1.本发明实施例涉及通信领域,具体而言,涉及一种资源调度方法、装置、存储介质及电子装置。
背景技术:
2.kubernetes是一种开源并用于管理云平台中多个主机上的容器化的应用的管理机制,kubernetes的目标是让部署容器化的应用简单并且高效(powerful),对此,kubernetes提供了应用部署,规划,更新,维护的机制。
3.其中,kubernetes默认提供的资源调度方式在是以创建时间等系统参数作为优先级的计算变量,这种调度方式在需要自定义参数的场景中并不能满足要求。
4.例如,以单个任务或者某些资源作为调度优先级的计算锚点,是以单个任务为中心,而在多数业务场景中这种调度方式将无法满足资源需求,从而导致任务的调度与用户优先级之间关联较弱,无法把用户优先级与任务优先级相统一,容易造成系统资源被单个用户活任务阻塞或过分占用的情况。
5.针对上述问题,当前并未提出有效的解决办法。
技术实现要素:
6.本发明实施例提供了一种资源调度方法、装置、存储介质及电子装置,以至少解决相关技术中资源调度效率低的问题。
7.根据本发明的一个实施例,提供了一种资源调度方法,包括:获取第一请求队列,其中,所述第一请求队列是根据预设的优先级算法以及来自请求对象的资源请求信息确定的;根据所述第一请求队列,获取第一调度请求,其中,所述第一调度请求为所述第一请求队列中初始优先级满足第一条件的所述初始资源调度请求;将所述第一调度请求与第二调度请求进行优先级比较操作,以得到优先级比较结果,其中,所述第二调度请求为预先存储的目标资源调度请求;在所述优先级比较结果满足第二条件的情况下,将所述第一调度请求作为所述目标资源调度请求,并根据所述目标资源调度请求,执行目标资源调度操作。
8.在一个示例性实施例中,所述优先级算法包括:式中,δt 为采样周期,t 为控制优先级趋近用量的速率。
9.在一个示例性实施例中,所述获取第一请求队列包括:获取初始资源调度请求,其中,所述初始资源调度请求包括发送所述初始资源调度请求的请求对象信息;根据所述请求对象信息以及所述优先级算法,确定所述资源调度请求的初始优先级;
基于所述初始优先级,将所述资源调度请求加入初始请求队列,并对所述初始请求队列进行排序处理,以得到第一请求队列。
10.在一个示例性实施例中,在所述将所述第一调度请求与第二调度请求进行优先级比较操作,以得到优先级比较结果之后,所述方法还包括:在所述优先级比较结果不满足第二条件的情况下,对所述第一调度请求进行时序等待操作;在所述第一调度请求的等待时序大于目标时序的情况下,对所述第一调度请求进行回归操作,以将所述第一调度请求回归至所述第一请求队列。
11.在一个示例性实施例中,所述方法还包括:获取所述请求对象的初始对象信息,其中所述初始对象信息包括所述请求对象的初始资源占用信息以及初始评分信息;根据所述优先级算法,对所述初始资源占用信息以及初始评分信息进行优先级评分计算,以得到目标优先级评分:根据所述目标优先级评分,确定目标类型的所述请求对象的优先级。
12.在一个示例性实施例中,所述根据所述优先级算法,对所述初始资源占用信息以及初始评分信息进行优先级评分计算,以得到目标优先级评分包括以下方式之一:根据预设周期,通过所述优先级算法,对所述初始资源占用信息以及初始评分信息进行优先级评分计算,以得到目标优先级评分;获取系统运行时间;基于所述系统运行时间,确定目标周期;基于所述目标周期,通过所述优先级算法,对所述初始资源占用信息以及初始评分信息进行优先级评分计算,以得到目标优先级评分;对所述目标对象执行初始化操作,以得到初始对象信息,其中,所述初始对象信息包括所述请求对象的类型信息;根据所述类型信息以及所述优先级算法,确定所述请求对象的优先级权重;基于所述优先级权重以及所述类型信息,执行类型评分计算操作,以得到所述目标优先级评分。
13.根据本发明的另一个实施例,提供了一种资源调度装置,包括:队列获取模块,用于获取第一请求队列,其中,所述第一请求队列是根据预设的优先级算法以及来自请求对象的资源请求信息确定的;第一请求模块,用于根据所述第一请求队列,获取第一调度请求,其中,所述第一调度请求为所述第一请求队列中初始优先级满足第一条件的所述初始资源调度请求;优先级比较模块,用于将所述第一调度请求与第二调度请求进行优先级比较操作,以得到优先级比较结果,其中,所述第二调度请求为预先存储的目标资源调度请求;资源调度模块,用于在所述优先级比较结果满足第二条件的情况下,将所述第一调度请求作为所述目标资源调度请求,并根据所述目标资源调度请求,执行目标资源调度操作。
