技术特征:
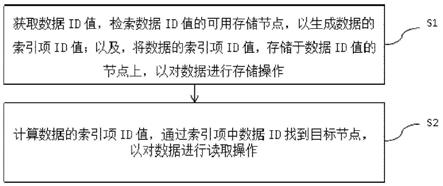
1.一种基于nauru-graph的大规模数据存储和读取方法,其特征在于,包括以下步骤:步骤s1,获取数据id值,检索所述数据id值的可用存储节点,以生成所述数据的索引项id值;以及,将所述数据的索引项id值,存储于所述数据id值的节点上,以对所述数据进行存储操作;步骤s2,计算所述数据的索引项id值,通过所述索引项中数据id找到目标节点,以对所述数据进行读取操作。2.根据权利要求1所述的基于nauru-graph的大规模数据存储和读取方法,其特征在于,所述步骤s1,包括:s1.1,获取数据的存储id,检索可用存储节点,假设当前检索节点id为i,尝试通过节点i写入数据,若节点i中空间充足,则数据存储id为i,并将数据存入节点i中;若节点i中空间不足,检索与节点i相邻的其它节点,按id从小到大进行检索,直到找到合适的节点j,将数据写入对应节点j中,并将数据的存储id置为j,并生成索引项;s1.2,通过s1.1中的账户名/对象名获取数据的初始索引id;s1.3,根据hashmap重置数据的索引id;将s1.2中得到的索引id进行哈希映射得到索引项的id值:k=hash(f)%24,k取[0,23]之间的任意唯一值;s1.4,根据邻接矩阵表,找到当前节点到存储索引项节点k的一条最短路径,在节点k中存入索引项。3.根据权利要求1所述的基于nauru-graph的大规模数据存储和读取方法,其特征在于,所述步骤s2,包括:s2.1,根据数据账户名/对象名计算索引id;通过hashmap找到索引id在nauru-graph中对应的存储索引项节点的id:i=f_id=hash(f)%24。s2.2,通过最短路径到节点i,取出索引项;s2.3,根据索引项中的数据存储id,找到目标节点,取出数据。4.根据权利要求2所述的基于nauru-graph的大规模数据存储和读取方法,其特征在于,所述步骤s1.4,包括:根据邻接矩阵表,找到当前节点到存储索引项节点k的一条最短路径,检查节点k的状态;若正常,则在节点k中存入索引项,若不正常,则检查与节点k相邻的其他节点,按id从小到大进行检查,直到找到合适的节点k
‘
,在k
‘
中存入索引项。5.根据权利要求1所述的基于nauru-graph的大规模数据存储和读取方法,其特征在于,所述步骤s1,还包括:s1.5定期对邻接表中的邻接节点进行检测,如果某个邻接节点失效,则修改对应的行列值,将所述行列值预设一个阈值,表示路径已失效。6.一种基于nauru-graph的大规模数据存储和读取装置,其特征在于,包括:存储模块,用于获取数据id值,检索所述数据id值的可用存储节点,以生成所述数据的索引项id值;以及,将所述数据的索引项id值,存储于所述数据id值的节点上,以对所述数据进行存储操作;读取模块,用于计算所述数据的索引项id值,通过所述索引项中数据id找到目标节点,
以对所述数据进行读取操作。7.根据权利要求6所述的基于nauru-graph的大规模数据存储和读取装置,其特征在于,所述存储模块,包括:生成模块,用于获取数据的存储id,检索可用存储节点,假设当前检索节点id为i,尝试通过节点i写入数据,若节点i中空间充足,则数据存储id为i,并将数据存入节点i中;若节点i中空间不足,检索与节点i相邻的其它节点,按id从小到大进行检索,直到找到合适的节点j,将数据写入对应节点j中,并将数据的存储id置为j,并生成索引项;获取模块,用于通过所述生成模块中的账户名/对象名获取数据的初始索引id;映射模块,用于根据hashmap重置数据的索引id;将所述获取模块中得到的索引id进行哈希映射得到索引项的id值:k=hash(f)%24,k取[0,23]之间的任意唯一值;存入模块,用于根据邻接矩阵表,找到当前节点到存储索引项节点k的一条最短路径,在节点k中存入索引项。8.根据权利要求6所述的基于nauru-graph的大规模数据存储和读取装置,其特征在于,所述读取模块,包括:计算模块,用于根据数据账户名/对象名计算索引id;通过hashmap找到索引id在nauru-graph中对应的存储索引项节点的id:i=f_id=hash(f)%24;节点模块,用于通过最短路径到节点i,取出索引项;目标模块,用于根据索引项中的数据存储id,找到目标节点,取出数据。9.根据权利要求7所述的基于nauru-graph的大规模数据存储和读取装置,其特征在于,所述存入模块,还用于:根据邻接矩阵表,找到当前节点到存储索引项节点k的一条最短路径,检查节点k的状态;若正常,则在节点k中存入索引项,若不正常,则检查与节点k相邻的其他节点,按id从小到大进行检查,直到找到合适的节点k
‘
,在k
‘
中存入索引项。10.根据权利要求6所述的基于nauru-graph的大规模数据存储和读取装置,其特征在于,所述存储模块,还包括:检测模块,用于定期对邻接表中的邻接节点进行检测,如果某个邻接节点失效,则修改对应的行列值,将所述行列值预设一个阈值,表示路径已失效。
技术总结
本发明提出一种基于Nauru-graph的大规模数据存储和读取方法和装置,其中,方法包括:获取数据ID值,检索数据ID值的可用存储节点,以生成数据的索引项ID值;以及,将数据的索引项ID值,存储于数据ID值的节点上,以对数据进行存储操作;步骤S2,计算数据的索引项ID值,通过索引项中数据ID找到目标节点,以对数据进行读取操作。本发明主要通过引入高对称强联通的拓扑结构改进数据存储时,数据分布均衡,系统稳定性和存储效率不能兼得的问题。同时给出了依据实际场景生成高对称强连通拓扑结构的方案。据实际场景生成高对称强连通拓扑结构的方案。据实际场景生成高对称强连通拓扑结构的方案。
技术研发人员:殷瑜雪 戴国浩 汪玉
受保护的技术使用者:清华大学
技术研发日:2021.11.02
技术公布日:2022/3/25
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。