1.本发明涉及计算机技术领域,尤其涉及一种算力的计算方法、装置、终端设备和存储介质。
背景技术:
2.随着人工智能领域的快速发展,各种基于深度学习模型的应用不断被开发,如何高效地为用户提供智能服务是it从业者们关心的问题。硬件是其中一个比较关键的问题。目前,国内有许多针对智能计算而开发的npu加速卡,这些加速卡的算力不能简单通过硬件数据进行计算。而且,通过硬件数据计算出来的算力仅是理想值,实际算力需要根据具体的深度学习应用来测试。
3.mlperf是一套用于测量和提高机器学习软硬件性能的通用基准,主要用来测量训练和推理不同神经网络所需要的时间。但是mlperf对部分npu加速卡并不适用,无法对用户任务的算力进行预测。
技术实现要素:
4.本发明意在提供一种算力的计算方法、装置、终端设备和存储介质,以解决现有技术中存在的不足,本发明要解决的技术问题通过以下技术方案来实现。
5.第一个方面,本发明实施例提供一种算力的计算方法,所述方法包括:
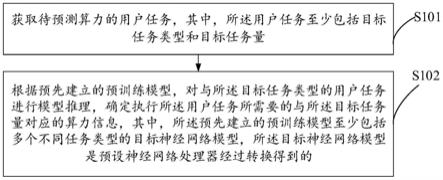
6.获取待预测算力的用户任务,其中,所述用户任务至少包括目标任务类型和目标任务量;
7.根据预先建立的预训练模型,对与所述目标任务类型的用户任务进行模型推理,确定执行所述用户任务所需要的与所述目标任务量对应的算力信息,其中,所述预先建立的预训练模型至少包括多个不同任务类型的目标神经网络模型,所述目标神经网络模型是预设神经网络处理器经过转换得到的,其中,所述预设神经网络处理器包括npu加速卡或cpu与npu加速卡的组合。
8.可选地,所述预先建立的预训练模型通过如下方式得到:
9.获取不同任务类型对应的训练样本集,其中,所述不同任务类型至少包括:图像分类任务、物体识别任务、推荐任务、语音识别任务、文本识别任务或强化学习任务;
10.采用不同的训练样本集对不同的神经网络模型进行训练,得到不同的初始神经网络模型;
11.根据不同类型的预设神经网络处理器,对所述初始神经网络模型进行转换,确定与所述预设神经网络处理器相对应的预训练模型。
12.可选地,所述获取不同任务类型对应的训练样本集,包括:
13.通过imagenet数据库、coco数据库或wikipedia数据库,获取不同任务类型对应的训练样本集。
14.可选地,所述采用不同的训练样本集对不同的神经网络模型进行训练,得到不同
的初始神经网络模型,包括:
15.根据图像分类样本集对vgg19模型进行训练,得到初始图像分类神经网络模型;
16.根据物体识别样本集对yolov3模块进行训练,得到初始物体识别神经网络模型;
17.根据推荐任务样本集对dlrm模型进行训练,得到初始推荐任务神经网络模型;
18.根据语音识别样本集对rnn-t模型进行训练,得到初始语音识别神经网络模型;
19.根据文本识别样本集对bert模型进行训练,得到初始文本识别神经网络模型;
20.根据强化学习样本集对minigo模型进行训练,得到初始强化学习神经网络模型。
21.可选地,所述根据不同类型的预设神经网络处理器,对所述初始神经网络模型进行转换,确定与所述预设神经网络处理器相对应的预训练模型,包括:
22.获取深度学习样本集;
23.采用深度学习框架建立网络架构,其中,所述深度学习框架至少包括tensorflow、pytorch中的一种;
24.根据所述深度学习样本集,对所述不同类型的预设神经网络处理器对应的初始神经网络模型进行训练,得到训练结果;
25.若所述训练结果满足预设条件,则将与不同类型的预设神经网络处理器对应的初始神经网络模型,确定为所述预训练模型。
26.第二个方面,本发明实施例提供一种算力的计算装置,所述装置包括:
27.获取模块,用于获取待预测算力的用户任务,其中,所述用户任务至少包括目标任务类型和目标任务量;
