1.一种网购平台入驻商户经营数据的预测方法和系统(以下简称“本系统”),隶属商业智能(business intelligence,简称:bi)领域。本系统综合运用了随机过程分析技术、数据挖掘和数据展现技术、计量经济学分析技术,目的是借助计算机算法帮助互联网经济时代的线上商户实现更加智能化的企业管理。本系统基于泊松过程数学原理,利用计量经济学模型对泊松过程分析中涉及的核心参数进行分析预测,可帮助平台商户实现总销售额预测、细分品种订单量预测、备货资金管理、客服人员服务效率监测及提升、客服人员结构优化和“差评”预警等六大功能。
2.在保证数据的及时性和有效性上,本系统采用了“滚动优化”策略。以回溯360天的方式,滚动抽样,每天更新一次核心参数的估值,并实时监测模型的可信度。本系统可根据最新的关键参数估值,结合各影响因子当前的时点数据,对未来30天的目标指标进行预测,帮助线上商户更加科学的管理企业的经营,同时系统保持实时自我更新的能力,确保“驾驶舱”面板上的各预测值处于实时更新状态。
3.本系统采用python编程语言。本说明书将对各个模块的核心算法提供相应的计算机代码说明,并采用假设抽样数据,对各个功能模块的运行结果进行简单地模拟。
4.本系统亦可作为线上平台商户端操作界面的增值服务模块,帮助线上商户挖掘数据价值,提高企业经营管理的精细化水平,提升线上平台对入驻该平台的商户的综合服务能力,增强线上平台的市场竞争力。
背景技术:
5.本系统的数学基础如下:基于更新理论,分析如下随机过程:“b2c购物网站上,b端商户销售某种商品,陆续会收到来自c端消费者按照某一数学规律的采购订单”。
6.我们观察[0,t]时间段内,订单的发生情况。我们把每笔订单发生的时刻,按时间顺序依次标记为1,2,3,
…
,用xi表示第i笔订单距离上一笔订单的等待时间。比如:x1表示从观察起始时刻至商户收到第1笔订单的等待时间,x2表示商户从第1笔订单到收到第2笔订单的等待时间(或称时间间隔),依次类推
…
。
[0007]
那么,x1,x2,
…
,就构成了一个随机变量序列。设{xn,n=1,2,
…
}是一列相互独立同分布的非负随机变量,xn表示第(n-1)笔订单和第n笔订单之间的时间间隔,用随机变量{n
t
,t≥0}表示观察时间[0,t]内订单发生的次数。这样的计数过程即为更新过程。
[0008]
由于b2c购物网站上c端消费者相互之间的购物行为是独立的,每笔订单基本都以匿名的方式发生,任何两个消费者之间的购买决策没有直接关联,因此,用更新理论能够较好地刻画b2c购物网站上的订单发生规律。
[0009]
用sn表示第n笔订单发生的时刻,即:,n=1,2,
…
用n(t)表示在[0,t]观察时间段订单发生的笔数,用s
n(t)
表示在时刻t之前最后一笔订单发生的时刻,用s
n(t) 1
表示在时刻t之后首笔订单发生的时刻。令y(t)= s
n(t) 1
-t,y(t)表示观察时点t与下一笔订单之间的时间间隔。当{xn,n≥1}独立同分布,且y(t)与xn也是同分布时,我们来分析随机变量xi的分布函数f(x)。
[0010]
令:得:g(x t)=g(x)g(t)对上式两边求导,得:令x>0,则:令,解微分方程,得:从而得到:即:xn(n≥1)服从指数分布。
[0011]
下面求解[0,t]上订单发生笔数n(t)的均值e(n
t
)。
[0012]
令:m(t)= e(n
t
),t≥0,根据更新理论,有下列更新方程:其中,f(t)为两笔订单之间的时间间隔xi的分布函数,将代入上述方程,得:。
[0013]
下面求解[0,t]上订单发生笔数n(t)的概率函数p(n
t
=n)。
[0014]
根据更新理论,p(n
t
=n) = fn(t)-f
n 1
(t)其中,f(t)为两笔订单之间的时间间隔xi的分布函数,fn(t)为f(t)的n重卷积,即:fn(t)=f*f*f*
…
*f。
[0015]
为了求解f(t)的n重卷积,需要先考察sn的矩母函数。
[0016]
由于xi服从指数分布,xi的矩母函数为:因为,由矩母函数的性质,得sn的矩母函数为:等式右边正是参数为(n,λ)的γ分布的矩母函数。由矩母函数的唯一性,得:sn服从γ分布,其概率分布密度函数为:其概率分布密度函数为:上述结果正是泊松分布的概率函数,表明n(t)是强度为λ的泊松过程。
技术实现要素:
[0017]
第一部分:六大功能模块模块1:在t时间段内,在b2c购物网站上,某b端商户收到的订单笔数符合强度为λ1的泊松过程。根据随机过程理论,可对该商户在未来t时间段内的总销售额情况绘制一条预测曲线。
[0018]
用{εn,n≥1}表示每笔订单的金额,εn是一个独立同分布的随机变量序列。用{n
t
,t≥0}表示t时间段内的订单笔数,n
t
是强度为λ1的泊松过程,且与{εn,n≥1}是相互独立的。用y
t
表示t时间段内的总销售额,则:
{y
t
,t≥0}为复合泊松过程,总销售额的均值e(y
t
)=λ1te(ε)。
[0019]
假设某商品有a和b两个品类,其中a款属商家重点推荐的爆款,b款购买人数相对较少。每笔订单要么选择a,要么选择b,概率分别为pa和pb。由于两个品类的购买量属离散型随机变量,根据大数定律,可用每个品类被选中的频率作为其概率的估值。本系统对近30天内,每个品类的购买频率进行统计,构造一张频率统计表。系统每天重新计算近30天的频率统计表,滚动更新。模型假定该商品各品类的概率分布在短期内是可以保持稳定的。
[0020]
表1:商品细分品类购买频率统计表商品品类购买频率(近30天)价格品类apaa品类bpbb表2:不同品类组合的概率情况分析订单笔数泊松过程概率金额商品选择概率对应杨辉三角数值1p(n
t
=1)apa[1,1]1p(n
t
=1)bpb[1,1]2p(n
t
=2)2ap
a2
[1,2,1]2p(n
t
=2)2bp
b2
[1,2,1]2p(n
t
=2)a b2 p
a pb[1,2,1]3p(n
t
=3)3ap
a3
[1,3,3,1]3p(n
t
=3)3bp
b3
[1,3,3,1]3p(n
t
=3)2a b3 p
a2 pb[1,3,3,1]3p(n
t
=3)2b a3 p
b2 pa[1,3,3,1]4p(n
t
=4)4ap
a4
[1,4,6,4,1]4p(n
t
=4)4bp
b4
[1,4,6,4,1]4p(n
t
=4)3a b4 p
a3 pb[1,4,6,4,1]4p(n
t
=4)3b a4 p
b3 pa[1,4,6,4,1]4p(n
t
=4)2a 2b6 p
a2 p
b2
[1,4,6,4,1]
……………
import mathimport matplotlib.pyplot as plt"""对未来一段时间的销售总金额绘制一条预测曲线""""""生成一个杨辉三角列表"""def coefficient_type(lambda_1,period_1,sigma_1):
ꢀꢀꢀꢀ
#初始化杨辉三角列表
ꢀꢀꢀꢀ
coefficient = [[1],[1,1]]
ꢀꢀꢀꢀ
#设置子列表的有效范围为sum_lambda之前之后各一个sigma_1的区间
ꢀꢀꢀꢀ
sum_lambda = lambda_1 * period_1
ꢀꢀꢀꢀ
