从自然语言自动生成功能架构文档和软件设计与分析规范文档的过程和系统
1.1.相关申请的交叉引用
2.本发明要求获得临时专利申请u.s.62/154,093的申请日的优先权,该临时申请的标题为“生成分析和设计规范文档的过程”,于2015年4月28日提交,且由本发明的同一发明人提出。上述临时申请作为参考被纳入本文,正如本文档中的公开。
2.技术领域
3.本发明总体上涉及通过类似于人类处理自然语言的抽象思维的形式逻辑进行建模推理的过程。具体地,本发明涉及从基于自然语言的案例规范中推导出过程模型。
3.
背景技术:
4.现有技术公开了自动生成软件设计文档的设备,这些设备来自于用短语表达的需求。这些短语存储在知识库中。在此基础上,这些设备对“类”(在面向对象编程的背景下)进行建模,随后被可视化为uml图。现有技术还公开了将自然语言形式化的系统和方法,从而使产生的语言能够被计算机处理。
5.美国专利申请us 2013/0097583公开了一种系统和方法,提供了一种自动化支持工具,以指导/帮助软件工程师创建软件产品。该系统包括输入/输出、存储、处理和通信设备。该系统通过一个或多个描述需求和所涉及的行为者或实体的短语,帮助软件工程师识别并以图形方式表示从需求、行为者或实体、系统和子系统得出的用例,以及生成领域模型和uml类图以可视化该领域模型。该系统还允许创建扩展用例,创建对象交互模型,创建顺序图,以及创建设计类图。基于设计类图,软件工程师可以制作高质量的计算机程序。该系统可包括或可连接到图生成器,以便自动生成uml(统一建模语言)类图。与本发明不同的是,所述专利的输入是用自然语言编写的软件需求,而本发明由描述业务“案例”的自然语言句子组成。所述专利的输入是本发明可以解决的具体案例之一。解析器(单词识别技术)是传统的并且基于字典。本发明中的解析器是自动的,基于不采用字典的规则。本发明在更短的处理时间内提高了准确性。美国专利申请us 2013/0097583为了实现完整的软件设计,需要软件工程师参与设计和开发代码,并由该专利所产生的图来支持。而在本发明中,所产生的设计是完整和自动的,包括描述性文本中所述的100%的设计。在本发明中,概念领域模型的抽象化是正式的。也就是说,该设计总是对相同的规则作出反应,并因此产生可预测的结果。在美国专利申请us 2013/0097583中,概念模型有20%是人工制作的,并依赖于案例。
6.美国专利申请us 2011/0239183公开了一种方法,其中一个或多个过程模型来自自然语言用例模型。例如,通过使用处理器和访问存储在存储器中的用例模型,可以根据预定的建模符号将存储在存储器中的模型转化为过程模型。该用例模型是从使用具有预先分配的意义的有限的预定义单词列表描述的自然语言文本信息中获得的。在本发明中,设计是在功能架构文档层面进行的,基于无限的自然语言,从中可以得到不同类型的软件设计
图。
7.每个行业都面临着改进其建设过程的挑战。其中,主要的错误因素是请求者的描述(“案例”)和行业产生的产物(解决方案)之间的差异。
8.目前,对于想要描述“案例”的请求者,为了根据所述描述构建解决方案,他/她需要:
9.·
行业分析师来解释和记录。这种记录是由分析师对请求者关于“案例”的评论进行记录。然后,分析师分析文档,并通过应用行业内习知的技术创建一些图表。当文档被充分审查后,它们被提交到“案例”设计阶段。这些图表的内容完全取决于专家的解释和专家将上述图表转化为每个行业特有的图表的能力。
10.·
行业设计师来根据分析和上述关于描述的“案例”的文档,设计所需的解决方案。设计师获得分析图并与分析师会面,从而寻求解释,进而能够最大限度地正确理解这些图表。在此基础上,设计师才可以为“案例”设计一个解决方案。这种设计是通过创建其他图表来进行的,这些图表也取决于行业。这些图表代表了将请求者描述的逻辑转化为建立“案例”解决方案所需的技术语言的新翻译。
