1.本发明涉及智能化教育技术领域,尤其涉及一种拍照搜题方法。
背景技术:
2.随着科学技术的不断发展,学生在学习过程中遇到问题时,大多会进行拍照搜题。而现有的拍照搜题技术在对文本中的字符进行识别时,需要预先使文本行处于水平状态 (受拍摄角度、光线等其他因素的影响,在拍摄试题时,得到的图片中的文本可能处于倾斜状态,这就需要对其进行校正)。而目前,对文本字符倾斜校正是首先通过计算文本行所在直线与水平线之间的夹角,然后反向旋转该夹角进行校正的,这里就有一个问题,如若文本行的倾斜角度大于180
°
,则即使将其旋转成水平状态,得到的字符确是倒置的(如图2所示),而倒置的字符并不能准确的进行识别,因此,需要对其进行改进。
技术实现要素:
3.本发明的目的是提供一种拍照搜题方法,该方法在对字符进行识别前,首先需要将文本行调整成水平状态,并判断处于水平状态下的文本行的字符是否是倒置的,若是倒置的,则依据预先构建的图片倾斜校正模型,再将整个图片旋转一定的角度,使得文本行中的字符处于正常的方向,进而提高字符识别精度。
4.为实现上述目的,采用以下技术方案:
5.一种拍照搜题方法,包括以下步骤:
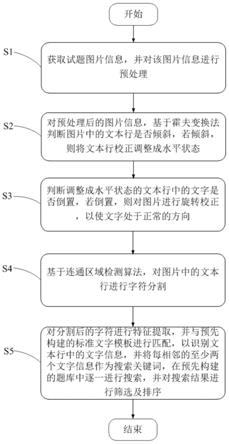
6.s1:获取试题图片信息,并对该图片信息进行预处理;
7.s2:对预处理后的图片信息,基于霍夫变换法判断图片中的文本行是否倾斜,若倾斜,则将文本行校正调整成水平状态;
8.s3:判断调整成水平状态的文本行中的文字是否倒置,若倒置,则对图片进行旋转校正,以使文字处于正常的方向;
9.s4:基于连通区域检测算法,对图片中的文本行进行字符分割;
10.s5:对分割后的字符进行特征提取,并与预先构建的标准文字模板进行匹配,以识别文本行中的文字信息,并将每相邻的至少两个文字信息作为搜索关键词,在预先构建的题库中逐一进行搜索,并对搜索结果进行筛选及排序。
11.进一步地,所述s2中将文本行校正调整成水平状态具体包括以下步骤:
12.s21:将获取的图片信息按纵向或横向划分成m个子块图像,其中,m=h/h,h为图片的高度,h为子块图像的高度;
13.s22:搜索并获取每一子块图像的左边界的坐标值信息,并将其存储于数组m中;
14.s23:依据下式,计算文本行的倾斜角度;
15.其中,
16.k=|h
1-h2|,h为每个子块图像的高度;
17.s24:基于s23计算得到的文本行的倾斜角度,将其反向旋转该角度,使其处于水平状态。
18.进一步地,所述s22中在搜索每一子块图像的左边界的坐标值信息时,若位于最左端的子块图像的左边界不存在像素点,则搜索向右平移一列的子块图像的左边界坐标值信息。
19.进一步地,所述s3具体包括以下步骤:
20.s31:预先获取至少5000张文字正常排布的正向图片信息,以及至少5000张文字倒置的反向图片信息,作为训练集;
21.s32:基于vgg16网络结构构建图片倾斜校正模型,并依据s31获取的训练集对其进行训练;
22.s33:使用小批量梯度下降法作为优化器,并基于softmax损失函数对模型进行优化;
23.s34:基于优化后的图片倾斜校正模型,判断文本行中的文字是否倒置,并依据判断结果,对其进行校正。
24.进一步地,所述s1中的预处理具体包括以下步骤:
25.s11:基于加权平均法对获取的试题图片信息进行灰度化处理;
26.s12:基于niblack算法对灰度化处理后的试题图片信息进行二值化;
27.s13:基于数字形态学滤波法对二值化后的试题图片信息进行降噪。
28.采用上述方案,本发明的有益效果是:
29.该方法在对字符进行识别前,首先需要将文本行调整成水平状态,并判断处于水平状态下的文本行的字符是否是倒置的,若是倒置的,则依据预先构建的图片倾斜校正模型,再将整个图片旋转一定的角度,使得文本行中的字符处于正常的方向,进而提高字符识别精度。
附图说明
30.图1为本发明的流程性框图;
31.图2为本发明的其中一实施例中,文本行倾斜校正的流程图;
具体实施方式
32.以下结合附图和具体实施例,对本发明进行详细说明。
33.参照图1至2所示,本发明提供一种拍照搜题方法,包括以下步骤:
34.s1:获取试题图片信息,并对该图片信息进行预处理;
35.s2:对预处理后的图片信息,基于霍夫变换法判断图片中的文本行是否倾斜,若倾斜,则将文本行校正调整成水平状态;
36.s3:判断调整成水平状态的文本行中的文字是否倒置,若倒置,则对图片进行旋转校正,以使文字处于正常的方向;
37.s4:基于连通区域检测算法,对图片中的文本行进行字符分割;
38.s5:对分割后的字符进行特征提取,并与预先构建的标准文字模板进行匹配,以识别文本行中的文字信息,并将每相邻的至少两个文字信息作为搜索关键词,在预先构建的题库中逐一进行搜索,并对搜索结果进行筛选及排序。
39.其中,所述s2中将文本行校正调整成水平状态具体包括以下步骤:
40.s21:将获取的图片信息按纵向或横向划分成m个子块图像,其中,m=h/h,h为图片的高度,h为子块图像的高度;