sum_lambda_before = int(sum_lambda
ꢀ‑ꢀ
sigma_1)
ꢀꢀꢀꢀ
sum_lambda_after = int(sum_lambda sigma_1)
ꢀꢀꢀꢀ
#如果区间下限小于2,则直接输出初始列表
ꢀꢀꢀꢀ
if sum_lambda_after 《 2:
ꢀꢀꢀꢀꢀꢀꢀꢀ
return coefficient
ꢀꢀꢀꢀ
#如果区间上限大于等于2,则依次计算杨辉三角各子列表的数值
ꢀꢀꢀꢀ
else:
ꢀꢀꢀꢀꢀꢀꢀꢀ
for serial_number in range(2,sum_lambda_after 1):
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
#新生成一个列表,用于计算杨辉三角的数值
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
new_list = [1,1]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
#在新生成的列表中依次插入数值
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
for i in range(1,serial_number):
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
new_list.insert(i,coefficient[-1][i-1] coefficient[-1][i])
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
#将新生成的列表添加到杨辉三角列表中
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
coefficient.append(new_list)
ꢀꢀꢀꢀꢀꢀꢀꢀ
#输出列表有效区间内的所有系数
ꢀꢀꢀꢀꢀꢀꢀꢀ
return coefficient[sum_lambda_before:sum_lambda_after 1]"""描述泊松过程""""""速率用变量lambda_1表示,发生次数用变量occurrence_order表示观察时间段用变量period_order表示"""def p_possion_order(occurrence_order,lambda_1,period_order):
ꢀꢀꢀꢀ
#计算泊松分布概率函数中的k!
ꢀꢀꢀꢀ
occurrence_order_factorial = 1
ꢀꢀꢀꢀ
for i in range(1,occurrence_order 1):
ꢀꢀꢀꢀꢀꢀꢀꢀ
occurrence_order_factorial *= i
ꢀꢀꢀꢀ
#计算泊松分布概率函数中的lambda_1*t
ꢀꢀꢀꢀ
lambda_1_order = lambda_1 * period_order
ꢀꢀꢀꢀ
#计算泊松分布的概率函数
ꢀꢀꢀꢀ
result_order = math.pow(lambda_1_order,occurrence_order)
ꢀꢀꢀꢀ
result_order /= occurrence_order_factorial
ꢀꢀꢀꢀ
result_order *= math.e**(-lambda_1_order)
ꢀꢀꢀꢀ
return result_order"""绘制散点图""""""通过coefficient_list向函数传递计算不同商品组合对应的概率所需的系数列表用period_amount表示观察时间段用merchant_1向函数传递某商户商品价格和对应概率的字典用lambda_1表示泊松过程的速率
"""def scatter_diagram_amount(coefficient_list,period_amount,merchant_1,lambda_1):
ꢀꢀꢀꢀ
#创建一张空列表,用于统计不同金额和其对应概率
ꢀꢀꢀꢀ
summary_list = []
ꢀꢀꢀꢀ
#依次从coefficient_list列表中取出子列表进行计算
ꢀꢀꢀꢀ
for product in coefficient_list:
ꢀꢀꢀꢀꢀꢀꢀꢀ
#判断子列表对应的订单笔数
ꢀꢀꢀꢀꢀꢀꢀꢀ
number_temp = product[1]
ꢀꢀꢀꢀꢀꢀꢀꢀ
#该子列表对应的泊松过程概率函数值
ꢀꢀꢀꢀꢀꢀꢀꢀ
probability_temp = p_possion_order(number_temp,lambda_1,period_amount)
ꢀꢀꢀꢀꢀꢀꢀꢀ
"""依次计算子列表中每一项对应的总金额"""
ꢀꢀꢀꢀꢀꢀꢀꢀ
#根据子列表的对称性分成左右两部分计算
ꢀꢀꢀꢀꢀꢀꢀꢀ
length_temp = int(len(product) / 2)
ꢀꢀꢀꢀꢀꢀꢀꢀ
#计算左半部分的金额
ꢀꢀꢀꢀꢀꢀꢀꢀ
for j in range(0,length_temp):
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
amount_left = number_temp
ꢀ‑ꢀjꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
amount_left *= merchant_1['price_a']
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
amount_left = j * merchant_1['price_b']
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
#计算该金额对应的概率
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
probability_left = merchant_1['probability_a']**(number_temp
ꢀ‑ꢀ
j)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
probability_left *= merchant_1['probability_b']**j
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
probability_left *= product[j]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
probability_left *= probability_temp
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
#添加到summary_list总表
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
summary_list.append([amount_left,probability_left])
ꢀꢀꢀꢀꢀꢀꢀꢀ
#计算右半部分的金额
