基于hive的拉链式模型数据汇聚方法及系统
技术领域:
:1.本发明涉及数据汇聚
技术领域:
:,尤其涉及一种基于hive的拉链式模型数据汇聚方法以及一种基于hive的拉链式模型数据汇聚系统。
背景技术:
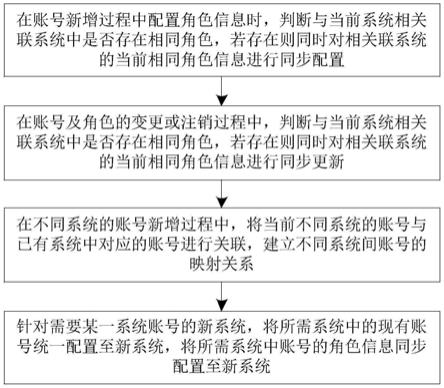
::2.在运营商行业,现已全面推动去o、去mpp等技术场景,引入大数据技术做数据存储、计算和应用。根据数据时效性,按照业务场景划分,主要分实时业务、准实时业务以及离线业务三个场景。不管是哪种业务场景,都要按照一定的频率周期对数据进行操作,其中离线业务场景在大数据技术背景下,普遍采用hive来替代oracle,作为数据主要存储计算的技术方案。但hive是基于hdfs(hadoopdistributedfilesystem,分布式文件系统)文件存储方式,对update、delete支持不太友好,同时也不建议在hive中进行更新、删除操作。技术实现要素:3.针对上述问题,本发明提供了一种基于hive的拉链式模型数据汇聚方法及系统,通过数据的标准化,根据标准接口模型与目标结果模型之间的关联,以主键为依据对数据进行插入、删除和更新操作,只需要根据模型字段和属性进行无逻辑开发,从而避免文件级的更新和删除操作,实现历史数据拉链式存储,能够保留所有数据变化轨迹,同时能够降低数据冗余度,模板化的开发方式降低了开发工作量和运维难度,解决了在hive环境中的数据操作问题。4.为实现上述目的,本发明提供了一种基于hive的拉链式模型数据汇聚方法,包括:5.对接业务系统,并由所述业务系统中抽取原始数据;6.对所述原始数据进行清洗和标准化,以确定标准接口模型;7.由目标结果模型中获取当前有效数据,通过所述有效数据的主键与所述标准接口模型内关联,确定所述目标结果模型中的待更新数据模型;8.将所述标准接口模型左外关联所述待更新数据模型,剔除主键重复的数据以生成增量数据,并将所述增量数据直接插入至所述目标结果模型中;9.将所述标准接口模型内关联所述待更新数据模型,将原始数据中全字段匹配的数据删除;10.将所述待更新数据模型内关联所述标准接口模型,并采用所述标准接口模型的数据对所述待更新数据模型进行更新,实现所述目标结果模型的数据汇聚。11.在上述技术方案中,优选地,基于hive的拉链式模型数据汇聚方法还包括:在对所述待更新数据模型的数据更新完成后,针对相同主键更新前的数据的数据状态日期进行更新。12.在上述技术方案中,优选地,所述标准接口模型与所述业务系统中的数据模型一致,所述标准接口模型用于将所述业务系统中抽取的原始数据复制至所述目标结果模型中。13.在上述技术方案中,优选地,采用etl(extract-transform-load,抽取-转换-加载)工具实现所述业务系统中原始数据的抽取。14.在上述技术方案中,优选地,所述对所述原始数据进行清洗和标准化具体包括:15.将所述原始数据中的无关字符删除,实现对所述原始数据的清洗;16.将所述原始数据中相应的字段名称和字段属性与所述目标结果模型保持一致,实现对所述原始数据的标准化。17.在上述技术方案中,优选地,所述通过所述有效数据的主键与所述标准接口模型内关联,确定所述目标结果模型中的待更新数据模型具体包括:18.通过所述目标结果模型与所述标准接口模型的内关联,对比所述有效数据与所述标准接口模型的主键数据,以所述目标结果模型中主键相同的对应数据作为待更新数据模型。19.本发明还提出一种基于hive的拉链式模型数据汇聚系统,应用如上述技术方案中任一项公开的基于hive的拉链式模型数据汇聚方法,包括:20.数据抽取模块,用于对接业务系统,并由所述业务系统中抽取原始数据;21.数据处理模块,用于对所述原始数据进行清洗和标准化,以确定标准接口模型;22.更新确认模块,用于从目标结果模型中获取当前有效数据,通过所述有效数据的主键与所述标准接口模型内关联,确定所述目标结果模型中的待更新数据模型;23.增量插入模块,用于将所述标准接口模型左外关联所述待更新数据模型,剔除主键重复的数据以生成增量数据,并将所述增量数据直接插入至所述目标结果模型中;24.