1.本发明属于图像美学风格分类领域,涉及一种摄影图像美学风格分类方法,特别涉及一种基于自监督特征学习与深度森林的多标签摄影图像美学风格分类方法。
背景技术:
2.由于在摄影图像中,总是包含多种美学风格标签,因此多标签的摄影图像美学风格分类方法相比单标签更有实际意义,目的是为了把摄影图像所属的美学风格都预测出来。由于摄影图像包含多种美学风格标签,分类的结果组合数目相比单标签是指数级别的增长,多标签摄影图像美学风格分类问题难度更大、精度更低。
3.现有方法主要存在以下问题:现有的大规模数据集不适用于美学风格分类任务的特征学习,很难学习到对美学风格分类任务有价值的特征;多标签任务学习时不能充分利用标签之间的关联信息
技术实现要素:
4.针对现有技术中存在的不足,本发明提供了一种基于自监督学习与深度森林的摄影图像美学风格分类方法,包含自监督特征学习模型和深度森林模型。利用大规模的美学图像对自监督特征学习模型进行训练,训练完成后,将多标签的摄影图像数据集作为输入,得到对应的特征向量矩阵作为深度森林模型的输入,训练深度森林模型,得到最终的多标签预测结果。
5.本发明的技术方案为:
6.步骤1:构建并训练自监督特征学习模型;
7.所述的自监督特征学习模型由特征提取网络与投影网络组成。
8.步骤1-1:建立特征提取网络。
9.步骤1-2:建立投影网络。
10.步骤1-3:建立自监督对比学习损失函数。
11.步骤2:构建并训练深度森林模型,具体包括:
12.步骤2-1:数据集采用多标签摄影图像共2000张,总共有14个摄影美学风格,每张图像有大于1个的摄影美学风格标签。将这2000张图像通过步骤1中的自监督特征学习模型得到的特征向量按照列拼接得到输入矩阵。
13.步骤2-2:建立深度森林模型层次结构。
14.步骤2-3:建立深度森林模型层与层之间的连接方式。
15.步骤3:通过训练好的特征提取网络和深度森林模型完成摄影图像美学风格分类。
16.本发明的有益效果:
17.1.采用自监督特征学习模型进行预训练,充分挖掘美学特征,有利于深度森林模型更好寻找多标签摄影图像美学风格分类的最优解。
18.2.深度森林模型在迭代训练过程中充分考虑了多标签之间的关联信息,提升多标
签摄影图像美学风格分类的精度。
附图说明
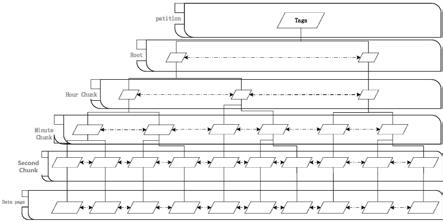
19.图1为本发明方法实施例流程示意图。
具体实施方式
20.下面结合附图,对本发明的具体实施方案作进一步详细描述。
21.如图1所示,一种基于自监督学习与深度森林的摄影图像美学风格分类方法,步骤如下:
22.步骤1:构建并训练自监督特征学习模型,具体如下:
23.所述的自监督特征学习模型由特征提取网络与投影网络组成。
24.步骤1-1:建立特征提取网络。
25.数据集采用ava美学数据集共250000张美学图像,针对每个输入样本x,将resnet50作为特征提取网络得到表征向量resnet50作为特征提取网络得到表征向量进行归一化到超球面。
26.步骤1-2:建立投影网络。
27.获得表征向量r后,通过投影网络获得向量投影网络为一个多层感知机网络,包括一个2048维度的隐层和一个d
p
=128的输出层。将向量z再次归一化到超球面。
28.步骤1-3:建立自监督对比学习损失函数。
29.若给定容量为n的一批随机采样的数据/标签对{xk,yk}
k=1
…n,则对应用于训练的是经过数据增强(旋转,平移等)的一批数据容量为2n的数据/标签对其中和是xk分别经过两次不同数据增强生成的,且标签
30.在同一批次训练数据中,任意选取i∈i≡1
