1.本发明属于流数据处理领域,尤其涉及一种负载自适应的分布式空间文本流数据处理系统。
背景技术:
2.基于地理位置的服务的发展导致了空间文本数据的爆炸式增长。社交媒体用户使用微博和微信等社交平台发布含有位置信息的帖子,生活服务平台例如美团等提供外卖和跑腿等同城服务,打车软件也会基于顾客位置信息来给附近的出租车司机发放订单。这些服务在便民的同时也促使了大规模地理标记文本数据流的产生,这些包含空间信息的文本数据含有大量有价值的信息,因此一个具备实时性和高吞吐量的空间文本流数据处理系统尤为重要。
3.现有技术通常使用hadoop或spark等框架来处理大规模数据集。通过扩展hadoop来支持空间文本数据并行处理的spatialhadoop和hadoop-gis是基于磁盘的空间分析系统,对于流式空间文本数据的实时性不够好。geospark和locationspark是基于spark的分布式空间数据分析系统,前者采用了quadtree和r-tree两种空间索引结构来支持空间链接,范围查询和knn查询;后者通过查询调度器和本地查询执行器扩展了spark。这些基于磁盘和内存的系统侧重于静态空间数据,不适合大规模流数据,存在巨大的通信成本和负载不均衡问题。
技术实现要素:
4.本发明的目的在于针对现有技术不适合空间文本流数据,以及通信成本高和负载不均衡等缺陷,提供一种负载自适应的分布式空间文本流数据处理系统。该系统可用于空间文本流数据的分布式处理,能够支持更加实时高效和负载均衡的查询工作。
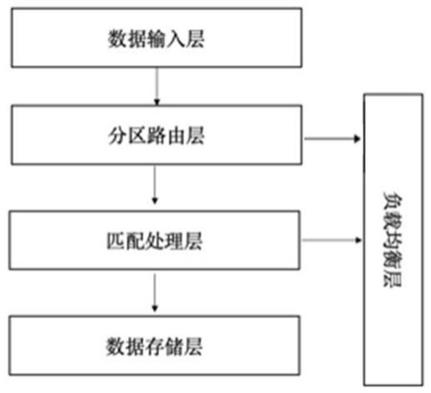
5.本发明的目的是通过以下技术方案来实现的:一种负载自适应的分布式空间文本流数据处理系统,该系统包括:
6.数据输入层,用于读取流式空间文本数据对象和空间查询,并进行解析和预处理后,得到包含标识符、地理位置、文本数据和产生时间的空间文本数据对象四元列表以及包含标识符、查询范围、关键字和查询持续时间的空间查询四元列表;
7.分区路由层,根据来自数据输入层的流式空间文本数据对象和空间查询的四元列表进行空间分区的路由操作;
8.匹配处理层,基于分区路由层的空间分区,在空间查询的持续时间内,存储并连续匹配满足查询空间范围和查询关键字集合的空间文本数据对象;
9.负载均衡层,用于实时监控和收集匹配处理层中匹配处理层的负载信息,并在负载失衡时,调用负载自适应策略,并对局部空间分区重新划分,以满足负载均衡;
10.数据存储层,用于存储匹配处理层中的过时数据。
11.进一步地,所述数据输入层将空间文本数据对象的流数据进行解析,处理成后续
容易操作的四元列表;所述空间文本数据对象为含有位置信息的文本数据,将其处理为四元列表lo=[oid,loc,text,ts],oid为数据对象标识符,loc为地理位置,text为文本数据,ts为产生时间;所述空间查询为包含空间范围和关键字限定的过滤查询,将其处理为四元列表lq=[qid,mbr,text,t],qid为查询标识符,mbr为查询空间范围的矩形边界,text为查询关键字集合,t为查询持续时间。
[0012]
进一步地,所述分区路由层对空间文本数据对象和空间查询进行索引和搜索空间分区;每一个空间分区对应连续单元格组成的矩形区域,空间分区中的每一个单元格均包含该空间分区的标识符信息和边界信息;空间文本数据对象的loc信息确定唯一的空间分区,而查询的空间范围会覆盖多个空间分区。
[0013]
进一步地,空间分区所占据的矩形区域的划分具有顺序,首先在横向或纵向上进行第一维度的切分,形成候选空间分区,然后再对候选空间分区在另一个维度上进行切分,以形成空间分区:
[0014]
