1.本发明涉及个性化需求预测技术领域,具体涉及一种面向科技服务平台的企业画像与科技服务个性化需求预测方法。
背景技术:
2.科技服务平台是为企业提供科技服务的综合信息平台,承担着企业科技服务需求与供给匹配的纽带作用。近年来,随着科技企业对科技服务需求的快速提升,科技服务平台迎来了众多机遇和挑战。一方面,不同企业的规模、创新能力、行为偏好各不相同,科技服务需求呈个性化趋势发展;另一方面,现有科技服务平台大多采用被动式等待企业在站内寻找服务,缺乏主动推送科技服务的相关技术。
3.在此背景下,研究企业创新能力、行为偏好等特征画像,预测企业个性化科技服务需求,对科技服务平台提高科技服务需求与供给匹配精度,推动科技企业创新发展具有重要意义。
4.近年来,随着人工智能与机器学习技术的快速发展,研究者对基于机器学习技术的企业画像与个性化需求预测方法进行了深入的研究,提出了许多针对不同领域的画像模型和服务需求预测方法。
5.例如,田娟等(2018)提出了一种基于大数据平台的企业画像构建框架,分析了常用的企业画像生成模型及基于大数据的企业画像设计方法,总结了企业画像技术在企业营销、政府税收管理系统、股票证券交易系统及企业招聘系统等领域的应用;刘志中等(2015)提出了一种基于矩阵分析与深度学习的服务需求预测方法,该方法通过对用户历史使用数据进行矩阵分析得到用户特征矩阵与服务特征矩阵,将两种矩阵分别作为深度神经网络的输出与输入构建神经网络预测模型,实现用户服务需求预测,并在此基础上给出了主动服务及服务推荐策略。
6.尽管研究者提出了一些企业画像与服务需求预测方法,这些方法在企业科技服务领域尚未进行深入研究和应用。一方面,现有企业画像方法未考虑企业在创新能力、行为偏好、平台活跃度等方面的差异,无法对企业寻求科技服务过程中所表现出的特征进行准确描述;另一方面,现有服务需求预测方法的总体思路是通过大量用户历史数据构建和训练预测模型,但在企业科技服务背景下,不同行业的企业服务需求通常表现出很强的差异性,需要分别建立预测模型,一些行业通常存在企业数据难以获取、历史样本数量不足的情况,这对构建预测模型造成了很大困难。
7.因此当前方法在科技服务需求预测的实际应用中面临预测准确度偏低的问题。
技术实现要素:
8.针对现有方法在本领域存在的不足,本发明提供了一种面向科技服务平台的企业画像与科技服务个性化需求预测方法。该方法通过数据挖掘方法提取企业在创新投入、创
新产出、行为偏好与平台活跃度等方面的特征标签,以此为基础构建企业画像,并利用企业的历史行为数据与科技服务需求建立神经网络预测模型,结构迁移学习的方式克服不同企业的行业差异及历史样本不足的问题,实现企业科技服务准确预测。
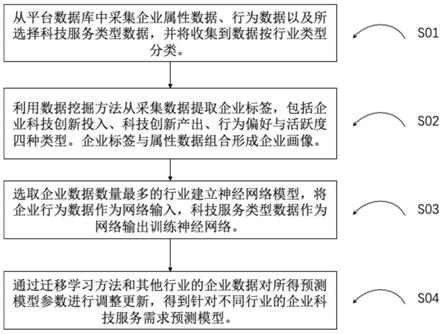
9.一种面向科技服务平台的企业画像与科技服务个性化需求预测方法,包括步骤:
10.(1)从平台数据库中采集企业属性数据、行为数据以及所选择科技服务类型数据,并将收集到数据按行业类型分类;
11.(2)利用数据挖掘方法从采集的数据提取企业标签,包括企业科技创新投入、科技创新产出、行为偏好与活跃度四种类型;企业画像为企业标签与企业属性数据组成的集合;
12.(3)选取企业数据数量最多的行业建立神经网络模型,将企业行为数据作为网络输入,科技服务类型数据作为网络输出训练神经网络,得到针对该行业的企业科技服务需求预测模型;
13.(4)通过迁移学习方法和其他行业的企业数据对所得预测模型参数进行调整更新,得到针对不同行业的企业科技服务需求预测模型。
14.步骤(1)中:
15.企业属性数据指标包括企业名称、省份、行业、企业规模与信用;
16.行为数据包括企业科技创新投资、专利、论著与标准数量、平台广告偏好及平台内点击次数、访问、浏览次数;
17.科技服务类型包括行业认证、管理咨询、科技活动和知识产权代理。
18.步骤(2)中,所述标签指描述企业参与科技服务活动的特征标识,具体包括企业科技创新投入、科技创新产出、行为偏好与活跃度四种类型。其中:
19.企业科技创新投入、科技创新产出与活跃度标签分为高中低三档,分别由企业科技创新投资、知识产权数量及企业对平台访问浏览次数描述;
