1.本公开总体涉及电子学的领域。更具体而言,一些实施例涉及用于缓解前端分支重引导(branch resteer)的分支预取(branch prefetch)机制的技术。
背景技术:
2.为了提高性能,一些处理器利用推测性处理(有时也被称为无序(out-of-order,ooo)处理器),这种处理尝试预测正在执行的程序的未来进程,以例如通过采用并行性来加快其执行。预测最终可能正确,也可能不正确。当预测正确时,程序的执行时间可能比采用非推测性处理时更短。然而,当预测不正确时,处理器必须重引导分支操作,并且将其状态恢复到误预测之前的点,这就造成了效率低下。
3.此外,尽管最近在微处理器设计方面取得了进展,但即使在多核心时代,实现很高的单线程性能仍然是一个重大挑战。对于新兴的数据中心和云应用,大量的处理器周期(约30%)在处理器的前端引擎中损失,其中很大一部分(约35%)可能是由分支重引导引起的。
技术实现要素:
4.根据本公开的一个方面,提供了一种装置,包括:预解码电路,用于对缓存中的条目进行预解码以生成预解码的分支操作,所述条目与冷分支操作相关联,其中所述冷分支操作对应于在存储在指令缓存中之后第一次检测到的操作,并且其中所述冷分支操作由于其被存储在缓存行中的如下位置而保持未解码:该位置在所述缓存行中的分支操作的后续位置之前;以及分支预取缓冲器(bpb),用于响应于所述冷分支操作在指令缓存中的缓存行填充操作而存储所述预解码的分支操作。
5.根据本公开的另一方面,提供了一种系统,包括:存储器,用于存储一个或多个指令;具有一个或多个核心的处理器,用于执行所述一个或多个指令;预解码电路,用于对缓存中的条目进行预解码以生成预解码的分支操作,所述条目与冷分支操作相关联,其中所述冷分支操作对应于在存储在指令缓存中之后第一次检测到的操作,并且其中所述冷分支操作由于其被存储在缓存行中的如下位置而保持未解码:该位置在该缓存行中的分支操作的后续位置之前;以及分支预取缓冲器(bpb),用于响应于所述冷分支操作在指令缓存中的缓存行填充操作而存储所述预解码的分支操作。
附图说明
6.为了使得本文记载的这些实施例的特征可被详细理解,通过参考实施例可进行对实施例的更具体描述,实施例中的一些在附图中图示。然而,要注意,附图只是图示了典型实施例并且因此不应被认为是限制其范围。
7.图1根据一实施例图示了缓存行中的分支操作的阴影call(shadow call)。
8.图2根据一实施例图示了检测分支预取缓冲器的使用的微基准的样本伪代码。
9.图3根据一实施例图示了可被用于实现具有分支预取缓冲器的分支预测单元的处
理器的各种组件的框图。
10.图4根据一实施例图示了两阶段预解码算法的样本数据。
11.图5根据一实施例图示了反向字节标记算法的样本伪代码。
12.图6和图7根据一些实施例图示了用于比较不同的分支预取缓冲器分配/大小和替换策略的数据样本图。
13.图8a是根据实施例图示出示范性有序管线和示范性寄存器重命名、无序发出/执行管线两者的框图。
14.图8b是根据实施例图示出要被包括在处理器中的有序体系结构核心的示范性实施例和示范性寄存器重命名、无序发出/执行体系结构核心两者的框图。
15.图9图示了根据一实施例的soc(片上系统)封装的框图。
16.图10是根据一实施例的处理系统的框图。
17.图11是根据一些实施例的具有一个或多个处理器核心的处理器的实施例的框图。
18.图12是根据一实施例的图形处理器的框图。
具体实施方式
19.在以下描述中,阐述了许多具体细节以提供对各种实施例的透彻理解。然而,没有这些具体细节也可以实现各种实施例。在其他情况下,没有详细描述公知的方法、过程、组件和电路,以免模糊特定实施例。另外,可使用各种手段来执行实施例的各种方面,例如集成半导体电路(“硬件”),被组织成一个或多个程序的计算机可读指令(“软件”),或者硬件和软件的某种组合。对于本公开而言,提及“逻辑”应指硬件、软件、固件或者其某种组合。
20.如上所述,即使在多核心时代,实现很高的单线程性能仍然是一个重大挑战。对于新兴的数据中心和云应用,大量的处理器周期(约30%)在处理器的前端引擎中损失,其中很大一部分(约35%)可能是由分支重引导引起的。正如本文所论述的,“分支重引导”一般是指将管线重新导向正确的路径,这可能是由于分支误预测引起的。更具体而言,分支预测器根据其预测来指导处理器管线走向某个控制流路径。在管线的后期,存在检查以确保预测是正确的。如果预测不正确,则进行检查之处的上游管线需要被冲刷,然后被重引导到正确的控制流路径。对于上述的新兴应用,主要的挑战在于其大的代码足迹和相关联的大量跳转目标,这些大量跳转目标很容易具有数百万个分支,远远超过当前的分支目标缓冲器(branch target buffer,btb)的大小,而btb只能容纳几千个跳转目标。有可能增大btb的大小,以及添加btb的层次体系,并且从较高级别的btb预取到较低级别的btb。虽然可以增大btb的大小/层次体系来扩展跳转目标,但更大的/扩展的btb会产生其他效率低下问题,例如制造成本、增大足迹和/或与搜索更大的btb相关联的延迟。
21.为此,一些实施例提供了用于缓解前端分支重引导的分支预取机制的技术。更具体而言,一个或多个实施例为具有预解码比特的处理器提供了一种后向解码逻辑/机制。另一实施例利用预解码比特来对字节进行预解码,以便找到插入到btb中的分支,从而避免不必要的重引导。一般而言,分支预测器单元/逻辑位于处理器管线的前端,并且只有指令地址要处理(即,它还没有指令,因为那些指令只有在指令字节被取得和解码之后才会被下游知道)。分支目标缓冲器(或者说“btb”)是一个缓存,当用指令地址来查询该缓存时,它将返回该地址是否有与之相关联的分支。此外,它还可返回分支预测器单元进行其工作所需要
的关于该分支的其他信息,例如分支类型(例如,call、return或者jump)和预测将采取的该分支的目标。btb可被添加到处理器的前端(例如,图8b的前端830)以协助分支预测操作。
