本发明涉及数据库查询的执行优化。在本文中是用于基于通过利用诸如部分评估、抽象句法树(AST)重写、即时(JIT)编译、动态剖析、推测性逻辑以及Futamura投影之类的优化翻译成域特定语言(DSL)进行查询解释的优化执行的技术。
背景技术
研究和工业的最新进展为给定的查询计划生成低级虚拟机(LLVM)位码。LLVM位码由LLVM编译器(LLC)通过经受代码生成步骤并通过在查询的编译时编译生成的代码被编译成机器代码。
代码生成和LLVM编译方法有很大的局限性。生成的代码是静态编译的,这意味着只考虑了在编译时可用的信息。这有明显的局限性,因为当前的运行时信息不能被考虑在内。当前的研究和行业解决方案无法利用动态剖析信息有几个原因。
οSQL表达式操作数中没有内置剖析基础设施。即使有,这也会产生很大的运行时开销。
ο编译时的先验知识也不可用,因为需要评估整个查询计划,包括所有中间结果。
ο不支持推测性逻辑。
附图说明
在附图中:
图1是描绘示例计算机的框图,该计算机基于通过利用诸如部分评估和即时(JIT)编译之类的优化翻译成域特定语言(DSL)进行解释来优化数据库查询的执行;
图2是描绘示例计算机过程的流程图,该过程用于基于通过利用诸如部分评估和JIT编译之类的优化翻译成DSL进行解释来优化数据库查询的执行;
图3是描绘示例数据库管理系统(DBMS)的框图,该DBMS在查询树中用合成的查询节点替换子树,该合成的查询节点具有对子树的部分评估;
图4是描绘示例DBMS过程的流程图,该DBMS过程在查询树中用合成的查询节点替换子树,该合成的查询节点具有对子树的部分评估;
图5是描绘DBMS的框图,该DBMS展示了诸如利用部分评估的渐进式优化;
图6是描绘示例DBMS过程的流程图,该DBMS过程直接或间接地从DSL指令序列生成编译;
图7是描绘由DBMS进行优化的示例的流程图,诸如用于结合到优化的编译中;
图8是描绘由DBMS进行的两个程序变换的示例的流程图,这些变换加速了解释和/或编译的执行;
图9是图示可以在其上实现本发明的实施例的计算机系统的框图;
图10是图示可以用于控制计算系统的操作的基本软件系统的框图。
具体实施方式
在下面的描述中,出于解释的目的,阐述了许多具体细节以便提供对本发明的透彻理解。但是,将显而易见的是,可以在没有这些具体细节的情况下实践本发明。在其它情况下,以框图形式示出了众所周知的结构和设备,以避免不必要地使本发明晦涩难懂。
总体概述
本文的方法与低级虚拟机(LLVM)的静态技术不同,尤其是通过添加实现动态优化所需的运行时反馈循环。通过使用Truffle语言框架和Graal即时(JIT)编译器,可以考虑运行时信息,并且可以产生更优化的代码。由此,Truffle语言是通过抽象句法树(AST)解释器实现的。更具体而言,域特定语言(DSL)元素被映射到根据Truffle框架实现的句法节点。每个句法节点具有实现语言元素的逻辑的执行方法。为了执行语言程序,Truffle框架调用语言解析器。Truffle语言解析器的输出是AST。对于每个解析的语言元素,解析器实例化对应的句法节点并链接所有AST节点以实例化AST。解析步骤的结果是实例化的AST。然后通过解释来执行Truffle语言程序,这意味着调用根AST节点的执行方法。然后根节点的执行方法调用作为根节点的子节点附接的句法节点的执行方法。这个过程以自上而下的深度优先方式对节点的子节点递归。
在解释过程期间收集运行时信息。Truffle的强项是能够充分利用剖析信息来触发自我优化技术。那些关键优化技术中的一些包括:类型特化、间接函数调用的重写、多态内联高速缓存、分支消除和推测性函数内联。如果这些推测性假设被证明是错误的,那么可以将专用AST恢复为更通用的版本,该版本为更通用的情况提供功能性(如果可用并已编译),或者触发去优化。
当句法节点的执行计数达到预定义的阈值时,Truffle通过调用Graal编译器来触发部分评估。通过编译由AST表示的程序及其解释器,应用第一Futamura投影。输出是具有去优化点的高度优化的机器代码。那些点被实现为检查点,在那些点处,当推测性假设不再成立时触发去优化。去优化意味着控制从编译后的代码转移回AST解释器,然后在那里将专用节点恢复为更通用的版本。
不是解释SQL表达式或生成和静态编译每个LLVM的代码,可以通过充分利用Truffle框架来评估SQL表达式。SQL标准定义了用于SQL语言的语法,包括用于SQL表达式的语法。因此,SQL表达式可以通过语言来描述。因此,SQL表达式可以被实现为Truffle语言。
通过将SQL表达式实现为Truffle语言,可以充分利用Truffle框架和Graal编译器的优势。示例实施方式可以具有以下技术:
ο将SQL表达式识别为可以“truffelized”的语言的总体思路。新语言是本文稍后给出的多语言引擎存根语言(MSL);
οMSL生成器:对于给定表达式树生成MSL代码的算法;
οMSL解析器:解析MSL代码并实例化对应MSL Truffle句法节点的算法;
ο如何将Truffle和Graal编译器框架嵌入数据库管理系统(DBMS)的体系架构。引入了新的SQL表达式节点,该节点负责在查询编译阶段存储MSL代码,并在查询执行阶段执行MSL代码。新的SQL表达式节点将替换对应SQL表达式树的根。
在实施例中,托管在计算机上的DBMS生成表示数据库查询的查询树,该数据库查询包含由查询树的子树表示的表达式。DBMS生成表示子树的域特定语言(DSL)指令的序列。在数据库查询的执行期间,执行DSL指令的序列以评估表达式。在实施例中,从DSL指令的序列生成抽象句法树(AST)。在实施例中,DSL AST基于包括动态剖析信息的运行时反馈循环被最优地重写。
与通用编程语言不同,DSL通常具有狭窄(即,特殊)用途,或多或少地限于特定主题领域,诸如特定技术问题。因为DSL的范围比通用语言更窄,所以DSL的语法可以小得多(即,更简单)。因此,与通用工具相比,诸如标记器、解析器、语义分析器、代码生成器、优化器、运行时剖析器和/或解释器之类的DSL工具可以大大简化。
此类精益工具本身应当具有更小的代码库,具有更简单的控制和数据流。使用本文的优化技术,此类精益工具(作为可优化工件本身)变得更加精益,诸如当类型推断排除了DSL解释器自己的一些逻辑时。被排除的解释器逻辑适用于死代码消除,这产生更小和更快的DSL解释器,诸如通过Futamura投影,如本文所呈现的。
Futamura投影是在解释(即,解释器操作)期间缩小和加速解释器在存储器中的代码库的方式。如本文稍后解释的,精益和优化的工具(诸如DSL解释器,尤其是通过Futamura投影)可以节省计算机资源(诸如时间和暂存空间)。优化的DSL解释器可以变得如此之小,以至于每个查询都可以有仅针对该查询被独立优化的自己的DSL解释器实例。随着跨数据库记录(诸如在数据库表或中间结果集中)的优化开销(即,时延)的分摊,可优化的DSL解释器可以很大程度上加速自组织查询。因此,根据本文的技术,可优化的DSL解释器可以容易地嵌入到DBMS的查询引擎中。
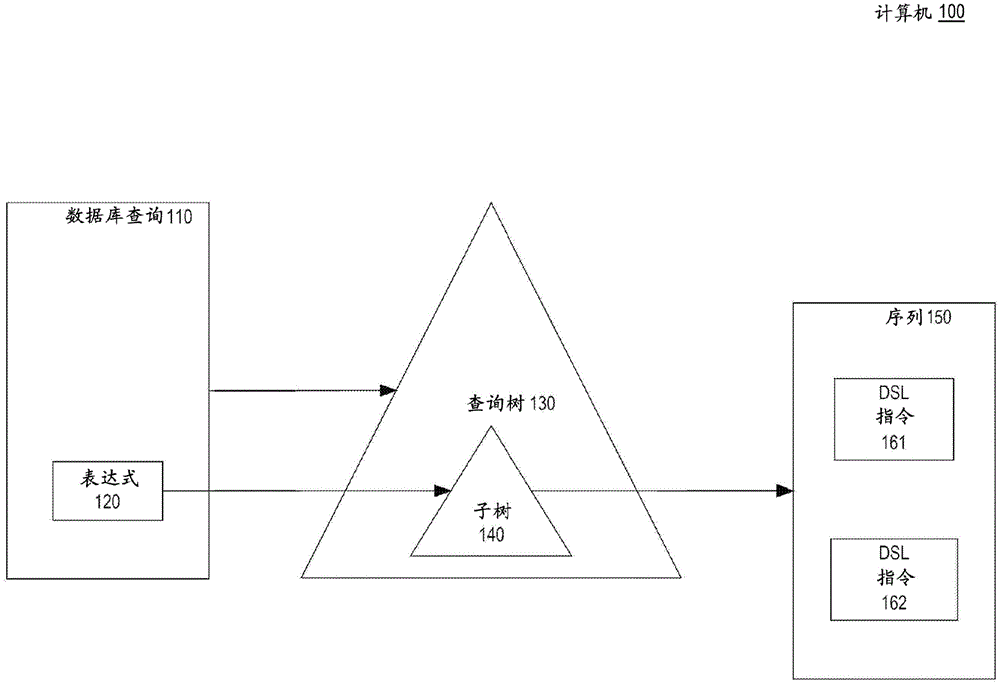
1.0示例计算机
图1是描绘实施例中的示例计算机100的框图。计算机100基于通过利用诸如部分评估和即时(JIT)编译之类的优化翻译成域特定语言(DSL)进行解释来优化数据库查询110的执行。更多优化将在后面呈现。
计算机100可以是至少一个计算机,诸如机架式服务器,诸如刀片、个人计算机、大型机、虚拟计算机或其它计算设备。当计算机100具有多个计算机时,多个计算机通过通信网络互连。
