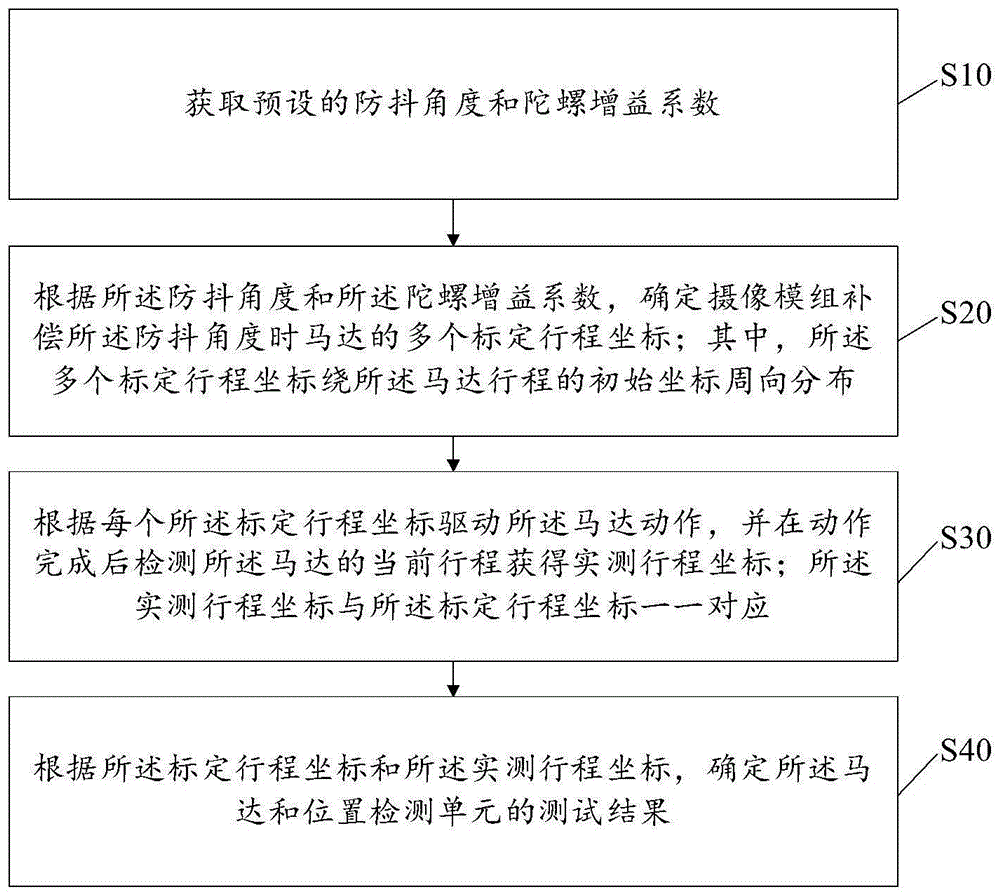
本申请实施例涉及基于人工智能(artificial intelligence,AI)的视频或图像压缩技术领域,尤其涉及一种帧间预测方法及装置。
背景技术
视频编码(视频编码和解码)广泛用于数字视频应用,例如广播数字电视、互联网和移动网络上的视频传输、视频聊天和视频会议等实时会话应用、数字多功能影音光盘(Digital Versatile Disc,DVD)和蓝光光盘、视频内容采集和编辑系统以及可携式摄像机的安全应用。
即使在影片较短的情况下也需要对大量的视频数据进行描述,当数据要在带宽容量受限的网络中发送或以其它方式传输时,这样可能会造成困难。因此,视频数据通常要先压缩然后在现代电信网络中传输。由于内存资源可能有限,当在存储设备上存储视频时,视频的大小也可能成为问题。视频压缩设备通常在信源侧使用软件和/或硬件,以在传输或存储之前对视频数据进行编码,从而减少用来表示数字视频图像所需的数据量。然后,压缩的数据在目的地侧由视频解压缩设备接收。在有限的网络资源以及对更高视频质量的需求不断增长的情况下,需要改进压缩和解压缩技术,这些改进的技术能够提高压缩率而几乎不影响图像质量。
视频编码中的预测可以分为帧内预测和帧间预测。帧间预测是在已重建的图像中,为当前图像中的当前块寻找匹配的参考块,将参考块中的像素点的值作为当前块中的像素点的值的预测值。编码器在参考图像中为当前块尝试多个参考块,然后决策出适合当前块的参考块,并传输运动信息到解码器。解码器通过码流中的运动信息,即可找到对应图像块的参考块,进而得到该图像块的预测。运动信息包括了一个或两个指向参考块的运动矢量(motion vector,MV),以及参考块所在图像的指示信息(通常记为参考帧索引(reference index,RI))。在高效率视频编码(high efficiency video coding,HEVC)标准中,定义了两种帧间预测模式,分别为先进的运动矢量预测(advanced motion vector prediction,AMVP)模式和融合(Merge)模式。这两种模式均为先通过当前块的空域或时域相邻的已重建图像块的运动信息构建候选运动信息列表,然后从候选运动信息列表中确定最优运动信息作为当前块的运动信息,进而基于当前块的运动信息获取当前块的预测。
因此如何根据多个候选运动信息获取当前块的预测是实现帧间预测的关键。
技术实现要素:
本申请提供一种帧间预测方法及装置,以提升帧间预测的准确度,减小帧间预测的误差,改善帧间预测的RDO效率。
第一方面,本申请提供一种帧间预测方法,包括:获取当前块的周边区域中的P个已重建图像块各自的运动矢量,所述周边区域包括所述当前块的空间邻域和/或时间邻域;根据所述P个已重建图像块各自的运动矢量得到所述当前块的Q个先验候选运动矢量以及与所述Q个先验候选运动矢量对应的Q个概率值;根据与M个先验候选运动矢量对应的M个概率值,得到与所述M个先验候选运动矢量对应的M个权重因子;M、P和Q为正整数;根据所述M个先验候选运动矢量分别执行运动补偿得到M个预测值;根据所述M个预测值和对应的所述M个权重因子加权求和得到所述当前块的预测值。
当前块的周边区域包括当前块的空间邻域和/或时间邻域,其中空间邻域的图像块可以包括位于当前块左侧的左方候选图像块和位于当前块上方的上方候选图像块。
已重建图像块可以是指编码端已经编码并获取其重建的编码图像块或者解码端已解码重构的解码图像块。已重建图像块也可以是指将编码图像块或解码图像块等大小划分而来的预设大小的基本单元图像块。
已重建图像块的运动矢量可以包括:(1)已重建图像块的多个后验运动矢量,该多个后验运动矢量是根据已重建图像块的重建值和多个后验候选运动矢量对应的预测值确定的;或者,(2)已重建图像块的最优运动矢量,该最优运动矢量是上述多个后验运动矢量中概率值最大或预测误差值最小的后验运动矢量。
已重建图像块的多个后验候选运动矢量是根据该已重建图像块的多个先验候选运动矢量得到的。针对已重建图像块的多个先验候选运动矢量中的任意一个先验候选运动矢量,可以让其在一个预设的搜索窗口内进行偏移,生成多个偏移候选运动矢量。可见,已重建图像块的一个先验候选运动矢量可以得到多个偏移候选运动矢量。已重建图像块的多个先验候选运动矢量,均按上述操作,得到的所有偏移候选运动矢量即为已重建图想块的多个后验候选运动矢量。上述P个已重建图像块均可按照该方法获取各自的多个后验候选运动矢量,此处不再逐一描述。
已重建图像块的多个后验运动矢量可以是指上述多个后验候选运动矢量;也可以是指上述多个后验候选运动矢量中的部分运动矢量,例如上述多个后验候选运动矢量中选出的多个指定的运动矢量。上述P个已重建图像块均可按照该方法获取各自的多个后验运动矢量,此处不再逐一描述。
可以将P个已重建图像块各自的运动矢量输入经训练的神经网络得到当前块的Q个先验候选运动矢量以及与Q个先验候选运动矢量对应的Q个概率值。该神经网络可以参照下文训练引擎25的描述,此处不再赘述。
当前块的Q个先验候选运动矢量可以是指P个已重建图像块各自的多个后验运动矢量去重后剩余的所有运动矢量,也可以是指P个已重建图像块各自的多个后验运动矢量去重后剩余的所有运动矢量中的部分运动矢量。
可选的,M=Q,此时M个概率值是指上述Q个概率值,M个先验候选运动矢量是指上述Q个先验候选运动矢量。
可选的,M<Q,此时M个概率值均大于Q个概率值中除M个概率值外的其他概率值,从当前块的Q个先验候选运动矢量中选取与该M个概率值对应的M个先验候选运动矢量。即从当前块的与Q个先验候选运动矢量对应的Q个概率值中选取概率值最大的前M个概率值,并从当前块的Q个先验候选运动矢量中选取与M个概率值对应的M个先验候选运动矢量,基于M个概率值和M个先验候选运动矢量进行权重因子和预测值的计算,进而得到当前块的预测值。而与多个先验候选运动矢量对应的多个概率值中除前述M个概率值外的其余概率值,由于值较小可以忽略,这样可以减少计算量,提高帧间预测的效率。
需要说明的是,与M个先验候选运动矢量对应的M个概率值中的“对应的”不是指一一对应,例如,当前块有5个先验候选运动矢量,与其对应的多个概率值可以是5个概率值,也可以是少于5个概率值。
当M个概率值之和为1时,将与第一先验候选运动矢量对应的概率值作为与第一先验候选运动矢量对应的权重因子。即M个先验候选运动矢量各自的权重因子,是M个先验候选运动矢量各自的概率值;或者,当M个概率值之和不为1时,对M个概率值进行归一化处理;将与第一先验候选运动矢量对应的概率值的归一化值作为与第一先验候选运动矢量对应的权重因子。即M个先验候选运动矢量各自的权重因子,是M个先验候选运动矢量各自的概率值的归一化值。上述第一先验候选运动矢量只是为了便于描述而采用的一个名词,其并非指特定的先验候选运动矢量,代表是Q个先验候选运动矢量中的任意一个。可见,与M个先验候选运动矢量对应的M个权重因子之和为1。
根据帧间预测的原理,一个候选运动矢量可以在当前块的参考帧中找到一个参考块,根据该参考块对当前块进行帧间预测得到对应于该候选运动矢量的预测值,可见当前块的预测值对应于候选运动矢量。因此根据M个先验候选运动矢量分别执行运动补偿,可以得到当前块的M个预测值。
根据M个预测值和对应的M个权重因子加权求和得到当前块的预测值。如上所述,M个预测值和M个先验候选运动矢量对应,M个权重因子也和M个先验候选运动矢量对应,因此针对同一个先验候选运动矢量,其对应的预测值和权重因子之间也建立起对应关系,将对应于同一个先验候选运动矢量的权重因子和预测值相乘,再将对应于多个先验候选运动矢量的多个乘积相加得到当前块的预测值。
本申请通过基于当前块的周边区域中的多个已重建图像块各自的运动矢量得到当前块的多个权重因子和多个预测值,将对应于同一个先验候选运动矢量的权重因子和预测值相乘,再将对应于多个先验候选运动矢量的多个乘积相加得到当前块的预测值,这样得到的当前块的预测值是结合了多个先验候选运动矢量,从而能够更好的拟合现实世界中丰富多变的纹理,提升帧间预测的准确度,减小帧间预测的误差,改善帧间预测的整体率失真(rate-distortion optimization,RDO)效率。
在一种可能的实现方式中,除了获取P个已重建图像块各自的运动矢量外,还可以获取该P个已重建图像块各自的相关信息。已重建图像块的相关信息可以是该已重建图像块的与多个后验运动矢量对应的多个预测误差值,该多个预测误差值也是根据已重建图像块的重建值和多个后验候选运动矢量对应的预测值确定的。
根据已重建图像块的多个后验候选运动矢量分别对已重建图像块执行运动补偿,可以得到多个预测值,该多个预测值和前述多个后验候选运动矢量对应。
将多个预测值分别与已重建图像块的重建值进行比较,得到多个预测误差值,该多个预测误差值和多个后验候选运动矢量对应。本申请可以采用绝对误差和(sum of absolute difference,SAD)或平方误差和(sum of squared difference,SSE)等方法获取对应于某一个后验候选运动矢量的预测误差值。
若已重建图像块的多个后验运动矢量是指上述多个后验候选运动矢量,则已重建图像块的与上述多个后验运动矢量对应的多个预测误差值是指对应于上述多个后验候选运动矢量的多个预测误差值;若已重建图像块的多个后验运动矢量是指上述多个后验候选运动矢量中的部分运动矢量,则已重建图像块的与上述多个后验运动矢量对应的多个预测误差值是指从对应于上述多个后验候选运动矢量的多个预测误差值中选出的与该部分运动矢量对应的预测误差值。
相应的,输入神经网络的包括P个已重建图像块各自的多个后验运动矢量以及与多个后验运动矢量对应的多个预测误差值。
在一种可能的实现方式中,除了获取P个已重建图像块各自的运动矢量外,还可以获取该P个已重建图像块各自的相关信息。已重建图像块的相关信息可以是该已重建图像块的与多个后验运动矢量对应的多个概率值,该多个概率值也是根据已重建图像块的重建值和多个后验候选运动矢量对应的预测值确定的。
已重建图像块的与多个后验运动矢量对应的多个概率值可以有以下两种获取方法:
一种是根据上述方法中得到的已重建图像块的多个预测误差值,得到已重建图像块的多个概率值。例如,可以使用归一化指数函数、线性归一化方法等方法对已重建图像块的多个预测误差值进行归一化处理,得到多个预测误差值的归一化值,该多个预测误差值的归一化值即为已重建图像块的多个概率值,基于已重建图像块的多个预测误差值与多个后验运动矢量的对应关系,已重建图像块的多个概率值也与已重建图像块的多个后验运动矢量对应,该概率值可以表示与之对应的后验运动矢量成为该已重建图像块的最优运动矢量的概率。
另一种是将已重建图像块的重建值和第一种方法中得到的已重建图像块的多个预测值,输入经训练的神经网络得到已重建图像块的与多个后验运动矢量对应的多个概率值。该神经网络可以参照上述训练引擎25的描述,此处不再赘述。
相应的,输入神经网络的包括P个已重建图像块各自的多个后验运动矢量以及与多个后验运动矢量对应的多个概率值。
因此,在通过上述两种方法得到的与多个后验运动矢量对应的多个预测误差值或者概率值之后,已重建图像块的最优运动矢量可以有以下两种获取方法:
一种是将与多个后验运动矢量对应的多个预测误差值中的最小预测误差值对应的后验运动矢量作为已重建图像块的最优运动矢量。
另一种是将与多个后验运动矢量对应的多个概率值中的最大概率值对应的后验运动矢量作为已重建图像块的最优运动矢量。
需要说明的时,本申请中的最优运动矢量仅是指通过上述两种方法之一获取到的运动矢量,是已重建图像块的多个后验运动矢量的其中之一,但该最优运动矢量并不是对已重建图像块进行帧间预测时采用的唯一的运动矢量。
在一种可能的实现方式中,在获取当前块的重建值后,可以立即获取当前块的后验运动矢量及其相关信息,该获取方法包括:
一、根据当前块的重建值和当前块的多个后验候选运动矢量对应的预测值得到当前块的多个后验运动矢量以及与多个后验运动矢量对应的多个预测误差值,当前块的多个后验运动矢量是根据当前块的多个先验候选运动矢量得到的。
二、根据当前块的重建值和当前块的多个后验候选运动矢量对应的预测值输入神经网络,得到当前块的多个后验运动矢量以及与多个后验运动矢量对应的多个概率值,当前块的多个后验运动矢量是根据当前块的多个先验候选运动矢量得到的,或者,根据当前块的多个预测误差值得到当前块的多个后验运动矢量对应的多个概率值。
三、将当前块的多个后验运动矢量中概率值最大或预测误差值最小的后验运动矢量确定为当前块的最优运动矢量。
在一种可能的实现方式中,训练引擎在训练神经网络时所依据的训练数据集合包括多组图像块的信息,其中每组图像块的信息包括多个已重建图像块各自的多个后验运动矢量、与所述多个后验运动矢量对应的多个概率值,以及当前块的多个后验运动矢量、与所述多个后验运动矢量对应的多个概率值,所述多个已重建图像块是所述当前块的空间邻域和/或时间邻域中的图像块;根据所述训练数据集合训练得到神经网络。
在一种可能的实现方式中,训练引擎在训练神经网络时所依据的训练数据集合包括多组图像块的信息,其中每组图像块的信息包括多个已重建图像块各自的多个后验运动矢量、与所述多个后验运动矢量对应的多个预测误差值,以及当前块的多个后验运动矢量、与所述多个后验运动矢量对应的多个概率值,所述多个已重建图像块是所述当前块的空间邻域和/或时间邻域中的图像块;根据所述训练数据集合训练得到神经网络。
在一种可能的实现方式中,训练引擎在训练神经网络时所依据的训练数据集合包括多组图像块的信息,其中每组图像块的信息包括多个已重建图像块各自的最优运动矢量,以及当前块的多个后验运动矢量、与所述多个后验运动矢量对应的多个概率值,所述多个已重建图像块是所述当前块的空间邻域和/或时间邻域中的图像块;根据所述训练数据集合训练得到神经网络。
可选的,所述神经网络至少包括卷积层和激活层。其中,所述卷积层的卷积核的深度为2、3、4、5、6、16、24、32、48、64或者128;所述卷积层中的卷积核的尺寸为1×1、3×3、5×5或者7×7。例如,某一卷积层的尺寸为3×3×2×10,其中,3×3表示该卷积层中的卷积核的尺寸;2表示卷积层中包含的卷积核的深度,输入该卷积层的数据通道数和卷积层中包含的卷积核的深度一致,即输入该卷积层的数据通道数也是2;10表示卷积层中包含的卷积核的个数,输出该卷积层的数据通道数和卷积层中包含的卷积核的个数一致,即输出该卷积层的数据通道数也是10。
可选的,所述神经网络包括卷积神经网络CNN、深度神经网络DNN或者循环神经网络RNN。
第二方面,本申请提供一种编码器,包括处理电路,用于执行根据上述第一方面任一项所述的方法。
第三方面,本申请提供一种解码器,包括处理电路,用于执行上述第一方面任一项所述的方法。
第四方面,本申请提供一种计算机程序产品,包括程序代码,当其在计算机或处理器上执行时,用于执行上述第一方面任一项所述的方法。
第五方面,本申请提供一种编码器,包括:一个或多个处理器;非瞬时性计算机可读存储介质,耦合到所述处理器并存储由所述处理器执行的程序,其中所述程序在由所述处理器执行时,使得所述解码器执行上述第一方面任一项所述的方法。
第六方面,本申请提供一种解码器,包括:一个或多个处理器;非瞬时性计算机可读存储介质,耦合到所述处理器并存储由所述处理器执行的程序,其中所述程序在由所述处理器执行时,使得所述编码器执行上述第一方面任一项所述的方法。
第七方面,本申请提供一种非瞬时性计算机可读存储介质,包括程序代码,当其由计算机设备执行时,用于执行上述第一方面任一项所述的方法。
第八方面,本发明涉及帧间预测装置,有益效果可以参见第一方面的描述此处不再赘述。所述帧间预测装置具有实现上述第一方面的方法实施例中行为的功能。所述功能可以通过硬件实现,也可以通过硬件执行相应的软件实现。所述硬件或软件包括一个或多个与上述功能相对应的模块。在一个可能的设计中,所述帧间预测装置包括:运动估计单元和帧间预测处理单元,其中,运动估计单元,用于获取当前块的周边区域中的P个已重建图像块各自的运动矢量,所述周边区域包括所述当前块的空间邻域和/或时间邻域;帧间预测处理单元,用于实现上述第一方面任一项所述的方法。这些模块可以执行上述第一方面方法示例中的相应功能,具体参见方法示例中的详细描述,此处不做赘述。