22.此外,有相当一部分的分支重引导可能是由于“冷”call和return引起的,即,第一次看到的call或return,并且这种call或return命中了指令缓存(instruction cache,ic),但还没有被解码,因为它们位于在缓存行中间跳转的分支的阴影中。为此,在一实施例中,这些“冷”分支在指令缓存填充发生之前被预解码,然后预解码的分支操作被插入到分支预取缓冲器(branch prefetch buffer,bpb)中。在一些实施例中,可与btb访问并行地查找bpb。在一个实施例中,在btb未命中时,可由bpb来服务请求。在一实施例中,在bpb命中时,该条目被提升到btb中。因此,在一些实施例中,btb和bpb都可被并行访问,以发现在特定的地址是否存在分支。如果在bpb中有命中,但在btb中未命中,那么该分支就被从bpb移动到btb中。分支首先被添加在bpb中,因为它避免了不正确的预取对btb的污染。一旦在bpb中对于给定的地址发生命中,就表明预取是正确的,并且它可被移动到btb。这为bpb腾出了更多的空间,而bpb要比btb小得多。
23.如前所述,分支重引导主要是由冷分支引起的,并且在各种应用中主导着前端的停滞。为此,一些实施例在不增大btb大小的情况下,通过为关联的逻辑和/或bpb引入可忽略的硬件资产,大大缓解了其影响。
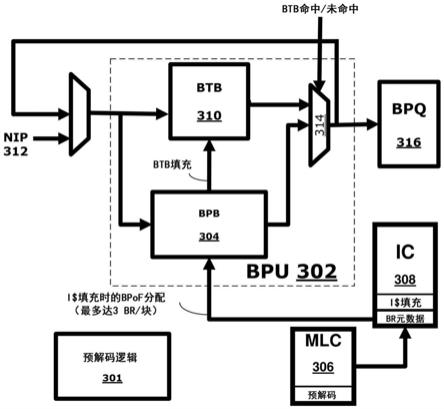
24.另外,一些实施例可被应用于包括一个或多个处理器的计算系统中(例如,其中一个或多个处理器可包括一个或多个处理器核心),例如参考图1及其后各图论述的那些,包括例如桌面型计算机、工作站、计算机服务器、服务器刀片、或者移动计算设备。移动计算设备可包括智能电话、平板设备、umpc(超便携个人计算机)、膝上型计算机、ultrabook
tm
计算设备、可穿戴设备(例如,智能手表、智能戒指、智能手镯、或者智能眼镜),等等。
25.图1根据一实施例图示了缓存行中的分支操作的阴影call。在没有本文论述的实施例的情况下,在缓存行的中间跳转的分支的阴影中的call或者return一般被预期会在其第一次被访问时未命中btb。这种阴影分支未命中btb的原因是,它们在第一次取得该行时还没有被解码,因为解码是从该行的入口lip的第一个字节(即,分支的目标,参见图1)开始向前进行的(其中“lip”指的是线性指令指针或者在此更概括地被称为“地址”)。另一方面,如果这些call或者return要命中btb,那就意味着它们已经被预解码并且在其第一次访问之前被插入到了btb中。虽然这里的一个主要焦点可能是在call和return(因为它们导致了最多的重引导),但实施例并不限于这些,而是也可以按相同的方式识别其他分支类型。
26.插入到btb中很可能是经由像bpb这样的中转缓冲器发生的,bpb在一些实施例中充当过滤器,因为直接插入到btb中会大大污染它。正如本文所论述的,污染btb是指这样的情形:在预取的一些情况中,预取可能实际上是不需要的,而如果不必要预取的数据被直接插入到btb中,那么它将使另一个实际上需要的条目受害。为了测试这种情况,一实施例涉及编写一个微基准,其中在同一缓存行上的另一个分支的阴影中有一系列的分支(call/return),如图2所示。
27.更具体而言,图2根据一实施例图示了检测bpb的使用的微基准的样本伪代码。该示例假设fun1和fun2中的分支在同一缓存行上,fun3和fun4中的分支也是如此,等等(例如,成对的)。在一实施例中,当fun1(以及分别是fun3等等)执行时,不预期阴影中的分支会导致重引导,因为它们会被提早带入。如果没有本文论述的实施例,这些分支将导致重引
导。
28.当在最终产品上执行这个微基准时,当在btb中引用了fun2(以及分别是fun4等等)中的每个分支之后,该微基准将开始引用fun1(以及分别是fun3等等)中的阴影分支。如果没有本文论述的实施例,每个独特的静态阴影分支都会导致重引导。但有了它,则只对于fun2(以及分别是fun4等等)中的系列分支中的静态分支看到重引导。在各种实现方式中可以很容易地利用(一个或多个)性能计数器来测量在这种情况下的分支重引导的数目。
29.图3根据一实施例图示了可被用于实现具有分支预取缓冲器(bpb)304的分支预测单元(bpu)302的处理器的各种组件的框图。至少一个实施例提供了一种新颖的机制,该机制减少了前端分支重引导的数目,这些前端分支重引导可能主要是由冷call和/或return引起的。然而,实施例并不限于冷call和/或return,而重引导可由其他操作引起。
30.如图3所示,在中间级缓存306(“mlc”,有时也可称为l2或者第2级缓存)中应用预解码算法/逻辑301,从缓存行中提取冷分支。在各种实施例中,预解码逻辑301可执行与预解码和/或bpb的更新等等相关联的一个或多个操作,例如参考图3论述的用于分支预取以缓解前端分支重引导的操作。在各种实施例中,预解码逻辑301可被实现为专用逻辑或者实现为处理器/核心的现有组件的一部分,例如图8b的分支预测逻辑832和/或处理器组件,例如执行单元,等等。当指令缓存(ic)308中发生缓存行(i$)填充时,这些分支随后被预取到bpb 304中。这种策略在此可被称为填充时分支预取(branch-prefetch-on-fill,bpof),它利用了(例如,相对较小的)缓存,这个缓存被称为分支预取缓冲器(bpb)304。在一实施例中,bpb和分支目标缓冲器(btb)310两者被并行查找。在btb未命中时,可由bpb来服务该请求。在bpb命中时,相应的bpb条目可被提升到btb中。
31.参考图3,当接收到新指令指针(new instruction pointer,nip)312(例如,与分支操作相关联)时,在bpb 304和分支目标缓冲器(btb,有时可称为目标地址(target address,ta)缓冲器)310两者中进行检查(例如,并行检查),并且将结果馈送到多路复用器314,该多路复用器314受btb命中/未命中信号控制以向分支预测队列(branch prediction queue,bpq)316提供输出。
