1.本发明涉及图形处理技术领域,尤其涉及一种图形处理器及图形处理方法。
背景技术:
2.传统的图形处理器(graphics processing unit,gpu)共享了gpu的传统体系结构,可以方便的增加矩阵的扩展指令集以及改善调度单元来为算术逻辑单元alu和张量核心(tensor core)提供足够的输入数据。
3.由于深度学习运算相对稳定的数据流,传统的图形处理器由于过度的细粒度必然导致数据无法很好地共享,例如权重等数据需要从共享内存(sharememory)或者外部缓存广播到不同的计算核心的寄存器文件,这个极大的增加了总线上的数据传输,同时张量核心受限于局部缓存,输入数据也很难被复用。
4.因此,有必要提供一种新型的图形处理器及图形处理方法以解决现有技术中存在的上述问题。
技术实现要素:
5.本发明的目的在于提供一种图形处理器及图形处理方法,便于数据的共享。
6.为实现上述目的,本发明的所述图形处理器,包括:处理器单元,包括多个流式多处理器;数据共享处理单元,包括张量核心阵列,所述流式多处理器共用所述张量核心阵列。
7.可选地,所述张量核心阵列包括呈矩阵分布的点积阵列引擎,所述流式多处理器包括多个流处理器,所述点积阵列引擎的数量与所述流处理器的数量相匹配。
8.可选地,所述数据共享处理单元还包括控制单元,用于存放所述张量核心阵列的控制指令,以实现对所述张量核心阵列的控制。
9.可选地,所述数据共享处理单元还包括缓冲单元,用于数据缓冲。
10.可选地,所述数据共享处理单元还包括第一神经网络单元,用于进行神经网络运算,所述缓冲单元包括数据缓冲子单元,所述第一神经网络单元与所述数据缓冲子单元连接。
11.可选地,所述数据共享处理单元还包括任务分配单元,所述任务分配单元与所有所述流式多处理器和所述数据缓冲子单元连接,所述任务分配单元用于实现所有所述流式多处理器的通用计算任务创建、提交及所述数据缓冲子单元之间的数据传输。
12.可选地,所述数据共享处理单元还包括数据引擎单元,所述缓冲单元包括输入缓冲子单元和外缓冲子单元,所述外缓冲子单元与所有所述流式多处理器和所述数据引擎单元连接,所述输入缓冲子单元与所述数据引擎单元和所述张量核心阵列连接。
13.可选地,所述数据共享处理单元还包括累加单元,与所述张量核心阵列连接,用于对所述张量核心阵列的运算结果进行累加运算。
14.可选地,所述数据共享处理单元还包括第二神经网络单元,与所述累加单元和所述外缓冲子单元连接,用于对所述累加单元的输出数据进行神经网络运算,并将神经网络运算结果传输给所述外缓冲子单元。
15.本发明还提供了一种图形处理器的图形处理方法,包括:处理器单元、数据共享处理单元中的至少一个获取待处理数据和权重数据;所述处理器单元、所述张量核心阵列中的至少一个根据所述权重数据独立或同步对所述待处理数据进行图形处理,其中,当所述处理器单元和所述数据共享处理单元共同进行图形处理时,通过事件令牌相互同步。
16.可选地,所述数据共享处理单元还包括控制单元,所述处理器单元、数据共享处理单元中的至少一个获取待处理数据和权重数据,包括:所述控制单元从内存或pcie总线获取待处理数据和权重数据。
17.可选地,所述数据共享处理单元还包括缓冲单元,所述缓冲单元包括外缓冲子单元,所述处理器单元、数据共享处理单元中的至少一个获取待处理数据和权重数据,包括:所述控制单元将所述待处理数据和所述权重数据传输给所述外缓冲子单元。
18.可选地,所述数据共享处理单元还包括数据引擎单元,所述处理器单元、数据共享处理单元中的至少一个获取待处理数据和权重数据,包括:所述数据引擎单元配合所述输入缓冲子单元对所述待处理数据完成矩阵输入的数据转换,以得到待运算数据,并将所述待运算数据传输给所述张量核心阵列。
19.可选地,所述图形处理包括点积阵列运算。
20.所述图形处理器的有益效果在于:所述流式多处理器共用所述张量核心阵列,使得所述张量核心阵列独立于所述流式多处理器外,减少了流式多处理器对张量核心阵列的影响,便于数据的共享。所述图形处理方法的有益效果在于:处理器单元、数据共享处理单元中的至少一个获取待处理数据和权重数据,能够独立获取待处理数据和权重数据,减少了流式多处理器对张量核心阵列的影响,便于数据的共享。
附图说明
21.图1为本发明图形处理器的结构框图;图2为本发明一些实施例中流式多处理器的结构框图。
具体实施方式
22.为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。除非另外定义,此处使用的技术术语或者科学术语应当为本发明所属领域内具有一般技能的人士所理解的通常意义。本文中使用的“包括”等类似的词语意指出现该词前面的元件或者物件涵盖出现在该词后面列举的元件或者物件及其等同,而不排除其他元件或者物件。
