一种用于安检ct三维图像的目标物体检测方法及系统
技术领域
1.本发明涉及安检图像技术领域,尤其涉及一种用于安检ct三维图像的目标物体检测方法及系统。
背景技术:
2.x射线安检设备在安防系统中的作用至关重要,尤其是在地铁站、火车站、机场等人流密集的交通节点中,安检设备是确保旅客人身财产安全乃至国家、社会稳定的重要安全保障工具。传统的安检设备检测方式是由安检员通过肉眼观察安检机中行李箱包的x射线成像,辨别其中是否有违禁品。但x射线图像与物品外貌无关,而是与物品自身的成分、密度以及成像时的角度、位置等有关,这与物品的自然图像相差较大,并且x射线图像存在更多的透视现象,上述这些因素会导致以肉眼方式观察违禁品难度较大,即便是经过培训上岗的熟练安检员,工作时间过长后也会产生视觉疲劳,同样会导致违禁品的检出率降低。由此,三维x射线计算机断层图像(ct图像)中的自动目标检测,近年来得到了行业广泛的关注。
3.目前,在三维目标检测方面卷积神经网络(cnn)取得了重大进展,研究重点有两类,一是将点云数据转换为体数据表示,并将cnn改进为3d cnn来用于目标检测网络,如3d-fcn利用3d全卷积网络直接预测类标签和边界框的位置;二是将三维体素网络利用三维卷积层将输入的三维体数据编码为多通道二维特征图,并将特征提供给后续检测网络,如vote3deep利用三维体数据的稀疏性来加速三维卷积。然而,这些基于三维网络的算法在用于检测高分辨率三维图像时计算成本和时间成本较高,不能满足实际场景应用需求。
技术实现要素:
4.鉴于上述的分析,本发明实施例旨在提供一种用于安检ct三维图像的目标物体检测方法及系统,用以解决现有安检ct图像检测方法,计算成本和时间成本较高,不能满足实际场景应用需求的问题。
5.一方面,本发明实施例提供了一种用于安检ct三维图像的目标物体检测方法,包括以下步骤:
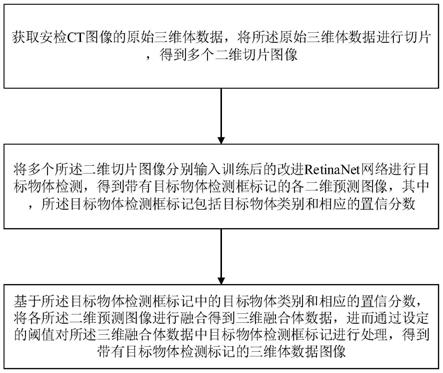
6.获取安检ct图像的原始三维体数据,将所述原始三维体数据进行切片,得到多个二维切片图像;
7.将多个所述二维切片图像分别输入训练后的改进retinanet网络进行目标物体检测,得到带有目标物体检测框标记的各二维预测图像,其中,所述目标物体检测框标记包括目标物体类别和相应的置信分数;
8.基于所述目标物体检测框标记中的目标物体类别和相应的置信分数,将各所述二维预测图像进行融合得到三维融合体数据,进而通过设定的阈值对所述三维融合体数据中目标物体检测框标记进行处理,得到带有目标物体检测标记的三维体数据图像。
9.进一步地,通过执行以下操作得到多个二维切片图像:
10.依据三维笛卡尔坐标系,沿着x、y和z方向分别将所述原始三维体数据切割成固定厚度的切片体数据,并依次进行编号;所述编号包括该切片体数据所属的切割方向和切割顺序编号;
11.将各切片体数据分别沿厚度方向进行投影,得到多个二维切片图像,其中,所述二维切片图像的每一像素点的像素值为切片体数据对应位置在厚度方向上各体素的像素值最大值。
12.进一步地,所述改进retinanet网络包括主干网络、分类子网络和回归子网络;
13.所述主干网络,用于从输入图像中提取特征图,包括resnet和fpn,构成7层的特征金字塔结构,其中,将特征金字塔结构的第一层、第二层和第三层的普通卷积更换为空洞卷积,以增大特征感受野;
14.所述分类子网络,用于基于主干网络提取的特征图进行目标物体分类,生成图像中的目标物体类别和相应置信分数;
15.所述回归子网络,用于基于主干网络提取的特征图进行边界框回归,生成图像中目标物体检测框。
16.进一步地,基于焦点损失函数对所述改进retinanet网络进行训练,所述焦点损失函数fl表示为:
17.fl(p
t
)=-α
t
(1-p
t
)
γ
log(p
t
),
18.其中,
[0019][0020]