附图及以下说明中将详细描述一个或多个实施例。其它特征、目的和优点在说明、附图以及权利要求中是显而易见的。
附图说明
图1a为本申请实施例的译码系统10的示例性框图;
图1b为本申请实施例的视频译码系统40的示例性框图;
图2为本申请实施例的视频编码器20的示例性框图;
图3为本申请实施例的视频解码器30的示例性框图;
图4为本申请实施例的视频译码设备400的示例性框图;
图5为本申请实施例的装置500的示例性框图;
图6a-图6e为本申请实施例的用于帧间预测的神经网络的几个示例性架构;
图7为本申请实施例的候选图像块的示例性的示意图;
图8为本申请实施例的帧间预测方法的过程800的流程图;
图9为本申请实施例的帧间预测方法的过程900的流程图;
图10为本申请实施例的搜索窗口的示例性的示意图;
图11为本申请实施例的帧间预测方法的过程1100的流程图;
图12为本申请实施例的帧间预测方法的过程1200的流程图;
图13为本申请实施例的帧间预测装置1300的结构示意图。
具体实施方式
本申请实施例提供一种基于AI的视频压缩技术,尤其是提供一种基于神经网络的视频压缩技术,具体提供一种基于神经网络(neural network,NN)的帧间预测技术,以改进传统的混合视频编解码系统。
视频编码通常是指处理形成视频或视频序列的图像序列。在视频编码领域,术语“图像(picture)”、“帧(frame)”或“图片(image)”可以用作同义词。视频编码(或通常称为编码)包括视频编码和视频解码两部分。视频编码在源侧执行,通常包括处理(例如,压缩)原始视频图像以减少表示该视频图像所需的数据量(从而更高效存储和/或传输)。视频解码在目的地侧执行,通常包括相对于编码器作逆处理,以重建视频图像。实施例涉及的视频图像(或通常称为图像)的“编码”应理解为视频图像或视频序列的“编码”或“解码”。编码部分和解码部分也合称为编解码(编码和解码,CODEC)。
在无损视频编码情况下,可以重建原始视频图像,即重建的视频图像与原始视频图像具有相同的质量(假设存储或传输期间没有传输损耗或其它数据丢失)。在有损视频编码情况下,通过量化等执行进一步压缩,来减少表示视频图像所需的数据量,而解码器侧无法完全重建视频图像,即重建的视频图像的质量比原始视频图像的质量较低或较差。
几个视频编码标准属于“有损混合型视频编解码”(即,将像素域中的空间和时间预测与变换域中用于应用量化的2D变换编码结合)。视频序列中的每个图像通常分割成不重叠的块集合,通常在块级上进行编码。换句话说,编码器通常在块(视频块)级处理即编码视频,例如,通过空间(帧内)预测和时间(帧间)预测来产生预测块;从当前块(当前处理/待处理的块)中减去预测块,得到残差块;在变换域中变换残差块并量化残差块,以减少待传输(压缩)的数据量,而解码器侧将相对于编码器的逆处理部分应用于编码或压缩的块,以重建用于表示的当前块。另外,编码器需要重复解码器的处理步骤,使得编码器和解码器生成相同的预测(例如,帧内预测和帧间预测)和/或重建像素,用于处理,即编码后续块。
在以下译码系统10的实施例中,编码器20和解码器30根据图1a至图3进行描述。
图1a为本申请实施例的译码系统10的示例性框图,例如可以利用本申请技术的视频译码系统10(或简称为译码系统10)。视频译码系统10中的视频编码器20(或简称为编码器20)和视频解码器30(或简称为解码器30)代表可用于根据本申请中描述的各种示例执行各技术的设备等。
如图1a所示,译码系统10包括源设备12,源设备12用于将编码图像等编码图像数据21提供给用于对编码图像数据21进行解码的目的设备14。
源设备12包括编码器20,另外即可选地,可包括图像源16、图像预处理器等预处理器(或预处理单元)18、通信接口(或通信单元)22。
图像源16可包括或可以为任意类型的用于捕获现实世界图像等的图像捕获设备,和/或任意类型的图像生成设备,例如用于生成计算机动画图像的计算机图形处理器或任意类型的用于获取和/或提供现实世界图像、计算机生成图像(例如,屏幕内容、虚拟现实(virtual reality,VR)图像和/或其任意组合(例如增强现实(augmented reality,AR)图像)的设备。所述图像源可以为存储上述图像中的任意图像的任意类型的内存或存储器。
为了区分预处理器(或预处理单元)18执行的处理,图像(或图像数据)17也可称为原始图像(或原始图像数据)17。
预处理器18用于接收原始图像数据17,并对原始图像数据17进行预处理,得到预处理图像(或预处理图像数据)19。例如,预处理器18执行的预处理可包括修剪、颜色格式转换(例如从RGB转换为YCbCr)、调色或去噪。可以理解的是,预处理单元18可以为可选组件。
视频编码器(或编码器)20用于接收预处理图像数据19并提供编码图像数据21(下面将根据图2等进一步描述)。
源设备12中的通信接口22可用于:接收编码图像数据21并通过通信信道13向目的设备14等另一设备或任何其它设备发送编码图像数据21(或其它任意处理后的版本),以便存储或直接重建。
目的设备14包括解码器30,另外即可选地,可包括通信接口(或通信单元)28、后处理器(或后处理单元)32和显示设备34。
目的设备14中的通信接口28用于直接从源设备12或从存储设备等任意其它源设备接收编码图像数据21(或其它任意处理后的版本),例如,存储设备为编码图像数据存储设备,并将编码图像数据21提供给解码器30。
通信接口22和通信接口28可用于通过源设备12与目的设备14之间的直连通信链路,例如直接有线或无线连接等,或者通过任意类型的网络,例如有线网络、无线网络或其任意组合、任意类型的私网和公网或其任意类型的组合,发送或接收编码图像数据(或编码数据)21。
例如,通信接口22可用于将编码图像数据21封装为报文等合适的格式,和/或使用任意类型的传输编码或处理来处理所述编码后的图像数据,以便在通信链路或通信网络上进行传输。
通信接口28与通信接口22对应,例如,可用于接收传输数据,并使用任意类型的对应传输解码或处理和/或解封装对传输数据进行处理,得到编码图像数据21。
通信接口22和通信接口28均可配置为如图1a中从源设备12指向目的设备14的对应通信信道13的箭头所指示的单向通信接口,或双向通信接口,并且可用于发送和接收消息等,以建立连接,确认并交换与通信链路和/或例如编码后的图像数据传输等数据传输相关的任何其它信息,等等。
视频解码器(或解码器)30用于接收编码图像数据21并提供解码图像数据(或解码图像数据)31(下面将根据图3等进一步描述)。
后处理器32用于对解码后的图像等解码图像数据31(也称为重建后的图像数据)进行后处理,得到后处理后的图像等后处理图像数据33。后处理单元32执行的后处理可以包括例如颜色格式转换(例如从YCbCr转换为RGB)、调色、修剪或重采样,或者用于产生供显示设备34等显示的解码图像数据31等任何其它处理。
显示设备34用于接收后处理图像数据33,以向用户或观看者等显示图像。显示设备34可以为或包括任意类型的用于表示重建后图像的显示器,例如,集成或外部显示屏或显示器。例如,显示屏可包括液晶显示器(liquid crystal display,LCD)、有机发光二极管(organic light emitting diode,OLED)显示器、等离子显示器、投影仪、微型LED显示器、硅基液晶显示器(liquid crystal on silicon,LCoS)、数字光处理器(digital light processor,DLP)或任意类型的其它显示屏。
译码系统10还包括训练引擎25,训练引擎25用于训练编码器20(尤其是编码器20中的帧间预测单元)或解码器30(尤其是解码器30中的帧间预测单元),以处理输入图像或图像区域或图像块以生成输入图像或图像区域或图像块的预测值。
可选的,本申请实施例中训练数据集合包括:多组图像块的信息,其中每组图像块的信息包括多个已重建图像块各自的多个后验运动矢量、与多个后验运动矢量对应的多个概率值,以及当前块的多个后验候选运动矢量、与多个后验候选运动矢量对应的多个概率值,多个已重建图像块是当前块的空间邻域和/或时间邻域中的图像块。经训练数据集合训练得到神经网络,该神经网络的输入为当前块的周边区域中的多个已重建图像块各自的多个后验运动矢量、与多个后验运动矢量对应的多个概率值,输出为当前块的多个先验候选运动矢量、与多个先验候选运动矢量对应的多个概率值。
可选的,本申请实施例中训练数据集合包括:多组图像块的信息,其中每组图像块的信息包括多个已重建图像块各自的多个后验运动矢量、与多个后验运动矢量对应的多个预测误差值,以及当前块的多个后验候选运动矢量、与多个后验候选运动矢量对应的多个概率值,多个已重建图像块是当前块的空间邻域和/或时间邻域中的图像块。经训练数据集合训练得到神经网络,该神经网络的输入为当前块的周边区域中的多个已重建图像块各自的多个后验运动矢量、与多个后验运动矢量对应的多个预测误差值,输出为当前块的多个先验候选运动矢量、与多个先验候选运动矢量对应的多个概率值。
可选的,本申请实施例中训练数据集合包括:多组图像块的信息,其中每组图像块的信息包括多个已重建图像块各自的最优运动矢量,以及当前块的多个后验候选运动矢量、与多个后验候选运动矢量对应的多个概率值,多个已重建图像块是当前块的空间邻域和/或时间邻域中的图像块。经训练数据集合训练得到神经网络,该神经网络的输入为当前块的周边区域中的多个已重建图像块各自的最优运动矢量,输出为当前块的多个先验候选运动矢量、与多个先验候选运动矢量对应的多个概率值。
可选的,本申请实施例中训练数据集合包括:多组图像块的信息,其中每组图像块的信息包括图像块的重建值和多个后验候选运动矢量对应的预测值,以及图像块的多个后验运动矢量、与多个后验运动矢量对应的多个概率值。经训练数据集合训练得到神经网络,该神经网络的输入为当前块的重建值和多个后验候选运动矢量对应的预测值,输出为当前块的多个后验运动矢量、与多个后验运动矢量对应的多个概率值。
训练引擎25训练神经网络的过程使得输出的当前块的多个先验候选运动矢量逼近当前块的多个后验运动矢量,与多个先验候选运动矢量对应的多个概率值逼近与多个后验运动矢量对应的多个概率值。每个训练过程可以使用64个图像的小批量大小和1e-4的初始学习率,遵循步长大小为10。多组图像块的信息可以是通过编码器对多个当前块进行帧间编码时生成的数据。神经网络能够用于实现本申请实施例提供的帧间预测方法,即,将当前块的周边区域中的多个已重建图像块的运动矢量及其相关信息输入该神经网络,可以得到当前块的多个先验候选运动矢量以及与多个先验候选运动矢量对应的多个概率值。下文将结合图6a-6e详细说明神经网络。
本申请实施例中的训练数据可以存入数据库(未示意)中,训练引擎25基于训练数据训练得到目标模型(例如:可以是用于图像帧间预测的神经网络)。需要说明的是,本申请实施例对于训练数据的来源不做限定,例如可以是从云端或其他地方获取训练数据进行模型训练。
训练引擎25训练得到的目标模型可以应用于译码系统10中,例如,应用于图1a所示的源设备12(例如编码器20)或目的设备14(例如解码器30)。训练引擎25可以在云端训练得到目标模型,然后译码系统10从云端下载并使用该目标模型;或者,训练引擎25可以在云端训练得到目标模型并使用该目标模型,译码系统10从云端直接获取处理结果。例如,训练引擎25训练得到具备帧间预测功能的目标模型,译码系统10从云端下载该目标模型,然后编码器20中的帧间预测单元244或解码器30中的帧间预测单元344可以根据该目标模型对输入的图像或图像块进行帧间预测,得到图像或图像块的预测。又例如,训练引擎25训练得到具备帧间预测功能的目标模型,译码系统10无需从云端下载该目标模型,编码器20或解码器30将图像或图像块传输给云端,由云端通过目标模型对该图像或图像块进行帧间预测,得到图像或图像块的预测并传输给编码器20或解码器30。
尽管图1a示出了源设备12和目的设备14作为独立的设备,但设备实施例也可以同时包括源设备12和目的设备14或同时包括源设备12和目的设备14的功能,即同时包括源设备12或对应功能和目的设备14或对应功能。在这些实施例中,源设备12或对应功能和目的设备14或对应功能可以使用相同硬件和/或软件或通过单独的硬件和/或软件或其任意组合来实现。
根据描述,图1a所示的源设备12和/或目的设备14中的不同单元或功能的存在和(准确)划分可能根据实际设备和应用而有所不同,这对技术人员来说是显而易见的。
编码器20(例如视频编码器20)或解码器30(例如视频解码器30)或两者都可通过如图1b所示的处理电路实现,例如一个或多个微处理器、数字信号处理器(digital signal processor,DSP)、专用集成电路(application-specific integrated circuit,ASIC)、现场可编程门阵列(field-programmable gate array,FPGA)、离散逻辑、硬件、视频编码专用处理器或其任意组合。编码器20可以通过处理电路46实现,以包含参照图2编码器20论述的各种模块和/或本文描述的任何其它编码器系统或子系统。解码器30可以通过处理电路46实现,以包含参照图3解码器30论述的各种模块和/或本文描述的任何其它解码器系统或子系统。所述处理电路46可用于执行下文论述的各种操作。如图5所示,如果部分技术在软件中实施,则设备可以将软件的指令存储在合适的非瞬时性计算机可读存储介质中,并且使用一个或多个处理器在硬件中执行指令,从而执行本申请技术。视频编码器20和视频解码器30中的其中一个可作为组合编解码器(encoder/decoder,CODEC)的一部分集成在单个设备中,如图1b所示。
源设备12和目的设备14可包括各种设备中的任一种,包括任意类型的手持设备或固定设备,例如,笔记本电脑或膝上型电脑、手机、智能手机、平板或平板电脑、相机、台式计算机、机顶盒、电视机、显示设备、数字媒体播放器、视频游戏控制台、视频流设备(例如,内容业务服务器或内容分发服务器)、广播接收设备、广播发射设备,等等,并可以不使用或使用任意类型的操作系统。在一些情况下,源设备12和目的设备14可配备用于无线通信的组件。因此,源设备12和目的设备14可以是无线通信设备。
在一些情况下,图1a所示的视频译码系统10仅仅是示例性的,本申请提供的技术可适用于视频编码设置(例如,视频编码或视频解码),这些设置不一定包括编码设备与解码设备之间的任何数据通信。在其它示例中,数据从本地存储器中检索,通过网络发送,等等。视频编码设备可以对数据进行编码并将数据存储到存储器中,和/或视频解码设备可以从存储器中检索数据并对数据进行解码。在一些示例中,编码和解码由相互不通信而只是编码数据到存储器和/或从存储器中检索并解码数据的设备来执行。
图1b为本申请实施例的视频译码系统40的示例性框图,如图1b所示,视频译码系统40可以包含成像设备41、视频编码器20、视频解码器30(和/或藉由处理电路46实施的视频编/解码器)、天线42、一个或多个处理器43、一个或多个内存存储器44和/或显示设备45。
如图1b所示,成像设备41、天线42、处理电路46、视频编码器20、视频解码器30、处理器43、内存存储器44和/或显示设备45能够互相通信。在不同实例中,视频译码系统40可以只包含视频编码器20或只包含视频解码器30。