…
2n索引的数据作为基准数据,则j(i)是与索引i的数据来源于同一个源数据样本进行数据增强得到的另一个数据索引。自监督对比学习损失函数公式如下:
[0031][0032]
其中,符号
·
表示内积运算,表示温度系数,。j(i)索引的数据作为正样本,a(i)表示其余数据的集合作为负样本。
[0033]
步骤2:构建并训练深度森林模型,具体如下:
[0034]
步骤2-1:数据集采用ava美学数据集中的多标签摄影图像共2000张,总共有14个摄影美学风格,每张图像有大于1个的摄影美学风格标签。将这2000张图像通过步骤1-1中的特征提取网络得到的对应的2000个2048特征向量按照列拼接得到输入矩阵。
[0035]
步骤2-2:建立深度森林模型层次结构。将步骤2-1得到的输入矩阵作为第一层的
输入。深度森林模模型一共有5层,每一层由4个随机森林模型组成,包括2个普通随机森林模型和2个完全随机森林模型。两者的区别在于分支时特征选取的不同,普通随机森林选取(n为样本特征数量)作为候选,之后再用基尼系数选取最佳的特征进行分支;而完全随机森林从n个特征中随机选取一个进行分支。给定数据集x
mn
,其中每一行xi(i=0,
…
,m-1)=[x0,
…
,x
n-1
],对应的标签集合为y
ml
,其中每一行为yi(i=0,
…
,m-1)=[y0,
…
,y
1-1
]。其中m=2000为样本总数,n=2048为特征总数,k=14为标签总数。模型每一层的随机森林模型会生成输入样本图像属于某个风格标签的概率值,如果该概率值大于设定的阈值,则判断该图像属于该风格标签,输出1,否则判断不属于,输出0。
[0036]
步骤2-3:建立深度森林模型层与层之间的连接方式。对每一层模型来说,遍历全部的4个随机森林模型,每个随机森林模型都采用多折交叉训练的方式。这样每个随机森林模型会输出一个m行k列的矩阵,表示的是每一个图像属于每一个风格标签的概率值。因此,每一层总共输出4个标签的概率矩阵,按列拼接得到输出矩阵其中t表示第t层的输出的结果矩阵,而m
×
4k表示矩阵的规模是m行,4*k列。
[0037]
层与层之间的连接方式采用复用机制。对于第一层的输出,直接将输出矩阵与最初的输入矩阵按照列拼接在一起,作为深度森林模型中下一层的输入。下一层同样按照第一层进行训练,生成结果矩阵。此时复用机制生效,将当前层的训练输出与上一层的训练输出做运算,生成新矩阵具体运算如下:
[0038][0039]
根据多标签任务评价指标的不同,将上一层中性能表现好的列或者行替换当前层的输出的对应的列或者行。如果采用hamming loss作为评价指标的计算方式,就是以列的方式迭代计算,计算每一列的hamming loss,当当前层的输出矩阵中某一列的损失比上一层的相同随机森林模型相同列的损失大,即性能更差,则这一列计算出的置信度放入集合中。迭代完后,得到当前预测结果中表现不好的列的置信度集合,对该置信度集合求平均,得到平均置信度。因此对于当前输出矩阵的每一列,如果置信度小于平均置信度,则用上一层的结果来代替这一列。
[0040]
当到达最后一层时,采用最大概率投票法得到最终预测的多标签结果,具体表达如下:
[0041][0042]
步骤3:通过训练好的特征提取网络和深度森林模型完成摄影图像美学风格分类。
[0043]
输入一张摄影图像,通过步骤1-1中的特征提取网络得到特征向量,再输入到步骤2中的深度森林模型,得到预测的多标签分类结果。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。