1.本发明涉及一种调整播放声音的方法和播放声音系统,特别是一种可以配合多个听众的年龄来调整声音,以使声音更容易被聆听的调整播放声音的方法和播放声音系统。
背景技术:
2.「均衡器(equalizer,eq)」是一种用于调整声音的工具,其可调整各频段声音的增益值。亦即,可调整声音(或音讯档案)于不同频率下的增益值,藉此改变输出声音所产生的听觉效果。例如,以重低音呈现的爆破声,听觉感较为震撼且逼真。因此,目前的均衡器主要被用在输出音效的调整。现有大部分的电脑,也多储存有均衡器的应用程序,可供使用者在听音乐时娱乐之用。
3.关于调整均衡器的增益值设定,多是由单一使用者调整一频率的增益值,或者是内建多个模式,令单一使用者可直接选择不同的模式以一次性的调整多个频率的增益值,可作为单一使用者听音乐时的娱乐之用。然而,若是在有多个听众的场合,由于每个听众的听力程度不相同,例如年长者的听力可能受损;因此单一使用者根据个人需求而调整的声音,可能无法让多个使用者里的年长而听力受损者听到。
4.因此,有必要提供一种新的电子装置及调整播放声音,以解决现有技术的缺失。
技术实现要素:
5.本发明的主要目的在于提供一种可以配合多个听众的年龄来调整声音,以使声音更容易被聆听的调整播放声音的方法。
6.为达成上述的目的,本发明的一种调整播放声音的方法,用于一播放声音系统,播放声音系统包括一照相模块,一脸部分析模块,一声音输入模块,一声音调整模块及一喇叭。该方法包括:通过照相模块对多个人的脸部取得一影像;通过脸部分析模块,分析影像以预估多个人的每一人的年纪,根据每一人的年纪以取得一目标年纪;通过声音输入模块取得一播放声音;通过声音调整模块,根据目标年纪处理播放声音以得到一输出声音;通过喇叭播放输出声音。
7.根据本发明的一实施例,其中声音调整模块根据目标年纪以选择一均衡器目标设定,以处理播放声音,以得到输出声音。
8.根据本发明的一实施例,其中声音调整模块根据目标年纪,通过处理播放声音以进行降低频率调整,以得到输出声音。
9.根据本发明的一实施例,其中目标年纪为多个人的每一人中的年纪最大者。
10.根据本发明的一实施例,其中目标年纪为多个人的平均年纪。
11.本发明的另一主要目的在提供一种可以配合多个听众的年龄来调整声音,以使声音更容易被聆听的播放声音系统。
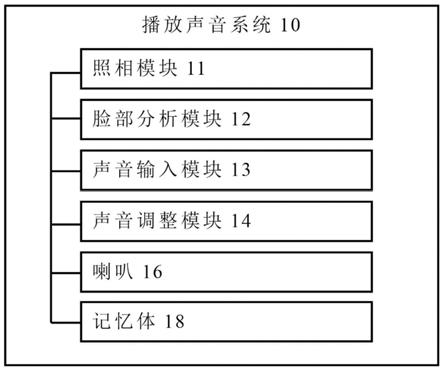
12.为达成上述的目的,本发明的一种播放声音系统包括一照相模块、一脸部分析模块、一声音输入模块、一声音调整模块及一喇叭。照相模块用以对多个人的脸部取得一影
像。脸部分析模块用以分析影像以预估多个人的每一人的年纪,并根据每一人的年纪以取得一目标年纪。声音输入模块用以取得一播放声音。声音调整模块用以根据目标年纪处理播放声音,以得到一输出声音。喇叭电性连接照相模块、脸部分析模块、声音输入模块和声音调整模块,喇叭用以播放输出声音。
13.根据本发明的一实施例,播放声音系统更包括一记忆体,记忆体电性连接声音调整模块,并储存多个均衡器目标设定数据。
14.以下结合附图和具体实施例对本发明进行详细描述,但不作为对本发明的限定。
附图说明
15.图1本发明的一实施例的播放声音系统的系统架构图;
16.图2本发明的一实施例的调整播放声音的方法的步骤流程图;
17.图3本发明的一实施例的照相模块取得的影像的示意图。
18.其中,附图标记
19.播放声音系统10
20.照相模块11
21.脸部分析模块12
22.声音输入模块13
23.声音调整模块14
24.喇叭16
25.记忆体18
26.影像30
27.人脸31、31a
28.目标年纪50t
29.播放声音60
30.输出声音61
具体实施方式
