1.本发明属于人工智能领域,涉及一种基于神经网络的语音增强方法。
背景技术:
2.话音增强的目标是从噪声环境中将目标语音分离出来,在许多研究中也称为语音分离。语音分离是语音信号处理的基本方法和任务,在许多应用中,只有将语音尽可能地与背景干扰和噪声分隔开,后续处理过程才会取得良好的效果。早期的语音增强算法主要以非监督学习算法为主,基于统计信号模型设计算法。但这些算法依赖人工假设的数学模型,往往与实际条件有一定的偏差,因此性能始终有限。近年来,随着硬件计算能力的快速进步和深度学习理论的快速发展,基于深度学习的语音增强方法被大量提出并迅速成为语音增强的主要发展方向。现有深度学习语音增强方法绝大多数以卷积层作为主要网络组成部分,提取语音的局部信息;以循环神经网络(recurrent neural network,rnn)作为辅助模块,提取语音的时间信息。然而,尽管卷积运算由于其简单的结构和强大的特征提取能力而成为神经网络的基本组成单元,但目前一些研究认为常规的卷积存在两个缺陷需要解决:第一个缺陷是卷积运算的内容无关性,即卷积网络的滤波器是空间不变的,并且其参数在训练完成后面对不同的输出将不会再改变,故而理论上空间不变性的滤波器在面对内容各异的输入时,其特征提取能力是次优的;第二个缺陷是卷积运算的计算复杂度会随着滤波器的大小和通道数目的增加而急剧增加,这就导致了滤波器的尺寸往往被限制在较小的数值(3
×
3,5
×
5或者7
×
7),因而导致感受野较小从而进一步限制了网络的性能。
技术实现要素:
3.本发明针对背景技术的缺陷,将前沿的动态解耦滤波器(decoupled dynamic filter,ddf)引入到经典的门控卷积循环网络(gated convolutional recurrent networks,gcrn)中,提出了一种新型的动态门控卷积循环网络(语音增强网络)语音增强方法。本发明将原始gcrn中的主支路卷积层全部换成了动态滤波器ddf,一方面降低了计算量和参数量,另一方面使得相应卷积层的卷积参数根据输入自适应地进行调整,具有更强的特征提取能力,性能得到了显著提升。
4.本发明技术方案为一种基于动态卷积门控卷积循环网络的语音增强方法,该方法包括:
5.步骤1:建立语音增强网络;
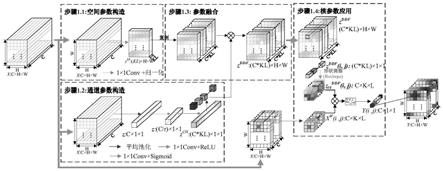
6.步骤1.1:构造ddf空间参数
7.输入的语音x有ci个通道,其频率方向大小为h,时间方向大小为t,输入表示为x∈rc×h×
t
;将期望生成的滤波器沿着频率方向的长度设置为k,沿着时间方向的长度设置为l,即期望使用大小为k
×
l的滤波器处理输入特征,则应用一个输入通道为ci,输出通道为kl的1
×
1卷积层对其进行处理,得到空间上参数z
(sp)
∈r
kl
×h×w,即
[0008][0009]
然后对z
(sp)
的每个空间位置上长度为kl
×1×
1的向量进行归一化,即
[0010][0011][0012]
其中,e[
·
]和std[
·
]分别表示取均值和标准差,而α和γ是可学习的参数;
[0013]
最后将沿着通道第一个维度复制ci份得到规整后的形式为
[0014]
步骤1.2:构造ddf通道参数
[0015]
首先对x的每个通道取均值得到x
gap
∈rc×1×1,再连续使用两个1
×
1卷积对x
gap
进行处理,最终得到通道分支参数所述的两个卷积分别表示为和并且σ是取值范围为(0,1)区间内的常数,即:
[0016][0017][0018]
其中,φ表示线性整流激活函数,将z
(ch)
沿着第2个维度复制h次,再沿着第3个维度复制t次得到规整后的形式为
[0019]
步骤1.3:融合空间参数和通道参数
[0020]
将得到的和逐点对应相乘得到再将的第一个维度拆解成大小为ci、k和t的三个新的维度得到最终的得到通过步骤1.1~1.2构造的卷积层滤波器,由于该滤波器是根据输入动态生成并被用于与输入信号进行卷积,故而称为动态卷积核,对于输入的每个通道和每个时间、频率位置,都具有对应的大小为k
×
l的滤波器参数;
[0021]