ꢀꢀꢀꢀꢀꢀꢀꢀ
for j in range(0,length_temp):
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
amount_right = number_temp
ꢀ‑ꢀjꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
amount_right *= merchant_1['price_b']
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
amount_right = j * merchant_1['price_a']
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
#计算该金额对应的概率
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
probability_right = merchant_1['probability_b']**(number_temp
ꢀ‑ꢀ
j)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
probability_right *= merchant_1['probability_a']**j
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
probability_right *= product[j]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
probability_right *= probability_temp
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
#添加到summary_list总表
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
summary_list.append([amount_right,probability_right])
ꢀꢀꢀꢀꢀꢀꢀꢀ
#子列表中间数值单独计算
ꢀꢀꢀꢀꢀꢀꢀꢀ
if len(product) % 2 == 1:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
mean_temp = int(number_temp / 2)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
amount_middle = merchant_1['price_a'] merchant_1['price_b']
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
amount_middle *= mean_temp
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
#计算该金额对应的概率
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
probability_middle = merchant_1['probability_a']**mean_temp
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
probability_middle *= merchant_1['probability_b']**mean_temp
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
probability_middle *= product[mean_temp]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
probability_middle *= probability_temp
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
#添加到summary_list总表
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
summary_list.append([amount_middle,probability_middle])
ꢀꢀꢀꢀ
#返回总表
ꢀꢀꢀꢀ
return summary_list"""假设系统测算的lambda_1等于2,sigma_1等于5,预测某商户未来30天的"销售总额-概率"数据列表"""lambda_1 = 2sigma_1 = 5period_1 = 30period_amount = 30#假设某商户商品价格和对应概率的字典如下merchant_1 = {
ꢀꢀꢀꢀ
'price_a': 2,
ꢀꢀꢀꢀ
'price_b': 5,
ꢀꢀꢀꢀ
'probability_a': 0.8,
ꢀꢀꢀꢀ
'probability_b': 0.2,
ꢀꢀꢀꢀ
}coefficient_list = []coefficient_list = coefficient_type(lambda_1,period_1,sigma_1)summary_list = scatter_diagram_amount(coefficient_list,period_amount,
ꢀꢀꢀꢀ
merchant_1,lambda_1)"""绘制散点图"""
x_data = []y_data = []for sub_list in summary_list:
ꢀꢀꢀꢀ
x_data.append(sub_list[0])
ꢀꢀꢀꢀ
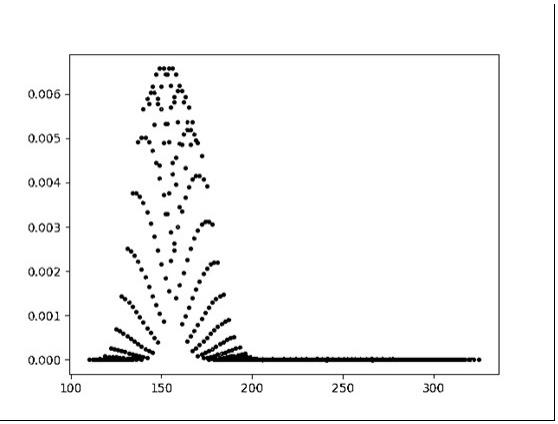
y_data.append(sub_list[1])plt.scatter(x_data, y_data, s=10)plt.show()以上代码的运行结果,如《说明书附图》中的图号1.“模块1演示”所示。
[0021]
模块2:对每一细分品种的销售量绘制预测曲线。
[0022]
假设某商品分为品种1和品种2,c端消费者选择品种1的概率为p,选择品种2的概率为1-p。那么,在[0,t]时间段内,品种1的销量n1(t)和品种2的销量n2(t)是相互独立的随机变量,分别服从均值为λ1tp和λ1t(1-p)的泊松分布。
[0023]
即:品种1的概率函数为:品种2的概率函数为:import mathimport matplotlib.pyplot as plt"""对每一细分品种的销售量绘制预测曲线速率用变量lambda_1表示,发生次数用变量occurrence_1表示,观察时间段用变量period_1表示选择某一细分品类的概率用变量probability_1表示"""def p_possion(occurrence_1,lambda_1,period_1,probability_1):
ꢀꢀꢀꢀ
#计算泊松分布概率函数中的k!