式中,y的值为1或-1,其中,1表示图像前景、-1表示图像背景;p表示检测样本属于图像前景的概率;α
t
表示平衡参数,α
t
∈[0,1];γ表示聚焦参数,γ≥0。
[0021]
进一步地,通过执行以下步骤将各所述二维预测图像进行融合,得到三维融合体数据:
[0022]
对每一切割方向的二维预测图像进行以下处理得到相应的融合体数据:
[0023]
将该切割方向的二维预测图像依照切割顺序编号进行排列,再利用线性插值将各相邻的二维预测图像填充为固定厚度的体数据,得到该切割方向上的融合体数据;
[0024]
将所述各切割方向上得到的融合体数据进行融合,得到三维融合体数据。
[0025]
进一步地,通过执行以下步骤将各切割方向上得到的融合体数据进行融合,得到三维融合体数据:
[0026]
以任一融合体数据为基准,获取该融合体数据中目标物体检测框标记所在的体素点位置;再获取另两个融合体数据中相同位置体素点的目标物体检测框标记;
[0027]
对于获取的相同位置的每一体素点,若均存在目标物体检测框标记且其中的目标物体类别相同,则获取各目标物体检测框标记中的置信分数,并选取两个最大的置信分数求取平均值,将该平均值作为置信分数,并与该目标物体类别构成三维融合体数据相应位置体素点的目标物体检测框标记,从而得到三维融合体数据。
[0028]
进一步地,所述通过设定的阈值对所述三维融合体数据中目标物体检测框标记进行处理,得到带有目标物体检测标记的三维体数据图像,包括:
[0029]
获取三维融合体数据中带有目标物体检测框标记的体素点;
[0030]
将获取的每一体素点的目标物体检测框标记中的置信分数与设定的阈值进行比较,若大于设定的阈值,保留该体素点的目标物体检测框标记,否则,删除该体素点的目标物体检测框标记;
[0031]
依据目标物体类别分别在三维融合体数据中获取带有目标物体检测框标记的体素点;并依据相同目标物体类别的体素点分别生成最小尺寸的立体框,满足分别将相应目标物体类别的体素点全部覆盖;
[0032]
获取各立体框的边缘所在的体素点,在原始三维体数据中相同位置添加目标物体检测标记,得到带有目标物体检测标记的三维体数据图像,其中,目标物体检测标记为相应的目标物体类别。
[0033]
进一步地,所述阈值设定为0.6。
[0034]
另一方面,本发明实施例提供了一种用于安检ct三维图像的目标物体检测系统,包括:
[0035]
数据采集和处理模块,用于获取安检ct图像的原始三维体数据,将所述原始三维体数据进行切片,得到多个二维切片图像;
[0036]
二维预测图像获取模块,用于将多个所述二维切片图像分别输入训练后的改进retinanet网络进行目标物体检测,得到带有目标物体检测框标记的各二维预测图像,其中,所述目标物体检测框标记包括目标物体类别和相应的置信分数;
[0037]
三维融合体数据获取模块,用于基于所述目标物体检测框标记中的目标物体类别和相应的置信分数将各所述二维预测图像进行融合,得到三维融合体数据;
[0038]
检测数据获取模块,用于通过设定的阈值对所述三维融合体数据中目标物体检测框标记进行处理,得到带有目标物体检测标记的三维体数据图像。
[0039]
进一步地,所述数据采集和处理模块通过执行以下操作得到多个二维切片图像:
[0040]
依据三维笛卡尔坐标系,沿着x、y和z方向分别将所述原始三维体数据切割成固定厚度的切片体数据,并依次进行编号;所述编号包括该切片体数据所属的切割方向和切割顺序编号;
[0041]
将各切片体数据分别沿厚度方向进行投影,得到多个二维切片图像,其中,所述二维切片图像的每一像素点的像素值为切片体数据对应位置在厚度方向上各体素的像素值最大值。
[0042]
与现有技术相比,本发明可实现如下有益效果:
[0043]