虽然未示出,但计算机100可以托管接收和执行数据库查询110的数据库管理系统(DBMS),该数据库查询110可以包含关系代数,诸如根据诸如结构化查询语言(SQL)之类的数据操作语言(DML)。例如,DBMS可以是包含(一个或多个)数据库的关系DBMS(RDBMS),而(一个或多个)数据库包含关系表的。代替地,DBMS可以包含(一个或多个)其它数据存储库,诸如列存储库、元组存储库(诸如资源描述框架(RDF)三元存储库)、NoSQL数据库和/或Hadoop文件系统(HDFS)(诸如具有Hadoop和/或Apache Hive)。
数据库查询110可以是自组织查询或其它DML语句,诸如准备好的(即,批处理的)语句和/或创建、读取、更新和/或删除(CRUD)的语句。DBMS可以接收并解析数据库查询110以创建查询树130,该查询树130以可以由DBMS的数据库服务器执行(例如,解释)以应用关系代数的格式表示数据库查询110。
查询树130包含操作节点作为布置为逻辑树数据结构的树节点(未示出),诸如在查询解析器(未示出)解析数据库查询110时(诸如在查询计划之前)创建。根据本文的(一个或多个)其它图,DBMS可以包含查询引擎,该查询引擎包含生成数据库查询110的越来越快的表示的序列的阶段的管线。该管线的可生性阶段中的一些可以按以下管线排序包括:查询树130、域特定语言(DSL)指令序列150和用于DSL指令序列150的抽象句法树(AST),如(一个或多个)其它图中所示。
因此,DBMS可以生成查询树和DSL AST。因此,可以生成两个逻辑树,每个逻辑树表示数据库查询110中的一些或全部。
在实施例中,查询树130也是AST,但是用于与DSL AST不同的语言,诸如SQL。在任何情况下,查询树130和DSL AST都包含树节点。在本文中,查询节点是查询树中的任何树节点。句法节点是DSL AST中的任何树节点。DSL和AST将在后面呈现。在实施例中,查询树130可以是查询计划。
两种树都可以分层布置它们的树节点。树节点可以有另一个树节点作为它的父节点,该父节点可以有更多的子节点。树可以具有间接共享同一祖先节点的节点的子树,诸如140。没有子节点的树节点是叶子节点。
每个查询节点可以执行数据库查询110的一部分,使得查询树130中所有节点的操作完成数据库查询110。数据库查询110包含表达式120,其可以是逻辑和/或算术表达式,诸如具有许多项和运算符的复合表达式,诸如在数据库查询110的子句中,诸如用于过滤,诸如SQL WHERE子句。查询子树140表示表达式120并由其生成。
在实施例中,DBMS可以直接执行一些或全部查询节点来完成数据库查询110。在实施例中,DBMS替代地或附加地生成诸如161-162(诸如命令式语句)之类的DSL指令的(一个或多个)序列(诸如150),诸如DSL源逻辑文本的行。例如,DSL序列150可以是DSL脚本,诸如存储在文件中或随机存取存储器(RAM)中。多语言引擎存根语言(MSL)是特定DSL的示例实施方式,它基于本文稍后呈现的若干创新技术和机制。
一个DSL序列可以表示整个查询树130并从其生成,或者,对于部分评估,(一个或多个)DSL序列可以表示查询树130的(一个或多个)相应子树或各个查询节点并从其生成。因此,DSL序列150表示子树140和表达式120两者,并且直接从子树140生成,因此间接地从表达式120生成。因此,DBMS可以执行或者子树130或者DSL序列150以实际应用表达式120。
例如,诸如查询计划器之类的(例如,急切的)优化器可以或多或少地立即生成DSL序列150,并且一旦生成DSL序列150就切换到使用它。在实施例中,优化器可以等待DSL序列150的生成完成。懒惰的优化器可以决定是继续操作子树130还是代替地(例如,暂停以)生成DSL序列150,诸如甚至在查询结果(未示出)已经开始生成之后。
DSL序列130最终或甚至最初可以比子树130运行得更快,诸如根据本文稍后呈现的渐进式和/或推测性优化。因此,即使生成DSL序列150带来诸如时延之类的开销,但这些成本可以在例如数百万行的数据库表中分摊。例如,用于查询树130或子树140的DSL序列可以被高速缓存,正如查询树130或子树140可以被高速缓存一样。
如本文稍后所呈现的,可以存在附加级别的代码生成,诸如将DSL序列150编译成字节代码和/或机器代码,并且此类进一步生成的代码也可以被高速缓存、推测性和/或部分评估,并且那些优化可以是协同的,如本文稍后讨论的。例如,可以已经为子树140生成了直接可执行的机器代码。但是,查询树130的另一个子树可以仍然只有字节码用于解释。
在实施例中,DBMS可以维护诸如表基数(即,行数量)之类的统计元数据,这可以促进成本计算以预测分摊是否可以证明特定优化的合理性。在实施例中,可以对数据库表列进行运行长度编码,并且成本计算基于(一个或多个)运行长度。
2.0示例DSL生成过程
图2是描绘在实施例中计算机100基于通过利用诸如部分评估和JIT编译之类的优化翻译成DSL进行解释来优化数据库查询110的执行的流程图。参考图1讨论图2。
步骤202生成表示数据库查询110的查询树130,该数据库查询110包含由子树140表示的表达式120。例如,计算机100的DBMS诸如在根据开放数据库连接(ODBC)在网络套接字上接收诸如文本语句的(例如,自组织的)数据库查询110。DBMS包含解析器,它对数据库查询110进行标记和解析以生成查询树130及其查询节点。
步骤204生成直接表示查询子树140并间接表示查询表达式120的DSL指令的序列150。例如,诸如根据访问者软件设计模式,DBMS可以遍历子树140的查询节点以生成DSL指令161-162。例如,DSL指令161-162中的每一个可以从子树140的相应查询节点生成。在一些情况下,可以为同一个查询节点生成多个(例如,连续的)DSL指令。稍后在本文中呈现用于查询表达式120的DSL指令序列150的工作示例实施方式。
步骤206在执行数据库查询110期间执行DSL指令序列150以评估查询表达式120。例如,DBMS可以将DSL指令序列150编译成字节代码或机器代码以在步骤206中执行,诸如本文稍后讨论的。
3.0DSL嵌入
图3是描绘实施例中的示例DBMS 300的框图。在查询树340中,DBMS 300用合成的查询节点366替换子树350,合成的查询节点366具有对子树350的部分评估。DBMS 300可以是由计算机100托管的DBMS(未示出)的实施方式。
DBMS 300从接收到的包含DML表达式320的数据库查询310生成查询树340,子树350由DML表达式320生成。子树350的重复解释可以慢并且可以立即或最终成熟以进行部分评估。例如,懒惰阈值在后面讨论。DBMS 300从子树350生成DSL指令序列370。将DSL指令序列370改型到查询树340中可以如下发生。
可以生成合成的树节点366作为用于DSL指令序列370的适配器(例如,容器)。虽然子树350可以包含许多查询节点(诸如361-362),但是子树350具有一个查询节点(未示出)作为其根。在查询树340中,DBMS 300用单个查询节点366替换子树350。因此,查询树340的执行将引起DSL指令序列370而不是子树350的执行。
在实施例中,子树350的叶子节点(诸如363-365)被特别处置。与在从查询树340移除之后可以被丢弃或高速缓存的查询节点361-362不同,叶子节点363-365代替地重新找父节点以成为合成的树节点366的子节点。在实施例中,叶子节点363-365可以同时是查询节点361或362和366的子节点。