20.行为偏好标签代表企业对平台内不同类型科技服务广告的偏好程度,由企业对不同类型广告的点击次数描述。
21.步骤(2)中,所述数据挖掘方法为k-means聚类方法。
22.以企业科技创新投入为例。该方法提取标签的具体过程为:
23.(2-1)从企业科技创新投资数据中随机抽取三个样本,作为聚类中心点,记为c1、c2、c3;
24.(2-2)计算剩余所有样本点到聚类中心c1、c2、c3的距离,根据距离大小将样本划分为三类,并计算每一类样本点均值,作为新的聚类中心;
25.(2-3)用新的聚类中心替代上一聚类中心,重复步骤(2-2),直至新聚类中心点位置变化小于事先设定点阈值;
26.(2-4)将样本划分的最终结果按聚类中心由高到低排列,分别对应高、中、低三种企业科技创新投入等级。
27.类似地,按照上述步骤,可根据企业知识产权数量与平台访问浏览次数数据得到企业科技创新产出与活跃度标签值。企业行为偏好标签由描述统计得到,即统计其对不同类型科技服务广告的点击次数,根据点击次数由高到低列出企业对不同服务类型的偏好。企业画像由企业属性数据与标签组成,即属性数据(企业名称、省份、行业与信用、企业规模和技术领域等)和标签(科技创新投入、科技创新产出、行为偏好与活跃度)组成的集合。
28.步骤(3)中,所述神经网络模型是一个前反馈神经网络,它由输入层、隐层与输出层三部分组成,神经网络将企业行为数据(科技创新投资、专利、论著与标准数量、平台广告偏好及访问次数等)作为输入,科技服务类型数据作为输出,具体计算过程为:
[0029][0030][0031]
β3=φ(θ3β2)
[0032]
其中,θ1、θ2和θ3分别代表网络输入层、隐层与输出层的参数,和φ(
·
)代表非线性激活函数,其函数形式为和φ(
·
)=1/(1-e
x
)。
[0033]
步骤(4)中,迁移学习是一种机器学习方法,其目标是将某领域学习到的知识应用至相关但不同领域的问题中,以解决传统模型面对数据分布差异时存在的低准确率问题。在企业科技服务需求问题中,迁移学习方法首先将利用行业数据对神经网络模型进行预训练,然后利用训练后的神经网络和其他行业的数据进行需求预测并计算误差,最后根据预测误差与梯度下降算法训练后的模型参数进行调整,得到针对该行业的神经网络预测模型,具体计算过程为:
[0034][0035][0036][0037]
其中,α1、α2和α3分别代表网络参数θ1、θ2和θ3的更新结果,e代表神经网络对科技服务需求的预测误差,代表误差e关于网络参数θ1、θ2和θ3的梯度,ρ代表梯度下降的更新速率。
[0038]
本发明与现有技术相比,主要优点包括:
[0039]
本发明通过数据挖掘方法提取企业在创新投入、创新产出、行为偏好与平台活跃度等方面的特征标签,以此为基础构建企业画像,并利用企业的历史行为数据与科技服务需求建立神经网络预测模型,结构迁移学习的方式克服不同企业的行业差异及历史样本不足的问题,实现企业科技服务准确预测。
附图说明
[0040]
图1为本发明面向科技服务平台的企业画像与科技服务个性化需求预测方法流程图;
[0041]
图2为企业科技服务画像结构图;
[0042]
图3为实施例企业科技服务预测结果统计图;
[0043]
图4为本发明提出方法与对比例传统神经网络方法预测结果对比图。
具体实施方式
[0044]
下面结合附图及具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。
[0045]
如图1所示,本发明提出的面向科技服务平台的企业画像与科技服务个性化需求
预测方法的流程包括步骤:
[0046]
s01,从平台数据库中采集企业属性数据、行为数据以及所选择科技服务类型数据,并将收集到数据按行业类型分类。
[0047]
s02,利用数据挖掘方法从采集数据提取企业标签,包括企业科技创新投入、科技创新产出、行为偏好与活跃度四种类型。企业标签与属性数据组合形成企业画像。
[0048]
