1.本发明属于可见光-红外目标跟踪技术领域,具体涉及一种基于深度网络的可见光-红外目标跟踪方法及系统。
背景技术:
2.近年来得益于计算机硬件快速发展的夯实基础,深度学习的热度持续增加,在工业界和学术界都受到了广泛关注。深度学习模模型往往有着较深的网络结构和较多的参数,可以提取到更深层次、更具辨识力的特征,同时也要求了更大的数据量。计算机视觉依托于深度学习的广泛应用,在更多细分领域也取得了振奋人心的进步。
3.目标跟踪是计算机视觉的一个重要分支和基本问题,也是视觉领域近年来的热点和难点之一。但现阶段的目标跟踪仍面临着许多挑战性问题,尤其是在各种复杂的环境条件下(如低光照、雨天、烟雾等),可见光图像成像质量会受到显著影响,使跟踪目标物体很艰难。研究发现,热红外(thermal infrared)传感器为这些情况提供了更稳定的特征。两种模态的特征,可以在各种挑战场景中互补:在可见光受到低照度、高照度或背景遮挡的干扰时,热信息可以有效地克服它们;当热光谱受到热交叉、玻璃等影响时,可见光信息可以有效地处理它们。
4.在过去十年中,研究者已经提出许多用于可见光-红外目标跟踪的方法。从基于稀疏表示和相关滤波的传统可见光-红外目标跟踪方法到基于深度学习的可见光-红外目标跟踪,可见光-红外目标跟踪已经成为了跟踪领域一个有针对性的研究内容。rgb-t目标跟踪的传统方法多为在线目标跟踪,旨在利用简单有效的人工设计视觉特征,结合浅层外观模型,利用匹配或分类算法进行快速有效的目标跟踪。如基于稀疏表示的方法,将可见光和红外信息结合起来,稀疏地表示目标模板空间中的每个样本。为抑制噪声和减少误差,研究人员提出了利用低秩约束的相关滤波可见光-红外目标跟踪方法[zhai s,shao p,liang x,et al.fast rgb-t tracking via cross-modal correlation filters[j].neurocomputing,2019,334:172-181.]。利用交叉模态相关滤波器以获得可见光和热红外两个模态之间的相互依赖性,实现多种模态的协同融合,使所学习的滤波器可以包含来自不同数据源的有用信息,从而获得鲁棒的跟踪结果。近年来,随着深度网络的不断发展和大型可见光-红外目标跟踪数据集的公开,基于深度学习的可见光-红外目标跟踪方法逐渐成为主流,如使用双卷积神经网络分别提取可见光和红外特征进行级联融合;但这种方式会引入冗余噪声,为提升性能研究人员提出了基于密集特征聚合与剪枝网络的可见光-红外目标跟踪的方法[zhu y,li c,luo b,et al.dense feature aggregation and pruning for rgbt tracking[c]//proceedings of the 27th acm international conference on multimedia.2019:465-472.],在提供更具丰富的特征表示的同时消除冗余噪声;此外,基于多适配器和挑战感知[long li c,lu a,hua zheng a,et al.multi-adapter rgbt tracking[c]//proceedings of the ieee international conference on computer vision workshops.2019:0-0.]、基于全局注意力和局部注意力的深度方法也被提出,进一
步提升了跟踪的精度。但由于这些深度模型都使用了在线训练的方式以在跟踪过程中提升模型性能,它们的速度往往成为软肋,无法在满足实时性的情况下运行。
技术实现要素:
[0005]
本发明公开了一种基于深度网络的可见光-红外目标跟踪方法及系统,可以抵抗跟踪速度的下降,提高了跟踪的精度和速度。
[0006]
实现本发明的技术解决方案为:一种基于深度网络的可见光-红外目标跟踪方法,包括步骤:
[0007]
第一步,输入的视频包括可见光视频序列和红外视频序列,即网络的输入包含红外样本图像序列和红外候选图像序列、可见光样本图像序列和可见光候选图像序列;
[0008]
第二步,建立对称的双流孪生网络结构,可见光分支和红外分支的骨干网络分别共享权重;
[0009]
第三步,采用通道注意力模块和通道-空间联合注意力模块且可训练,通道注意力模块和通道-空间联合注意力模块作为特征增强单元嵌入网络中;
[0010]
第四步,原始特征和增强特征通过分类分支和回归分支进行互相关操作,得到分类响应图和回归响应图并进行融合;所述分类分支使用交叉熵作为损失函数,回归分支使用光滑化l1范数作为损失函数联合训练网络;
[0011]