数据库查询310可以访问表列331-332,诸如在CRUD表达式中,诸如用于过滤。在DSL指令序列370内,可以为表列331-332中的每一个分别生成局部变量声明,诸如381-382。因此,局部变量的语义可以被利用,如由特定DSL定义的,并且可以包括逻辑代数、数据类型和词汇范围的问题,诸如可见性和寿命。
数据类型可以或多或少普遍地强加在数据上,诸如对于表列、DML表达式320的项和/或局部变量。数据类型引起(例如,推测性)优化。例如,一些数据类型消耗更少的存储空间,用更少的指令执行,和/或利用特殊硬件进行加速(诸如寄存器、向量硬件和/或协处理器)。因此,DSL指令序列370可以包含特定于类型的指令(诸如390),这些指令如果应用于错误的(例如,非预期的)数据类型的数据,那么可能误动,如本文稍后讨论的。
4.0示例DSL嵌入过程
图4是描绘在实施例中DBMS 300在查询树340中用合成的查询节点366替换子树350的流程图,该合成的查询节点366具有子树350的部分评估。参考图3讨论图4。
图4的过程在可以快速相继发生的两个阶段中发生。步骤402和404生成DSL指令序列370。步骤406A-B将DSL指令序列370插入查询树340中。
步骤402可以读取DBMS 300中数据库的数据库模式和/或数据库字典以发现示意性细节,诸如表、它们的列以及表之间的明确或暗示关系。步骤402可以替代地或附加地从用于查询树340的查询优化器、查询计划器和/或语义分析器接收这种信息。因此,步骤402检测到查询表达式320引用表列331-332。局部变量声明381-382被生成为DSL指令,其可以提供诸如访问和/或在相应表列331-332中键入实际数据之类的功能性。
步骤404生成特定于类型的指令。例如,表列331或332的数据类型可以如针对步骤402的其它示意性细节所描述的那样获得。例如,查询节点361-362可以已经专门用于相应的数据类型,和/或查询节点361-362可以具有指示相应数据类型的元数据。
例如,表列331可以存储应当与数字不同地被处理的文本。因此,步骤404生成专门用于文本处理的特定于类型的DSL指令390。在未示出的示例中,当DSL指令382和390实际上是相同的单个指令时,步骤402和404作为单个步骤一起发生以生成同一个单个指令。换句话说,局部变量声明382可以是特定于类型的。例如,特定的DSL可能是强类型的(strongly typed)。
步骤406A生成包含DSL指令序列370的合成的查询节点366。例如,DSL指令序列370可以驻留在RAM缓冲区中,并且查询节点366可以将地址、指针、句柄和/或偏移量存储到和/或存储在那个缓冲区中。
如本文其它地方所解释的,AST、字节代码和/或机器代码可以在不同时间已经或最终从DSL指令序列370直接或间接生成。这种生成的素材可以动态地附接到查询节点366,诸如通过存储器指针,使得(例如,重复地)操作查询节点366总是执行最新生成的实施方式。因此,操作查询节点366有时可以解释字节代码而其它时候直接执行机器代码。
在任何情况下,查询节点366都应当在调用查询节点366之前被插入到查询树340中。在查询树340中,步骤406B用查询节点366替换子树350。因此,查询树340在某种程度上是可变的,诸如用于优化。
5.0部分评估
图5是描绘实施例中的示例DBMS 500的框图。DBMS 500展示了诸如利用部分评估的渐进式优化。例如,DBMS 500解析DSL指令序列520以生成DSL AST 530,该DSL AST 530随后可以被最优地重写并且可以从其立即生成初始编译551并进一步细化为优化的编译552,如下所示。DBMS 500可以是计算机100的DBMS(未示出)的实施方式。
在接收到数据库查询510后并且虽然未示出,但是可以从数据库查询510生成查询树。DSL指令序列520可以从那个查询树的一些或全部生成。DSL指令序列520可以被解析以生成DSL AST 530。因此,可以生成两个树,每个树表示数据库查询510的至少一部分。
在未示出的更高效的实施例中,不生成DSL指令序列520,而是直接从查询树的一些或全部生成DSL AST 530。在不太高效的实施例中,数据库查询510是DML中的语句,它也是可扩展标记语言(XML),诸如SQL/XML或XQuery,使得可扩展样式表语言(XSL)可以被应用于数据库查询510的部分或全部以生成DSL指令序列520。
在实施例中,Oracle Truffle可以解析DSL指令序列520以生成DSL AST 530。在实施例中,可配置的解析器可以使用定义特定DSL的形式语法。
Oracle技术堆栈可以包括Truffle、Graal、Substrate和Java虚拟机(JVM)。如本文所讨论的,这种工具链提供了稳健的优化,诸如部分评估、AST重写、即时(JIT)编译、动态分析、数据类型推断、推测性逻辑和Futamura投影。
例如,JVM可以推迟垃圾收集(GC)直到方便,而C程序通常不会。例如,在最坏的情况下,C的释放(free)函数和C 的删除(delete)运算符对于标准库在前台(即,执行的关键路径)实际发生的堆管理可能有些不稳定。
JVM GC技术(诸如并行GC和分代清除)以及热点即时(JIT)编译在一些情况下会引起比C更快的执行。因此,与最先进的数据库操作相比,基于JVM的数据库查询引擎可能(例如,很快或最终)构成对丰富芯片电路系统的更好使用。
代码的优化/生成可以是急切的或懒惰的并且发生在前台(即,关键路径)或后台(例如,备用CPU核心或线程)。数据库可以存储鼓励迭代的规则化数据,诸如表行。因此,数据库查询510的执行,即使是一次,也可能需要大量重复,诸如利用表扫描。在执行数据库查询510时,可以或多或少地分阶段生成渐进式优化。那些优化/生成阶段可以或可以不被只有足够重复才能跨越的懒惰阈值分隔,诸如利用热点。
懒惰优化有两个主要益处。首先,惰性实现了优先化,使得首先优化热点,并且永远不需要优化未使用的代码。其次,如本文后面所讨论的,惰性促进动态优化。但是,急切的优化只有静态优化。例如,数据类型推断和推测性逻辑可以依赖于本文稍后讨论的惰性。例如,惰性可以实现优化反馈循环,而急切的优化则不能。
例如,查询结果570可以在完成数据库查询510时生成。查询结果570可以增量生成,诸如按顺序生成的部分574-576。首先,可以仅生成查询树并直接解释以处理表的一些行以生成部分574。与生成结果部分574并发地,可以从查询树生成DSL AST 530,并且可以从DSL AST 530的一些或全部生成字节代码和/或机器代码的初始编译551。初始编译551可能是便利的(即,朴素的),具有有限的优化或没有优化,诸如仅静态优化。
当初始编译551准备好(即,生成)时,查询树的直接解释可以停止,并且初始编译551可以在时间T1执行以处理同一个表的更多一些行以生成结果部分575。初始编译551可以伴随有机制(例如,仪器),以便在初始编译551在T1期间执行时可以记录动态简档数据560。因此,初始编译551的执行生成结果部分575和动态简档数据560。动态简档数据560可以包括诸如用于数据类型推断以生成推测性逻辑的观察到的数据类型之类的细节,以及诸如具有基本块或各个指令之类的执行频率,诸如用于死代码消除或热点检测(诸如紧密循环)。
在时间T2处,在以下场景中有可能进行进一步优化,诸如生成优化的编译552作为初始编译551的替换。例如,优化的编译552可以具有密集的静态优化。例如,编译551-552的生成可以在单独的处理器核心上被同时发起,而初始编译551完成生成并首先投入使用。在另一个示例中,动态简档数据560可以提供生成优化的编译552所需的反馈,编译551-552在不同时间直接从DSL AST 530生成。在另一个示例中,优化的编译552是基于动态简档数据560和/或辅助静态优化(诸如利用窥孔)的初始编译551的细化。