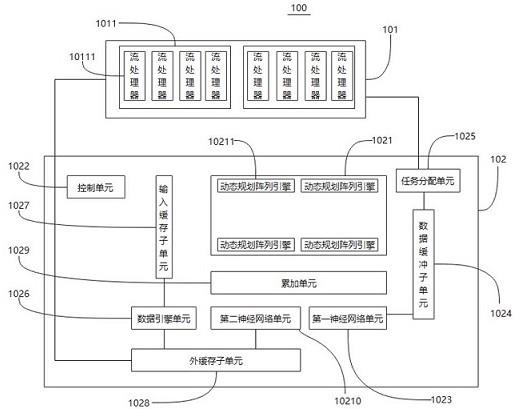
23.针对现有技术存在的问题,本发明的实施例提供了一种图形处理器。参照图1,所述图形处理器100包括处理器单元101和数据共享处理单元102。
24.参照图1,所述处理器单元101包括多个流式多处理器1011,所述数据共享处理单元102包括张量核心阵列1021,所述流式多处理器1011共用所述张量核心阵列1021。
25.一些实施例中,所述图形处理器还包括指令集单元,所述指令集单元通过扩展所述图形处理器的指令集支持所述张量核心阵列,所述指令集包括ld.flag dst指令、[src.crdnum]指令、src0[imm]指令,并共享传统的gpu指令,所述传统的gpu指令包括中间计算。
[0026]
一些实施例中,所述处理器单元和所述张量核心阵列均能够作为当前层的主体,且所述处理器单元和所述张量核心阵列之间通过事件令牌相互同步,独立的任务可以相互运行不受影响。
[0027]
一些实施例中,以所述处理器单元作为主体启动计算着色器任务的主要目的是为了提供更好的灵活性,对后处理激活函数的输入提供更多的选择,为下一层的输入或输出提供更方便的控制。
[0028]
一些实施例中,以所述张量核心阵列作为主体启动计算着色器任务的主要目的是为了更高的加速比。
[0029]
参照图1,所述张量核心阵列1021包括呈矩阵分布的点积阵列引擎10211,所述流式多处理器1011包括多个流处理器10111,所述点积阵列引擎10211的数量与所述流处理器10111的数量相匹配。
[0030]
参照图1,所述数据共享处理单元102还包括控制单元1022,用于存放所述张量核心阵列1021的控制指令,以实现对所述张量核心阵列1021的控制。所述控制指令包括循环控制指令、预读取数据指令、权重数据、调用数据引擎的指令。所述调用数据引擎的指令包括压平指令、复制指令、变换指令等。
[0031]
一些实施例中,所述数据共享处理单元还包括缓冲单元,用于数据缓冲。
[0032]
参照图1,所述数据共享处理单元102还包括第一神经网络单元1023,用于进行神经网络运算,所述缓冲单元包括数据缓冲子单元1024,所述第一神经网络单元1023与所述数据缓冲子单元1024连接。
[0033]
参照图1,所述数据共享处理单元102还包括任务分配单元1025,所述任务分配单元1025与所有所述流式多处理器1011和所述数据缓冲子单元1024连接,所述任务分配单元1025用于实现所有所述流式多处理器1011的通用计算任务创建、提交及所述数据缓冲子单元1024之间的数据传输。
[0034]
参照图1,所述数据共享处理单元102还包括数据引擎单元1026,所述缓冲单元包括输入缓冲子单元1027和外缓冲子单元1028,所述外缓冲子单元1028与所有所述流式多处理器1011和所述数据引擎单元1026连接,所述输入缓冲子单元1027与所述数据引擎单元1026和所述张量核心阵列1021连接。
[0035]
参照图1,所述数据共享处理单元102还包括累加单元1029,所述累加单元1029与所述张量核心阵列1021连接,用于对所述张量核心阵列1021的运算结果进行累加运算。
[0036]
参照图1,所述数据共享处理单元102还包括第二神经网络单元10210,所述第二神经网络单元10210与所述累加单元1029和所述外缓冲子单元1028连接,用于对所述累加单元1029的输出数据进行神经网络运算,并将神经网络运算结果传输给所述外缓冲子单元1028。所述外缓冲子单元1028包括高速缓冲存储器或缓冲器。
[0037]
图2为本发明一些实施例中流式多处理器的结构框图。参照图2,所述流式多处理器1011包括四个调度单元10111、寄存器单元10112、四个算术逻辑单元10113、四个特殊函数单元10114、四个读取单元10115和内存单元10116。
[0038]
参照图2,一个所述算术逻辑单元10113和一个所述特殊函数单元10114共同对应一个所述读取单元10115,一个所述算术逻辑单元10113和一个所述特殊函数单元10114共同对应一个所述寄存器单元10112,一个所述寄存器单元10112对应一个所述调度单元10111。
[0039]
参照图2,所述内存单元10116包括共享内存(图中未示出)和高速缓冲存储器(图中未示出)中的至少一个。
[0040]
一些实例中,一个所述调度单元、一个所述算术逻辑单元、一个特殊函数单元、一个读取单元构成一个所述流处理器。
[0041]
