基于分支双重深度q网络的配网实时动态重构方法及系统
技术领域
1.本公开涉及配电网重构相关技术领域,具体的说,是涉及基于分支双重深度q网络的配网实时动态重构方法及系统。
背景技术:
2.本部分的陈述仅仅是提供了与本公开相关的背景技术信息,并不必然构成在先技术。
3.配电网重构(distribution network reconfiguration,dnr)是配电管理系统中的一项重要功能,其目的通常包含最小化网损,提升电能质量及供电可靠度。dnr可以分为两类:静态重构和动态重构,动态重构可以确保配电网安全、高质量和经济性的运行,与静态重构相比,其更符合配电网(distribution network,dn)实际运行调度的需求。
4.基于长短期记忆(long-short term memory,lstm)网络模型和开关动作函数的动态重构算法能够有效的解决动态配电网重构(distribution network reconfiguration,dnr)问题,但是该方法需要分为两步才能解决动态重构问题,且在执行算法时需要进行潮流计算,而部分低感知度配网的实时潮流建模往往难度较大。
技术实现要素:
5.本公开为了解决上述问题,提出了基于分支双重深度q网络的配网实时动态重构方法及系统,挖掘动态dnr决策变量和决策结果之间的时序动态变化规律,在线应用时无需进行潮流建模和分段决策,且不依赖日前的负荷和分布式电源出力预测,能够大大提高配电网的运行性能。
6.为了实现上述目的,本公开采用如下技术方案:
7.一个或多个实施例提供了基于分支双重深度q网络的配网实时动态重构方法,包括如下过程:
8.获取配电网实时节点负荷和分布式电源出力;
9.将获取的数据传输至基于马尔可夫决策过程mdp构建的动态dnr模型;所述动态dnr模型以最小化网损成本和开关动作成本为目标函数;
10.基于配电网环路分解得到分支双重深度q网络,采用q学习算法对动态dnr模型进行求解,获得使得分支双重深度q网络输出回报最大的开关动作集合,根据开关动作集合更新配电网的拓扑结构。
11.一个或多个实施例提供了基于分支双重深度q网络的配网实时动态重构系统,包括:
12.获取模块:被配置为用于获取配电网实时节点负荷和分布式电源出力;
13.马尔可夫决策构建模块:被配置为用于将获取的数据传输至基于马尔可夫决策过程mdp构建的动态dnr模型;所述动态dnr模型以最小化网损成本和开关动作成本为目标函数;
14.配电网动态重构模块:被配置为用于基于配电网环路分解得到分支双重深度q网络,采用q学习算法对动态dnr模型进行求解,获得使得分支双重深度q网络输出回报最大的开关动作集合,根据开关动作集合更新配电网的拓扑结构。
15.一种电子设备,包括存储器和处理器以及存储在存储器上并在处理器上运行的计算机指令,所述计算机指令被处理器运行时,完成上述方法所述的步骤。
16.与现有技术相比,本公开的有益效果为:
17.本公开基于配电网的环路分解,改进q学习算法网络结构,得到了分支双重深度q网络(branch double deep q network,bddqn)的深度强化学习算法以实现动态dnr模型的求解。bddqn算法可以通过迭代的方式,寻求配网马尔科夫动态重构模型的最优决策,并且执行过程不需要进行潮流计算,通过bddqn给出的动态重构解则能够产生更少的运行成本,大大提升系统运行的性能。
18.本公开附加方面的优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本公开的实践了解到。
附图说明
19.构成本公开的一部分的说明书附图用来提供对本公开的进一步理解,本公开的示意性实施例及其说明用于解释本公开,并不构成对本公开的限定。
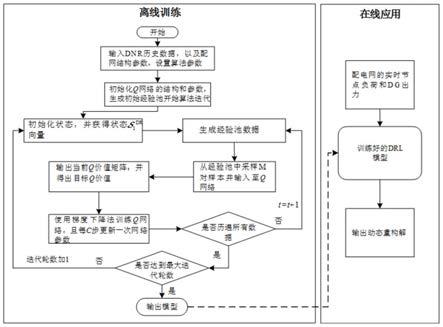
20.图1是本公开实施例1的重构方法的流程图;
21.图2是本公开实施例1的配电网马尔可夫动态重构决策框架图;
22.图3是本公开实施例1的改进前的双重深度q网络;
23.图4是本公开实施例1的基于配电网环路改进得到的分支双重深度q网络;
24.图5(a)是本公开实施例1的算例分析中ieee 33节点系统仿真测试集的节点负荷数据;
25.图5(b)是本公开实施例1的算例分析中ieee 33节点系统仿真测试集的dg出力序列数据;
26.图6是本公开实施例1的算例分析中ieee 33节点系统仿真结果对比;