利用根据动态简档数据560的数据类型推断,优化的编译552可以包括推测数据类型的推测性逻辑590。当类型推测被证明是错误的时,推测性逻辑590可以伴随着用于去优化的保护。例如,初始编译551可以被高速缓存,然后如果推测性逻辑590无效,那么恢复。否则在时间T3处,优化的编译552成功执行以处理同一个表的更多行以生成结果部分576。因此,可以为数据库查询510中的同一个DML表达式生成结果部分574-576的全部,但是每个由相应的(例如,非常)不同生成的实施方式生成。例如,部分574可以由DSL AST 530的解释产生;部分575可以由字节代码解释生成;而部分576可以由机器代码的直接执行来生成。
DBMS 500的独特之处在于它能够沿着优化/生成管线向后传播运行时反馈,并将其返回到任何管线阶段,包括一直返回到最早阶段。现有技术可以使用低级虚拟机(LLVM)进行优化,其不具有这种能力。例如,数据类型推断和热点检测(诸如对于动态简档数据560)可以向后传播足够远,以进行创新优化,诸如重写DSL AST 530或甚至重新生成DSL指令序列520。这种深度反馈,尤其是当与部分评估组合时,可以实现彻底的优化,诸如本文稍后解释的Futamura投影。
为了进一步优化,优化/生成管线的后期阶段可以模糊早期阶段人为强加的结构边界。例如,DSL AST 530包含或多或少地反映数据库查询510的语义的句法节点,诸如541-542。例如,数据库查询510的单独子句可以由DSL AST 530的单独子树表示。
但是,优化的编译552的优化/生成可以具有基于忽略人工边界(诸如查询节点、句法节点541-542以及查询树或DSL AST 530的子树)的密集优化。例如,优化的编译552可以包含机器或字节代码指令的序列580,其将用于句法节点541的指令583和585与用于句法节点542的指令584和586交织。因此,DSL AST 530在指令序列580内可以或多或少地被模糊(即,丢失)。
6.0示例优化过程
图6是描绘在实施例中DBMS 500直接或间接从DSL指令序列520生成编译551-552的流程图。参考图5讨论图6。
DSL AST 530的生成和使用具有示范意义。取决于实施例,从DSL AST 530或在不创建DSL AST 530的情况下直接从DSL指令序列520生成诸如551之类的编译。
步骤601编译DSL AST 530以生成初始编译551,该初始编译551可以是对字节代码和/或机器码的朴素编译,而几乎没有优化。
步骤602-603在时间T1处并发地发生。步骤602执行初始编译551以生成查询结果570的部分575。当初始编译551执行时,步骤603记录初始编译551的动态简档数据560。例如,步骤603可以记录用于类型推断的观察到的数据类型和用于检测热点的逻辑频率。
在时间T2处,步骤604基于动态简档数据560生成优化的编译552。在一个示例中,将动态简档数据560应用于初始编译551以生成优化的编译552。在另一个示例中,动态简档数据560和DSL AST 530都被用于生成优化的编译552。在任一情况下,步骤604都可以使用动态简档数据560进行优化分析,诸如类型推断和/或热点检测。
在时间T3处,步骤605执行优化的编译552以生成结果部分576。优化的示例(诸如用于结合到优化的编译552中)如下。
7.0附加优化
图7是描绘实施例中由DBMS 500进行优化的示例的流程图,诸如用于结合到优化的编译552中。参考图5讨论图7。
步骤701生成对多个树节点的处理进行交织的指令序列。实施例可以在生成指令的任何优化/生成管线阶段应用交织。例如并且虽然未示出,但是数据库查询510可以被解析为查询节点的查询树。可以从每个查询节点生成相应的(一个或多个)DSL指令,并且用于不同查询节点的DSL指令可以被交织。例如,可以将来自多个查询子树的局部变量声明提升到DSL指令序列520的开头。
在所示的另一个示例中,可以从每个句法节点541-542生成相应的字节代码或机器代码,并且用于不同句法节点的那些代码可以被交织。例如,代码生成器可以通过分散(即,分解)用于句法节点541的存储器-总线密集型代码的集群以对用于句法节点542的计算进行交织来对指令进行重新排序。在另一个重新排序示例中,句法节点541-542的一些指令可以变得聚集在一起,诸如对于当来自RAM的共享数据在寄存器中临时可用时。
步骤701可以或可以不仅基于静态分析而发生。但是,步骤702-706具有可以要求分析动态简档数据560的动态优化,例如用于类型推断。
步骤702在优化的编译552、DSL AST 530和/或DSL指令序列520中实现类型特化。例如,指令583可以专门用于文本处理,诸如根据类型推断。
用于类型特化的动机包括精简以节省时间和/或空间。例如,步骤703选择比原始(即,通用)类型需要更少存储空间的子类型。例如,指示日历月份的整数变量可以从机器字降级为字节。同样,数据库表列可以是字典编码的,并且其编码字典可以暗示最多需要几个位或字节。例如,当字典只有几十个键时,一个字节有足够的空间来存储任何值。在实施例中,编码字典本身存储在数据库模式或数据库字典中。
步骤704A基于推断的类型生成推测性逻辑590。例如,字节可以足够宽,以存储迄今为止针对特定变量观察到的任何值。因此,推测性逻辑590将那个变量视为字节。
但是,推断的类型最终可能被违反。例如,那个特定字节变量最终可能遇到需要更多字节来存储的值。因此,当防护检测到违(即,大)值时,会引起步骤704B。步骤704B对优化的逻辑552进行去优化。例如,初始编译551可以被重新生成或从高速缓存中检索。
步骤705消除控制流分支,诸如用于消除死代码。例如,类型推断可以揭示数值变量的所有值都不为零。因此,可以消除检测和专门处置除以零的算术除法的逻辑。
类型推断由多态性驱动,其中相同的源逻辑可以处理不同实际类型的值。诸如继承和/或鸭子类型(duck typing)之类的面向对象技术鼓励多态性,对其而言诸如虚拟方法的动态分派之类的机制是可可用的。因此,调用者可以在不知道方法可以有多种实施方式的情况下调用该方法。
基于thunk(双形式转换)、trampoline(蹦床)或分派表的技术可以提供选择和调用方法的特定实施方式所需的间接性。类型推断促进对方法的特定实施方式的急切选择,这是高效的。因此,步骤706可以重写逻辑以直接调用特定实施方式而不是遍历间接结构。
例如,步骤707可以通过将所选择的实施方式直接内联(即,嵌入)到调用者的逻辑中来更进一步。例如,蜘蛛可以是动物的子类型,其腿计数方法总是返回八。因此,字面常量八可以内联到其动物都是蜘蛛的调用者中,如由类型推断确定的。
例如,步骤708可以通过操作多态内联高速缓存更进一步,这在数据类型推断可以将变量缩窄到几个不同的数据类型但不能缩窄到单个类型时会有所帮助。多态内联高速缓存作为增量增长的分派表操作,该分派表最初是空的,并且可以在最终遇到相应子类型时添加和保留与方法的特定实施方式的绑定。如果那个分派表对要存储的绑定数量有上限,那么分派表将停止增长,但不会驱逐已高速缓存的绑定。调用相同方法的每个调用站点可以有其自己相应的多态内联高速缓存,即使不同调用站点以相同的名义(即,抽象)方法为目标,其内容也可以不同(即,区分)。
8.0程序变换
图8是描绘在实施例中由DBMS 500进行的加速解释和/或编译的执行的两个程序变换的示例的流程图。参考图5讨论图8。