11.分析师和设计师都是经过培训的专业人员,他们的目标是理解案例的描述,并将其翻译为技术分析和设计语言,然后由构建解决方案的人进行解释。这就是说,从描述“案例”到开始构建相关的解决方案,需要使用几种语言(见图4:行业设计过程):
12.a.描述“案例”的语言(介入角色:提出需求的请求者):自然语言。
13.b.“案例”的分析语言(介入角色:行业分析师,解析需求并将其转化为分析图):使用标准行业符号的数字,手工制作的草案,用自然语言表达的补充描述,以设计为重点。
14.c.“案例”的设计语言(介入角色:设计师、架构师,解析分析师的工作并将其转化为设计图):使用行业特有的架构数字、计划和图表,代表解决方案的设计。
15.需求设计某种解决方案的人(请求者)通常不是特定行业的专家设计师,因此无法独立构建解决方案。请求者需要行业分析师和行业设计师正确地解释他/她的需求,并在“案例”的解决方案设计中捕获这些需求。这在实践中是不可能的,因为请求者不理解设计语言(建筑师、土木工程师、书籍设计师、软件设计师,以及其他应用的设计语言)。因此,请求者不能控制所产生的设计,进而不能确保所描述的“案例”的解决方案能够被构建。在这里,描述(“案例”)和实际构建(解决方案)之间的偏差占了最大的比重,因为由于语言的变化,通常会出现意义概念的扭曲,如图1所示。其结果是,请求者收到的设计和由此产生的产品(房子、软件、家具、书籍等)并没有完全适应他的需求。
16.行业正在不断努力提高解决方案和请求者对其需求的描述之间的衔接程度。这些努力的重点是通过培训专家或改进他们工作中使用的工具来改进目前的方法,而不取代他们参与解释和构建上述描述的人工制作过程。
17.这种处理技术问题的方法必然产生对需求的多种解释,因为将请求者使用的语言(自然语言)翻译成分析师和设计师使用的语言(技术语言)需要进行转换,这可能会导致知识的损失。遗憾的是,这是任何人都无法精确控制的。
18.在本发明中,为了完整地描述“案例”,只需使用自然语言结构的句子。没有必要通过人工将上述句子翻译成具有技术图形符号的图表,以便能够理解和传递描述中包含的知识。这些图表是由工具从自然语言中自动生成的。
19.现有技术与本发明之间的差异如下表所示(图4:行业设计过程)。
[0020][0021][0022]
在获得希望得到特定行业设计的现实描述后,基于上述描述所代表的内容,系统对自然语言描述进行结构化,从而保证从语义的角度以相互联系和连贯的方式存储“案例”的全部语言成分。该系统还自动构建了在多种行业应用中有用的功能架构文档。
[0023]
本发明展示了使用功能架构文档及其组件来构建软件设计应用。
[0024]
在本发明中,提到“案例”是指一个现实问题,我们要为这个问题建立一个软件应用程序,让计算机处理其逻辑。因此,“案例”的软件行业面临着改进软件建设项目的挑战,其中的主要错误因素是请求者的描述(问题)和“案例”所解决的问题(解决方案)之间的差异。目前,对于想要描述“案例”的请求者,为了根据所述描述构建软件解决方案,他/她需要:
[0025]
·
系统分析师来解释和记录。这种记录是由分析师收集客户对“案例”的意见而产生的。然后,分析师分析文档,并通过应用行业内习知的技术(uml图、流程图、过程图)创建一些图表。当文档被充分审查后,它们被提交到“案例”设计阶段。这些图表的内容完全取决
于分析师的解释和分析师翻译成上述图表的能力。
[0026]
·
软件设计师来设计上述软件。该软件须允许自动捕获整个描述的“案例”中产生的数据。设计师获得分析图,并与分析师会面,从而寻求解释,进而能够最大限度地正确理解这些图表。在此基础上,设计师才可以设计“案例”。这种设计是通过创建其他图表来进行的,如数据库图(用于存储系统数据)、屏幕图(用于数据上传、搜索和处理)、“案例”的功能逻辑图(表示要解决的问题的逻辑)、架构图(定义“案例”的内部组织,以便有效、可靠和持续地运行:客户-服务器、soa(面向服务的架构),等等)。这些图表代表了将请求者描述的逻辑转化为建立“案例”解决方案所需的技术语言的新翻译。