27.图7(a)是本公开实施例1的ieee 33节点系统仿真中本实施例的bddqn算法与静态重构算法重构后综合运行成本比较图;
28.图7(b)是本公开实施例1的ieee 33节点系统仿真中本实施例的bddqn算法与静态重构算法产生的网损比较图;
29.图7(c)是本公开实施例1的ieee 33节点系统仿真中本实施例的bddqn算法与静态重构算法重构后最低节点电压比较图;
30.图8(a)是本公开实施例1的算例分析中185节点系统仿真测试集的节点负荷数据;
31.图8(b)是本公开实施例1的算例分析中185节点系统仿真测试集的dg出力序列数据;
32.图9(a)是本公开实施例1的185节点系统仿真中本实施例的bddqn算法与静态重构算法重构后综合运行成本比较图;
33.图9(b)是本公开实施例1的185节点系统仿真中本实施例的bddqn算法与静态重构算法产生的网损比较图;
34.图9(c)是本公开实施例1的185节点系统仿真中本实施例的bddqn算法与静态重构算法重构后开关动作次数比较图。
具体实施方式:
35.下面结合附图与实施例对本公开作进一步说明。
36.应该指出,以下详细说明都是示例性的,旨在对本公开提供进一步的说明。除非另有指明,本实施例使用的所有技术和科学术语具有与本公开所属技术领域的普通技术人员通常理解的相同含义。
37.需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本公开的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。需要说明的是,在不冲突的情况下,本公开中的各个实施例及实施例中的特征可以相互组合。下面将结合附图对实施例进行详细描述。
38.本公开首先在配网动态重构的数学模型的基础上,结合马尔可夫决策过程,建立了以最小化网损成本和开关动作成本的配网马尔可夫动态重构决策过程。然后针对配网“多环网结构、辐射状运行”的特点,对传统双重深度q网络(double deep q network,ddqn)算法进行改进,提出了一种基于环路分解的分支双重深度q网络(branch double deep q network,bddqn)的深度强化学习算法以实现动态dnr的求解。相对于传统方法,本公开所提方法可以根据bddqn算法挖掘动态dnr决策变量和决策结果之间的时序动态变化规律,在线应用时无需进行潮流建模和分段决策,且不依赖日前的负荷和分布式电源(distributed generation,dg)出力预测。算例分析表明,所提方法能够有效地提升系统运行性能以及经济性。下面以具体的实施例进行说明。
39.实施例1
40.在一个或多个实施方式公开的技术方案中,如图1所示,基于分支双重深度q网络的配网实时动态重构方法,包括如下过程:
41.步骤1、获取配电网实时节点负荷和分布式电源出力;
42.步骤2、将获取的数据传输至基于马尔可夫决策过程mdp构建的动态dnr模型;动态dnr模型以最小化网损成本和开关动作成本为目标函数;
43.步骤3、基于配电网环路分解改进q学习算法网络的结构,得到分支双重深度q网络,采用q学习算法对动态dnr模型进行求解,获得使得分支双重深度q网络输出回报最大的开关动作集合,根据开关动作集合更新配电网的拓扑结构。
44.本实施例中,基于配电网的环路分解,改进q学习算法网络结构,得到了分支双重深度q网络(branch double deep q network,bddqn)的深度强化学习算法以实现动态dnr模型的求解。bddqn算法可以通过迭代的方式,寻求配网马尔科夫动态重构模型的最优决策,并且执行过程不需要进行潮流计算,通过bddqn给出的动态重构解则能够产生更少的运行成本,大大提升系统运行的性能。
45.下面进行详细说明。
46.(1)基于马尔可夫决策过程mdp构建动态dnr模型。
47.马尔可夫决策过程mdp的原理如下:
48.mdp是一种基于马尔可夫过程理论的随机动态系统的决策过程,它主要由5个元素构成:
[0049][0050]
式中,s表示状态集合,是agent所能感知到环境的所有状态的集合。a表示动作集合,是agent所有可能动作的集合。r为回报集合,是环境根据状态和动作反馈给agent的即时回报集合,是评价动作好坏的指标。p表示状态转移概率矩阵,由环境确定,同时在mdp的过程中,状态转移概率满足马尔可夫性,即当前所处的状态与采取的动作仅对下一个时刻的状态有影响。γ∈[0,1]为衰减因子。