28.计算模块,用于根据预先建立的预训练模型,对与所述目标任务类型的用户任务进行模型推理,确定执行所述用户任务所需要的与所述目标任务量对应的算力信息,其中,所述预先建立的预训练模型至少包括多个不同任务类型的目标神经网络模型,所述目标神经网络模型是预设神经网络处理器经过转换得到的,其中,所述预设神经网络处理器包括npu加速卡或cpu与npu加速卡的组合。
29.可选地,所述装置还包括训练模块,所述训练模块用于:
30.获取不同任务类型对应的训练样本集,其中,所述不同任务类型至少包括:图像分类任务、物体识别任务、推荐任务、语音识别任务、文本识别任务或强化学习任务;
31.采用不同的训练样本集对不同的神经网络模型进行训练,得到不同的初始神经网络模型;
32.根据不同类型的预设神经网络处理器,对所述初始神经网络模型进行转换,确定与所述预设神经网络处理器相对应的预训练模型。
33.可选地,所述训练模块用于:
34.通过imagenet数据库、coco数据库或wikipedia数据库,获取不同任务类型对应的训练样本集。
35.可选地,所述训练模块具体用于:
36.根据图像分类样本集对vgg19模型进行训练,得到初始图像分类神经网络模型;
37.根据物体识别样本集对yolov3模块进行训练,得到初始物体识别神经网络模型;
38.根据推荐任务样本集对dlrm模型进行训练,得到初始推荐任务神经网络模型;
39.根据语音识别样本集对rnn-t模型进行训练,得到初始语音识别神经网络模型;
40.根据文本识别样本集对bert模型进行训练,得到初始文本识别神经网络模型;
41.根据强化学习样本集对minigo模型进行训练,得到初始强化学习神经网络模型。
42.可选地,所述训练模块具体用于:
43.获取深度学习样本集;
44.采用深度学习框架建立网络架构,其中,所述深度学习框架至少包括tensorflow、pytorch中的一种;
45.根据所述深度学习样本集,对所述不同类型的预设神经网络处理器对应的初始神经网络模型进行训练,得到训练结果;
46.若所述训练结果满足预设条件,则将与不同类型的预设神经网络处理器对应的初始神经网络模型,确定为所述预训练模型。
47.第三个方面,本发明实施例提供一种终端设备,包括:至少一个处理器和存储器;
48.所述存储器存储计算机程序;所述至少一个处理器执行所述存储器存储的计算机程序,以实现第一个方面提供的算力的计算方法。
49.第四个方面,本发明实施例提供一种计算机可读存储介质,该计算机可读存储介质中存储有计算机程序,所述计算机程序被执行时实现第一个方面提供的算力的计算方法。
50.本发明实施例包括以下优点:
51.本发明实施例提供的算力的计算方法、装置、终端设备和存储介质,通过获取待预测算力的用户任务,其中,用户任务至少包括目标任务类型和目标任务量;根据预先建立的预训练模型,对与目标任务类型的用户任务进行模型推理,确定执行用户任务所需要的与目标任务量对应的算力信息,其中,预先建立的预训练模型至少包括多个不同任务类型的目标神经网络模型,目标神经网络模型是预设神经网络处理器经过转换得到的,通过本发明实施例中在终端设备上建立预训练模型,这样,在输入用户任务时,不论终端设备上的预设神经网络处理器是什么类型的,都可以对用户任务进行算力预测。
附图说明
52.图1是本发明的一种算力的计算方法实施例的步骤流程图;
53.图2是本发明的又一种算力的计算方法实施例的步骤流程图;
54.图3是本发明的再一种算力的计算方法实施例的步骤流程图;
55.图4是本发明的预训练模型建立的步骤流程图;
56.图5是本发明的一种算力的计算装置实施例的结构框图;
57.图6是本发明的一种终端设备的结构示意图。
具体实施方式
58.需要说明的是,在不冲突的情况下,本技术中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本发明。
59.本发明一实施例提供一种算力的计算方法,用于对用户任务进行算力预测。本实施例的执行主体为算力的计算装置,设置在终端设备上,例如,终端设备至少包括手机终端、平板终端和计算机终端等。
