1.本发明属于自然语言处理技术领域,尤其涉及基于深度学习的文本摘要获取方法。
背景技术:
2.随着互联网产业的迅速发展,越来越多的人依赖于从互联网平台发布和获取信息,人们日常接触的文本信息呈爆发式增长,通过互联网平台,可以快速访问大量信息,但是由于网络的信息极其庞大、杂乱,人们需要花费更多的时间去筛选文本中的关键信息。因此,从大量文本信息中提取重要的内容,已经成为人们的一个迫切需求。传统的文本摘要主要依赖于人工总结,需要庞大的时间成本和人工成本。与此同时,由于文本信息的爆发式增长,单纯依赖人工来总结文本摘要是不切实际的。因此,自动文本摘要作为一种通过机器自动总结文本摘要的技术,成为目前正在积极研究的一个热门领域。
3.自动文本摘要按照输出类型可以分为两类,分别是抽取式文本摘要和生成式文本摘要。抽取式文本摘要通过从原始文本中抽取出重要的片段,并将它们组合形成摘要,不仅可以有效地使内容简洁,便于人们理解,而且实现简单,是目前最主流、应用最多、最容易的方法。但是这种方法有一个不可忽视的缺点,在文本摘要中相邻的片段在内容上不一定相邻,所以可能造成摘要的语义不连贯。相比之下,生成式文本摘要不仅仅是从原始文本中抽取几个现有片段,而是对原始文本主要内容的压缩解释,可能产生原始文本中没有的词汇,相比于抽象式文本摘要更灵活,更接近人工总结摘要的过程。生成式文本摘要要求理解原始文档、生成可读性强的简练摘要,使得任务变得困难和具有挑战性。自动文本摘要按照文档类型可以分为单文档摘要和多文档摘要。单文档摘要从给定的一个文档中生成摘要,多文档摘要从给定的一组主题相关的文档中生成摘要。随着人工智能技术的快速发展,基于神经网络和深度学习的自然语言处理技术也取得了令人瞩目的发展。自动文本摘要作为自然语言处理的重要领域,也得到了广泛的关注。越来越多的研究者们致力于利用深度神经网络来实现自动文本摘要,生成式文本摘要技术在一定程度上取得了实质性的进展,与此同时,抽取式文本摘要技术也得到了极大的改善。尽管近年来自动文本摘要技术有了很大的进展,但是对于生成高质量的摘要还是远远不够的。对于生成式文本摘要来说,要求模型有更强的表示、理解和生成文本的能力。目前生成式文本摘要还存在可读性、冗余度、信息量以及虚假信息等问题。
技术实现要素:
4.文本摘要任务是对海量文本数据的提炼和总结,通过将海量的文本数据压缩成简单、直观的摘要来节约用户浏览文本数据的时间成本。随着人们日常接触的文本信息越来越多,文本摘要成为人们的迫切需求。自动文本摘要是自然语言处理中的重要领域,其旨在通过机器自动总结出简洁、连贯、信息量大、准确的文本摘要。随着深度学习的发展,文本摘要技术在一定程度上取得了进步,然而,该技术对满足人们的实际需求是远远不够的,对于
计算机而言,生成摘要是一件很有挑战性的任务,在生成摘要时要求计算机在阅读原文本后理解其内容,并且根据轻重缓急对内容进行取舍、裁剪和拼接,最后生成流畅的短文本。
5.针对生成的文本摘要的质量问题,本发明采用的技术提出一种将局部信息和全局特征融合的方式加强模型对输入文本的语义表示,从而提高摘要的生成质量。包括以下步骤:
6.步骤1,提取原文本的关键词。
7.对于文本,往往可以通过一些关键词窥探整个文本的主题思想,本发明通过提取出若干个代表文章语义内容的关键词作为文本的局部信息。由于文本摘要相关的数据集中并没有给定关键词,因此,在本发明中,首先需要提取原文档的关键词,本发明使用的方法主要基于无监督的思想。
8.提取原文本关键词的步骤如下:
9.步骤1.1考虑词的位置信息,一般首句和末句出现的词语是关键词的概率更高,因此,我们将文档的首句和末句分别重复3次,从而增加关键词在首句和末句的词频。
10.步骤1.2将文本进行分词,利用每个词的tf-idf统计信息,挑选出20个词语作为候选关键词。
11.步骤1.3我们希望得到的关键词能够尽可能的代表原文本的中心思想,仅仅利用统计信息得到的关键词无法保证这一点,因此我们需要步骤1.2得到的关键词进行进一步的筛选:使用doc2vec获得文档的向量表示d,使用word2vec获得候选关键词的向量表示w。根据w和d的余弦距离对候选关键词进行排序,从初始的候选关键词中挑选出与文档接近的关键短语,关键词与文档越接近,说明信息量越大,从而保证得到的关键词与文档更具有相关性。
12.步骤1.4为避免最终关键词出现冗余,即提取出来的关键词虽然具有不同的表达方式,但具有相同的含义,因而我们需要对步骤1.3得到的关键词进行二次筛选:同理,根据候选关键词之间的余弦距离进行排序,对于有相同语义的关键词,我们只保留一个。