[0051]
在mdp中,状态s和最优动作a之间的映射关系被称为策略π:如果动作a
t
∈a是确定的,则π为一个确定策略a
t
=π(s
t
),如果动作a
t
服从一个概率分布,则π为一个随机策略π(a
t
|s
t
),mdp的最终目标是为了寻找一个最优策略以最大化累积回报g
t
:
[0052]gt
=r
t
γr
t 1
γ2r
t 2
l
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0053]
式中,r
t
表示t时刻的即时回报。
[0054]
写成数学期望的形式,即状态价值函数:
[0055]vπ
(s)=e(g
t
|s
t
=s)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0056]
其中,策略π决定了动作的分布以及对状态转移概率和即时回报产生的影响。在状态s,agent执行动作a之后产生回报的数学期望被定义为动作价值q
π
(s,a),即:
[0057]qπ
(s,a)=e(g
t
|s
t
=s,a
t
=a)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0058]
根据式(3)和(4),策略π的动作势函数可以写为:
[0059]aπ
(s,a)=q
π
(s,a)-v
π
(s)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0060]
该函数表示在状态s,系统采取动作a所带来的回报。注意此回报不同于即时回报,而是一个长期回报。理论上可以证明,在mdp中存在一个最优策略π
*
,π
*
会产生一组时间序列的动作a0,a1,a2l,a
t
,使得系统从状态s0出发得到的累积回报最大。rl算法的目的就是通过环境和智能体之间不断交互,以求寻找该最优策略π
*
。贝尔曼最优方程则为寻找该最优策略提供了理论基础:
[0061][0062][0063]
式中,表示系统在状态s时,执行动作a后,系统状态变为s'的概率。r(s,a)为系统在状态s时,执行动作a后产生的即时回报。
[0064]
基于马尔可夫决策过程mdp构建动态dnr模型,构建过程如下:
[0065]
1.1构建mdp的状态集合和动作集合。
[0066]
将节点负荷和dg出力整合为节点注入功率,将节点注入功率和断开的开关的集合作为mdp中的状态集合s
dr
,即:
[0067][0068]
式中,p
tinj
和分别表示在t时刻,配网所有节点的注入有功和无功功率。
[0069]
将动作的开关集合定义为动作集合其中,动作开关按照其在基本环路中的位置进行编码。
[0070]
1.2根据状态集合和动作集合,构建配网状态转移概率函数矩阵;
[0071]
根据上述状态集合和动作集合可以定义一个当前状态s
tdr
和下一个状态之间状态转移概率函数矩阵:
[0072][0073]
1.3本实施例中,可选的,设置配电网运行成本的倒数为mdp的即时回报,并添加惩罚项,所述惩罚项用于惩罚不符合系统安全约束的开关动作策略,即:
[0074][0075]
式中,s
tdr
表示t时刻的状态。a
tdr
表示t时刻的动作开关。λ
dr
为一个二进制变量,当动作开关满足系统约束时,λ
dr
=1,反之,λ
dr
=0。m为一个较大的正实数,当动作不满足系统安全约束时,式中的分母项将会被m修正为一个较大的数,从而让回报趋近于0。β'为一个正整数。
[0076]
通过上述变换,动态重构的决策问题可以被转换为一个mdp,配电网动态重构的最优贝尔曼方程即为构建的模型,可以表示为:
[0077][0078][0079]
其中,表示系统在状态s
tdr
时,执行动作a
tdr
后,系统状态变为的概率;为系统在状态s
tdr
时,执行动作a
tdr
后产生的即时回报。
[0080]
如图2所示,为配电网马尔可夫动态重构决策框架,训练主体(agent)通过与配电网交互来获取动作信息和状态信息,并选择能够达到预设目标的最佳开关动作。agent在做出决策后,系统会对当前动作的执行情况做出一个回报反馈,agent根据这个反馈信号的好坏进行学习,最终发现最优策略。
[0081]