步骤802描绘了基于运行时反馈的DSL AST优化。例如,DSL AST 530可以基于动态简档数据560被重写(即,优化)。例如,动态简档数据560可以指示控制流分支在迄今为止迭代超过1000个表行之后保持未使用。DSL AST 530可以被重写,而这种死代码被消除并被用防护代替。如果防护最终遇到对错过的控制分支的需要,那么可以恢复先前的DSL AST 530(例如,重新生成或来自高速缓存中),或者可以从先前的DSL AST 530复制错过的分支并插入到有缺陷的当前DSL AST 530中。
当DSL AST 530就绪时,它的字节代码和/或机器代码可以来自高速缓存或被(重新)生成,或者急切地或者懒惰地。代替等待代码生成完成,DBMS 500可以通过直接解释来继续执行DSL AST 530,这可以在代码在后台生成时同时发生。即,DBMS 500可以遍历和操作句法节点541-542以继续处理表行。
工程师可能预期DSL AST解释是慢的。但是,自身可以优选地进化的DSL AST解释器可以积累许多突变(即,优化)。例如,防护可以注意到一种类型推断的到期,但这不需要使大多数其它类型推断失效。通过部分评估,解释器的还原在范围上可以是非常有选择性的。
通常,例如,当推测性逻辑到期时,大多数解释器应当保持不变。因此,诸如Truffle、Grail和Substrate之类的优化器堆栈可以在优化DSL AST解释器上投入大量资金,并确信大部分投资将保留用于分摊。例如,解释器本身要进行动态分析,诸如部分评估、特化和其它(例如,推测性)优化以及JIT编译。
DSL AST解释器本身可以基于动态简档数据560进行优化,这会使得解释器或多或少变得专门用于数据库查询510,诸如当每个查询具有其自己的DSL AST解释器实例时,该实例可以被独立优化并在完成查询之后立即丢弃。实施例高速缓存解释器实例以防查询被重用。
如本文前面所解释的,与通用编程语言不同,DSL通常具有狭窄(即,特殊)用途,或多或少限于特定主题领域,诸如特定技术问题。因为DSL的范围比通用语言更窄,所以DSL的语法可以小得多(即,更简单)。因此,与通用工具相比,诸如标记器、解析器、语义分析器、代码生成器、优化器、运行时分析器和/或解释器之类的DSL工具可以大大简化。
此类精益工具本身应当具有更小的代码库,具有更简单的控制和数据流。使用本文的优化技术,此类精益工具(作为可优化工件本身)变得更加精益,诸如当类型推断排除了DSL解释器自己的一些逻辑时。被排除的解释器逻辑适用于死代码消除,这产生更小和更快的DSL解释器,诸如通过Futamura投影。
Futamura投影是在解释(即,解释器操作)期间缩小和加速解释器在存储器中的代码库的方式。自然精益的DSL解释器通过Futamura投影进一步优化可以节省计算机资源(诸如时间和暂存空间)。优化的DSL解释器可以变得如此之小,以至于每个查询都可以有自己的DSL解释器实例,该实例仅针对该查询被独立优化。
随着跨数据库记录(诸如在数据库表或中间结果集中)的优化开销(即,时延)的分摊,可优化的DSL解释器可以很大程度上加速自组织查询。因此,根据本文的技术,可优化的DSL解释器可以容易地嵌入到DBMS的查询引擎中。但是,基于C/C 的最先进的数据库操作可以或多或少不可能以创新的方式(诸如Futamura投影)进行优化。
适合特定查询的解释器特化是Futamura投影的示例,其中沿着强度的谱有几个渐进程度(即,投影),从谱的一端优化解释器到谱的另一端将优化的解释器重铸到编译器中,以优化编译器。步骤804A-C至少实现第一度Futamura投影(即,解释器优化)。步骤804A和804C示出DSL AST解释器可以在解释器在步骤804B中经历Futamura投影之前和之后处理一些表行。Futamura投影效率可以取决于表行的大规模迭代以分摊优化开销(例如,初始时延)。
9.0示例实施方式
这个示例实施方式基于Truffle、Graal和Substrate作为软件层,它们按如下方式协作。在这个示例中,特定DSL是用于SQL表达式的多语言引擎存根语言(MSL)。MSL AST最初被解释(即,直接操作)。
当AST节点的执行计数达到预定义阈值时,Truffle通过调用Graal编译器来触发部分评估。通过编译由AST树表示的程序及其解释器,实现了第一次Futamura投影。输出是具有去优化点的高度优化的机器代码。这些点被实现为检查点,在那些点处,当推测性假设不再成立时触发去优化。去优化意味着控制从编译后的代码转移回AST解释器,然后在那里将专用节点恢复为更通用的版本。
不是像LLVM那样解释MSL或生成代码并静态编译它,可以通过充分利用Truffle框架来评估MSL。SQL标准定义了用于SQL语言的语法并且随后定义了用于SQL表达式的语法。因此,SQL表达式可以通过语言来描述。因此,SQL表达式可以被实现为Truffle语言,诸如MSL。
通过将SQL表达式实现为Truffle语言,可以充分利用Truffle框架和Graal编译器的优势。具体而言,包括:
·将SQL表达式识别为可以“truffelized”的语言的总体思路。新语言是多语言引擎存根语言(MSL);
·MSL生成器:对于给定表达式树生成MSL代码的算法;
·MSL解析器:解析MSL代码并实例化对应MSL Truffle句法节点的算法;
·如何将Truffle和Graal编译器框架嵌入DBMS的体系架构。特别地,引入了新的SQL表达式节点,该节点负责在查询编译阶段存储MSL代码,并在查询执行阶段执行MSL代码。新的SQL表达式节点将替换对应SQL表达式树的根。
MSL生成器将给定的SQL表达式树翻译成MSL代码。MSL代码是在针对给定SQL表达式树的查询编译阶段生成的。MSL代码存储到新颖的表达式查询节点的专用字段中。在查询执行期间,当评估表达式节点时,DBMS调用MSL解析器来解析MSL代码以实例化对应的MSL Truffle AST节点。
此时可以评估AST节点。在SQL执行期间,收集可能导致类型特化的运行时简档。在某个阈值之后,当SQL表达式被执行多次时,Graal触发部分评估。在这个步骤期间,Graal编译器产生优化的机器代码。积极的代码内联是此处应用的优化技术的一个示例。通过内联代码,Truffle节点沿着表达式操作数管线被融合,该管线强制数据局部性并去除了调用开销。
通过应用那些策略,去除了传统的解释开销。本文的方法利用Truffle的自我优化特征,如基于收集的运行时简档的类型特化或分支消除。即时编译被推迟到Graal认为值得的时候。在这种点处,Graal可以利用已经进行的代码特化并将它们包括到部分评估步骤中。这样做的一个有益副作用是,与LLVM方法相比,这种方法不必支付高昂的前期编译成本。但是那些成本只是被推迟并且在Graal触发后台编译线程时产生。
使代码特化依赖于先前做出的特化假设的正确性。但是,如果输入数据的特点改变,那么假设可能不再成立。因此,特化代码需要是非特化的。但是,Graal并没有中止查询,而是提供了两种替代方案:(1)或者在解释期间恢复到更通用的代码路径,或者,如果已经编译,(2)Graal提供去优化。这种自适应方法确保那些类型的场景的正确性和改进的性能。
此处提出的方法由两个阶段组成:MSL计划生成和MSL计划执行。这些阶段由对应的RDBMS阶段触发:计划生成和计划执行。在RDBMS计划生成期间,生成SQL表达式树。在SQL表达式树的生成结束时,RDBMS检查是否可以为对应的SQL表达式树生成MSL计划。
在一些情况下,RDBMS无法生成等效的MSL计划。最常见的原因是某个操作在MSL中还没有实现。在那些情况下,RDBMS可以会接管附接到不可行操作的子表达式树。
对于生成等效MSL计划的大多数场景,SQL(子)表达式树的根节点由SQL表达式节点替换。从根节点开始,除叶子节点外,作为根节点的后代的所有SQL表达式树节点都被替换为一个且相同的SQL表达式节点。SQL表达式树的叶子作为直接子节点附接到SQL表达式节点。