定义两个二元组(xmin,ymin),(xmax,ymax)来表示空间分区的位置,(xmin,ymin)为空间分区的左下角单元格坐标,(xmax,ymax)为空间分区的右上角单元格坐标。空间查询在遍历所覆盖的空间分区时,通过《y不变,xmax 1》的方法向右移动,遍历同一候选空间分区中的其他空间分区,然后再将x变为此候选空间分区的第一个主单元格横坐标,对y进行ymin-1操作,向下移动,到达其他候选空间分区,从而遍历空间查询所覆盖的所有空间分区;
[0015]
定义一个主单元格,即空间查询所覆盖的空间分区的左上角单元格。在进行邻近空间分区搜索时只访问主单元格。
[0016]
进一步地,在邻近搜索时,当向右移动到未被查询空间范围覆盖到的空间分区时,改变y值进入其他候选空间分区进行遍历;当向下移动到未被查询空间范围覆盖到的空间分区,则路由操作结束。
[0017]
进一步地,所述匹配处理层由多个处理单元组成,每一个空间分区对应一个处理单元,每个处理单元都维护一个局部关键字索引;当空间文本数据对象的地理位置满足空间查询的空间范围并且空间文本数据对象的文本数据信息包含空间查询的所有关键词时,为该空间查询匹配这个空间文本数据对象。
[0018]
进一步地,所述匹配处理层对流式空间文本数据对象划分时隙,每隔一定时间更新时隙,越旧的数据具有越粗的粒度;粒度遵循指数函数f(x)=2
x
,其中x为数据在匹配处理层中的生存时间;定期检查处理单元内数据大小,若超过预定义阈值,则将最旧的时隙数据存入数据存储层。
[0019]
进一步地,所述负载均衡层实时监控和收集匹配处理层每个处理单元的总负载信息wi和维度负载分布表wdi,当处理单元中最大的负载和处理单元中最小的负载之比w
max
/w
min
》δ时,基于负载自适应策略,转移最大负载处理单元p
max
中的负载到该处理单元的邻近处理单元上;其中维度负载分布表wdi统计该处理单元在第二维度上的负载分布情况。
[0020]
进一步地,当匹配处理层的负载不平衡时,在同一候选空间分区内重新划分最大负载处理单元附近的局部空间分区,过程如下:
[0021]
(1)根据p
max
的二元组坐标(xmin,ymin),(xmax,ymax)确定与p
max
位于同一候选空间分区的相邻处理单元所在的空间分区;
[0022]
(2)对p
max
和相邻两处理单元进行局部空间重划分操作,先计算相邻三个空间分区的总负载,进而得到每个空间分区的平均负载,以重划分后三者中的最大负载为w
max
,若不再满足w
max
/w
min
》δ的均衡触发条件,则进行步骤(3),否则扩大局部空间重划分的范围,加入p
max
的相邻两处理单元的邻近处理单元后,判断是否满足均衡触发条件,若不满足,进行步骤(3),若满足,再次扩大局部空间重划分的范围,以此类推,直至重划分后的空间分区不满足均衡触发条件;
[0023]
(3)重划分时,按空间顺序从左到右合并n个处理单元的维度负载分布表wd
i1
,wd
i2
,
…
,wd
in
,对n个处理单元需要进行n-1次切分,重新划分为n个空间分区;切分过程具体为:对合并后的维度负载分布表从左到右进行维度负载的累加,当第一次累加和大于或等于平均负载时,进行第一次切分,不清零继续累加,第二次累加和大于或等于两倍的平均负载时,进行第二次切分,以此类推,直到进行n-1次切分。
[0024]
进一步地,所述数据存储层将过时的数据从匹配处理层的处理单元中的内存释放,写入持久性存储器,与其他外围系统连接,以供将来的处理分析,所述外围系统包括rdms,hdfs,hbase,hive。
[0025]
本发明的优点及有益效果是:
[0026]
1.能够降低所有处理单元的总负载,并且提高实时性和吞吐量。
[0027]
本发明对空间文本数据对象和查询进行空间分区的路由时,采用neighbor-based路由算法的增强网格,搜索复杂度不依赖于网格的粒度,只和邻近空间分区的数量有关,大大降低了路由的开销。对处理单元中的流数据划分时隙,定期迁移过时数据,提高了实时性和吞吐量。
[0028]
2.动态调节负载,并且大大降低了负载迁移的开销。
[0029]
