1.本发明涉及一种声音空间化方法。
2.本发明特别适用于汽车背景下的立体声再现领域。
背景技术:
3.声音空间化旨在在听者周围创造声音环境,使他们感觉自己所听到的声音来自他们所处环境中的某一精确点。
4.营造声音空间化方法,包括幅度平移、延迟平移。
5.幅度平移在于控制(jouer sur)各种声源(通常是扬声器)的强度,从而建立一个虚拟声源,通过改变这些声源的强度,使该虚拟声源在环境中移位。赫尔辛基理工大学声学和音频信号处理实验室的ville pulkki在“virtual sound source positioning using vector base amplitude panning [使用矢量基幅度平移的虚拟声源定位]”中提出:vbap(矢量基幅度平移)方法可使用任何数量的声源在二维或三维上重新建立声场。
[0006]
延迟平移考虑了双耳时间差(itd),给人一种声音来源位于相对于听者头部的精确角度的感觉。该方法适用于位于用户头部对称平面两侧的两个声源(通常是扬声器)。对这两个扬声器之一的广播信号施加延迟,可在对称平面外创建虚拟源。延迟越大,虚拟源与对称平面形成的角度就越大。
[0007]
其他声音空间化的方法包括,例如,控制直达声与混响声之间的比率,以产生距离感,或者近感;还可使用低通滤波器模拟空气对高频的吸收来提供深度感。
[0008]
然而,大多数现有的声音空间化技术对扬声器与听者之间的相对定位误差很敏感。因此,在声音空间化方法的设置期间,轻微的设置误差就会产生对虚拟源位置的错误感知。
[0009]
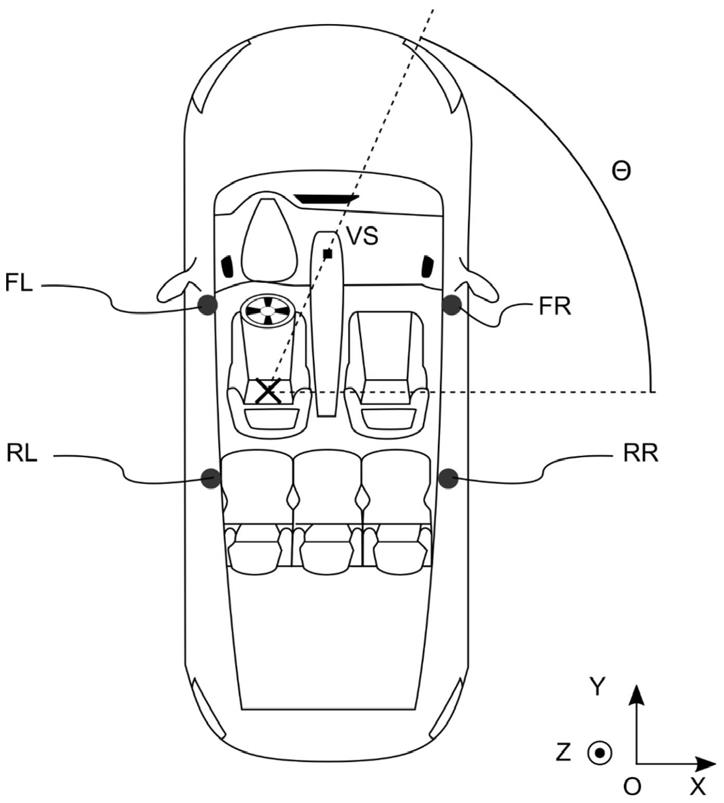
图1示出了其中布置有以下四个扬声器的车辆乘客舱:左前扬声器fl、右前扬声器fr、左后扬声器rl和右后扬声器rr。
[0010]
坐在驾驶员座椅上的听者的头部位置用十字符号表示。
[0011]
图2a以笛卡尔图和极坐标图的形式示出了根据试图要创建的虚拟源vs(其在图1中用实心方块符号表示)的角位置θ而将施加于由每一个扬声器广播的信号的幅度:
‑ꢀ
将施加于左前扬声器fl的幅度曲线被表示为虚线;
‑ꢀ
将施加于右前扬声器fr的幅度曲线被表示为实线;
‑ꢀ
将施加于左后扬声器rl的幅度曲线被表示为全点线;
‑ꢀ
将施加于右后扬声器rr的幅度曲线被表示为点划线。
[0012]
虚拟源vs的角位置θ的定义为由穿过听者头部和虚拟源vs的直线与如图1中定义的轴线ox所形成的角度。
[0013]
位于图2a上部的笛卡尔图或极坐标图示出了对于如图1所示的听者头部位置所要施加的幅度。
[0014]
位于下部的笛卡尔图或极坐标图示出了对于听者头部位置相对于其在图1中的位
置向左偏移十厘米(即在负x轴方向上偏移十厘米)的情况所要施加的幅度。
[0015]
以相同的方式,图2b以笛卡尔图和极坐标图的形式示出了根据试图要创造的虚拟源vs的角位置θ以及图2a所示的幅度而要施加于由每一个扬声器广播信号的延迟。
[0016]
线的约定与图2a中的相同。
[0017]
同样,位于图2b上部的笛卡尔图或极坐标图示出了对于如图1所示的听者头部位置所要施加的延迟。
[0018]
位于下部的笛卡尔图或极坐标图示出了对于听者头部位置相对于其在图1中的位置向左偏移十厘米(即在负x轴方向上偏移十厘米)的情况所要施加的延迟。
[0019]
例如在图2a中可以观察到,基于听者头部位置在负x轴方向上对十厘米误差进行积分,创建的角位置为70
°
的虚拟源(在下部的笛卡尔图上对应于左前和右前扬声器的曲线的交点),根据上部的笛卡尔图,实际上对应于75
