一种基于改进apriori算法的相似模型检索方法
技术领域
1.本发明属于相似性检索技术领域,具体涉及一种基于改进apriori算法的相似模型检索方法。
背景技术:
2.随着计算机科学的快速发展,算法模型已成为人类重要的智慧成果,加之人工智能发展如火如荼,机器学习模型作为人工智能的“灵魂”,其知识产权保护愈加引起人们的重视。然而,当下的算法模型知识产权保护中尚存在著作权和专利权保护的纷争,算法模型只有在继承与保护中才能得到有效长远的发展。此外,在这知识井喷的时代,算法模型成果每年都有巨大的产出,面对大量算法模型数据集的算法相似性检索任务,显得尤为艰巨,使用检索技术检索相似算法模型,其效率必然是一个重要考量指标。因此,本发明根据算法模型的使用情况,使用改进apriori算法挖掘算法模型之间的关联规则,提升关联规则的挖掘效率,再利用余弦相似度算法挖掘潜在相似模型,最后对潜在相似模型进行源码级别上的相似度计算或人工鉴别。该方法为算法的继承与保护提供了强有力的技术保障,避免了低相似性相关性算法模型在文本层面上进行相似度计算,造成计算资源的浪费。
3.计算机科学以及数据挖掘领域中,先验算法(apriori algorithm)是关联规则学习的经典算法之一。先验算法采用广度优先搜索算法进行搜索并采用树结构来对候选项目集进行高效计数。它通过长度为k-1的候选项目集来产生长度为k的候选项目集,然后从中删除包含不常见子模式的候选项。根据向下封闭性引理,该候选项目集包含所有长度为k的频繁项目集。之后,就可以通过扫描交易数据库来决定候选项目集中的频繁项目集。
4.关联规则挖掘是由rakesh agrawal等人在1993年的sidmod会议上提出,经过了二十几年的发展,目前在互联网、电商、医疗、金融等行业得到广泛应用。d.w.cheung等人提出了关联规则快速更新算法fup,解决了在最小支持度和最小置信度保持不变的情况下,增加数据集时的关联规则更新问题。在国内,冯玉才等人提出了iua和piua算法,解决了最小支持度和最小置信度发生变化的情况下,关联规则快速更新的问题。上述研究表面,apriori在频繁项集的挖掘效率仍然存在许多改进空间,其应用场景也存在许多探索空间。本发明使用apriori关联规则算法应用于潜在相似模型挖掘,开辟apriori关联规则算法在相似性检索领域的开创性应用。
技术实现要素:
5.(一)要解决的技术问题
6.本发明要解决的技术问题是:如何设计一种快速高效的潜在相似模型检索方案。
7.(二)技术方案
8.为了解决上述技术问题,本发明提供了一种基于改进apriori算法的相似模型检索方法,包括以下步骤:
9.s1、选取模型数据集d,对模型数据集d进行去重、排序,创建一项候选集c1;
10.s2、扫描数据集d,计算一项候选集c1在数据集d中的支持度,判断支持度是否大于最小支持度minsupport,大于最小支持度minsupport的项集形成一项频繁集l1;
11.s3、根据l1进行组合计算,得到所有可能的候选项集c2,计算二项候选集c2在数据集d中的支持度,大于最小支持度minsupport的项集形成二项频繁集l2,迭代执行此步,得到k项频繁集lk;
12.s4、通过频繁项集lk递归计算可信度,记录可信度大于最小可信度minconf的集合,生成关联规则;
13.s5、新增数据集dn,使用apriori增量快速更新算法快速生成新的频繁项集lk,再递归计算可信度,通过可信度计数生成关联规则;
14.s6、更新最小支持度minsupport,使用apriori阈值快速更新算法生成新的频繁项集lk,再递归计算可信度,通过可信度计数生成关联规则;
15.s7、使用余弦相似度算法计算s6中关联规则rules的相似度,对余弦相似度设定阈值剔除非潜在相似模型,得到潜在相似模型。