32.此外,当控制流改变到新的行时(例如,由于分支而改变),解码则从入口地址的第一字节(即分支的目标)继续前进。如果入口地址的第一字节不在行的开头,则入口地址的阴影中的分支就不会被解码,并且在第一次查找时将未命中btb。平均而言,大约60%的分支重引导似乎属于这一类。在这些阴影分支在btb中的第一次访问之前取回这些阴影分支的一种方式是也要对字节向后解码(如图1所示),从紧挨在入口地址的第一字节之前的字节开始。这可针对导致分支未命中的指令(miss-causing instruction,bmi,即,预测的已采取的分支,其目标未命中指令缓存308)来进行,因为这将提供足够的时间对这些分支进行预解码,并且在其第一次访问之前将其插入到bpb中。
33.相比之下,其他技术可进行前向预解码,即,一旦知道入口点,就尝试对缓存行中的所有剩余字节进行预解码。然而,一些实施例按相反的方向对字节执行预解码,即从入口点到缓存行的开始(参见例如图1,并且如本文进一步论述,例如,参考图3和/或4)。
34.另外,图3的各种组件可与图8b的一个或多个名称相同/相似的组件相同或者相似,例如分支预测逻辑832、前端830、l2缓存876、指令缓存834,等等。此外,在一实施例中,图8b的核心890可被修改以包含bpb。
35.图4根据一实施例图示了两阶段预解码算法的样本数据。如图所示,预解码算法按两阶段进行:指令长度计算阶段和反向字段标记阶段。指令长度计算将计算字节流中的每个潜在指令的以字节为单位的长度,假设每个字节可能是新指令的开始。这个阶段可能类似于一些传统的指令集体系结构(instruction set architecture,isa)管线中的指令长度解码(instruction length decode,ild)算法。在前向字节标记中,预先知道解码开始于何处(入口地址的第一字节)并且从指令长度计算阶段收集的信息被用来揭示所有剩余指令。与之不同,对于反向字节标记阶段,知道解码结束于何处(入口地址的第一字节之前的最后一个字节),并且从指令长度计算阶段收集的信息被用来暴露所有可能的后向指令链中的阴影分支。
36.指令长度计算假定在入口地址的第一字节之前的每个字节都有可能是指令的开始,并且相应地计算其长度。长度计算的结果是lengthis向量,如图4所示的示例中所示。
37.反向字节标记产生比特向量,brstart,其指示出阴影分支的第一字节。与lengthis向量一起,brstart也识别了阴影分支的最后一个字节。知道了阴影分支的第一个字节和最后一个字节,就可以提取阴影分支的操作码和目标来插入到bpb中。虽然在一些实施例中,一个主要的重点可能在于call和return,但也可按相同的方式识别其他分支类型。此外,一些实施例将所有的指令字节分割成不同的指令。图4示出了只标记入口地址之前的第一条冷指令的第一字节。但是还有其他的方式可以用来对字节进行标记,以把它们分割成不同的指令。例如,在图中,可以用“1”标记字节9-13。如果在这些字节之前有另一条指令,则可以用“2”来标记它们,等等依此类推。因此,一个目标是识别出如何将字节分割成指令。另外,即使在图4中只有一条指令被标记,但在它之前也可能有另一条1字节的指令,从字节8开始,因为lengthis计算说有一条1字节的指令从字节8开始,其于是将与图中标记的指令相接。或者,也有可能是一条从字节7开始的2字节指令。或者还有一种情况是,可能有一条从字节6开始的3字节指令。因此,通过反向解码,可以有多个可能的序列可工作,而逻辑将需要挑选序列。
38.图5根据一实施例图示了反向字节标记算法的样本伪代码。这个算法的一个目标是暴露在该行的入口地址之前的所有潜在的指令链,例如参考图4所提到的。这是通过寻找紧挨在入口地址之前的链中的第一条指令来实现的。如果这样的指令存在,则其长度(由lengthis向量给出)与入口地址相距“n”个字节。然后验证该指令是call还是return,并且对应的brstart比特被相应地设置。假设先前发现的指令是新的入口地址,该算法会递归地发现链中的剩余指令。
39.此外,给定入口字节,有可能在它之前有1字节指令,即n=1,或者在它之前有2字节指令,即n=2,等等。图5中的算法挑选了可能的最短指令,但其他算法也是可能的。
40.正如参考图3所论述的,在预解码阶段发现的“冷”call和return在行填充时被插入到bpb中。这在本文中被称为bpb分配策略填充时分支预取(bpof)。尽管所有预解码的冷分支都可在填充时被插入bpb中,但一实施例认为使用bpof在bpb中分配的冷分支的最大数目是三个,这平均起来覆盖了大约93%的缓存行。这个结论是假设64字节的缓存行得出的。对于更大或者更短的行,可能需要填充更多或者更少的分支。在入口地址之前的剩余分支可被忽略,尽管在不同的方案中,这些分支也可被插入到bpb中。在一实施例中,行中的入口地址,即,导致分支未命中的指令(bmi),被排除在计数之外,因为据信如果在三个分支之
中,它在bpb中被预取,则会将预取有用性平均降低达50%。这些冷分支往往具有较短的预取到使用时间,例如,仅仅几百个执行的uop就足以捕获所有冷分支的大约65%,暗示了bpb的小尺寸。一实施例表明,192个条目的bpb可提供最好的性能,例如参考图6和图7论述的那样。
41.图6和图7图示了根据一些实施例,相对于基线的冷baclear的分数的样本值。当分支预测器单元/逻辑进行预测时,它可预测可通过解码指令来确定的信息(即,静态信息)和只能通过执行分支来确定的信息。正如本文所论述的,“baclear”一般发生在指令被解码并且检测到分支预测器不正确地预测了一些静态信息时。因此,baclear响应于解码器解码指令并且检测到对分支的静态信息的误预测而指示出分支重引导。图6示出了将bpb扩展到192个条目以上将不会带来什么好处。图7比较了在192个bpb条目下的最近最少使用(least recently used,lru)与最大预取到使用(largest-prefetch-to-use,lpu)替换策略。因此,图6和图7根据一些实施例图示了用于比较不同的分支预取缓冲器分配/大小和替换策略的数据样本图。