数据舍弃模块,用于将所述标准接口模型内关联所述待更新数据模型,并将原始数据中全字段匹配的数据删除;25.数据更新模块,用于将所述待更新数据模型内关联所述标准接口模型,并采用所述标准接口模型的数据对所述待更新数据模型进行更新,实现所述目标结果模型的数据汇聚。26.在上述技术方案中,优选地,基于hive的拉链式模型数据汇聚系统还包括:27.日期更新模块,用于在对所述待更新数据模型的数据更新完成后,针对相同主键更新前的数据的数据状态日期进行更新。28.在上述技术方案中,优选地,所述数据处理模块具体用于:29.将所述原始数据中的无关字符删除,实现对所述原始数据的清洗;30.将所述原始数据中相应的字段名称和字段属性与所述目标结果模型保持一致,实现对所述原始数据的标准化。31.在上述技术方案中,优选地,所述更新确认模块具体用于:32.通过所述目标结果模型与所述标准接口模型的内关联,对比所述有效数据与所述标准接口模型的主键数据,以所述目标结果模型中主键相同的对应数据作为待更新数据模型。33.与现有技术相比,本发明的有益效果为:通过数据的标准化,根据标准接口模型与目标结果模型之间的关联,以主键为依据对数据进行插入、删除和更新操作,只需要根据模型字段和属性进行无逻辑开发,从而避免文件级的更新和删除操作,实现历史数据拉链式存储,能够保留所有数据变化轨迹,同时能够降低数据冗余度,模板化的开发方式降低了开发工作量和运维难度,解决了在hive环境中的数据操作问题。附图说明34.图1为本发明一种实施例公开的基于hive的拉链式模型数据汇聚方法的流程示意图;35.图2为本发明一种实施例公开的基于hive的拉链式模型数据汇聚方法的数据变化情况示意图;36.图3为本发明一种实施例公开的基于hive的拉链式模型数据汇聚系统的模块示意图。37.图中,各组件与附图标记之间的对应关系为:38.11.数据抽取模块,12.数据处理模块,13.更新确认模块,14.增量插入模块,15.数据舍弃模块,16.数据更新模块,17.日期更新模块。具体实施方式39.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。40.下面结合附图对本发明做进一步的详细描述:41.如图1所示,根据本发明提供的一种基于hive的拉链式模型数据汇聚方法,包括:42.对接业务系统,并由业务系统中抽取原始数据;43.对原始数据进行清洗和标准化,以确定标准接口模型;44.由目标结果模型中获取当前有效数据,通过有效数据的主键与标准接口模型内关联,确定目标结果模型中的待更新数据模型;45.将标准接口模型左外关联待更新数据模型,剔除主键重复的数据以生成增量数据,并将增量数据直接插入至目标结果模型中;46.将标准接口模型内关联待更新数据模型,将原始数据中全字段匹配的数据删除;47.将待更新数据模型内关联标准接口模型,并采用标准接口模型的数据对待更新数据模型进行更新,实现目标结果模型的数据汇聚。48.在该实施例中,通过数据的标准化,根据标准接口模型与目标结果模型之间的关联,以主键为依据对数据进行插入、删除和更新操作,只需要根据模型字段和属性进行无逻辑开发,从而避免文件级的更新和删除操作,实现历史数据拉链式存储,能够保留所有数据变化轨迹,同时能够降低数据冗余度,模板化的开发方式降低了开发工作量和运维难度,解决了在hive环境中的数据操作问题。49.具体地,首先,通过模型设计模板,对关键处理字段进行标准化;50.其次,通过预定义数据处理模板,将目标数据和待处理数据进行字段映射,使之保持同样的字段名称和属性;51.最后,按照预定义业务数据处理流程,按部就班的完成数据加工处理过程,实现数据增量拉链存储。52.通过上述方法,主要解决两个问题:53.1.解决在hive环境中进行数据操作时,对update、delete操作支持不友好的问题;54.2.降低hive环境下数据汇聚逻辑开发和运维的难度,实现无逻辑开发,只需要关心模型字段和属性。55.具体地,在该方法中,主要使用以下技术:56.1.