14.在一个示例性实施例中,所述优先级算法包括:式中,δt 为采样周期,t 为控制优先级趋近用量的速率。
15.根据本发明的又一个实施例,还提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,其中,所述计算机程序被设置为运行时执行上述任一项方法实施例中的步骤。
16.根据本发明的又一个实施例,还提供了一种电子装置,包括存储器和处理器,所述存储器中存储有计算机程序,所述处理器被设置为运行所述计算机程序以执行上述任一项方法实施例中的步骤。
17.通过本发明,先对资源请求信息进行排列,随后将优先级较高的第一资源调度请求与目标资源调度请求再进行优先级比较,从而满足多任务场景的资源调度需求,同时,由于反复对任务的优先级进行比较,并实时对新的资源调度请求进行排序,因此能够灵活调用各类资源,避免系统资源被单个任务阻塞或过分占用的情况,因此,可以解决资源调度效率低的问题,达到提高资源调度效率的效果。
附图说明
18.图1是本发明实施例的一种资源调度方法的移动终端的硬件结构框图;图2是根据本发明实施例的一种资源调度方法的流程图;图3是根据本发明具体实施例进行模拟的模拟结果示意图;图4是根据本发明实施例的一种资源调度装置的结构框图;图5是根据本发明具体实施例的结构框图。
具体实施方式
19.下文中将参考附图并结合实施例来详细说明本发明的实施例。
20.需要说明的是,本发明的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。
21.本技术实施例中所提供的方法实施例可以在移动终端、计算机终端或者类似的运算装置中执行。以运行在移动终端上为例,图1是本发明实施例的一种资源调度方法的移动终端的硬件结构框图。如图1所示,移动终端可以包括一个或多个(图1中仅示出一个)处理器102(处理器102可以包括但不限于微处理器mcu或可编程逻辑器件fpga等的处理装置)和用于存储数据的存储器104,其中,上述移动终端还可以包括用于通信功能的传输设备106以及输入输出设备108。本领域普通技术人员可以理解,图1所示的结构仅为示意,其并不对上述移动终端的结构造成限定。例如,移动终端还可包括比图1中所示更多或者更少的组件,或者具有与图1所示不同的配置。
22.存储器104可用于存储计算机程序,例如,应用软件的软件程序以及模块,如本发明实施例中的一种资源调度方法对应的计算机程序,处理器102通过运行存储在存储器104内的计算机程序,从而执行各种功能应用以及数据处理,即实现上述的方法。存储器104可包括高速随机存储器,还可包括非易失性存储器,如一个或者多个磁性存储装置、闪存、或者其他非易失性固态存储器。在一些实例中,存储器104可进一步包括相对于处理器102远程设置的存储器,这些远程存储器可以通过网络连接至移动终端。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
23.传输装置106用于经由一个网络接收或者发送数据。上述的网络具体实例可包括
移动终端的通信供应商提供的无线网络。在一个实例中,传输装置106包括一个网络适配器(network interface controller,简称为nic),其可通过基站与其他网络设备相连从而可与互联网进行通讯。在一个实例中,传输装置106可以为射频(radio frequency,简称为rf)模块,其用于通过无线方式与互联网进行通讯。
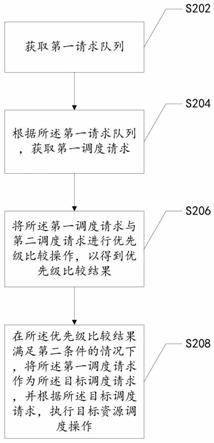
24.在本实施例中提供了一种资源调度方法,图2是根据本发明实施例的一种资源调度方法的流程图,如图2所示,该流程包括如下步骤:步骤s202,获取第一请求队列,其中,第一请求队列是根据预设的优先级算法以及来自请求对象的资源请求信息确定的;在本实施例中,获取已经排列好的资源请求信息是为了确定多任务场景下各个任务的优先级,从而保证高优先级的资源调度请求能够被及时处理,而避免出现多任务场景下资源调度不及时的问题。