13.步骤2,构建encoder模块。
14.该模块的目的是对输入的文本进行编码,即向量化表示。本发明的encoder模块使用transformer的编码器模块最终获得具有语义特征、上下文特征的原文本的语义表示,我们成为全局语义信息。
15.步骤3,构建图卷积模块。
16.本模块的目的是局部语义信息的关系整合。在步骤1中得到了不同关键词的语义信息,为了挖掘更有效的局部语义特征,我们利用图卷积的方法,将局部特征加入关系特征,从而得到具有关系信息的局部语义信息。在图卷积中,输入包括节点和邻接矩阵,其中节点为步骤1提取出来的局部语义信息,节点之间是有关系的,邻接矩阵表示节点之间的关系程度,然后使用图卷积自适应学习每个关键词之间的关系权重,得到关键词之间的邻接矩阵后,将其和初始的语义信息相乘,得到关系特征,再将关系特征与初始特征融合,得到新的一轮特征。
17.包括以下步骤:
18.步骤3.1在步骤1和步骤2得到了k个局部语义信息以及1个全局语义信息,作为图的节点。
19.步骤3.2构建图的邻接矩阵,初始化为1。
20.步骤3.3局部特征与整体特征差异越大的,越离群,因此本发明通过计算局部语义信息和全局语义信息的差异,构建差异矩阵,利用差异来动态更新图中所有节点的边的权重。首先将全局语义信息重复k次,分别得到k个局部语义信息与全局语义信息的差异程度,最终得到差异矩阵。
21.步骤3.4利用线性变换等操作将3.3得到的差异矩阵转换为维度为(k,k)的矩阵,称其为更新矩阵。
22.步骤3.5将步骤3.4得到的更新矩阵与邻接矩阵逐元素相乘,该操作的目的就是利用更新矩阵来自适应的学习邻接矩阵。
23.步骤3.6将3.5得到的邻接矩阵与节点信息相乘,得到语义信息的关系特征。
24.步骤3.7将3.6得到的局部关系特征与节点的局部语义信息拼接,得到具有关系信息的局部语义信息。
25.步骤4,构建decoder模块
26.本模块的目的是生成原文本的摘要。指针生成器网络是一个带有复制机制的seq2seq模型,它根据生成器和指针的概率分布预测单词,其中生成器主要利用encoder模块输出的背景向量、decoder当前步的隐藏层以及decoder上一步预测的输出来预测当前步的词汇,生成器预测的摘要为词汇表中的单词,可以预测原文档之外的单词,指针的概率分布预测的单词为指针指向的原文档中的文本,因此指针生成器网络生成的摘要既可以生成新的词汇,也可以复制原文档中的文本。指针生成器网络可以看作是提取方法和抽象方法之间的平衡,通过复制单词提高了未登录词的准确性和处理能力,同时保留了产生新词的能力。本发明使用带有注意力机制的rnn作为解码器来输出摘要。具体步骤如下:
27.步骤4.1将步骤2和步骤3得到的全局语义信息和具有关系信息的局部语义信息通过求和的方式融合,作为decoder模块的初始化隐藏向量。
28.步骤4.2根据attention机制计算原文本中的每个单词对于decoder词的重要程度,对于decoder的每一步,根据不同的重要程度获得具有不同关注信息的原文本的语义表示,称为背景向量。
29.步骤4.3根据原文本的语义表示、上一个时间步的输出以及当前时间步的隐藏向量来预测当前时间步的输出,最终获得每个时间步的预测输出,从而获得原文本的文本摘要。
30.与现有技术相比,本发明具有以下优点:
31.(1)本方法将关键点作为局部特征,原文本作为全局特征,获得了更加丰富的原文本的语义表示。生成高质量摘要的前提是理解原文本语义
32.(2)有意义的特征比没意义的特征更接近全局特征,本方法利用图卷积更新了特征之间的权重,进一步促进了语义信息的传递,并且抑制了无意义的消息传递,从而获得的原文本的语义信息更能体现原文的中心思想,从而保证生成的摘要能够体现原文本的中心,避免生成无中心思想的摘要。
附图说明
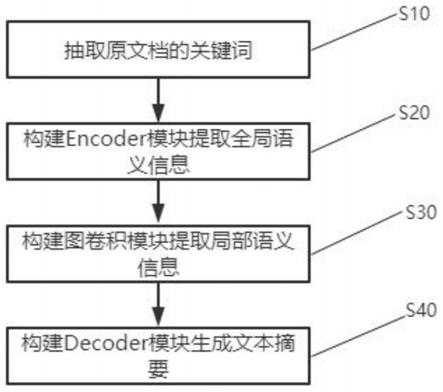
33.图1为本发明具体实施方式的流程图。
具体实施方式
34.以下结合附图和实施例对本发明进行详细说明。
35.实施方式的流程图如图1所示,包括以下步骤:
36.步骤s10,抽取原文档的关键词;
37.步骤s20,构建encoder模块提取全局语义信息;
38.步骤s30,构建图卷积模块提取局部语义信息;
39.步骤s40,构建decoder模块生成文本摘要。
40.步骤1,提取原文本的关键词。
41.对于文本,往往可以通过一些关键词窥探整个文本的主题思想,本发明通过提取出若干个代表文章语义内容的关键词作为文本的局部信息。由于文本摘要相关的数据集中并没有给定关键词,因此,在本发明中,首先需要提取原文档的关键词,本发明使用的方法主要基于无监督的思想。