通过python进行数据库底层链接和函数的调用,以及业务流程逻辑判断,并将具体的数据处理进行封装隔离,对外提供接口调用,对内进行参数传递;57.2.通过hive-sql实现数据的过滤、清洗、存储、汇总计算以及数据共享。在本发明中主要是用来汇聚数据,按照预定义的压缩算法和存储格式以及业务需求(比如:历史拉链)进行数据的逻辑运算和存储;58.3.特别使用了droptableifexists、createtablexxxasselect*fromaaa、replace、notexists、exists、rename等数据库专用语法结构和函数等。59.具体的,如图2所示,处理过程如下:60.1、抽取业务系统新增的原始数据;61.1.1、把业务系统的原始数据通过etl工具抽取过来;62.1.2、根据目标结果模型his的数据结构对抽取过来的数据进行标准化(主要目的是为了让接口模型与目标模型有相同的字段名称和字段属性),获得标准接口模型cur。63.2、用业务系统新增的数据更新目标模型的数据his。以数据模型主键为依据,将更新数据分为3个主要操作类型。64.2.1、标准接口模型cur有(主键)的数据,目标结果模型his没有(这些主键)的(数据),视为完全新增数据,将cur中这类数据直接insert(插入)到his中;65.2.2、标准接口模型cur有的,目标结果模型his也有,但其他字段属性值不一样的,需要用cur的字段属性值去update(更新)目标模型相同主键的其他字段属性值;66.2.3、标准接口模型cur有的,目标结果模型his也有,而且其他所有字段属性值也一样的,标准接口模型cur这部分主键的数据就需要舍弃,不需要更新his。67.3、目标结果模型his中存量但不需要更新的模型继续保留到新的账期中,即,存量不需要更新的数据 新增更新的数据,组合成新的账期完整的拉链数据。68.其中,标准接口模型cur是与业务系统完全一致的模型,其主要实现过程是拷贝业务系统对应模型结构,在目标端进行复制,然后通过etl工具实现数据在业务系统与目标系统之间的传输。etl同时也要实现数据治理(包括清洗、标准化)的工作。采用这种接口方式,可以在数据抽取完成之后不对业务系统进行依赖,保障数据的完整性和一致性,与业务系统完成解耦。69.在上述实施例中,优选地,基于hive的拉链式模型数据汇聚方法还包括:在对待更新数据模型的数据更新完成后,针对相同主键更新前的数据的数据状态日期进行更新。70.在上述实施例中,优选地,对原始数据进行清洗和标准化具体包括:71.将原始数据中的无关字符删除,实现对原始数据的清洗;72.将原始数据中相应的字段名称和字段属性与目标结果模型保持一致,实现对原始数据的标准化。73.在上述实施例中,优选地,通过有效数据的主键与标准接口模型内关联,确定目标结果模型中的待更新数据模型具体包括:74.通过目标结果模型与标准接口模型的内关联,对比有效数据与标准接口模型的主键数据,以目标结果模型中主键相同的对应数据作为待更新数据模型。75.如图3所示,本发明还提出一种基于hive的拉链式模型数据汇聚系统,应用如上述实施例中任一项公开的基于hive的拉链式模型数据汇聚方法,包括:76.数据抽取模块11,用于对接业务系统,并由业务系统中抽取原始数据;77.数据处理模块12,用于对原始数据进行清洗和标准化,以确定标准接口模型;78.更新确认模块13,用于从目标结果模型中获取当前有效数据,通过有效数据的主键与标准接口模型内关联,确定目标结果模型中的待更新数据模型;79.增量插入模块14,用于将标准接口模型左外关联待更新数据模型,剔除主键重复的数据以生成增量数据,并将增量数据直接插入至目标结果模型中;80.数据舍弃模块15,用于将标准接口模型内关联待更新数据模型,并将原始数据中全字段匹配的数据删除;81.数据更新模块16,用于将待更新数据模型内关联标准接口模型,并采用标准接口模型的数据对待更新数据模型进行更新,实现目标结果模型的数据汇聚。82.在上述实施例中,优选地,基于hive的拉链式模型数据汇聚系统还包括:83.