(2)基于配电网环路分解,采用q学习算法对动态dnr模型进行求解。
[0082]
q学习算法是一种典型的基于值函数的强化学习算法,即在某一状态下,最大化动作后能够获得收益的期望,q学习算法以最大化q值来学习最优策略,其中q值的更新公式如下:
[0083][0084]
式中,s
t
表示t时刻的状态,a
t
表示t时刻的所执行的动作,δ∈[0,1]表示学习率,γ表示折扣因子,r
t
表示在t时刻执行动作a
t
后获得的即时回报,q(s
t 1
,a)表示执行动作a
t
后状态s
t
所产生的q估计值。
[0085]
传统q学习算法通过更新q表格来储存q值,但是在解决动态重构问题时,状态和动作的数量往往是巨大的,因此q学习算法的学习效率可能会很低。
[0086]
在配电网动态重构dnr问题中,其开关的动作状态之间是相互关联的,每条环路中各个开关协调动作以达到最优的系统运行状态。
[0087]
本实施例中采用双重深度q网络(double deep q network,ddqn)的算法,该算法使用两个结构相同的q网络,一个为当前q网络q
predict
用来选择动作并更新模型参数,另一个为目标q网络q
target
用于计算目标q值。通过解耦目标q值动作的选择和目标q值的计算这两步,来消除过估计问题。
[0088]
双重深度q网络如图3所示,经验池是用来储存算法迭代过程中,agent与环境进行交互所产生的状态特征,动作向量和即时回报。
[0089]
本实施例基于配电网环路分解,采用q学习算法对动态dnr模型进行求解,首先基于配电网环路分解改进了q学习算法网络的结构,基于改进的网络进行求解,具体的包括以下步骤:
[0090]
2.1以配电网中的环路数作为q学习算法网络的输出维度,每一维度输出向量的维度为所属环路的开关数量,改进q学习算法网络的结构,得到分支双重深度q网络;
[0091]
可选的,本实施例中,将一维输出的q网络改进为具有多维输出的q网络,其输出维度等于dnr问题中的基本环路数。q网络的每一维输出为一个向量,每个向量的维度由环路中可能动作的开关数量所决定。如图4所示,为基于配电网环路数改进后的q网络的结构,即为分支双重深度q网络。
[0092]
假设某一配网有l条环路,即为l条支路,环路中最多的开关动作数为d,则q网络输出一个l
×
d的状态价值矩阵。该状态价值矩阵和开关动作矩阵(flm)是同维度的,中的每个数值为flm中对应位置开关动作所产生的价值。若flm中元素为0,则相应地将中同位置的元素设为0即可。
[0093]
其中,flm是指在辐射状配电网中按照一个联络开关与若干分段开关为一个基本环路组成的基本环路矩阵,其中,flm的每一行为一个环路中包含的所有联络开关与分段开关。
[0094]
2.2基于改进的分支双重深度q网络求解,获得使得q学习算法网络每一维输出回报最大的开关动作集合
[0095]
根据和贪婪选择策略以选择每个维度中回报最大的开关,作为决策动作开关,根据ε贪婪选择法选择动作,价值函数为:
[0096][0097]
式中,为状态价值矩阵中每一行值最大的动作所组成一组开关动作策略。
[0098]
价值函数可以从状态价值矩阵的每一行中选择一个产生价值最大的动作,以构成一个完整的重构策略。
[0099]
改进后的q学习算法网络,即分支双重深度q网络,将原始的一维复杂决策问题分解为多维度的简单决策。
[0100]
进一步地,还包括对分支双重深度q网络训练的步骤,训练过程与使用过程可以是分离的,包括如下:
[0101]
步骤3.1、获取配电网的历史运行数据,以及配电网的网络结构参数,构建训练集;
[0102]
其中,历史运行数据包括配电网的历史节点负荷和分布式电源的出力;
[0103]
步骤3.2、初始化分支双重深度q网络的结构和参数,生成初始经验池,开始算法迭代;
[0104]
步骤3.3、初始化状态向量,从经验池中采集样本并输入至分支双重深度q网络;
[0105]
步骤3.4、根据采集样本中开关动作集合计算分支双重深度q网络的输出以及损失函数,并更新经验池;
[0106]
在选出每一维中回报最大的动作开关后,将动作输入至以计算的输出,然后再加上当前动作的回报r
t
,便可得到目标q
*
值,即:
[0107][0108]
式中,z为一个一维行向量,其列数等于环路数,其包含的元素全为1。
[0109]
此时,和不再只是一个数值,而是一个一维向量,因此为了计算平均损失,改进损失函数为:
[0110][0111]
步骤3.5、利用梯度下降法优化分支双重深度q网络的参数,进行下一轮迭代,直到遍历训练集的数据。
[0112]
本实施例中,经验池的初始数据可以直接采用配电网的历史数据集代替,即dnr数据集,可以加快算法的收敛速度。
[0113]
步骤3.4中,更新经验池,在每轮迭代过程中,假设遍历到t时刻,更新分支双重深度q网络(bddqn)经验池的步骤如下:
[0114]
步骤一:在分支双重深度q网络中使用当前时刻的状态s
tdr
作为输入,采用ε贪婪选择法选择对应的开关动作a
tdr
:
[0115][0116]
其中,β为q
predict
的参数。为一个随机数。ε∈[0,1]为贪婪选择的概率。该动作选择方法以ε的概率选择q值最大的策略作为最优动作。或者以1-ε的概率随机选择一个动作,以实现策略搜索的多样性。
[0117]
步骤二:在当前状态s
tdr
执行动作对应a
tdr
后,进行潮流计算,并计算得出即时回报r
tdr
,并从配电网的节点负荷和dg出力数据集中索引得出下一时刻的状态
[0118]
步骤三:将获得的这5个元组存入经验池,判断经验池容量是否已达上限,若是,则删除经验池中的第一个旧数据,即按照经验池数据存储的时间删除最早的数据。
[0119]
算例分析
[0120]
为了验证所提算法的有效性,本节分别在ieee 33节点系统和185节点系统上进行了仿真验证。
[0121]
由于drl方法对动态dnr问题的求解是在决策主体与环境的交互过程中完成的。因此在仿真过程中,使用matlab通过潮流计算来模拟训练环境,用python对算法主体进行训练,交互过程可以通过两者之间的接口来实现。测试设备的cpu为“4核i5-8250u-1.6ghz”,gpu为“nvidia geforce gtx 1060”。此外,本实施例所提drl算法的超参数设置为:折扣因子0.99,学习率0.001,经验池容量50000,训练轮数9000,批处理数128,贪婪选择概率0.8。其中配电网的历史数据以及参数按照以下原则设置:负荷数据来自文献“real-time power system state estimation and forecasting via deepunrolled neural networks”,dg出力数据来自“2014global energy forecasting competition”借助二阶锥规划和启发式算法的dnr方法,通过模拟系统运行的方式获取dnr数据集,以小时为单位取8760组连续的负荷和dg数据生成训练集,取4000组连续的负荷和dg数据生成测试集。
[0122]
ieee 33节点系统
[0123]
为了分析模型学习的学习效果,在算法的训练过程中,每训练30轮记录一次策略神经网络的权重,并用于评估在测试集上算法的决策收敛性能。其中测试集为如图5所示的100组实时连续节点负荷和dg出力序列,以测试集中的系统运行成本为评价标准,并与传统ddqn算法进行了对比,结果如图6所示。
[0124]
从图6中可以看出,bddqn和ddqn分别在迭代至110轮和200轮左右开始收敛。由于本实施例将q网络的输出设置为多维的形式,简化了决策过程中重构解的表示方式,能够提升传统ddqn最优决策的搜寻效率,因此在图6中,bddqn能够以更快的速度收敛至最优决策。在迭代至收敛时,bddqn和ddqn的综合运行成本分别为1.2076
×
103usd和1.2155
×
103usd。根据如表1中统计的所有可能动作开关可以得出,如果按照ddqn一维输出的方式对策略进行编码,待选的策略为1200个,而按照bddqn的多维方式编码,待选的策略被分解为5个、2个、6个、4个和5个,每一维均被转换为简单的策略组合。因此,两种算法的策略搜索空间存在显著差异,且ddqn难以搜索到最优的动态重构策略,所以图中bddqn算法最终能够将运行成本降至更低的水平。
[0125]
表1重构结果统计
[0126][0127]
为了进一步验证本实施例所提方法的效果,在图5的负荷条件下,对各时段的静态重构和bddqn决策出的重构方案所产生的网损、最低节点电压和综合运行成本进行了对比。
[0128]