s03,选取企业数据数量最多的行业建立神经网络模型,将企业行为数据作为网络输入,科技服务类型数据作为网络输出训练神经网络,得到针对该行业的企业科技服务需求预测模型。
[0049]
s04,通过迁移学习方法和其他行业的企业数据对所得预测模型参数进行调整更新,得到针对不同行业的企业科技服务需求预测模型。
[0050]
实施例
[0051]
本实施例从国内科技服务平台收集了2236家企业的基本属性数据,并模拟生成了行为数据与科技服务类型数据。企业属性数据指标包括企业名称、省份、行业、企业规模与信用;行为数据包括企业科技创新投资、专利、论著与标准数量、平台广告偏好、以及平台内点击次数、访问、浏览次数,其中广告偏好包括技术交易、专利代理、软件检测、创业融资;企业科技服务包括行业认证、管理咨询、科技活动和知识产权服务四种类型。按照步骤s01,本实施按行业对所收集的企业数据与模拟数据进行了分类整理,企业行业与规模分布情况以及模拟数据描述统计结果如表1至表4所示。
[0052]
表1企业规模与行业分布数据
[0053] 微型企业小型企业中型企业大型企业高技术服务834221现代农业1252113制造业9885111电子信息21899743053生物与新医药321018914
[0054]
表2企业科技创新投资、知识产权数量与平台访问浏览次数描述统计结果
[0055] 科技创新投投资(万元)知识产权数量平台访问流量次数平均值60.3210.00149.00方差19.932.9831.07
[0056]
表3企业科技服务广告偏好统计结果
[0057]
广告类型技术交易专利代理软件检测创业融资企业数量558552549577
[0058]
表4企业选择科技服务类型统计结果
[0059]
科技服务类型行业认证管理咨询科技活动知识产权代理企业数量51510309404
[0060]
然后,按照步骤s02,本实施例利用k-means聚类方法从上述企业数据中提取企业标签,具体包括企业科技创新投入、科技创新产出、行为偏好与活跃度四种类型。企业科技创新投入、科技创新产出与活跃度标签分为高中低三档,分别由企业科技创新投资、知识产
权数量及企业对平台访问浏览次数描述;行为偏好标签代表企业对平台内不同类型科技服务广告的偏好程度,由企业对不同类型广告的点击次数描述。企业画像由企业属性数据与标签组成,即属性数据(企业名称、省份、行业与信用、企业规模和技术领域)和标签(科技创新投入、科技创新产出、行为偏好与活跃度)组成的集合。企业科技服务画像如图2所示。
[0061]
最后,按照步骤s03、步骤s04,本实施例利用电子信息行业的企业科技服务数据搭建神经网络模型并对神经网络进行训练,同时利用迁移学习方法将训练结果分别应用至其他四个行业的企业科技服务预测当中。为检测本发明提出方法的可靠性,实施例将每个行业的企业数据分别两个部分,其中百分之八十的数据用于训练神经网络和迁移学习,剩余百分之二十数据用于测试神经网络预测企业科技服务需求结果的准确性,相应的统计结果如图3所示。
[0062]
对比例
[0063]
为说明本发明提出方法在企业科技服务需求预测方面的优势,对比例采用前反馈神经网络模型和传统批量学习方法搭建企业科技服务需求模型,并使用与实施例相同的企业数据与模型的预测结果进行验证。验证过程中,百分之八十的数据用于训练神经网络,百分之二十的数据用于测试神经网络预测结果的准确度。前反馈神经网络与本发明提出方法预测准确度的对比结果如图4所示。
[0064]
从图4中可以看出,本发明提出方法的正确率为96.65%,错误率为3.35%,明显优于传统神经网络方法的正确率92.85%和错误率7.15%。本发明提出方法考虑了部分行业中企业数据数量不足对模型预测的问题,采用迁移学习等前沿技术对传统模型进行优化调整,从而能够获得更高的预测精度。
[0065]
此外应理解,在阅读了本发明的上述描述内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本技术所附权利要求书所限定的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。