日期更新模块17,用于在对待更新数据模型的数据更新完成后,针对相同主键更新前的数据的数据状态日期进行更新。84.在上述实施例中,优选地,数据处理模块12具体用于:85.将原始数据中的无关字符删除,实现对原始数据的清洗;86.将原始数据中相应的字段名称和字段属性与目标结果模型保持一致,实现对原始数据的标准化。87.在上述实施例中,优选地,更新确认模块13具体用于:88.通过目标结果模型与标准接口模型的内关联,对比有效数据与标准接口模型的主键数据,以目标结果模型中主键相同的对应数据作为待更新数据模型。89.根据上述实施例公开的基于hive的拉链式模型数据汇聚方法,以下采用具体的示例和数据进行具体说明,具体的更新数据变化过程及结果如下。90.假设目标模型his未更新之前的数据为:91.账期主键nameageincomeexpendetl_dt202105311001tom1820005002021/5/30202105311001tom19400010003000/12/31202105311002samon251000045003000/12/3192.当前账期(比如2021/6/1)从生产系统抽取过来的接口数据中:93.1)原始数据94.主键nameageincomeexpendid1001tom20岁45001200id1002samon25100004500id1003lucky25150001000095.2)对原始数据清洗并标准化后的数据96.主键nameageincomeexpend1001tom20450012001002samon251000045001003lucky25150001000097.从his中抽取截止到上个账期仍然生效(etl_dt=30001231),即,当前状态有效的数据98.账期主键nameageincomeexpendetl_dt202105311001tom19400010003000/12/31202105311002samon251000045003000/12/3199.his有效的数据关联cur,结果为待更新数据模型pre100.账期主键nameageincomeexpendetl_dt202105311001tom19400010003000/12/31202105311002samon251000045003000/12/31101.cur左外关联pre,剔除重复主键数据,生成增量数据ins102.主键nameageincomeexpend1003lucky251500010000103.将上述增量数据插入到his中之后结果为104.账期主键nameageincomeexpendetl_dt202106011003lucky2515000100003000/12/31105.cur内关联pre,并进行全字段匹配,生成需要删除的数据106.主键nameageincomeexpend1002samon25100004500107.这部分数据是需要舍弃的。108.pre内关联cur,并用cur的值更新pre109.主键nameageincomeexpend1001tom2045001200110.将上述数据插入到目标模型his中之后结果为111.账期主键nameageincomeexpendetl_dt202106011001tom20450012003000/12/31112.同时要将原来his相同主键的数据状态日期进行更新113.账期主键nameageincomeexpendetl_dt202105311001tom20450012002021/5/31114.最终目标模型his的数据为115.[0116][0117]根据上述示例可知,由目标结果模型的最终数据来看,既保留了历史变化信息—每个主键的变化像一条链子一样,可以顺着日期查看所有变化过程;又能根据状态日期,获取到每个主键的唯一信息,兼顾了数据的唯一性。此即为拉链模型。[0118]以上仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。当前第1页12当前第1页12
