一种基于flink流处理的地铁轨道几何检测数据清洗方法
技术领域
1.本发明涉及数据处理领域,具体是一种基于flink流处理的地铁轨道几何检测数据清洗方法。
背景技术:
2.轨道巡检是保障地铁安全运营的重要措施,巡检后将会保存轨道所有的几何检测数据,根据轨道巡检设备设定,一般为一米四个检测点,即一米之内有四条几何数据。然而一条地铁线路短则数公里,长则数十公里,每巡检一次都会累计大量的轨道几何检测数据。同时,这些数据具有缺失、异常、多表存储、结构不一致等特点,在使用前还需对某些字段进行匹配。所以,若直接将这些数据保存下来,待需要时再直接使用,将存在效率低、逻辑复杂等问题。
3.flink是一种基于google dataflow实现的开源流处理框架,其具有高吞吐、低延迟、高性能兼具实时流式计算等优点。因此,本发明采用flink实时流式计算框架对地铁轨道几何检测数据进行清洗,为后续使用提供了高质量数据,同时提高了处理效率,简化了处理逻辑。
技术实现要素:
4.本发明的目的在于克服现有技术的不足,提供一种基于flink流处理的地铁轨道几何检测数据清洗方法,包括如下步骤:
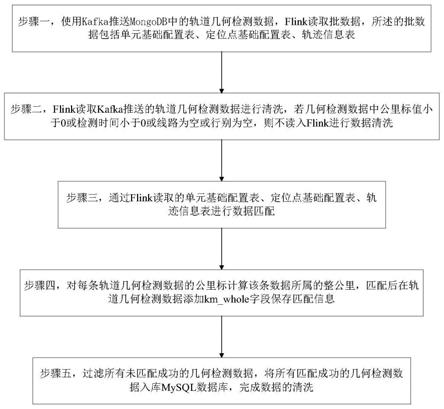
5.步骤一,使用kafka推送mongodb中的轨道几何检测数据,flink读取批数据,所述的批数据包括单元基础配置表、定位点基础配置表、轨迹信息表;
6.步骤二,flink读取kafka推送的轨道几何检测数据进行清洗,若几何检测数据中公里标值小于0或检测时间小于0或线路为空或行别为空,则不读入flink进行数据清洗;
7.步骤三,通过flink读取的轨迹信息表对flink读取的轨道几何检测数据,进行轨迹信息匹配,匹配后在轨道几何检测数据添加track_id字段保留匹配信息;通过flink读取的单元基础配置表对flink读取的轨道几何检测数据,进行单元id匹配,匹配后在轨道几何检测数据添加seg_id字段保存匹配信息;通过flink读取的定位点基础配置表对flink读取的轨道几何检测数据,进行定位点id匹配,匹配后在轨道几何检测数据添加point_id字段保存匹配信息;
8.步骤四,对每条轨道几何检测数据的公里标k计算该条数据所属的整公里k
whole
,匹配后在轨道几何检测数据添加km_whole字段保存匹配信息;
9.步骤五,过滤所有未匹配成功的几何检测数据,将所有匹配成功的几何检测数据入库mysql数据库,完成数据的清洗。
10.进一步的,所述的通过flink读取的轨迹信息表对flink读取的轨道几何检测数据,进行轨迹信息匹配,匹配后在轨道几何检测数据添加track_id字段保留匹配信息,包括如下过程:
11.提取每条轨道几何检测数据的检测时间到轨迹信息表中去匹配,对于每一条轨道几何检测数据,若检测时间在轨迹数据ti的开始时间与结束时间范围之内,则该条轨道几何检测数据数据的轨迹为ti,若未匹配到,则返回-10000作为每条数据的轨迹。
12.进一步的,所述的通过flink读取的单元基础配置表对flink读取的轨道几何检测数据,进行单元id匹配,匹配后在轨道几何检测数据添加seg_id字段保存匹配信息,包括如下过程:
13.根据每条轨道几何检测数据的线路行别在单元基础配置表检索到该线路行别的起始公里标ks及其序号ns,获取每条数据公里标ki所对应的序号ni,计算公式为:
[0014][0015]
其中200为每个单元间隔长度,在得到ni后,在单元基础配置表检索出序号为ni的单元id作为每条数据的单元id,若未检索到,则返回-10000作为每条数据的单元id。
[0016]
进一步的,所述的通过flink读取的定位点基础配置表对flink读取的轨道几何检测数据,进行定位点id匹配,匹配后在轨道几何检测数据添加point_id字段保存匹配信息,包括如下过程:
[0017]