[0027]
分析师和设计师都是经过培训的专业人员,他们的目标是理解案例的描述,并将其翻译为技术分析和设计语言,然后由开发应用程序的人进行解释。图1示出了现有技术和本发明的比较图,关于从开始描述到软件设计的“案例”理解和翻译的每个阶段中所使用的语言。在现有技术中,使用了以下语言:
[0028]
a.描述“案例”的语言(介入角色:提出需求的使用者):自然语言。
[0029]
b.“案例”的分析语言(介入角色:系统分析师,解析用户的需求并将其转化为分析图):数据流图、分析用例,以及用自然语言表达的、以设计为导向的补充描述。
[0030]
c.“案例”的设计语言(介入角色:设计师、架构师,解析分析师的工作并将其转化为设计图):表示应用程序功能设计的图(目前主要是uml);表示存储用户数据的数据库的设计的数据库图;表示将要建立的应用程序的分层架构的架构图。
[0031]
需要设计定制软件的用户通常不是软件设计师,也不是软件开发工程师,因此,他不可能自己构建软件。用户需要分析师和设计师正确地解释他的需求,并将其纳入“案例”的设计中。
[0032]
这在实践中是不可能的,因为请求者不理解设计语言,因此他不能控制所产生的设计,进而不能确保所需求的“案例”能够被构建。这就是需求(问题)和实际构建(解决方案)之间的最大偏差。也就是说,请求者会收到一个设计和一个结果产品(软件),而这个产品通常不能完美地适应他的需求、修改或随后的变化(在某些情况下,这可能需要更多的时间或比最初预期的更复杂、更昂贵)。
[0033]
行业正在作出重要努力,通过case(计算机辅助软件工程)工具来解决这个问题。然而,这些工具并不使用自然语言,因此出现了前面描述的一些限制。
[0034]
这种处理技术问题的方法必然产生对问题的多种解释,因为熟悉该过程的用户或客户使用的语言(自然语言)与分析师和设计师使用的语言(技术语言)之间的翻译需要进行转换,这可能会导致知识的损失。遗憾的是,这是任何人都无法精确控制的。
[0035]
本发明采用自然语言作为软件解决方案的描述、分析和设计的唯一语言,从而将导致结果失真的知识损失降到最低。
[0036]
与现有技术不同,本发明允许使用自然语言的简单句子对“案例”进行完整地描述。与现有技术不同,本发明不需要将所述句子翻译成具有技术图形符号的图表,以便理解和传递该过程的知识。相反,本发明以自然语言为基础,使用一个确定的模型,通过应用实现所述模型功能逻辑的分析规则,自动生成所述图表。
[0037]
根据预先定义的概念层次,用简单的句子构造描述,确保所述描述的完整性,并使高质量的软件设计能够被自动推断出来。
[0038]
为了促进对本发明的理解,并使本发明与现有技术中的内容易于区分,现提出以下对比表:
[0039][0040]
目前的现有技术指出,软件是由人工或部分人工设计的,这在本质上带来了以下问题:解释系统需求的模糊性,修复设计错误的高成本,设计缩放和开发的困难,以及过时的文档,等等。本发明克服了这些困难,它基于一个完全自动化和可工业化的过程,从而实现了概念的精确性,产生了可扩展的不断发展的设计,产生了自动更新的文档,并大大降低了软件设计成本。
[0041]
4.词汇表
[0042]
句子:最小的可能的句法形成,能够传达一个声明或表达一个逻辑命题的内容。
[0043]
简单句:包含一个动词的句子。
[0044]
完整的简单句:从本发明的角度:明确回答所有陈述问题的句子。
[0045]
自然语言:我们所说的人类用于一般交流的口头或书面语言。
[0046]
功能需求:按照需求工程的定义,功能需求决定了系统的行为。全局性的功能需求将与系统本身的行为相关的其他更详细的功能需求分组。
[0047]
类图:显示组成系统的不同类以及彼此之间关系的图表。该图表还显示了类,类的方法和属性,以及它们的相互关系。
[0048]
案例宇宙:围绕“案例”的定义和概念的集合。
[0049]
复合名词:由一个以上的词组成的名词。例如:价格表、文档号。