技术领域:
:1.本发明涉及数据汇聚
技术领域:
:,尤其涉及一种基于hive的拉链式模型数据汇聚方法以及一种基于hive的拉链式模型数据汇聚系统。
背景技术:
::2.在运营商行业,现已全面推动去o、去mpp等技术场景,引入大数据技术做数据存储、计算和应用。根据数据时效性,按照业务场景划分,主要分实时业务、准实时业务以及离线业务三个场景。不管是哪种业务场景,都要按照一定的频率周期对数据进行操作,其中离线业务场景在大数据技术背景下,普遍采用hive来替代oracle,作为数据主要存储计算的技术方案。但hive是基于hdfs(hadoopdistributedfilesystem,分布式文件系统)文件存储方式,对update、delete支持不太友好,同时也不建议在hive中进行更新、删除操作。技术实现要素:3.针对上述问题,本发明提供了一种基于hive的拉链式模型数据汇聚方法及系统,通过数据的标准化,根据标准接口模型与目标结果模型之间的关联,以主键为依据对数据进行插入、删除和更新操作,只需要根据模型字段和属性进行无逻辑开发,从而避免文件级的更新和删除操作,实现历史数据拉链式存储,能够保留所有数据变化轨迹,同时能够降低数据冗余度,模板化的开发方式降低了开发工作量和运维难度,解决了在hive环境中的数据操作问题。4.为实现上述目的,本发明提供了一种基于hive的拉链式模型数据汇聚方法,包括:5.对接业务系统,并由所述业务系统中抽取原始数据;6.对所述原始数据进行清洗和标准化,以确定标准接口模型;7.由目标结果模型中获取当前有效数据,通过所述有效数据的主键与所述标准接口模型内关联,确定所述目标结果模型中的待更新数据模型;8.将所述标准接口模型左外关联所述待更新数据模型,剔除主键重复的数据以生成增量数据,并将所述增量数据直接插入至所述目标结果模型中;9.将所述标准接口模型内关联所述待更新数据模型,将原始数据中全字段匹配的数据删除;10.将所述待更新数据模型内关联所述标准接口模型,并采用所述标准接口模型的数据对所述待更新数据模型进行更新,实现所述目标结果模型的数据汇聚。11.在上述技术方案中,优选地,基于hive的拉链式模型数据汇聚方法还包括:在对所述待更新数据模型的数据更新完成后,针对相同主键更新前的数据的数据状态日期进行更新。12.在上述技术方案中,优选地,所述标准接口模型与所述业务系统中的数据模型一致,所述标准接口模型用于将所述业务系统中抽取的原始数据复制至所述目标结果模型中。13.在上述技术方案中,优选地,采用etl(extract-transform-load,抽取-转换-加载)工具实现所述业务系统中原始数据的抽取。14.在上述技术方案中,优选地,所述对所述原始数据进行清洗和标准化具体包括:15.将所述原始数据中的无关字符删除,实现对所述原始数据的清洗;16.将所述原始数据中相应的字段名称和字段属性与所述目标结果模型保持一致,实现对所述原始数据的标准化。17.在上述技术方案中,优选地,所述通过所述有效数据的主键与所述标准接口模型内关联,确定所述目标结果模型中的待更新数据模型具体包括:18.通过所述目标结果模型与所述标准接口模型的内关联,对比所述有效数据与所述标准接口模型的主键数据,以所述目标结果模型中主键相同的对应数据作为待更新数据模型。19.本发明还提出一种基于hive的拉链式模型数据汇聚系统,应用如上述技术方案中任一项公开的基于hive的拉链式模型数据汇聚方法,包括:20.数据抽取模块,用于对接业务系统,并由所述业务系统中抽取原始数据;21.数据处理模块,用于对所述原始数据进行清洗和标准化,以确定标准接口模型;22.更新确认模块,用于从目标结果模型中获取当前有效数据,通过所述有效数据的主键与所述标准接口模型内关联,确定所述目标结果模型中的待更新数据模型;23.增量插入模块,用于将所述标准接口模型左外关联所述待更新数据模型,剔除主键重复的数据以生成增量数据,并将所述增量数据直接插入至所述目标结果模型中;24.数据舍弃模块,用于将所述标准接口模型内关联所述待更新数据模型,并将原始数据中全字段匹配的数据删除;25.