在一些实例中,天线42可以用于传输或接收视频数据的经编码比特流。另外,在一些实例中,显示设备45可以用于呈现视频数据。处理电路46可以包含专用集成电路(application-specific integrated circuit,ASIC)逻辑、图形处理器、通用处理器等。视频译码系统40也可以包含可选的处理器43,该可选处理器43类似地可以包含专用集成电路(application-specific integrated circuit,ASIC)逻辑、图形处理器、通用处理器等。另外,内存存储器44可以是任何类型的存储器,例如易失性存储器(例如,静态随机存取存储器(static random access memory,SRAM)、动态随机存储器(dynamic random access memory,DRAM)等)或非易失性存储器(例如,闪存等)等。在非限制性实例中,内存存储器44可以由超速缓存内存实施。在其它实例中,处理电路46可以包含存储器(例如,缓存等)用于实施图像缓冲器等。
在一些实例中,通过逻辑电路实施的视频编码器20可以包含(例如,通过处理电路46或内存存储器44实施的)图像缓冲器和(例如,通过处理电路46实施的)图形处理单元。图形处理单元可以通信耦合至图像缓冲器。图形处理单元可以包含通过处理电路46实施的视频编码器20,以实施参照图2和/或本文中所描述的任何其它编码器系统或子系统所论述的各种模块。逻辑电路可以用于执行本文所论述的各种操作。
在一些实例中,视频解码器30可以以类似方式通过处理电路46实施,以实施参照图3的视频解码器30和/或本文中所描述的任何其它解码器系统或子系统所论述的各种模块。在一些实例中,逻辑电路实施的视频解码器30可以包含(通过处理电路46或内存存储器44实施的)图像缓冲器和(例如,通过处理电路46实施的)图形处理单元。图形处理单元可以通信耦合至图像缓冲器。图形处理单元可以包含通过处理电路46实施的视频解码器30,以实施参照图3和/或本文中所描述的任何其它解码器系统或子系统所论述的各种模块。
在一些实例中,天线42可以用于接收视频数据的经编码比特流。如所论述,经编码比特流可以包含本文所论述的与编码视频帧相关的数据、指示符、索引值、模式选择数据等,例如与编码分割相关的数据(例如,变换系数或经量化变换系数,(如所论述的)可选指示符,和/或定义编码分割的数据)。视频译码系统40还可包含耦合至天线42并用于解码经编码比特流的视频解码器30。显示设备45用于呈现视频帧。
应理解,本申请实施例中对于参考视频编码器20所描述的实例,视频解码器30可以用于执行相反过程。关于信令语法元素,视频解码器30可以用于接收并解析这种语法元素,相应地解码相关视频数据。在一些例子中,视频编码器20可以将语法元素熵编码成经编码视频比特流。在此类实例中,视频解码器30可以解析这种语法元素,并相应地解码相关视频数据。
为便于描述,参考通用视频编码(versatile video coding,VVC)参考软件或由ITU-T视频编码专家组(video coding experts group,VCEG)和ISO/IEC运动图像专家组(motion picture experts group,MPEG)的视频编码联合工作组(joint collaboration team on video coding,JCT-VC)开发的高性能视频编码(high-efficiency video coding,HEVC)描述本申请实施例。本领域普通技术人员理解本申请实施例不限于HEVC或VVC。
编码器和编码方法
图2为本申请实施例的视频编码器20的示例性框图。如图2所示,视频编码器20包括输入端(或输入接口)201、残差计算单元204、变换处理单元206、量化单元208、反量化单元210、逆变换处理单元212、重建单元214、环路滤波器220、解码图像缓冲器(decoded picture buffer,DPB)230、模式选择单元260、熵编码单元270和输出端(或输出接口)272。模式选择单元260可包括帧间预测单元244、帧内预测单元254和分割单元262。帧间预测单元244可包括运动估计单元和运动补偿单元(未示出)。图2所示的视频编码器20也可称为混合型视频编码器或基于混合型视频编解码器的视频编码器。
参见图2,帧间预测单元为经过训练的目标模型(亦称为神经网络),该神经网络用于处理输入图像或图像区域或图像块,以生成输入图像块的预测值。例如,用于帧间预测的神经网络用于接收输入的图像或图像区域或图像块,并且生成输入的图像或图像区域或图像块的预测值。下面将结合图6a-图6e详细地描述用于帧间预测的神经网络。
残差计算单元204、变换处理单元206、量化单元208和模式选择单元260组成编码器20的前向信号路径,而反量化单元210、逆变换处理单元212、重建单元214、缓冲器216、环路滤波器220、解码图像缓冲器(decoded picture buffer,DPB)230、帧间预测单元244和帧内预测单元254组成编码器的后向信号路径,其中编码器20的后向信号路径对应于解码器的信号路径(参见图3中的解码器30)。反量化单元210、逆变换处理单元212、重建单元214、环路滤波器220、解码图像缓冲器230、帧间预测单元244和帧内预测单元254还组成视频编码器20的“内置解码器”。
图像和图像分割(图像和块)
编码器20可用于通过输入端201等接收图像(或图像数据)17,例如,形成视频或视频序列的图像序列中的图像。接收的图像或图像数据也可以是预处理后的图像(或预处理后的图像数据)19。为简单起见,以下描述使用图像17。图像17也可称为当前图像或待编码的图像(尤其是在视频编码中将当前图像与其它图像区分开时,其它图像例如同一视频序列,即也包括当前图像的视频序列,中的之前编码后图像和/或解码后图像)。
(数字)图像为或可以视为具有强度值的像素点组成的二维阵列或矩阵。阵列中的像素点也可以称为像素(pixel或pel)(图像元素的简称)。阵列或图像在水平方向和垂直方向(或轴线)上的像素点数量决定了图像的大小和/或分辨率。为了表示颜色,通常采用三个颜色分量,即图像可以表示为或包括三个像素点阵列。在RBG格式或颜色空间中,图像包括对应的红色、绿色和蓝色像素点阵列。但是,在视频编码中,每个像素通常以亮度/色度格式或颜色空间表示,例如YCbCr,包括Y指示的亮度分量(有时也用L表示)以及Cb、Cr表示的两个色度分量。亮度(luma)分量Y表示亮度或灰度水平强度(例如,在灰度等级图像中两者相同),而两个色度(chrominance,简写为chroma)分量Cb和Cr表示色度或颜色信息分量。相应地,YCbCr格式的图像包括亮度像素点值(Y)的亮度像素点阵列和色度值(Cb和Cr)的两个色度像素点阵列。RGB格式的图像可以转换或变换为YCbCr格式,反之亦然,该过程也称为颜色变换或转换。如果图像是黑白的,则该图像可以只包括亮度像素点阵列。相应地,图像可以为例如单色格式的亮度像素点阵列或4:2:0、4:2:2和4:4:4彩色格式的亮度像素点阵列和两个相应的色度像素点阵列。
在一个实施例中,视频编码器20的实施例可包括图像分割单元(图2中未示出),用于将图像17分割成多个(通常不重叠)图像块203。这些块在H.265/HEVC和VVC标准中也可以称为根块、宏块(H.264/AVC)或编码树块(coding tree block,CTB),或编码树单元(coding tree unit,CTU)。分割单元可用于对视频序列中的所有图像使用相同的块大小和使用限定块大小的对应网格,或在图像或图像子集或图像组之间改变块大小,并将每个图像分割成对应块。
在其它实施例中,视频编码器可用于直接接收图像17的块203,例如,组成所述图像17的一个、几个或所有块。图像块203也可以称为当前图像块或待编码图像块。
与图像17一样,图像块203同样是或可认为是具有强度值(像素点值)的像素点组成的二维阵列或矩阵,但是图像块203的比图像17的小。换句话说,块203可包括一个像素点阵列(例如,单色图像17情况下的亮度阵列或彩色图像情况下的亮度阵列或色度阵列)或三个像素点阵列(例如,彩色图像17情况下的一个亮度阵列和两个色度阵列)或根据所采用的颜色格式的任何其它数量和/或类型的阵列。块203的水平方向和垂直方向(或轴线)上的像素点数量限定了块203的大小。相应地,块可以为M×N(M列×N行)个像素点阵列,或M×N个变换系数阵列等。
在一个实施例中,图2所示的视频编码器20用于逐块对图像17进行编码,例如,对每个块203执行编码和预测。
在一个实施例中,图2所示的视频编码器20还可以用于使用片(也称为视频片)分割和/或编码图像,其中图像可以使用一个或多个片(通常为不重叠的)进行分割或编码。每个片可包括一个或多个块(例如,编码树单元CTU)或一个或多个块组(例如H.265/HEVC/VVC标准中的编码区块(tile)和VVC标准中的砖(brick)。
在一个实施例中,图2所示的视频编码器20还可以用于使用片/编码区块组(也称为视频编码区块组)和/或编码区块(也称为视频编码区块)对图像进行分割和/或编码,其中图像可以使用一个或多个片/编码区块组(通常为不重叠的)进行分割或编码,每个片/编码区块组可包括一个或多个块(例如CTU)或一个或多个编码区块等,其中每个编码区块可以为矩形等形状,可包括一个或多个完整或部分块(例如CTU)。
残差计算
残差计算单元204用于通过如下方式根据图像块(或原始块)203和预测块265来计算残差块205(后续详细介绍了预测块265):例如,逐个像素点(逐个像素)从图像块203的像素点值中减去预测块265的像素点值,得到像素域中的残差块205。
变换
变换处理单元206用于对残差块205的像素点值执行离散余弦变换(discrete cosine transform,DCT)或离散正弦变换(discrete sine transform,DST)等,得到变换域中的变换系数207。变换系数207也可称为变换残差系数,表示变换域中的残差块205。
变换处理单元206可用于应用DCT/DST的整数化近似,例如为H.265/HEVC指定的变换。与正交DCT变换相比,这种整数化近似通常由某一因子按比例缩放。为了维持经过正变换和逆变换处理的残差块的范数,使用其它比例缩放因子作为变换过程的一部分。比例缩放因子通常是根据某些约束条件来选择的,例如比例缩放因子是用于移位运算的2的幂、变换系数的位深度、准确性与实施成本之间的权衡等。例如,在编码器20侧通过逆变换处理单元212为逆变换(以及在解码器30侧通过例如逆变换处理单元312为对应逆变换)指定具体的比例缩放因子,以及相应地,可以在编码器20侧通过变换处理单元206为正变换指定对应比例缩放因子。
在一个实施例中,视频编码器20(对应地,变换处理单元206)可用于输出一种或多种变换的类型等变换参数,例如,直接输出或由熵编码单元270进行编码或压缩后输出,例如使得视频解码器30可接收并使用变换参数进行解码。
量化
量化单元208用于通过例如标量量化或矢量量化对变换系数207进行量化,得到量化变换系数209。量化变换系数209也可称为量化残差系数209。
量化过程可减少与部分或全部变换系数207有关的位深度。例如,可在量化期间将n位变换系数向下舍入到m位变换系数,其中n大于m。可通过调整量化参数(quantization parameter,QP)修改量化程度。例如,对于标量量化,可以应用不同程度的比例来实现较细或较粗的量化。较小量化步长对应较细量化,而较大量化步长对应较粗量化。可通过量化参数(quantization parameter,QP)指示合适的量化步长。例如,量化参数可以为合适的量化步长的预定义集合的索引。例如,较小的量化参数可对应精细量化(较小量化步长),较大的量化参数可对应粗糙量化(较大量化步长),反之亦然。量化可包括除以量化步长,而反量化单元210等执行的对应或逆解量化可包括乘以量化步长。根据例如HEVC一些标准的实施例可用于使用量化参数来确定量化步长。一般而言,可以根据量化参数使用包含除法的等式的定点近似来计算量化步长。可以引入其它比例缩放因子来进行量化和解量化,以恢复可能由于在用于量化步长和量化参数的等式的定点近似中使用的比例而修改的残差块的范数。在一种示例性实现方式中,可以合并逆变换和解量化的比例。或者,可以使用自定义量化表并在比特流中等将其从编码器向解码器指示。量化是有损操作,其中量化步长越大,损耗越大。
在一个实施例中,视频编码器20(对应地,量化单元208)可用于输出量化参数(quantization parameter,QP),例如,直接输出或由熵编码单元270进行编码或压缩后输出,例如使得视频解码器30可接收并使用量化参数进行解码。
反量化
反量化单元210用于对量化系数执行量化单元208的反量化,得到解量化系数211,例如,根据或使用与量化单元208相同的量化步长执行与量化单元208所执行的量化方案的反量化方案。解量化系数211也可称为解量化残差系数211,对应于变换系数207,但是由于量化造成损耗,反量化系数211通常与变换系数不完全相同。
逆变换
逆变换处理单元212用于执行变换处理单元206执行的变换的逆变换,例如,逆离散余弦变换(discrete cosine transform,DCT)或逆离散正弦变换(discrete sine transform,DST),以在像素域中得到重建残差块213(或对应的解量化系数213)。重建残差块213也可称为变换块213。
重建
重建单元214(例如,求和器214)用于将变换块213(即重建残差块213)添加到预测块265,以在像素域中得到重建块215,例如,将重建残差块213的像素点值和预测块265的像素点值相加。
滤波
环路滤波器单元220(或简称“环路滤波器”220)用于对重建块215进行滤波,得到滤波块221,或通常用于对重建像素点进行滤波以得到滤波像素点值。例如,环路滤波器单元用于顺利进行像素转变或提高视频质量。环路滤波器单元220可包括一个或多个环路滤波器,例如去块滤波器、像素点自适应偏移(sample-adaptive offset,SAO)滤波器或一个或多个其它滤波器,例如自适应环路滤波器(adaptive loop filter,ALF)、噪声抑制滤波器(noise suppression filter,NSF)或任意组合。例如,环路滤波器单元220可以包括去块滤波器、SAO滤波器和ALF滤波器。滤波过程的顺序可以是去块滤波器、SAO滤波器和ALF滤波器。再例如,增加一个称为具有色度缩放的亮度映射(luma mapping with chroma scaling,LMCS)(即自适应环内整形器)的过程。该过程在去块之前执行。再例如,去块滤波过程也可以应用于内部子块边缘,例如仿射子块边缘、ATMVP子块边缘、子块变换(sub-block transform,SBT)边缘和内子部分(intra sub-partition,ISP)边缘。尽管环路滤波器单元220在图2中示为环路滤波器,但在其它配置中,环路滤波器单元220可以实现为环后滤波器。滤波块221也可称为滤波重建块221。
在一个实施例中,视频编码器20(对应地,环路滤波器单元220)可用于输出环路滤波器参数(例如SAO滤波参数、ALF滤波参数或LMCS参数),例如,直接输出或由熵编码单元270进行熵编码后输出,例如使得解码器30可接收并使用相同或不同的环路滤波器参数进行解码。
解码图像缓冲器
解码图像缓冲器(decoded picture buffer,DPB)230可以是存储参考图像数据以供视频编码器20在编码视频数据时使用的参考图像存储器。DPB 230可以由多种存储器设备中的任一种形成,例如动态随机存取存储器(dynamic random access memory,DRAM),包括同步DRAM(synchronous DRAM,SDRAM)、磁阻RAM(magnetoresistive RAM,MRAM)、电阻RAM(resistive RAM,RRAM)或其它类型的存储设备。解码图像缓冲器230可用于存储一个或多个滤波块221。解码图像缓冲器230还可用于存储同一当前图像或例如之前的重建图像等不同图像的其它之前的滤波块,例如之前重建和滤波的块221,并可提供完整的之前重建即解码图像(和对应参考块和像素点)和/或部分重建的当前图像(和对应参考块和像素点),例如用于帧间预测。解码图像缓冲器230还可用于存储一个或多个未经滤波的重建块215,或一般存储未经滤波的重建像素点,例如,未被环路滤波单元220滤波的重建块215,或未进行任何其它处理的重建块或重建像素点。