°
的角位置。听者头部位置处的十厘米误差会引起虚拟源角位置的5
°
角偏移。因此,驾驶员感知到75
°
角位置的虚拟源,而不是最初期望的70
°
角位置。
技术实现要素:
[0020]
本发明涉及一种声音空间化方法,该方法包括:
‑ꢀ
确定数字处理参数的步骤,这些数字处理参数将被施加于一组至少两个扬声器广播的声音信号,以便在期望位置再现虚拟声源;
‑ꢀ
通过扬声器恢复声音信号的步骤,在该步骤中将这些数字处理参数施加于这些声音信号;根据本发明,该声音空间化方法还包括:
‑ꢀ
定义由一组n个点定义的轨迹的步骤,所述轨迹的两个连续点通过曲线连接在一起;
‑ꢀ
定位步骤,在该步骤期间,在所述轨迹上定义虚拟声源的期望位置。
[0021]
在实施例中,轨迹具有折线形状,连接这些点的曲线是线段。
[0022]
在实施例中,对虚拟声源的定位是通过与轨迹的任何点x唯一相关联并由下式定义的位置索引ipx来执行的:[math 1]其中,α为0至1之间的实数,j为1至n-1之间的整数。
[0023]
在实施例中,虚拟声源沿轨迹的定位由操作员手动执行。
[0024]
在实施例中,在定位步骤中以如下方式定义虚拟声源的位置:
‑ꢀ
通过针对轨迹的每条曲线确定在线段与穿过定义听者位置的点和虚拟声源的位置目标的直线之间是否存在交点,来确定轨迹上的虚拟声源的位置目标的一组投影图像,所述交点随后可定义潜在虚拟声源;
‑ꢀ
如果至少存在一个潜在虚拟声源,则将虚拟声源的位置定义为与虚拟声源的位置目标的距离最小的潜在虚拟声源。
[0025]
在实施例中,在不存在潜在虚拟声源的情况下,执行以下动作之一:
‑ꢀ
将虚拟声源定位在预先定义的默认位置,比如在听者前方一米处;
‑ꢀ
将虚拟声源定位在轨迹上的某一点,该点相对于听者的角位置最接近虚拟声源的位置目标的角位置;
‑ꢀ
修改轨迹,以覆盖更宽的关注区域,但包含与初始轨迹一样的点。
[0026]
在实施例中,根据以下关系式预定义虚拟声源位置在总移动持续时间t
总
内沿着轨迹的移动:[math 2]其中,t是指定时间的变量,在0至t
总
之间。
[0027]
本发明还涉及一种用于实施根据本发明的声音空间化方法的设备。根据本发明,该设备包括:
‑ꢀ
用于定义轨迹的装置;
‑ꢀ
用于确定虚拟声源在所述轨迹上的期望位置的装置;
‑ꢀ
用于确定数字处理参数的装置,这些数字处理参数将被施加于一组至少两个扬声器广播的声音信号,以便在期望位置产生虚拟声源;
‑ꢀ
用于将数字处理参数施加于声音信号的装置;
‑ꢀ
用于恢复已经施加了数字处理参数的声音信号的装置。
附图说明
[0028]
[图1]示出了包括四个扬声器的车辆乘客舱,这些扬声器被配置为再现虚拟声源。
[0029]
[图2a]以笛卡尔图和极坐标图的形式示出了对于两个不同的驾驶员头部位置,根据虚拟源的期望角位置而施加于图1中车辆扬声器广播的信号的幅度。
[0030]
[图2b]以笛卡尔图和极坐标图的形式示出了对于两个不同的驾驶员头部位置,根据虚拟源的期望角位置而施加于图1中车辆扬声器广播的信号的延迟。
[0031]
[图3]为根据本发明的方法的示意性表示。
[0032]
[图4]示出了具有折线形状的轨迹。
[0033]
[图5a]示出了与汽车在水平面中的轮廓大致对应的轨迹t。
[0034]
[图5b]示出了在水平面中围绕汽车布置的大致圆形的轨迹t。
[0035]
[图6a]示出了轨迹t和车辆,其中轨迹可覆盖180
°
的角扇区,并覆盖与驾驶员相距大约五米的距离。
[0036]
[图6b]示出了图6a的轨迹t。
具体实施方式