生成的MSL计划存储在SQL表达式节点中。在评估SQL表达式节点时的RDBMS执行阶段,首先评估其所有子节点。之后,MSL计划由Graal解析、实例化和执行。
以下是示例SQL查询。它计算将数字1添加到empno列的简单SQL表达式。这需要empno 1的简单SQL表达式。
select empno 1 from emp;
下面以JSON格式示出用于那个查询的MSL计划。
以下计划可以给出上面刚示出的MSL的更好思路。以下计划是人类可读的形式。
查看上面的计划,可以确定MSL计划的几个MSL元素:
·STUB FUNCTION。存根函数有VARIABLES部分和BODY部分
·VARIABLES:变量部分声明MSL程序的局部变量。
·BODY:MSL程序的实际实施方式可以在其主体中找到。主体部分如下。
ο第一个命令块将输入列指派给MLRIRVARIABLE列0。在这个示例中,列0与SQL表达式的empno列对应。
ο第二个命令块特化输入。实施例具有Oracle Number实施方式。由于Oracle Number是最多22个字节的可变长度数据类型,因此计算可以非常计算密集。DBMS为Oracle Number提供十进制标度二进制(DSB)特化,其性能可与整数特化的性能相媲美。如果给定输入的底层数据可以由DSB表示,那么DBMS能够特化到DSB的输入。这将显著提高性能。无论输入是用专门的形式还是用Oracle Number表示,它都被指派给特化为0的列0
ο第三个命令块指定如何计算结果。在此OPTTAD象征着求和运算。输入是特化为0的列0和常数1。结果指派给变量OPTTAD_cse_0_0。
ο最后一个命令块对结果进行去特化并将其存储在RDBMS预期以Oracle Number形式的结果的缓冲区中。
这种示例实施方式有产生上面所示的MSL代码的MSL代码生成器。
SQL表达式树可以具有以下类型层次结构。
οSQLEXPRESSION:每个SQL表达式节点都是SQLEXPRESSION类型,但有具体的子类型:
οSQLEXPRESSIONNODE:那些是SQL表达式树的内部节点。示例是如SUM或MULTIPLICATION的二元运算。
οSQLCOLUMNNODE:是SQL表达式树的叶子节点并且表示SQL表达式的输入。
οSQLCONSTANTNODE:是叶子节点并且表示像前面示例中的“1”一样的常量。
算法产生几个MSL IR(多语言引擎存根语言中间表示)元素。此处是它的类型层次结构。
οMSLIRVARIABLE
οMSLIRCOLUMNVARIABLE
οMSLIRSPECIALIZEDVARIABLE
οMSLIEXPRESSION
οMSLIRREADEXPRESSION
οMSLIROPERATIONEXPRESSION
οMSLIRASSIGNVALUESTMT
οMSLIRCOLUMNTONUMBERSPECIALIZATIONEXPRESSION
οMSLIRCOLUNTODOUBLEEXPRESSION
οMSLILITERLEXPRESSION
可以通过调用COMPILESQLEXPRESSION来生成MSL计划,如下面所给出的。因此,调用ANALYZESQLEXPRESSION(如下)以自上而下地分析SQL表达式树。取决于SQL表达式节点类型,调用不同的子方法。
ANALYZESQLEXPRESSIONNODE(如下)检查之前是否已经分析过完全相同的SQL表达式节点。如果是这种情况,那么将在FRAMESLOTVARIABLEMAP中找到对应的变量。如果可以找到,那么返回MSLIRREADEXPRESSION。如果不是,那么需要分析SQL表达式节点的子节点,然后才能继续处理SQL表达式节点。对于每个子节点,预期MSLIREXPRESSION作为返回值。如果SQL表达式节点能够消费特化的操作数,那么每个输入如果之前没有特化,那么应当被特化。这是通过调用SPECIALIZE(如下)来处置的。以下是COMPILESQLEXPRESSION的示例实施方式。
以下是ANALYZESQLEXPRESSION的示例实施方式。
一旦已经处理了输入,就生成MSLIROPERATIONEXPRESSION以通过查看GETOPERANDTYPE()来封装实际操作。对COMMONSUBEXPRESSIONELEMINATION的调用(如下)通过将结果存储到变量中来保留结果,以便在需要时可以重用它。
下面示出如何处置SQLCOLUMNNODE和SQLCONSTANTNODE。重要的是要注意ANALYZESQLCOLUMNNODE调用注册SQL表达式树的叶子节点的REGISTERSQLEXPRESSIONARGUMENT,以便稍后可以通过GENERATEEXPRESSIONOPERATOR将其作为直接子节点附接到新的表达式节点。
一旦对ANALYZESQLEXPRESSION的调用返回,就通过调用GENERATESTUBLANGUAGEFUNCTION(如下)生成MSL计划。GENERATESTUBLANGUAGEFUNCTION正在查看由ANALYZESQLEXPRESSION生成的MSLIRVARLIST和MSLIREXPLIST。
GENERATEEXPRESSIONOPERATOR生成新的MSL表达式节点,它将替换RDBMS SQL表达式树。它将SQL表达式树的叶子注册为其子节点。如前面所提到的,叶子已经由REGISTERSQLEXPRESSIONARGUMENT收集。新的SQL表达式节点将以JSON格式存储MSL计划,诸如如上文所示。
以下是ANALYZESQLEXPRESSIONNODE的示例实施方式。
以下是SPECIALIZE的示例实施方式。
以下是COMMONSUBEXPRESSIONELEMINATION的示例实施方式。
以下是ANALYZESQLCOLUMNNODE的示例实施方式。
以下是ANALYZESQLCONSTANTNODE的示例实施方式。
以下是GENERATESTUBLANGUAGEPLAN的示例实施方式。
10.0数据库概述
本发明的实施例在数据库管理系统(DBMS)的上下文中使用。因此,提供了示例DBMS的描述。
一般而言,诸如数据库服务器之类的服务器是集成的软件组件和诸如存储器、节点以及节点上用于执行集成的软件组件的进程之类的计算资源的分配的组合,其中软件和计算资源的组合专用于代表服务器的客户端提供特定类型的功能。数据库服务器控制并促进对特定数据库的访问,处理客户端访问数据库的请求。
用户通过向数据库服务器提交使数据库服务器对存储在数据库中的数据执行操作的命令来与DBMS的数据库服务器进行交互。用户可以是在与数据库服务器交互的客户端计算机上运行的一个或多个应用。多个用户在本文中也可以被统称为用户。
数据库包括数据和数据库字典,其存储在诸如硬盘集之类的持久性存储器机构上。数据库由其自己的分开数据库字典定义。数据库字典包括定义数据库中包含的数据库对象的元数据。实际上,数据库字典定义了许多数据库。数据库对象包括表、表列和表空间。表空间是用于存储各种类型的数据库对象(诸如表)的数据的一个或多个文件的集合。如果将用于数据库对象的数据存储在表空间中,那么数据库字典将数据库对象映射到保存用于数据库对象的数据的一个或多个表空间。
DBMS参考数据库字典来确定如何执行提交给DBMS的数据库命令。数据库命令可以访问由字典定义的数据库对象。