模式选择(分割和预测)
模式选择单元260包括分割单元262、帧间预测单元244和帧内预测单元254,用于从解码图像缓冲器230或其它缓冲器(例如,列缓冲器,图中未显示)接收或获得原始块203(当前图像17的当前块203)和重建图像数据等原始图像数据,例如,同一(当前)图像和/或一个或多个之前解码图像的滤波和/或未经滤波的重建像素点或重建块。重建图像数据用作帧间预测或帧内预测等预测所需的参考图像数据,以得到预测块265或预测值265。
模式选择单元260可用于为当前块(包括不分割)和预测模式(例如帧内或帧间预测模式)确定或选择一种分割,生成对应的预测块265,以对残差块205进行计算和对重建块215进行重建。
在一个实施例中,模式选择单元260可用于选择分割和预测模式(例如,从模式选择单元260支持的或可用的预测模式中),所述预测模式提供最佳匹配或者说最小残差(最小残差是指传输或存储中更好的压缩),或者提供最小信令开销(最小信令开销是指传输或存储中更好的压缩),或者同时考虑或平衡以上两者。模式选择单元260可用于根据码率失真优化(rate distortion Optimization,RDO)确定分割和预测模式,即选择提供最小码率失真优化的预测模式。本文“最佳”、“最低”、“最优”等术语不一定指总体上“最佳”、“最低”、“最优”的,但也可以指满足终止或选择标准的情况,例如,超过或低于阈值的值或其他限制可能导致“次优选择”,但会降低复杂度和处理时间。
换言之,分割单元262可用于将视频序列中的图像分割为编码树单元(coding tree unit,CTU)序列,CTU 203可进一步被分割成较小的块部分或子块(再次形成块),例如,通过迭代使用四叉树(quad-tree partitioning,QT)分割、二叉树(binary-tree partitioning,BT)分割或三叉树(triple-tree partitioning,TT)分割或其任意组合,并且用于例如对块部分或子块中的每一个执行预测,其中模式选择包括选择分割块203的树结构和选择应用于块部分或子块中的每一个的预测模式。
下文将详细地描述由视频编码器20执行的分割(例如,由分割单元262执行)和预测处理(例如,由帧间预测单元244和帧内预测单元254执行)。
分割
分割单元262可将一个图像块(或CTU)203分割(或划分)为较小的部分,例如正方形或矩形形状的小块。对于具有三个像素点阵列的图像,一个CTU由N×N个亮度像素点块和两个对应的色度像素点块组成。CTU中亮度块的最大允许大小在正在开发的通用视频编码(versatile video coding,VVC)标准中被指定为128×128,但是将来可指定为不同于128×128的值,例如256×256。图像的CTU可以集中/分组为片/编码区块组、编码区块或砖。一个编码区块覆盖着一个图像的矩形区域,一个编码区块可以分成一个或多个砖。一个砖由一个编码区块内的多个CTU行组成。没有分割为多个砖的编码区块可以称为砖。但是,砖是编码区块的真正子集,因此不称为编码区块。VVC支持两种编码区块组模式,分别为光栅扫描片/编码区块组模式和矩形片模式。在光栅扫描编码区块组模式,一个片/编码区块组包含一个图像的编码区块光栅扫描中的编码区块序列。在矩形片模式中,片包含一个图像的多个砖,这些砖共同组成图像的矩形区域。矩形片内的砖按照片的砖光栅扫描顺序排列。这些较小块(也可称为子块)可进一步分割为更小的部分。这也称为树分割或分层树分割,其中在根树级别0(层次级别0、深度0)等的根块可以递归地分割为两个或两个以上下一个较低树级别的块,例如树级别1(层次级别1、深度1)的节点。这些块可以又分割为两个或两个以上下一个较低级别的块,例如树级别2(层次级别2、深度2)等,直到分割结束(因为满足结束标准,例如达到最大树深度或最小块大小)。未进一步分割的块也称为树的叶块或叶节点。分割为两个部分的树称为二叉树(binary-tree,BT),分割为三个部分的树称为三叉树(ternary-tree,TT),分割为四个部分的树称为四叉树(quad-tree,QT)。
例如,编码树单元(CTU)可以为或包括亮度像素点的CTB、具有三个像素点阵列的图像的色度像素点的两个对应CTB、或单色图像的像素点的CTB或使用三个独立颜色平面和语法结构(用于编码像素点)编码的图像的像素点的CTB。相应地,编码树块(CTB)可以为N×N个像素点块,其中N可以设为某个值使得分量划分为CTB,这就是分割。编码单元(coding unit,CU)可以为或包括亮度像素点的编码块、具有三个像素点阵列的图像的色度像素点的两个对应编码块、或单色图像的像素点的编码块或使用三个独立颜色平面和语法结构(用于编码像素点)编码的图像的像素点的编码块。相应地,编码块(CB)可以为M×N个像素点块,其中M和N可以设为某个值使得CTB划分为编码块,这就是分割。
例如,在实施例中,根据HEVC可通过使用表示为编码树的四叉树结构将编码树单元(CTU)划分为多个CU。在叶CU级作出是否使用帧间(时间)预测或帧内(空间)预测对图像区域进行编码的决定。每个叶CU可以根据PU划分类型进一步划分为一个、两个或四个PU。一个PU内使用相同的预测过程,并以PU为单位向解码器传输相关信息。在根据PU划分类型应用预测过程得到残差块之后,可以根据类似于用于CU的编码树的其它四叉树结构将叶CU分割为变换单元(TU)。
例如,在实施例中,根据当前正在开发的最新视频编码标准(称为通用视频编码(VVC),使用嵌套多类型树(例如二叉树和三叉树)的组合四叉树来划分用于分割编码树单元的分段结构。在编码树单元内的编码树结构中,CU可以为正方形或矩形。例如,编码树单元(CTU)首先由四叉树结构进行分割。四叉树叶节点进一步由多类型树结构分割。多类型树形结构有四种划分类型:垂直二叉树划分(SPLIT_BT_VER)、水平二叉树划分(SPLIT_BT_HOR)、垂直三叉树划分(SPLIT_TT_VER)和水平三叉树划分(SPLIT_TT_HOR)。多类型树叶节点称为编码单元(CU),除非CU对于最大变换长度而言太大,这样的分段用于预测和变换处理,无需其它任何分割。在大多数情况下,这表示CU、PU和TU在四叉树嵌套多类型树的编码块结构中的块大小相同。当最大支持变换长度小于CU的彩色分量的宽度或高度时,就会出现该异常。VVC制定了具有四叉树嵌套多类型树的编码结构中的分割划分信息的唯一信令机制。在信令机制中,编码树单元(CTU)作为四叉树的根首先被四叉树结构分割。然后每个四叉树叶节点(当足够大可以被)被进一步分割为一个多类型树结构。在多类型树结构中,通过第一标识(mtt_split_cu_flag)指示节点是否进一步分割,当对节点进一步分割时,先用第二标识(mtt_split_cu_vertical_flag)指示划分方向,再用第三标识(mtt_split_cu_binary_flag)指示划分是二叉树划分或三叉树划分。根据mtt_split_cu_vertical_flag和mtt_split_cu_binary_flag的值,解码器可以基于预定义规则或表格推导出CU的多类型树划分模式(MttSplitMode)。需要说明的是,对于某种设计,例如VVC硬件解码器中的64×64的亮度块和32×32的色度流水线设计,当亮度编码块的宽度或高度大于64时,不允许进行TT划分。当色度编码块的宽度或高度大于32时,也不允许TT划分。流水线设计将图像分为多个虚拟流水线数据单元(virtual pipeline data unit,VPDU),每个VPDU在图像中定义为互不重叠的单元。在硬件解码器中,连续的VPDU在多个流水线阶段同时处理。在大多数流水线阶段,VPDU大小与缓冲器大小大致成正比,因此需要保持较小的VPDU。在大多数硬件解码器中,VPDU大小可以设置为最大变换块(transform block,TB)大小。但是,在VVC中,三叉树(TT)和二叉树(BT)的分割可能会增加VPDU的大小。
另外,需要说明的是,当树节点块的一部分超出底部或图像右边界时,强制对该树节点块进行划分,直到每个编码CU的所有像素点都位于图像边界内。
例如,所述帧内子分割(intra sub-partitions,ISP)工具可以根据块大小将亮度帧内预测块垂直或水平地分为两个或四个子部分。
在一个示例中,视频编码器20的模式选择单元260可以用于执行上文描述的分割技术的任意组合。
如上所述,视频编码器20用于从(预定的)预测模式集合中确定或选择最好或最优的预测模式。预测模式集合可包括例如帧内预测模式和/或帧间预测模式。
帧内预测
帧内预测模式集合可包括35种不同的帧内预测模式,例如,像DC(或均值)模式和平面模式的非方向性模式,或如HEVC定义的方向性模式,或者可包括67种不同的帧内预测模式,例如,像DC(或均值)模式和平面模式的非方向性模式,或如VVC中定义的方向性模式。例如,若干传统角度帧内预测模式自适应地替换为VVC中定义的非正方形块的广角帧内预测模式。又例如,为了避免DC预测的除法运算,仅使用较长边来计算非正方形块的平均值。并且,平面模式的帧内预测结果还可以使用位置决定的帧内预测组合(position dependent intra prediction combination,PDPC)方法修改。
帧内预测单元254用于根据帧内预测模式集合中的帧内预测模式使用同一当前图像的相邻块的重建像素点来生成帧内预测块265。
帧内预测单元254(或通常为模式选择单元260)还用于输出帧内预测参数(或通常为指示块的选定帧内预测模式的信息)以语法元素266的形式发送到熵编码单元270,以包含到编码图像数据21中,从而视频解码器30可执行操作,例如接收并使用用于解码的预测参数。
HEVC中的帧内预测模式包括直流预测模式,平面预测模式和33种角度预测模式,共计35个候选预测模式。图3为HEVC帧内预测方向示意图,如图3所示,当前块可以使用左侧和上方已重建图像块的像素作为参考进行帧内预测。当前块的周边区域中用来对当前块进行帧内预测的图像块成为参考块,参考块中的像素称为参考像素。35个候选预测模式中,直流预测模式适用于当前块中纹理平坦的区域,该区域中所有像素均使用参考块中的参考像素的平均值作为预测;平面预测模式适用于纹理平滑变化的图像块,符合该条件的当前块使用参考块中的参考像素进行双线性插值作为当前块中的所有像素的预测;角度预测模式利用当前块的纹理与相邻已重建图像块的纹理高度相关的特性,沿某一角度复制对应的参考块中的参考像素的值作为当前块中的所有像素的预测。
HEVC编码器给当前块从图3所示的35个候选预测模式中选择一个最优帧内预测模式,并将该最优帧内预测模式写入视频码流。为提升帧内预测的编码效率,编码器/解码器会从周边区域中、采用帧内预测的已重建图像块各自的最优帧内预测模式中推导出3个最可能模式,如果给当前块选择的最优帧内预测模式是这3个最可能模式的其中之一,则编码一个第一索引指示所选择的最优帧内预测模式是这3个最可能模式的其中之一;如果选中的最优帧内预测模式不是这3个最可能模式,则编码一个第二索引指示所选择的最优帧内预测模式是其他32个模式(35个候选预测模式中除前述3个最可能模式外的其他模式)的其中之一。HEVC标准使用5比特的定长码作为前述第二索引。
HEVC编码器推导出3个最可能模式的方法包括:选取当前块的左相邻图像块和上相邻图像块的最优帧内预测模式放入集合,如果这两个最优帧内预测模式相同,则集合中只保留一个即可。如果这两个最优帧内预测模式相同且均为角度预测模式,则再选取与该角度方向邻近的两个角度预测模式加入集合;否则,依次选择平面预测模式、直流模式模式和竖直预测模式加入集合,直到集合中的模式数量达到3。
HEVC解码器对码流做熵解码后,获得当前块的模式信息,该模式信息包括指示当前块的最优帧内预测模式是否在3个最可能模式中的指示标识,以及当前块的最优帧内预测模式在3个最可能模式中的索引或者当前块的最优帧内预测模式在其他32个模式中的索引。
帧间预测
在可能的实现中,帧间预测模式集合取决于可用参考图像(即,例如前述存储在DBP230中的至少部分之前解码的图像)和其它帧间预测参数,例如取决于是否使用整个参考图像或只使用参考图像的一部分,例如当前块的区域附近的搜索窗口区域,来搜索最佳匹配参考块,和/或例如取决于是否执行半像素、四分之一像素和/或16分之一内插的像素内插。
除上述预测模式外,还可以采用跳过模式和/或直接模式。
例如,扩展合并预测,这个模式的合并候选列表由以下五个候选类型按顺序组成:来自空间相邻CU的空间MVP、来自并置CU的时间MVP、来自FIFO表的基于历史的MVP、成对平均MVP和零MV。可以使用基于双边匹配的解码器侧运动矢量修正(decoder side motion vector refinement,DMVR)来增加合并模式的MV的准确度。带有MVD的合并模式(merge mode with MVD,MMVD)来自有运动矢量差异的合并模式。在发送跳过标志和合并标志之后立即发送MMVD标志,以指定CU是否使用MMVD模式。可以使用CU级自适应运动矢量分辨率(adaptive motion vector resolution,AMVR)方案。AMVR支持CU的MVD以不同的精度进行编码。根据当前CU的预测模式,自适应地选择当前CU的MVD。当CU以合并模式进行编码时,可以将合并的帧间/帧内预测(combined inter/intra prediction,CIIP)模式应用于当前CU。对帧间和帧内预测信号进行加权平均,得到CIIP预测。对于仿射运动补偿预测,通过2个控制点(4参数)或3个控制点(6参数)运动矢量的运动信息来描述块的仿射运动场。基于子块的时间运动矢量预测(subblock-based temporal motion vector prediction,SbTMVP),与HEVC中的时间运动矢量预测(temporal motion vector prediction,TMVP)类似,但预测的是当前CU内的子CU的运动矢量。双向光流(bi-directional optical flow,BDOF)以前称为BIO,是一种减少计算的简化版本,特别是在乘法次数和乘数大小方面的计算。在三角形分割模式中,CU以对角线划分和反对角线划分两种划分方式被均匀划分为两个三角形部分。此外,双向预测模式在简单平均的基础上进行了扩展,以支持两个预测信号的加权平均。
帧间预测单元244可包括运动估计(motion estimation,ME)单元和运动补偿(motion compensation,MC)单元(两者在图2中未示出)。运动估计单元可用于接收或获取图像块203(当前图像17的当前图像块203)和解码图像231,或至少一个或多个之前重建块,例如,一个或多个其它/不同之前解码图像231的重建块,来进行运动估计。例如,视频序列可包括当前图像和之前的解码图像231,或换句话说,当前图像和之前的解码图像231可以为形成视频序列的图像序列的一部分或形成该图像序列。
例如,编码器20可用于从多个其它图像中的同一或不同图像的多个参考块中选择参考块,并将参考图像(或参考图像索引)和/或参考块的位置(x、y坐标)与当前块的位置之间的偏移(空间偏移)作为帧间预测参数提供给运动估计单元。该偏移也称为运动矢量(motion vector,MV)。
