1.本发明涉及数据分析与处理领域,特别涉及一种不平衡数据与图像处理方法、系统及计算机设备。
背景技术:
2.在同一个数据集中,一个或部分的类的样本数很少(正类或少数类),而另一种或其他部分的类的样本数相对很多(负类或多数类),并且这两部分所包含的样本在数量上的差距很大,把符合这种情况的数据集称为不平衡数据集。在不平衡数据集中,由于少数类样本的数量很少,所以在分类学习的无法提供给分类器足够的信息,而多数类数量较多,为分类器提供了足够信息,这就导致了分类器在分类过程中更容易识别多数类,对少数类的识别率则很低。
3.在现实生活中有很多的领域都需要针对数据不平衡的状况进行知识建模分析,例如如下领域:医疗信息辅助诊断、大量广告垃圾邮件处理、多媒体信息检索、信用卡欺诈检测、文本信息分类等。在很多相关领域,对少数类的识别与分类至关重要,对少数类正确识别对整个分类学习的意义要远远超过对多数类样本的正确识别。比如,在医疗信息辅助诊断中,医生的诊断可分为四种情况:正常人正确诊断为正常、有病的人正确诊断为有病、正常的人误诊为有病、有病的人误诊为正常。这个过程当中如果医生把正常人误诊为病人,就会给正常人带来非常严重的心理和金钱的压力。但是如果一个病人被辅助医疗诊断系统误诊为健康人,那么极有可能让病人不能够及时被医治。而在这四种情况中把病人误诊为正常则是现实中发生最少见的一种情况,可以视作少数类,而其他的三种情况发生的频率较为频繁,视作多数类。可是,现有的分类方法中,大多数方法对多数类具有较高的识别率,但对于少数类的识别率却很低,并没有体现分类器真正的作用。
4.针对不平衡数据的处理方法主要是通过重采样技术,对样本进行欠采样或者过采样,以调整样本集不平衡程度。从少数类角度调整不平衡数据的常用方法有:随机过采样、smote,borderline-smote等。这些方法没有很好地考虑实际数据集的数据分布特性,具有一定的随机性和盲目性,从而影响分类效果。
5.所以,现在有必要提供一种更可靠的方案。
技术实现要素:
6.本发明所要解决的技术问题在于针对上述现有技术中的不足,提供一种不平衡数据与图像处理方法、系统及计算机设备。
7.为解决上述技术问题,本发明采用的技术方案是:提供一种不平衡数据与图像处理方法,包括以下步骤:
8.1)对不平衡数据集o进行预处理;
9.2)对预处理后的不平衡数据集o使用基于豪斯多夫距离的最大分布算法进行处理,确定需构建的rbf神经网络数据生成模型的参数;所述参数包括rbf神经网络数据生成
模型的隐层神经元,每个隐层神经元对应的类别、输出权值和对角分布矩阵,以及每个隐层神经元与对应输出神经元之间的连接权重;
10.3)基于步骤2)的结果构建rbf神经网络数据生成模型;
11.4)使用构建的rbf神经网络数据生成模型结合mvnrnd函数进行数据生成,得到生成的样本集合s;
12.5)将生成的样本集合s填充到原始不平衡数据集o中,获得处理后的平衡数据集os,os=o∪s。
13.优选的是,所述步骤1)具体为:
14.对不平衡数据集o中数值属性的缺失值使用同类样本该属性的均值进行补全;对于序数属性和标称属性的缺失值,使用同类样本该属性出现频率最高的值进行补全;
15.数据补全完成后,对序数属性和标称属性进行顺序编码;
16.采用基于pyradiomics工具包将对不平衡数据集o中的图像数据转化为数值型数据添加到o中,使用z-score方法对所有属性进行标准化,得到预处理后的数据集d;
17.使用向量l
mean
和l
std
分别保存每个属性的均值和标准差,并保存序数属性和标称属性的顺序编码方式。
18.优选的是,所述步骤2)具体包括:
19.2-1)假设数据集d中有n个输入样本{xn,n=1,2,
…
,n},每个样本有m个属性,每个样本属于c类中的一类,第c类的样本个数为nc,c=1,2,
…
,c;
20.2-2)将数据集中的样本根据所属类别进行划分,得到属于第c类的样本组成的数据子集dc,c=1,2,
…
,c;进行初始化,令当前的类别索引c=0,当前的隐层神经元个数p=0;
21.2-3)令c=c 1;
22.2-4)令p=p 1,计算dc和其他样本间的豪斯多夫距离h
p
,对应的样本作为第c类新增的一个隐层神经元中心k
p
;计算dc中所有样本到k
p
的欧式距离,记录距离小于h
p
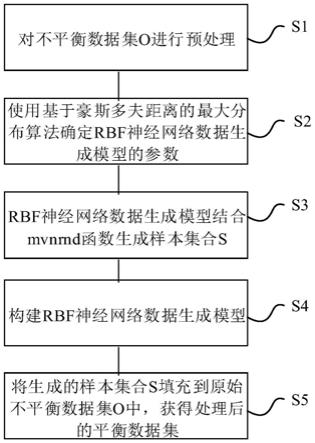
对应的所有样本构成的子集dc,并将dc从dc中删除;以dc中样本数量作为k
p
与对应类别的输出神经元之间的连接权重w
p
,k
p
与其他类别的输出神经元之间的连接权值为0;计算dc中每一维属性的方差vm,组成k
p
对应的对角分布矩阵