本发明提供的一种用于安检ct三维图像的目标物体检测方法及系统,通过将安检ct的原始三维体数据进行切片,将三维体数据转换为二维切片图像,将二维切片图像输入改进的retinanet网络得到二维预测图像,再融合得到三维融合体数据,采用二维的图像进行目标物体检测预测,能够极大的降低计算复杂度、提高计算效率和加快检测时间,为安检ct三维图像中的目标物体检测的实际部署应用提供了可能性;使用改进的retinanet网络进行目标物体检测,能够增大神经网络的特征感受野,获得额外的语义信息,提高目标检测的准确性。
[0044]
本发明中,上述各技术方案之间还可以相互组合,以实现更多的优选组合方案。本发明的其他特征和优点将在随后的说明书中阐述,并且,部分优点可从说明书中变得显而
易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过说明书以及附图中所特别指出的内容中来实现和获得。
附图说明
[0045]
附图仅用于示出具体实施例的目的,而并不认为是对本发明的限制,在整个附图中,相同的参考符号表示相同的部件。
[0046]
图1为本发明实施例提供的用于安检ct三维图像的目标物体检测方法的流程示意图;
[0047]
图2为本发明实施例提供的原始三维体数据切割的流程示意图;
[0048]
图3为本发明实施例提供的retinanet网络结构示意图;
[0049]
图4为本发明实施例提供的空洞卷积空洞核的示意图;
[0050]
图5为本发明实施例提供的改进的retinanet网络的主干网络的结构示意图;
[0051]
图6为本发明实施例提供的得到三维融合体数据的流程示意图。
具体实施方式
[0052]
下面结合附图来具体描述本发明的优选实施例,其中,附图构成本技术一部分,并与本发明的实施例一起用于阐释本发明的原理,并非用于限定本发明的范围。
[0053]
实施例1
[0054]
本发明的一个具体实施例,公开了一种用于安检ct三维图像的目标物体检测方法,如图1所示,包括以下步骤:
[0055]
s1、获取安检ct图像的原始三维体数据,将所述原始三维体数据进行切片,得到多个二维切片图像。
[0056]
具体地,获取安检设备中生成的3d行李数据作为原始三维体数据;可以理解的是,相同型号的安检设备ct采集的3d数据尺寸一致。
[0057]
实施时,通过执行以下操作得到多个二维切片图像:
[0058]
依据三维笛卡尔坐标系,沿着x、y和z方向分别将所述原始三维体数据切割成固定厚度的切片体数据,并依次进行编号;所述编号包括该切片体数据所属的切割方向和切割顺序编号;
[0059]
将各切片体数据分别沿厚度方向进行投影,得到多个二维切片图像,其中,所述二维切片图像的每一像素点的像素值为切片体数据对应位置在厚度方向上各体素的像素值最大值。
[0060]
具体地,切片体数据的厚度为n个体素,n的取值依据实际中获取的原始三维体数据的尺寸进行设置;示例性地,原始三维体数据的尺寸为750
×
750
×
750,设置n为10个体素。
[0061]
也就是说,获取的原始三维体数据v,其中,n
x
、ny、nz为分别是原始三维体数据长度、高度和宽度的体素个数,如图2所示,以z轴作为切割方向为例,生成平行xy平面的nz/n个二维切片图像:首先,以n个体素为固定厚度进行切割,得到nz/n个nx
×
ny
×
n切片体数据,将每一切片体数据沿厚度方向进行投影,并各位置在厚度方向应用最大数操作,得到nx
×
ny的二维切片图像;以同样的方式得到x方向和y方向的二维切片图像,根据
三个切割方向得到三组二维切片图像共n
x
/n ny/n nz/n个二维切片图像。
[0062]
可以理解的是,根据切片体数据的切割顺序编号可以得到每个二维切片图像的提取位置,也就是保留了深度信息,使得在后续生成切割体数据时能够准确得到完整的体数据。
[0063]