ꢀꢀꢀꢀ
occurrence_1_factorial = 1
ꢀꢀꢀꢀ
for i in range(1,occurrence_1 1):
ꢀꢀꢀꢀꢀꢀꢀꢀ
occurrence_1_factorial *= i
ꢀꢀꢀꢀ
#计算泊松分布概率函数中的lambda_1*t*p
ꢀꢀꢀꢀ
lambda_1_temp = lambda_1 * period_1 * probability_1
ꢀꢀꢀꢀ
#计算泊松分布的概率函数
ꢀꢀꢀꢀ
result_1 = math.pow(lambda_1_temp,occurrence_1) / occurrence_1_factorial
ꢀꢀꢀꢀ
result_1 *= math.e**(-lambda_1_temp)
ꢀꢀꢀꢀ
return result_1#系统根据大数定律自动获取消费者选择每个品类的概率估值#假设某商户的细分品类概率估值字典如下merchant_1 = {
ꢀꢀꢀꢀ
'type_1': 0.8,
ꢀꢀꢀꢀ
'type_2': 0.2,
ꢀꢀꢀꢀ
}"""假设系统测算的每天的速率lambda_1为4笔订单量,预测未来30天的总订单量"""lambda_1 = 4period_1 = 30for type,probability_1 in merchant_1.items():
ꢀꢀꢀꢀ
if probability_1 != 0:
ꢀꢀꢀꢀꢀꢀꢀꢀ
"""计算均值左右两边各1个标准差范围的概率值"""
ꢀꢀꢀꢀꢀꢀꢀꢀ
lambda_1_sum = lambda_1 * period_1 * probability_1
ꢀꢀꢀꢀꢀꢀꢀꢀ
sigma_1 = math.sqrt(lambda_1_sum)
ꢀꢀꢀꢀꢀꢀꢀꢀ
#建立存储x轴和y轴数据的空列表
ꢀꢀꢀꢀꢀꢀꢀꢀ
x_data = []
ꢀꢀꢀꢀꢀꢀꢀꢀ
y_data = []
ꢀꢀꢀꢀꢀꢀꢀꢀ
#计算概率
ꢀꢀꢀꢀꢀꢀꢀꢀ
for occurrence_1 in range(int(lambda_1_sum
ꢀ‑ꢀ
sigma_1),
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
int(lambda_1_sum sigma_1)):
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
volume_merchant_1 = p_possion(occurrence_1,lambda_1,
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
period_1,probability_1)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
x_data.append(occurrence_1)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
y_data.append(volume_merchant_1)
ꢀꢀꢀꢀꢀꢀꢀꢀ
"""绘制散点图"""
ꢀꢀꢀꢀꢀꢀꢀꢀ
plt.scatter(x_data, y_data, s=10)
ꢀꢀꢀꢀꢀꢀꢀꢀ
plt.show()以上代码的运行结果,如《说明书附图》中的图号2.“模块2演示”所示。
[0024]
模块3:消费者订金——备货资金预测曲线。
[0025]
本模块应用场景:消费者在商家提前预付订金,用于其在指定日期(比如:“双11”)集中购物消费。本模块的用途:帮助商家预测消费者订金所带来的现金流,实现合理安排备货资金的功能。
[0026]
假设b端商户提前t0时间(比如:1个月)向c端消费者开展预付订金购物优惠活动。消费者可提前支付订金,以便在指定日期享受购物优惠。按照泊松过程支付的第1笔订金的支付时点为s1,我们将(t0-s1)记为第1笔订金对该商户的现金流贡献度。显然,越早支付的订金,在商户账面上停留的时间将越长,对该商户的现金流入贡献度也越大。
[0027]
第i笔订金的现金流贡献度为(t0-si)。商户在[0,t0]时间段内共收到n
t0
笔订金,
则所有订金的总贡献度为:我们需要求解上述随机过程的均值,作为合理安排备货资金的依据。由于对于泊松过程而言,在[0,t0]时间段内已知发生n笔订单的条件下,各订单发生的时刻s1,s2,s3,
…
,sn可看作不排序的随机变量,这些随机变量相互独立且具有相同的分布u(0,t0)。u表示均匀分布随机变量:从而得到:商户账面上订金的总贡献度,或者可理解为预收资金为商户带来的现金流量贡献分别与t
02
和泊松过程的强度λ成正比。
[0028]
import math"""预测消费者支付订金的总贡献度速率用变量lambda_1表示,支付订金的观察时间段用变量term_1表示"""#计算商户收到的所有订金总贡献度的均值def p_possion_deposit(lambda_1,term_1):
ꢀꢀꢀꢀ
result = 0.5 * lambda_1 * term_1**2
ꢀꢀꢀꢀ
return result"""假设某商户在"双11"前30天开展预付订金活动,系统测算的速率lambda_1为每天4笔"""lambda_1 = 4term_1 = 30deposit_merchant_1 = p_possion_deposit(lambda_1,term_1)print("contribution of cash flow is:" str(deposit_merchant_1))上述代码的运算结果为1800。
[0029]
模块4:客服人员服务效率监测及提升模块。
[0030]
本模块的功能是帮助商户改善在线客服人员的服务效率。当c端有购买意向的消费者按照强度为λ2的泊松过程,呼叫客服人员时,假定客服人员可以及时响应,并向该消费
者提供咨询服务。我们用y表示每名消费者所耗用的服务时间,则y是独立同分布的随机变量,其分布函数为g(t)。
[0031]
用n1(t)表示在时刻t,已经服务完的客户数。n2(t)表示在时刻t,未服务完的客户数。假设某消费者于时刻s呼叫客服人员,s≤t,客服人员立即给予响应,那么,到时刻t服务完毕,就意味着该客户的服务时间y≤(t-s),其概率为g(t-s)。
[0032]
服务完毕的概率分布密度函数为:p(s)= g(t-s),s≤t。那么,在[0,t]时间段内,已经服务完的客户数n1(t)的均值为:在[0,t]时间段内,未服务完的客户数n2(t)的均值为:我们只需知道消费者所耗用服务时间的分布函数g(t),便可预测到t时刻终了,客服系统总共可服务多少名客户,以及还剩多少名客户尚未完成咨询服务。这一功能可帮助商家评估当前客服人员的综合服务效率,以及在下一阶段,是否有必要调整客服人员数量,或者提高客服人员技能,以便提升客服系统的运行效率。