数据更新模块,用于将所述待更新数据模型内关联所述标准接口模型,并采用所述标准接口模型的数据对所述待更新数据模型进行更新,实现所述目标结果模型的数据汇聚。26.在上述技术方案中,优选地,基于hive的拉链式模型数据汇聚系统还包括:27.日期更新模块,用于在对所述待更新数据模型的数据更新完成后,针对相同主键更新前的数据的数据状态日期进行更新。28.在上述技术方案中,优选地,所述数据处理模块具体用于:29.将所述原始数据中的无关字符删除,实现对所述原始数据的清洗;30.将所述原始数据中相应的字段名称和字段属性与所述目标结果模型保持一致,实现对所述原始数据的标准化。31.在上述技术方案中,优选地,所述更新确认模块具体用于:32.通过所述目标结果模型与所述标准接口模型的内关联,对比所述有效数据与所述标准接口模型的主键数据,以所述目标结果模型中主键相同的对应数据作为待更新数据模型。33.与现有技术相比,本发明的有益效果为:通过数据的标准化,根据标准接口模型与目标结果模型之间的关联,以主键为依据对数据进行插入、删除和更新操作,只需要根据模型字段和属性进行无逻辑开发,从而避免文件级的更新和删除操作,实现历史数据拉链式存储,能够保留所有数据变化轨迹,同时能够降低数据冗余度,模板化的开发方式降低了开发工作量和运维难度,解决了在hive环境中的数据操作问题。附图说明34.图1为本发明一种实施例公开的基于hive的拉链式模型数据汇聚方法的流程示意图;35.图2为本发明一种实施例公开的基于hive的拉链式模型数据汇聚方法的数据变化情况示意图;36.图3为本发明一种实施例公开的基于hive的拉链式模型数据汇聚系统的模块示意图。37.图中,各组件与附图标记之间的对应关系为:38.11.数据抽取模块,12.数据处理模块,13.更新确认模块,14.增量插入模块,15.数据舍弃模块,16.数据更新模块,17.日期更新模块。具体实施方式39.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。40.下面结合附图对本发明做进一步的详细描述:41.如图1所示,根据本发明提供的一种基于hive的拉链式模型数据汇聚方法,包括:42.对接业务系统,并由业务系统中抽取原始数据;43.对原始数据进行清洗和标准化,以确定标准接口模型;44.由目标结果模型中获取当前有效数据,通过有效数据的主键与标准接口模型内关联,确定目标结果模型中的待更新数据模型;45.将标准接口模型左外关联待更新数据模型,剔除主键重复的数据以生成增量数据,并将增量数据直接插入至目标结果模型中;46.将标准接口模型内关联待更新数据模型,将原始数据中全字段匹配的数据删除;47.将待更新数据模型内关联标准接口模型,并采用标准接口模型的数据对待更新数据模型进行更新,实现目标结果模型的数据汇聚。48.在该实施例中,通过数据的标准化,根据标准接口模型与目标结果模型之间的关联,以主键为依据对数据进行插入、删除和更新操作,只需要根据模型字段和属性进行无逻辑开发,从而避免文件级的更新和删除操作,实现历史数据拉链式存储,能够保留所有数据变化轨迹,同时能够降低数据冗余度,模板化的开发方式降低了开发工作量和运维难度,解决了在hive环境中的数据操作问题。49.具体地,首先,通过模型设计模板,对关键处理字段进行标准化;50.其次,通过预定义数据处理模板,将目标数据和待处理数据进行字段映射,使之保持同样的字段名称和属性;51.最后,按照预定义业务数据处理流程,按部就班的完成数据加工处理过程,实现数据增量拉链存储。52.通过上述方法,主要解决两个问题:53.1.解决在hive环境中进行数据操作时,对update、delete操作支持不友好的问题;54.2.降低hive环境下数据汇聚逻辑开发和运维的难度,实现无逻辑开发,只需要关心模型字段和属性。55.具体地,在该方法中,主要使用以下技术:56.1.通过python进行数据库底层链接和函数的调用,以及业务流程逻辑判断,并将具体的数据处理进行封装隔离,对外提供接口调用,对内进行参数传递;57.2.