1.本发明属于语音信号智能处理技术领域,具体涉及一种用于情绪评估的语言情感识别方法。
背景技术:
2.随着人工智能的快速发展,人机交互越来越人性化、智能化。语音情感识别从语音信号中识别情感状态,这对于推进人机交互非常重要。根据一个人的在交谈时的情绪,去理解对话内容和给出恰当的回应具有重要意义。尤其在演讲等一些特殊的环境中,演讲者的表达语言的情绪与生理和行为变化联系紧密,影响着听众的情绪和整体的氛围,而现有的语言情感识别方法,通常采用情绪分类的方式对演讲者的演讲过程中情绪进行识别,实现对演讲者的表现进行评估,这种评估方式无法精准的掌握演讲者的情绪变化,尤其对于整条音频的识别,容易出现忽略情绪的问题。
技术实现要素:
3.发明目的:提供一种用于情绪评估的语言情感识别方法,解决了现有技术存在的上述问题。
4.技术方案:一种用于情绪评估的语言情感识别方法,包括以下步骤:
5.预先录制对话内容生成源音频,对所述源音频进行预处理并保存得到情感数据库;将所述情感数据库按照预定需求划分为训练集和测试集;
6.基于情感数据库搭建语音情感识别模型;所述语音情感识别模型通过愉悦度和激情度来预测情感数据库;
7.获取演讲者的演讲内容,并对演讲内容进行预处理生成相应的音频文件;
8.以情感数据库的训练集语音时长为分割参数,将所述音频文件分割成若干个语音片段,得到目标语音文件;
9.将所述目标语音文件为输入语音情感识别模型,基于语音情感识别模型对演讲者情绪的评估分析,同时测试集作用于训练集使语音情感识别模型的参数得到优化。
10.采用上述技术方案:通过预先录制对话内容生成源音频,并对录制的源音频预处理并保存得到情感数据库,并根据预设比例将情感数据库按照训练集和测试集进行划分,测试集作用于训练集使语音情感识别模型的参数得到优化,同时获取演讲者的演讲内容并对演讲内容进行预处理生成音频文件,基于语音情感识别模型对演讲者情绪的评估分析。
11.优选的,所述音频文件为:所述音频文件的生成至少包括以下步骤:
12.对演讲内容依次进行预加重、分帧和加窗处理。
13.优选的,所述语音片段的频率为16-20khz,每段语音片段时长为10-15s,当语音片段时间短于10-15s,则放弃该语音片段。
14.优选的,所述参数的优化包括以下流程:以训练集为输入,并以处理后源音频的愉悦度和激情度为目标值,对语音情感识别模型参数进行优化,并使用测试集检验训练优化
后的语音情感识别模型;测试集的语音情感识别模型中愉悦度和激情度分别预设指标阈值,当检验结果大于阈值,则重新训练模型;当检验结果小于等于阈值,则使用此模型预测目标语音文件的愉悦度和激情度。
15.优选的,对语音情感识别模型进行训练优化,使用均方差作为损失函数,使用随机梯度下降法进行参数优化,卷积核大小设置为7、3和1,激活函数使用的是relu,学习率设置为0.0002,batch-size设置为16,迭代次数设置为100,其中均方差损失函数:式中,n表示样本数量,表示预测值,y表示真实值。
16.优选的,所述愉悦度与所述激情度的数值范围为[-3,3]。
[0017]
优选的,所述语音情感识别模型包含卷积神经网络,其中卷积神经网络包括池化层和两层全连接层;第一层全连接层用于提取语音片段;所述第二层全连接层用于情绪值的预测,所述卷积神经网络有12层一维卷积,其中卷积核数和卷积的大小分别设置为3和1,每层卷积后都跟有归一化层。
[0018]
优选的,所述卷积神经网络对测试集数据进行识别,得到相应的预测值和对应的真实值进行比较,通过平均绝对误差和均方误差两个指标表示预测精度;
[0019]
平均绝对误差:
[0020]
均方根误差:
[0021]
式中,n表示样本数量,表示预测值,y表示真实值。
[0022]
优选的,还包括残差结构,所述残差结构包括堆叠的卷积层和bn层;所述bn层的原理如下:
[0023][0024][0025][0026]
yi=γxi' β。
[0027]
式中,x=[x1,x2,l l,xn]为给定的语音信号,n为样本数量,μ表示样本平均值,σ2表示样本方差,x
i’为每个元素标准化后的新值,ε用于防止无效计算,γ和β是两个引入的可学习参数。
[0028]
优选的,还包括对语音信号的预加重处理,具体包括以下步骤:
[0029]
通信连接于所述情感数据库的高通滤波器;利用高通滤波器对语音信号预加重;采用下列公式进行信号预加重:a[k]=b[k]*0.97b[k-1],其中,b[k]为输入信号,0.97为预加重系数。
[0030]
有益效果:本发明涉及一种用于情绪评估的语言情感识别方法,通过提前录制说