31.为能更了解本发明的技术内容,特举较佳具体实施例说明如下。
32.以下请一并参考图1至图3关于本发明的一实施例的播放声音系统和调整播放声音的方法。图1本发明的一实施例的播放声音系统的系统架构图。图2本发明的一实施例的调整播放声音的方法的步骤流程图。图3本发明的一实施例的照相模块取得的影像的示意图。
33.如图1至图3所示,在本发明的一实施例中,调整播放声音的方法和播放声音系统10可以应用于有多个听众的场合(例如客厅、会议厅、电影院、剧院或音乐厅),以配合多个听众的年龄来调整播放的声音,以使声音更容易被聆听。播放声音系统10例如是电视、音响或其他具有播放声音功能的装置。播放声音系统10包括一照相模块11、一脸部分析模块12、一声音输入模块13、一声音调整模块14、一喇叭16和一记忆体18。
34.在本发明的一实施例中,照相模块11例如为一摄影镜头,其用以对播放声音系统10设置的场合里的多个人的脸部取得一影像30,影像30包含多个人的人脸31、31a。照相模
块11可以内建于电视、音响或外部设备(如遥控器或手机)。脸部分析模块12例如为具有分析功能的芯片,其用以分析照相模块11取得的影像30,以预估多个人的每一人的年纪,并根据每一人的年纪以取得一目标年纪50t。本发明的目标年纪50t为播放声音系统10设置的场合里的多个人中的年纪最大者;但是目标年纪50t的设计不以上述为限,目标年纪50t也可以是多个人的平均年纪。
35.在本发明的一实施例中,声音输入模块13例如为对外连接的音源线,其用以取得从外部输入的一播放声音60。声音调整模块14例如为具有声音调整功能的芯片,其用以根据脸部分析模块12得到的目标年纪50t,以选择一均衡器目标设定以处理播放声音60,以得到一输出声音61。
36.在本发明的一实施例中,喇叭16电性连接照相模块11、脸部分析模块12、声音输入模块13和声音调整模块14,喇叭16用以播放声音调整模块14处理完的输出声音61,以供播放声音系统10设置的场合里的多个人聆听。记忆体18电性连接声音调整模块14,并储存多个均衡器目标设定数据,以供声音调整模块14从记忆体18储存的多个均衡器目标设定数据的中,选择均衡器目标设定以处理播放声音60。记忆体18储存的多个均衡器目标设定数据如同下表所示。
[0037][0038]
各个均衡器目标设定数据包括年龄区段,以及频率250hz、500hz、1khz、2khz、4khz、8khz、12.5khz、16khz等不同频率所对应的补偿增益值;举例来说,在70~90的年龄区段里,频率250hz、500hz、1khz、2khz、4khz、8khz、12.5khz、16khz所对应的补偿增益值分别为3.0、3.1、3.2、4.0、5.6、8.8、11.4、12.0,因此若是声音调整模块14使用70~90的年龄区段的均衡器目标设定来处理声音,则听众会听到频率250hz、500hz、1khz、2khz、4khz、8khz、12.5khz、16khz分别具有3.0、3.1、3.2、4.0、5.6、8.8、11.4、12.0补偿增益值的声音。但需注意的是,上述均衡器目标设定数据的各项数值仅为举例说明,年龄区段的年龄范围不以上述为限,年龄区段的年龄范围可依照设计需求而改变,例如修改为每隔五岁就分为一年龄区段。另外,补偿增益值的数值限制也不限于此,补偿增益值的数值限制也可以是负数,因此声音调整模块14会处理播放声音60以进行降低频率调整,以得到降低频率的输出声音61。
[0039]
在本发明的一实施例中,调整播放声音的方法被编程为软件程序并储存在记忆体18。在进行本发明的调整播放声音的方法时,播放声音系统10会执行调整播放声音的方法的软件程序,以执行步骤101:通过照相模块11对多个人的脸部取得一影像30。