首先从图7(a)中可以看出,由于静态重构通过频繁地动作开关以最小化网络损耗,其开关动作所带来的损耗会导致成本曲线出现大幅度的波动,而bddqn在考虑了开关动作成本的情况下,给出的动态重构策略会以运行成本最小为目标,且在图5的负荷条件下,bddqn给出的重构策略为支路s33,s14,s9,s36,和s27断开,所以在此100个重构时段内开关动作成本为0,因此bddqn和未重构的成本曲线变化趋势一致,未出现大幅度波动的情况。图7(a)中动态、静态和未重构的运行成本之和分别为1.2076
×
103usd,1.6377
×
103usd和1.7737
×
103usd,从总运行成本可以看出,静态重构虽然频繁动作开关,但是成本依旧低于初始未重构的成本,而通过bddqn给出的动态重构解则可以较大幅度地降低运行成本。
[0129]
通过观察图7(b)可以看出,静态重构后的系统网损均小于动态重构,但两条网损曲线的差距不大,其中静态和动态重构的网损之和分别为7.3858
×
103kw和7.5494
×
103kw,仅相差163.6kw。所以在考虑了开关动作成本以后,动态重构的运行成本要比静态重构少26.38%。
[0130]
通过图7(c)可以看出,动态重构后的最低节点电压均大于0.95p.u.,满足系统运行约束。此外由于本实施例未将降低电压偏差设为目标函数,所以部分时段动态重构后的最低节点电压会高于静态重构。
[0131]
为对比基于lstm模型和开关动作函数的动态重构方法以及本实施例提出的基于bddqn模型的动态重构算法的重构优化效果,本实施例取图5中的前24个时段作为动态重构优化周期,对四种不同算法进行了对比,结果如表2所示。
[0132]
表2
[0133][0134]
从表2中可以看出,在该优化周期内静态重构虽然总网损量最低,但是由于其频繁地动作开关,因此其运行成本最高,甚至高于原始未重构的状态。,在所有的动态重构策略中,misocp算法的降损率是最低的,但是该算法给出重构策略的开关动作次数为4次,所以其综合运行成本要略高于bddqn。而在成本降低比率上,bddqn所给出的重构方案是最高的,这是由于bddqn的重构方案仅为支路[s33,s14,s9,s36,s27]断开,该重构方案能够保证整
个优化周期内总网损量在一个较低的水平,且开关动作次数最少。因此,可以看出,本实施例所提的基于bddqn的配网动态重构方法能够有效降低ieee 33节点系统的综合运行成本,且要优于现有算法。
[0135]
185节点系统
[0136]
在185实际节点系统上对所提算法进行了验证。首先在图8的负荷条件下进行测试。
[0137]
将各时段的静态重构和bddqn决策出的最重构方案所产生的综合运行成本、网损和开关动作次数进行了对比,如图9所示。
[0138]
首先从图9(a)中可以看出,在此大型系统上,由于静态重构会较为频繁地动作开关,所以其开关动作所带来的损耗同样会导致成本曲线出现大幅度的波动,甚至会出现大于未重构时的成本。同时还可以发现,在12,14-16,60,61,82,83等少部分时段会出现动态重构的成本大于静态重构的情况。这是因为,在动态重构的过程中为了减少优化周期内的开关动作次数,有部分时段的动态重构策略无法保证网损最小,若在这些时段内静态重构的开关动作成本损耗小于降损所带来的收益,则静态重构的运行成本会小于动态重构。图(a)中动态、静态和未重构的运行成本之和分别为1.6772
×
103usd,1.7841
×
103usd和2.1663
×
103usd,从总运行成本可以看出,静态重构虽然频繁动作开关但仍能够较大幅度地降低运行成本,但是这会影响开关的使用寿命。而通过bddqn给出的动态重构解则能够产生更少的运行成本,以提升系统运行的经济性。
[0139]
然后通过观察图9(b)可以看出,虽然静态重构后的系统网损均小于动态重构,但两条网损曲线的差距不大,其中静态和动态重构的网损之和分别为1.0083
×
104kw和9.7145
×
103kw,仅相差368.5kw。此外由于该系统较为复杂,有20条环路,所以在图7(b)中,静态和动态重构的开关动作次数分别为120和32次。在考虑了开关动作成本以后,动态重构的运行成本要比静态重构少5.99%。虽然在此复杂系统上,bddqn算法的成本降低比率要小于在ieee 33节点系统上的比率,但是动态重构后开关的动作次数和动作频率明显要小于静态重构,因此可以得出bddqn决策出的动态重构策略可有效地延长开关使用寿命,并降低系统运行成本。
[0140]
