1.本发明属于数据处理领域,具体涉及一种基于数据安全性的多方投影方法及多方生产数据分析方法。
背景技术:
2.随着技术的发展和人们生活水平的提高,智能大数据技术已经广泛应用于人们的生产和生活当中。目前的数据一般都是高维度的数据,因此对于高维数据的处理就显得尤为重要。
3.高维数据投影方法是一种常用的数据分析方法。它将高维数据投影到低维空间中,从而支持数据分析者从低维投影结果中分析高维数据特征。在过去,数据分析者通常将多个数据提供方的数据集中在一台设备上,然后进行投影。然而,随着人们隐私保护意识的加强和隐私保护政策的出台,在数据提供方之间收集和分享数据变得愈发困难,尤其是具有敏感信息的数据。因此,如何在无需收集各方数据的前提下获得全局数据投影结果,成为了目前数据分析者普遍面临的困难;而该问题也被称为安全多方投影问题。
4.为了让投影结果能够真实反映高维数据分布,保持数据邻近关系是必要的。这为安全多方投影问题带来两个挑战:首先是如何让投影结果保持跨方数据邻近关系:保持跨方数据邻近关系指的是让分散各方的高维邻居数据被投影到低维邻近的位置上;其次是如何在数据非独立同分布的前提下保持数据邻近关系。在上述场景中,各方的数据通常是非独立同分布的,在该条件下,各方的投影结果容易产生重叠,从而破坏数据邻近关系。
5.传统的投影方法需要将数据集中在一起才能进行投影,这不符合数据保密性的要求。目前已有一些投影方法能够计算多方投影结果。基于同态加密方法的多方t-sne(t-distributed stochastic neighbor embedding,t分布随机邻居嵌入)联合投影方法smap(secure multi-party projection,安全多方投影),能够计算出与单方投影效果一致的联合投影;然而同态加密所增加的计算开销较大,导致该方法难以被运用到实践中。msdsne(multishot decentralized data stochastic neighbor embedding,多镜头分散数据随机邻居嵌入)投影方法基于共享的锚点数据在各数据方间进行联合t-sne投影;然而msdsne方法存在许多限制:首先,该方法需要共享额外数据集,不符合问题的要求;其次,该方法的投影效果具有高度随机性;最后,该方法将额外数据集作为锚点来近似保持跨方数据邻近关系,其保持能力受限于额外数据集规模。因此目前的方法都不能有效解决安全多方投影问题。
技术实现要素:
6.本发明的目的之一在于提供一种投影效果好、安全性高且效率较高的基于数据安全性的多方投影方法。
7.本发明的目的之二在于提供一种包括了所述基于数据安全性的多方投影方法的多方生产数据分析方法。
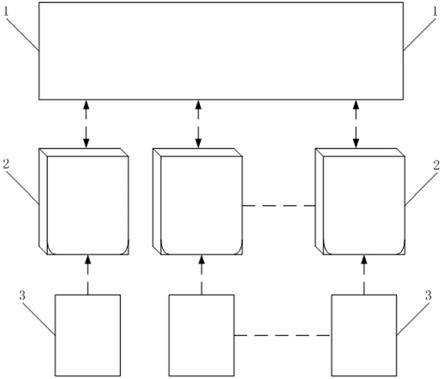
8.本发明提供的这种基于数据安全性的多方投影方法,包括如下步骤:s1. 获取服务器和客户端集合;s2. 服务器构建全局模型和初始的全局字典,并将全局模型和全局字典下发到各个客户端;s3. 各个客户端根据接收到的全局模型初始化各自当前的本地模型,并从接收到的全局字典中过滤得到他方字典;s4. 各个客户端根据步骤s3得到的本地模型和他方字典,训练得到各自的新的本地模型,并作为当前的本地模型;s5. 各个客户端用步骤s4得到的当前的本地模型对自身的本地数据进行投影得到投影结果,并将当前的本地模型和随机选择的部分投影结果上传到服务器;s6. 服务器根据接收到的本地模型和投影结果,聚合得到新的全局模型和新的全局字典,并将新的全局模型和新的全局字典下发到各个客户端;s7. 重复步骤s3~s6直至满足设定的条件,服务器得到最终的投影模型;s8. 服务器将步骤s7得到的最终的投影模型下发到各个客户端;s9. 各个客户端采用接收到的投影模型,对自身的本地数据进行投影,并将投影结果上传服务器;s10. 服务器将接收到的所有投影结果绘制到一张散点图上,完成种基于数据安全性的安全多方投影。
9.步骤s2所述的服务器构建全局模型和初始的全局字典,具体包括如下步骤:a. 服务器选择模型架构并生成模型参数,构建全局模型,并将全局模型下发到各个客户端;b. 各个客户端采用接收到的全局模型对各自的本地数据进行投影,得到各自的本地投影结果;c. 各个客户端在各自的本地投影结果中随机抽取一部分上传到服务器;d. 服务器根据接收到的投影结果构建初始的全局字典。