本发明增加负载均衡层,可以实时监控各处理单元的负载变化,负载平衡机制是增量的,即不是重新定义所有分区,只是简单的移位,拆分和合并操作来更新少数邻近分区,大大地降低了负载迁移的开销。
附图说明
[0030]
下面结合附图和实施例对本发明进一步说明;
[0031]
图1为本发明的一种负载自适应的分布式空间文本流数据处理系统;
[0032]
图2为本发明分区路由层空间分区的划分和搜索说明图;
[0033]
图3为本发明负载均衡空间分区示意图。
具体实施方式
[0034]
为使本发明实施例的目的、技术方案和优点更加清楚,下面结合附图和实施例详细说明本发明的实施方式。
[0035]
如图1所示,本系统由五个部分组成,分别是数据输入层,分区路由层,匹配处理层,负载均衡层和数据存储层。系统的输入数据为特定的流数据,如社交平台上带位置信息的帖子,搜索引擎中的搜索条目,打车软件顾客发起的乘车请求等。
[0036]
首先,将上述携带地理位置信息的空间文本数据对象和空间查询接入数据输入层进行解析和预处理。
[0037]
接着,处理后的流数据进入分区路由层,将空间文本数据对象和空间查询路由到相关空间分区的处理单元上。
[0038]
然后,在处理单元上对空间查询和空间文本数据对象进行匹配并对流数据划分时隙,转移过时数据。
[0039]
数据存储层对来自匹配处理层处理单元上的过时数据与其他外围文件系统对接,以供将来分析。
[0040]
最后,负载均衡层实时监控处理单元上的负载变化,当负载失衡时,使用空间分区路由算法搜寻邻域,并调用均衡策略转移负载。
[0041]
本发明中各个子系统的详细介绍如下:
[0042]
1.数据输入层
[0043]
主要用于读取流式空间文本数据对象和空间查询并对原始数据流进行解析和预处理,得到包含标识符,地理位置,文本数据和产生时间的四元列表以及包含标识符、查询范围、关键字和查询持续时间的空间查询四元列表。
[0044]
具体地,数据输入层对给定流数据的处理过程如下:
[0045]
提取原始流数据中包含的标识符,地理位置,文本数据和产生时间信息,将其表示为四元列表。所述空间文本数据对象为含有位置信息的文本数据,将其处理为四元列表lo=[oid,loc,text,ts],oid为数据对象标识符,loc为地理位置,text为文本数据,ts为产生时间。所述空间查询为包含空间范围和关键字限定的过滤查询,将其处理为四元列表lq=[qid,mbr,text,t],qid为查询标识符,mbr为查询空间范围的矩形边界,text为查询关键字集合,t为查询持续时间。
[0046]
2.分区路由层
[0047]
主要基于来自数据输入层的流式空间文本数据对象和空间查询的四元列表进行空间分区的路由操作。
[0048]
具体地,如图2所示,分区路由层对流式空间文本数据对象和空间查询分配和搜索空间分区的处理过程如下:
[0049]
首先,分区路由层将空间在y方向上进行第一维度的切分,形成候选空间分区rs1,rs2,rs3,
…
,然后再对rsi在x方向上进行切分,以形成最终的空间分区s
ij
,每个空间分区都是包含连续多个单元格的矩形区域,其中i值相同的空间分区属于同一个候选空间分区rsi。此时分区路由层将空间划分为不重叠的矩形空间分区s
ij
,一个矩形空间分区s
ij
对应一个匹配处理层的处理单元p
ij
,由于实际中处理单元p
ij
的数量是巨大的,分区路由层用来索引匹配处理层的处理单元,为流式空间文本数据对象和空间查询分配相关处理单元。通过不重叠的空间分区s
ij
,分区路由层可以根据空间文本数据对象的loc信息,将其直接分发所在空间分区的单个处理单元p
ij
。
[0050]
空间查询的空间范围mbr可能与多个空间分区s
ij
重叠,因此需要将空间查询路由到多个处理单元。对空间查询的路由操作我们使用空间分区路由算法来建立处理单元p
ij
的索引和搜索。每个处理单元p