42.提取原文本关键词的步骤如下:
43.步骤1.1考虑词的位置信息,一般首句和末句出现的词语是关键词的概率更高,因此,我们将文档的首句和末句分别重复3次,从而增加关键词在首句和末句的词频。
44.步骤1.2将文本进行分词,利用每个词的tf-idf统计信息,挑选出20个词语作为候选关键词。
45.步骤1.3我们希望得到的关键词能够尽可能的代表原文本的中心思想,仅仅利用统计信息得到的关键词无法保证这一点,因此我们需要步骤1.2得到的关键词进行进一步的筛选:使用doc2vec获得文档的向量表示d,使用word2vec获得候选关键词的向量表示w。根据w和d的余弦距离对候选关键词进行排序,从初始的候选关键词中挑选出与文档接近的关键短语,关键词与文档越接近,说明信息量越大,从而保证得到的关键词与文档更具有相关性。
46.步骤1.4为避免最终关键词出现冗余,即提取出来的关键词虽然具有不同的表达方式,但具有相同的含义,因而我们需要对步骤1.3得到的关键词进行二次筛选:同理,根据候选关键词之间的余弦距离进行排序,对于有相同语义的关键词,我们只保留一个。
47.步骤2,构建encoder模块。
48.该模块的目的是对输入的文本进行编码,即向量化表示。本发明的encoder模块使用transformer的编码器模块最终获得具有语义特征、上下文特征的原文本的语义表示,我们成为全局语义信息。
49.步骤3,构建图卷积模块。
50.本模块的目的是局部语义信息的关系整合。在步骤1中得到了不同关键词的语义信息,为了挖掘更有效的局部语义特征,我们利用图卷积的方法,将局部特征加入关系特征,从而得到具有关系信息的局部语义信息。在图卷积中,输入包括节点和邻接矩阵,其中节点为步骤1提取出来的局部语义信息,节点之间是有关系的,邻接矩阵表示节点之间的关系程度,然后使用图卷积自适应学习每个关键词之间的关系权重,得到关键词之间的邻接矩阵后,将其和初始的语义信息相乘,得到关系特征,再将关系特征与初始特征融合,得到新的一轮特征。包括以下步骤:
51.步骤3.1在步骤1和步骤2得到了k个局部语义信息以及1个全局语义信息,作为图
的节点。
52.步骤3.2构建图的邻接矩阵,初始化为1。
53.步骤3.3局部特征与整体特征差异越大的,越离群,因此本发明通过计算局部语义信息和全局语义信息的差异,构建差异矩阵,利用差异来动态更新图中所有节点的边的权重。首先将全局语义信息重复k次,分别得到k个局部语义信息与全局语义信息的差异程度,最终得到差异矩阵。
54.步骤3.4利用线性变换等操作将3.3得到的差异矩阵转换为维度为(k,k)的矩阵,称其为更新矩阵。
55.步骤3.5将步骤3.4得到的更新矩阵与邻接矩阵逐元素相乘,该操作的目的就是利用更新矩阵来自适应的学习邻接矩阵。
56.步骤3.6将3.5得到的邻接矩阵与节点信息相乘,得到语义信息的关系特征。
57.步骤3.7将3.6得到的局部关系特征与节点的局部语义信息拼接,得到具有关系信息的局部语义信息。
58.步骤4,构建decoder模块
59.本模块的目的是生成原文本的摘要。指针生成器网络是一个带有复制机制的seq2seq模型,它根据生成器和指针的概率分布预测单词,其中生成器主要利用encoder模块输出的背景向量、decoder当前步的隐藏层以及decoder上一步预测的输出来预测当前步的词汇,生成器预测的摘要为词汇表中的单词,可以预测原文档之外的单词,指针的概率分布预测的单词为指针指向的原文档中的文本,因此指针生成器网络生成的摘要既可以生成新的词汇,也可以复制原文档中的文本。指针生成器网络可以看作是提取方法和抽象方法之间的平衡,通过复制单词提高了未登录词的准确性和处理能力,同时保留了产生新词的能力。本发明使用带有注意力机制的rnn作为解码器来输出摘要。具体步骤如下:
60.步骤4.1将步骤2和步骤3得到的全局语义信息和具有关系信息的局部语义信息通过求和的方式融合,作为decoder模块的初始化隐藏向量。
61.步骤4.2根据attention机制计算原文本中的每个单词对于decoder词的重要程度,对于decoder的每一步,根据不同的重要程度获得具有不同关注信息的原文本的语义表示,称为背景向量。
62.步骤4.3根据原文本的语义表示、上一个时间步的输出以及当前时间步的隐藏向量来预测当前时间步的输出,最终获得每个时间步的预测输出,从而获得原文本的文本摘要。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。