10.步骤s3所述的各个客户端根据接收到的全局模型初始化各自当前的本地模型,并从接收到的全局字典中过滤得到他方字典,具体包括如下步骤:a. 各个客户端根据接收到的全局模型的拓扑结构和参数,生成本地模型;b. 各个客户端根据自身的序号,在接收到的全局字典中选定自身投影数据所在的区间,并将区间外的数据构建为他方字典。
11.步骤s4所述的各个客户端根据步骤s3得到的本地模型和他方字典,训练得到各自的新的本地模型,并作为当前的本地模型,具体包括如下步骤:(1)客户端获取本地数据的领域图,并计算得到加权图;(2)根据步骤(1)中得到的加权图中边的权值的大小采样数据对,并生成训练数据集;(3)采用步骤s3得到的本地模型对训练数据集中的每一个数据对进行投影,从而得到投影对;(4)对步骤(3)中得到的每一个投影对,随机采样n个高维向量并设定为非邻居向量,从而计算n个高维向量的投影结果;
(5)重复步骤(3)~步骤(4)直至达到设定的条件,并在重复过程中采用交叉熵损失函数优化本地模型的参数;(6)得到最终优化后的新的本地模型,并作为当前的本地模型。
12.步骤(5)所述的交叉熵损失函数,具体为采用如下交叉熵损失函数:式中loss(x,y,d)为交叉熵损失函数;x为高维数据;y为投影结果;d为他方投影字典;为超参数,用于控制排斥力度;r(y,d)为实现他方排斥策略的损失项,用于在本方投影结果与他方投影结果之间引入排斥力,且,为y中第i个元素与d中第k个元素之间的低维相似度且,a和b为umap(uniform manifold approximation and projection,均匀流形近似与投影)算法在计算低维相似度时的参数,优选为a=1.93,b=0.79,yi为y中第i个元素,dk为d中第k个元素;ce(x,y)为数据对的投影分布和高维分布之间的差异,且,为采用umap算法计算高维数据x中第i个元素和第j个元素之间的相似度函数;为采用umap算法计算低维数据y中第i个元素和第j个元素之间的相似度函数;log为取e为底数的对数操作。
13.步骤s5所述的各个客户端用步骤s4得到的当前的本地模型对自身的本地数据进行投影得到投影结果,并将当前的本地模型和随机选择的部分投影结果上传到服务器,具体为各个客户端用步骤s4得到的当前的本地模型对自身的本地数据进行投影得到投影结果,并根据投影结果的长度随机抽取定长且不重复的投影结果,并连同当前的本地模型一同上传服务器。
14.步骤s6所述的服务器根据接收到的本地模型和投影结果,聚合得到新的全局模型和新的全局字典,并将新的全局模型和新的全局字典下发到各个客户端,具体包括如下步骤:1)服务器接收各个客户端上传的本地模型和投影结果;2)服务器根据步骤1)接收到的各个客户端的本地模型,采用联邦平均算法对本地模型进行聚合,从而得到新的全局模型;3)服务器将步骤1)接收到的各个客户端的投影结果,按照客户端的编号顺序结合,从而得到新的全局字典。
15.步骤2)所述的采用联邦平均算法对本地模型进行聚合,具体为采用如下算式进行聚合:式中f(w)为聚合模型的参数;nk为第k个客户端所拥有的数据量;n为总数据量;为第k个本地模型的参数;k为客户端数量。
16.本发明还提供了一种包括上述基于数据安全性的多方投影方法的多方生产数据
分析方法,包括如下步骤:sa. 以企业总部服务器作为上述的基于数据安全性的多方投影方法中的服务器,以企业各个工厂的数据中心作为上述的基于数据安全性的多方投影方法中的客户端;sb. 企业各个工厂的数据中心和企业总部服务器,采用上述的基于数据安全性的多方投影方法进行投影;sc. 企业总部服务器将接收到的所有投影结果绘制到一张散点图上,完成种基于数据安全性的安全多方投影;sd. 企业总部人员根据步骤sc得到的散点图,进行多方生产数据的分析。
17.本发明提供的这种基于数据安全性的多方投影方法及多方生产数据分析方法,创新性地将联邦学习框架与深度降维方法结合起来,能够保持跨方数据邻近关系,为安全多方投影问题提供新的解决方法;而且本发明提出了数据非独立同分布条件下保持数据邻近关系的新技术,有效解决了数据非独立同分布条件下投影重叠问题;因此本发明方法的投影效果好、安全性高且效率较高。
