技术特征:
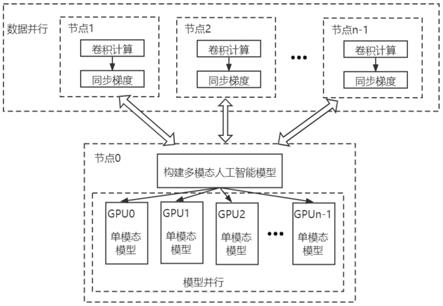
1.一种人工智能模型的快速训练系统,其特征是,包括:至少一个本地计算机终端和n个边缘计算机终端;所述本地计算终端,分别与n个边缘计算终端连接;其中,n为正整数;每个边缘计算终端上均设有至少一个图形处理器gpu;每个本地计算终端上设有n个图形处理器gpu;其中,所述本地计算终端的每个图形处理器上,均部署一个待训练的人工智能模型;本地计算终端的不同图形处理器分别处理不同模态的人工智能模型;本地计算终端的每个图形处理器,在对自身部署的人工智能模型进行训练的过程中,除了卷积操作以外的其他操作,均由本地计算终端的图形处理器来完成;对于卷积操作的处理过程为:每次遇到卷积操作,就将卷积操作传输给对应的边缘计算终端,由边缘计算终端的图形处理器gpu完成卷积操作,并将卷积操作得到的结果回传给本地计算终端对应的图形处理器上。2.如权利要求1所述的一种人工智能模型的快速训练系统,其特征是,所述待训练的人工智能模型,是指:卷积神经网络。3.如权利要求1所述的一种人工智能模型的快速训练系统,其特征是,所述本地计算终端的不同图形处理器分别处理不同模态的人工智能模型,至少包括:本地计算终端的第一个图形处理器,处理用于语音识别的卷积神经网络;本地计算终端的第二个图形处理器,处理用于视频目标对象识别的卷积神经网络;本地计算终端的第三个图形处理器,处理用于图像目标检测的卷积神经网络。4.如权利要求1所述的一种人工智能模型的快速训练系统,其特征是,所述本地计算终端的每个图形处理器,在对自身部署的人工智能模型进行训练的过程中,除了卷积操作以外的其他操作,均由本地计算终端的图形处理器来完成;其中,除了卷积操作以外的其他操作,至少包括:输入层的操作、池化层的操作、全连接层的操作和softmax层的操作。5.如权利要求1所述的一种人工智能模型的快速训练系统,其特征是,所述对于卷积操作的处理过程为:每次遇到卷积操作,就将卷积操作传输给对应的边缘计算终端,由边缘计算终端的图形处理器gpu完成卷积操作,并将卷积操作得到的结果回传给本地计算终端对应的图形处理器上;其中,回传的过程中,还会同步梯度。6.如权利要求1所述的一种人工智能模型的快速训练系统,其特征是,所述对于卷积操作的处理过程为:每次遇到卷积操作,就将卷积操作传输给对应的边缘计算终端,由边缘计算终端的图形处理器gpu完成卷积操作,并将卷积操作得到的结果回传给本地计算终端对应的图形处理器上;其中,本地计算终端的图形处理器是与边缘计算终端一一对应的,也就是说,本地计算终端第i个图形处理器将卷积操作传输给对应的第i个边缘计算终端,由第i个边缘计算终端的图形处理器gpu完成卷积操作,并将卷积操作得到的结果回传给本地计算终端的第i个图形处理器,其中,i为正整数。7.一种人工智能模型的快速训练方法,其特征是,包括:在本地计算终端的每个图形处理器上,均部署一个待训练的人工智能模型;本地计算终端的不同图形处理器分别处理不同模态的人工智能模型;本地计算终端的每个图形处理器,在对自身部署的人工智能模型进行训练的过程中,除了卷积操作以外的其他操作,均由本地计算终端的图形处理器来完成;
对于卷积操作的处理过程为:每次遇到卷积操作,就将卷积操作传输给对应的边缘计算终端,由边缘计算终端的图形处理器gpu完成卷积操作,并将卷积操作得到的结果回传给本地计算终端对应的图形处理器上。8.如权利要求7所述的一种人工智能模型的快速训练方法,其特征是,所述本地计算终端的不同图形处理器分别处理不同模态的人工智能模型,至少包括:本地计算终端的第一个图形处理器,处理用于语音识别的卷积神经网络;本地计算终端的第二个图形处理器,处理用于视频目标对象识别的卷积神经网络;本地计算终端的第三个图形处理器,处理用于图像目标检测的卷积神经网络。9.如权利要求7所述的一种人工智能模型的快速训练方法,其特征是,所述本地计算终端的每个图形处理器,在对自身部署的人工智能模型进行训练的过程中,除了卷积操作以外的其他操作,均由本地计算终端的图形处理器来完成;其中,除了卷积操作以外的其他操作,至少包括:输入层的操作、池化层的操作、全连接层的操作和softmax层的操作。10.如权利要求7所述的一种人工智能模型的快速训练方法,其特征是,所述对于卷积操作的处理过程为:每次遇到卷积操作,就将卷积操作传输给对应的边缘计算终端,由边缘计算终端的图形处理器gpu完成卷积操作,并将卷积操作得到的结果回传给本地计算终端对应的图形处理器上;其中,本地计算终端的图形处理器是与边缘计算终端一一对应的,也就是说,本地计算终端第i个图形处理器将卷积操作传输给对应的第i个边缘计算终端,由第i个边缘计算终端的图形处理器gpu完成卷积操作,并将卷积操作得到的结果回传给本地计算终端的第i个图形处理器。
技术总结
本发明公开了一种人工智能模型的快速训练系统及方法,每个边缘计算终端上均设有至少一个图形处理器;每个本地计算终端上设有n个图形处理器GPU;其中,所述本地计算终端的每个图形处理器上,均部署一个待训练的人工智能模型;本地计算终端的不同图形处理器分别处理不同模态的人工智能模型;本地计算终端的每个图形处理器,在对自身部署的人工智能模型进行训练的过程中,除了卷积操作以外的其他操作,均由本地计算终端的图形处理器来完成;对于卷积操作的处理过程为:每次遇到卷积操作,就将卷积操作传输给对应的边缘计算终端,由边缘计算终端的图形处理器GPU完成卷积操作,并将卷积操作得到的结果回传给本地计算终端对应的图形处理器上。形处理器上。形处理器上。
技术研发人员:耿世超 李小宁 王正中 王琳 张化祥
受保护的技术使用者:山东师范大学
技术研发日:2021.11.01
技术公布日:2022/3/25
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。