42.在图6和图7中,602指的是3的bpof和1k的lru,604指的是3的bpof和192的lru,606指的是3的bpof和2k的lru,608指的是3的bpof和1k的lpu,610指的是无限的bpof,612指的是3的bpof和2k的lpu,614指的是3的bpof和192的lpu,702指的是3的bpof和192的lru,704指的是3的bpof和192的lpu,并且706指的是无限的bpof。
43.如前所述,冷分支往往比其他分支具有更短的预取到使用时间,可以根据除了lru之外的其他bpb替换策略来考虑这一点。例如,最大预取到使用时间(lpu)可能提供比lru更好的性能,平均提高bpb命中率约6%(如图7所示)。在lpu替换策略下,受害者条目是自预取发生以来经过时间最长的条目。
44.示范性核心体系结构、处理器和计算机体系结构
45.可按不同的方式、为了不同的目的、在不同的处理器中实现处理器核心。例如,这种核心的实现方式可包括:1)打算用于通用计算的通用有序核心;2)打算用于通用计算的高性能通用无序核心;3)主要打算用于图形和/或科学(吞吐量)计算的专用核心。不同处理器的实现方式可包括:1)包括打算用于通用计算的一个或多个通用有序核心和/或打算用于通用计算的一个或多个通用无序核心的cpu(中央处理单元);以及2)包括主要打算用于图形和/或科学(吞吐量)的一个或多个专用核心的协处理器。这样的不同处理器导致不同的计算机系统体系结构,这些体系结构可包括:1)协处理器在与cpu分开的芯片上;2)协处理器在与cpu相同的封装中的分开的管芯上;3)协处理器与cpu在同一管芯上(在此情况下,这种协处理器有时被称为专用逻辑,例如集成图形和/或科学(吞吐量)逻辑,或者被称为专用核心);以及4)片上系统,其可在同一管芯上包括所描述的cpu(有时称为(一个或多个)应用核心或者(一个或多个)应用处理器)、上述的协处理器以及额外的功能。接下来描述示范性核心体系结构,然后是对示范性处理器和计算机体系结构的描述。
46.示范性核心体系结构
47.图8a是根据实施例图示出示范性有序管线和示范性寄存器重命名、无序发出/执行管线两者的框图。图8b是根据实施例图示出要被包括在处理器中的有序体系结构核心的示范性实施例和示范性寄存器重命名、无序发出/执行体系结构核心两者的框图。图8a-8b中的实线框图示了有序管线和有序核心,而虚线框的可选添加图示了寄存器重命名、无序
发出/执行管线和核心。考虑到有序方面是无序方面的子集,将描述无序方面。
48.在图8a中,处理器管线800包括取得阶段802、长度解码阶段804、解码阶段806、分配阶段808、重命名阶段810、调度(也称为调遣或发出)阶段812、寄存器读取/存储器读取阶段814、执行阶段816、写回/存储器写入阶段818、异常处理阶段822、以及提交阶段824。
49.图8b示出了处理器核心890包括耦合到执行引擎单元850的前端单元830,并且两者都耦合到存储器单元870。核心890可以是精简指令集计算(reduced instruction set computing,risc)核心、复杂指令集计算(complex instruction set computing,cisc)核心、超长指令字(very long instruction word,vliw)核心、或者混合或替换核心类型。作为另外一个选项,核心890可以是专用核心,例如,网络或通信核心、压缩引擎、协处理器核心、通用计算图形处理单元(general purpose computing graphics processing unit,gpgpu)核心、图形核心,等等。
50.前端单元830包括分支预测单元832,其耦合到指令缓存单元834,指令缓存单元834耦合到指令转化后备缓冲器(translation lookaside buffer,tlb)836,tlb 836耦合到指令取得单元838,指令取得单元838耦合到解码单元840。解码单元840(或解码器)可对指令解码,并且生成一个或多个微操作、微代码入口点、微指令、其他指令或其他控制信号作为输出,这些微操作、微代码入口点、微指令、其他指令或其他控制信号是从原始指令解码来的,或者以其他方式反映原始指令,或者是从原始指令得出的。可利用各种不同的机制来实现解码单元840。适当机制的示例包括但不限于查找表、硬件实现、可编程逻辑阵列(programmable logic array,pla)、微代码只读存储器(read only memory,rom),等等。在一个实施例中,核心890包括微代码rom或其他介质,其为某些宏指令存储微代码(例如,在解码单元840中或者以其他方式在前端单元830内)。解码单元840耦合到执行引擎单元850中的重命名/分配器单元852。
51.执行引擎单元850包括重命名/分配器单元852,其耦合到引退单元854和一组一个或多个调度器单元856。(一个或多个)调度器单元856表示任何数目的不同调度器,包括预留站、中央指令窗口等等。(一个或多个)调度器单元856耦合到(一个或多个)物理寄存器文件单元858。物理寄存器文件单元858中的每一者表示一个或多个物理寄存器文件,这些物理寄存器文件中的不同物理寄存器文件存储一个或多个不同的数据类型,例如标量整数、标量浮点、紧缩整数、紧缩浮点、向量整数、向量浮点、状态(例如,作为要执行的下一指令的地址的指令指针),等等。在一个实施例中,物理寄存器文件单元858包括向量寄存器单元、写入掩码寄存器单元、和标量寄存器单元。这些寄存器单元可提供体系结构式向量寄存器、向量掩码寄存器、和通用寄存器。(一个或多个)物理寄存器文件单元858与引退单元854重叠以示出可用来实现寄存器重命名和无序执行的各种方式(例如,利用(一个或多个)重排序缓冲器和(一个或多个)引退寄存器文件;利用(一个或多个)未来文件、(一个或多个)历史缓冲器、和(一个或多个)引退寄存器文件;利用寄存器图谱和寄存器的池;等等)。引退单元854和(一个或多个)物理寄存器文件单元858耦合到(一个或多个)执行集群860。(一个或多个)执行集群860包括一组一个或多个执行单元862和一组一个或多个存储器访问单元864。执行单元862可在各种类型的数据(例如,标量浮点、紧缩整数、紧缩浮点、向量整数、向量浮点)上执行各种操作(例如,移位、加法、减法、乘法)。虽然一些实施例可包括专用于特定功能或功能集合的若干个执行单元,但其他实施例可只包括一个执行单元或者全部执行