s2、将多个所述二维切片图像分别输入训练后的改进retinanet网络进行目标物体检测,得到带有目标物体检测框标记的各二维预测图像,其中,所述目标物体检测框标记包括目标物体类别和相应的置信分数。
[0064]
实施时,如图3所示,所述改进retinanet网络包括主干网络、分类子网络和回归子网络;
[0065]
所述主干网络,用于从输入图像中提取特征图,包括resnet和fpn,构成7层的特征金字塔结构,其中,将特征金字塔结构的第一层、第二层和第三层的普通卷积更换为空洞卷积,以增大特征感受野;
[0066]
所述分类子网络,用于基于主干网络提取的特征图进行目标物体分类,生成图像中的目标物体类别和相应置信分数;
[0067]
所述回归子网络,用于基于主干网络提取的特征图进行边界框回归,生成图像中目标物体检测框。
[0068]
具体地,将空洞核设置为dilation rate=[5,2,1],如图4所示,分别与特征金字塔结构的第一层、第二层和第三层的空洞卷积对应。
[0069]
具体地,如图5所示,所述主干网络包括resnet和fpn,构成7层的特征金字塔结构,包括backbone生成特征阶段、特征融合阶段和检测头输出结果阶段;
[0070]
(1)backbone生成特征阶段
[0071]
backbone生成的特征,按stage划分,分别记作c1、c2、c3、c4、c5、c6和c7,分别是特征金字塔的第1~7层,其中的数字与stage的编号相同,代表的是分辨率减半的次数;示例性的,c2代表stage2输出的特征图,分辨率为输入图像的1/4;c5代表stage5输出的特征图,分辨率为输入图像的1/32。
[0072]
(2)特征融合阶段
[0073]
fpn将backbone生成特征阶段生成的不同分辨率特征图作为输入,输出为经过融合后的特征图;输出的特征图以p作为编号标记;示例性地,fpn的输入是c3、c4、c5、c6和c7生成的特征图,经过融合后,输出为p3、p4、p5、p6和p7的特征图;应当注意的是特征融合是fpn的特有阶段,不再进行赘述。
[0074]
(3)检测头输出结果阶段
[0075]
接收fpn输出的融合后的特征图做具体的物体检测。
[0076]
需要注意的是,由于fpn的每个尺度输入是从resnet网络得到,相邻尺度特征融合过程中的信息损失:在高层-》底层适配(融合)的过程中,会丢失语义信息,因为通道数变少了;考虑到不同stage学习到的特征感受野不一致,包含的语义信息也不同,本实施例中将stage1~stage3即特征金字塔结构的第1~3层的普通卷积网络更换为空洞卷积以增大特征的感受野,并且根据安检ct得到的二维切片图像较大,为每一层设置不同的空洞核。
[0077]
可以理解的是,将主干网络进行改进后,能够利用多层信息融合对高层带有丰富语义信息的特征与低层带有较小目标的细节信息进行融合,并在此过程中淘汰大量无效信
息,实现对网络结构的优化;并且改进后增大了神经网络的感受野,能够获得额外的语义信息,增加后期目标检测的准确性。
[0078]
实施时,基于焦点损失函数对所述改进retinanet网络进行训练,所述焦点损失函数fl表示为:
[0079]
fl(p
t
)=-α
t
(1-p
t
)
γ
log(p
t
),
[0080]
其中,
[0081][0082]
式中,y的值为1或-1,其中,1表示图像前景、-1表示图像背景;p表示检测样本属于图像前景的概率;α
t
表示平衡参数,α
t
∈[0,1];γ表示聚焦参数,γ≥0。
[0083]
具体地,γ和α
t
的最优值是相互影响的,在评估准确度时需要将两者组合进行调节;更具体地,γ范围在[0,5];优选地,γ=2、α
t
=0.25,使得resnet fpn作为主干网络的结构具有最优的性能。
[0084]