16.优选地,所述apriori增量快速更新算法是在数据集d有新增dn的情况下,只遍历计算新增候选集的支持度计数,原有候选集不再遍历计算其支持度计数,候选集再根据支持度阈值得出频繁集。
17.优选地,所述apriori增量快速更新算法的具体实现流程如下:
18.首先,apriori增量快速更新算法每一次遍历计算候选集的支持度计数后,都将该支持度计数存储起来,然后,当数据集有新增候选集时,遍历计算新增候选集的支持度计数,再读取原有候选集的支持度计数,将原有候选集的支持度计数与新增候选集的支持度计数相加,最后,将合并后的候选集的支持度计数除以更新后的数据集总长度,得出更新后的数据集中各候选集的支持度,候选集再根据支持度阈值得出频繁集。
19.优选地,所述数据集的更新模型中,设sscnt为支持度,lenold为原数据集长度,lennew为插入新增数据集后的新数据集长度,通过公式newcnt=sscnt/(lenold lennew),重新计算原有频繁项集支持度,原有非频繁项集与新增候选集组成并集计算支持度,将原有频繁项集支持度与并集计算支持度相加再作阈值判断得到新频繁项集。
20.优选地,所述apriori阈值快速更新算法是在支持度阈值更新后,只遍历计算因阈值更新而产生的新的候选集,原本满足支持度阈值的候选集不再做遍历计算,候选集再根据新的支持度阈值得出频繁集。
21.优选地,支持度阈值更新包括两种情况:情况一,新支持度阈值比原支持度阈值大,此时利用频繁项集的支持度计数,通过遍历之间删除不满足newsupport的频繁项集;情况二,新支持度阈值比原支持度阈值小,此时重新计算频繁一项集newl1,得到新增频繁一项集l1
′
=newl1-l1,将满足新最小支持度newsupport的频繁项集lk分为三类:
22.①
第一类频繁集lk1:候选集通过apriori_gen(lk
1-1)得出;
23.②
第二类频繁集lk2:候选集通过apriori_gen(lk
2-1
′
)得出;
24.③
第三类频繁集lk3:候选集通过apriori_gen(lk
3-1,lk
3-1
′
)得出;
25.分别针对这三类频繁集,进行处理,其中apriori_gen()函数用于计算频繁项集组合而成所有可能的候选集。
26.优选地,对于类型
①
,通过apriori_gen(lk
1-1)-lk1的方式修剪这部分候选集,并
计算剩余候选数据集在数据集d中的支持度。
27.优选地,对于类型
②
,直接计算候选集apriori_gen(lk
2-1
′
)在数据集d中的支持度。
28.优选地,对于类型
③
,拼接第一类频繁集lk1和第二类频繁集lk2,并通过“频繁项集任一子集必是频繁项集”原则检测候选集的子集是否为频繁项集,不是则修剪这部分候选集。
29.本发明还提供了一种所述方法在相似性检索技术领域中的应用。
30.(三)有益效果
31.本发明为提高apriori关联规则挖掘效率,采用改进apriori算法实现增量快速更新与阈值快速更新,根据“频繁项集任一子集必是频繁项集”原则,利用现有频繁项集,对新增候选项集进行剪枝,接着生成新频繁项集,然后通过频繁项集计算关联规则。最后,使用余弦相似度算法挖掘潜在相似模型。
32.本发明采用改进apriori算法挖掘模型关联规则,之后用得到的关联规则挖掘相似模型,具有如下优点和有益效果:
33.1、本发明采用apriori增量快速更新算法和apriori阈值快速更新算法改进了apriori算法,可以根据模型使用情况有针对性地挖掘潜在相似模型,具有高效、快速等特点。
34.2、本发明采用支持度与可信度阈值控制数据生成,并实现支持度快速更新,使用者可根据需求挖掘数据获取潜在相似模型。
35.本发明为相似算法模型检索提供了高效的技术方案,具有重要的现实应用价值。
附图说明