25.其中,优先级算法可以(但不限于)是根据资源用量与系数的卷积递推得到的,还可以是通过其它方式得到的;优先级算法可以(但不限于)是多个算法的集合,也可以是单独的算法;请求对象可以(但不限于)是发送资源调度请求的对象,如任务管理器、任务处理单元等,资源请求信息包括(但不限于)请求对象的接口信息、ip地址、id信息、请求周期、请求内容、资源占用量、任务周期/时间等;对应的,第一请求队列可以(但不限于)是不同优先级的不同类型的请求对象的资源请求排列的队列,也可以是相同类型的请求对象的不同优先等级的资源请求队列,还可以是其它形式的队列,第一请求队列的数量可以(但不限于)是一个队,也可以是多个队列。
26.步骤s204,根据第一请求队列,获取第一调度请求,其中,第一调度请求为第一请求队列中初始优先级满足第一条件的初始资源调度请求;在本实施例中,获取第一调度请求是为了方便为优先级较高的请求对象调度资源,从而避免资源调度不及时的问题,提高提高资源调度效率。
27.其中,第一条件可以(但不限于)是优先级最高,也可以是优先级大于预设值,还可以是其它条件;第一调度请求可以是一个,也可以是多个;对应的,第一条件可以是一个,也可以是多个;第一调度请求的获取可以(但不限于)是对第一请求队列进行轮询获得的,也可以是通过获取预设位置的资源调度请求得到的。
28.例如,轮询第一请求队列,并将优先级最高的资源调度请求作为第一调度请求。
29.步骤s206,将第一调度请求与第二调度请求进行优先级比较操作,以得到优先级比较结果,其中,第二调度请求为预先存储的目标资源调度请求;在本实施例中,确定优先级比较结果是为了保证资源是响应于优先级最高的请求而被调度的,避免资源被堵塞。
30.其中,第二调度请求可以是上一时序的第一请求队列中优先级最高的第一调度请求,也可以是根据需求预先输入的资源调度请求,还可以是其它类型的请求;第二调度请求的数量可以是一个,也可以是多个。
31.例如,将第一请求队列设置在等待序列中,并根据预先设置的执行序列中的资源调度请求调度相应的资源;其中,先将等待序列中的第一请求队列的最高优先级请求调入执行序列中,随后当接收到新的资源调度请求时,将新的资源调度请求加入第一请求队列中,并根据优先级对第一请求队列进行重新排列,以得到新的第一请求队列;再将位于等待
序列中的新的第一请求队列中的最高优先级的资源调度请求(即第三调度请求)与位于执行序列中的最高优先级的资源调度请求(即第四调度请求)进行比较级对比。
32.步骤s208,在优先级比较结果满足第二条件的情况下,将第一调度请求作为目标资源调度请求,并根据目标资源调度请求,执行目标资源调度操作。
33.在本实施例中,在确定优先级比较结果之后再进行资源调度是为了保证资源调度的准确性。
34.其中,第二条件可以(但不限于)是第一调度请求的优先级高于第二调度请求,也可以是第二调度请求的优先级高于第一调度请求,还可以是第一调度请求的优先级与第二调度请求的优先级相同。
35.例如,当第三调度请求的优先级高于第四调度请求时,则将第三调度请求放入等待序列中,并按第四调度请求的内容调度相应的资源,否则按照第三调度请求的内容调度对应的资源。
36.需要说明的是,在进行优先级比较时,应将相同类型的资源调度请求进行比较,例如,或同一类型的请求对象调度同一资源所提出的请求,这是因为gpu类型不同的资源相互之间不阻塞,所以不会进行优先级的比较。
37.通过上述步骤,先对资源请求信息进行排列,随后将优先级较高的第一资源调度请求与目标资源调度请求再进行优先级比较,从而满足多任务场景的资源调度需求,同时,由于反复对任务的优先级进行比较,并实时对新的资源调度请求进行排序,因此能够灵活调用各类资源,避免系统资源被单个任务阻塞或过分占用的情况,解决了资源调度效率低的问题,提高了资源调度效率。
38.其中,上述步骤的执行主体可以为基站、终端等,但不限于此。
39.在一个可选的实施例中,优先级算法包括:式中,δt 为采样周期,t 为控制优先级趋近用量的速率,g(t)为当前资源的使用量。
40.在本实施例中,在计算当前资源用量的同时,还将任意时刻的变化速率进行考量,从而使优先级的计算更加准确。
41.例如,在进行优先级确定时,主要考虑以下几种情况:1、资源使用得越多,资源得分越高,从而导致优先级越低;2、既要考虑当前用量, 也要考虑历史用量;3、近期用量比远期用量对优先级的影响更大;4、不同类型资源分别计算分数和优先级;即,在任意时刻 t,优先级评分 s(t)不止反应当前资源用量g(t) 的值,还能受 τ《t 期间g(τ) 取值的影响,因此可以将g(τ) 取值对s(t) 的影响(即系数)记为 f(t),此时优先级评分是资源用量与系数的卷积,即为:
ꢀ………
(1)又因f(t) 应该满足以下条件:1)0≤f(t)≤1;
2)f(0)=c,c为一正常数;3)f( ∞)=0;4)当 g(t)为常函数g 时,;5)严格单调;6)同时,f(t)变化的速率应可调节;综合上述要求,选择方便计算的指数函数:
………
(2)再将卷积过程转换为差分形式:
………
(3)又,由于系数之和应满足:
………
(4)故:
………
(5)其中 δt 即为采样周期,t为调节时间,用于控制评分趋近用量的速率, g(t)为当前资源的使用量;其中,根据上式,令 t=10,δt= =1, g(t)模拟实际生产中 gpu 用量的变化,则评分随资源用量s(t) 变化趋势如图3所示,其中,轴线刻度为10,每个刻度代表1t,由图3可知,在实际使用量发生变化之后,根据公式计算出的score在4t周期内追踪误差的结果,就如图3所示;可看到在每次 g(t)发生变动后,无论变动幅度大小,经 t后, s(t) 与g(t) 的误差 (追踪误差) 约为 37%;经 2t后,追踪误差约为 14%;经 4t后, 追踪误差约为 2%;这是因为公式(5)主要关注的是4个单位时间之内的历史用量,小于2%表示4个单位时间之前的历史用量对计算结果基本不产生影响,即任务在系统中的优先级取决于4个单位时间里的历史用量和当前用量的加权计算,因而可以忽略4个单位时间之前历史资源用量。
42.在一个可选的实施例中,获取第一请求队列包括:步骤s2022,获取初始资源调度请求,其中,初始资源调度请求包括发送初始资源调度请求的请求对象信息;步骤s2024,根据请求对象信息以及优先级算法,确定资源调度请求的初始优先级;步骤s2026,基于初始优先级,将资源调度请求加入初始请求队列,并对初始请求队列进行排序处理,以得到第一请求队列。
43.在本实施例中,先对初始资源调度请求进行排列是为了有序的调度资源,避免出现因请求过多造成的资源调度堵塞的问题,提高资源调度效率。
44.其中,请求对象信息包括请求对象的类型、ip地址、id、资源请求时间、资源需求类型、资源调度周期、资源调度数据量等信息。
45.需要说明的是,在得到第一请求队列之后,如果重新得到新的初始资源调度请求,则将新的初始资源调度请求加入至第一请求队列中,并进行新的排列,从而保证第一请求
队列始终保持有序状态。
46.例如,用户创建资源后,系统会在kubernetes中创建一个类型为atjob,并由atjob operator创建相关kubernetes资源,同时通知atuser operator更新atuser分数;随后调度器监听到有新建的pod资源,会把pod放入排序队列中进行优先级排序。
47.其中,pod是kubernetes系统中的最小调度单元,也是基础单元,其他的大多数资源对象都是用于支撑和扩展pod对象功能的,而pod的创建可以通过命令创建或者将pod资源定义为资源清单,再通过定义的清单被创建。atjob是一种kubernetes 自定义资源(crd),用以维护一个计算任务的各种信息,它包括所需要的各种计算机资源(gpu类型,gpu卡数,内存,cpu核数等),计算任务执行的状态,计算任务对应的kubernetes资源(pod,service,configmap)等;atjob operator用于负责维护atjob与kubernetes之间的关系,根据atjob的自动创建,更新,删除kubernetes 资源;atuser是一种kubernetes 自定义资源(crd),代表系统中每一个用户,维护了用户名称,优先级分数等信息;调度器(scheduler)是指用kubernetes sig社区提供的scheduling-framework实现的kuberntes自定义扩展调度器,主要包括排序队列(sort queue),等待队列(waiting queue),prefilter插件,premit插件,prebind插件等,用以在不同阶段实现对资源调度的计算。