需要说明的是,retinanet网络是one-stage一阶目标检测方法,基于交叉熵损失函数,提出了新的分类损失函数焦点损失函数focal loss,是一个动态缩放的交叉熵损失,该损失函数通过抑制容易分类样本的权重,将注意力集中在难以区分的样本上,有效控制正负样本比例,防止失衡现象;具体过程如下:
[0085]
二分类交叉熵ce,其公式为:
[0086][0087]
式中,y的值为1或-1,其中,1表示图像前景、-1表示图像背景;p表示检测样本属于图像前景的概率;
[0088][0089]
则得到:
[0090]
ce(p,y)=ce(p
t
)=-log(p
t
);
[0091]
在安检中行李ct的二维切片图像中,对于包含一个目标物体的行李,在大多数情况下,包含目标物体的比例是15个以上切片图像中只有一个切片存在目标物体;在切片图像中,目标物体仅占总图像分辨率的很小一部分。也就是说,用于训练的安检中行李ct的二维切片图像目标物体和杂乱背景的像素点数量存在严重不平衡,即正负样本不平衡,其中正样本为包含目标物体的二维切片图像,负样本为不包含目标物体的二维切片图像。
[0092]
为了解决极端的类间不平衡问题,本实施例在训练过程中采用了焦点损失方法,是在交叉熵损失函数中引入一个调制因子,防止大量容易产生负样本的情况下淹没检测器。
[0093]
损失函数变形为:
[0094]
ce(p
t
)=-α
t
log(p
t
);
[0095]
焦点损失定义为:
[0096]
fl
′
(p
t
)=-(1-p
t
)
γ
log(p
t
);
[0097]
最后得到焦点损失函数:
[0098]
fl(p
t
)=-α
t
(1-p
t
)
γ
log(p
t
);
[0099]
式中,α
t
表示平衡参数,α
t
∈[0,1];γ表示聚焦参数,γ≥0。
[0100]
可以理解的是,在焦点损失函数增加了两个调制因子α
t
和(1-p
t
)
γ
表示交叉熵损失;γ越大,分类良好的样本对损失的影响越小,可以控制简单/难区分样本数量失衡;根据正负样本的比例调整α
t
可以抑制正负样本的数量失衡,略微提高分类精度。
[0101]
s3、基于所述目标物体检测框标记中的目标物体类别和相应的置信分数,将各所述二维预测图像进行融合得到三维融合体数据,进而通过设定的阈值对三维融合体数据中目标物体检测框标记进行处理,得到带有目标物体检测标记的三维体数据图像。
[0102]
实施时,如图6所示,通过执行以下步骤将各所述二维预测图像进行融合,得到三维融合体数据:
[0103]
对每一切割方向的二维预测图像进行以下处理得到相应的融合体数据:
[0104]
将该切割方向的二维预测图像依照切割顺序编号进行排列,再利用线性插值将各相邻的二维预测图像填充为固定厚度的体数据,得到该切割方向上的融合体数据;
[0105]
将所述各切割方向上得到的融合体数据进行融合,得到三维融合体数据。
[0106]
具体地,通过执行以下步骤将各切割方向上得到的融合体数据进行融合,得到三维融合体数据:
[0107]
以任一融合体数据为基准,获取该融合体数据中目标物体检测框标记所在的体素点位置;再获取另两个融合体数据中相同位置体素点的目标物体检测框标记;
[0108]
对于获取的相同位置的每一体素点,若均存在目标物体检测框标记且其中的目标物体类别相同,则获取各目标物体检测框标记中的置信分数,并选取两个最大的置信分数求取平均值,将该平均值作为置信分数,并与该目标物体类别构成三维融合体数据相应位置体素点的目标物体检测框标记,从而得到三维融合体数据。
[0109]
可以理解的,在得到三维融合体数据时,选取各融合体数据中的相应类别的置信分数的两个最大值进行平均,确保了多个切割方向之间的空间一致性,使每个体素的3d检测更加可靠;并且由于采用2d检测网络进行图像检测再融合,降低了计算复杂度、提高了计算效率和缩短了计算时间。
[0110]
实施时,所述通过设定的阈值对三维融合体数据中目标物体检测框标记进行处理,得到带有目标物体检测标记的三维体数据图像,包括:
[0111]
获取三维融合体数据中带有目标物体检测框标记的体素点;
[0112]
将获取的每一体素点的目标物体检测框标记中的置信分数与设定的阈值进行比较,若大于设定的阈值,保留该体素点的目标物体检测框标记,否则,删除该体素点的目标物体检测框标记;
[0113]
依据目标物体类别分别在三维融合体数据中获取带有目标物体检测框标记的体素点;并依据相同目标物体类别的体素点分别生成最小尺寸的立体框,满足分别将相应目标物体类别的体素点全部覆盖;
[0114]
获取各立体框的边缘所在的体素点,在原始三维体数据中相同位置添加目标物体
检测标记,得到带有目标物体检测标记的三维体数据图像,其中,目标物体检测标记为相应的目标物体类别。
[0115]
具体地,所述阈值可根据实际检测情况进行设定,优选地,阈值设定为0.6,可达到较好的目标检测效果。
[0116]
与现有技术相比,本发明提供了一种用于安检ct三维图像的目标物体检测方法及系统,通过将安检ct的原始三维体数据进行切片,将三维体数据转换为二维切片图像,将二维切片图像输入改进的retinanet网络得到二维预测图像,再融合得到三维融合体数据,采用二维的图像进行目标物体检测预测,能够极大的降低计算复杂度、提高计算效率和加快检测时间,为安检ct三维图像中的目标物体检测的实际部署应用提供了可能性;使用改进的retinanet网络进行目标物体检测,能够增大神经网络的特征感受野,获得额外的语义信息,提高目标检测的准确性。
[0117]
实施例2
[0118]
本发明的一个具体实施例,公开了一种用于安检ct三维图像的目标物体检测系统,包括:
[0119]
数据采集和处理模块,用于获取安检ct图像的原始三维体数据,将所述原始三维体数据进行切片,得到多个二维切片图像;
[0120]
二维预测图像获取模块,用于将多个所述二维切片图像分别输入训练后的改进retinanet网络进行目标物体检测,得到带有目标物体检测框标记的各二维预测图像,其中,所述目标物体检测框标记包括目标物体类别和相应的置信分数;
[0121]
三维融合体数据获取模块,用于基于所述目标物体检测框标记中的目标物体类别和相应的置信分数将各所述二维预测图像进行融合,得到三维融合体数据;
[0122]
检测数据获取模块,用于通过设定的阈值对所述三维融合体数据中目标物体检测框标记进行处理,得到带有目标物体检测标记的三维体数据图像。
[0123]
实施时,所述数据采集和处理模块通过执行以下操作得到多个二维切片图像:
[0124]
依据三维笛卡尔坐标系,沿着x、y和z方向分别将所述原始三维体数据切割成固定厚度的切片体数据,并依次进行编号;所述编号包括该切片体数据所属的切割方向和切割顺序编号;
[0125]
将各切片体数据分别沿厚度方向进行投影,得到多个二维切片图像,其中,所述二维切片图像的每一像素点的像素值为切片体数据对应位置在厚度方向上各体素的像素值最大值。
[0126]
本发明实施例的二维预测图像获取模块、三维融合体数据获取模块和检测数据获取模块的具体实施过程参见上述方法实施例即可,本实施例在此不再赘述。
[0127]
由于本实施例与上述方法实施例原理相同,所以本系统也具有上述方法实施例相应的技术效果。
[0128]
本领域技术人员可以理解,实现上述实施例方法的全部或部分流程,可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于计算机可读存储介质中。其中,所述计算机可读存储介质为磁盘、光盘、只读存储记忆体或随机存储记忆体等。
[0129]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,
都应涵盖在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。