步骤1.4:应用处理输入x,将得到的输出结果记为y∈rc×h×
t
;
[0022][0023]
其中,表示在通道为c,频率位置为i,时间位置为j上大小为k
×
l的滤波器中位置为(k,l)处的滤波器参数,x[c,i-k,j-l]通道为c,频率位置为i-k,时间位置为j-l的输入样本点;
[0024]
步骤2:由纯净语音数据集x
train
构造含噪语音数据集
[0025][0026]
其中,x
train
表示纯净语音数据集,n
train
为指定信噪比的加性噪声;将纯净语音数据集x
train
和含噪语音数据集经过短时傅里叶变换进行特征提取,获得相应语音信号
的stft谱数据集:训练输入和训练目标输出x
train
;
[0027]
步骤3:训练步骤1得到的语音增强网络;
[0028]
将步骤2所得的作为输入信号,x
train
作为目标,使用如下所示的mse作为损失函数进行卷积神经网络训练,
[0029][0030]
其中,为步骤1得到的语音增强网络的实际输出,和分别表示对信号取实部和虚部,直到训练完毕;
[0031]
步骤4:采用训练好的语音增强网络对实际语音进行增强处理。
[0032]
进一步地,所述语音增强网络中通过构造空间参数和通道参数生成的卷积核大小均设为(k,l)=(3,1),所述语音增强网络设置5个带门控分支的卷积层和5个带门控分支的反卷积层,称为门控卷积模块和门控反卷积模块,即对每个模块中的卷积层和反卷积层均使用并行的门控分支进行调整,门控分支的设置与卷积层一致,但使用sigmoid作为激活函数;卷积层和反卷积层的滤波器系数使用步骤1.3得到的中为卷积层和反卷积层提供相应的系数;此外,前5个门控卷积模块通过将步长设置为2不断压缩输入沿频率方向的大小,即每过一个卷积层,输入的长度减小一半,而后5个门控反卷积模块通过将步长设置为2不断将输入的长度恢复成原来的2倍;所有卷积层和反卷积层的通道数均设置为64;长短时记忆(long-short-time-memory,lstm)的输入特征数和隐藏神经元数均为320,所有激活函数均使用prelu。进行stft时,将语音信号使用汉明窗进行分帧,每帧帧长256,相邻两帧重叠50%的采样点,逐帧进行傅里叶变换即可得到信号语谱图;由于语音是实信号,其频谱是共轭对称的,因此仅取半边谱,即每帧129长度送入语音增强网络。
[0033]
本发明的主要特点在于:创新性地提出将动态卷积应用于深度学习语音增强方法中,令神经网络的参数随着输入的变化而动态调整,这一做法克服了卷积网络完成训练之后内容不可知的特性,即网络参数不再随着输入而变化从而导致特征提取能力次优的问题,使得神经网络能够更好地提取特征;本发明使用了前沿的ddf动态卷积方法,并将其嵌入到先进的神经网络结构gcrn中,重新设计了相应的门控卷积模块和门控反卷积模块,在参数量没有增加的情况下取得了显著优于原始gcrn的性能。
附图说明
[0034]
图1为本发明适用的ddf的简化框图;
[0035]
图2为本发明使用的语音增强网络网络结构图;
[0036]
图3为本发明方法中语音增强网络中的门控卷积模块结构图,门控反卷积模块与之相似,仅仅将门控分支(gate branch)中的卷积层换为反卷积。
具体实施方式
[0037]
下面结合附图和实施例,详述本发明的技术方案。但不应将此理解为本发明上述主体的范围仅限于以下实施例,凡基于本发明内容所实现的技术均属于本发明的范围。
[0038]
ddf被提出后已经被证明能够取得比常规的卷积层更好的特征提取能力。本发明使用ddf替代了图2所示的语音增强网络结构中各个模块中的卷积层以及反卷积层。每个门控卷积模块和门控反卷积模块中ddf的具体位置如图3所示,由于门控卷积模块与门控反卷积模块结构类似,仅将门控分支(gate branch)中的卷积层换成了反卷积层,因此不再给出冗余图示。值得注意的是,在门控卷积模块中,ddf分支和门控分支中均通过调整步长为2压缩输入的频率维度大小至原来的二分之一,而在门控反卷积模块中的ddf分支通过子像素卷积的方式来将输入的频率维度(第二个维度)大小扩大两倍:假设门控反卷积模块的输入为x∈rc×h×
