基于dbn-lstm半监督联合模型的剩余使用寿命预测方法
技术领域
1.本发明属于工业过程控制领域,特别涉及一种基于dbn-lstm半监督联合模型的剩余使用寿命预测方法。
背景技术:
2.在工业领域中,由于内部运动因素或外部环境因素的影响,一些重要的机器设备和工业组件在连续工作时,其工作性能和健康状态会呈现衰减的趋势。随着健康状况不断衰减,在未来的某一时刻设备将无法正常工作,其工作效率迅速下降甚至停止运转,达到使用寿命,这会导致工业过程受到影响甚至发生中断。因此需要预测系统在其整个使用寿命期间的剩余使用寿命(remaining useful life,rul),即从当前时间开始直到机器设备使用寿命结束的时间长度。
3.近些年来随着大量工业数据的采集和积累,数据驱动的解决方案在rul预测中受到广泛的关注。工业领域虽然储存了海量的过程数据,但可用于训练rul预测模型的有标签数据不足,其主要原因是:(1)运行时间不足,完整的退化过程数据有限:目前公开的数据集主要来自实验室模拟工业环境进行损耗实验结果。对于实际的工业设备的生产,企业缺少制作数据集的技术,同时很难花费巨大成本进行完整退化过程数据的采集。因此日常运行数据大多处于设备退化的早期,时序长度不足,并且无法得到准确的剩余使用寿命标签数据,无法有效地利用于rul的预测。(2)测量环境恶劣:在一些高温、高压、震动、腐蚀等恶劣情况下,传感器的损坏频率很高,维修难度大且成本高,往往只安装少量传感器。在此条件下即使增加运行时间,过程中仍旧采集不到充足的过程数据,难以进行rul预测模型的训练。
4.深度学习虽然能够更准确地进行rul预测,但需要大量数据支持,当训练数据不能满足数据驱动模型进行充分地训练时,模型会无法正确描述数据的真实分布,导致预测结果的精度降低甚至可能导致模型无法使用。对于神经网络模型,训练数据的规模不足可能会导致过拟合现象的发生,使得训练得到得模型对训练集学习程度过深,而当部署到工业场景中时却无法很好地拟合实时的在线数据。即使通过正则化或减少模型结构的复杂程度解决过拟合的问题,模型的预测效果也会大打折扣。现有的预测rul的深度学习方法是有监督的学习方法,需要大量的有标签的工业数据,但在对工业设备剩余使用寿命预测的领域中,由于运行时间不足和测量环境恶劣,有标签的工业数据较难获得,且有大量的无标签数据无法有效利用,有标签数据的缺失很大程度影响了训练得到的模型的有效性。
技术实现要素:
5.本发明的目的在于针对现有技术的不足,本发明提供一种基于dbn-lstm半监督联合模型的剩余使用寿命预测方法,该方法采用半监督联合模型,所需有标签的工业数据少,同时能够充分利用大量的无标签数据。同时在判断出机器当前剩余使用寿命的同时能够获得性能退化过程的信息。
6.一种基于dbn-lstm半监督联合模型的剩余使用寿命预测方法,所述dbn-lstm半监督联合模型通过在输入层和深度lstm神经网络之间增加dbn神经网络实现,所述dbn神经网络用于数据融合;所述深度lstm神经网络用于剩余使用寿命预测,即rul预测;
7.该方法包括以下步骤:
8.步骤一:收集设备数据,组成数据集,将数据集分为无标签训练集,有标签训练集、有标签验证集,根据不同工况进行数据预处理;
9.步骤二:将所述无标签训练集输入给所述dbn神经网络进行无监督预训练,训练得到的dbn神经网络将多维传感器特征压缩为健康特征指标,得到若干健康指数hi时间序列;
10.步骤三:将健康指数hi时间序列输入到深度lstm神经网络中,由深度lstm神经网络计算获得rul预测值;
11.步骤四:基于rul的预测值和真实值之间的误差计算损失函数,采用有标签训练集通过rmsprop梯度自适应对dbn-lstm半监督联合模型中的深度lstm神经网络进行训练,同时对dbn神经网络的参数进行微调;有标签验证集的误差结果小于一定值或其变化量小于一定值,同时模型训练的损失函数达到收敛时,模型训练结束并保存dbn-lstm半监督联合模型;
12.步骤五:将待预测的设备数据预处理后输入到保存的dbn-lstm半监督联合模型中,得到实时输出的hi和rul数值。
13.进一步地,所述步骤一中的有标签数据集为:
14.xo={(x
it
,rul
it
)|i≤n,t≤ti}
ꢀꢀ
(1)
15.其中,rul
it
为t时刻的剩余使用寿命的值,
