1.本发明属于图像描述领域,具体涉及一种基于实例分割的图像语义描述改进方法。
背景技术:
2.实例分割不仅可以提取出图像中的目标,同时还能给出基于像素级别的分类,相当于同时解决了图像目标检测和图像语义分割的任务,但是图像的内容丰富多彩,即使是不同的目标之间,他们也存在诸多的联系,通过为图像生成语句描述,可以提取出图片中丰富的语义信息,不仅可以获取图片中的目标,还能得到目标的属性,同时还可以获取目标之间的相互关系,借助于机器翻译领域经典的编解码框架,将图像视作一种语言,而描述语句视为另外一种语言的编解码框架成为图像语义描述的经典框架模型。
技术实现要素:
3.本发明要解决的技术问题是:对经典的基于编解码框架的图像语义描述框架进行改进,改进后算法的精度比原算法更高。
4.本发明基于bottom-up and top-down的编解码框架进行改进,包括以下步骤:
5.步骤1:输入一张图像,对图像进行实例分割提取实例区域;
6.其中步骤1的具体步骤为:
7.步骤101:实例分割采用mask rcnn网络,提取图片得到k个实例区域;
8.步骤2:对提取到的实例区域通过cnn提取特征;
9.步骤3:将提取到的特征输入到注意力模块;
10.步骤4:通过注意力机制给提取到的特征分配权重,并且融合特征;
11.其中步骤4的具体步骤为:
12.步骤401:将步骤2提取的特征向量和上一时刻输出的单词对应的词向量以及top-down lstm中的语句lstm中上一时刻的隐藏状态拼接成一个向量;
13.步骤402:将拼接好的向量输入top-down lstm中的注意力lstm,经过注意力lstm处理之后得到输出的隐藏状态,把它输入到注意力机制模块。
14.步骤403:注意力机制模块对输入的隐藏状态和输入的特征向量融合之后,使用双曲正切tanh激活函数处理得到各个特征向量的权重。
15.步骤404:使用softmax对前面的权重进行归一化处理,将归一化处理得到的权重与对应的特征向量相乘再累加输入top-down lstm中的语句lstm。
16.步骤5:将融合特征和上一时刻生成的单词的词向量输入当前时刻的lstm隐藏层;
17.步骤6:lstm隐藏层计算得到当前时刻的输出单词的概率分布;
18.其中步骤6的具体步骤为:
19.步骤601:将加权处理之后的特征向量和top-down lstm中的注意力lstm的输出隐藏层状态拼接之后输入top-down lstm中的语句lstm,经过语句lstm的处理,再使用
softmax归一化处理,得到每个单词对应的概率,概率最大的值对应的索引就是词典中单词对应的索引。
20.步骤7:通过概率分布,输出最大概率索引对应的单词;
21.其中步骤7的具体步骤为:
22.求出输出概率分布的最大值对应的下标号,从构造的词典中找到对应的下标号的单词。
23.步骤8:输出结束标志符或者输出达到最大长度时,所有输出的单词按序组成的句子为输入图像的描述语句。
24.综上所述,由于采用了上述技术方案,本发明的有益效果是:
25.(1)解决了传统编解码框架中使用基于目标检测的编码器提取图像特征时存在的区域重合从而导致生成描述中语义重复不准确的问题;
26.(2)基于实例分割的编码器将提取图像中的所有实例目标,解决了传统编码器忽略图像背景的问题,从而使得生成的描述更加详细。
附图说明
27.图1改进后图像语义描述算法的网络框架图
28.图2常用编码器提取语义特征结果对比图
29.图3基于实例分割的编码器提取语义特征结果图
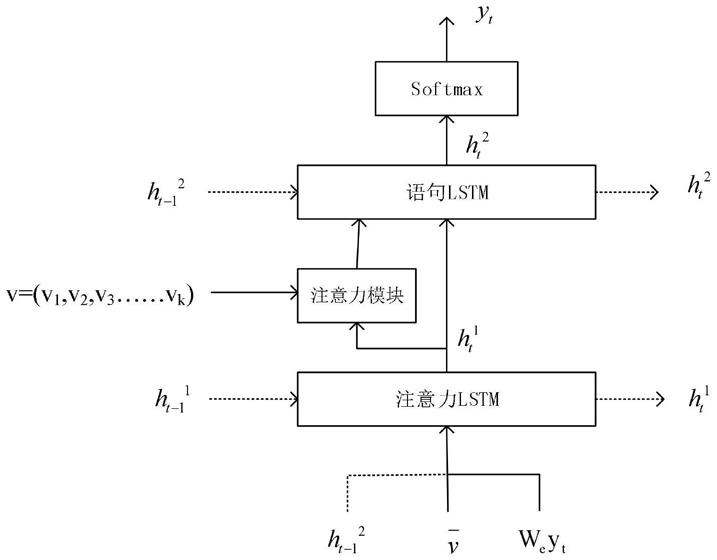
30.图4双层lstm架构图
31.图5lstm内部结构
具体实施方式
32.图像语义描述算法改进后的网络结构如图1所示。
33.经典bottom-up and top-down的编解码框架中通过使用faster r-cnn提取图像感兴趣目标区域,然后将提取的目标特征输入到解码器生成图像描述语句,对于简单场景下,这种做法能生成较为理想的描述语句,但是对于复杂场景下,目标如果出现相互重叠的情况则会使得提取的不同的区域出现目标重合的情况,这将使得不同的区域提取的特征出现特征重合的问题,在解码的过程中将使得生成的语句中出现重复的词语或者语句冗余的问题。另外使用vgg等基于网格划分的编码器,将图像均匀的分割成14