[0050]
:在本文档中,它的意思是“串联”,加入或添加文本。
[0051]
合格的语言:由于可以用不同的语言来描述“案例”,所以可以用各自的句法和语法结构来说明。
[0052]
串联:给定一个或多个词,串联是指将它们连成一个短语,用空格隔开。例如:“the”和“house”,将这两个词串联起来就得到了“the house”。
[0053]
基础规则:在本发明中,基础规则是一个由问题定义的行为结构,其目的是描述构成所述问题答案的词的形态和句法序列。
[0054]
do:指直接宾语。在本发明中,它指的是出现在“何事”的问题中并跟在及物动词后面的名词。
5.附图说明
[0055]
图1示出了本发明的自然语言转换过程。
[0056]
图2示出了本发明的过程的各个阶段,以获得功能架构文档。
[0057]
图3示出了本发明的系统。
[0058]
图4示出了本发明的过程的各个阶段,以获得软件设计文档。
[0059]
图4a示出了阶段a。
[0060]
图4a1示出了mas元模型。
[0061]
图4a2示出了一个形态句法规则。
[0062]
图4a3示出了mas元模型应用的一个案例。
[0063]
图4b示出了阶段b。
[0064]
图4c.示出了阶段c。
[0065]
图4d示出了阶段d。
[0066]
图4e示出了阶段e。
[0067]
图4e1示出了处理器150的功能逻辑,配置为自动句子分析器151。
[0068]
图4f示出了阶段f。
[0069]
图4f1示出了功能架构图。
[0070]
图4g示出了阶段g。
[0071]
图4g1示出了处理器150的功能逻辑,配置为自动软件设计器152。
[0072]
图4g2示出了阶段4g2
[0073]
图4g2a示出了fx步骤的例子。
[0074]
图4g2b.示出了cc步骤的例子。
[0075]
图4g3示出了4g3阶段。
[0076]
图4g3a示出了qs步骤的例子。
[0077]
图4h示出了阶段h。
[0078]
图4i示出了阶段i。
[0079]
图4i1示出了一个软件设计图。
[0080]
图4i2示出了一个业务文档的结构。
[0081]
图4i3示出了一个分析文档的结构。
[0082]
图5示出了类设计的例子。
[0083]
图6示出了功能架构图中使用的图形符号。
[0084]
图7示出了软件设计文档的图形符号。
[0085]
6.本发明的详细描述
[0086]
本发明提供了一种解决前述问题的方法,该方法由计算机和可视化设备实现,用于从描述案例的自然语言短语中表达的需求中生成软件设计规范文档,这些短语被存储在知识库中。这些短语允许对设计组件进行建模,这些组件随后被转换并可视化为软件设计的类图。该设备可以被调整为与处理器互动。
[0087]
首先,如图4所述,该过程以自然语言对“案例”的描述开始。为了在本发明中进行所述描述,有必要事先确定在描述中使用哪种语言,包括其语法和句法特征,如描述形容词是位于名词之前还是之后的形容词序列,以及构成该语言的冠词列表等等。
[0088]
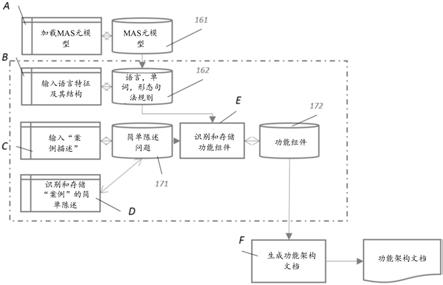
为了用任何拥有确定的句法结构和语法规则的语言来描述“案例”,通过一个输入/输出设备120,使用如图3所述的系统来输入自然语言的“案例”描述。输入的文本被转移到主存储器中,以便以后由处理器150使用。该处理器被配置为自动分析、设计和生成文档。每个处理功能的结果都存储在数据库存储器130中。
[0089]
下面介绍图3中系统100的组件:
[0090]
1.输入/输出设备120:通过该设备采集自然语言文本。它允许处理器采用显示媒体(屏幕、投影仪、电视、打印机、显示器、移动设备等)来显示结构,用户可以在其中输入“案例”描述数据并显示所产生的文档,采用以下配置:
[0091]
a.语言用户界面121:一种视觉结构,允许用户选择语言并上传其语法和句法特征,然后存储在数据库存储器130中。