23.2-5)如果dc中剩下的样本个数不为0,则回到步骤c;否则,检查c是否等于c,如果c<c,则回到步骤2-3),如果c=c,则算法终止。
24.优选的是,所述步骤3)具体包括:
25.3-1)根据数据集d中的每个样本有m个属性,确定rbf神经网络数据生成模型的输入层具有m个输入神经元,每个神经元对应于一个属性;
26.3-2)根据数据集d共有c个类别,确定rbf神经网络数据生成模型的输出层具有c个输出神经元,每个神经元对应于一个类别;
27.3-3)根据步骤2)的结果,得到p个隐层神经元{k1,k2,
…
,k
p-1
,k
p
}及其对应的类别和输出权值{w1,w2,
…
,w
p-1
,w
p
},以及对应的p个对角分布矩阵{v1,v2,
…
,v
p-1
,v
p
},确定p个
隐层神经元的参数{(k1,v1),(k2,v3),
…
,(k
p-1
,v
p-1
),(k
p
,v
p
)},以及每个隐层神经元与对应输出神经元之间的连接权重{w1,w2,
…
,w
p-1
,w
p
}。
28.优选的是,所述步骤4)具体包括:
29.4-1)设置各类别需要生成的样本数量sc,c=1,2,
…
,c;进行初始化,令当前的隐层神经元中心索引p=0,生成的样本集合表示空集;
30.4-2)令p=p 1,假设当前隐层神经元中心k
p
属于类别c,则k
p
对应的生成样本数量为
31.4-3)生成的样本矩阵其中每个样本均属于类别c;将合并到生成的样本集合s中,检查p是否等于p,如果p<p,则回到步骤4-2);如果p=p,则得到完整的生成样本集合s,执行下一步;
32.4-4)根据预处理时保存的所有属性的均值向量l
mean
和标准差l
std
,对s进行逆标准化;根据序数属性和标称属性的顺序编码方式,将s中对应的数值转换回序数属性和标称属性的原始值。
33.本发明还提供一种不平衡数据与图像处理系统,其采用如上所述的方法进行不平衡数据的处理,该系统包括:
34.数据预处理模块,其用于按照所述步骤1)的方法对不平衡数据集o进行预处理,得到数据集d;
35.最大分布算法模块,其用于按照所述步骤2)的方法确定需构建的rbf神经网络数据生成模型的参数;
36.网络模型构建模块,其按照所述步骤3)的方法构建得到rbf神经网络数据生成模型;
37.rbf神经网络数据生成模型,其结合mvnrnd函数,按照所述步骤4)的方法根据原始不平衡数据集的分布自适应地生成新的数据集合s;
38.以及数据后处理模块,将生成的样本集合s填充到原始不平衡数据集o中,获得处理后的平衡数据集os。
39.本发明还提供一种存储介质,其上存储有计算机程序,该程序被执行时用于实现如上所述的方法。
40.本发明还提供一种计算机设备,包括存储器、处理器以及存储在所述存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上所述的方法。
41.本发明的有益效果是:本发明提供的不平衡数据与图像处理方法,能够处理缺失值和不同类型的属性,自适应地学习原始不平衡数据的类内和类间分布,自动按类别生成数据扩充原始数据中的少数类,从而能有效改善数据的不平衡性,提高数据分析的准确性。
附图说明
42.图1为本发明的不平衡数据与图像处理方法的流程图;
43.图2为本发明的rbf神经网络数据生成模型的原理结构示意图。
具体实施方式
44.下面结合实施例对本发明做进一步的详细说明,以令本领域技术人员参照说明书文字能够据以实施。
45.应当理解,本文所使用的诸如“具有”、“包含”以及“包括”术语并不排除一个或多个其它元件或其组合的存在或添加。
46.实施例1
47.参照图1,本实施例的一种不平衡数据与图像处理方法,包括以下步骤:
48.s1、对不平衡数据集o进行预处理:
49.对不平衡数据集o中数值属性的缺失值使用同类样本该属性的均值进行补全;对于序数属性和标称属性的缺失值,使用同类样本该属性出现频率最高的值进行补全;
50.数据补全完成后,对序数属性和标称属性进行顺序编码;
51.采用基于pyradiomics工具包将对不平衡数据集o中的图像数据转化为数值型数据添加到o中,使用z-score方法对所有属性进行标准化,得到预处理后的数据集d;其中,不平衡数据集o中的数据类型包括数值型数据和图像数据等;
52.使用向量l
mean
和l
std
分别保存每个属性的均值和标准差,并保存序数属性和标称属性的顺序编码方式。
53.s2、对预处理后的不平衡数据集o使用基于豪斯多夫距离的最大分布算法进行处理,确定需构建的rbf神经网络数据生成模型的参数;参数包括rbf神经网络数据生成模型的隐层神经元,每个隐层神经元对应的类别、输出权值和对角分布矩阵,以及每个隐层神经元与对应输出神经元之间的连接权重;具体包括:
54.s2-1)假设数据集d中有n个输入样本{xn,n=1,2,