所有功能的多个执行单元。(一个或多个)调度器单元856、(一个或多个)物理寄存器文件单元858和(一个或多个)执行集群860被示为可能是多个,因为某些实施例为某些类型的数据/操作创建单独的管线(例如,标量整数管线、标量浮点/紧缩整数/紧缩浮点/向量整数/向量浮点管线和/或存储器访问管线,它们各自具有其自己的调度器单元、物理寄存器文件单元和/或执行集群——并且在单独的存储器访问管线的情况下,实现了某些实施例,其中只有此管线的执行集群具有(一个或多个)存储器访问单元864)。还应当理解,在使用分开管线的情况下,这些管线中的一个或多个可以是无序发出/执行,并且其余的是有序的。
52.存储器访问单元864的集合耦合到存储器单元870,存储器单元870包括数据tlb单元872,数据tlb单元872耦合到数据缓存单元874,数据缓存单元874耦合到第2级(l2)缓存单元876。在一个示范性实施例中,存储器访问单元864可包括加载单元、存储地址单元和存储数据单元,它们中的每一者耦合到存储器单元870中的数据tlb单元872。指令缓存单元834进一步耦合到存储器单元870中的第2级(l2)缓存单元876。l2缓存单元876耦合到一个或多个其他级别的缓存并且最终耦合到主存储器。
53.作为示例,示范性寄存器重命名、无序发出/执行核心体系结构可实现管线800如下:1)指令取得838执行取得和长度解码阶段802和804;2)解码单元840执行解码阶段806;3)重命名/分配器单元852执行分配阶段808和重命名阶段810;4)(一个或多个)调度器单元856执行调度阶段812;5)(一个或多个)物理寄存器文件单元858和存储器单元870执行寄存器读取/存储器读取阶段814;执行集群860执行执行阶段816;6)存储器单元870和(一个或多个)物理寄存器文件单元858执行写回/存储器写入阶段818;7)在异常处理阶段822中可涉及各种单元;并且8)引退单元854和(一个或多个)物理寄存器文件单元858执行提交阶段824。
54.核心890可支持一个或多个指令集(例如,x86指令集(带有已随着较新版本添加的一些扩展);加州森尼维尔市的mips技术公司的mips指令集;加州森尼维尔市的arm控股公司的arm指令集(带有可选的额外扩展,例如neon)),包括本文描述的(一个或多个)指令。在一个实施例中,核心890包括逻辑来支持紧缩数据指令集扩展(例如,avx1、avx2),从而允许了被许多多媒体应用使用的操作被利用紧缩数据来执行。
55.图9图示了根据一实施例的soc封装的框图。如图9所示,soc 902包括一个或多个中央处理单元(cpu)核心920、一个或多个图形处理器单元(gpu)核心930、输入/输出(i/o)接口940、以及存储器控制器942。soc封装902的各种组件可耦合到互连或总线,例如本文参考其他附图所论述的。另外,soc封装902可包括更多或更少的组件,例如本文参考其他附图所论述的那些。另外,soc封装902的每个组件可包括一个或多个其他组件,例如,如本文参考其他附图所论述的。在一个实施例中,在一个或多个集成电路(ic)管芯上提供soc封装902(及其组件),例如,这些管芯被封装成单个半导体器件。
56.如图9所示,soc封装902经由存储器控制器942耦合到存储器960。在一实施例中,存储器960(或者它的一部分)可被集成在soc封装902上。
57.i/o接口940可耦合到一个或多个i/o设备970,例如,经由互连和/或总线,例如本文参考其他附图所论述的。(一个或多个)i/o设备970可包括以下各项中的一个或多个:键盘、鼠标、触摸板、显示器、图像/视频捕捉设备(例如相机或者摄像机/录像机)、触摸屏、扬声器,等等。
58.图10是根据一实施例的处理系统1000的框图。在各种实施例中,系统1000包括一个或多个处理器1002和一个或多个图形处理器1008,并且可以是单处理器桌面系统、多处理器工作站系统、或者具有大量处理器1002或处理器核心1007的服务器系统。在一个实施例中,系统1000是包含在片上系统(soc或soc)集成电路内的处理平台,用于移动、手持或者嵌入式设备中。
59.系统1000的实施例可包括或者被包含在以下各项内:基于服务器的游戏平台、包括游戏和媒体控制台的游戏控制台、移动游戏控制台、手持游戏控制台、或者在线游戏控制台。在一些实施例中,系统1000是移动电话、智能电话、平板计算设备、或者移动互联网设备。数据处理系统1000还可包括可穿戴设备、与可穿戴设备耦合或者被集成在可穿戴设备内,例如智能手表可穿戴设备、智能眼镜设备、增强现实设备、或者虚拟现实设备。在一些实施例中,数据处理系统1000是具有一个或多个处理器1002和由一个或多个图形处理器1008生成的图形界面的电视或者机顶盒设备。
60.在一些实施例中,一个或多个处理器1002各自包括一个或多个处理器核心1007,以处理指令,这些指令在被执行时,执行系统和用户软件的操作。在一些实施例中,一个或多个处理器核心1007中的每一者被配置为处理特定的指令集1009。在一些实施例中,指令集1009可促进复杂指令集计算(cisc),精简指令集计算(risc),或者经由超长指令字(vliw)的计算。多个处理器核心1007可各自处理不同的指令集1009,其中可包括促进对其他指令集的仿真的指令。处理器核心1007也可包括其他处理设备,例如数字信号处理器(dsp)。