为进一步验证本实施例所提算法的优越性,取图8中的前24个时段作为一个动态重构优化周期,对三种不同算法进行了对比,结果如表3所示。
[0141]
表3动态重构效果对比
[0142][0143]
从表3中可以看出,在该复杂系统的优化周期内,静态重构同样总网损量最低,由于该系统初始状态的网损量过高,所以静态重构虽频繁地动作开关,但没有出现表2中的运行成本高于原始未重构成本的情况。此外,还可以看出在成本降低比率上,bddqn所给出的重构方案同样是最高的。但是由于该决策方案的开关动作次数为8次,所以在成本降低比率
的增加幅度上,要小于该算法在ieee 33节点系统上的决策方案。
[0144]
最后,为了验证本实施例所提方法在计算速度上的优越性,对几种不同算法的动态重构决策时间进行了测试,由于本实施例所提的两种算法均以离线的方式进行训练,因此表中只统计其决策时间。结果如表4所示。
[0145]
表4不同动态重构方法的计算效率对比
[0146][0147][0148]
isocp算法的结果为三种不同动态重构时段数t=1、t=5和t=24下的计算时间。首先可以看出,本实施例所提两种基于数据驱动的动态重构方法的决策时间最短,且当配网规模增大时,基于数据驱动的算法的优势变得更加明显。其中基于lstm模型决策的动态重构方法需要执行两次潮流计算,所以它的计算效率会略低于bddqn。
[0149]
此外可以看出,misocp的计算时间会随着重构时段数的增加呈指数型增长。当t=1时,相当于单时段静态重构。当t=5时,33节点系统的计算时间相对于t=1增加了96.67倍。而在185节点系统的t=5时,计算时间则增加了591.71倍。这是由于misocp的约束维度会随着动态重构时段的增加而增加,当约束维度过高时商用求解器将无法有效地获取最优解。且当t=24时,33和185节点系统的约束维度分别为11160和61440,所以misocp算法在33节点系统上需要3.37个小时才能获得最优解,而在185节点系统上将无法在可接受的时间内获得最优解。
[0150]
因此,综上可得,基于数据驱动的动态重构方法在计算效率上要明显优于传统方法,正是由于这一优势,使得该类方法在获得配网实时运行状态之后,可以迅速地做出重构决策,从而降低对负荷和dg出力高预测精度的依赖。
[0151]
通过对两个不同规模的配网进行仿真,算例结果表明,本实施例所提bddqn算法能够有效学习动态重构策略,且能够根据系统实时运行状态,在毫秒级的时间内给出当前重构时段的理想动态重构方案。相对与传统日前动态重构方法,本实施例所提方法在成本降低比率上有着显著的提升,且直接利用系统实时状态进行决策,不依赖负荷和dg出力的日前预测,对负荷和dg出力的预测精度要求不高。
[0152]
实施例2
[0153]
基于实施例1,本实施例提供基于分支双重深度q网络的配网实时动态重构系统,包括:
[0154]
获取模块:被配置为用于获取配电网实时节点负荷和分布式电源出力;
[0155]
马尔可夫决策构建模块:被配置为用于将获取的数据传输至基于马尔可夫决策过程mdp构建动态dnr模型;动态dnr模型以最小化网损成本和开关动作成本为目标函数;
[0156]
配电网动态重构模块:被配置为用于基于配电网环路分解得到分支双重深度q网络,采用q学习算法对动态dnr模型进行求解,获得使得分支双重深度q网络输出回报最大的
开关动作集合,根据开关动作集合更新配电网的拓扑结构。
[0157]
实施例3
[0158]
本实施例一种电子设备,包括存储器和处理器以及存储在存储器上并在处理器上运行的计算机指令,所述计算机指令被处理器运行时,完成上述方法所述的步骤。
[0159]
以上所述仅为本公开的优选实施例而已,并不用于限制本公开,对于本领域的技术人员来说,本公开可以有各种更改和变化。凡在本公开的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本公开的保护范围之内。
[0160]
上述虽然结合附图对本公开的具体实施方式进行了描述,但并非对本公开保护范围的限制,所属领域技术人员应该明白,在本公开的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本公开的保护范围以内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
