技术特征:
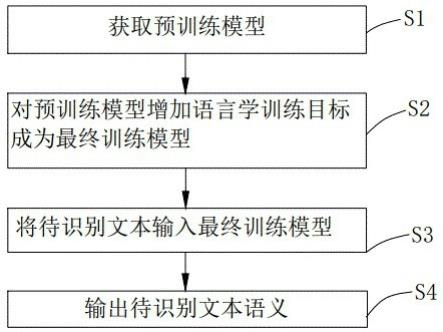
1.一种降低语义识别计算量的方法,其特征在于:包括以下步骤:获取预训练模型;对预训练模型增加语言学训练目标成为最终训练模型;将待识别文本输入最终训练模型;输出待识别文本语义。2.如权利要求1所述的降低语义识别计算量的方法,其特征在于:所述获取预训练模型的具体步骤包括:获取训练句子样本w,设立第一训练目标;将训练句子样本w拆分成子词序列,对训练句子样本w的子词序列进行随机覆盖以生成拓展句子样本w’;将所述拓展句子样本w’输入语言模型,得到编码后的上下文表示h,并通过第一训练目标训练模型获得预训练模型。3.如权利要求2所述的降低语义识别计算量的方法,其特征在于:对预训练模型增加语言学训练目标成为最终训练模型的具体步骤包括:将训练句子样本w标注词性标签和实体标签,并给预训练模型增加相应的语言学训练目标,即第二训练目标,将第一训练目标与第二训练目标结合对模型进行增强训练,获得最终训练模型。4.如权利要求3所述的降低语义识别计算量的方法,其特征在于:所述第一训练目标为解析被覆盖的子词序列,第二训练目标为让模型根据句子的上下文的表示h,预测相应的词性标签和实体标签概率。5.如权利要求3所述的降低语义识别计算量的方法,其特征在于:通过自然语言处理工具对训练句子样本w进行词性标签和实体标签的标注。6.如权利要求4所述的降低语义识别计算量的方法,其特征在于:所述第一训练目标设置为;所述第二训练目标设置为;,所述最终训练模型的训练目标设置为,其中为预训练模型的损失函数,与为词性标签和实体标签的预测损失函数,为第k个输入的句子,为拓展句子样本,为第i个词性标签,为第i个实体标签,和为预测其对应的语言学标签的概率。7.如权利要求6所述的降低语义识别计算量的方法,其特征在于:通过损失函数作为训练目标,损失函数设置为交叉熵损失函数。8.如权利要求2所述的降低语义识别计算量的方法,其特征在于:切分子词序列时记录每个词所切分后的子词元素及与其对应的词性标签和实体标签。9.一种降低语义识别计算量的系统,其特征在于:包括:训练模块,用于获取预训练模型,并对预训练模型增加语言学训练目标成为最终训练模型;输入模块,用于将待识别文本输入最终训练模型;
输出模块,用于输出待识别文本语义。10.一种存储介质,其上存储有计算机程序,其特征在于:所述计算机程序被处理器执行时实现权利要求1-8任一项所述的方法。
技术总结
本发明涉及自然语言处理领域,特别涉及一种降低语义识别计算量的方法、系统及存储介质。本发明的降低语义识别计算量的方法包括如下步骤:获取预训练模型;对预训练模型增加语言学训练目标成为最终训练模型;将待识别文本输入最终训练模型;输出待识别文本语义。通过增加语言学训练目标的设计,使得无需改变模型的结构就能提升训练的精确性和模型的鲁棒性,同时还降低了模型的复杂程度,降低了模型的计算量,解决了现有技术模型的计算量过大的问题。题。题。
技术研发人员:王宇龙 张倬胜 华菁云 周明
受保护的技术使用者:北京澜舟科技有限公司
技术研发日:2022.02.22
技术公布日:2022/3/25
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。