16.rul
it
=t
i-t
ꢀꢀ
(2)
17.当设备完全无法使用时,rul
it
为0,且所有的rul
it
是按时序逆向增加;
18.x
it
为第i个传感器数据从初始到时间t的序列,
19.x
it
=[xi(1),xi(2),
…
,xi(t)]
ꢀꢀ
(3)
[0020]
其中,xi为第i个传感器数据从初始到时间ti的序列,
[0021]
xi=[xi(1),xi(2),
…
,xi(ti)]
ꢀꢀ
(4)
[0022]
所述预处理包括归一化处理和滑动时间窗采样处理;其中,归一化处理包括全局归一化和条件归一化,当设备数据为不同工况下的数据时,进行条件归一化,否则,进行全局归一化。
[0023]
进一步地,所述步骤二中,向dbn中输入多传感器信息多维时间序列,dbn将多维数据压缩为一维,最后输出包含健康指标hi时间序列的集合;
[0024]
所述dbn的搭建和预训练过程如下:
[0025]
通过gibbs采样使rbm获得抽样样本,给定隐藏层值,对可见层进行采样;当给定可见层值时,对隐藏层进行采样;采用近似的对比散度算法,有如下的马尔可夫链步骤:
[0026]h(n 1)
=σ(w
′v(n)
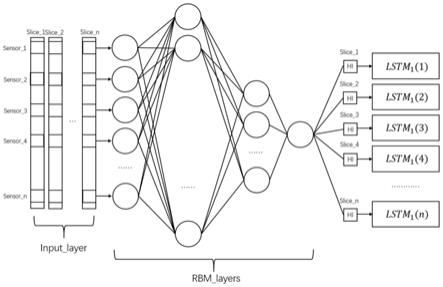
bh)
ꢀꢀ
(5)
[0027]v(n 1)
=σ(wh
(n 1)
bv)
ꢀꢀ
(6)
[0028]
σ表示n 1步的隐藏层和可见层的激活函数,h
(n 1)
表示第n 1步得到的隐藏层,v
(n 1)
表示第n 1步得到的可见层,w
′
、w为权重参数;bh、bv分别表示隐藏层和可见层的偏差;
[0029]
利用n 1步重构得到的可见层v
(n 1)更
新参数:
[0030][0031][0032]
δcj=p(hi=1|v
(0)
)-p(hi=1|v
(k)
)
ꢀꢀꢀ
(9)
[0033]
其中,δω
ij
、δbj、δcj分别表示rbm参数的变化量,k表示rbm的层数;
[0034]
对rbm进行堆叠和贪婪训练形成dbn;dbn包含一个可见层和多个隐藏层,用于学习提取训练数据的较深层次表示;dbn的可见层和l层的隐藏层的联合密度函数为:
[0035][0036]
v=h0ꢀꢀ
(11)
[0037]
在获得可见层的传感器采样数据之后,dbn神经网络首先完成第一个rbm的训练,然后,将第一层rbm的隐藏层用作第二层rbm的可见层,以形成第二层rbm,以此类推,得到多层堆叠的rbm网络,进而得到初步预训练的dbn神经网络;
[0038]
进一步地,所述步骤三具体分为如下的子步骤:
[0039]
深度lstm网络由多层lstm堆叠而成,每一层lstm的向量维度可变;hi健康指标通过第一层lstm解码为多维的传感器时间序列,深度lstm网络的上一层的输出作为下一层的输入,第l层的更新公式如下:
[0040][0041][0042][0043][0044][0045]
其中,l表示深度lstm神经网络的层数,t表示lstm某时刻的单元数,表示第l层t时刻的输入单元,表示第l层t时刻的遗忘单元,表示第l层t时刻的输出单元,表示第l层t时刻的状态单元,表示第l层t时刻的隐藏单元,σ表示sigmoid激活函数,
⊙
表示元素乘法计算,tanh表示tanh激活函数,表示第l-1层t时刻的隐藏单元权重,表示第l层t-1时刻的隐藏单元权重,表示偏差;
[0046]
最后一层的lstm神经网络的最后一单元输出多维特征向量,经过线性层计算,得到rul预测值。
[0047]
进一步地,所述步骤四通过如下的子步骤来实现:
[0048]
(1)深度lstm神经网络的输入层是dbn-lstm半监督联合模型的第l层,包含n个神经元,dbn神经网络的输出层则是dbn-lstm半监督联合模型的第l-1层,只有一个神经元;设计dbn-lstm半监督联合模型的第l层和l-1层的神经元误差δ
l
、δ
l-1
,用于实现dbn神经网络和深度lstm神经网络的同步训练;
[0049]
δ
l
=(w
l 1
)
t
δ
l 1
ꢀꢀ
(17)
[0050][0051]
其中,w和b分别是神经网络的权重参数和批尺寸;
[0052]