41.s22:搜索并获取每一子块图像的左边界的坐标值信息,并将其存储于数组m中;
42.s23:依据下式,计算文本行的倾斜角度;
43.其中,
44.k=|h
1-h2|,h为每个子块图像的高度;
45.s24:基于s23计算得到的文本行的倾斜角度,将其反向旋转该角度,使其处于水平状态。
46.所述s22中在搜索每一子块图像的左边界的坐标值信息时,若位于最左端的子块图像的左边界不存在像素点,则搜索向右平移一列的子块图像的左边界坐标值信息。
47.所述s3具体包括以下步骤:
48.s31:预先获取至少5000张文字正常排布的正向图片信息,以及至少5000张文字倒置的反向图片信息,作为训练集;
49.s32:基于vgg16网络结构构建图片倾斜校正模型,并依据s31获取的训练集对其进行训练;
50.s33:使用小批量梯度下降法作为优化器,并基于softmax损失函数对模型进行优化;
51.s34:基于优化后的图片倾斜校正模型,判断文本行中的文字是否倒置,并依据判断结果,对其进行校正。
52.所述s1中的预处理具体包括以下步骤:
53.s11:基于加权平均法对获取的试题图片信息进行灰度化处理;
54.s12:基于niblack算法对灰度化处理后的试题图片信息进行二值化;
55.s13:基于数字形态学滤波法对二值化后的试题图片信息进行降噪。
56.本发明工作原理:
57.继续参照图1至2所示,本实施例中,提供了一种拍照搜题方法,该方法首先需要获取试题图片信息(可通过摄像头拍摄采集),由于拍摄者的拍摄角度、光线等其他因素的影响,所得到的试题图片信息可能会存在模糊、阴暗及字符倾斜等问题,因此,在对拍摄的图片进行字符识别前,需要对其进行预处理,该实施例中,首先依据加权平均法对获取的试题图片信息进行灰度化处理,其公式如下:
58.f(i,j)=k*r(i,j) m*g(i,j) b*r(i,j),
59.其中,(i,j)是某一像素点的坐标,f(i,j)是某一像素点的灰度值。
60.随后,再对图片进行二值化处理,使得图片中包含的信息量更少,便于后续的处理,采用niblack算法将图片进行二值化,其基本原理是针对图片上的某一点,依据图片灰
度分布,设置一个邻域,随后,计算该邻域的图片灰度的标准方差及均值,则该点的阈值即是该均值与标准方差之和,其公式如下:
61.t(x,y)=e(x,y) k
·
s(x,y),
62.其中,t(x,y)为图片上某点的阈值,e(x,y)某邻域的灰度均值,s(x,y)是某邻域灰度方差,k是方差权重系数。
63.最后,再依据数字形态学滤波法对二值化后的试题图片进行降噪,也可用其他方法,如高斯滤波法、双边滤波法等,以使图片更加清晰明了,便于后续的分析处理。
64.由于受拍摄者拍摄角度的影响,预处理后的试题图片中的文本行可能处于倾斜状态,而现有的对文本倾斜校正是首先通过计算文本行所在直线与水平线之间的夹角,然后反向旋转该夹角进行校正的,这里就有一个问题,如若文本行的倾斜角度大于180
°
,则即使将其旋转成水平状态,得到的字符确是倒置的(如图2所示),而倒置的字符并不能准确的进行识别,因此,本方法首先经霍夫变换法(常用的字符倾斜校正方法)判断图片中的文本行是否倾斜,若处于倾斜状态,则将其进行校正,校正方法如下:
65.首先将获取的图片信息按纵向或横向划分成m个子块图像,其中,m=h/h,h为图片的高度,h为子块图像的高度;随后,搜索并获取每一子块图像的左边界的坐标值信息,并将其存储于数组m中;最后,依据下式计算文本行的倾斜角度:
66.其中,
67.k=|h
1-h2|,h为每个子块图像的高度;同时,这里的m(h1),m(h2)为整个图片处于中间的子块图像的左边界的坐标值,较正后的图片如图2 所示。
68.将文本行调整成水平状态后,文本行中的字符可能处于倒置的状态(如图2所示),因此,需要对其进行检测调整,该实施例中,首先预先获取至少5000张文字正常排布的正向图片信息,以及至少5000张文字颠倒的反向图片信息,作为训练集,随后,基于vgg16网络结构构建图片倾斜校正模型,并对其进行训练,模型可通过深层次的卷积运算提取图片的高级特征,并对字符的方向进行180
°
和0
°
的二分类,为提高模型的运算精度,又将小批量梯度下降法作为优化器,并基于softmax损失函数对模型进行优化,基于优化后的模型对字符进行判断并校正(如图2所示)。
69.随后,基于基于连通区域检测算法,对图片中的文本行进行字符分割,然后,再对分割后的字符进行特征提取(可通过tesseract-ocr字符识别引擎进行识别,在此不作限制),并与预先构建的标准文字模板进行匹配,以识别文本行中的文字信息,并将每相邻的至少两个文字信息作为搜索关键词,在预先构建的题库中逐一进行搜索,并对搜索结果进行筛选及排序,并将搜索排序后的结果显示于外界即可。
70.以上仅为本发明的较佳实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。