48.在一个可选的实施例中,在将第一调度请求与第二调度请求进行优先级比较操作,以得到优先级比较结果之后,该方法还包括:步骤s2062,在优先级比较结果不满足第二条件的情况下,对第一调度请求进行时序等待操作;步骤s2064,在第一调度请求的等待时序大于目标时序的情况下,对第一调度请求进行回归操作,以将第一调度请求回归至第一请求队列。
49.在本实施例中,在比较结果不满足第二条件的情况下,先将第一调度请求放在等待时序中进行等待,以在前一个第一调度请求被操作后可以及时对等待时序中的第一调度请求进行操作,从而保证资源调度的效率;而在等待一定时序后仍未被操作,则说明前一个第一调度请求还未被处理,此时再将等待时序中的第一调度请求回归至第一请求队列中,从而避免该第一调度请求丢失。
50.其中,时序等待操作可以(但不限于)是将第一调度请求发送至等待序列中进行等待,并一直等待至目标时间,对应的,目标时序可以(但不限于)是第一调度请求再等待序列中等待的时序,目标时序可以是提前设置的,也可以是通过算法生成确定。
51.在一个可选的实施例中,该方法还包括:步骤s2010,获取请求对象的初始对象信息,其中,初始对象信息包括请求对象的初始资源占用信息以及初始评分信息;步骤s2012,根据优先级算法,对初始资源占用信息以及初始评分信息进行优先级评分计算,以得到目标优先级评分:步骤s2014,根据目标优先级评分,确定目标类型的请求对象的优先级。
52.在本实施例中,引入初始资源占用信息以及初始评分信息是为了精确计算优先级评分,从而提高优先级判断的准确性。
53.例如,由atuser operator基于评分计算公式,根据用户近一段时间的系统资源占用量,更新atuser分数,并把atuser的name作为label添加到atjob及所属的kubernetes资
源中。
54.其中,atuser operator用于负责维护atuser主动和定时更新atuser的资源分数。
55.在一个可选的实施例中,根据优先级算法,对初始资源占用信息以及初始评分信息进行优先级评分计算,以得到目标优先级评分包括以下方式之一:根据预设周期,通过优先级算法,对初始资源占用信息以及初始评分信息进行优先级评分计算,以得到目标优先级评分;获取系统运行时间;基于系统运行时间,确定目标周期;基于目标周期,通过优先级算法,对初始资源占用信息以及初始评分信息进行优先级评分计算,以得到目标优先级评分;对目标对象执行初始化操作,以得到初始对象信息,其中,初始对象信息包括请求对象的类型信息;根据所述类型信息以及优先级算法,确定请求对象的优先级权重;基于优先级权重以及类型信息,执行类型评分计算操作,以得到目标优先级评分。
56.在本实施例中,根据预设周期确定目标优先级评分是为了节约计算资源,同时方便用户进行实时调整;通过系统运行时间确定目标优先级评分是为了在重启等特殊情况下仍然保持正常运行;对目标对象执行初始化操作后再确定目标优先级评分是为了在系统第一次运行或面对有任务运行却无记录的新用户的情况下依然能够保持正常运行。
57.例如,可以先调节时间和采样周期可配置,例如暂定 4t=7d,δt=1;随后记录每个用户当前资源占用量 g 和当前分数 s,按 gpu 类型分别计算,再以 δt 为周期,以公式(5)更新所有用户的分数。
58.也可以在operator 重启时,视情况依递推公式(5)更新分数, 此时 δt 为与上次更新时间的差。
59.还可以是在operator 第一次运行时, 或对于有任务运行却无记录的新用户时,执行以下操作:1、对于每一个用户,初始化对象用户对象;2、对每一个在运行的任务,根据其用量,以任务已运行时间为 δt,计算单个任务在评分中的分量;3、将属于同一种资源的评分分量累加,即为该资源最终评分。
60.通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到根据上述实施例的方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质(如rom/ram、磁碟、光盘)中,包括若干指令用以使得一台终端设备(可以是手机,计算机,服务器,或者网络设备等)执行本发明各个实施例所述的方法。
61.在本实施例中还提供了一种资源调度装置,该装置用于实现上述实施例及优选实施方式,已经进行过说明的不再赘述。如以下所使用的,术语“模块”可以实现预定功能的软件和/或硬件的组合。尽管以下实施例所描述的装置较佳地以软件来实现,但是硬件,或者软件和硬件的组合的实现也是可能并被构想的。