附图说明
18.图1为本发明投影方法的方法流程示意图。
19.图2为iid(independent and identically distributed,独立同分布)条件下本发明方法与现有的msdsne方法的性能对比示意图。
20.图3为noniid(non-independent and identically distributed,非独立同分布)条件下他方排斥策略的有效性定量验证示意图。
21.图4为noniid条件下small_fashion数据集上客户端数量为2时他方投影排斥策略的有效性定性验证示意图。
22.图5为本发明的分析方法的方法流程示意图。
具体实施方式
23.如图1所示为本发明方法的方法流程示意图:本发明提供的这种基于数据安全性的多方投影方法,包括如下步骤:s1. 获取服务器和客户端集合;s2. 服务器构建全局模型和初始的全局字典,并将全局模型和全局字典下发到各个客户端;具体包括如下步骤:a. 服务器选择模型架构并生成模型参数,构建全局模型,并将全局模型下发到各个客户端;b. 各个客户端采用接收到的全局模型对各自的本地数据进行投影,得到各自的本地投影结果;c. 各个客户端在各自的本地投影结果中随机抽取一部分上传到服务器;d. 服务器根据接收到的投影结果构建初始的全局字典;s3. 各个客户端根据接收到的全局模型初始化各自当前的本地模型,并从接收到的全局字典中过滤得到他方字典;具体包括如下步骤:a. 各个客户端根据接收到的全局模型的拓扑结构和参数,生成本地模型;
b. 各个客户端根据自身的序号,在接收到的全局字典中选定自身投影数据所在的区间,并将区间外的数据构建为他方字典;s4. 各个客户端根据步骤s3得到的本地模型和他方字典,训练得到各自的新的本地模型,并作为当前的本地模型;具体包括如下步骤:(1)客户端获取本地数据的领域图,并计算得到加权图;(2)根据步骤(1)中得到的加权图中边的权值的大小采样数据对,并生成训练数据集;(3)采用步骤s3得到的本地模型对训练数据集中的每一个数据对进行投影,从而得到投影对;(4)对步骤(3)中得到的每一个投影对,随机采样n个高维向量并设定为非邻居向量,从而计算n个高维向量的投影结果;(5)重复步骤(3)~步骤(4)直至达到设定的条件,并在重复过程中采用交叉熵损失函数优化本地模型的参数;具体实施时,采用如下交叉熵损失函数:式中loss(x,y,d)为交叉熵损失函数;x为高维数据;y为投影结果;d为他方投影字典;为超参数,用于控制排斥力度;r(y,d)为实现他方排斥策略的损失项,用于在本方投影结果与他方投影结果之间引入排斥力,且,为y中第i个元素与d中第k个元素之间的低维相似度且,a和b为umap算法在计算低维相似度时的参数,优选为a=1.93,b=0.79,yi为y中第i个元素,dk为d中第k个元素;ce(x,y)为数据对的投影分布和高维分布之间的差异,且,为采用umap算法计算高维数据x中第i个元素和第j个元素之间的相似度函数;为采用umap算法计算低维数据y中第i个元素和第j个元素之间的相似度函数;log为取e为底数的对数操作;(6)得到最终优化后的新的本地模型,并作为当前的本地模型;s5. 各个客户端用步骤s4得到的当前的本地模型对自身的本地数据进行投影得到投影结果,并将当前的本地模型和随机选择的部分投影结果上传到服务器;具体为各个客户端用步骤s4得到的当前的本地模型对自身的本地数据进行投影得到投影结果,并根据投影结果的长度随机抽取定长且不重复的投影结果,并连同当前的本地模型一同上传服务器;s6. 服务器根据接收到的本地模型和投影结果,聚合得到新的全局模型和新的全局字典,并将新的全局模型和新的全局字典下发到各个客户端;具体包括如下步骤:1)服务器接收各个客户端上传的本地模型和投影结果;2)服务器根据步骤1)接收到的各个客户端的本地模型,采用联邦平均算法对本地模型进行聚合,从而得到新的全局模型;具体为采用如下算式进行聚合:
式中f(w)为聚合模型的参数;nk为第k个客户端所拥有的数据量;n为总数据量;为第k个本地模型的参数;k为客户端数量;3)服务器将步骤1)接收到的各个客户端的投影结果,按照客户端的编号顺序结合,从而得到新的全局字典;s7. 重复步骤s3~s6直至满足设定的条件,服务器得到最终的投影模型;s8. 服务器将步骤s7得到的最终的投影模型下发到各个客户端;s9. 各个客户端采用接收到的投影模型,对自身的本地数据进行投影,并将投影结果上传服务器;s10. 服务器将接收到的所有投影结果绘制到一张散点图上,完成种基于数据安全性的安全多方投影。
24.图2为iid条件下本发明方法与现有的msdsne方法的性能对比示意图。
25.在iid条件下对比本发明方法与现有的msdsne方法的性能,如图2所示。左图(图2(a))是mnist_test数据集实验结果,右图(图2(b))是small_fashion数据集实验结果。其中umap和pumap(parametric uniform manifold approximation and projection,参数化均匀流形近似与投影)都是集中投影方法,在该实验中作对照。fp是本发明方法。msdsne方法为背景技术中提及的现有技术,括号中的百分比数字表示msdsne方法中共享数据的规模。图2中,采用knn(k-nearest neighbors,k最邻近)分类准确度和邻域保持程度作为指标,来进行性能的对比。从图中可以看出,本发明方法在knn分类准确度和邻域保持程度上大幅优于现有的msdsne方法。
26.图3为noniid条件下他方投影排斥策略的有效性定量验证示意图。
27.在noniid条件下定量评估他方排斥策略的有效性,如图3所示。左图(图3(a))是mnist_test数据集实验结果,右图(图3(b))是small_fashion数据集实验结果。其中lr表示label_ratio指标,用于表示knn分类准确度;ir表示indice_ratio指标,用于表示邻域保持程度。fp是不使用他方排斥策略的本发明方法(即在损失函数中设置)。fp(r)是使用他方排斥策略的本发明方法(即在损失函数中设置)。msdsne方法用来做对照。因此,图3中的6条折线,对应关系分别为:折线1为msdsne方法的lr指标;折线2为不使用他方排斥策略的本发明方法的lr指标;折线3为使用他方排斥策略的本发明方法的lr指标;折线4为msdsne方法的ir指标;折线5为不使用他方排斥策略的本发明方法的ir指标;折线6为使用他方排斥策略的本发明方法的ir指标。在图3中,折线3高于折线2,说明在knn分类准确度上他方排斥策略对解决投影重叠问题的有效性。折线6高于折线5,说明解决投影重叠问题后,邻域保持程度保持得更好了。
28.图4为noniid条件下small_fashion数据集上客户端数量为2时他方投影排斥策略的有效性定性验证示意图。
29.定性评估noniid条件下small_fashion数据集上客户端数量为2时他方投影排斥策略的有效性。如图4所示。图4(a)显示了集中投影方法pumap的投影结果,用于做对照,该
方法的lr(label_ratio)指标结果为98.2%,ir(indice_ratio)指标结果为22.3%。在4(b)图中不使用他方排斥策略的本发明方法出现了投影重叠问题,该方法的lr(label_ratio)指标结果为76.8%,ir(indice_ratio)指标结果为17.5%。而在4(c)图中,使用他方排斥策略的本发明方法解决了投影重叠问题,该方法的lr(label_ratio)指标结果为100%,ir(indice_ratio)指标结果为22.5%;这说明了他方排斥策略在解决投影重叠问题的有效性。图4(d)显示了msdsne方法的投影结果,可以看出存在严重的投影重叠问题,该方法的lr(label_ratio)指标结果为78.6%,ir(indice_ratio)指标结果为1.6%。这表明msdsne方法在noniid条件下无法解决投影重叠问题。
30.本发明方法(简称fp)和现有技术smap方法的区别:1. 在smap方法中,各个数据方需要将加密数据传输到两个中心服务器,然后两个中心服务器通过协作计算投影结果。而在本发明方法(fp方法)中,数据既不需要加密,也不需要离开数据方本地,仅将模型参数以及投影结果传输到中心服务器。相比而言,smap方法仍存在加密数据被破解的风险。如果它的两个中心服务器串通,加密数据可能被破解。而本发明方法(fp方法)则没有原始数据被破解的风险。虽然目前存在通过模型参数推测原始数据的方法,但这些方法的约束较多,并且推测效果不佳。