36.图1是本发明潜在相似模型挖掘流程图;
37.图2是本发明支持度阈值动态更新模型图。
具体实施方式
38.为使本发明的目的、内容、和优点更加清楚,下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。
39.本发明提供的一种基于改进apriori算法的相似模型检索方法是一种快速高效的潜在相似模型检索方案。本发明针对算法模型著作权与专利权保护的问题,提出一种基于改进apriori算法的相似模型检索方法,根据模型的使用情况,有目标性地快速挖掘潜在的相似模型,以提升相似模型的检索效率。其中,采用改进apriori算法挖掘模型关联规则,使用余弦相似度算法计算关联向量相似度挖掘潜在相似模型。本发明相关的一些基本概念为:
40.1.apriori算法:apriori算法是一种挖掘关联规则的频繁项集算法,它是由rakesh agrawal和ramakrishnanskrikant提出的。它使用一种称作逐层搜索的迭代方法,k项集用于探索(k 1)项集。首先,找出频繁一项集的集合。该集合记作l1。l1用于找频繁二项集的集合l2,而l2用于找l3,如此下去,直到不能找到频繁k项集。每找一个lk需要一次数据库扫描。
41.2.候选集:k维候选集计为ck。一项候选集c1由数据集去重、排序得到,除此之外,ck 1项候选集由频繁集lk组合得到,计算公式表示为ck=apriori_gen(lk-1)。
42.3.频繁集:大于最小支持度的候选集即为频繁项集,其中,k维数据项集lk是频繁项集的必要条件是它所有k-1维子项集也为频繁项集,记为lk-1。
43.4.关联规则:{a}-》{b}就是一条关联规则,这意味者个体在使用了模型a后,也使用了模型b这一事件。
44.5.支持度:通过扫描数据集,计算数据集中包含该项集的记录所占的比例,该比例即为支持度,数据集a的支持度表示为support(a)。
45.6.可信度:针对一条诸如{a}-》{b}这样具体的关联规则来定义的,一条规则{a}-》{b}的可信度定义为support(a|b)/support(a)。
46.7.k项集:如果事件a中包含k个元素,那么称这个事件a为k项集,并且事件a满足最小支持度阈值的事件称为频繁k项集。
47.8.余弦相似度:余弦相似度,又称为余弦相似性,是通过计算两个向量的夹角余弦值来评估他们的相似度。余弦相似度将向量根据坐标值,绘制到向量空间中,如最常见的二维空间。
48.针对模型算法著作权与专利权保护问题,存在着现存算法模型数据量大、相似性难以鉴别问题,本发明使用基于改进apriori算法挖掘潜在相似模型的方法,能够在数据集动态更新、支持度动态更新的情况下,实现频繁项集的高效、快速更新,再利用频繁项集计算关联规则,然后,使用余弦相似度算法计算关联规则向量挖掘潜在相似模型,最后,通过文本相似度计算或人工鉴别等手段鉴别模型是否相似。如图1所示,本发明包括以下步骤:
49.s1、选取模型数据集d,对模型数据集d进行去重、排序,创建一项候选集c1;
50.s2、扫描数据集d,计算一项候选集c1在数据集d中的支持度,判断支持度是否大于最小支持度minsupport,大于最小支持度minsupport的项集形成一项频繁集l1;
51.s3、根据l1进行组合计算,得到所有可能的候选项集c2,计算二项候选集c2在数据集d中的支持度,大于最小支持度minsupport的项集形成二项频繁集l2,迭代执行此步,得到k项频繁集lk;
52.s4、通过频繁项集lk递归计算可信度,记录可信度大于最小可信度minconf的集合,生成关联规则rules;
53.s5、新增数据集dn,使用apriori增量快速更新算法快速生成新的频繁项集lk,再递归计算可信度,通过可信度计数生成关联规则rules;