62.图4是根据本发明实施例的一种资源调度装置的结构框图,如图4所示,该装置包括:
队列获取模块32,用于获取第一请求队列,其中,所述第一请求队列是根据预设的优先级算法以及来自请求对象的资源请求信息确定的;第一请求模块34,用于根据所述第一请求队列,获取第一调度请求,其中,所述第一调度请求为所述第一请求队列中初始优先级满足第一条件的所述初始资源调度请求;优先级比较模块36,用于将所述第一调度请求与第二调度请求进行优先级比较操作,以得到优先级比较结果,其中,所述第二调度请求为预先存储的目标资源调度请求;资源调度模块38,用于在所述优先级比较结果满足第二条件的情况下,将所述第一调度请求作为所述目标资源调度请求,并根据所述目标资源调度请求,执行目标资源调度操作。
63.在一个可选的实施例中,优先级算法包括:式中,δt 为采样周期,t 为控制优先级趋近用量的速率,g(t)为当前资源的使用量。
64.在一个可选的实施例中,队列获取模块32包括:初始请求采集单元322,用于获取初始资源调度请求,其中,初始资源调度请求包括发送初始资源调度请求的请求对象信息;初始优先级确定单元324,用于根据请求对象信息以及优先级算法,确定资源调度请求的初始优先级;排序单元326,用于基于初始优先级,将资源调度请求加入初始请求队列,并对初始请求队列进行排序处理,以得到第一请求队列。
65.在一个可选的实施例中,优先级比较模块36还包括:时序等待单元362,用于在所述将所述第一调度请求与第二调度请求进行优先级比较操作,以得到优先级比较结果之后,在所述优先级比较结果不满足第二条件的情况下,对所述第一调度请求进行时序等待操作;请求回归单元364,用于在所述第一调度请求的等待时序大于目标时序的情况下,对所述第一调度请求进行回归操作,以将所述第一调度请求回归至所述第一请求队列。
66.在一个可选的实施例中,该装置还包括:对象信息采集模块310,用于获取请求对象的初始对象信息,其中,初始对象信息包括请求对象的初始资源占用信息以及初始评分信息;评分模块312,用于根据优先级算法,对初始资源占用信息以及初始评分信息进行优先级评分计算,以得到目标优先级评分:优先级确定模块314,用于根据目标优先级评分,确定目标类型的请求对象的优先级。
67.在一个可选的实施例中,评分模块312包括以下单元至少之一:周期计算单元3122,用于根据预设周期,通过优先级算法,对初始资源占用信息以及初始评分信息进行优先级评分计算,以得到目标优先级评分;运行计算单元3124,用于获取系统运行时间;基于系统运行时间,确定目标周期;基于目标周期,通过优先级算法,对初始资源占用信息以及初始评分信息进行优先级评分计算,以得到目标优先级评分;
初始化计算单元3126,用于对目标对象执行初始化操作,以得到初始对象信息,其中,初始对象信息包括请求对象的类型信息;根据所述类型信息以及优先级算法,确定请求对象的优先级权重;基于优先级权重以及类型信息,执行类型评分计算操作,以得到目标优先级评分。
68.需要说明的是,上述各个模块是可以通过软件或硬件来实现的,对于后者,可以通过以下方式实现,但不限于此:上述模块均位于同一处理器中;或者,上述各个模块以任意组合的形式分别位于不同的处理器中。
69.下面通过具体实施例对本发明进行说明。
70.如图5所示,在本实施例中,主要包括atjob、atjob operator、atuser、atuser operator、调度器(scheduler)等模块,其中:atjob:一种kubernetes 自定义资源(crd),用以维护一个计算任务的各种信息,包括所需要的各种计算机资源(gpu类型,gpu卡数,内存,cpu核数等),计算任务执行的状态,计算任务对应的kubernetes资源(pod,service,configmap)等;atjob operator:负责维护atjob与kubernetes之间的关系,根据atjob的自动创建,更新,删除kubernetes 资源;atuser:一种kubernetes 自定义资源(crd),代表系统中每一个用户,维护了用户名称,优先级分数等信息;atuser operator:负责维护atuser主动和定时更新atuser的资源分数;调度器(scheduler):用kubernetes sig社区提供的scheduling-framework实现的kuberntes自定义扩展调度器,主要包括排序队列(sort queue),等待队列(waiting queue),prefilter插件,premit插件,prebind插件等,用以在不同阶段实现对资源调度的计算。