[0033]
该模块还可用于帮助商家及时应对泊松过程强度λ2的变化。针对λ2在未来一段时间可能出现的变化(比如:双“11”),商家可及时优化客服系统,以便提前做好应对准备。
[0034]
以y~e(λ3)为例,则:则:import math"""消费者咨询客服的强度用变量lambda_2表示,指数分布的参数用变量lambda_3表示观察时间段用变量period_3表示预测可服务完的客户数的均值"""def complete_serve(lambda_2,period_3,lambda_3):
ꢀꢀꢀꢀ
integral_t = (math.e**(-lambda_3 * period_3)
ꢀ‑ꢀ
1) / lambda_3 period_3
ꢀꢀꢀꢀ
mean_complete = lambda_2 * integral_t
ꢀꢀꢀꢀ
return mean_complete#假设某商户的客服时间的概率分布的参数字典如下
merchant_1 = {
ꢀꢀꢀꢀ
'lambda_serve': 5,
ꢀꢀꢀꢀ
}#假设系统测算的lambda_2等于8名客户,预测未来30天可服务完的客户数均值lambda_2 = 8period_3 = 30lambda_3 = merchant_1['lambda_serve']complete_merchant_1 = int(complete_serve(lambda_2,period_3,lambda_3))print(complete_merchant_1)上述代码的运行结果为:238。
[0035]
模块5:客服人员结构优化。
[0036]
本模块分析售后客服人员响应客户咨询(处理售后问题)数量的概率函数p(na(t)=k),以及售前客服人员响应客户咨询数量的概率函数p(nb(t)=k)。本模块可实现帮助商家优化客服人员(分为售前和售后两类)结构的功能。
[0037]
当客服系统收到一个来自消费者的呼叫,属于售后问题的概率为pa,属于售前咨询的概率为(1-pa),则:则:import mathimport matplotlib.pyplot as plt"""绘制未来30天客户咨询售前及售后问题数量的预测曲线,帮助商户优化客服人员结构速率用变量lambda_2表示,发生次数用变量occurrence_2表示,观察时间段用变量period_2表示客户咨询归属某一类(售前或者售后)的概率用变量probability_2表示"""def p_possion_service(occurrence_2,lambda_2,period_2,probability_2):
ꢀꢀꢀꢀ
#计算泊松分布概率函数中的k!
ꢀꢀꢀꢀ
occurrence_2_factorial = 1
ꢀꢀꢀꢀ
for i in range(1,occurrence_2 1):
ꢀꢀꢀꢀꢀꢀꢀꢀ
occurrence_2_factorial *= i
ꢀꢀꢀꢀ
#计算泊松分布概率函数中的lambda_2*t*p
ꢀꢀꢀꢀ
lambda_2_temp = lambda_2 * period_2 * probability_2
ꢀꢀꢀꢀ
#计算泊松分布的概率函数
ꢀꢀꢀꢀ
result = math.pow(lambda_2_temp,occurrence_2) / occurrence_2_sn(t) 1
-t,y(t)表示出现下一次差评的时间间隔。y(t)的分布函数为: 根据上式即可预测未来一周出现差评的概率,以便商家提前做好应对准备。
[0041]
import math"""预测未来一周出现“差评”的概率差评出现的速率用变量lambda_3表示,观察时间段用变量period_3表示""""""下一次出现差评的时间间隔的分布函数"""def p_possion_feedback(lambda_3,period_3):
ꢀꢀꢀꢀ
#计算分布函数中的lambda_3*t
ꢀꢀꢀꢀ
lambda_3_temp = lambda_3 * period_3
ꢀꢀꢀꢀ
#分布函数公式
ꢀꢀꢀꢀ
result = (1
ꢀ‑ꢀ
math.e**(-lambda_3_temp))
ꢀꢀꢀꢀ
return result#系统根据历史记录自动获取某商户差评出现的频率数值delta#假设某商户差评频率字典如下merchant_1 = {
ꢀꢀꢀꢀ
'delta': 0.01,
ꢀꢀꢀꢀ
}"""假设系统测算的每天的订单量速率lambda_1为4笔,预测未来7天出现“差评”的概率"""lambda_1 = 4lambda_3 = lambda_1 * merchant_1['delta']period_3 = 7feedback_merchant_1 = p_possion_feedback(lambda_3,period_3)print("probability of negative feedback is:" str(feedback_merchant_1))上述代码的运行结果为:0.24。
[0042]
第二部分:模型关键参数的估值及自动校准基本思路如下:构造样本统计量对模型中的核心参数λ1、λ2进行估值。根据中心极限定理,当样本量足够大时,样本均值逼近于正态分布。因此,构造z值估计量,根据样本均值计算给定置信水平下总体均值的置信区间。而泊松分布的均值,正是强度λ。
[0043]
模型通过对订单笔数进行抽样,计算样本均值,从而得到给定置信水平下强度λ1的置信区间;模型通过对呼叫客服人员的消费者人数进行抽样,计算样本均值,从而得到给定置信水平下强度λ2的置信区间。样本数量越大,置信区间越窄,模型的估值越精确。
[0044]
由于λ并不是一个固定不变的量,λ值受多个因素影响,比如:商户的历史销量排名、价格竞争力、好评率等,都是该商户当前阶段λ取值的影响因素。用函数可表示为:λ
t
=f(r
t
,p
t
,g
t
),其中:r
t
表示历史销量排名,p
t
表示价格竞争力,g
t
表示好评率,λ
t
是r
t
、p
t
、g
t
的函数。为了对下一阶段的λ取值做出实时动态调整,以便确保模型预测能力的可靠性,我们需要计算各影响因子的系数。
[0045]
模型采用了“滚动优化、反馈矫正”的策略。以回溯360天的方式,滚动抽样,每天更新一次各参数的估值,并实时监测模型的可信度,确保“驾驶舱”面板上的各预测值处于实时更新状态。
[0046]
具体步骤如下:首先,构造核心参数λ的置信区间的样本统计量:当样本量足够大(n≥30)时,样本均值渐近服从正态分布。此时,z统计量的计算公式为: 其中,为样本均值,u为总体均值,s为样本标准差,n为样本数量。s的计算公式为: 由于z服从标准正态分布,可以得出总体均值u在(1-α)置信水平下的置信区间为:其中,是标准正态分布右侧面积为时的z值;(1-α)为置信水平。
[0047]