60.参照图1,示出了本发明的一种算力的计算方法实施例的步骤流程图,该方法具体可以包括如下步骤:
61.s101、获取待预测算力的用户任务,其中,用户任务至少包括目标任务类型和目标任务量;
62.具体地,在对终端设备的算力进行预测时,单纯依靠终端设备上的硬件设备npu加速卡进行计算,是不准确,需要一些辅助的软件进行更加精确的计算,因此,mlperf是一套用于测量和提高机器学习软硬件性能的通用基准,主要用来测量训练和推理不同神经网络所需要的时间。mlperf测试集包含了不同领域的benchmark子项,主要包括图像分类、物体识别、翻译、推荐、语音识别、情感分析以及强化学习。
63.但是mlperf对国内的部分npu(neural-network processing unit,神经网络处理器)加速卡并不适用,这些npu加速卡不支持训练,只能进行推理应用。对于推理的预训练模型,需要先进行转换才能使用。同时,mlperf没有其他类型cpu(central processing unit/processor,中央处理器)的运算结果,无法对比不同cpu和npu组合设备的算力区别。因此,本发明实施例提供一种算力的计算方法,终端设备上安装有不同类型的cpu和/或npu加速卡,终端设备获取到待预测算力的用户任务,该用户任务包括目标任务类型和目标任务量。
64.具体地,根据不同的深度学习领域以及用户常用的应用,确定用户任务的目标任务类型,具体方式如下:
65.通过爬取网络新闻和各种人工智能领域的信息,同时对用户进行需求调研,得到深度学习领域的不同任务类型,包括:图像分类、目标识别、推荐、语音、文本和强化学习。
66.示例性的,用户任务为对100张图像进行目标物的识别。
67.s102、根据预先建立的预训练模型,对与目标任务类型的用户任务进行模型推理,确定执行用户任务所需要的与目标任务量对应的算力信息,其中,预先建立的预训练模型至少包括多个不同任务类型的目标神经网络模型,目标神经网络模型是预设神经网络处理器经过转换得到的,其中,所述预设神经网络处理器包括npu加速卡或cpu与npu加速卡的组合。
68.具体的,在终端设备上预先建立的预训练模型,该预训练模型是根据不同的任务类型训练得到的目标神经网络模型,由于在终端设备上会安装预设神经网络处理器,其中,预设神经网络处理器至少包括各种不同类型的cpu和/或npu加速卡,例如,预设神经网络处理器可以是npu加速卡,也可以是cpu和npu加速卡的组合,因此,该目标神经网络模型是不同的cpu或npu加速卡经过转换得到的,该目标神经网络模型是cpu或npu可以识别的。
69.终端设备在获取到用户输入的用户任务后,通过终端设备上的cpu和/或npu上的预训练模型,根据目标任务类型选择对应的神经网络模型,通过该对应的神经网络模型对该用户任务中的目标任务量进行计算,得到用户任务对应的算力信息。
70.其中,该预训练模型在训练过程中,通过不断增加任务量,来计算不同的算力信息,最终,确定能够最大程度利用加速卡的性能,选择稳定运行状态下的最优算力结果的预训练模型。
71.本发明实施例提供的算力的计算方法,通过获取待预测算力的用户任务,其中,用户任务至少包括目标任务类型和目标任务量;根据预先建立的预训练模型,对与目标任务类型的用户任务进行模型推理,确定执行用户任务所需要的与目标任务量对应的算力信
息,其中,预先建立的预训练模型至少包括多个不同任务类型的目标神经网络模型,目标神经网络模型是预设神经网络处理器经过转换得到的,通过本发明实施例中在终端设备上建立预训练模型,这样,在输入用户任务时,不论终端设备上的预设神经网络处理器是什么类型的,都可以对用户任务进行算力预测。
72.本发明又一实施例对上述实施例提供的算力的计算方法做进一步补充说明。
73.可选地,预先建立的预训练模型通过如下方式得到:
74.步骤a1、获取不同任务类型对应的训练样本集,其中,不同任务类型至少包括:图像分类任务、物体识别任务、推荐任务、语音识别任务、文本识别任务或强化学习任务;
75.步骤a2、采用不同的训练样本集对不同的神经网络模型进行训练,得到不同的初始神经网络模型;
76.步骤a3、根据不同类型的预设神经网络处理器,对初始神经网络模型进行转换,确定与预设神经网络处理器相对应的预训练模型。
77.可选地,获取不同任务类型对应的训练样本集,包括:
78.通过imagenet数据库、coco数据库或wikipedia数据库,获取不同任务类型对应的训练样本集。
79.可选地,采用不同的训练样本集对不同的神经网络模型进行训练,得到不同的初始神经网络模型,包括:
80.根据图像分类样本集对vgg19模型进行训练,得到初始图像分类神经网络模型;
81.根据物体识别样本集对yolov3模块进行训练,得到初始物体识别神经网络模型;
82.根据推荐任务样本集对dlrm模型进行训练,得到初始推荐任务神经网络模型;
83.根据语音识别样本集对rnn-t模型进行训练,得到初始语音识别神经网络模型;
84.根据文本识别样本集对bert模型进行训练,得到初始文本识别神经网络模型;
85.根据强化学习样本集对minigo模型进行训练,得到初始强化学习神经网络模型。
86.具体地,收集不同的数据集和构建神经网络结构,具体方式如下:
87.在人工智能领域,不同的应用对于数据的需求差别很大,因此需要针对每个应用找到特定的数据集。同时,需要设置与该不同的数据集即样本集对应的深度神经网络,以发挥加速卡的性能。在本发明实施例中通过imagenet、coco、wikipedia等数据集获取样本集,并存储到数据仓库。
88.在本发明实施例中还需要进行网络模型构建,为每个领域构建不同的深度神经网络模型,即初始神经网络模型:
89.(1)图像分类-vgg19
90.vgg19(visual geometry group)采用连续的几个3x3的卷积核代替alexnet中的较大卷积核(11x11,7x7,5x5),包含了19个隐藏层(16个卷积层和3个全连接层);
91.(2)目标识别-yolo
92.yolo使用了darknet-53的前面的52层,yolov3是一个全卷积网络,大量使用残差的跳层连接,并且为了降低池化带来的梯度负面效果,直接摒弃了pooling,用conv的stride来实现降采样。
93.(3)dlrm深度学习推荐模型
94.dlrm模型用embeddings来处理表示分类数据的稀疏特征,用mlp来处理稠密特征,
然后将这些特征显示的用24中的统计技术进行交叉。最后通过另一个mlp后处理交叉结果来找到事件概率。
95.(4)文本-bert(bidirectional encoder representation from transformers,文本训练模型)
96.bert是一个预训练的语言表征模型。它采用新的mlm结构,以致能生成深度的双向语言表征。
97.(5)语音-rnn-t强大的端到端语音识别框架
98.rnn-t使得模型具有了端到端联合优化、具有语言建模能力、便于实现online语音识别等突出的优点,更加适合语音任务。
99.(6)强化学习-minigo
100.minigo用的是强化学习,解决的是策略问题,分析当前所处环境,依据现在已有的经验,选择价值更高的行为,此后将会在一定时间内得到回馈。
101.如图4所示,图4是本发明的预训练模型建立的步骤流程图;可选地,根据不同类型的预设神经网络处理器,对初始神经网络模型进行转换,确定与预设神经网络处理器相对应的预训练模型,包括:
102.步骤b1、获取深度学习样本集;
103.步骤b2、采用深度学习框架建立网络架构,其中,深度学习框架至少包括tensorflow、pytorch中的一种;
104.步骤b3、根据深度学习样本集,对不同类型的预设神经网络处理器对应的初始神经网络模型进行训练,得到训练结果;