(2)有监督的联合训练中,应用受l2正则化约束的平方误差损失函数进行梯度自适应训练参数,并采用评分函数评估dbn-lstm半监督联合模型的预测准确度,将评分函数以一定权重加入全局损失函数中作为惩罚,优化平方误差损失函数,用于得到偏向早期预测的dbn-lstm半监督联合模型:
[0053]
其中,所述平方误差损失函数计算公式如下:
[0054][0055]
其中θ,w,b,λ,和yi分别表示在dbn-lstm半监督联合模型中学习的参数集、在dbn-lstm半监督联合模型中的权重参数集、批尺寸、正则化参数、第i个样本的预测rul和真实rul;
[0056]
所述评分函数score的计算公式如下:
[0057][0058]
d=rul
pred-rul
true
ꢀꢀ
(21)
[0059]
所述全局损失函数loss
total
的计算公式如下:
[0060]
loss
tta
/=αloss
score
(1-α)loss
mse
ꢀꢀ
(22)
[0061]
其中,α为两种评分函数的权重;
[0062]
(3)采用有标签训练集通过rmsprop梯度自适应对dbn-lstm半监督联合模型进行训练,计算公式如下:
[0063][0064]
其中r是历史梯度的累积变量,ρ是用于控制历史信息获取的收缩系数,η是学习率,δ是一个常数,g为loss
total
的梯度。
[0065]
本发明的有益效果如下:
[0066]
本发明针对机器设备运行退化过程分析了现有的rul预测方法,根据工业过程rul数据集缺失的问题,结合了半监督学习理论,在此基础上提出了一个通用的rul半监督联合预测框架方法,实现了基于大批次无标签数据的无监督预训练过程和小批次有标签数据集的有监督训练优化。相比于只使用小批次的有监督训练模型,dbn-lstm半监督联合模型能够更有效地对rul进行预测。此外,在无监督预训练过程后,用于数据融合的dbn神经网络已经处于距最优点较近的位置,使得第二阶段的联合训练时间极大地减小。同时预训练模型参数可存储,在进行多次有标签数据集优化训练时,使用存储的预训练模型参数大大增加了训练效率。
附图说明
[0067]
图1为dbn-lstm神经网络模型示意图;
[0068]
图2为联合模型框架训练实施流程图;
[0069]
图3为不同归一化策略后产生的结果示意图;
[0070]
图4为数据融合输出健康指标hi随时间变化曲线(原始)示意图,其中图4中的上图表示测试集所有涡轮机数据的hi输出,下图表示选取的测试集部分采样数据的hi输出。
[0071]
图5为数据融合输出健康指标hi随时间变化曲线(滤波后)示意图,其中图5中的上图表示测试集所有涡轮机数据的hi输出,下图表示选取的测试集部分采样数据的hi输出。
[0072]
图6为dbn-lstm神经网络模型拟合曲线示意图。
具体实施方式
[0073]
下面根据附图和优选实施例详细描述本发明,本发明的目的和效果将变得更加明白,应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0074]
本发明的基于dbn-lstm半监督联合模型的剩余使用寿命预测方法中,dbn-lstm半监督联合模型通过在输入层和深度lstm神经网络之间增加dbn神经网络实现,所述dbn神经网络用于数据融合;所述深度lstm神经网络用于剩余使用寿命预测,即rul预测。将数据切片序列输入到dbn-lstm半监督联合模型的第一层rbm进行无监督学习预训练,通过梯度下降方法使对数损失函数下降更新权重参数。将第一层rbm的输出作为第二层rbm的输入,依次训练若干层后最终输出单一维度的hi时间序列。将训练好的权重参数部署到模型网络层上,最后一层连接深度lstm网络模型,即将经dbn网络数据融合后的hi序列按time_step长度依次输入至深度lstm网络计算。得到完整的dbn-lstm网络联合预测模型后,进一步使用反向传播算法进行lstm网络的训练和dbn网络的微调,使用rmsprop优化器进行梯度下降迭代。具体结构如图1所示。此外由于dbn神经网络能够深度提取数据特征,训练过程会容易出现过拟合问题,采用批标准化网络层来对网络进行优化,给dbn神经网络增加正则化项以解决此问题。输入测试集的数据,在dbn网络输出健康指标hi的变化过程,在整个模型最后的网络层输出rul的预测值。具体工程实现中,两个模型中的网络层在同一个model中相连接,使用rmsprop优化器进行迭代联合训练。全部训练流程如图2所示进行。