第五步,在跟踪推理阶段,通过自适应峰值选择模块处理分类响应图和回归响应图,完成目标定位。
[0012]
一种基于深度网络的可见光-红外目标跟踪系统,包括数据采集处理模块和目标跟踪网络,其中:
[0013]
所述采集处理模块用于获取红外样本图像和红外候选图像、可见光样本图像和可见光候选图像;
[0014]
所述目标跟踪网络为对称的双流孪生网络结构,包括用于特征提取的可见光子网络和红外子网络、嵌入可见光子网络及红外子网络的通道注意力模块和通道-空间联合注意力模块、分类分支和回归分支、图像融合模块和自适应峰值选择模块;所述通道注意力模块和通道-空间联合注意力模块用于提取特征的增强,所述分类分支和回归分支分别用于原始模板和候选特征及增强的模板和候选特征的分类、分支,输出对应的分类响应图和回归响应图;所述图像融合模块用于对分类响应图和回归响应图进行融合,所述自适应峰值选择模块用于处理分类响应图和回归响应图,获取目标定位。
[0015]
本发明与现有技术相比,其显著特点在于:(1)建立对称的深度双流孪生网络结构,有效提取可见光模态和红外模态的语义特征;(2)使用注意力机制自适应增强可见光模态和红外模态特征,增强其判别力;(3)通过响应级融合,并使用最大峰值选择方式以在目标定位中获得更高精度;(4)采用端到端的网络结构,结构简单,简洁有序,摒弃了复杂的预处理、后处理流程,计算复杂度低;具有泛化性强、跟踪精度高及跟踪速度快的优点,在基准数据集上的精度达到88.2%,同时速度高达140帧/秒。
附图说明
[0016]
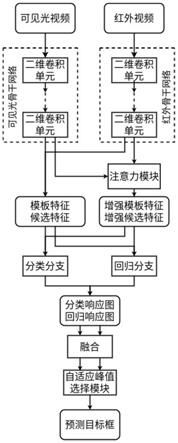
图1是本发明方法的流程示意图。
[0017]
图2是本发明方法的网络结构图。
[0018]
图3是本发明通道注意力模块结构图。
[0019]
图4是本发明空间注意力模块结构图。
具体实施方式
[0020]
结合图1,下面详细说明本发明的实施过程,一种双模态响应融合深度网络的可见光-红外目标跟踪方法,步骤如下:
[0021]
第一步,输入的样本-候选图片对包含可见光模态和红外模态,即网络的输入包含红外样本图像和红外候选图像,记为可见光样本图像和可见光候选图像,记为
[0022]
第二步,建立对称的双流孪生网络结构,可见光分支和红外分支的骨干网络分别共享权重。骨干网络由多个二维卷积单元串联而成,每个二维卷积单元的输出作为下一个二维卷积单元的输入。x
rgb
∈rh×w×c为可见光图像数据,h、w、c分别为可见光图像数据的三个维度,即高、宽、通道数。x
tir
∈rh×w×c,。h、w、c分别为红外图像数据的三个维度,即高、宽、通道数。第i(1≤i≤n)个二维卷积单元的输入为xi,输出为则有:
[0023][0024][0025][0026][0027]
其中,n表示骨干网络中的二维卷积单元数量,relu(
·
)表示激活函数,bn(
·
)表示批归一化函数,运算符表示卷积运算,和分别表示可见光和红外骨干网络第i个二维卷积单元的卷积核(k
×
k为卷积核大小),和分别为可见光和红外卷积核对应的偏置项。
[0028][0029][0030][0031][0032][0033][0034]
和分别表示第i个可见光和红外二维卷积单元。feat
rgb
和feat
tir
分别为可见光数据和红外数据通过骨干网络后的输出,f
rgb
(
·
)和f
tir
(
·
)分别表示可见光和红外骨干网络。
[0035]
第三步,采用通道注意力模块和通道-空间联合注意力模块且可训练,通道注意力模块和通道-空间联合注意力模块作为特征增强单元嵌入网络中。结合图3,通道注意力模块的输入feat
rgb
∈rh×w×c,feat
tir
∈rh×w×c:
[0036]
feat
rgb
∈rh×w×c,feat
tir
∈rh×w×c[0037]
feat
union
=cat(feat
rgb
,feat
tir
)
[0038]
weight=g(resize(fc(gp(feat
union
))))
[0039][0040][0041]
其中,feat
rgb
、feat
rgb
分别表示经过骨干网络提取的可见光特征和红外特征,cat(
·
,
·
)表示按通道维度级联操作,feat
union
∈rh×w×
2c
表示级联后的特征;gp(
·
)表示全局池化操作,fc(
·
)表示全连接层,resize(
·
)表示调整尺寸操作,g(
·
)表示激活函数,weight∈rh×w×
2c
表示计算出的权重;*表示矩阵的点乘,表示加权(增强)后的特征;apart(
·
)表示按通道维度特征拆分,分别表示加权(增强)后的可见光特征和红外特征。