根据每条轨道几何检测数据的线路行别在定位点基础配置表检索到该线路行别的起始公里标ks及其序号ns,获取每条数据公里标ki所对应的序号ni,计算公式为:
[0018][0019]
其中2为每个定位点间隔长度,得到ni后,在定位点基础配置表检索出序号为ni的定位点id作为每条数据的定位点id,若未检索到,则返回-10000作为每条数据的定位点id。
[0020]
进一步的,所述的整公里k
whole
采用如下公式计算:
[0021][0022]
本发明的有益效果是:本发明基于flink流处理框架实现量级大数据的快速高性能数据处理工作,方便后续其他模型更加高性能高质量完成模型计算。
附图说明
[0023]
图1为一种基于flink流处理的地铁轨道几何检测数据清洗方法的原理示意图;
[0024]
图2为基于flink流处理的地铁轨道几何检测数据清洗方法的实施例示意图。
具体实施方式
[0025]
下面结合附图进一步详细描述本发明的技术方案,但本发明的保护范围不局限于以下所述。
[0026]
如图1所示,一种基于flink流处理的地铁轨道几何检测数据清洗方法,包括如下步骤:
[0027]
步骤一,使用kafka推送mongodb中的轨道几何检测数据,flink读取批数据,所述的批数据包括单元基础配置表、定位点基础配置表、轨迹信息表;
[0028]
步骤二,flink读取kafka推送的轨道几何检测数据进行清洗,若几何检测数据中
公里标值小于0或检测时间小于0或线路为空或行别为空,则不读入flink进行数据清洗;
[0029]
步骤三,通过flink读取的轨迹信息表对flink读取的轨道几何检测数据,进行轨迹信息匹配,匹配后在轨道几何检测数据添加track_id字段保留匹配信息;通过flink读取的单元基础配置表对flink读取的轨道几何检测数据,进行单元id匹配,匹配后在轨道几何检测数据添加seg_id字段保存匹配信息;通过flink读取的定位点基础配置表对flink读取的轨道几何检测数据,进行定位点id匹配,匹配后在轨道几何检测数据添加point_id字段保存匹配信息;
[0030]
步骤四,对每条轨道几何检测数据的公里标k计算该条数据所属的整公里k
whole
,匹配后在轨道几何检测数据添加km_whole字段保存匹配信息;
[0031]
步骤五,过滤所有未匹配成功的几何检测数据,将所有匹配成功的几何检测数据入库mysql数据库,完成数据的清洗。
[0032]
进一步的,所述的通过flink读取的轨迹信息表对flink读取的轨道几何检测数据,进行轨迹信息匹配,匹配后在轨道几何检测数据添加track_id字段保留匹配信息,包括如下过程:
[0033]
提取每条轨道几何检测数据的检测时间到轨迹信息表中去匹配,对于每一条轨道几何检测数据,若检测时间在轨迹数据ti的开始时间与结束时间范围之内,则该条轨道几何检测数据数据的轨迹为ti,若未匹配到,则返回-10000作为每条数据的轨迹。
[0034]
进一步的,所述的通过flink读取的单元基础配置表对flink读取的轨道几何检测数据,进行单元id匹配,匹配后在轨道几何检测数据添加seg_id字段保存匹配信息,包括如下过程:
[0035]
根据每条轨道几何检测数据的线路行别在单元基础配置表检索到该线路行别的起始公里标ks及其序号ns,获取每条数据公里标ki所对应的序号ni,计算公式为:
[0036][0037]
其中200为每个单元间隔长度,在得到ni后,在单元基础配置表检索出序号为ni的单元id作为每条数据的单元id,若未检索到,则返回-10000作为每条数据的单元id。
[0038]
进一步的,所述的通过flink读取的定位点基础配置表对flink读取的轨道几何检测数据,进行定位点id匹配,匹配后在轨道几何检测数据添加point_id字段保存匹配信息,包括如下过程:
[0039]
根据每条轨道几何检测数据的线路行别在定位点基础配置表检索到该线路行别的起始公里标ks及其序号ns,获取每条数据公里标ki所对应的序号ni,计算公式为:
[0040][0041]
其中2为每个定位点间隔长度,得到ni后,在定位点基础配置表检索出序号为ni的定位点id作为每条数据的定位点id,若未检索到,则返回-10000作为每条数据的定位点id。
[0042]
进一步的,所述的整公里k
whole
采用如下公式计算:
[0043][0044]
具体的,本发明的方法流程如下:
[0045]
(1)使用kafka推送mongodb中的最新实时地铁轨道几何检测数据,包含定位数据(线路、行别、区站、公里标等),几何数据(左右高低、左右轨向、水平、轨距、三角坑),检测时间数据。
[0046]
(2)flink读取批数据:单元基础配置表、定位点基础配置表、轨迹信息表。
[0047]
(3)flink读取kafka推送的地铁轨道几何检测流数据进行清洗,若几何数据中公里标值小于0或检测时间小于0或线路为空或行别为空,则不读入flink进行数据清洗。每读取1000条数据清洗一次。
[0048]
(4)具体地,以某1000条数据为例进行详细的数据清洗过程说明。
[0049]
(5)首先使用轨迹信息表对这1000条数据匹配轨迹信息,匹配后在检测数据添加track_id字段保留匹配信息。
[0050]
(6)上述(5)中的匹配方法为:提取每条数据的检测时间到轨迹信息表中去匹配,对于每一条轨道几何检测数据,若检测时间在轨迹数据ti的开始时间与结束时间范围之内,则该条轨道几何检测数据数据的轨迹为ti,若未匹配到,则返回-10000作为每条数据的轨迹。
[0051]
(7)接着使用单元基础配置表对这1000条数据匹配单元id,匹配后在检测数据添加seg_id字段保存匹配信息。
[0052]
(8)上述(7)中匹配方法为:首先根据每条数据的线路行别在单元基础配置表检索到该线路行别的起始公里标ks及其序号ns,接着计算每条数据公里标ki所对应的序号ni,计算公式为:其中200为每个单元间隔长度。在得到ni后,在单元基础配置表检索出序号为ni的单元id作为每条数据的单元id,若未检索到,则返回-10000作为每条数据的单元id。
[0053]
(9)接着使用定位点基础配置表对这1000条数据匹配定位点id,匹配后在检测数据添加point_id字段保存匹配信息。
[0054]
(10)上述(8)中匹配方法与(7)基本一致,具体为:首先根据每条数据的线路行别在定位点基础配置表检索到该线路行别的起始公里标ns及其序号ns,接着计算每条数据公里标ki所对应的序号ni,计算公式为:其中2为每个定位点间隔长度。在得到ni后,在定位点基础配置表检索出序号为ni的定位点id作为每条数据的定位点id,若未检索到,则返回-10000作为每条数据的定位点id。
[0055]
(11)最后,使用每条数据数据的公里标k计算该条数据所属的整公里k
whole
,整公里计算公式为:匹配后在检测数据添加km_whole字段保存匹配信息。
[0056]
(12)过滤所有未匹配成功的数据。匹配后track_id,seg_id,point_id为-10000的均为未匹配成功的数据,在入库之前需过滤掉。
[0057]
(13)将所有匹配成功的数据入库mysql数据库,完成这1000条数据的清洗。
[0058]
(14)为了提高查询效率,(13)入库时需入库两张表:一张历史表,存储所有清洗的数据;一张临时表,存储当前程序运行一次所清洗的数据。重复(1)~(14),直至消费完kafka中的所有消息。
[0059]
以上所述仅是本发明的优选实施方式,应当理解本发明并非局限于本文所披露的
形式,不应看作是对其他实施例的排除,而可用于各种其他组合、修改和环境,并能够在本文所述构想范围内,通过上述教导或相关领域的技术或知识进行改动。而本领域人员所进行的改动和变化不脱离本发明的精神和范围,则都应在本发明所附权利要求的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。