105.步骤b4、若训练结果满足预设条件,则将与不同类型的预设神经网络处理器对应的初始神经网络模型,确定为预训练模型。
106.具体的,在本发明实施例中采用的深度学习框架有tensorflow、pytorch等。部分的npu加速卡不支持训练,而推理过程支持绝大多数的深度学习框架,因此使用常用的深度学习框架和英伟达显卡进行训练,待训练效果达到目标质量后,保留预训练模型。
107.图2是本发明的又一种算力的计算方法实施例的步骤流程图,如图2所示,本发明实施例提出了一种基于模型推理的npu加速卡算力测试方法,在组合设备即终端设备上安装有不同类型的cpu和npu加速卡,其中,cpu可以包括arm处理芯片或x86处理芯片,在该组合设备上安装有预训练模型,其中该预训练模型是对初始神经网络模型经过npu加速技术栈进行转换后得到。
108.组合设备通过得到的预训练模型进行模型推理计算,在不断改变输入数值的情况下,以能够最大程度利用加速卡的性能,最后选择稳定运行状态下的最优算力结果。
109.本发明实施例提供的算力计算方法包括定义任务类型,根据实际应用确定深度学习的应用领域,比如图像分类、目标识别、推荐、语音、文本和强化学习;收集相关任务需要的数据集和并设计相应的网络模型;使用英伟达加速卡进行模型训练,存储预训练模型;使用加速栈工具包将预训练模型转化,并使用不同cpu和npu加速卡组合设备,进行模型推理并收集算力信息。
110.图3是本发明的再一种算力的计算方法实施例的步骤流程图,如图3所示,该算力的计算方法包括:
111.s1、任务定义,根据不同的深度学习领域以及用户常用的应用,确定相应的智能应用;
112.s2、对于不同的深度学习模型,需要收集不同的数据集和构建相应的神经网络结构;
113.s3、使用英伟达显卡进行深度学习模型训练,根据构建的深度神经网络使用数据集进行训练,达到相应的目标质量,并存储预训练模型;
114.s4、使用npu加速栈转换预训练模型,并在不同的cpu和npu加速卡设备中进行推理运算,收集算力信息。
115.具体地,不同的npu加速卡有不同的加速栈来对初始神经网络模型进行转换,目的是将初始神经网络模型转换成加速卡能够运行的内容,即得到预训练模型。
116.首先使用不同的cpu和npu加速卡进行组合,形成特定的服务设备,其中cpu有分别以x86和arm为架构的不同芯片,npu加速卡也有各种国产品牌;接着使用所选npu加速卡的特定加速栈进行转化;然后运行模型,在算力计算过程中,不断调整模型的输入,以能够最大程度利用加速卡的性能,最后选择稳定运行状态下的最优算力结果。
117.需要说明的是,对于方法实施例,为了简单描述,故将其都表述为一系列的动作组合,但是本领域技术人员应该知悉,本发明实施例并不受所描述的动作顺序的限制,因为依据本发明实施例,某些步骤可以采用其他顺序或者同时进行。其次,本领域技术人员也应该知悉,说明书中所描述的实施例均属于优选实施例,所涉及的动作并不一定是本发明实施例所必须的。
118.本发明实施例提供的算力的计算方法,通过获取待预测算力的用户任务,其中,用户任务至少包括目标任务类型和目标任务量;根据预先建立的预训练模型,对与目标任务类型的用户任务进行模型推理,确定执行用户任务所需要的与目标任务量对应的算力信息,其中,预先建立的预训练模型至少包括多个不同任务类型的目标神经网络模型,目标神经网络模型是预设神经网络处理器经过转换得到的,通过本发明实施例中在终端设备上建立预训练模型,这样,在输入用户任务时,不论终端设备上的预设神经网络处理器是什么类型的,都可以对用户任务进行算力预测。
119.本发明另一实施例提供一种算力的计算装置,用于执行上述实施例提供的算力的计算方法。
120.参照图5,示出了本发明的一种算力的计算装置实施例的结构框图,该装置具体可以包括如下模块:获取模块501和计算模块502,其中:
121.获取模块501用于获取待预测算力的用户任务,其中,用户任务至少包括目标任务类型和目标任务量;
122.计算模块502用于根据预先建立的预训练模型,对与目标任务类型的用户任务进行模型推理,确定执行用户任务所需要的与目标任务量对应的算力信息,其中,预先建立的预训练模型至少包括多个不同任务类型的目标神经网络模型,目标神经网络模型是预设神经网络处理器经过转换得到的。
123.本发明实施例提供的算力的计算装置,通过获取待预测算力的用户任务,其中,用户任务至少包括目标任务类型和目标任务量;根据预先建立的预训练模型,对与目标任务类型的用户任务进行模型推理,确定执行用户任务所需要的与目标任务量对应的算力信
息,其中,预先建立的预训练模型至少包括多个不同任务类型的目标神经网络模型,目标神经网络模型是预设神经网络处理器经过转换得到的,通过本发明实施例中在终端设备上建立预训练模型,这样,在输入用户任务时,不论终端设备上的预设神经网络处理器是什么类型的,都可以对用户任务进行算力预测。
124.本发明又一实施例对上述实施例提供的算力的计算装置做进一步补充说明。
125.可选地,装置还包括训练模块,训练模块用于:
126.获取不同任务类型对应的训练样本集,其中,不同任务类型至少包括:图像分类任务、物体识别任务、推荐任务、语音识别任务、文本识别任务或强化学习任务;
127.采用不同的训练样本集对不同的神经网络模型进行训练,得到不同的初始神经网络模型;
128.根据不同类型的预设神经网络处理器,对初始神经网络模型进行转换,确定与预设神经网络处理器相对应的预训练模型。
129.可选地,训练模块用于:
130.通过imagenet数据库、coco数据库或wikipedia数据库,获取不同任务类型对应的训练样本集。
131.可选地,训练模块具体用于:
132.根据图像分类样本集对vgg19模型进行训练,得到初始图像分类神经网络模型;
133.根据物体识别样本集对yolov3模块进行训练,得到初始物体识别神经网络模型;
134.根据推荐任务样本集对dlrm模型进行训练,得到初始推荐任务神经网络模型;
135.根据语音识别样本集对rnn-t模型进行训练,得到初始语音识别神经网络模型;
136.根据文本识别样本集对bert模型进行训练,得到初始文本识别神经网络模型;
137.根据强化学习样本集对minigo模型进行训练,得到初始强化学习神经网络模型。
138.可选地,训练模块具体用于:
139.获取深度学习样本集;
140.采用深度学习框架建立网络架构,其中,深度学习框架至少包括tensorflow、pytorch中的一种;
141.根据深度学习样本集,对不同类型的预设神经网络处理器对应的初始神经网络模型进行训练,得到训练结果;
142.若训练结果满足预设条件,则将与不同类型的预设神经网络处理器对应的初始神经网络模型,确定为预训练模型。
143.对于装置实施例而言,由于其与方法实施例基本相似,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
144.本发明实施例提供的算力的计算装置,通过获取待预测算力的用户任务,其中,用户任务至少包括目标任务类型和目标任务量;根据预先建立的预训练模型,对与目标任务类型的用户任务进行模型推理,确定执行用户任务所需要的与目标任务量对应的算力信息,其中,预先建立的预训练模型至少包括多个不同任务类型的目标神经网络模型,目标神经网络模型是预设神经网络处理器经过转换得到的,通过本发明实施例中在终端设备上建立预训练模型,这样,在输入用户任务时,不论终端设备上的预设神经网络处理器是什么类型的,都可以对用户任务进行算力预测。
145.本发明再一实施例提供一种终端设备,用于执行上述实施例提供的算力的计算方法。
146.图6是本发明的一种终端设备的结构示意图,如图6所示,该终端设备包括:至少一个处理器601和存储器602;