ij
所在的空间分区s
ij
在网格区域上都可以表示为两个二元组,第一个二元组(xmin,ymin)表示网格区域左下角单元格的坐标,第二个二元组(xmax,ymax)表示网格区域右上角单元格的坐标。两个点的坐标即可以确定一个网格区域,即对应的空间分区。网格区域中的每个单元格都维护着对应空间分区的标识符信息和边界信息。
[0051]
主单元格是空间查询所覆盖的空间分区的左上角单元格,在搜索邻近空间分区时,我们只需要访问每个空间分区中的主单元格,就可以知道空间分区的标识符和边界信息,然后通过《y不变,xmax 1》的方法向右移动,遍历同一候选空间分区中的其他空间分区,然后再将x变为此候选空间分区的第一个主单元格横坐标,对y进行ymin-1操作,向下移动,到达其他候选空间分区,从而遍历空间查询所覆盖的所有空间分区。在搜索邻近的空间分区时,当沿着网格向右访问到未被查询空间范围覆盖到的空间分区时,改变y值进入其他候选空间分区进行遍历;当向下访问到未被查询空间范围覆盖的单元格时,标志着空间查询的路由完毕。
[0052]
例如图2中空间查询mbr所覆盖的空间分区在进行索引和搜索空间分区时,从主单元格(1,8)开始搜索,得到此主单元格所在的空间分区标识符s
11
及空间分区的边界信息(0,5),(1,9),然后在同一候选空间分区rs1中向右搜索,将空间分区边界信息的xmax 1作为新的横坐标,纵坐标不变,到达下一个空间分区的主单元格(2,8),得到此主单元格所在的空间分区标识符s
12
及空间分区的边界信息(2,5),(6,9),将空间分区边界信息的xmax 1作为新的横坐标,纵坐标不变,到达下一个空间分区的主单元格(7,8),得到此主单元格所在的空间分区标识符s
13
及空间分区的边界信息(7,5),(9,9),向右继续访问下一个空间分区的主单元格(10,8),超出空间查询mbr所覆盖的空间分区,该候选空间分区rs1搜索结束,将x变为此候选空间分区的第一个主单元格(1,8)的横坐标,对y进行ymin-1操作,向下移动,到达下一个候选空间分区rs2的第一个主单元格(1,4),得到此主单元格所在的空间分区标识符s
21
及空间分区的边界信息(0,3),(4,4),然后向右向下搜索得到所覆盖的空间分区标识符s
22
,s
31
,s
32
,s
33
,当继续向下遍历时,得到下一个候选空间分区的主单元格(1,1),不在空间查询mbr所覆盖的空间范围内,则路由操作结束。
[0053]
3.匹配处理层
[0054]
主要用于在空间查询的持续时间内,存储并连续匹配满足查询空间范围和查询关键字集合的空间文本数据对象。
[0055]
具体地,匹配处理层由多个处理单元组成,每一个空间分区对应一个处理单元,每个处理单元都维护一个局部关键字索引。当空间文本数据对象的地理位置满足空间查询的空间范围并且空间文本数据对象的文本信息包含空间查询的所有关键词时,为该空间查询匹配这个空间文本数据对象。匹配处理层对到来的流式空间文本数据对象划分时隙,每隔一定时间更新时隙,越旧的数据具有越粗的粒度。其中更新时隙的时间间隔可以为1小时、3小时、6小时等;粒度遵循指数函数f(x)=2
x
,其中x为数据在匹配处理层中的生存时间。定期检查处理单元内数据大小,若超过预定义阈值,如总存储的50%,则将最旧的时隙存入数据存储层。
[0056]
4.负载均衡层
[0057]
主要用于实时监控和收集每个处理模块的负载信息,并在负载失衡时,调用负载自适应策略,对同一候选空间分区内局部空间分区重新划分,以满足负载均衡。
[0058]
具体地,给定一个时间段,某个处理单元w
ij
的负载大小为w
ij
=c1·
|o
ij
|
·
|q
iji
| c2·
|o
ij
| c3·
|q
iji
| c4·
|q
ijd
|,其中所述o
ij
是处理单元中空间文本数据对象集合,q
iji
是给定时间段查询插入请求集合,q
