t 2
……
t (t-1)的二维数据y
n(a,t)
。
44.步骤8:重复步骤7,对每个连续生产班组数据进行时间重构后,合并成待训练的预测数据集,得到多维输入矩阵x和二维输出矩阵y。
45.步骤9:对输入矩阵x和输出矩阵y中的数据列进行归一化处理,以消除各变量阈值变化较大对模型预测产生的影响。
46.步骤10:将经过时间序列重组、归一化处理后的输入矩阵x和目标变量矩阵y进行划分,80%用于训练,20%用于测试。
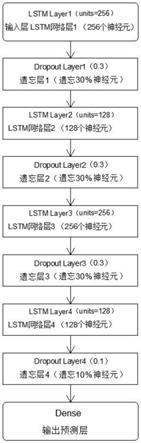
47.步骤11:模型搭建,构建多层lstm神经网络,为防止模型的过拟合,增强模型的适用性,增加多级遗忘层。
48.步骤12:模型训练,通过train loss和test loss的值和趋势调整步骤11的网络结构,本实例网络结构如附图2所示。
49.步骤13,保存模型及模型权重文件于本地。
50.步骤14:获取新的生产数据作为验证集,根据步骤3-9对输入变量进行预处理,带入上步保存的模型进行输出预测。
51.步骤16:选取均方根误差rmse和复判定系数r2来对预测误差进行评价,其中均方根误差表达式为:复判定系数表达式为:经模型仿真预测得到预测的精煤灰分值与真实的精煤灰分值间的rmse值为0.2416,r2值为0.8032。
52.步骤17:将上述数据处理方法与优化模型,应用于选煤厂生产环节的精煤质量预测,当预测的产品质量(精煤灰分)发生较大波动时,需及时调整控制变量,稳定产品质量。
53.本发明充分考虑了选煤工艺流程数据与待预测输出变量间的时空关系,使后续的机器学习预测模型结果,能够更好的适用于重介选煤这种具有复杂时空时间序列关系的工业过程。同时,利用上述数据的时空关系,实现了精煤质量的多步预测,并得到了较好的预测精度,这为后续选煤生产过程的精准控制与产品质量稳定提供了有力依据。
54.本领域技术人员可以理解,实现上述实施例方法的全部或部分流程,可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于计算机可读存储介质中。其中,所述计算机可读存储介质为磁盘、光盘、只读存储记忆体或随机存储记忆体等。
55.以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。