[0037]
在下文中,本发明将在汽车背景下进行描述,特别是在车辆乘客舱内的声音空间化框架中进行描述。然而,本领域技术人员将理解,本发明可以适用于除车辆环境之外的环境。
[0038]
车辆的乘客舱包括一组至少两个扬声器。在所示的示例中,保留了四个扬声器的数量,但这并不限制本发明,本发明可以适用于不同数量的扬声器。
[0039]
参考图3,根据本发明的方法100包括定义轨迹的第一步骤101。
[0040]
在该第一步骤101中,在平行于地面的平面中定义了用于定义轨迹t的一组n个点pi。在此,索引i是范围从1至n的有限整数。
[0041]
在此,轨迹t为折线的形状。本领域技术人员在阅读下文时将理解,该折线形状并不限制本发明,并且可以使用其他类型的轨迹,例如轨迹的两个点可以通过圆弧连接在一起。
[0042]
每个点pi由其在平面中的坐标(即x坐标pi
x
和y坐标piy)定义,以矩阵格式书写:[math 3]当且仅当存在一(α;j)对满足以下条件时,任何点x都属于轨迹t:[math 4]其中,α为0至1之间的实数,j为1至n-1之间的整数。
[0043]
图4示出了由七个点定义的轨迹t,并且任何点x的位置由一对(0.6;4)指定。
[0044]
位置索引ipx有利地被定义为唯一引用轨迹t上的任何点x:[math 5]可以通过应用以下公式找到点x的坐标:[math 6]其中,e(.) 指定整数部分运算符。
[0045]
有利地,轨迹的点pi的放置方式使车辆的显着元素(如例如方向盘中心或变速杆)对应于位置索引ipx的显着值,例如等于0.1或0.5的位置索引ipx。
[0046]
方法100还包括在轨迹t上定位虚拟源vs的第二步骤102。
[0047]
虚拟源vs在轨迹t上的定位是通过操作员手动或者自动(如下文将详细描述的)设置位置索引ipx来执行的。
[0048]
方法100还包括确定数字处理参数的第三步骤103,这些数字处理参数被施加于扬声器广播的信号。
[0049]
确定数字处理参数是借助于声音空间化领域的技术人员已知的技术来执行的,如延迟平移和幅度平移。
[0050]
数字处理参数可以包括例如增益、延迟、滤波器,特别取决于源vs的位置和车辆乘客舱的几何形状。
[0051]
方法100还包括基于在前一步骤中确定的参数,通过扬声器来恢复声音信号的第四步骤104,这些参数被施加于扬声器广播的信号。
[0052]
现在将在三个特定实施例的框架内详细描述本发明。
[0053]
在第一实施例中,本发明适用于静态声音的背景下。
[0054]
术语“静态声音”是指在车辆的使用期间假设其声音定位或声音场景不变的声音。
[0055]
这可以是例如:
‑ꢀ
从车辆的cd-rom或mp3播放器聆听的音乐,对于这种情况,声音场景通常放置成朝向车辆的前方;
‑ꢀ
与驾驶相关的声音信号,例如位于方向盘附近的指示音。
[0056]
在这些情况下,寻求特定的声音场景目标,并有利地使用轨迹t,以允许第一操作员通过改变位置索引ipx来手动放置虚拟源vs,而第二操作员从车辆内部评估声音再现。
[0057]
根据所寻求的目标,第二操作员可以无差别地坐在驾驶员座椅或乘客座椅上。
[0058]
轨迹t的定义方式为:它覆盖相对于第二操作员而言足够大的角扇区,以允许他们评估虚拟源vs的广泛位置,从而选择一个他们感觉是最相关的、即最符合所寻求声音场景目标的位置。
[0059]
有利地,轨迹t还允许第一操作员以调整由第二操作员感知的混响的方式改变从虚拟源vs到所述第二操作员的径向距离。
[0060]