[0042]
结合图4,空间注意力模块的输入feat
rgb
∈rh×w×c,feat
tir
∈rh×w×c:
[0043]
feat
rgb
∈rh×w×c,feat
tir
∈rh×w×c[0044]
feat
union
=cat(feat
rgb
,feat
tir
)
[0045][0046][0047][0048]
其中,feat
rgb
、feat
rgb
分别表示可见光特征和红外特征,cat(
·
,
·
)表示按通道维度级联操作,feat
union
∈rh×w×
2c
表示级联后的特征;avg(
·
)表示平均池化操作,max(
·
)表示最大池化操作,为二维卷积,s
spatial
∈rk×k×c表示空间注意力模块二维卷积核,g(
·
)表示激活函数,weight∈rh×w×
2c
为计算出的权重;
×
是广播乘,表示加权(增强)后的特征;apart(
·
)表示按通道维度特征拆分,分别是加权(增强)后的可见光特征和红外特征。
[0049]
通道-空间注意力模块的构成为串联的通道注意力模块和空间注意力模块。将由骨干网络提取的可见光样本特征和红外样本特征送入通道注意力模块进行增强,将由骨干网络提取的可见光候选特征和红外候选特征通道-空间注意力模块进行增强。
[0050]
第四步,原始特征和增强特征通过分类分支和回归分支进行互相关操作,得到分类响应图和回归响应图并进行融合。网络共包含4个分类分支和2个回归分支,分别为:原始可见光分类分支、增强可见光分类分支、原始红外分类分支、增强红外分类分支、增强可见光回归分支、增强红外回归分支。分类分支的输入为分别表示同属性的样本特征和候选特征(如红外增强样本特征和红外增强候选特征):
[0051]
[0052][0053]
其中,是分类样本卷积核,是分类候选卷积核,表示二维卷积,表示互相关操作,clsmap∈rn×n×2是分类响应图。
[0054]
回归分支的输入为分别表示同属性的样本特征和候选特征(如可见光增强样本特征和可见光增强候选特征):
[0055][0056][0057]
其中,是回归样本卷积核,是回归候选卷积核,表示二维卷积,表示互相关操作,regmap∈rn×n×4是回归响应图。原始特征和增强特征经过4个分类分支和2个回归分支,共计生成6张不同的响应图:
[0058][0059]
clsmap
rgb
∈rn×n×
l
×2,clsmap
tir
∈rn×n×
l
×2,
[0060][0061]
分别表示:增强可见光分类响应图、增强红外分类响应图、原始可见光分类响应图、原始红外分类响应图、增强可见光回归响应图、增强红外回归响应图。
[0062][0063][0064][0065]
其中, 表示矩阵元素点对点相加。clsmap1∈rn×n×
l
×2,clsmap2∈rn×n×
l
×2,regmap∈rn×n×
l
×4为最终得到的三张响应图,n表示响应图边长,l表示锚框不同尺度的数量。
[0066]
第五步,在跟踪推理阶段,通过自适应峰值选择模块对分类响应图和回归响应图进行处理,完成目标定位。在跟踪推理阶段,通过比较clsmap1和clsmap2两张响应图的最大响应值,取最大响应值锚框所对应的坐标为索引,在regmap中定位到预测框相对于上一帧的边界偏移。令clsmap1最大响应值点索引为令clsmap2最大响应值点索引为
[0067]
若
[0068][0069]
则
[0070][0071]
若
[0072][0073]
则
[0074]
[0075]imax
表示最大响应值锚框对应坐标。确定i
max
后,可以再回归响应图regmap中定位到边界偏移:
[0076]
(δcx,δcy,δw,δh)=regmap2[i
max
]
[0077]
δcx,δcy,δw,δh分别表示预测框中心横坐标偏移、中心纵坐标偏移、宽度偏移、高度偏移。根据(δcx,δcy,δw,δh)可以计算出当前帧预测框:
[0078]
(cx,cy,w,h)=(cx0 δcx,cy0 δcy,w0 δw,h0 δh)
[0079]
其中,cx,cy,w,h表示当前帧预测框的中心横坐标、中心纵坐标、宽度、高度;cx0,cy0,w0,h0表示上一帧预测框的中心横坐标、中心纵坐标、宽度、高度。
[0080]
第六步,分类分支使用交叉熵作为损失函数,回归分支使用坐标归一化的光滑化l1范数作为损失函数联合训练网络。分类分支完成区分前景与背景的二元分类任务,训练阶段分类分支输出的响应图为clsmap∈rn×n×
l
×2,经尺寸变换为clsmap∈rm×2,m=n
×n×