数据库命令可以是数据库语句的形式。为了使数据库服务器处理数据库语句,数据库语句必须符合数据库服务器支持的数据库语言。许多数据库服务器支持的数据库语言的一个非限制性示例是SQL,包括由诸如Oracle之类的数据库服务器支持的SQL专有形式(例如,Oracle Database 11g)。将SQL数据定义语言(“DDL”)指令发布到数据库服务器以创建或配置数据库对象,诸如表、视图或复杂类型。数据操纵语言(“DML”)指令被发布给DBMS,以管理存储在数据库结构内的数据。例如,SELECT、INSERT、UPDATE和DELETE是一些SQL实施方式中常见的DML指令示例。SQL/XML是在对象-关系数据库中操纵XML数据时使用的SQL的常见扩展。
多节点数据库管理系统由互连的节点组成,这些节点共享对同一数据库的访问。通常,节点经由网络互连,并在不同程度上共享对共享存储装置的访问,例如对一组盘驱动器和存储在其上的数据块的共享访问。多节点数据库系统中的节点可以是经由网络互连的一组计算机(例如,工作站、个人计算机)的形式。可替代地,节点可以是网格的节点,该网格由与机架上的其它服务器刀片互连的服务器刀片形式的节点组成。
多节点数据库系统中的每个节点都托管数据库服务器。服务器(诸如数据库服务器)是集成软件组件和计算资源(诸如存储器、节点以及节点上的用于在处理器上执行集成软件组件的进程)的分配的组合、专用于代表一个或多个客户端执行特定功能的软件和计算资源的组合。
可以分配来自多节点数据库系统中多个节点的资源,以运行特定的数据库服务器的软件。软件和节点中的资源的分配的每种组合都是在本文中被称为“服务器实例”或“实例”的服务器。数据库服务器可以包括多个数据库实例,其中一些或全部在单独的计算机(包括单独的服务器刀片)上运行。
10.1查询处理
查询是表达式、命令或命令集,在执行时,使服务器对数据集执行一个或多个操作。查询可以指定要从中确定(一个或多个)结果集的(一个或多个)源数据对象,诸如(一个或多个)表、(一个或多个)列、(一个或多个)视图或(一个或多个)快照。例如,(一个或多个)源数据对象可以出现在结构化查询语言(“SQL”)查询的FROM子句中。SQL是用于查询数据库对象的众所周知的示例语言。如本文所使用的,术语“查询”被用于指表示查询的任何形式,包括数据库语句形式的查询和用于内部查询表示的任何数据结构。术语“表”是指被查询引用或定义并且表示行的集合(诸如数据库表、视图或内联查询块(诸如内联视图或子查询))的任何源对象。
查询可以在(一个或多个)对象被加载时逐行地对来自源数据对象的数据执行操作,或者在(一个或多个)对象已被加载之后对(一个或多个)整个源数据对象执行操作。由一些操作生成的结果集可以让(一个或多个)其它操作可用,并且以这种方式,可以基于某些标准将结果集过滤掉或缩小范围,和/或与(一个或多个)其它结果集和/或(一个或多个)其它源数据对象联接或组合。
子查询是查询的一部分或组成部分,它与查询的其它(一个或多个)部分或(一个或多个)组成部分不同,并且可以与查询的其它(一个或多个)部分或(一个或多个)组成部分分开评估(即,作为单独的查询)。查询的其它(一个或多个)部分或(一个或多个)组成部分可以形成外部查询,其可以包括也可以不包括其它子查询。嵌套在外部查询中的子查询可以被单独评估一次或多次,同时为外部查询计算结果。
一般而言,查询解析器接收查询语句并生成查询语句的内部查询表示。通常,内部查询表示是互连的数据结构的集合,其表示查询语句的各种组件和结构。
内部查询表示可以是节点图的形式,每个互连的数据结构与节点和所表示的查询语句的组件对应。内部表示通常在存储器中生成,以用于评估、操作和变换。
硬件概述
根据一个实施例,本文描述的技术由一个或多个专用计算设备实现。专用计算设备可以是硬连线的以执行这些技术,或者可以包括数字电子设备(诸如被持久地编程为执行这些技术的一个或多个专用集成电路(ASIC)或现场可编程门阵列(FPGA)),或者可以包括被编程为根据固件、存储器、其它存储装置或组合中的程序指令执行这些技术的一个或多个通用硬件处理器。这种专用计算设备还可以将定制的硬连线逻辑、ASIC或FPGA与定制编程相结合,以实现这些技术。专用计算设备可以是台式计算机系统、便携式计算机系统、手持设备、联网设备或者结合硬连线和/或程序逻辑以实现这些技术的任何其它设备。
例如,图9是图示可以在其上实现本发明实施例的计算机系统900的框图。计算机系统900包括总线902或用于传送信息的其它通信机制,以及与总线902耦合以处理信息的硬件处理器904。硬件处理器904可以是例如通用微处理器。
计算机系统900还包括耦合到总线902的主存储器906,诸如随机存取存储器(RAM)或其它动态存储设备,用于存储将由处理器904执行的信息和指令。主存储器906还可以用于存储在执行由处理器904执行的指令期间的临时变量或其它中间信息。当存储在处理器904可访问的非瞬态存储介质中时,这些指令使计算机系统900成为被定制以执行指令中指定的操作的专用机器。
计算机系统900还包括耦合到总线902的只读存储器(ROM)908或其它静态存储设备,用于存储用于处理器904的静态信息和指令。提供存储设备910(诸如磁盘、光盘或固态驱动器)并耦合到总线902,用于存储信息和指令。
计算机系统900可以经由总线902耦合到显示器912(诸如阴极射线管(CRT)),用于向计算机用户显示信息。包括字母数字键和其它键的输入设备914耦合到总线902,用于将信息和命令选择传送到处理器904。另一种类型的用户输入设备是光标控件916(诸如鼠标、轨迹球或光标方向键),用于将方向信息和命令选择传送到处理器904并用于控制显示器912上的光标移动。这种输入设备通常在两个轴上具有两个自由度,第一轴(例如,x)和第二轴(例如,y),这允许设备指定平面中的位置。
计算机系统900可以使用定制的硬连线逻辑、一个或多个ASIC或FPGA、固件和/或程序逻辑(它们与计算机系统相结合,使计算机系统900成为或将计算机系统900编程为专用机器)来实现本文所述的技术。根据一个实施例,响应于处理器904执行包含在主存储器906中的一个或多个指令的一个或多个序列,计算机系统900执行所述的技术。这些指令可以从另一个存储介质(诸如存储设备910)读入到主存储器906中。包含在主存储器906中的指令序列的执行使得处理器904执行本文所述的处理步骤。在替代实施例中,可以使用硬连线的电路系统代替软件指令或与软件指令组合。
如本文使用的术语“存储介质”是指存储使机器以特定方式操作的数据和/或指令的任何非瞬态介质。这种存储介质可以包括非易失性介质和/或易失性介质。非易失性介质包括例如光盘、磁盘或固态驱动器,诸如存储设备910。易失性介质包括动态存储器,诸如主存储器906。存储介质的常见形式包括例如软盘、柔性盘、硬盘、固态驱动器、磁带或任何其它磁数据存储介质、CD-ROM、任何其它光学数据存储介质、任何具有孔图案的物理介质、RAM、PROM和EPROM、FLASH-EPROM、NVRAM、任何其它存储器芯片或盒式磁带。
存储介质不同于传输介质但可以与传输介质结合使用。传输介质参与在存储介质之间传送信息。例如,传输介质包括同轴电缆、铜线和光纤,包括包含总线902的导线。传输介质也可以采用声波或光波的形式,诸如在无线电波和红外数据通信期间生成的那些。
各种形式的介质可以参与将一个或多个指令的一个或多个序列传送到处理器904以供执行。例如,指令最初可以在远程计算机的磁盘或固态驱动器上携带。远程计算机可以将指令加载到其动态存储器中,并使用调制解调器通过电话线发送指令。计算机系统900本地的调制解调器可以在电话线上接收数据并使用红外发送器将数据转换成红外信号。红外检测器可以接收红外信号中携带的数据,并且适当的电路系统可以将数据放在总线902上。总线902将数据传送到主存储器906,处理器904从主存储器906检索并执行指令。由主存储器906接收的指令可以可选地在由处理器904执行之前或之后存储在存储设备910上。