31.本发明方法(简称fp)和现有技术msdsne方法的区别:1. msdsne方法需要在数据方间共享额外数据集,本发明方法(fp方法)不需要共享额外数据集;而且共享数据集也不符合目前的数据隐私保护政策;2. 本发明方法(fp方法)的投影效果优于msdsne方法:首先,在数据iid条件下,无论是类别分离程度指标还是邻近关系保持程度指标都优于msdsne方法;其次,在数据noniid条件下,使用他方投影排斥策略的本发明方法(简称fp)能够缓解投影重叠问题,使得上述两个指标得到提升。
32.如图5所示为本发明的分析方法的方法流程示意图:本发明还提供了一种包括上述基于数据安全性的多方投影方法的多方生产数据分析方法,包括如下步骤:sa. 以企业总部服务器作为上述的基于数据安全性的多方投影方法中的服务器,以企业各个工厂的数据中心作为上述的基于数据安全性的多方投影方法中的客户端;sb. 企业各个工厂的数据中心和企业总部服务器,采用上述的基于数据安全性的多方投影方法进行投影;sc. 企业总部服务器将接收到的所有投影结果绘制到一张散点图上,完成种基于数据安全性的安全多方投影;sd. 企业总部人员根据步骤sc得到的散点图,进行多方生产数据的分析。
33.比如,上述的多方生产数据分析方法,可以用于企业的异常生产数据分析;更为详细的说,比如某汽车生产企业的总部在a地,在全国各地设置了若干个汽车生产厂,各个汽车生产厂均各自独立运行且均为该汽车生产企业生产型号为b的汽车;那么,若该汽车生产企业的总部研究人员需要对该b型号汽车的生产过程中的异常数据进行分析,从而优化生产流程,那么该汽车生产企业总部就需要能够获取各个各个汽车生产厂的生产过程数据。
34.以往,传统的方法是将各个生产厂的生产数据集中起来到总部进行分析。然而生产数据可能在数据传输过程中被黑客攻击获取,而泄露产品生产数据可能会对该公司造成极其重大的危害。那么,该汽车生产企业的总部和各个生产工厂就可以采用本发明提供的
这种多方生产数据分析方法,将汽车生产企业的总部的服务器作为服务器,将各个生产厂的数据中心作为客户端,服务器和客户端一同运行本发明提供的基于数据安全性的多方投影方法,从而使得总部在保证数据安全的前提下获取各个生产厂的数据投影结果,并将结果绘制到一张散点图上;然后,总数研究人员再根据得到的散点图,即可实现多方生产数据的分析,即实现各个生产厂的生产过程中的异常数据的分析。
35.本发明提供的这种基于数据安全性的多方投影方法,还能够具体应用于互联网产业和工业物联网产业。
36.在互联网产业中,如果某互联网公司想要分析用户的手机浏览行为模式,但是用户的手机浏览行为信息是隐私数据,是不能离开用户的手机的。因此该互联网公司则可以使用本发明方法。在该应用场景中,本发明的服务器即为该互联网公司的公司服务器,用户的手机即为客户端。多个用户基于本地的手机浏览行为信息在该互联网公司服务器的帮助下协同训练投影模型。最终该互联网公司可以得到用户的手机浏览行为投影结果。在投影结果中,该互联网公司可以根据投影中的聚类情况分析用户的浏览行为模式。
37.针对工业物联网场景,工业物联网以极大的速度向产业链传输海量工业数据,使得基于数据驱动的机器学习方法广泛应用于工业制造中。然而在工业领域,企业间出于竞争或用户隐私原因而无法将数据资源共享。例如,某制造业公司想要分析某个产品的生产数据。传统的方法是将多地工厂的生产数据集中起来做分析。然而产品生产数据可能在数据传输过程中被黑客攻击获取。泄露产品生产数据可能会对公司的产品营销策略造成重大危害。因此如何在保护企业产品生产数据隐私的前提下进行数据分析十分重要。在该场景中,本发明的服务器即为公司总部的服务器,各地工厂数据存储中心即为客户端。多个工厂数据存储中心在总部服务器的帮助下协同训练投影模型。最终总部可以获得各地工厂的产品生产数据投影结果。在投影结果中,公司可以根据投影结果中的异常数据分析各地工厂产品生产过程存在的问题。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。