运动补偿单元用于获取,例如接收,帧间预测参数,并根据或使用该帧间预测参数执行帧间预测,得到帧间预测块246。由运动补偿单元执行的运动补偿可能包含根据通过运动估计确定的运动/块矢量来提取或生成预测块,还可能包括对子像素精度执行内插。内插滤波可从已知像素的像素点中产生其它像素的像素点,从而潜在地增加可用于对图像块进行编码的候选预测块的数量。一旦接收到当前图像块的PU对应的运动矢量时,运动补偿单元可在其中一个参考图像列表中定位运动矢量指向的预测块。
运动补偿单元还可以生成与块和视频片相关的语法元素,以供视频解码器30在解码视频片的图像块时使用。此外,或者作为片和相应语法元素的替代,可以生成或使用编码区块组和/或编码区块以及相应语法元素。
在获取先进的运动矢量预测(advanced motion vector prediction,AMVP)模式中的候选运动矢量列表的过程中,作为备选可以加入候选运动矢量列表的运动矢量(motion vector,MV)包括当前块的空域相邻和时域相邻的图像块的MV,其中空域相邻的图像块的MV又可以包括位于当前块左侧的左方候选图像块的MV和位于当前块上方的上方候选图像块的MV。示例性的,图7为本申请实施例的候选图像块的示例性的示意图,如图7所示,左方候选图像块的集合包括{A0,A1},上方候选图像块的集合包括{B0,B1,B2},时域相邻的候选图像块的集合包括{C,T},这三个集合均可以作为备选被加入到候选运动矢量列表中,但是根据现有编码标准,AMVP的候选运动矢量列表的最大长度为2,因此需要根据规定的顺序从三个集合中确定在候选运动矢量列表中加入最多两个图像块的MV。该顺序可以是优先考虑当前块的左方候选图像块的集合{A0,A1}(先考虑A0,A0不可得再考虑A1),其次考虑当前块的上方候选图像块的集合{B0,B1,B2}(先考虑B0,B0不可得再考虑B1,B1不可得再考虑B2),最后考虑当前块的时域相邻的候选图像块的集合{C,T}(先考虑T,T不可得再考虑C)。
得到上述候选运动矢量列表后,通过率失真代价(rate distortion cost,RD cost)从候选运动矢量列表中确定最优的MV,将RD cost最小的候选运动矢量作为当前块的运动矢量预测值(motion vector predictor,MVP)。率失真代价由以下公式计算获得:
J=SAD λR
其中,J表示RD cost,SAD为使用候选运动矢量进行运动估计后得到的预测块的像素值与当前块的像素值之间的绝对误差和(sum of absolute differences,SAD),R表示码率,λ表示拉格朗日乘子。
编码端将确定出的MVP在候选运动矢量列表中的索引传递到解码端。进一步地,可以在MVP为中心的邻域内进行运动搜索获得当前块实际的运动矢量,编码端计算MVP与实际的运动矢量之间的运动矢量差值(motion vector difference,MVD),并将MVD也传递到解码端。解码端解析索引,根据该索引在候选运动矢量列表中找到对应的MVP,解析MVD,将MVD与MVP相加得到当前块实际的运动矢量。
在获取融合(Merge)模式中的候选运动信息列表的过程中,作为备选可以加入候选运动信息列表的运动信息包括当前块的空域相邻或时域相邻的图像块的运动信息,其中空域相邻的图像块和时域相邻的图像块可参照图7,候选运动信息列表中对应于空域的候选运动信息来自于空间相邻的5个块(A0、A1、B0、B1和B2),若空域相邻块不可得或者为帧内预测,则其运动信息不加入候选运动信息列表。当前块的时域的候选运动信息根据参考帧和当前帧的图序计数(picture order count,POC)对参考帧中对应位置块的MV进行缩放后获得,先判断参考帧中位置为T的块是否可得,若不可得则选择位置为C的块。得到上述候选运动信息列表后,通过RD cost从候选运动信息列表中确定最优的运动信息作为当前块的运动信息。编码端将最优的运动信息在候选运动信息列表中位置的索引值(记为merge index)传递到解码端。
熵编码
熵编码单元270用于将熵编码算法或方案(例如,可变长度编码(variable length coding,VLC)方案、上下文自适应VLC方案(context adaptive VLC,CALVC)、算术编码方案、二值化算法、上下文自适应二进制算术编码(context adaptive binary arithmetic coding,CABAC)、基于语法的上下文自适应二进制算术编码(syntax-based context-adaptive binary arithmetic coding,SBAC)、概率区间分割熵(probability interval partitioning entropy,PIPE)编码或其它熵编码方法或技术)应用于量化残差系数209、帧间预测参数、帧内预测参数、环路滤波器参数和/或其它语法元素,得到可以通过输出端272以编码比特流21等形式输出的编码图像数据21,使得视频解码器30等可以接收并使用用于解码的参数。可将编码比特流21传输到视频解码器30,或将其保存在存储器中稍后由视频解码器30传输或检索。
视频编码器20的其它结构变体可用于对视频流进行编码。例如,基于非变换的编码器20可以在某些块或帧没有变换处理单元206的情况下直接量化残差信号。在另一种实现方式中,编码器20可以具有组合成单个单元的量化单元208和反量化单元210。
解码器和解码方法
图3为本申请实施例的视频解码器30的示例性框图。视频解码器30用于接收例如由编码器20编码的编码图像数据21(例如编码比特流21),得到解码图像331。编码图像数据或比特流包括用于解码所述编码图像数据的信息,例如表示编码视频片(和/或编码区块组或编码区块)的图像块的数据和相关的语法元素。
在图3的示例中,解码器30包括熵解码单元304、反量化单元310、逆变换处理单元312、重建单元314(例如求和器314)、环路滤波器320、解码图像缓冲器(DBP)330、模式应用单元360、帧间预测单元344和帧内预测单元354。帧间预测单元344可以为或包括运动补偿单元。在一些示例中,视频解码器30可执行大体上与参照图2的视频编码器100描述的编码过程相反的解码过程。
参见图3,帧间预测单元包括为经过训练的目标模型(亦称为神经网络),该神经网络用于处理输入图像或图像区域或图像块,以生成输入图像块的预测值。例如,用于帧间预测的神经网络用于接收输入的图像或图像区域或图像块,并且生成输入的图像或图像区域或图像块的预测值。下面将结合图6a-图6e详细地描述用于帧间预测的神经网络。
如编码器20所述,反量化单元210、逆变换处理单元212、重建单元214、环路滤波器220、解码图像缓冲器DPB230、帧间预测单元344和帧内预测单元354还组成视频编码器20的“内置解码器”。相应地,反量化单元310在功能上可与反量化单元110相同,逆变换处理单元312在功能上可与逆变换处理单元122相同,重建单元314在功能上可与重建单元214相同,环路滤波器320在功能上可与环路滤波器220相同,解码图像缓冲器330在功能上可与解码图像缓冲器230相同。因此,视频编码器20的相应单元和功能的解释相应地适用于视频解码器30的相应单元和功能。
熵解码
熵解码单元304用于解析比特流21(或一般为编码图像数据21)并对编码图像数据21执行熵解码,得到量化系数309和/或解码后的编码参数(图3中未示出)等,例如帧间预测参数(例如参考图像索引和运动矢量)、帧内预测参数(例如帧内预测模式或索引)、变换参数、量化参数、环路滤波器参数和/或其它语法元素等中的任一个或全部。熵解码单元304可用于应用编码器20的熵编码单元270的编码方案对应的解码算法或方案。熵解码单元304还可用于向模式应用单元360提供帧间预测参数、帧内预测参数和/或其它语法元素,以及向解码器30的其它单元提供其它参数。视频解码器30可以接收视频片和/或视频块级的语法元素。此外,或者作为片和相应语法元素的替代,可以接收或使用编码区块组和/或编码区块以及相应语法元素。
反量化
反量化单元310可用于从编码图像数据21(例如通过熵解码单元304解析和/或解码)接收量化参数(quantization parameter,QP)(或一般为与反量化相关的信息)和量化系数,并基于所述量化参数对所述解码的量化系数309进行反量化以获得反量化系数311,所述反量化系数311也可以称为变换系数311。反量化过程可包括使用视频编码器20为视频片中的每个视频块计算的量化参数来确定量化程度,同样也确定需要执行的反量化的程度。
逆变换
逆变换处理单元312可用于接收解量化系数311,也称为变换系数311,并对解量化系数311应用变换以得到像素域中的重建残差块213。重建残差块213也可称为变换块313。变换可以为逆变换,例如逆DCT、逆DST、逆整数变换或概念上类似的逆变换过程。逆变换处理单元312还可以用于从编码图像数据21(例如通过熵解码单元304解析和/或解码)接收变换参数或相应信息,以确定应用于解量化系数311的变换。
重建
重建单元314(例如,求和器314)用于将重建残差块313添加到预测块365,以在像素域中得到重建块315,例如,将重建残差块313的像素点值和预测块365的像素点值相加。
滤波
环路滤波器单元320(在编码环路中或之后)用于对重建块315进行滤波,得到滤波块321,从而顺利进行像素转变或提高视频质量等。环路滤波器单元320可包括一个或多个环路滤波器,例如去块滤波器、像素点自适应偏移(sample-adaptive offset,SAO)滤波器或一个或多个其它滤波器,例如自适应环路滤波器(adaptive loop filter,ALF)、噪声抑制滤波器(noise suppression filter,NSF)或任意组合。例如,环路滤波器单元220可以包括去块滤波器、SAO滤波器和ALF滤波器。滤波过程的顺序可以是去块滤波器、SAO滤波器和ALF滤波器。再例如,增加一个称为具有色度缩放的亮度映射(luma mapping with chroma scaling,LMCS)(即自适应环内整形器)的过程。该过程在去块之前执行。再例如,去块滤波过程也可以应用于内部子块边缘,例如仿射子块边缘、ATMVP子块边缘、子块变换(sub-block transform,SBT)边缘和内子部分(intra sub-partition,ISP)边缘。尽管环路滤波器单元320在图3中示为环路滤波器,但在其它配置中,环路滤波器单元320可以实现为环后滤波器。
解码图像缓冲器
随后将一个图像中的解码视频块321存储在解码图像缓冲器330中,解码图像缓冲器330存储作为参考图像的解码图像331,参考图像用于其它图像和/或分别输出显示的后续运动补偿。
解码器30用于通过输出端312等输出解码图像311,向用户显示或供用户查看。
预测
帧间预测单元344在功能上可与帧间预测单元244(特别是运动补偿单元)相同,帧内预测单元354在功能上可与帧间预测单元254相同,并基于从编码图像数据21(例如通过熵解码单元304解析和/或解码)接收的分割和/或预测参数或相应信息决定划分或分割和执行预测。模式应用单元360可用于根据重建图像、块或相应的像素点(已滤波或未滤波)执行每个块的预测(帧内或帧间预测),得到预测块365。
当将视频片编码为帧内编码(intra coded,I)片时,模式应用单元360中的帧内预测单元354用于根据指示的帧内预测模式和来自当前图像的之前解码块的数据生成用于当前视频片的图像块的预测块365。当视频图像编码为帧间编码(即,B或P)片时,模式应用单元360中的帧间预测单元344(例如运动补偿单元)用于根据运动矢量和从熵解码单元304接收的其它语法元素生成用于当前视频片的视频块的预测块365。对于帧间预测,可从其中一个参考图像列表中的其中一个参考图像产生这些预测块。视频解码器30可以根据存储在DPB 330中的参考图像,使用默认构建技术来构建参考帧列表0和列表1。除了片(例如视频片)或作为片的替代,相同或类似的过程可应用于编码区块组(例如视频编码区块组)和/或编码区块(例如视频编码区块)的实施例,例如视频可以使用I、P或B编码区块组和/或编码区块进行编码。
模式应用单元360用于通过解析运动矢量和其它语法元素,确定用于当前视频片的视频块的预测信息,并使用预测信息产生用于正在解码的当前视频块的预测块。例如,模式应用单元360使用接收到的一些语法元素确定用于编码视频片的视频块的预测模式(例如帧内预测或帧间预测)、帧间预测片类型(例如B片、P片或GPB片)、用于片的一个或多个参考图像列表的构建信息、用于片的每个帧间编码视频块的运动矢量、用于片的每个帧间编码视频块的帧间预测状态、其它信息,以解码当前视频片内的视频块。除了片(例如视频片)或作为片的替代,相同或类似的过程可应用于编码区块组(例如视频编码区块组)和/或编码区块(例如视频编码区块)的实施例,例如视频可以使用I、P或B编码区块组和/或编码区块进行编码。
在一个实施例中,图3的视频编码器30还可以用于使用片(也称为视频片)分割和/或解码图像,其中图像可以使用一个或多个片(通常为不重叠的)进行分割或解码。每个片可包括一个或多个块(例如CTU)或一个或多个块组(例如H.265/HEVC/VVC标准中的编码区块和VVC标准中的砖。
在一个实施例中,图3所示的视频解码器30还可以用于使用片/编码区块组(也称为视频编码区块组)和/或编码区块(也称为视频编码区块)对图像进行分割和/或解码,其中图像可以使用一个或多个片/编码区块组(通常为不重叠的)进行分割或解码,每个片/编码区块组可包括一个或多个块(例如CTU)或一个或多个编码区块等,其中每个编码区块可以为矩形等形状,可包括一个或多个完整或部分块(例如CTU)。
视频解码器30的其它变型可用于对编码图像数据21进行解码。例如,解码器30可以在没有环路滤波器单元320的情况下产生输出视频流。例如,基于非变换的解码器30可以在某些块或帧没有逆变换处理单元312的情况下直接反量化残差信号。在另一种实现方式中,视频解码器30可以具有组合成单个单元的反量化单元310和逆变换处理单元312。
应理解,在编码器20和解码器30中,可以对当前步骤的处理结果进一步处理,然后输出到下一步骤。例如,在插值滤波、运动矢量推导或环路滤波之后,可以对插值滤波、运动矢量推导或环路滤波的处理结果进行进一步的运算,例如裁剪(clip)或移位(shift)运算。
应该注意的是,可以对当前块的推导运动矢量(包括但不限于仿射模式的控制点运动矢量、仿射、平面、ATMVP模式的子块运动矢量、时间运动矢量等)进行进一步运算。例如,根据运动矢量的表示位将运动矢量的值限制在预定义范围。如果运动矢量的表示位为bitDepth,则范围为-2^(bitDepth-1)至2^(bitDepth-1)-1,其中“^”表示幂次方。例如,如果bitDepth设置为16,则范围为-32768~32767;如果bitDepth设置为18,则范围为-131072~131071。例如,推导运动矢量的值(例如一个8×8块中的4个4×4子块的MV)被限制,使得所述4个4×4子块MV的整数部分之间的最大差值不超过N个像素,例如不超过1个像素。这里提供了两种根据bitDepth限制运动矢量的方法。
尽管上述实施例主要描述了视频编解码,但应注意的是,译码系统10、编码器20和解码器30的实施例以及本文描述的其它实施例也可以用于静止图像处理或编解码,即视频编解码中独立于任何先前或连续图像的单个图像的处理或编解码。一般情况下,如果图像处理仅限于单个图像17,帧间预测单元244(编码器)和帧间预测单元344(解码器)可能不可用。视频编码器20和视频解码器30的所有其它功能(也称为工具或技术)同样可用于静态图像处理,例如残差计算204/304、变换206、量化208、反量化210/310、(逆)变换212/312、分割262/362、帧内预测254/354和/或环路滤波220/320、熵编码270和熵解码304。
图4为本申请实施例的视频译码设备400的示例性框图。视频译码设备400适用于实现本文描述的公开实施例。在一个实施例中,视频译码设备400可以是解码器,例如图1a中的视频解码器30,也可以是编码器,例如图1a中的视频编码器20。