61.在一些实施例中,处理器1002包括缓存存储器1004。取决于体系结构,处理器1002可具有单个内部缓存或者多个级别的内部缓存。在一些实施例中,在处理器1002的各种组件之间共享缓存存储器。在一些实施例中,处理器1002还使用外部缓存(例如,第3级(l3)缓存或者最后一级缓存(last level cache,llc))(未示出),可使用已知的缓存一致性技术在处理器核心1007之间共享这些外部缓存。在处理器1002中还包括寄存器文件1006,它可包括用于存储不同类型的数据的不同类型的寄存器(例如,整数寄存器、浮点寄存器、状态寄存器、以及指令指针寄存器)。一些寄存器可以是通用的寄存器,而其他寄存器可以是特定于处理器1002的设计的。
62.在一些实施例中,处理器1002耦合到处理器总线1010,以在处理器1002和系统1000中的其他组件之间传输通信信号,例如地址、数据、或者控制信号。在一个实施例中,系统1000使用示范性的“中枢”系统体系结构,包括存储器控制器中枢1016和输入输出(i/o)控制器中枢1030。存储器控制器中枢1016促进了存储器设备和系统1000的其他组件之间的通信,而i/o控制器中枢(ich)1030经由本地i/o总线提供与i/o设备的连接。在一个实施例中,存储器控制器中枢1016的逻辑被集成在处理器内。
63.存储器设备1020可以是动态随机访问存储器(dynamic random access memory,dram)设备、静态随机访问存储器(static random access memory,sram)设备、闪存设备、相变存储器设备、或者具有适当的性能来用作进程存储器的某种其他存储器设备。在一个实施例中,存储器设备1020可充当系统1000的系统存储器,以存储数据1022和指令1021来在一个或多个处理器1002执行应用或进程时使用。存储器控制器中枢1016还与可选的外部图形处理器1012耦合,该外部图形处理器可与处理器1002中的一个或多个图形处理器1008
通信以执行图形和媒体操作。
64.在一些实施例中,ich 1030使得外设能够经由高速i/o总线连接到存储器设备1020和处理器1002。i/o外设包括但不限于音频控制器1046、固件接口1028、无线收发器1026(例如,wi-fi、蓝牙)、数据存储设备1024(例如,硬盘驱动器、闪存,等等)、以及用于将传统(例如,个人系统2(personal system 2,ps/2))设备耦合到该系统的传统i/o控制器1040。一个或多个通用串行总线(universal serial bus,usb)控制器1042连接输入设备,例如键盘和鼠标1044的组合。网络控制器1034也可耦合到ich 1030。在一些实施例中,高性能网络控制器(未示出)耦合到处理器总线1010。将会明白,所示出的系统1000是示范性的,而不是限制性的,因为也可使用不同配置的其他类型的数据处理系统。例如,i/o控制器中枢1030可被集成在一个或多个处理器1002内,或者存储器控制器中枢1016和i/o控制器中枢1030可被集成到分立的外部图形处理器中,例如外部图形处理器1012。
65.图11是具有一个或多个处理器核心1102a至1102n、集成存储器控制器1114和集成图形处理器1108的处理器1100的实施例的框图。图11的具有与本文的任何其他附图中的元素相同的标号(或名称)的那些元素可按与本文别处所描述的相似的任何方式操作或工作,但不限于此。处理器1100可包括额外的核心,直到并包括由虚线框表示的额外核心1102n。处理器核1102a至1102n中的每一者包括一个或多个内部缓存单元1104a至1104n。在一些实施例中,每个处理器核心还能够访问一个或多个共享缓存单元1106。
66.内部缓存单元1104a至1104n和共享缓存单元1106代表处理器1100内的缓存存储器层次体系。该缓存存储器层次体系可包括每个处理器核心内的至少一级指令和数据缓存以及一个或多个级别的共享中间级缓存,例如第2级(l2)、第3级(l3)、第4级(l4)或者其他级别的缓存,其中外部存储器之前的最高级别缓存被分类为llc。在一些实施例中,缓存一致性逻辑维持各种缓存单元1106和1104a至1104n之间的一致性。
67.在一些实施例中,处理器1100还可包括一组一个或多个总线控制器单元1116和一系统代理核心1110。一个或多个总线控制器单元1116管理一组外围总线,例如一个或多个外围组件互连总线(例如,pci、快速pci)。系统代理核心1110为各种处理器组件提供管理功能。在一些实施例中,系统代理核心1110包括一个或多个集成存储器控制器1114,以管理对各种外部存储器设备(未示出)的访问。
68.在一些实施例中,处理器核心1102a至1102n中的一个或多个包括对同时多线程的支持。在这样的实施例中,系统代理核心1110包括用于在多线程处理期间协调和操作核心1102a至1102n的组件。系统代理核心1110可还包括功率控制单元(power control unit,pcu),其包括调节处理器核心1102a至1102n和图形处理器1108的功率状态的逻辑和组件。
69.在一些实施例中,处理器1100还包括图形处理器1108,以执行图形处理操作。在一些实施例中,图形处理器1108与一组共享缓存单元1106以及系统代理核心1110(包括一个或多个集成存储器控制器1114)相耦合。在一些实施例中,显示控制器1111与图形处理器1108耦合,以驱动图形处理器输出到一个或多个耦合的显示器。在一些实施例中,显示控制器1111可以是经由至少一个互连与图形处理器相耦合的单独模块,或者可被集成在图形处理器1108或者系统代理核心1110内。