然后,第一操作员例如通过借助于界面运算器改变(α;j)对或更简单地改变与轨迹t上的位置唯一相关联的位置索引ipx使虚拟源vs沿轨迹t移位。
[0061]
虚拟源vs的移位可以连续地或离散地执行。
[0062]
虚拟源vs停在被第二操作员判断为与所寻求的目标最相关的位置。
[0063]
然后执行确定数字处理参数的步骤103和通过扬声器恢复信号的步骤104。
[0064]
在第二实施例中,本发明适用于实时情况。
[0065]
这需要创建声音的声音空间化,在车辆的使用期间,希望声音定位是可变的。
[0066]
例如,可以发出声音信号以警告驾驶员车辆环境中的潜在危险,声音定位能够改变以适应所述环境中的危险的位置。例如,可用于警告驾驶员在盲点中存在行人或车辆。
[0067]
在该实施例中,声音定位不是先验地定义,能够随时间变化,例如可跟随行人或车辆的位移。
[0068]
因此,在该实施例中,如下文将看到的,虚拟源vs的位置是近似的,以便考虑由辅助系统(通常是高级驾驶员辅助系统(adas))提供的参数p。
[0069]
在此,轨迹t被定义为:根据其中应该近似地找到虚拟声源vs的假定区域,尽可能宽地覆盖角扇区和到驾驶员的距离。
[0070]
举例来说,参考图5a,定义了大体上与汽车在水平面中的轮廓相对应的轨迹t。
[0071]
在所示的示例中,点pi对应于车辆的显着元素,以便于操作员实施该方法,特别地:ipx = 0;左尾灯;ipx = 0,5;右前灯;ipx = 1;汽车的后中心点;轨迹t也可以具有大体圆形的形状,如图5b所示。
[0072]
这两个示例使得可以覆盖360
°
的角扇区。
[0073]
参考图6a和图6b,轨迹t被定义为可以覆盖180
°
的角扇区,角扇区的最远端距离驾
驶员大约五米。
[0074]
为了定位虚拟源vs,由辅助系统提供参数p以建立虚拟声源vs的位置目标vs
obj
。
[0075]
举例来说,虚拟声源的位置目标vs
obj
大体上对应于位于车辆环境中的行人的位置(此位置由传感器提供)。
[0076]
下文详细描述对虚拟源vs的定位。
[0077]
在图6a和图6b中,虚拟声源的位置目标vs
obj
由菱形表示。
[0078]
十字表示坐在驾驶员座椅上的听者的头部位置d。
[0079]
在定位虚拟源vs的步骤102期间,确定虚拟声源的位置目标vs
obj
在轨迹t上的投影。
[0080]
对于轨迹t中末端为pi和pi 1的每个线段,确定在所述线段与连接听者位置和虚拟声源的位置目标vs
obj
的线段之间是否存在交点。因此,每个交点定义了潜在虚拟源vsi,从而获得定义m个潜在虚拟源的一组m个交点。
[0081]
在图6a和图6b所示的情况中,出现一组四个潜在虚拟源vs1、vs2、vs3、vs4,用正方形符号表示。
[0082]
然后将虚拟源vs的位置确定为索引为k的潜在虚拟源vsk,该潜在虚拟源具有与虚拟声源的位置目标vs
obj
的最小距离,即满足:[math 7]在本说明书中,如此获得的虚拟源vsk称为虚拟声源的位置目标vs
obj
在轨迹t上的“投影”。
[0083]
在下文中,虚拟源vs的位置索引ipvs定义如下:[math 8]其中,索引x是指相关联点的x坐标,并且在此,索引y是指相关联点的y坐标。
[0084]
参考图6b,如此确定的虚拟源是虚拟源vs2。
[0085]
在轨迹t与将驾驶员d连接至虚拟声源vs的位置目标vs
obj
的虚拟线之间不存在交点的情况下,可以考虑:
‑ꢀ
不实施随后的步骤103和104,将虚拟声源vs的位置目标vs
obj
视为在关注区域之外;