147.存储器存储计算机程序;至少一个处理器执行存储器存储的计算机程序,以实现上述实施例提供的算力的计算方法。
148.本实施例提供的终端设备,通过获取待预测算力的用户任务,其中,用户任务至少包括目标任务类型和目标任务量;根据预先建立的预训练模型,对与目标任务类型的用户任务进行模型推理,确定执行用户任务所需要的与目标任务量对应的算力信息,其中,预先建立的预训练模型至少包括多个不同任务类型的目标神经网络模型,目标神经网络模型是预设神经网络处理器经过转换得到的,通过本发明实施例中在终端设备上建立预训练模型,这样,在输入用户任务时,不论终端设备上的预设神经网络处理器是什么类型的,都可以对用户任务进行算力预测。
149.本技术又一实施例提供一种计算机可读存储介质,该计算机可读存储介质中存储有计算机程序,计算机程序被执行时实现上述任一实施例提供的算力的计算方法。
150.根据本实施例的计算机可读存储介质,通过获取待预测算力的用户任务,其中,用户任务至少包括目标任务类型和目标任务量;根据预先建立的预训练模型,对与目标任务类型的用户任务进行模型推理,确定执行用户任务所需要的与目标任务量对应的算力信息,其中,预先建立的预训练模型至少包括多个不同任务类型的目标神经网络模型,目标神经网络模型是预设神经网络处理器经过转换得到的,通过本发明实施例中在终端设备上建立预训练模型,这样,在输入用户任务时,不论终端设备上的预设神经网络处理器是什么类型的,都可以对用户任务进行算力预测。
151.应该指出,上述详细说明都是示例性的,旨在对本技术提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语均具有与本技术所属技术领域的普通技术人员的通常理解所相同的含义。
152.需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本技术的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式。此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
153.需要说明的是,本技术的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的术语在适当情况下可以互换,以便这里描述的本技术的实施方式能够以除了在这里图示或描述的那些以外的顺序实施。
154.此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含。例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
155.为了便于描述,在这里可以使用空间相对术语,如“在
……
之上”、“在
……
上方”、“在
……
上表面”、“上面的”等,用来描述如在图中所示的一个器件或特征与其他器件或特
征的空间位置关系。应当理解的是,空间相对术语旨在包含除了器件在图中所描述的方位之外的在使用或操作中的不同方位。例如,如果附图中的器件被倒置,则描述为“在其他器件或构造上方”或“在其他器件或构造之上”的器件之后将被定位为“在其他器件或构造下方”或“在其他器件或构造之下”。因而,示例性术语“在
……
上方”可以包括“在
……
上方”和“在
……
下方”两种方位。该器件也可以其他不同方式定位,如旋转90度或处于其他方位,并且对这里所使用的空间相对描述作出相应解释。
156.在上面详细的说明中,参考了附图,附图形成本文的一部分。在附图中,类似的符号典型地确定类似的部件,除非上下文以其他方式指明。在详细的说明书、附图及权利要求书中所描述的图示说明的实施方案不意味是限制性的。在不脱离本文所呈现的主题的精神或范围下,其他实施方案可以被使用,并且可以作其他改变。
157.以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。