本系统面板实时显示该商户日均订单量的预测值区间,数据每天更新一次。python代码如下:import math"""计算lambda_1的置信区间""""""样本均值函数"""def mean_sample(sampling_list):
ꢀꢀꢀꢀ
#求和
ꢀꢀꢀꢀ
sum_temp = 0
ꢀꢀꢀꢀ
for i in sampling_list:
ꢀꢀꢀꢀꢀꢀꢀꢀ
sum_temp = i
ꢀꢀꢀꢀ
#求均值
ꢀꢀꢀꢀ
result_mean = sum_temp / len(sampling_list)
ꢀꢀꢀꢀ
return result_mean"""样本标准差函数"""def standard_deviation_sample(sampling_list):
ꢀꢀꢀꢀ
deviation_temp = 0
ꢀꢀꢀꢀ
for j in sampling_list:
ꢀꢀꢀꢀꢀꢀꢀꢀ
deviation_temp = (j
ꢀ‑ꢀ
mean_sample(sampling_list))**2
ꢀꢀꢀꢀ
deviation_temp /= len(sampling_list)
ꢀ‑ꢀ1ꢀꢀꢀꢀ
result_standard = deviation_temp**0.5
ꢀꢀꢀꢀ
return result_standard"""计算置信区间"""def confidence_intervals(z_score,sampling_list):
ꢀꢀꢀꢀ
intervals_temp = len(sampling_list)**0.5
ꢀꢀꢀꢀ
intervals_temp = standard_deviation_sample(sampling_list) / intervals_temp
ꢀꢀꢀꢀ
intervals_temp *= z_score
ꢀꢀꢀꢀ
mean_temp = mean_sample(sampling_list)
ꢀꢀꢀꢀ
#下限
ꢀꢀꢀꢀ
lower_limit = mean_temp
ꢀ‑ꢀ
intervals_temp
ꢀꢀꢀꢀ
#上限
ꢀꢀꢀꢀ
upper_limit = mean_temp intervals_temp
ꢀꢀꢀꢀ
intervals_sample = [lower_limit,upper_limit]
ꢀꢀꢀꢀ
return intervals_sample#每日订单量的30天算术平均值抽样数据存入sampling_list列表sampling_list = [5,6,5,4,3,6,5,6,5,5,7,4]#95%置信水平下的z值为1.96z_score = 1.96print(confidence_intervals(z_score,sampling_list))上述代码的运行结果为:[4.47,5.69]。
[0048]
接下来,为每个细分行业建立能够对λ取值产生影响的影响因子库。本模型将历史销售量排名、价格竞争力、好评率三项指标纳入影响因子库,分别用字母r、p、g表示。但该三项指标仅仅只是示例,具体哪些指标对λ值产生实际意义上的影响,不同行业之间会有所差异。因此,我们需要建立行业维度的影响因子库,并且需要通过相关系数的显著性检验来进行筛选。
[0049]
利用样本相关系数r作为度量自变量和因变量之间线性相关关系强度的统计量,计算公式为:
ꢀ
因为r是通过抽样产生的随机变量,通过对样本数据的r值进行t检验,来判断哪些影响因子与λ之间存在显著的线性关系。
[0050]
假设总体相关系数ρ=0,计算检验的统计量t,即:h0:ρ=0;h1:ρ≠0给定显著性水平α,若|t|>t
α/2
,则拒绝原假设h0,认为该影响因子可以纳入影响因子库。比如:只有历史销售量排名r和好评率g两项指标通过了t检验,则把上述两项指标纳入该细分行业的影响因子库。最终,建立各细分行业维度的影响因子库。
[0051]
第三步,将影响因子作为自变量,λ作为因变量,构建线性回归模型:其中:为偏回归系数,是通过抽样对总体参数的估计值。
[0052]
样本数据按照如下方式采集:以天为单位,每天的订单笔数记为xi(i=1,2,3,
…
),以30天为一个周期,一个周期内xi的算术平均值记为,离抽样时点最近30天的均值记为,再往前推30天的均值记为,依次类推,直到回溯至360天,即第12个周期,记为。销售量排名和好评率采用同样的抽样方法。如下表所示: 周期λrgtttt-1t-1t-1t-2t-2t-2t-3t-3t-3
t-4t-4t-4t-5t-5t-5t-6t-6t-6t-7t-7t-7t-8t-8t-8t-9t-9t-9t-10t-10t-10t-11t-11t-11采用最小二乘法来求解等各参数的值。
[0053]
作为数据演示,下面以仅有1个影响因子r为例,根据最小二乘法,求解使残差平方和最小的参数值。
[0054]
令,在给定样本数据后,q是和的函数,且最小值总是存在。根据极值定理,对q求相应于和的偏导数,令其等于0,即:解上述方程组,得:
回归模型的参数求解出来以后,还不能立刻使用。因为和是利用样本数据做出的估计值,只有通过了显著性检验,才能证明估值的可靠性。
[0055]
本系统会对线性关系的显著性进行检验。构造的检验统计量如下:ssr为回归平方和;sse为残差平方和;k为自变量的个数,在一元线性回归模型中,k值为1。上述抽样分布服从分子自由度为1,分母自由度为(n-2)的f分布。
[0056]
提出假设h0:β1=0,即假设自变量和因变量之间的线性因果关系不显著。确定显著性水平为α,若f值>f
α
,则拒绝h0,可认为影响因子对λ产生的线性关系影响是显著的。反之,模型的参数估值结果就是不可靠的,无法准确判定模型的有效性。逻辑关系如下:样本统计结果结论f值>f
α
拒绝原假设h0本系统将根据样本数据的f统计量数值与f分布表的比对结果,给出在满足“f值>f
α”的条件下,α的最小值。(1-α)的取值反映了模型整体的可靠性水平,将实时反馈在本系统的面板上。(1-α)值越大,代表模型的可信度越高。
[0057]
最后,本系统采用滚动优化的策略,对λ1,λ2,的取值进行自动校准,不断修正模型参数,使模型保持自我优化能力,逐步提升模型的精准度。本系统采用回溯360天的方式,滚动抽样,每天更新一次的估值,并实时监测可信度。未来30天λi的预测值,将根据最新的值,结合各影响因子当前的时点数据,实时进行自我更新,从而确保本系统面板上的各预测数值处于实时更新状态。
[0058]
import math"""计算线性回归模型的参数,返回lambda值,并实现每日滚动优化功能""""""一元线性回归模型"""def linear_regression(dependent_list,independent_list):
ꢀꢀꢀꢀ
#判断抽样数据是否匹配
ꢀꢀꢀꢀ
if len(dependent_list) == len(independent_list):