…
,n},每个样本有m个属性,每个样本属于c类中的一类,第c类的样本个数为nc,c=1,2,
…
,c;
55.s2-2)将数据集中的样本根据所属类别进行划分,得到属于第c类的样本组成的数据子集dc,c=1,2,
…
,c;进行初始化,令当前的类别索引c=0,当前的隐层神经元个数p=0;
56.s2-3)令c=c 1;
57.s2-4)令p=p 1,计算dc和其他样本间的豪斯多夫距离h
p
,对应的样本作为第c类新增的一个隐层神经元中心k
p
;计算dc中所有样本到k
p
的欧式距离,记录距离小于h
p
对应的所有样本构成的子集dc,并将dc从dc中删除;以dc中样本数量作为k
p
与对应类别的输出神经元之间的连接权重w
p
,k
p
与其他类别的输出神经元之间的连接权值为0;计算dc中每一维属性的方差vm,组成k
p
对应的对角分布矩阵
58.s2-5)如果dc中剩下的样本个数不为0,则回到步骤c;否则,检查c是否等于c,如果c<c,则回到步骤s2-3),如果c=c,则算法终止。
59.s3、基于步骤s2)的结果构建rbf神经网络数据生成模型,具体包括:
60.s3-1)根据数据集d中的每个样本有m个属性,确定rbf神经网络数据生成模型的输入层具有m个输入神经元,每个神经元对应于一个属性;
61.s3-2)根据数据集d共有c个类别,确定rbf神经网络数据生成模型的输出层具有c个输出神经元,每个神经元对应于一个类别;
62.s3-3)根据步骤s2)的结果,得到p个隐层神经元{k1,k2,
…
,k
p-1
,k
p
}及其对应的类别和输出权值{w1,w2,
…
,w
p-1
,w
p
},以及对应的p个对角分布矩阵{v1,v2,
…
,v
p-1
,v
p
},确定p个隐层神经元的参数{(k1,v1),(k2,v3),
…
,(k
p-1
,v
p-1
),(k
p
,v
p
)},以及每个隐层神经元与对应输出神经元之间的连接权重{w1,w2,
…
,w
p-1
,w
p
}。
63.其中,假设第1个和第2个隐层神经元属于类别1,第p-1个和第p个隐层神经元属于类别c。
64.构建的rbf神经网络数据生成模型的原理结构如图2所示。
65.s4、使用构建的rbf神经网络数据生成模型结合mvnrnd函数进行数据生成,得到生成的样本集合s,具体包括:
66.s4-1)设置各类别需要生成的样本数量sc,c=1,2,
…
,c;进行初始化,令当前的隐层神经元中心索引p=0,生成的样本集合表示空集;
67.s4-2)令p=p 1,假设当前隐层神经元中心k
p
属于类别c,则k
p
对应的生成样本数量为
68.s4-3)生成的样本矩阵其中每个样本均属于类别c;将合并到生成的样本集合s中,检查p是否等于p,如果p<p,则回到步骤s4-2);如果p=p,则得到完整的生成样本集合s,执行下一步;
69.s4-4)根据预处理时保存的所有属性的均值向量l
mean
和标准差l
std
,对s进行逆标准化;根据序数属性和标称属性的顺序编码方式,将s中对应的数值转换回序数属性和标称属性的原始值。
70.s5、将生成的样本集合s填充到原始不平衡数据集o中,获得处理后的平衡数据集os,os=o∪s。
71.实施例2
72.本实施例提供一种不平衡数据与图像处理系统,其采用实施例1的方法进行不平衡数据的处理,该系统包括:
73.数据预处理模块,其用于按照步骤1)的方法对不平衡数据集o进行预处理,得到数据集d;
74.最大分布算法模块,其用于按照步骤2)的方法确定需构建的rbf神经网络数据生成模型的参数;
75.网络模型构建模块,其按照步骤3)的方法构建得到rbf神经网络数据生成模型;
76.rbf神经网络数据生成模型,其结合mvnrnd函数,按照步骤4)的方法根据原始不平衡数据集的分布自适应地生成新的数据集合s;
77.以及数据后处理模块,将生成的样本集合s填充到原始不平衡数据集o中,获得处理后的平衡数据集os。
78.本实施例还提供一种存储介质,其上存储有计算机程序,该程序被执行时用于实现实施例1的方法。
79.本实施例还提供一种计算机设备,包括存储器、处理器以及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,处理器执行计算机程序时实现实施例1的方法。
80.尽管本发明的实施方案已公开如上,但其并不仅仅限于说明书和实施方式中所列运用,它完全可以被适用于各种适合本发明的领域,对于熟悉本领域的人员而言,可容易地实现另外的修改,因此在不背离权利要求及等同范围所限定的一般概念下,本发明并不限于特定的细节。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。