话内容生成源音频,并对源音频进行预处理并保存得到情感数据库,按照预设比例对情感数据库分配形成训练集和测试集,建立完成的情感数据库,测试集作用于训练集使语音情感识别模型的参数得到优化,使用测试集数据检验语音情感识别模型优化的结果,语音情感识别模型通过愉悦度和激情度来预测情感数据库,利用语音情感识别模型对演讲者的语音表达愉悦度和激情度进行数值预测,精准的掌握演讲者语言的情绪变化,避免了只对音频的识别而忽略了情绪变化的问题,更好的评估演讲者的表现。
附图说明
[0031]
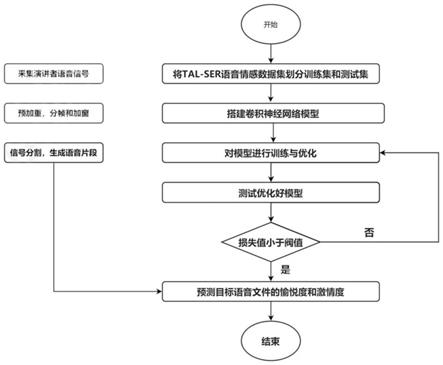
图1为本发明的语音情感识别方法流程图;
[0032]
图2为本发明的卷积神经网络流程图;
[0033]
图3为本发明的残差结构执行流程图。
具体实施方式
[0034]
在实际的应用中,申请人发现:随着人工智能的快速发展,人机交互越来越人性化、智能化。语音情感识别从语音信号中识别情感状态,这对于推进人机交互非常重要。根据一个人的在交谈时的情绪,去理解对话内容和给出恰当的回应具有重要意义。尤其在演讲等一些特殊的环境中,演讲者的表达语言的情绪与生理和行为变化联系紧密,影响着听众的情绪和整体的氛围,而现有的语言情感识别方法,通常采用情绪分类的方式对演讲者的演讲过程中情绪进行识别,实现对演讲者的表现进行评估,这种评估方式无法精准的掌握演讲者的情绪变化,尤其对于整条音频的识别,容易出现忽略情绪的问题,针对这些问题,所以发明了一种用于情绪评估的语言情感识别方法,能够有效的解决上述问题。
[0035]
如图1至图3所示,一种用于情绪评估的语言情感识别方法,通过提前录制说话内容进行录音生成源音频,在对说话内容录制的过程中,为了确保录制的音频清晰,所述音频数据库通信连接高通滤波器;利用高通滤波器对语音信号预加重;高通滤波器采用以下形式进行过滤,a[k]=b[k]*0.97b[k-1];其中,b[k]为输入信号,0.97为预加重系数,获取源音频,并对源音频进行预加重、分帧和加窗等处理形成预处理数据库,对预处理后的源音频进行分割处理生成音频片段,切割完成后的音频片段的频率为16-20khz,优选16khz,每段音频片段时长为10-15s,10s为最优时间长度,当切割后的音频片段时长小于10s,则舍弃该段音频片段,建立情感数据库,其中情感数据库至少拥有4541个源音频,并对情感数据库内的语音片段按照8:2的比例进行分配形成训练集和测试集,其中分别对测试集、训练集的音频片段的愉悦度和激情度进行标明搭建语音情感识别模型;同时基于情感数据库搭建语音情感识别模型,测试集作用于训练集使语音情感识别模型的参数得到优化;对愉悦度和激情度分别预设指标阈值,所述愉悦度与所述激情度的数值范围为[-3,3],当检验结果大于阈值,则重新训练模型;当检验结果小于等于阈值,则使用此模型预测目标语音文件的愉悦度和激情度,获取演讲者的演讲内容,并对演讲内容进行预处理生成相应的音频文件,其中对演讲内容的预处理方式与对源音频的预处理方式是相同的,以情感数据库的训练集语音时长为分割参数,将所述音频文件分割成若干个语音片段,得到目标语音文件,将所述目标语音文件为输入语音情感识别模型,基于语音情感识别模型完成对演讲者情绪的评估分析。
[0036]
在进一步实施例中,所述情感数据库还包括:卷积神经网络和resnet中的残差结构,避免在训练过程中出现梯度消失问题,所述卷积神经网络,其中一维卷积有12层,其中卷积核数和卷积的大小分别设置为3和1,每层卷积后都跟有归一化层,所述卷积神经网络包括池化层和两层全连接层;第一层全连接层用于提取语音片段;所述第二层全连接层用于情绪值的预测;所述残差结构包括:堆叠的卷积层和bn层;所述bn层的原料如下:
[0037][0038][0039][0040]
yi=γxi' β
[0041]
式中,x=[x1,x2,l l,xn]为给定的语音信号,n为样本数量,μ表示样本平均值,σ2表示样本方差,x
i’为每个元素标准化后的新值,ε用于防止无效计算,γ和β是两个引入的可学习参数。
[0042]
其中,所述卷积神经网络对测试集数据进行识别,得到相应的预测值和对应的真实值进行比较,通过平均绝对误差和均方误差两个指标表示预测精度;
[0043]
平均绝对误差:
[0044]
均方根误差:
[0045]
式中,n表示样本数量,表示预测值,y表示真实值。
[0046]
进一步实施例中,对情感识别模型进行训练优化,使用均方差作为损失函数,使用随机梯度下降法进行参数优化,卷积核大小设置为7、3和1,激活函数使用的是relu,学习率设置为0.0002,batch-size设置为16,迭代次数设置为100,其中均方差损失函数:式中,n表示样本数量,表示预测值,y表示真实值。
[0047]
以上详细描述了本发明的优选实施方式,但是,本发明并不限于上述实施方式中的具体细节,在本发明的技术构思范围内,可以对本发明的技术方案进行多种等同变换,这些等同变换均属于本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。