l,其对应的标签l
cls
∈rm;从l
cls
中抽取p个正样本生成正样本集并记录其索引从l
cls
中抽取q个负样本生成负样本集并记录其索引从clsmap中抽取索引对应样本生成正预测集抽取索引对应样本生成负预测集则有:
[0081][0082]
回归分支完成边界框回归的任务,训练阶段回归分支输出的响应图为regmap∈rn×n×
l
×4,经尺寸变换为regmap∈rm×4,m=n
×n×
l,其对应的标签l
reg
∈rm×4;从l
reg
中抽取p个正样本生成正样本集并记录其索引从regmap中抽取索引对应样本生成正预测集则有:
[0083][0084]
其中,smoothl1(
·
)表示光滑化l1范数。
[0085]
最终的loss定义为:
[0086][0087]
其中,γ∈[0,10)是用于平衡两种loss的超参数。
[0088]
对本发明方法进行仿真,仿真实验采用三组真实可见光-红外数据集:gtot数据集、rgbt234数据集、lasher数据集。其中,gtot数据集共包含50个序列,共计7800帧经手工标注的可见光-红外图片对,每个序列平均包含157帧;rgbt234数据集共包含234个序列,共计116700帧经手工标注的可见光-红外图片对,每个序列平均包含498帧;lasher数据集共包含1224个序列,共计734800帧经手工标注的可见光-红外图片对,每个序列平均包含600帧。因gtot和rgbt234未划分训练集和测试集,实验选择两种训练-测试方式:1、以rgbt234数据集和lasher数据集作为训练集对网络进行训练,并以gtot数据集作为测试集进行测试;2、以lasher数据集作为训练集对网络进行训练,并以rgbt234数据集作为测试集进行测试。训练每次前向传播过程中,从训练集中随机抽取一个序列,并生成该序列对应的可见
光-红外模板图像对和可见光-红外候选图像对并送入网络中。网络的优化器算法选择为随机梯度下降(sgd)、动量设置为0.9、权值衰减设置为0.0005、初始学习率设置为0.01、终止学习率设置为0.00001、批大小设置为28,数据集无需任何的预处理。两组实验以pr(precisionrate)、sr(successrate)和fps(framespersecond)作为评价指标。仿真实验软件环境:ubuntu16.04操作系统、python3.7、pytorch1.7.1;仿真实验硬件环境:i7-9700k处理器、16gb内存、英伟达2080ti显卡;完成实验中使用的网络架构如图2所示。
[0089]
表1与表2分别为本发明方法在gtot数据集及rgbt234数据集上仿真实验结果的性能指标。从实验结果来看,该方法对真实数据集非常有效,在gtot数据集上的跟踪精度达到了88.2%,在rgbt234数据集上的跟踪精度达到了75.0%,且速度达到了了140帧/秒。本发明方法在pr、sr、fps三个指标上均远超过包括eco、sgt、dusiamrt、siamft在内的先进方法;dapnet、manet等方法由于采取了在线训练的策略,速度受到了极大的限制,在gtot数据集和rgbt234数据集上的速度仅有1帧/秒左右;本发明方法采取了离线训练、在线跟踪的策略,在pr、sr指标与dapnet、manet处于同一水平的同时,速度超越了它们的一百倍以上。上述结果表明,本发明方法能够有效的利用可见光与红外两种模态具有判别性的语义特征,在保证跟踪精度和鲁棒性的同时仍能高速运行。
[0090]
表1不同方法在gtot数据集上的跟踪结果
[0091] ecosgtdapnetmanetsiamftdusiamrtourspr(%)77.085.188.288.975.876.688.2sr(%)63.162.870.771.962.362.870.3fps11.25.01.51.232.0117.0140.0
[0092]
表2不同方法在rgbt234数据集上的跟踪结果
[0093][0094][0095]
本发明使用端到端的离线训练、在线跟踪方式,以抵抗跟踪速度的下降。同时建立了双流孪生网络结构以提取两个模态的深层语义信息;并使用通道注意力和空间注意力模块生成自适应权重以增强特征的判别力并减小噪声,能更好地完成两个模态特征的融合;本方法在gtot数据集上的跟踪精度达到了88.2%,在rgbt234数据集上的跟踪精度达到了75.0%,且能以140帧/秒的速度运行,达到了实时性标准的6倍,体现了本发明方法相对于其他方法的优越性。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。