[0040]
在本发明的一实施例中,照相模块11对着播放声音系统10设置的场合里的三个人的脸部拍照,以取得三个人的脸部的影像30,影像30内有三个人的人脸31、31a。照相模块11会将拍摄到的影像30传送给脸部分析模块12。
[0041]
接着,播放声音系统10会执行步骤102:通过脸部分析模块12,分析影像30以预估多个人的每一人的年纪,根据每一人的年纪以取得一目标年纪50t。
[0042]
脸部分析模块12接收到照相模块11拍摄到的三个人的脸部的影像30后,会分析影像30以预估三个人的每一人的年纪,并且根据每一人的年纪以取得一目标年纪50t。目标年纪50t为播放声音系统10设置的场合里的多个人的每一人中的年纪最大者。在本发明的一实施例中,脸部分析模块12根据人脸31、31a的外表特征,例如皱纹、眼袋、头发发色而预估每一人的年纪,因此脸部分析模块12根据人脸31而预估对应的人的年纪为35岁,并根据人脸31a而预估对应的人的年纪为65岁;藉此,目标年纪50t为三个人中的年纪最大者的65岁。
[0043]
接着,播放声音系统10会执行步骤103:通过声音输入模块13取得一播放声音60。
[0044]
在本发明的一实施例中,声音输入模块13的音源线取得外部输入的一播放声音60,播放声音60例如音乐、人声或影片的配音。声音输入模块13会将接收到的播放声音60传送给声音调整模块14。
[0045]
接着,播放声音系统10会执行步骤104:通过声音调整模块14,根据目标年纪50t以选择一均衡器目标设定,以处理播放声音60,以得到一输出声音61。
[0046]
在本发明的一实施例中,声音调整模块14根据目标年纪50t的65岁,以从记忆体18储存的多个均衡器目标设定数据的中,选择对应的均衡器目标设定以处理播放声音60。由于目标年纪50t是65岁,因此声音调整模块14选择的均衡器目标设定是60~69岁年龄区段对应的设定,也就是频率250hz、500hz、1khz、2khz、4khz、8khz、12.5khz、16khz所对应的补偿增益值分别为2.6、2.6、2.5、2.8、4.0、6.3、10.1、11.8。因此,播放声音60会被声音调整模块14处理成各个频率具有不同的补偿增益值,而得到适合60~69岁年龄区段的人聆听的一输出声音61,以便年纪最大的65岁的人清楚得聆听。
[0047]
然而,若是目标年纪50t是设计为多个人的平均年纪,则目标年纪50t会是45岁,因此声音调整模块14选择的均衡器目标设定是40~49岁年龄区段对应的设定,并且将播放声音60处理成适合40~49岁年龄区段的人聆听的一输出声音61,以便尽量多人能清楚得聆听。
[0048]
最后,播放声音系统10会执行步骤105:通过喇叭16播放输出声音61。
[0049]
声音调整模块14会将输出声音61传送给喇叭16,喇叭16会播放输出声音61以供播放声音系统10设置的场合里的三个人聆听。由于输出声音61已被调整为适合60~69岁年龄区段的人聆听,因此播放声音系统10设置的场合里的三个人之中,年纪最大的65岁的一人,也可以清楚得听到调整后的输出声音61。
[0050]
藉由本发明的调整播放声音的方法和播放声音系统10,可以应用于有多个听众的场合,以配合多个听众的年龄来调整播放的声音,以使声音可以让多个听众中的年龄最长者听到,或是让尽量多人听到,使得声音更容易被听众聆听。
[0051]
当然,本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,熟悉本领域的技术人员当可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。