一些实施例中,所述指令集单元通过所述指令集中指令的标识告知译码器(decoder)这是一条矩阵操作指令,并通知所述调度单元是否需要挂起当前线程,所述指令由指令发送单元发送到加载存储控制单元(load store control unit),然后旁路给所述张量核心阵列,所述张量核心阵列接收到指令后,根据位置单元提供的权重偏移得知当前以哪一组权重进行计算,并且所述位置单元根据维度发送相应的位置坐标。其中,所述译码器、所述加载存储控制单元(load store control unit)和所述位置单元均为gpu中的常用单元,在此不再详细赘述。
[0042]
本发明还提供了一种图形处理器的图形处理方法,包括以下步骤:s1:处理器单元、数据共享处理单元中的至少一个获取待处理数据和权重数据;s2:所述处理器单元、所述张量核心阵列中的至少一个根据所述权重数据独立或同步对所述待处理数据进行图形处理,其中,当所述处理器单元和所述数据共享处理单元共同进行图形处理时,通过事件令牌相互同步。
[0043]
一些实施例中,所述图形处理包括点积阵列运算。
[0044]
一些实施例中,所述处理器单元、数据共享处理单元中的至少一个获取待处理数据和权重数据,包括:所述控制单元从内存或pcie总线获取待处理数据和权重数据。
[0045]
一些实施例中,所述缓冲单元包括外缓冲子单元,所述处理器单元、数据共享处理单元中的至少一个获取待处理数据和权重数据,包括:所述控制单元将所述待处理数据和所述权重数据传输给所述外缓冲子单元。
[0046]
一些实施例中,所述处理器单元、数据共享处理单元中的至少一个获取待处理数据和权重数据,包括:所述数据引擎单元配合所述输入缓冲子单元对所述待处理数据完成矩阵输入的数据转换,以得到待运算数据,并将所述待运算数据传输给所述张量核心阵列。
[0047]
一些实施例中,当所述张量核心阵列作为主体,当激活函数以及输出是默认的传统模式时,数据走固定流水线,以减少对gpu逻辑的依赖,当需要自定义后续操作时,则将数据写入到所述数据缓冲子单元,所述任务分配单元根据所述数据缓冲子单元内的数据构建新的异步运行cs任务,所述cs任务会根据预先定义的着色程序,对数据进行处理,并通过uva路径将数据写入到内存中。
[0048]
本发明的一些实施例中,所述图形处理器读取直接存储器访问(direct memory access,dma)的指令,然后按照所述指令配置相关的所述寄存器单元;
所述控制单元从内存或pcie总线获取待处理数据,并将所述待处理数据传输给所述外缓冲子单元;在所述待处理数据传输给所述外缓冲子单元后,所述控制单元触发所述数据引擎单元,所述数据引擎单元配合所述输入缓冲子单元对所述待处理数据完成矩阵输入的数据转换,以得到待运算数据,并传输给所述张量核心阵列;所述张量核心阵列对待运算数据进行点积阵列(dot product array,dp)运算,以得到待累加数据;所述累加单元对所述待累加数据进行累加,以得到待激活数据;所述第二神经网络单元对所述待激活数据依次进行激活、归一化处理、池化等操作,以得到中间结果数据及最终结果数据,然后将最终结果数据发送到pcie总线,以便于cpu访问。将中间结果数据写入到局部缓存,若中间结果数据的大小超过局部缓存的容量,则将超过局部缓存容量的部分中间结果数据写入到显存中。
[0049]
其中,所述第二神经网络单元每完成一层操作,都会将中间结果数据写入所述外缓冲子单元,并且向所述张量核心阵列发送事件,所述张量核心阵列根据所述事件判断当前层操作是否结束,并判断是否开始下一层操作。
[0050]
本技术相对于现有技术中的传统cpu,待处理数据和权重数据从内存传输到全局缓存或图形处理集群(graphics processing cluster,gpc)的缓存,无需向更细粒度的流式多处理器传输,对数据带宽的需求减小,也能够让gpu任务并行,即使对于需要做后续处理的过程,传输的也仅仅是最终的数据,而无需传输待处理数据和权重数据等信息,从而能够更好的共享卷积中的数据和权重数据,减少了数据的内部传输。
[0051]
本技术中采用所述张量核心阵列,待处理数据由所述数据引擎单元提前划分好,且任务被一次性提交,所述控制单元能够准确的知道所有地址,无需任何计算,只需要按照既定规则进行循环处理即可。基于所述张量核心阵列,可以有效降低现有技术中分散在所述算术逻辑单元内部的大量地址计算,能够获得更好的数据处理效率。
[0052]
虽然在上文中详细说明了本发明的实施方式,但是对于本领域的技术人员来说显而易见的是,能够对这些实施方式进行各种修改和变化。但是,应理解,这种修改和变化都属于权利要求书中所述的本发明的范围和精神之内。而且,在此说明的本发明可有其它的实施方式,并且可通过多种方式实施或实现。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。