视频译码设备400包括:用于接收数据的入端口410(或输入端口410)和接收单元(receiver unit,Rx)420;用于处理数据的处理器、逻辑单元或中央处理器(central processing unit,CPU)430;例如,这里的处理器430可以是神经网络处理器430;用于传输数据的发送单元(transmitter unit,Tx)440和出端口450(或输出端口450);用于存储数据的存储器460。视频译码设备400还可包括耦合到入端口410、接收单元420、发送单元440和出端口450的光电(optical-to-electrical,OE)组件和电光(electrical-to-optical,EO)组件,用于光信号或电信号的出口或入口。
处理器430通过硬件和软件实现。处理器430可实现为一个或多个处理器芯片、核(例如,多核处理器)、FPGA、ASIC和DSP。处理器430与入端口410、接收单元420、发送单元440、出端口450和存储器460通信。处理器430包括译码模块470(例如,基于神经网络的译码模块470)。译码模块470实施上文所公开的实施例。例如,译码模块470执行、处理、准备或提供各种编码操作。因此,通过译码模块470为视频译码设备400的功能提供了实质性的改进,并且影响了视频译码设备400到不同状态的切换。或者,以存储在存储器460中并由处理器430执行的指令来实现译码模块470。
存储器460包括一个或多个磁盘、磁带机和固态硬盘,可以用作溢出数据存储设备,用于在选择执行程序时存储此类程序,并且存储在程序执行过程中读取的指令和数据。存储器460可以是易失性和/或非易失性的,可以是只读存储器(read-only memory,ROM)、随机存取存储器(random access memory,RAM)、三态内容寻址存储器(ternary content-addressable memory,TCAM)和/或静态随机存取存储器(static random-access memory,SRAM)。
图5为本申请实施例的装置500的示例性框图,装置500可用作图1a中的源设备12和目的设备14中的任一个或两个。
装置500中的处理器502可以是中央处理器。或者,处理器502可以是现有的或今后将研发出的能够操控或处理信息的任何其它类型设备或多个设备。虽然可以使用如图所示的处理器502等单个处理器来实施已公开的实现方式,但使用一个以上的处理器速度更快和效率更高。
在一种实现方式中,装置500中的存储器504可以是只读存储器(ROM)设备或随机存取存储器(RAM)设备。任何其它合适类型的存储设备都可以用作存储器504。存储器504可以包括处理器502通过总线512访问的代码和数据506。存储器504还可包括操作系统508和应用程序510,应用程序510包括允许处理器502执行本文所述方法的至少一个程序。例如,应用程序510可以包括应用1至N,还包括执行本文所述方法的视频译码应用。
装置500还可以包括一个或多个输出设备,例如显示器518。在一个示例中,显示器518可以是将显示器与可用于感测触摸输入的触敏元件组合的触敏显示器。显示器518可以通过总线512耦合到处理器502。
虽然装置500中的总线512在本文中描述为单个总线,但是总线512可以包括多个总线。此外,辅助储存器可以直接耦合到装置500的其它组件或通过网络访问,并且可以包括存储卡等单个集成单元或多个存储卡等多个单元。因此,装置500可以具有各种各样的配置。
由于本申请实施例涉及神经网络的应用,为了便于理解,下面先对本申请实施例所使用到的一些名词或术语进行解释说明,该名词或术语也作为发明内容的一部分。
(1)神经网络
神经网络(neural network,NN)是机器学习模型,神经网络可以是由神经单元组成的,神经单元可以是指以xs和截距1为输入的运算单元,该运算单元的输出可以为:
其中,s=1、2、……n,n为大于1的自然数,Ws为xs的权重,b为神经单元的偏置。f为神经单元的激活函数(activation functions),用于将非线性特性引入神经网络中,来将神经单元中的输入信号转换为输出信号。该激活函数的输出信号可以作为下一层卷积层的输入。激活函数可以是sigmoid函数。神经网络是将许多个上述单一的神经单元联结在一起形成的网络,即一个神经单元的输出可以是另一个神经单元的输入。每个神经单元的输入可以与前一层的局部接受域相连,来提取局部接受域的特征,局部接受域可以是由若干个神经单元组成的区域。
(2)深度神经网络
深度神经网络(deep neural network,DNN),也称多层神经网络,可以理解为具有很多层隐含层的神经网络,这里的“很多”并没有特别的度量标准。从DNN按不同层的位置划分,DNN内部的神经网络可以分为三类:输入层,隐含层,输出层。一般来说第一层是输入层,最后一层是输出层,中间的层数都是隐含层。层与层之间是全连接的,也就是说,第i层的任意一个神经元一定与第i 1层的任意一个神经元相连。虽然DNN看起来很复杂,但是就每一层的工作来说,其实并不复杂,简单来说就是如下线性关系表达式:其中,是输入向量,是输出向量,是偏移向量,W是权重矩阵(也称系数),α()是激活函数。每一层仅仅是对输入向量经过如此简单的操作得到输出向量由于DNN层数多,则系数W和偏移向量的数量也就很多了。这些参数在DNN中的定义如下所述:以系数W为例:假设在一个三层的DNN中,第二层的第4个神经元到第三层的第2个神经元的线性系数定义为上标3代表系数W所在的层数,而下标对应的是输出的第三层索引2和输入的第二层索引4。总结就是:第L-1层的第k个神经元到第L层的第j个神经元的系数定义为需要注意的是,输入层是没有W参数的。在深度神经网络中,更多的隐含层让网络更能够刻画现实世界中的复杂情形。理论上而言,参数越多的模型复杂度越高,“容量”也就越大,也就意味着它能完成更复杂的学习任务。训练深度神经网络的也就是学习权重矩阵的过程,其最终目的是得到训练好的深度神经网络的所有层的权重矩阵(由很多层的向量W形成的权重矩阵)。
(3)卷积神经网络
卷积神经网络(convolutional neuron network,CNN)是一种带有卷积结构的深度神经网络,是一种深度学习(deep learning)架构,深度学习架构是指通过机器学习的算法,在不同的抽象层级上进行多个层次的学习。作为一种深度学习架构,CNN是一种前馈(feed-forward)人工神经网络,该前馈人工神经网络中的各个神经元可以对输入其中的图像作出响应。卷积神经网络包含了一个由卷积层和池化层构成的特征抽取器。该特征抽取器可以看作是滤波器,卷积过程可以看作是使用一个可训练的滤波器与一个输入的图像或者卷积特征平面(feature map)做卷积。
卷积层是指卷积神经网络中对输入信号进行卷积处理的神经元层。卷积层可以包括很多个卷积算子,卷积算子也称为核,其在图像处理中的作用相当于一个从输入图像矩阵中提取特定信息的过滤器,卷积算子本质上可以是一个权重矩阵,这个权重矩阵通常被预先定义,在对图像进行卷积操作的过程中,权重矩阵通常在输入图像上沿着水平方向一个像素接着一个像素(或两个像素接着两个像素……这取决于步长stride的取值)的进行处理,从而完成从图像中提取特定特征的工作。该权重矩阵的大小应该与图像的大小相关,需要注意的是,权重矩阵的纵深维度(depth dimension)和输入图像的纵深维度是相同的,在进行卷积运算的过程中,权重矩阵会延伸到输入图像的整个深度。因此,和一个单一的权重矩阵进行卷积会产生一个单一纵深维度的卷积化输出,但是大多数情况下不使用单一权重矩阵,而是应用多个尺寸(行×列)相同的权重矩阵,即多个同型矩阵。每个权重矩阵的输出被堆叠起来形成卷积图像的纵深维度,这里的维度可以理解为由上面所述的“多个”来决定。不同的权重矩阵可以用来提取图像中不同的特征,例如一个权重矩阵用来提取图像边缘信息,另一个权重矩阵用来提取图像的特定颜色,又一个权重矩阵用来对图像中不需要的噪点进行模糊化等。该多个权重矩阵尺寸(行×列)相同,经过该多个尺寸相同的权重矩阵提取后的特征图的尺寸也相同,再将提取到的多个尺寸相同的特征图合并形成卷积运算的输出。这些权重矩阵中的权重值在实际应用中需要经过大量的训练得到,通过训练得到的权重值形成的各个权重矩阵可以用来从输入图像中提取信息,从而使得卷积神经网络进行正确的预测。当卷积神经网络有多个卷积层的时候,初始的卷积层往往提取较多的一般特征,该一般特征也可以称之为低级别的特征;随着卷积神经网络深度的加深,越往后的卷积层提取到的特征越来越复杂,比如高级别的语义之类的特征,语义越高的特征越适用于待解决的问题。
由于常常需要减少训练参数的数量,因此卷积层之后常常需要周期性的引入池化层,可以是一层卷积层后面跟一层池化层,也可以是多层卷积层后面接一层或多层池化层。在图像处理过程中,池化层的唯一目的就是减少图像的空间大小。池化层可以包括平均池化算子和/或最大池化算子,以用于对输入图像进行采样得到较小尺寸的图像。平均池化算子可以在特定范围内对图像中的像素值进行计算产生平均值作为平均池化的结果。最大池化算子可以在特定范围内取该范围内值最大的像素作为最大池化的结果。另外,就像卷积层中用权重矩阵的大小应该与图像尺寸相关一样,池化层中的运算符也应该与图像的大小相关。通过池化层处理后输出的图像尺寸可以小于输入池化层的图像的尺寸,池化层输出的图像中每个像素点表示输入池化层的图像的对应子区域的平均值或最大值。
在经过卷积层/池化层的处理后,卷积神经网络还不足以输出所需要的输出信息。因为如前所述,卷积层/池化层只会提取特征,并减少输入图像带来的参数。然而为了生成最终的输出信息(所需要的类信息或其他相关信息),卷积神经网络需要利用神经网络层来生成一个或者一组所需要的类的数量的输出。因此,在神经网络层中可以包括多层隐含层,该多层隐含层中所包含的参数可以根据具体的任务类型的相关训练数据进行预先训练得到,例如该任务类型可以包括图像识别,图像分类,图像超分辨率重建等等。
可选的,在神经网络层中的多层隐含层之后,还包括整个卷积神经网络的输出层,该输出层具有类似分类交叉熵的损失函数,具体用于计算预测误差,一旦整个卷积神经网络的前向传播完成,反向传播就会开始更新前面提到的各层的权重值以及偏差,以减少卷积神经网络的损失,及卷积神经网络通过输出层输出的结果和理想结果之间的误差。
(4)循环神经网络
循环神经网络(recurrent neural networks,RNN)是用来处理序列数据的。在传统的神经网络模型中,是从输入层到隐含层再到输出层,层与层之间是全连接的,而对于每一层层内之间的各个节点是无连接的。这种普通的神经网络虽然解决了很多难题,但是却仍然对很多问题却无能无力。例如,你要预测句子的下一个单词是什么,一般需要用到前面的单词,因为一个句子中前后单词并不是独立的。RNN之所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐含层本层之间的节点不再无连接而是有连接的,并且隐含层的输入不仅包括输入层的输出还包括上一时刻隐含层的输出。理论上,RNN能够对任何长度的序列数据进行处理。对于RNN的训练和对传统的CNN或DNN的训练一样。同样使用误差反向传播算法,不过有一点区别:即,如果将RNN进行网络展开,那么其中的参数,如W,是共享的;而如上举例上述的传统神经网络却不是这样。并且在使用梯度下降算法中,每一步的输出不仅依赖当前步的网络,还依赖前面若干步网络的状态。该学习算法称为基于时间的反向传播算法(Back propagation Through Time,BPTT)。
既然已经有了卷积神经网络,为什么还要循环神经网络?原因很简单,在卷积神经网络中,有一个前提假设是:元素之间是相互独立的,输入与输出也是独立的,比如猫和狗。但现实世界中,很多元素都是相互连接的,比如股票随时间的变化,再比如一个人说了:我喜欢旅游,其中最喜欢的地方是云南,以后有机会一定要去。这里填空,人类应该都知道是填“云南”。因为人类会根据上下文的内容进行推断,但如何让机器做到这一步?RNN就应运而生了。RNN旨在让机器像人一样拥有记忆的能力。因此,RNN的输出就需要依赖当前的输入信息和历史的记忆信息。
(5)损失函数
在训练深度神经网络的过程中,因为希望深度神经网络的输出尽可能的接近真正想要预测的值,所以可以通过比较当前网络的预测值和真正想要的目标值,再根据两者之间的差异情况来更新每一层神经网络的权重向量(当然,在第一次更新之前通常会有初始化的过程,即为深度神经网络中的各层预先配置参数),比如,如果网络的预测值高了,就调整权重向量让它预测低一些,不断的调整,直到深度神经网络能够预测出真正想要的目标值或与真正想要的目标值非常接近的值。因此,就需要预先定义“如何比较预测值和目标值之间的差异”,这便是损失函数(loss function)或目标函数(objective function),它们是用于衡量预测值和目标值的差异的重要方程。其中,以损失函数举例,损失函数的输出值(loss)越高表示差异越大,那么深度神经网络的训练就变成了尽可能缩小这个loss的过程。
(6)反向传播算法
卷积神经网络可以采用误差反向传播(back propagation,BP)算法在训练过程中修正初始的超分辨率模型中参数的大小,使得超分辨率模型的重建误差损失越来越小。具体地,前向传递输入信号直至输出会产生误差损失,通过反向传播误差损失信息来更新初始的超分辨率模型中参数,从而使误差损失收敛。反向传播算法是以误差损失为主导的反向传播运动,旨在得到最优的超分辨率模型的参数,例如权重矩阵。
(7)生成式对抗网络
生成式对抗网络(generative adversarial networks,GAN)是一种深度学习模型。该模型中至少包括两个模块:一个模块是生成模型(Generative Model),另一个模块是判别模型(Discriminative Model),通过这两个模块互相博弈学习,从而产生更好的输出。生成模型和判别模型都可以是神经网络,具体可以是深度神经网络,或者卷积神经网络。GAN的基本原理如下:以生成图片的GAN为例,假设有两个网络,G(Generator)和D(Discriminator),其中G是一个生成图片的网络,它接收一个随机的噪声z,通过这个噪声生成图片,记做G(z);D是一个判别网络,用于判别一张图片是不是“真实的”。它的输入参数是x,x代表一张图片,输出D(x)代表x为真实图片的概率,如果为1,就代表100%是真实的图片,如果为0,就代表不可能是真实的图片。在对该生成式对抗网络进行训练的过程中,生成网络G的目标就是尽可能生成真实的图片去欺骗判别网络D,而判别网络D的目标就是尽量把G生成的图片和真实的图片区分开来。这样,G和D就构成了一个动态的“博弈”过程,也即“生成式对抗网络”中的“对抗”。最后博弈的结果,在理想的状态下,G可以生成足以“以假乱真”的图片G(z),而D难以判定G生成的图片究竟是不是真实的,即D(G(z))=0.5。这样就得到了一个优异的生成模型G,它可以用来生成图片。
下面将结合图6a-图6e详细地描述用于帧间预测的目标模型(亦称为神经网络)。图6a-图6e为本申请实施例的用于帧间预测的神经网络的几个示例性架构。
如图6a所示,该神经网络按照处理的先后顺序,依次包括:3×3卷积层(3×3Conv)、激活层(Relu)、块处理层(Res-Block)、…、块处理层、3×3卷积层、激活层和3×3卷积层。输入神经网络的原始矩阵经过上述层处理后得到的矩阵,再与原始矩阵相加得到最终的输出矩阵。
如图6b所示,该神经网络按照处理的先后顺序,依次包括:两路3×3卷积层和激活层,一路块处理层、…、块处理层、3×3卷积层、激活层和3×3卷积层。第一矩阵经过一路3×3卷积层和激活层,第二矩阵经过另一路3×3卷积层和激活层,处理后的两个矩阵合并(contact)后再经过块处理层、…、块处理层、3×3卷积层、激活层和3×3卷积层处理后得到的矩阵,再与第一矩阵相加得到最终的输出矩阵。