‑ꢀ
将声音定位在默认位置,例如在听者前方;
‑ꢀ
在最接近虚拟声源vs的位置目标vs
obj
的角位置(相对于驾驶员的)生成声音;
‑ꢀ
人工修改轨迹,以覆盖更宽的关注区域,但包含与初始轨迹一样的点。
[0086]
一旦确定了虚拟源vs,随后执行确定数字处理参数的步骤103和通过扬声器恢复
信号的步骤104。
[0087]
当然,虚拟源vs的位置能够根据虚拟声源vs的位置目标vs
obj
的变化(例如,位移)而随时间变化,因此,在实施根据本发明的方法中,定位虚拟源vs的第二步骤102和后续步骤被迭代地应用。
[0088]
在第三实施例中,本发明适用于虚拟源vs沿轨迹t的预定义移位。
[0089]
在该实施例中,在实施根据本发明的方法中,在第二步骤102中定位虚拟源vs、以及确定数字处理参数和通过扬声器恢复声音信号的后续步骤103和104被迭代地应用,虚拟源vs的位置是时间的函数。
[0090]
虚拟源vs的起始位置(即对应于移动的开始)和到达位置(即对应于移动的结束)是任意定义的轨迹的任何两个点,例如起始位置对应于点p1,并且到达位置对应于点pn。
[0091]
在该实施例中,虚拟源vs沿着轨迹t的位置索引ipx和移位速度sp由以下公式给出:[math 9]其中:
‑ꢀ
t是表示时间的变量,在0至t
总
之间;
‑ꢀ
t
总
表示移动总持续的时间;
‑ꢀ
e(.) 为整数部分运算符。
[0092]
这导致移位速度sp在轨迹t的两个连续点之间随时间变化,就像恒定阶梯函数一样,并且两个点之间的距离越大,移位速度就越大。
[0093]
在此,位置索引的时间变化被认为是与时间成线性关系的,但本领域技术人员将理解该线性关系可以具有更通用的形式:[math 10]其中,f为任何先验函数。
[0094]
应当注意的是,虽然本发明的实施方式在上文中仅用单个轨迹进行描述,但是在第一步骤101期间可以定义几个轨迹。
[0095]
然后通过单独考虑每一个轨迹上的定位,在定义的一组轨迹上考虑虚拟源vs的定位。
[0096]
例如,在上文的第二实施例中描述的实时声音空间化的情况下,将所有轨迹看做一个整体,在一组轨迹上执行对虚拟声源vs的位置目标vs
obj
的投影,并且通过考虑最接近虚拟声源vs的位置目标vs
obj
的潜在虚拟源来确定虚拟源的位置。
[0097]
本发明还涉及一种用于实施根据本发明的方法的声音空间化设备。
[0098]
根据本发明的声音空间化设备包括用于以下操作的装置:
‑ꢀ
定义一组定义轨迹t的点;
‑ꢀ
在轨迹t上定位虚拟源vs;
‑ꢀ
确定数字处理参数,这些数字处理参数被施加于扬声器广播的信号;
‑ꢀ
恢复声音信号。
[0099]
本发明还可在听者的环境中精确地放置虚拟声源,以创建声音空间化。
[0100]
使用轨迹使得本发明可适用于各种应用,特别是驾驶员辅助静态声音、作为来自高级驾驶员辅助系统的补充警报、或者沿着预定义轨迹移位的声源。
[0101]
应当注意的是,虽然在上文描述的内容中,在定义轨迹的第一步骤101中定义了轨迹,但是如果需要,可以在整个方法中动态调整轨迹,实时使用本发明。
[0102]
此处在2d应用框架中描述的本发明可以比照适用于三维声音空间化的背景,所实施的原理和等式类似于上文在二维应用框架中描述的原理和等式。
[0103]
本领域技术人员将理解,本发明不限于本发明已经描述了的汽车领域,而是可以更普遍地适用于实施声音空间化的任何领域,例如音乐或电影。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。