计算机系统900还包括耦合到总线902的通信接口918。通信接口918提供耦合到网络链路920的双向数据通信,其中网络链路920连接到本地网络922。例如,通信接口918可以是集成服务数字网(ISDN)卡、电缆调制解调器、卫星调制解调器或者提供与对应类型的电话线的数据通信连接的调制解调器。作为另一个示例,通信接口918可以是局域网(LAN)卡,以提供与兼容LAN的数据通信连接。还可以实现无线链路。在任何此类实现中,通信接口918都发送和接收携带表示各种类型信息的数字数据流的电信号、电磁信号或光信号。
网络链路920通常通过一个或多个网络向其它数据设备提供数据通信。例如,网络链路920可以提供通过本地网络922到主计算机924或到由互联网服务提供商(ISP)926操作的数据设备的连接。ISP 926进而通过全球分组数据通信网络(现在通常称为“互联网”928)提供数据通信服务。本地网络922和互联网928都使用携带数字数据流的电信号、电磁信号或光信号。通过各种网络的信号以及网络链路920上并通过通信接口918的信号(其将数字数据携带到计算机系统900和从计算机系统900携带数字数据)是传输介质的示例形式。
计算机系统900可以通过(一个或多个)网络、网络链路920和通信接口918发送消息和接收数据,包括程序代码。在互联网示例中,服务器930可以通过互联网928、ISP 926、本地网络922和通信接口918发送对应用程序的所请求代码。
接收到的代码可以在被接收到时由处理器904执行,和/或存储在存储设备910或其它非易失性存储器中以供稍后执行。
软件概述
图10是可以用于控制计算系统900的操作的基本软件系统1000的框图。软件系统1000及其组件,包括它们的连接、关系和功能,仅仅是示例性的,并且不意味着限制(一个或多个)示例实施例的实现。适于实现(一个或多个)示例实施例的其它软件系统可以具有不同的组件,包括具有不同的连接、关系和功能的组件。
软件系统1000用于指导计算系统900的操作。可以存储在系统存储器(RAM)906和固定存储装置(例如,硬盘或闪存)910上的软件系统1000包括内核或操作系统(OS)1010。
OS 1010管理计算机操作的低级方面,包括管理进程的执行、存储器分配、文件输入和输出(I/O)以及设备I/O。表示为1002A、1002B、1002C...1002N的一个或多个应用可以被“加载”(例如,从固定存储装置910传送到存储器906中)以供系统1000执行。意图在计算机系统900上使用的应用或其它软件也可以被存储为可下载的计算机可执行指令集,例如,用于从互联网位置(例如,Web服务器、app商店或其它在线服务)下载和安装。
软件系统1000包括图形用户界面(GUI)1015,用于以图形(例如,“点击”或“触摸手势”)方式接收用户命令和数据。进而,这些输入可以由系统1000根据来自操作系统1010和/或(一个或多个)应用1002的指令来操作。GUI 1015还用于显示来自OS 1010和(一个或多个)应用1002的操作结果,用户可以提供附加的输入或终止会话(例如,注销)。
OS 1010可以直接在计算机系统900的裸硬件1020(例如,(一个或多个)处理器904)上执行。可替代地,管理程序或虚拟机监视器(VMM)1030可以插入在裸硬件1020和OS 1010之间。在这个配置中,VMM 1030充当OS 1010与计算机系统900的裸硬件1020之间的软件“缓冲”或虚拟化层。
VMM 1030实例化并运行一个或多个虚拟机实例(“访客机”)。每个访客机包括“访客”操作系统(诸如OS 1010),以及被设计为在客户操作系统上执行的一个或多个应用(诸如(一个或多个)应用1002)。VMM 1030向访客操作系统呈现虚拟操作平台并管理访客操作系统的执行。
在一些情况下,VMM 1030可以允许访客操作系统如同其直接在计算机系统900的裸硬件1020上运行一样运行。在这些实例中,被配置为直接在裸硬件1020上执行的访客操作系统的相同版本也可以在VMM 1030上执行而无需修改或重新配置。换句话说,VMM 1030可以在一些情况下向访客操作系统提供完全硬件和CPU虚拟化。
在其它情况下,访客操作系统可以被专门设计或配置为在VMM 1030上执行以提高效率。在这些实例中,访客操作系统“意识到”它在虚拟机监视器上执行。换句话说,VMM 1030可以在某些情况下向客户操作系统提供半虚拟化。
计算机系统进程包括硬件处理器时间的分配,以及存储器的分配(物理和/或虚拟)、用于存储由硬件处理器执行的指令的存储器的分配,用于存储由硬件处理器执行指令所生成的数据,和/或用于当计算机系统进程未运行时在硬件处理器时间的分配之间存储硬件处理器状态(例如,寄存器的内容)。计算机系统进程在操作系统的控制下运行,并且可以在计算机系统上执行的其它程序的控制下运行。
云计算
本文一般地使用术语“云计算”来描述计算模型,该计算模型使得能够按需访问计算资源的共享池,诸如计算机网络、服务器、软件应用和服务,并且允许以最少的管理工作或服务提供商交互来快速提供和释放资源。
云计算环境(有时称为云环境或云)可以以各种不同方式实现,以最好地适应不同要求。例如,在公共云环境中,底层计算基础设施由组织拥有,该组织使其云服务可供其它组织或公众使用。相反,私有云环境一般仅供单个组织使用或在单个组织内使用。社区云旨在由社区内的若干组织共享;而混合云包括通过数据和应用可移植性绑定在一起的两种或更多种类型的云(例如,私有、社区或公共)。
一般而言,云计算模型使得先前可能由组织自己的信息技术部门提供的那些职责中的一些代替地作为云环境内的服务层来输送,以供消费者使用(根据云的公共/私人性质,在组织内部或外部)。取决于特定实现,由每个云服务层提供或在每个云服务层内提供的组件或特征的精确定义可以有所不同,但常见示例包括:软件即服务(SaaS),其中消费者使用在云基础设施上运行的软件应用,同时SaaS提供者管理或控制底层云基础设施和应用。平台即服务(PaaS),其中消费者可以使用由PaaS的供应者支持的软件编程语言和开发工具,以开发、部署和以其它方式控制它们自己的应用,同时PaaS提供者管理或控制云环境的其它方面(即,运行时执行环境下的一切)。基础设施即服务(IaaS),其中消费者可以部署和运行任意软件应用,和/或提供进程、存储装置、网络和其它基础计算资源,同时IaaS提供者管理或控制底层物理云基础设施(即,操作系统层下面的一切)。数据库即服务(DBaaS),其中消费者使用在云基础设施上运行的数据库服务器或数据库管理系统,同时DbaaS提供者管理或控制底层云基础设施和应用。
为了说明可以用于实现(一个或多个)示例实施例的基本底层计算机组件而呈现的上述基本计算机硬件和软件以及云计算环境。但是,(一个或多个)示例实施例不必限于任何特定的计算环境或计算设备配置。代替地,根据本公开,(一个或多个)示例实施例可以在本领域技术人员将理解为能够支持本文呈现的(一个或多个)示例实施例的特征和功能的任何类型的系统体系架构或处理环境中实现。
在前面的说明书中,已经参考众多具体细节描述了本发明的实施例,这些细节可以从实现到实现有所变化。因而,说明书和附图应被视为说明性而非限制性的。本发明范围的唯一和排他性指示,以及申请人意图作为本发明范围的内容,是以发布这种权利要求书的具体形式从本申请发布的权利要求书集合的字面和等同范围,包括任何后续更正。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。