如图6c所示,该神经网络按照处理的先后顺序,依次包括:两路3×3卷积层和激活层,一路块处理层、…、块处理层、3×3卷积层、激活层和3×3卷积层。第一矩阵和第二矩阵在输入神经网络之前,先做相乘,然后将第一矩阵经过一路3×3卷积层和激活层,将相乘后的矩阵经过另一路3×3卷积层和激活层,处理后的两个矩阵相加后再经过块处理层、…、块处理层、3×3卷积层、激活层和3×3卷积层处理后得到的矩阵,再与第一矩阵相加得到最终的输出矩阵。
如图6d所示,上述块处理层按照处理的先后顺序,依次包括:3×3卷积层、激活层和3×3卷积层,将输入矩阵经这三层处理后,再将处理后得到的矩阵和初始输入矩阵相加得到输出矩阵。如图6c所示,上述块处理层按照处理的先后顺序,依次包括:3×3卷积层、激活层、3×3卷积层和激活层,将输入矩阵经3×3卷积层、激活层和3×3卷积层处理后,再将处理后得到的矩阵和初始输入矩阵相加后再经过一个激活层得到输出矩阵。
需要说明的是,如图6a-图6e仅示出了本申请实施例的用于帧间预测的神经网络的几种示例性的架构,其并不构成对神经网络架构的限定,该神经网络中包括的层数、层结构、相加、相乘或合并等处理,以及输入和/或输出的矩阵的数量、尺寸等均可以根据实际情况而定,本申请对此不做具体限定。
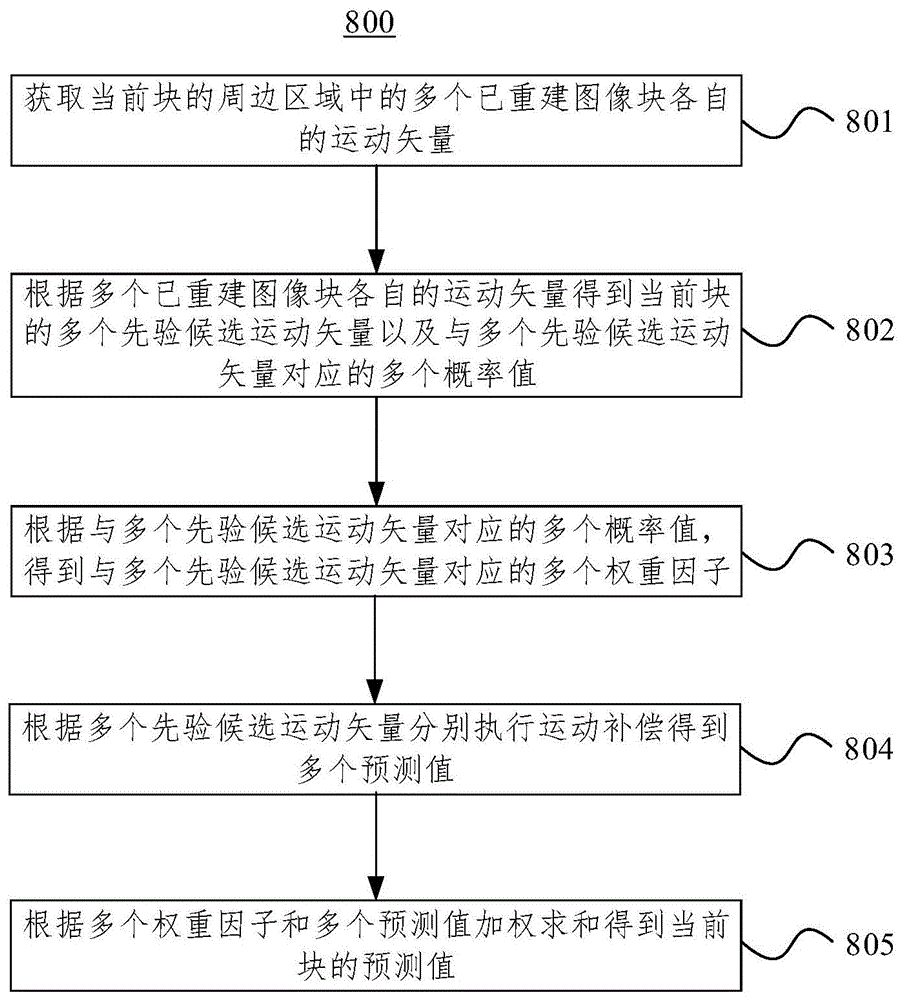
图8为本申请实施例的帧间预测方法的过程800的流程图。过程800可由视频编码器20或视频解码器30执行,具体的,可以由视频编码器20或视频解码器30的帧间预测单元244、344来执行。过程800描述为一系列的步骤或操作,应当理解的是,过程800可以以各种顺序执行和/或同时发生,不限于图8所示的执行顺序。假设具有多个图像帧的视频数据流正在使用视频编码器或者视频解码器,执行包括如下步骤的过程800来对图像或图像块进行帧间预测。过程800可以包括:
步骤801、获取当前块的周边区域中的多个已重建图像块各自的运动矢量。
当前块的周边区域包括当前块的空间邻域和/或时间邻域,其中空间邻域的图像块可以包括位于当前块左侧的左方候选图像块和位于当前块上方的上方候选图像块。示例性的,如图7所示,左方候选图像块的集合包括{A0,A1},上方候选图像块的集合包括{B0,B1,B2},时域相邻的候选图像块的集合包括{C,T}。已重建图像块可以是指编码端已经编码并获取其重建的编码图像块或者解码端已解码重构的解码图像块。已重建图像块也可以是指将编码图像块或解码图像块等大小划分而来的预设大小的基本单元图像块。例如,编码图像块或解码图像块的尺寸可以是16×16、64×64或32×16,基本单元图像块的尺寸可以是4×4或8×8。
以下以某个已重建图像块为例进行说明,该已重建图像块可以是周边区域中的多个已重建图像块中的任意一个,其他已重建图像块均可参照该方法。
已重建图像块的运动矢量可以包括:(1)已重建图像块的多个后验运动矢量,该多个后验运动矢量是根据已重建图像块的重建值和多个后验候选运动矢量对应的预测值确定的;或者,(2)已重建图像块的最优运动矢量,该最优运动矢量是上述多个后验运动矢量中概率值最大或预测误差值最小的后验运动矢量。
多个后验候选运动矢量是根据已重建图像块的多个先验候选运动矢量得到的,针对已重建图像块的多个先验候选运动矢量中的任意一个先验候选运动矢量,可以让其在一个预设的搜索窗口内进行偏移,生成多个偏移候选运动矢量。可见,已重建图像块的一个先验候选运动矢量可以得到多个偏移候选运动矢量。已重建图像块的多个先验候选运动矢量,均按上述操作,得到的所有偏移候选运动矢量即为已重建图想块的多个后验候选运动矢量。例如,图10为本申请实施例的搜索窗口的示例性的示意图,如图10所示,假设已重建图像块的某一个先验候选运动矢量为(0,0),将该先验候选运动矢量在一个3×3的搜索窗口内进行偏移,可以得到9个偏移候选运动矢量:(-1,-1)、(-1,0)、(-1,1)、(0,-1)、(0,0)、(0,1)、(1,-1)、(1,0)、(1,1)。该9个偏移候选运动矢量即为已重建图像块的多个后验候选运动矢量。
已重建图像块的多个后验运动矢量可以是指上述多个后验候选运动矢量;也可以是指上述多个后验候选运动矢量中的部分运动矢量,例如上述多个后验候选运动矢量中选出的多个指定的运动矢量。
多个后验运动矢量的概率值或者预测误差值可以参见下文描述。
在一种可能的实现方式中,除了获取已重建图像块的运动矢量外,还可以获取已重建图像块的相关信息,该相关信息及其获取方法如下所述:
一、已重建图像块的与多个后验运动矢量对应的多个预测误差值,多个预测误差值也是根据已重建图像块的重建值和多个后验候选运动矢量对应的预测值确定的。
根据多个后验候选运动矢量分别对已重建图像块执行运动补偿,可以得到多个预测值,该多个预测值和多个后验候选运动矢量对应。
将多个预测值分别与已重建图像块的重建值进行比较,得到多个预测误差值,该多个预测误差值和多个后验候选运动矢量对应。本申请可以采用绝对误差和(sum of absolute difference,SAD)或平方误差和(sum of squared difference,SSE)等方法获取对应于某一个后验候选运动矢量的预测误差值。
若已重建图像块的多个后验运动矢量是指上述多个后验候选运动矢量,则已重建图像块的与上述多个后验运动矢量对应的多个预测误差值是指对应于上述多个后验候选运动矢量的多个预测误差值;若已重建图像块的多个后验运动矢量是指上述多个后验候选运动矢量中的部分运动矢量,则已重建图像块的与上述多个后验运动矢量对应的多个预测误差值是指从对应于上述多个后验候选运动矢量的多个预测误差值中选出的与该部分运动矢量对应的预测误差值。
二、已重建图像块的与多个后验运动矢量对应的多个概率值,多个概率值也是根据已重建图像块的重建值和多个后验候选运动矢量对应的预测值确定的。
已重建图像块的与多个后验运动矢量对应的多个概率值可以有以下两种获取方法:
一种是根据第一种方法中得到的已重建图像块的多个预测误差值,得到已重建图像块的多个概率值。例如,可以使用归一化指数函数、线性归一化方法等方法对已重建图像块的多个预测误差值进行归一化处理,得到多个预测误差值的归一化值,该多个预测误差值的归一化值即为已重建图像块的多个概率值,基于已重建图像块的多个预测误差值与多个后验运动矢量的对应关系,已重建图像块的多个概率值也与已重建图像块的多个后验运动矢量对应,该概率值可以表示与之对应的后验运动矢量成为该已重建图像块的最优运动矢量的概率。
另一种是将已重建图像块的重建值和第一种方法中得到的已重建图像块的多个预测值,输入经训练的神经网络得到已重建图像块的与多个后验运动矢量对应的多个概率值。该神经网络可以参照上述训练引擎25的描述,此处不再赘述。
因此,在通过上述两种方法得到的与多个后验运动矢量对应的多个预测误差值或者概率值之后,已重建图像块的最优运动矢量可以有以下两种获取方法:
一种是将与多个后验运动矢量对应的多个预测误差值中的最小预测误差值对应的后验运动矢量作为已重建图像块的最优运动矢量。
另一种是将与多个后验运动矢量对应的多个概率值中的最大概率值对应的后验运动矢量作为已重建图像块的最优运动矢量。
本申请中,可以直接读取存储器获取已重建图像块的上述运动矢量及其相关信息。在对已重建图像块进行编码或解码之后,可以立即采用上述方法获取已重建图像块的运动矢量或者运动矢量及其相关信息,然后将其存储下来,在对后续的图像块(当前块)进行帧间预测时可以直接从存储器的相应位置读取即可。这样可以提高当前块的帧间预测效率。
本申请中,也可以在对当前块进行帧间预测时,才计算已重建图像块的运动矢量或者运动矢量及其相关信息,即在对当前块进行帧间预测时,采用上述方法获取已重建图像块的运动矢量或者运动矢量及其相关信息。这样在确定需要用到哪个已重建图像块,才去计算,可以节省存储空间。
如果上述多个已重建图像块在编码或解码过程中均采用帧间预测,则可以采用上述方法获取该多个已重建图像块的运动矢量或者运动矢量及其相关信息。如果多个已重建图像块中有部分图像块在编码或解码过程中没有采用帧间预测,也可以按照上述三种情况中描述的方法中的任意一种获取该部分图像块的运动矢量或者运动矢量及其相关信息。
如果已重建图像块包含多个基本单元图像块,则可以将该已重建图像块的运动矢量或者运动矢量及其相关信息作为其包含的所有基本单元图像块的运动矢量或者运动矢量及其相关信息。进一步的,可以细化到将该已重建图像块的运动矢量或者运动矢量及其相关信息作为其包含的所有像素的运动矢量或者运动矢量及其相关信息。
步骤802、根据多个已重建图像块各自的运动矢量得到当前块的多个先验候选运动矢量以及与多个先验候选运动矢量对应的多个概率值。
当前块的多个先验候选运动矢量可以是指多个已重建图像块各自的多个后验运动矢量去重后剩余的所有运动矢量,也可以是指多个已重建图像块各自的多个后验运动矢量去重后剩余的所有运动矢量中的部分运动矢量。
可以将多个已重建图像块各自的运动矢量输入经训练的神经网络得到当前块的多个先验候选运动矢量以及与多个先验候选运动矢量对应的多个概率值。该神经网络可以参照上述训练引擎25的描述,此处不再赘述。
可选的,可以将多个已重建图像块各自的多个后验运动矢量以及与多个后验运动矢量对应的多个预测误差值,输入经训练的神经网络得到当前块的多个先验候选运动矢量以及与多个先验候选运动矢量对应的多个概率值。
可选的,可以将多个已重建图像块各自的多个后验运动矢量以及与多个后验运动矢量对应的多个概率值,输入经训练的神经网络得到当前块的多个先验候选运动矢量以及与多个先验候选运动矢量对应的多个概率值。
可选的,可以将多个已重建图像块的最优运动矢量,输入经训练的神经网络得到当前块的多个先验候选运动矢量以及与多个先验候选运动矢量对应的多个概率值。
步骤803、根据与多个先验候选运动矢量对应的多个概率值,得到与多个先验候选运动矢量对应的多个权重因子。
当多个概率值之和为1时,将与第一先验候选运动矢量对应的概率值作为与第一先验候选运动矢量对应的权重因子。即多个先验候选运动矢量各自的权重因子,是多个先验候选运动矢量各自的概率值;或者,当多个概率值之和不为1时,对多个概率值进行归一化处理;将与第一先验候选运动矢量对应的概率值的归一化值作为与第一先验候选运动矢量对应的权重因子。即多个先验候选运动矢量各自的权重因子,是多个先验候选运动矢量各自的概率值的归一化值。上述第一先验候选运动矢量是多个先验候选运动矢量中的任意一个。可见,与多个先验候选运动矢量对应的多个权重因子之和为1。
步骤804、根据多个先验候选运动矢量分别执行运动补偿得到多个预测值。
根据帧间预测的原理,一个候选运动矢量可以在当前块的参考帧中找到一个参考块,根据该参考块对当前块进行帧间预测得到对应于该候选运动矢量的预测值,可见当前块的预测值对应于候选运动矢量。因此根据多个先验候选运动矢量分别执行运动补偿,可以得到当前块的多个预测值。
步骤805、根据多个权重因子和多个预测值加权求和得到当前块的预测值。
将对应于同一个先验候选运动矢量的权重因子和预测值相乘,再将对应于多个先验候选运动矢量的多个乘积相加得到当前块的预测值。
本申请通过基于当前块的周边区域中的多个已重建图像块各自的运动矢量得到当前块的多个权重因子和多个预测值,将对应于同一个先验候选运动矢量的权重因子和预测值相乘,再将对应于多个先验候选运动矢量的多个乘积相加得到当前块的预测值,这样得到的当前块的预测值是结合了多个先验候选运动矢量,从而能够更好的拟合现实世界中丰富多变的纹理,提升帧间预测的准确度,减小帧间预测的误差,改善帧间预测的整体率失真(rate-distortion optimization,RDO)效率。
在一种可能的实现方式中,在获取当前块的重建值后,可以立即获取当前块的运动矢量及其相关信息,该运动矢量及其相关信息可以参考步骤801,其获取方法包括:
一、根据当前块的重建值和当前块的多个后验候选运动矢量对应的预测值得到当前块的多个后验运动矢量以及与多个后验运动矢量对应的多个预测误差值,当前块的多个后验运动矢量是根据当前块的多个先验候选运动矢量得到的。
二、根据当前块的重建值和当前块的多个后验候选运动矢量对应的预测值输入神经网络,得到当前块的多个后验运动矢量以及与多个后验运动矢量对应的多个概率值,当前块的多个后验运动矢量是根据当前块的多个先验候选运动矢量得到的,或者,根据当前块的多个预测误差值得到当前块的多个后验运动矢量对应的多个概率值。
三、将当前块的多个后验运动矢量中概率值最大或预测误差值最小的后验运动矢量确定为当前块的最优运动矢量。
在一种可能的实现方式中,当前块的多个概率值包括M个概率值,该M个概率值均大于当前块的多个概率值中除M个概率值外的其他概率值。因此可以从当前块的多个先验候选运动矢量中选取与M个概率值对应的M个先验候选运动矢量,然后根据M个概率值获取M个权重因子,根据M个先验候选运动矢量分别执行运动补偿得到当前块的M个预测值,最后根据M个权重因子和M个预测值加权求和得到当前块的预测值。即从当前块的与多个先验候选运动矢量对应的多个概率值中选取概率值最大的前M个概率值,并从当前块的多个先验候选运动矢量中选取与M个概率值对应的M个先验候选运动矢量,基于M个概率值和M个先验候选运动矢量进行权重因子和预测值的计算,进而得到当前块的预测值。而与多个先验候选运动矢量对应的多个概率值中除前述M个概率值外的其余概率值,由于值较小可以忽略,这样可以减少计算量,提高帧间预测的效率。
下面采用几个具体的实施例,对图8所示方法实施例的技术方案进行详细说明。
实施例一
本实施例中,根据周边区域中的多个已重建图像块各自的多个后验运动矢量以及与多个后验运动矢量对应的多个预测误差值,确定当前块的多个先验候选运动矢量以及与多个先验候选运动矢量对应的多个概率值。
图9为本申请实施例的帧间预测方法的过程900的流程图。过程900可由视频编码器20或视频解码器30执行,具体的,可以由视频编码器20或视频解码器30的帧间预测单元244、344来执行。过程900描述为一系列的步骤或操作,应当理解的是,过程900可以以各种顺序执行和/或同时发生,不限于图9所示的执行顺序。假设具有多个图像帧的视频数据流正在使用视频编码器或者视频解码器,执行包括如下步骤的过程900来对图像或图像块进行帧间预测。过程900可以包括:
步骤901、获取周边区域中的多个已重建图像块各自的多个后验运动矢量以及与多个后验运动矢量对应的多个预测误差值。
以下以某个已重建图像块为例进行说明,该已重建图像块可以是周边区域中的多个已重建图像块中的任意一个,其他已重建图像块均可参照该方法获取多个后验运动矢量以及与多个后验运动矢量对应的多个预测误差值。
已重建图像块的有N4个后验候选运动矢量,该N4个后验候选运动矢量是根据已重建图像块的多个先验候选运动矢量得到的,该获取方法可以参照上述步骤801的描述。根据该N4个后验候选运动矢量分别执行运动补偿,可以得到已重建图像块的N4个预测值,该N4个预测值和N4个后验候选运动矢量对应,即根据一个后验候选运动矢量对应的参考块对已重建图像块进行帧间预测,可以得到已重建图像块的一个预测值。将N4个预测值分别与已重建图像块的重建值进行比较,得到已重建图像块的N4个预测误差值,该N4个预测误差值和N4个后验候选运动矢量对应。本申请可以采用SAD或SSE等方法获取已重建图像块对应于某一个后验候选运动矢量的预测误差值。
已重建图像块的N2个后验运动矢量可以是指上述N4个后验候选运动矢量;也可以是指上述N4个后验候选运动矢量中的部分运动矢量,例如上述N4个后验候选运动矢量中选出的多个指定的运动矢量。
相应的,已重建图像块的与N2个后验运动矢量对应的预测误差值的个数也是N2。
多个已重建图像块的全部后验运动矢量可以表示为一个N2×Q的二维矩阵,N2为后验运动矢量的个数,Q为已重建图像块的个数,其中的元素表示为k=0、1、…、Q-1,表示已重建图像块的索引,n=0、1、…、N2-1,表示后验运动矢量的索引,其含义为k指示的已重建图像块的n指示的后验运动矢量。