t
,则通过该模块的ddf后的输出为y
′
∈r
2c
×h×
t
,将y
′
中一半的通道维度分离出来填充到频率维度中,即:
[0039][0040]
其中1≤i≤h,1≤j≤t。由于子像素操作是比较基础的深度学习处理手段,此处不再赘述。而门控反卷积模块中的门控分支使用反卷积层完成频率维度扩增的操作;经过以上修改,得到本发明提出的语音增强网络。
[0041]
数据集和仿真参数设置如下:
[0042]
本发明实施例采用timit数据集对语音增强网络进行训练和测试,该数据集包含了由630名发音人员构成的6300条音频(70%为男性)。选择其中的4620条音频作为训练数据x
train
,另外1680条作为测试数据x
test
。
[0043]
训练数据x
train
添加的噪声类型为短波噪声,指定噪声snr为-5db,-4db,-3db,-1db和0db,每个snr下的音频数目为1500,即总共9000条音频用于训练。
[0044]
测试数据x
test
所选噪声类型为短波噪声,指定噪声snr为0db。
[0045]
所有音频数据采样率为8khz,使用汉明窗进行加窗分帧操作,帧长为256样本,帧移为128样本。
[0046]
卷积神经网络使用adam优化器以1e-3的初始学习率对模型进行训练,每一个怕批次(mini-batch)的大小为4,每5个训练周期(epoch)减小一半学习率。
[0047]
评价指标:语音质量感知指标(perceptual evaluation of speech quality,pesq),该指标的量化区间为-0.5~4.5,分数越高,表示语音质量越好。短时客观可懂度(short-time objective intelligibility,stoi),该指标的量化区间为0~1,可使用百分比的形式表示,分数越高代表语音质量越好。
[0048]
具体实施例包括以下步骤:
[0049]
步骤1:根据图1的ddf简化框图构建ddl模块,并将其插入到图3所示的门控卷积模块或者门控反卷积模块结构中,再使用图3所示的门控卷积模块和门控反卷积模块构建图2所示的gcrn结构,得到语音增强网络网络。
[0050]
步骤2:由将上述timit语音训练数据集x
train
构造含噪语音数据集
[0051][0052]
其中n
train
为指定信噪比的加性噪声,从而获得9000条语音数据集x
train
和含噪语音数据集将这两个处理后的数据集与纯净语音数据集经过短时傅里叶变换(short time fourier transform,stft)进行特征提取,获得相应语音信号的stft谱数据集获得相
应语音信号的语谱图数据集x
train
和转入步骤3.
[0053]
步骤3:训练步骤1构造的神经网络语音增强网络,将步骤2所得的语音语谱图数据集作为输入信号,将纯净语音语谱图数据集x
train
作为目标,使用mse作为损失函数进行卷积神经网络训练,最终获得具有噪声抑制能力的神经网络模型,转入步骤4.
[0054]
步骤4:将步骤3获得的神经网络模型语音增强网络用于实际信号的语音增强。首先对待增强信号y
test
进行stft得到语谱图y
test
,将y
test
送入语音增强网络得到输出对进行逆stft,得到增强后的信号由此完成本发明的短波语音增强。
[0055]
与本发明的方法对比的有:短波语音不经过增强处理(unprocessed),使用原始gcrn算法,以及本发明所用方法语音增强网络。如下表1所示为0db下不同方法在不同噪声上对于pesq指标和stoi指标的测试结果。
[0056]
表1
[0057]
质量指标pesqstoi(%)unprocessed1.483669.0589gcrn2.724986.7464本发明语音增强网络2.881888.9105
[0058]
实验对比结果表示,本发明相比原始的gcrn语音增强算法,显著提高了增强语音质量。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