通过hive-sql实现数据的过滤、清洗、存储、汇总计算以及数据共享。在本发明中主要是用来汇聚数据,按照预定义的压缩算法和存储格式以及业务需求(比如:历史拉链)进行数据的逻辑运算和存储;58.3.特别使用了droptableifexists、createtablexxxasselect*fromaaa、replace、notexists、exists、rename等数据库专用语法结构和函数等。59.具体的,如图2所示,处理过程如下:60.1、抽取业务系统新增的原始数据;61.1.1、把业务系统的原始数据通过etl工具抽取过来;62.1.2、根据目标结果模型his的数据结构对抽取过来的数据进行标准化(主要目的是为了让接口模型与目标模型有相同的字段名称和字段属性),获得标准接口模型cur。63.2、用业务系统新增的数据更新目标模型的数据his。以数据模型主键为依据,将更新数据分为3个主要操作类型。64.2.1、标准接口模型cur有(主键)的数据,目标结果模型his没有(这些主键)的(数据),视为完全新增数据,将cur中这类数据直接insert(插入)到his中;65.2.2、标准接口模型cur有的,目标结果模型his也有,但其他字段属性值不一样的,需要用cur的字段属性值去update(更新)目标模型相同主键的其他字段属性值;66.2.3、标准接口模型cur有的,目标结果模型his也有,而且其他所有字段属性值也一样的,标准接口模型cur这部分主键的数据就需要舍弃,不需要更新his。67.3、目标结果模型his中存量但不需要更新的模型继续保留到新的账期中,即,存量不需要更新的数据 新增更新的数据,组合成新的账期完整的拉链数据。68.其中,标准接口模型cur是与业务系统完全一致的模型,其主要实现过程是拷贝业务系统对应模型结构,在目标端进行复制,然后通过etl工具实现数据在业务系统与目标系统之间的传输。etl同时也要实现数据治理(包括清洗、标准化)的工作。采用这种接口方式,可以在数据抽取完成之后不对业务系统进行依赖,保障数据的完整性和一致性,与业务系统完成解耦。69.在上述实施例中,优选地,基于hive的拉链式模型数据汇聚方法还包括:在对待更新数据模型的数据更新完成后,针对相同主键更新前的数据的数据状态日期进行更新。70.在上述实施例中,优选地,对原始数据进行清洗和标准化具体包括:71.将原始数据中的无关字符删除,实现对原始数据的清洗;72.将原始数据中相应的字段名称和字段属性与目标结果模型保持一致,实现对原始数据的标准化。73.在上述实施例中,优选地,通过有效数据的主键与标准接口模型内关联,确定目标结果模型中的待更新数据模型具体包括:74.通过目标结果模型与标准接口模型的内关联,对比有效数据与标准接口模型的主键数据,以目标结果模型中主键相同的对应数据作为待更新数据模型。75.如图3所示,本发明还提出一种基于hive的拉链式模型数据汇聚系统,应用如上述实施例中任一项公开的基于hive的拉链式模型数据汇聚方法,包括:76.数据抽取模块11,用于对接业务系统,并由业务系统中抽取原始数据;77.数据处理模块12,用于对原始数据进行清洗和标准化,以确定标准接口模型;78.更新确认模块13,用于从目标结果模型中获取当前有效数据,通过有效数据的主键与标准接口模型内关联,确定目标结果模型中的待更新数据模型;79.增量插入模块14,用于将标准接口模型左外关联待更新数据模型,剔除主键重复的数据以生成增量数据,并将增量数据直接插入至目标结果模型中;80.数据舍弃模块15,用于将标准接口模型内关联待更新数据模型,并将原始数据中全字段匹配的数据删除;81.数据更新模块16,用于将待更新数据模型内关联标准接口模型,并采用标准接口模型的数据对待更新数据模型进行更新,实现目标结果模型的数据汇聚。82.在上述实施例中,优选地,基于hive的拉链式模型数据汇聚系统还包括:83.日期更新模块17,用于在对待更新数据模型的数据更新完成后,针对相同主键更新前的数据的数据状态日期进行更新。84.在上述实施例中,优选地,数据处理模块12具体用于:85.