ꢀꢀꢀꢀꢀꢀꢀꢀ
"""求第一个参数的估计值beta_1"""
ꢀꢀꢀꢀꢀꢀꢀꢀ
#计算分子前半部分
ꢀꢀꢀꢀꢀꢀꢀꢀ
part_1_temp = 0
ꢀꢀꢀꢀꢀꢀꢀꢀ
for i in range(0,len(dependent_list)):
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
part_1_temp = dependent_list[i] * independent_list[i]
ꢀꢀꢀꢀꢀꢀꢀꢀ
part_1_temp *= len(dependent_list)
ꢀꢀꢀꢀꢀꢀꢀꢀ
#计算分子后半部分
ꢀꢀꢀꢀꢀꢀꢀꢀ
part_2_temp = 0
ꢀꢀꢀꢀꢀꢀꢀꢀ
for i in range(0,len(dependent_list)):
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
part_2_temp = dependent_list[i]
ꢀꢀꢀꢀꢀꢀꢀꢀ
part_3_temp = 0
ꢀꢀꢀꢀꢀꢀꢀꢀ
for i in range(0,len(dependent_list)):
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
part_3_temp = independent_list[i]
ꢀꢀꢀꢀꢀꢀꢀꢀ
#计算分母前半部分
ꢀꢀꢀꢀꢀꢀꢀꢀ
part_4_temp = 0
ꢀꢀꢀꢀꢀꢀꢀꢀ
for i in range(0,len(dependent_list)):
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
part_4_temp = independent_list[i]**2
ꢀꢀꢀꢀꢀꢀꢀꢀ
part_4_temp *= len(dependent_list)
ꢀꢀꢀꢀꢀꢀꢀꢀ
#计算分母后半部分
ꢀꢀꢀꢀꢀꢀꢀꢀ
part_5_temp = part_3_temp**2
ꢀꢀꢀꢀꢀꢀꢀꢀ
#将各个部分代入公式
ꢀꢀꢀꢀꢀꢀꢀꢀ
beta_1 = part_1_temp
ꢀ‑ꢀ
part_2_temp * part_3_temp
ꢀꢀꢀꢀꢀꢀꢀꢀ
beta_1 /= (part_4_temp
ꢀ‑ꢀ
part_5_temp)
ꢀꢀꢀꢀꢀꢀꢀꢀ
"""求第二个参数的估计值beta_zero"""
ꢀꢀꢀꢀꢀꢀꢀꢀ
#计算因变量的均值
ꢀꢀꢀꢀꢀꢀꢀꢀ
mean_dependent_temp = 0
ꢀꢀꢀꢀꢀꢀꢀꢀ
for i in dependent_list:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
mean_dependent_temp = i
ꢀꢀꢀꢀꢀꢀꢀꢀ
mean_dependent = mean_dependent_temp / len(dependent_list)
ꢀꢀꢀꢀꢀꢀꢀꢀ
#计算自变量的均值
ꢀꢀꢀꢀꢀꢀꢀꢀ
mean_independent_temp = 0
ꢀꢀꢀꢀꢀꢀꢀꢀ
for j in independent_list:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
mean_independent_temp = j
ꢀꢀꢀꢀꢀꢀꢀꢀ
mean_independent = mean_independent_temp / len(independent_list)
ꢀꢀꢀꢀꢀꢀꢀꢀ
#将各个部分代入公式
ꢀꢀꢀꢀꢀꢀꢀꢀ
beta_zero = mean_dependent
ꢀ‑ꢀ
beta_1 * mean_independent
ꢀꢀꢀꢀꢀꢀꢀꢀ
#将模型的参数估值封装入字典
ꢀꢀꢀꢀꢀꢀꢀꢀ
parameter_estimation = {}
ꢀꢀꢀꢀꢀꢀꢀꢀ
parameter_estimation['beta_zero'] = beta_zero
ꢀꢀꢀꢀꢀꢀꢀꢀ
parameter_estimation['beta_1'] = beta_1
ꢀꢀꢀꢀꢀꢀꢀꢀ
return parameter_estimation"""对lambda_1进行实时预测parameter_estimation向函数传递回归模型参数估值
real_time向函数传递自变量的实时数据"""def forecast_lambda(parameter_estimation,real_time):
ꢀꢀꢀꢀ
valuation_beta_zero = parameter_estimation['beta_zero']
ꢀꢀꢀꢀ
valuation_beta_1 = parameter_estimation['beta_1']
ꢀꢀꢀꢀ
result_lambda_1 = valuation_beta_zero valuation_beta_1 * real_time
ꢀꢀꢀꢀ
#返回lambda_1值
ꢀꢀꢀꢀ
return result_lambda_1"""显著性检验n向函数传递自变量的个数"""def significance_test(dependent_list,independent_list,parameter_estimation,n):
ꢀꢀꢀꢀ
#计算因变量的均值
ꢀꢀꢀꢀ
mean_dependent_temp = 0
ꢀꢀꢀꢀ
for i in dependent_list:
ꢀꢀꢀꢀꢀꢀꢀꢀ
mean_dependent_temp = i
ꢀꢀꢀꢀꢀꢀꢀꢀ
mean_dependent = mean_dependent_temp / len(dependent_list)
ꢀꢀꢀꢀ
valuation_beta_zero = parameter_estimation['beta_zero']
ꢀꢀꢀꢀ
valuation_beta_1 = parameter_estimation['beta_1']
ꢀꢀꢀꢀ
#计算f统计量的分子
ꢀꢀꢀꢀ
f_numerator = 0
ꢀꢀꢀꢀ
for i in independent_list:
ꢀꢀꢀꢀꢀꢀꢀꢀ
fitted_value = valuation_beta_zero valuation_beta_1 * i
ꢀꢀꢀꢀꢀꢀꢀꢀ
f_numerator = (fitted_value
ꢀ‑ꢀ
mean_dependent)**2
ꢀꢀꢀꢀ
f_numerator /= n
ꢀꢀꢀꢀ
#计算f统计量的分母
ꢀꢀꢀꢀ
f_denominator = 0
ꢀꢀꢀꢀ
for j in range(0,len(dependent_list)):
ꢀꢀꢀꢀꢀꢀꢀꢀ
fitted_value = valuation_beta_1 * independent_list[j]