70.在一些实施例中,使用基于环形的互连单元1112来耦合处理器1100的内部组件。然而,也可使用替代的互连单元,例如点对点互连、交换式互连或者其他技术,包括本领域
公知的技术。在一些实施例中,图形处理器1108经由i/o链路1113与环形互连1112耦合。
71.示范性i/o链路1113代表多个品种的i/o互连中的至少一种,包括封装上i/o互连,它促进了各种处理器组件和高性能嵌入式存储器模块1118之间的通信,例如edram(或者嵌入式dram)模块。在一些实施例中,处理器核心1102至1102n中的每一者和图形处理器1108使用嵌入式存储器模块1118作为共享的最后一级缓存。
72.在一些实施例中,处理器核心1102a至1102n是执行相同指令集体系结构的同构核心。在另一实施例中,处理器核心1102a至1102n就指令集体系结构(isa)而言是异构的,其中处理器核心1102a至1102n中的一个或多个执行第一指令集,而其他核心中的至少一个执行第一指令集的子集或者不同的指令集。在一个实施例中,处理器核心1102a至1102n就微体系结构而言是异构的,其中具有相对更高的功率消耗的一个或多个核心与具有更低功率消耗的一个或多个功率核心相耦合。此外,处理器1100可被实现在一个或多个芯片上,或者被实现为soc集成电路,该soc集成电路除了其他组件以外还具有图示的组件。
73.图12是图形处理器1200的框图,该图形处理器可以是分立的图形处理单元,或者可以是与多个处理核心集成的图形处理器。在一些实施例中,图形处理器经由存储器映射的i/o接口与图形处理器上的寄存器和放入处理器存储器中的命令进行通信。在一些实施例中,图形处理器1200包括存储器接口1214以访问存储器。存储器接口1214可以是与本地存储器、一个或多个内部缓存、一个或多个共享外部缓存和/或系统存储器的接口。
74.在一些实施例中,图形处理器1200还包括显示控制器1202,以驱动显示输出数据到显示设备1220。显示控制器1202包括用于视频或用户界面元素的多个层的显示和合成的一个或多个覆盖平面的硬件。在一些实施例中,图形处理器1200包括视频编解码器引擎1206,用于将媒体编码到一个或多个媒体编码格式,从一个或多个媒体编码格式解码媒体,或者在一个或多个媒体编码格式之间对媒体进行转码,这些媒体编码格式包括但不限于运动图片专家组(moving picture experts group,mpeg)格式,例如mpeg-2,高级视频编码(advanced video coding,avc)格式,例如h.264/mpeg-4avc,以及美国电影电视工程师协会(society of motion picture&television engineers,smpte)321m/vc-1,以及联合摄影专家组(joint photographic experts group,jpeg)格式,例如jpeg和运动jpeg(mjpeg)格式。
75.在一些实施例中,图形处理器1200包括块图像传送(block image transfer,blit)引擎1204,以执行二维(2d)光栅化操作,包括例如比特边界块传送。然而,在一个实施例中,使用图形处理引擎(graphics processing engine,gpe)1210的一个或多个组件执行12d图形操作。在一些实施例中,图形处理引擎1210是计算引擎,用于执行图形操作,包括三维(3d)图形操作和媒体操作。
76.在一些实施例中,gpe 1210包括3d管线1212,用于执行3d操作,例如使用作用于3d基元形状(例如,矩形、三角形,等等)的处理函数来渲染三维图像和场景。3d管线1212包括可编程的和固定的功能元素,这些功能元素执行元素内的各种任务和/或派生执行线程到3d/媒体子系统1215。虽然3d管线1212可被用于执行媒体操作,但gpe 1210的一实施例还包括媒体管线1216,该媒体管线专门用于执行媒体操作,例如视频后期处理和图像增强。
77.在一些实施例中,媒体管线1216包括固定功能或者可编程逻辑单元,以执行一个或多个专门的媒体操作,例如视频解码加速、视频解交织以及视频编码加速,以代替或者代
表视频编解码器引擎1206。在一些实施例中,媒体管线1216还包括线程派生单元,用于派生线程来在3d/媒体子系统1215上执行。所派生的线程在3d/媒体子系统1215中包括的一个或多个图形执行单元上执行媒体操作的计算。
78.在一些实施例中,3d/媒体子系统1215包括用于执行由3d管线1212和媒体管线1216派生的线程的逻辑。在一个实施例中,管线将线程执行请求发送到3d/媒体子系统1215,该3d/媒体子系统包括用于仲裁和调遣各种请求到可用线程执行资源的线程调遣逻辑。执行资源包括处理3d和媒体线程的图形执行单元的阵列。在一些实施例中,3d/媒体子系统1215包括用于线程指令和数据的一个或多个内部缓存。在一些实施例中,该子系统还包括共享存储器,包括寄存器和可寻址存储器,以在线程之间共享数据并且存储输出数据。
79.在以下描述中,记载了许多具体细节以提供更透彻的理解。然而,本领域技术人员将会清楚,没有这些具体细节中的一个或多个也可实现本文描述的实施例。在其他情况下,没有描述公知的特征以避免模糊这些实施例的细节。