多个已重建图像块的全部预测误差值也可以表示为一个N2×Q的二维矩阵,其中的元素表示为k=0、1、…、Q-1,表示已重建图像块的索引,n=0、1、…、N2-1,表示后验运动矢量的索引,其含义为k指示的已重建图像块的n指示的后验运动矢量对应的预测误差值。
步骤902、根据多个已重建图像块各自的多个后验运动矢量以及与多个后验运动矢量对应的多个预测误差值,得到当前块的多个先验候选运动矢量以及与多个先验候选运动矢量对应的多个预测误差值。
本申请可以将多个已重建图像块的全部预测误差值和全部后验运动矢量,即上述两个N2×Q的二维矩阵输入经训练的神经网络,由该神经网络输出当前块的多个先验候选运动矢量以及与多个先验候选运动矢量对应的多个预测误差值。该神经网络可以参照上述训练引擎25的描述,此处不再赘述。
当前块的多个先验候选运动矢量可以表示为一个N1×S的二维矩阵,N1为当前块的先验候选运动矢量的个数,S为当前块包含的基本单元图像块或像素的个数,若当前块没有被进一步划分,则S=1。矩阵中的元素表示为l=0、1、…、S-1,表示基本单元图像块或像素的索引,n=0、1、…、N1-1,表示先验候选运动矢量的索引,其含义为l指示的基本单元图像块或像素的n指示的先验候选运动矢量。
当前块的与多个先验候选运动矢量对应的多个预测误差值也可以表示为一个N1×S的二维矩阵。矩阵中的元素表示为l=0、1、…、S-1,表示基本单元图像块或像素的索引,n=0、1、…、N1-1,表示先验候选运动矢量的索引,其含义为l指示的基本单元图像块或像素的n指示的先验候选运动矢量成为该基本单元图像块或像素的最优运动矢量的概率。
可选的,在l不变的情况下,即l指示的基本单元图像块或像素的与N1个先验候选运动矢量对应的N1个概率值之和为1。或者,也可以将使用整型化的方式表达,可以得到256与的整数值的二进制比特数相关,其表示的整数值采用8比特表示,因此也可以等于128或512等。
步骤903、根据当前块的与多个先验候选运动矢量对应的多个预测误差值,得到与多个先验候选运动矢量对应的多个权重因子。
当前块的与多个先验候选运动矢量对应的多个权重因子也可以表示为一个N1×S的二维矩阵。矩阵中的元素表示为l=0、1、…、S-1,表示基本单元图像块或像素的索引,n=0、1、…、N1-1,表示先验候选运动矢量的索引,其含义为l指示的基本单元图像块或像素的n指示的先验候选运动矢量的权重因子。
若当前块中l指示的基本单元图像块或像素的与N1个先验候选运动矢量对应的N1个概率值进行了归一化处理,即则可以将该N1个概率值作为与N1个先验候选运动矢量对应的N1个权重因子,例如若当前块中l指示的基本单元图像块或像素的与N1个先验候选运动矢量对应的N1个概率值没有进行归一化处理,则可以先对该N1个概率值进行归一化处理,然后将该N1个概率值的归一化值作为与N1个先验候选运动矢量对应的N1个权重因子。因此,在l不变的情况下,
步骤904、根据多个先验候选运动矢量分别执行运动补偿得到多个预测值。
以某一个先验候选运动矢量为例进行说明,该先验候选运动矢量是多个先验候选运动矢量中的任意一个,其他先验候选运动矢量均可参照该方法。
按照先验候选运动矢量执行运动补偿得到当前块的一个预测值,因此N1个先验候选运动矢量可以得到N1个预测值。
当前块的多个预测值可以表示为一个BH×WH×S的三维矩阵,BH×WH表示当前块包含的基本单元图像块的尺寸,S为当前块包含的基本单元图像块或像素的个数,若当前块没有被进一步划分,则S=1。矩阵中的元素表示为l=0、1、…、S-1,表示基本单元图像块或像素的索引,n=0、1、…、N1-1,表示先验候选运动矢量的索引,其含义为l指示的基本单元图像块中的第i行、第j列的像素,n指示的先验候选运动矢量对应的预测值。
步骤905、根据多个权重因子和多个预测值加权求和得到当前块的预测值。
将对应于同一个先验候选运动矢量的权重因子和预测值相乘,再将对应于多个先验候选运动矢量的多个乘积相加得到当前块的预测值。当前块中,l指示的基本单元图像块中的第i行、第j列的像素的预测值可以表示为:
实施例二
本实施例中,根据周边区域中的多个已重建图像块各自的多个后验运动矢量以及与多个后验运动矢量对应的多个概率值,确定当前块的多个先验候选运动矢量以及与多个先验候选运动矢量对应的多个概率值。
图11为本申请实施例的帧间预测方法的过程1100的流程图。过程1100可由视频编码器20或视频解码器30执行,具体的,可以由视频编码器20或视频解码器30的帧间预测单元244、344来执行。过程1100描述为一系列的步骤或操作,应当理解的是,过程1100可以以各种顺序执行和/或同时发生,不限于图11所示的执行顺序。假设具有多个图像帧的视频数据流正在使用视频编码器或者视频解码器,执行包括如下步骤的过程1100来对图像或图像块进行帧间预测。过程1100可以包括:
步骤1101、获取周边区域中的多个已重建图像块各自的多个后验运动矢量以及与多个后验运动矢量对应的多个概率值。
本实施例的步骤1101与上述实施例一的步骤901不同,区别在于:与多个后验运动矢量对应的多个预测误差值变为与多个后验运动矢量对应的多个概率值。
以下以某个已重建图像块为例进行说明,该已重建图像块可以是周边区域中的多个已重建图像块中的任意一个,其他已重建图像块均可参照该方法获取多个后验运动矢量以及与多个后验运动矢量对应的多个概率值。
已重建图像块的N2个后验运动矢量可以参照上述步骤901中的方法获取,此处不再赘述。
已重建图像块的与N2个后验运动矢量对应的N2个概率值可以有以下两种获取方法:
一种是根据实施例一获取到的已重建图像块的N2个预测误差值获取已重建图像块的N2个概率值。
已重建图像块的N2个预测误差值对应多个已重建图像块的全部预测误差值中的一个N2维向量,其中的元素表示为k1为已重建图像块的索引,n=0、1、…、N2-1,表示后验运动矢量的索引,可以根据已重建图像块的N2个预测误差值计算得到已重建图像块的N2个概率值。已重建图像块的N2个概率值也可以表示为一个N2维向量,其中的元素表示为k1为已重建图像块的索引,n=0、1、…、N2-1,表示后验运动矢量的索引,其含义为k1指示的已重建图像块的n指示的后验运动矢量成为该已重建图像块的最优运动矢量的概率。
可选的,可以使用下述归一化指数函数将转换为
又例如,可以使用线性归一化方法将转换为
因此,在k不变的情况下,
另一种是将已重建图像块的重建值和与N2个后验运动矢量对应的N2个预测值输入经训练的神经网络得到已重建图像块的与N2个后验运动矢量对应的N2个概率值。该神经网络可以参照上述训练引擎25的描述,此处不再赘述。
已重建图像块的重建值可以在对已重建图像块的编码之后获取,已重建图像块的与N2个后验运动矢量对应的N2个预测值可以参照上述步骤901中的方法获取,此处不再赘述。
多个已重建图像块的全部后验运动矢量可以表示为一个N2×Q的二维矩阵,N2为后验运动矢量的个数,Q为已重建图像块的个数,其中的元素表示为k=0、1、…、Q-1,表示已重建图像块的索引,n=0、1、…、N2-1,表示后验运动矢量的索引,其含义为k指示的已重建图像块的n指示的后验运动矢量。
多个已重建图像块的全部概率值也可以表示为一个N2×Q的二维矩阵,其中的元素表示为k=0、1、…、Q-1,表示已重建图像块的索引,n=0、1、…、N2-1,表示后验运动矢量的索引,其含义为k指示的已重建图像块的n指示的后验运动矢量成为该已重建图像块的最优运动矢量的概率。
步骤1102、根据多个已重建图像块各自的多个后验运动矢量以及与多个后验运动矢量对应的多个概率值,得到当前块的多个先验候选运动矢量以及与多个先验候选运动矢量对应的多个概率值。
本实施例的步骤1102与上述实施例一的步骤902不同,区别在于:输入神经网络的与多个后验运动矢量对应的多个预测误差值变为与多个后验运动矢量对应的多个概率值。
步骤1103、根据当前块的与多个先验候选运动矢量对应的多个概率值,得到与多个先验候选运动矢量对应的多个权重因子。
步骤1104、根据多个先验候选运动矢量分别执行运动补偿得到多个预测值。
步骤1105、根据多个权重因子和多个预测值加权求和得到当前块的预测值。
本实施例的步骤1103-1105可参照实施例一的步骤903-905,此处不再赘述。
实施例三
本实施例中,根据周边区域中的多个已重建图像块各自的最优运动矢量,确定当前块的多个先验候选运动矢量以及与多个先验候选运动矢量对应的多个概率值。
图12为本申请实施例的帧间预测方法的过程1200的流程图。过程1200可由视频编码器20或视频解码器30执行,具体的,可以由视频编码器20或视频解码器30的帧间预测单元244、344来执行。过程1200描述为一系列的步骤或操作,应当理解的是,过程1200可以以各种顺序执行和/或同时发生,不限于图12所示的执行顺序。假设具有多个图像帧的视频数据流正在使用视频编码器或者视频解码器,执行包括如下步骤的过程1200来对图像或图像块进行帧间预测。过程1200可以包括:
步骤1201、获取周边区域中的多个已重建图像块各自的最优运动矢量。
本实施例的步骤1201与上述实施例一的步骤901不同,区别在于:多个后验运动矢量以及与多个后验运动矢量对应的多个预测误差值变为最优运动矢量。
以下以某个已重建图像块为例进行说明,该已重建图像块可以是周边区域中的多个已重建图像块中的任意一个,其他已重建图像块均可参照该方法获取最优运动矢量。
已重建图像块的最优运动矢量可以有以下两种获取方法:
一种是根据实施例一获取到的已重建图像块的N2个预测误差值获取已重建图像块的最优运动矢量,即将已重建图像块的N2个预测误差值中的最小预测误差值对应的后验运动矢量作为已重建图像块的最优运动矢量。
另一种是根据实施例二获取到的已重建图像块的N2个概率值获取已重建图像块的最优运动矢量,即将已重建图像块的N2个概率值中的最大概率值对应的后验运动矢量作为已重建图像块的最优运动矢量。
步骤1202、根据多个已重建图像块各自的最优运动矢量,得到当前块的多个先验候选运动矢量以及与多个先验候选运动矢量对应的多个概率值。
本实施例的步骤1202与上述实施例一的步骤902不同,区别在于:输入神经网络的多个后验运动矢量以及与多个后验运动矢量对应的多个预测误差值变为多个已重建图像块的最优运动矢量。
步骤1203、根据当前块的与多个先验候选运动矢量对应的多个概率值,得到与多个先验候选运动矢量对应的多个权重因子。
步骤1204、根据多个先验候选运动矢量分别执行运动补偿得到多个预测值。
步骤1205、根据多个权重因子和多个预测值加权求和得到当前块的预测值。
本实施例的步骤1203-1205可参照实施例一的步骤903-905,此处不再赘述。
图13为本申请实施例的帧间预测装置1300的结构示意图。该帧间预测装置1300包括:运动估计单元1301和帧间预测处理单元1302,其中,运动估计单元1301用于获取当前块的周边区域中的P个已重建图像块各自的运动矢量,所述周边区域包括所述当前块的空间邻域和/或时间邻域;帧间预测处理单元1302用于根据所述P个已重建图像块各自的运动矢量得到所述当前块的Q个先验候选运动矢量以及与所述Q个先验候选运动矢量对应的Q个概率值;根据与M个先验候选运动矢量对应的M个概率值,得到与所述M个先验候选运动矢量对应的M个权重因子;M、P和Q为正整数,M小于或等于Q;根据所述M个先验候选运动矢量分别执行运动补偿得到M个预测值;根据所述M个预测值和对应的所述M个权重因子加权求和得到所述当前块的预测值。在一种示例下,包括运动估计单元1301和帧间预测处理单元1302的帧间预测装置1300可以对应于图2中的帧间预测单元244,或者对应于图3中的帧间预测单元344。
在实现过程中,上述方法实施例的各步骤可以通过处理器中的硬件的集成逻辑电路或者软件形式的指令完成。处理器可以是通用处理器、数字信号处理器(digital signal processor,DSP)、特定应用集成电路(application-specific integrated circuit,ASIC)、现场可编程门阵列(field programmable gate array,FPGA)或其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。本申请实施例公开的方法的步骤可以直接体现为硬件编码处理器执行完成,或者用编码处理器中的硬件及软件模块组合执行完成。软件模块可以位于随机存储器,闪存、只读存储器,可编程只读存储器或者电可擦写可编程存储器、寄存器等本领域成熟的存储介质中。该存储介质位于存储器,处理器读取存储器中的信息,结合其硬件完成上述方法的步骤。
上述各实施例中提及的存储器可以是易失性存储器或非易失性存储器,或可包括易失性和非易失性存储器两者。其中,非易失性存储器可以是只读存储器(read-only memory,ROM)、可编程只读存储器(programmable ROM,PROM)、可擦除可编程只读存储器(erasable PROM,EPROM)、电可擦除可编程只读存储器(electrically EPROM,EEPROM)或闪存。易失性存储器可以是随机存取存储器(random access memory,RAM),其用作外部高速缓存。通过示例性但不是限制性说明,许多形式的RAM可用,例如静态随机存取存储器(static RAM,SRAM)、动态随机存取存储器(dynamic RAM,DRAM)、同步动态随机存取存储器(synchronous DRAM,SDRAM)、双倍数据速率同步动态随机存取存储器(double data rate SDRAM,DDR SDRAM)、增强型同步动态随机存取存储器(enhanced SDRAM,ESDRAM)、同步连接动态随机存取存储器(synchlink DRAM,SLDRAM)和直接内存总线随机存取存储器(direct rambus RAM,DR RAM)。应注意,本文描述的系统和方法的存储器旨在包括但不限于这些和任意其它适合类型的存储器。
本领域普通技术人员可以意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、或者计算机软件和电子硬件的结合来实现。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本申请的范围。
所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的系统、装置和单元的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
在本申请所提供的几个实施例中,应该理解到,所揭露的系统、装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
另外,在本申请各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。
所述功能如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(个人计算机,服务器,或者网络设备等)执行本申请各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、只读存储器(read-only memory,ROM)、随机存取存储器(random access memory,RAM)、磁碟或者光盘等各种可以存储程序代码的介质。
以上所述,仅为本申请的具体实施方式,但本申请的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应以所述权利要求的保护范围为准。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。