71.如图5所示,各个模块的流程配合如下:s51,用户创建计算任务并申请资源用户创建资源后,系统会在kubernetes中创建一个类型为atjob,并由atjob operator创建相关kubernetes资源,同时通知atuser operator更新atuser分数;s52,根据用户一段时间对内系统各种资源的申请的资源计算出用户优先级;由atuser operator基于评分计算公式,根据用户近一段时间的系统资源占用量,更新atuser分数,并把atuser的name作为label添加到atjob及所属的kubernetes资源中;s53,使用计算出的用户优先级参数作为任务调度的依据,放入优先级队列中排队;此时调度器监听到有新建的pod资源,会把pod放入排序队列中进行优先级排序。
72.其中,优先级排序过程包括:从pod的label中取出atuser的信息,根据labels中的atuser信息从kubernetes中获取atuser的资源分数,从队列中依次取出pod与当前pod比较对应的atuser资源分数,分数越高的pod,优先级越低,最终确定当前pod在优先级队列中的位置。
73.s54,从优先级队列中取出优先级最高的任务进入prefilter调度阶段;每次调度完成,就会从优先级队列中取出一个优先级最高的pod,进入调度器的prefilter插件,prefilter主要负责比较当前pod与等待队列中pod的优先级,若等待队列
中的pod优先级更高,则把当前pod拒绝,退回到排序队列中重新排序,若当前pod的优先级更高,pod进入permit阶段。
74.s55,permit阶段;permit阶段把pod与等待队列中所有的pod比较优先级,若当前的pod并不是最高的,则放入等待队列中,而等待队列中的等待一段时间,若发生超时,则把pod退回到排序队列中,当前pod的优先级高于等待队列中所有的pod,则说明当前pod是系统中优先级最高的pod,可以进行调度,进入bind阶段。
75.s56,bind阶段;bind阶段,调度计算现有的系统所有节点的剩余资源,寻找到匹配当前pod的节点,并调度pod到制定节点运行,若没有节点的资源符合要求,则pod则会处于阻塞状态,等待有符合资源的节点出现时,直接调度pod到指定节点运行。
76.本发明的实施例还提供了一种计算机可读存储介质,该计算机可读存储介质中存储有计算机程序,其中,该计算机程序被设置为运行时执行上述任一项方法实施例中的步骤。
77.在一个示例性实施例中,上述计算机可读存储介质可以包括但不限于:u盘、只读存储器(read-only memory,简称为rom)、随机存取存储器(random access memory,简称为ram)、移动硬盘、磁碟或者光盘等各种可以存储计算机程序的介质。
78.本发明的实施例还提供了一种电子装置,包括存储器和处理器,该存储器中存储有计算机程序,该处理器被设置为运行计算机程序以执行上述任一项方法实施例中的步骤。
79.在一个示例性实施例中,上述电子装置还可以包括传输设备以及输入输出设备,其中,该传输设备和上述处理器连接,该输入输出设备和上述处理器连接。
80.本实施例中的具体示例可以参考上述实施例及示例性实施方式中所描述的示例,本实施例在此不再赘述。
81.显然,本领域的技术人员应该明白,上述的本发明的各模块或各步骤可以用通用的计算装置来实现,它们可以集中在单个的计算装置上,或者分布在多个计算装置所组成的网络上,它们可以用计算装置可执行的程序代码来实现,从而,可以将它们存储在存储装置中由计算装置来执行,并且在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤,或者将它们分别制作成各个集成电路模块,或者将它们中的多个模块或步骤制作成单个集成电路模块来实现。这样,本发明不限制于任何特定的硬件和软件结合。
82.以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。