[0075]
该方法包括以下步骤:
[0076]
步骤一:收集设备数据,组成数据集,将数据集分为无标签训练集,有标签训练集、有标签验证集,根据不同工况进行数据预处理;
[0077]
其中无标签训练集的数据包含时序数据的时间戳,各个特征变量在每个时刻的数值;其中有标签训练集的数据包含时序数据的时间戳,各个特征变量在每个时刻的数值,以及rul数据标签或可用于计算rul标签的设备寿命结束时间;其中有标签验证集内容与有标签训练集相同,数量应在有标签训练集的10%-30%范围内。
[0078]
所述步骤一中的有标签数据集为:
[0079]
xo={(x
it
,rul
it
)|i≤n,t≤ti}
ꢀꢀꢀꢀ
(1)
[0080]
其中,rul
it
为t时刻的剩余使用寿命的值,
[0081]
rul
it
=t
i-t
ꢀꢀ
(2)
[0082]
当设备完全无法使用时,rul
it
为0,且所有的rul
it
是按时序逆向增加;
[0083]
x
it
为第i个传感器数据从初始到时间t的序列,
[0084]
x
it
=[xi(1),xi(2),...,xi(t)]
ꢀꢀ
(3)
[0085]
其中,xi为第i个传感器数据从初始到时间ti的序列,
[0086]
xi=[xi(1),xi(2),...,xi(ti)]
ꢀꢀ
(4)
[0087]
所述预处理包括归一化处理和滑动时间窗采样处理;其中,归一化处理包括全局归一化和条件归一化,当设备数据为不同工况下的数据时,进行条件归一化,否则,进行全局归一化。
[0088]
lstm循环神经网络具有标准的输入形式(batch_size,time_steps,feature_nums),batch_size指在神经网络模型的训练过程中批处理样本的个数,time_steps指每一个样本中时间序列数据的时间步长,feature_nums指多传感器数据中特征的维度数目。为了将数据集进一步处理成标准样式,需要使用滑动时间窗方法进行样本采样。
[0089]
步骤二:将所述无标签训练集输入给所述dbn神经网络进行无监督预训练,训练得到的dbn神经网络将多维传感器特征压缩为健康特征指标,得到若干健康指数hi时间序列;
[0090]
所述步骤二中,向dbn中输入多传感器信息多维时间序列,dbn将多维数据压缩为一维,最后输出包含健康指标hi时间序列的集合;
[0091]
所述dbn的搭建和预训练过程如下:
[0092]
通过gibbs采样使rbm获得抽样样本,给定隐藏层值,对可见层进行采样;当给定可见层值时,对隐藏层进行采样;采用近似的对比散度算法,有如下的马尔可夫链步骤:
[0093]h(n 1)
=σ(w
′v(n)
bh)
ꢀꢀ
(5)
[0094]v(n 1)
=σ(wh
(n 1)
bv)
ꢀꢀ
(6)
[0095]
σ表示n 1步的隐藏层和可见层的激活函数,h
(n 1)
表示第n 1步得到的隐藏层,v
(n 1)
表示第n 1步得到的可见层,w
′
、w为权重参数;bh、bv分别表示隐藏层和可见层的偏差;
[0096]
利用n 1步重构得到的可见层v
(n 1)
更新参数:
[0097][0098][0099]
δcj=p(hi=1|v
(0)
)-p(hi=1|v
(k)
)
ꢀꢀ
(9)
[0100]
其中,δω
ij
、δbj、δcj分别表示rbm参数的变化量,k表示rbm的层数;
[0101]
对rbm进行堆叠和贪婪训练形成dbn;dbn包含一个可见层和多个隐藏层,用于学习提取训练数据的较深层次表示;dbn的可见层和l层的隐藏层的联合密度函数为:
[0102][0103]
v=h0ꢀꢀ
(11)
[0104]
在获得可见层的传感器采样数据之后,dbn神经网络首先完成第一个rbm的训练,然后,将第一层rbm的隐藏层用作第二层rbm的可见层,以形成第二层rbm,以此类推,得到多层堆叠的rbm网络,进而得到初步预训练的dbn神经网络;
[0105]
步骤三:将健康指数hi时间序列输入到深度lstm神经网络中,由深度lstm神经网络计算获得rul预测值;
[0106]
深度lstm网络由多层lstm堆叠而成,每一层lstm的向量维度可变;hi健康指标通
过第一层lstm解码为多维的传感器时间序列,深度lstm网络的上一层的输出作为下一层的输入,第l层的更新公式如下:
[0107][0108][0109][0110][0111][0112]
其中,l表示深度lstm神经网络的层数,t表示lstm某时刻的单元数,表示第l层t时刻的输入单元,表示第l层t时刻的遗忘单元,表示第l层t时刻的输出单元,表示第l层t时刻的状态单元,表示第l层t时刻的隐藏单元,σ表示sigmoid激活函数,
⊙
表示元素乘法计算,tanh表示tanh激活函数,表示第l-1层t时刻的隐藏单元权重,表示第l层t-1时刻的隐藏单元权重,表示偏差;
[0113]
最后一层的lstm神经网络的最后一单元输出多维特征向量,经过线性层计算,得到rul预测值。
[0114]
步骤四:基于rul的预测值和真实值之间的误差计算损失函数,采用有标签训练集通过rmsprop梯度自适应对dbn-lstm半监督联合模型中的深度lstm神经网络进行训练,同时对dbn神经网络的参数进行微调;有标签验证集的误差结果小于一定值或其变化量小于一定值,同时模型训练的损失函数达到收敛时,模型训练结束并保存dbn-lstm半监督联合模型;
[0115]
所述步骤四通过如下的子步骤来实现:
[0116]
(1)深度lstm神经网络的输入层是dbn-lstm半监督联合模型的第l层,包含n个神经元,dbn神经网络的输出层则是dbn-lstm半监督联合模型的第l-1层,只有一个神经元;设计dbn-lstm半监督联合模型的第l层和l-1层的神经元误差δ
l
、δ
l-1
,用于实现dbn神经网络和深度lstm神经网络的同步训练;
[0117]
δ
l
=(w
l 1
)
t
δ
l 1
ꢀꢀ
(17)
[0118][0119]
其中,w和b分别是神经网络的权重参数和批尺寸;
[0120]
(2)有监督的联合训练中,应用受l2正则化约束的平方误差损失函数进行梯度自适应训练参数,并采用评分函数评估dbn-lstm半监督联合模型的预测准确度,将评分函数以一定权重加入全局损失函数中作为惩罚,优化平方误差损失函数,用于得到偏向早期预测的dbn-lstm半监督联合模型:
[0121]
其中,所述平方误差损失函数计算公式如下:
[0122]
[0123]
其中θ,w,b,λ,和yi分别表示在dbn-lstm半监督联合模型中学习的参数集、在dbn-lstm半监督联合模型中的权重参数集、批尺寸、正则化参数、第i个样本的预测rul和真实rul;
[0124]
所述评分函数score的计算公式如下:
[0125][0126]
d=rul
pred-rul
true
ꢀꢀ
(21)
[0127]
所述全局损失函数loss
total
的计算公式如下:
[0128]
loss
tota
=αloss
score
(1-α)loss
mse
ꢀꢀ
(22)
[0129]
其中,α为两种评分函数的权重;
[0130]
(3)由于神经网络是非凸的,并且rmsprop(root mean square prop)优化算法可以在非凸条件下有效执行,rmsprop优化器可用于有监督的联合训练。采用有标签训练集通过rmsprop梯度自适应对dbn-lstm半监督联合模型进行训练,计算公式如下:
[0131][0132]
其中r是历史梯度的累积变量,ρ是用于控制历史信息获取的收缩系数,η是学习率,δ是一个常数,g为loss
total
的梯度。
[0133]
其中,用于数据融合的dbn神经网络中的逐层rbm网络参数达到的是各层的最优解,并不是dbn网络的全局最优。所以从最后一层获得数据与标签数据进行比较,利用比较得到的误差信息使用rmsprop优化算法对rbm权重做出微调。
[0134]
步骤五:将待预测的设备数据预处理后输入到保存的dbn-lstm半监督联合模型中,得到实时输出的hi和rul数值。
[0135]
以下结合一个具体的工业例子来说明本发明的有效性。本发明采用美国国家航空航天局nasa提供的开源涡轮风扇发动机退化模拟数据集c-mapss作为实例,该数据具体包括四个操作条件和故障模式不同的子数据集fd001-fd004,每个数据集中包含train_fd00x、test_fd00x、rul_fd00x三个文件,分别为训练集、测试集和测试集的rul真值标签。具体如下表所示:
[0136]
表1:c-mapss数据集详情
[0137]