ꢀꢀꢀꢀꢀꢀꢀꢀ
fitted_value = valuation_beta_zero
ꢀꢀꢀꢀꢀꢀꢀꢀ
f_denominator = (dependent_list[j]
ꢀ‑ꢀ
fitted_value)**2
ꢀꢀꢀꢀ
f_denominator /= (len(dependent_list)
ꢀ‑ꢀ
2)
ꢀꢀꢀꢀ
#将分子分母代入公式
ꢀꢀꢀꢀ
f_statistic = f_numerator / f_denominator
ꢀꢀꢀꢀ
#返回f值
ꢀꢀꢀꢀ
return f_statistic
"""显示模型预测精度f_distribution_statistics向函数传递f分布统计表"""def reliability_model(f_statistic,f_distribution_statistics):
ꢀꢀꢀꢀ
#对f分布统计表中的值进行排序
ꢀꢀꢀꢀ
list_temp = list(f_distribution_statistics.items())
ꢀꢀꢀꢀ
list_temp.sort(key=lambda value: value[1],reverse=true)
ꢀꢀꢀꢀ
#比f_statistic小的所有值中最大的值对应的置信水平
ꢀꢀꢀꢀ
i = 0
ꢀꢀꢀꢀ
while true:
ꢀꢀꢀꢀꢀꢀꢀꢀ
if f_statistic 《= list_temp[i][1]:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
i = 1
ꢀꢀꢀꢀꢀꢀꢀꢀ
else:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
break
ꢀꢀꢀꢀ
#返回模型精度数值
ꢀꢀꢀꢀ
return list_temp[i-1][0]"""按天滚动优化former_sampling_list是回溯360天的抽样数据列表"""def rolling_optimization(former_sampling_list,new_data):
ꢀꢀꢀꢀ
#替换新数据
ꢀꢀꢀꢀ
del former_sampling_list[0]
ꢀꢀꢀꢀ
former_sampling_list.append(new_data)
ꢀꢀꢀꢀ
#判断列表长度是否正确
ꢀꢀꢀꢀ
if len(former_sampling_list) != 360:
ꢀꢀꢀꢀꢀꢀꢀꢀ
print("update failed")
ꢀꢀꢀꢀ
else:
ꢀꢀꢀꢀꢀꢀꢀꢀ
#建立一张空表
ꢀꢀꢀꢀꢀꢀꢀꢀ
new_list = []
ꢀꢀꢀꢀꢀꢀꢀꢀ
#每30天数据求一次均值
ꢀꢀꢀꢀꢀꢀꢀꢀ
i =
ꢀ‑1ꢀꢀꢀꢀꢀꢀꢀꢀ
while true:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
new_list_temp = 0
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
j = 0
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
while j 《 30:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
i = 1
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
j = 1
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
new_list_temp = former_sampling_list[i]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
new_list_temp /= 30
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
new_list.append(new_list_temp)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
if i == 359:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
break
ꢀꢀꢀꢀꢀꢀꢀꢀ
#返回更新后的列表
ꢀꢀꢀꢀꢀꢀꢀꢀ
return new_listdependent_list = [5,6,5,4,3,6,5,6,5,5,7,4]independent_list = [8,7,8,10,10,9,8,8,8,8,9,9]n = 1real_time = 5f_distribution_statistics = {
ꢀꢀꢀꢀ
'99%': 10.044,
ꢀꢀꢀꢀ
'95%': 4.96,
ꢀꢀꢀꢀ
'90%': 3.29,
ꢀꢀꢀꢀ
}parameter_estimation = linear_regression(dependent_list,independent_list)print(parameter_estimation)lambda_1 = forecast_lambda(parameter_estimation,real_time)print(lambda_1)f_statistic = significance_test(dependent_list,independent_list, parameter_estimation,n)print(f_statistic)accuracy = reliability_model(f_statistic,f_distribution_statistics)print(accuracy)上述代码的运行结果为:=10.27,,=-0.61,λ1=7.22,f值等于3.51,模型精准度为95%。
[0059]
本系统商户端操作界面设计图如《说明书附图》中的图号4.“操作界面设计图”所示。附图说明:图1是模块1的python代码导入模拟数据后的运行结果散点图;图2是模块2的python代码导入模拟数据后的运行结果散点图;图3是模块5的python代码导入模拟数据后的运行结果散点图;图4是本系统商户端操作界面的一种设计图,综合了本系统六大功能模块,该图中1号位置是操作界面的标题区,可以显示诸如“商户智能驾驶舱”之类的标题,2号位置是基本信息区,展示该商户所销售商品的基本信息,3号位置用仪表盘的方式显示该商户销售均值的当前估值,6号位置显示的是预测值的精确度水平,其它4、5、7、8号位置均为六大模块
的预测值显示区域。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。