×
14个网格大小,但是会出现一个目标被分割在多个网格中,在解码的过程中无法对目标进行准确的描述。基于vgg和faster r-cnn提取语义特征的结果如图2所示。
34.实例分割算法可以有效的从像素级别提取出目标,使得图像中的每一个像素都有一个单独的类别,不会出现目标重叠的情况,也不会出现一个目标被分割在多个不同的网格中,因此使用实例分割算法将有效的解决上述描述中问题,如图3为使用实例分割算法对图2中的同一张图片处理的结果。具体使用mask rcnn网络提取出图像中的k个目标区域,得到的区域使用cnn提取特征,提取的特征为v=(v1,v2,v3……
vk),其中vi∈r1×
512
,每个特征的维度为512,如图4所示为结合注意力注意力机制的双层lstm架构图,其中图5为lstm内部结构图,在lstm中位于下面的是注意力lstm,主要用来给图像特征分配注意力权重,上面的是语句lstm,主要用来生成当前时刻的单词的概率分布。从v可以得到图像的全局特征
在图4中,我们把语句lstm的上一时刻的输出h
t-12
全局特征以及上一时刻输出的单词的词向量拼接在一起得到注意力lstm的输入x
t1
如下:
[0035][0036]
其中we∈r×n,e是词汇表中单词的数量,n是每个词向量的维度,因为前面图片特征的维度为512,所以这里的n为512。拼接的三个变量分别代表了输出的语句的上下文、图像全局特征和上一时刻的输出单词。
[0037]
注意力lstm的输出h
t
和局部特征向量v=(v1,v2,v3……
vk)一起作为输入,输入到注意力机制得到t时刻每个特征向量vi对应的权重a
i,t
,其对应的表达式如公式(2):
[0038]
α
i,t
=ω
at tanh(w
va
vi w
ha h
t1
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0039]
α
t
=softmax(a
t
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0040]
其中ω
at
、w
va
、w
ha
是网络学习的超参数,注意力机制输出的是对所有特征的加权和,如公式(4)所示:
[0041][0042]
接着再将注意力机制的输出和注意力lstm的输出h
t1
拼接得到新的向量具体拼接如公式(5)所示:
[0043][0044]
使用y
1:t
表示生成的单词序列(y1,y2……yt
),在每个时刻t生成单词yt的条件概率为公式(6):
[0045][0046]
其中w
p
∈rn×m为学习参数,b
p
为偏差项,完整的句子输出的概率可以由概率的乘法公式得出如公式(7)所示:
[0047][0048]
给定图片数据集以及对应的语句描述,我们以最小化公式(8)所示的交叉熵损失函数来训练学习参数。
[0049]
l
xe
(θ)=-∑log(p
θ
(y
t*
|y
1:t-1*
))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0050]
另外由于训练与测试时的目标不一致。即模型训练时以交叉熵为代价函数,最大化对数似然概率,然而在测试时以bleu-n、meteor、rouge、cider等指标评价模型的性能,这些指标离散且不可导的,无法直接通过优化评价指标提升生成的描述句子的质量。另外,基于交叉熵损失函数的训练方法只是最大化每一步生成单词的概率,而没有从整体句子的角度考虑,这样会出现整体训练损失变小了但是模型的实际评估指标并没有下降,为了进一步提高模型的效率,同时引入基于强化学习的训练方法,基于强化学习的训练方法分为两个阶段。
[0051]
两阶段训练法中的第一阶段为网络的预训练阶段,利用基于负对数似然的交叉熵损失函数对网络进行训练。因此,第一阶段的整体损失函数为式(8)。最小化该损失函数,可
得到一系列预训练好的模型和网络参数。
[0052]
两阶段训练法中的第二阶段为网络的微调训练阶段,将基于cider指标的强化学习目标函数代替预训练阶段整体损失函数中的交叉熵损失,用于第二阶段网络微调的整体损失函数。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