将原始数据中的无关字符删除,实现对原始数据的清洗;86.将原始数据中相应的字段名称和字段属性与目标结果模型保持一致,实现对原始数据的标准化。87.在上述实施例中,优选地,更新确认模块13具体用于:88.通过目标结果模型与标准接口模型的内关联,对比有效数据与标准接口模型的主键数据,以目标结果模型中主键相同的对应数据作为待更新数据模型。89.根据上述实施例公开的基于hive的拉链式模型数据汇聚方法,以下采用具体的示例和数据进行具体说明,具体的更新数据变化过程及结果如下。90.假设目标模型his未更新之前的数据为:91.账期主键nameageincomeexpendetl_dt202105311001tom1820005002021/5/30202105311001tom19400010003000/12/31202105311002samon251000045003000/12/3192.当前账期(比如2021/6/1)从生产系统抽取过来的接口数据中:93.1)原始数据94.主键nameageincomeexpendid1001tom20岁45001200id1002samon25100004500id1003lucky25150001000095.2)对原始数据清洗并标准化后的数据96.主键nameageincomeexpend1001tom20450012001002samon251000045001003lucky25150001000097.从his中抽取截止到上个账期仍然生效(etl_dt=30001231),即,当前状态有效的数据98.账期主键nameageincomeexpendetl_dt202105311001tom19400010003000/12/31202105311002samon251000045003000/12/3199.his有效的数据关联cur,结果为待更新数据模型pre100.账期主键nameageincomeexpendetl_dt202105311001tom19400010003000/12/31202105311002samon251000045003000/12/31101.cur左外关联pre,剔除重复主键数据,生成增量数据ins102.主键nameageincomeexpend1003lucky251500010000103.将上述增量数据插入到his中之后结果为104.账期主键nameageincomeexpendetl_dt202106011003lucky2515000100003000/12/31105.cur内关联pre,并进行全字段匹配,生成需要删除的数据106.主键nameageincomeexpend1002samon25100004500107.这部分数据是需要舍弃的。108.pre内关联cur,并用cur的值更新pre109.主键nameageincomeexpend1001tom2045001200110.将上述数据插入到目标模型his中之后结果为111.账期主键nameageincomeexpendetl_dt202106011001tom20450012003000/12/31112.同时要将原来his相同主键的数据状态日期进行更新113.账期主键nameageincomeexpendetl_dt202105311001tom20450012002021/5/31114.最终目标模型his的数据为115.[0116][0117]根据上述示例可知,由目标结果模型的最终数据来看,既保留了历史变化信息—每个主键的变化像一条链子一样,可以顺着日期查看所有变化过程;又能根据状态日期,获取到每个主键的唯一信息,兼顾了数据的唯一性。此即为拉链模型。[0118]以上仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。当前第1页12当前第1页12
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。