ijd
是给定时间段查询删除请求集合,c1是一个查询和一个空间文本数据对象的匹配开销,c2是处理一个空间文本数据对象的平均开销,c3是处理查询
插入的平均开销,c4时处理查询删除的平均开销。负载均衡层实时监控和收集每个处理模块的总负载信息w
ij
和维度负载分布表wd
ij
,当处理单元中最大的负载和处理单元中最小的负载之比满足w
max
/w
min
》δ的均衡触发条件时,转移最大负载处理单元p
max
中的负载到该处理单元的邻近处理单元上。
[0059]
(1)根据p
max
的二元组坐标(xmin,ymin),(xmax,ymax)可以确定与p
max
位于同一候选空间分区的相邻处理单元所在的空间分区;
[0060]
(2)对p
max
和相邻两处理单元进行局部空间重划分操作,先计算三个空间分区的总负载,进而得到每个空间分区的平均负载,预演步骤(3),以重划分后三者中的最大负载为w
max
,若不再满足w
max
/w
min
》δ的均衡触发条件,则进行步骤(3),否则扩大局部空间重划分的范围,加入p
max
的相邻两处理单元的邻近两处理单元后,判断是否满足均衡触发条件,若不满足,再进行步骤(3),若满足,再次扩大局部空间重划分的范围,以此类推,直至重划分后的空间分区不满足均衡触发条件;
[0061]
(3)重划分时,按空间顺序从左到右合并n个处理单元的维度负载分布表wd
i1
,wd
i2
,
…
,wd
in
,对n个处理单元需要进行n-1次切分,重新划分为n个空间分区,切分过程具体为:对合并后的维度负载分布表从左到右进行维度负载的累加,当第一次累加和大于或等于平均负载时,进行第一次切分,不清零继续累加,第二次累加和大于或等于两倍的平均负载时,进行第二次切分,以此类推,直到进行n-1次切分。
[0062]
如图3所示,每个处理模块的维度负载分布表记录了空间分区内负载在横轴上的分布情况,空间分区s
ij
由三列单元格组成,统计并监控每列单元格的负载之和,得到该处理模块的维度负载分布表wd
ij
=[8,2,10]和总负载信息w
ij
=20。当由于空间分区s
ij
所在的处理单元p
ij
超负荷运行成为p
max
且满足均衡触发条件时,对p
ij
和位于同一候选空间分区的相邻处理单元p
i(j-1)
、p
i(j 1)
进行局部空间重划分操作。根据p
ij
的空间分区s
ij
的两个二元组坐标(xmin,ymin),(xmax,ymax),通过《xmin-1,ymax》和《xmax 1,ymax》分别到达左侧和右侧空间分区,得到其空间分区标识符s
i(j-1)
、s
i(j 1)
和维度负载分布表wd
i(j-1)
([2,2,4,2,8])、wd
i(j 1)
([2,4,2,2]),得到三者的总负载为40,平均负载为13.3,预演步骤(3),进行两次切分,得到负载均衡后的处理模块总负载信息w
i(j-1)
,w
ij
和w
i(j 1)
分别为18,14,8;若最大负载wmax=18时不再满足均衡触发条件,则执行步骤(3),否则扩大局部空间重划分的范围,加入s
i(j-2)
、s
i(j 2)
计算5个空间分区的总负载和平均负载,并预演步骤(3),以此类推,直到不再满足w
max
/w
min
》δ的均衡触发条件。
[0063]
5.数据存储层
[0064]
主要用于存储匹配处理层的处理模块中的过时数据。
[0065]
具体地,数据存储层会将过时的数据从处理单元中的内存释放,写入持久性存储器,该系统与其他外围系统(如rdms,hdfs,hbase,hive等)连接,以供将来的处理分析。
[0066]
上述实施例用来解释说明本发明,而不是对本发明进行限制,在本发明的精神和权利要求的保护范围内,对本发明作出的任何修改和改变,都落入本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。