54.s6、更新最小支持度minsupport,使用apriori阈值快速更新算法生成新的频繁项集lk,再递归计算可信度,通过可信度计数生成关联规则rules;
55.s7、使用余弦相似度算法计算s6中关联规则rules的相似度,对余弦相似度设定阈值剔除非潜在相似模型,得到潜在相似模型。
56.在本实施例中,apriori增量快速更新算法和apriori阈值快速更新算法的具体流程如下:
57.(1)apriori增量快速更新算法
58.增量快速更新的目的是在数据集d有新增dn的情况下,只遍历计算新增候选集的支持度计数,原有候选集不再遍历计算其支持度计数,候选集再根据支持度阈值得出频繁
集。通过增量快速更新方法,避免了重复的遍历计算,实现了频繁集的快速更新。
59.首先,apriori增量快速更新算法每一次遍历计算候选集的支持度计数后,都将该支持度计数存储起来。这一步是为了避免数据集有新增时,已计算过支持度计数的候选集重新遍历计算。然后,当数据集有新增候选集时,遍历计算新增候选集的支持度计数。再读取原有候选集的支持度计数,将原有候选集的支持度计数与新增候选集的支持度计数相加。最后,将合并后的候选集的支持度计数除以更新后的数据集总长度,得出更新后的数据集中各候选集的支持度。候选集再根据支持度阈值得出频繁集。
60.数据集动态更新模型如图1所示,其中,sscnt为支持度技术,lenold为原数据集长度,lennew为插入新增数据集后的新数据集长度,通过公式newcnt=sscnt/(lenold lennew),重新计算原有频繁项集支持度,原有非频繁项集与新增候选集组成并集计算支持度,将原有频繁项集支持度与上述并集支持度相加再作阈值判断得到新频繁项集。
61.(2)apriori阈值快速更新算法
62.阈值快速更新的目的是在支持度阈值更新后,只遍历计算因阈值更新而产生的新的候选集,原本满足支持度阈值的候选集不再做遍历计算,候选集再根据新的支持度阈值得出频繁集,从而提升了频繁集的更新效率。支持度阈值更新包括两种情况:新支持度阈值比原支持度阈值大、新支持度阈值比原支持度阈值小。
63.支持度阈值动态更新如图1所示的数据集动态更新模型所示。情况一,newsupport》oldsupport,原有的一些频繁项目集可能失去最小支持度,利用频繁项集的支持度计数,通过遍历之间删除不满足newsupport的频繁项集;情况二,newsupport《oldsupport,重新计算频繁一项集newl1,得到新增频繁一项集l1
′
=newl1-l1。将满足新最小支持度newsupport的频繁项集lk分为三类:
64.①
第一类频繁集lk:候选集通过apriori_gen(lk-1)得出
65.②
第二类频繁集lk:候选集通过apriori_gen(lk-1
′
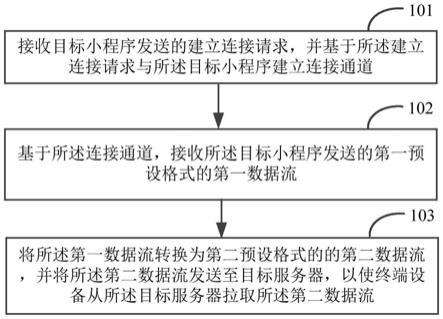
)得出
66.③
第三类频繁集lk:候选集通过apriori_gen(lk-1,lk-1
′
)得出
67.其中apriori_gen()函数用于计算频繁项集组合而成所有可能的候选集;
68.类型
①
,由于newsupport《oldsupport,故原有满足最小支持度oldsuppport的频繁集必定满足newsupport,故通过apriori_gen(lk-1)-lk的方式修剪该部分候选集,并计算剩余候选数据集在数据集d中的支持度。类型
②
,直接计算候选集apriori_gen(lk-1
′
)在数据集d中的支持度。类型
③
,拼接第一类频繁集lk和第二类频繁集lk,并通过“频繁项集任一子集必是频繁项集”原则检测候选集的子集是否为频繁项集,不是则修剪该候选集。
69.以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。