数据集fd001fd002fd003fd004train发动机数100260100249test发动机数100259100248操作模式1616故障模式1122
[0138]
本发明主要采用数据集fd002作为研究对象,与fd001或fd003相比,该数据集的多传感器数据有6个工况条件,外部环境复杂度较高且数据较多,理论上更难进行rul的预测。
传感器各个维度的具体含义如下表所示:
[0139]
表2:涡轮机的多传感器数据具体表示
[0140]
[0141][0142]
得到数据后,划分数据集得到无标签训练集、有标签训练集、有标签验证集,根据该数据集的6个工况条件对原始数据进行条件归一化处理,然后进行滑动窗口处理得到数据切片序列。涡轮机的工况条件对传感器值有巨大影响,不同状态下传感器的读数位于完全不同的值范围内。全局归一化忽略工况条件影响,对每个传感器的所有值同时进行归一化。而条件归一化则是在相同工况条件情况下,对每个传感器数据进行归一化。如图3所示,分别是某个涡轮机单元传感器4、7在不同归一化策略下处理后的效果。如果使用全局归一化,虽然不影响rul的预测精度,但是会导致数据融合模型的输出hi为全局归一化变量,难以呈现出退化趋势。因此在数据预处理时使用条件归一化策略以获得退化趋势的健康指标hi。
[0143]
训练数据集和测试数据集均具有100个单元的涡轮机。在每个单元子集中使用大小为num_steps的滑动窗口来生成输入序列。对于模型结构本身,主要受两个超参数的影响:batch_size和num_steps,为了比较不同超参数的影响,将它们设置为不同的值并训练不同的lstm模型。然后根据每个模型在测试集中得到的score来选择合适的参数。
[0144]
根据train_loss和val_loss的变化及稳定时的情况调整dropout和bn网络的正则化参数,正则化过小则会导致过拟合问题出现,过大则会影响模型精度。为了防止过拟合和减少训练时间成本,需要使用早停策略,设置loss下降变化的阈值,连续n个周期内变化未超出阈值则停止训练。根据模型结果精度的需要,可以设置一个合适的阈值参数来实现早停策略。
[0145]
基于搭建的联合训练神经网络,可以在中间网络层得到多传感器数据融合模型的输出,即健康指标hi的时间序列。如图4所示为每个涡轮机的健康指标衰减过程曲线。进一步使用savitzky-golay滤波器对hi时间序列进行滤波。该方法是一种在时域内通过结合卷积与局部多项式回归实现平滑滤波的方法。这种滤波器最大的特点在于在滤除噪声的同时可以保持信号的形状、宽度不变。滤波后的hi时间序列曲线如图5所示。
[0146]
基于c-mapss数据集fd002子数据集,采样30%作为有标签数据集,其余为无标签数据集。使用上述神经网络模型对测试集进行rul预测,可以得到如图6所示的深度学习模型对测试集中100个涡轮机的多传感器时间序列的rul预测结果。可以发现dbn-lstm联合模型可以较好地根据目前的多维传感器时间序列对每个涡轮机进行rul的预测。预测结果与只使用小批次有标签数据集的深度lstm神经网络方法预测结果对比如表3所示:
[0147]
表3:rmse和score指标下的预测结果
[0148]
methodsrmsescorelstm20.574650
dbn-lstm17.73865
[0149]
从表3可以看出,与同样结构的有监督训练的神经网络相比,增加了大量无标签数据进行无监督预训练的dbn-lstm神经网络联合模型预测精度得到了13.8%的提升。与此同时,实验过程中,经过无监督预训练的模型在有标签数据微调阶段的联合模型收敛速度大幅度上升,相比于直接使用有标签数据集训练,前者训练速度为后者的10-20倍,在进行多次优化训练时能够节约时间,提高训练效率。
[0150]
本领域普通技术人员可以理解,以上所述仅为发明的优选实例而已,并不用于限制发明,尽管参照前述实例对发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实例记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在发明的精神和原则之内,所做的修改、等同替换等均应包含在发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