80.以下示例属于进一步实施例。示例1包括一种装置,包括:预解码电路,用于对缓存中的条目进行预解码以生成预解码的分支操作,所述条目与冷分支操作相关联,其中所述冷分支操作对应于在存储在指令缓存中之后第一次检测到的操作,并且其中所述冷分支操作由于其被存储在缓存行中的如下位置而保持未解码,并且保持未解码:该位置不是该缓存行的开始,并且在该缓存行中的分支操作的后续位置之前;以及分支预取缓冲器(bpb),用于响应于所述冷分支操作在指令缓存中的缓存行填充操作而存储所述预解码的分支操作。示例2包括如示例1所述的装置,其中所述预解码电路从紧挨在入口地址的第一字节之前的字节开始按相反顺序对所述缓存的一个或多个条目进行预解码。示例3包括如示例2所述的装置,其中所述预解码电路在两个阶段中对所述缓存的一个或多个条目进行预解码。示例4包括如示例3所述的装置,其中所述两个阶段包括:第一阶段,用于计算与所述冷分支操作相对应的指令的长度;以及第二阶段,用于从紧挨在所述入口地址的第一字节之前的字节开始按相反顺序标记与所述冷分支操作相对应的所述指令的第一字节。示例5包括如示例1所述的装置,其中所述bpb耦合到分支目标缓冲器(btb),其中所述btb存储与被采取的一个或多个分支及其目标地址相对应的信息。示例6包括如示例5所述的装置,其中在指向所述btb的请求发生未命中时,所述请求将被所述bpb来服务。示例7包括如示例5所述的装置,其中在指向所述btb的请求命中时,相应的bpb条目将被存储在所述btb中。示例8包括如示例1所述的装置,其中所述bpb和分支目标缓冲器(btb)响应于查找请求而被并行查找。示例9包括如示例1所述的装置,其中所述缓存包括中间级缓存(mlc)或第2级(l2)缓存。示例10包括如示例1所述的装置,其中所述预解码的分支操作将被存储在所述指令缓存中。示例11包括如示例1所述的装置,其中所述缓存行被存储在所述缓存中。示例12包括如示例1所述的装置,其中所述bpb用于存储192个条目。示例13包括如示例1所述的装置,其中所述bpb响应于所述指令缓存中的缓存行填充操作而分配最多三个冷分支。示例14包括如示例1所述的装置,其中具有一个或多个处理器核心的处理器包括以下各项中的一个或多个:所述预解码电路,所述bpb,以及分支目标缓冲器(btb)。示例15包括如示例14所述的装置,其中所述处理器包括具有一个或多个图形处理核心的图形处理单元(gpu)。
81.示例16包括一种系统,包括:存储器,用于存储一个或多个指令;具有一个或多个核心的处理器,用于执行所述一个或多个指令;预解码电路,用于对缓存中的条目进行预解
码以生成预解码的分支操作,所述条目与冷分支操作相关联,其中所述冷分支操作对应于在存储在指令缓存中之后第一次检测到的操作,并且其中所述冷分支操作由于其被存储在缓存行中的如下位置而保持未解码:该位置在该缓存行中的分支操作的后续位置之前;以及分支预取缓冲器(bpb),用于响应于所述冷分支操作在指令缓存中的缓存行填充操作而存储所述预解码的分支操作。示例17包括如示例16所述的系统,其中所述预解码电路从紧挨在入口地址的第一字节之前的字节开始对所述缓存的一个或多个条目进行预解码。示例18包括如示例17所述的系统,其中所述预解码电路在两个阶段中对所述缓存的一个或多个条目进行预解码。示例19包括如示例18所述的系统,其中所述两个阶段包括:第一阶段,用于计算与所述冷分支操作相对应的指令的长度;以及第二阶段,用于从紧挨在所述入口地址的第一字节之前的字节开始按相反顺序标记字节。示例20包括如示例16所述的系统,其中所述bpb耦合到分支目标缓冲器(btb),其中所述btb存储与被采取的一个或多个分支及其目标地址相对应的信息。
82.示例21包括一种方法,包括:对缓存中的条目进行预解码以生成预解码的分支操作,所述条目与冷分支操作相关联,其中所述冷分支操作对应于在存储在指令缓存中之后第一次检测到的操作,并且其中所述冷分支操作由于其被存储在缓存行中的如下位置而保持未解码:该位置在该缓存行中的分支操作的后续位置之前;并且响应于所述冷分支操作在指令缓存中的缓存行填充操作而在分支预取缓冲器(bpb)中存储所述预解码的分支操作。示例22包括如示例21所述的方法,还包括从紧挨在入口地址的第一字节之前的字节开始对所述缓存的一个或多个条目进行预解码。示例23包括如示例22所述的方法,还包括在两个阶段中对所述缓存的一个或多个条目进行预解码。示例24包括如示例21所述的方法,还包括在与所述bpb耦合的分支目标缓冲器(btb)中存储与被采取的一个或多个分支及其目标地址相对应的信息。示例25包括如示例21所述的方法,还包括响应于查找请求而并行查找所述bpb和分支目标缓冲器(btb)。
83.示例26包括一种装置,包括用于执行如任何在前示例中记载的方法的装置。示例27包括机器可读存储装置,其中包括机器可读指令,所述指令当被执行时,实现如任何在前示例中记载的方法或者实现如任何在前示例中记载的装置。
84.在各种实施例中,参考图1及其后各图论述的一个或多个操作可由参考任何附图论述的一个或多个组件(在此可互换地称为“逻辑”)执行。
85.在各种实施例中,本文论述的操作,例如参考图1及其后各图论述的操作,可被实现为硬件(例如,逻辑电路)、软件、固件或者其组合,其可被提供为计算机程序产品,例如,包括一个或多个有形(例如,非暂态)机器可读或计算机可读介质,其上存储有用于对计算机编程以执行本文论述的过程的指令(或者软件过程)。该机器可读介质可包括存储设备,例如关于附图论述的那些。
86.此外,这种计算机可读介质可作为计算机程序产品被下载,其中该程序可经由通信链路(例如,总线、调制解调器、或者网络连接)通过在载波或其他传播介质中提供的数据信号被从远程计算机(例如,服务器)传送到请求方计算机(例如,客户端)。
87.本说明书中提及“一个实施例”或“一实施例”的意思是联系该实施例描述的特定特征、结构和/或特性可被包括在至少一个实现方式中。在本说明书中各种地方出现短语“在一个实施例中”可能全都指的是同一实施例,也可能不是全都指同一实施例。
88.另外,在说明书和权利要求中,可以使用术语“耦合”和“连接”及其衍生词。在一些实施例中,“连接”可被用于指示出两个或更多个元素与彼此发生直接物理或电气接触。“耦合”的意思可以是两个或更多个元素发生直接物理或电气接触。然而,“耦合”也可以指两个或更多个元素可能没有与彼此发生直接接触,但仍可与彼此合作或交互。
89.从而,虽然是以依结构特征和/或方法动作而定的语言来描述实施例的,但要理解,要求保护的主题可不限于所描述的具体特征或动作。更确切地说,这些具体特征和动作是作为实现要求保护的主题的样本形式被公开的。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。