[0092]
b.案例用户界面122:一种视觉结构,允许用户上传描述“案例”的简单句,然后存储在数据库存储器130中。该结构还允许用户与配置为自动句子分析器151和自动软件设计器152的处理器150的功能进行互动。
[0093]
c.格式、图形符号和std句子用户界面123:在本发明的一个实施例中,用户被呈现为这种视觉结构,它允许用户添加或修改静态数据库存储器160中可用的格式、图形符号和std句子,以准备由配置为自动文档生成器153的处理器150构建的业务、分析和设计文档。
[0094]
d.文档显示用户界面124:一种结构,允许用户访问由配置为自动文档生成器153的处理器150生成的文档。
[0095]
2.cpu 110:系统100的处理装置。该装置被设计用来执行自动设计生成的所有自然语言处理功能,并包含允许在所述功能和系统的其他组件之间交换的主存储器。
[0096]
a.主存储器140:易失性存储设备,用于在输入/输出设备、数据库存储器和处理器之间交换信息。根据其配置,它执行以下功能:
[0097]
i.图表141:主存储器的配置,通过使用存储在静态数据库存储器160中的格式、图形符号和std句子163,使配置为自动文档生成器153的处理器150能够进行文档处理。
[0098]
ii.句子矩阵142:主存储器的配置,通过使用存储在静态数据库存储器160中的mas元模型161、语言、词和形态句法规则162,使配置为自动句子分析器151的处理器150能够处理简单句。
[0099]
iii.fc矩阵143:主存储器的配置,通过使用存储在静态数据库存储器160中的mas元模型161、语言、词和形态句法规则162,使配置为自动句子分析器151的处理器150能够处理功能组件。
[0100]
iv.dc矩阵144:主存储器的配置,通过使用存储在静态数据库存储器160中的mas元模型161、语言、词和形态句法规则162,使配置为自动软件设计器152的处理器150能够处理设计组件。
[0101]
b.处理器150:执行处理和交换任务的设备。根据其配置,它执行以下功能:
[0102]
i.自动句子分析器151:处理器的配置,主要任务是从简单句中自动生成功能组件,并将其发送到动态数据库存储器170中储存。
[0103]
ii.自动软件设计器152:处理器的配置,主要任务是从简单句中自动生成设计组件,并将其发送到动态数据库存储器170中进行存储。
[0104]
iii.文档生成器153:处理器的配置,主要任务是从简单句中自动生成设计组件,并将其发送到动态数据库存储器170中进行存储。
[0105]
3.数据库存储器130:永久存储器,用于存储用户上传的和由处理器150生成的各种配置的数据。该存储器拥有两种存储配置:一种是静态配置,一种是动态配置。静态配置存储必要的固定数据,这些数据是为一次性处理而上传的,并不特定于“案例”。动态配置存储的是针对“案例”的数据,这些数据是为每个案例上传的。
[0106]
a.静态数据库存储器160:
[0107]
i.mas元模型161:数据库存储器130的配置,包含高度抽象的形式逻辑规则,这些规则产生了储存在数据库存储器130的语言、词和形态句法规则结构162中的形态句法规则。
[0108]
ii.语言、词和形态句法规则162:数据库存储器130的配置,包含合格语言的特征、每种合格语言的特殊词和它的形态句法规则。
[0109]
iii.格式、图形符号和std句子163:数据库存储器130的配置,包含适用于文档的格式、适用于图表的图形符号和准备分析文档所需的std句子。
[0110]
b.动态数据库存储器170:
[0111]
i.简单句问题171:数据库存储器130的配置,包含用户上传的简单句以及与每个简单句相对应的何时、何人、何事、如何和何处的问题的答案。
[0112]
ii.功能组件172:数据库存储器130的配置,包含由配置为自动句子分析器151的处理器150自动生成的功能组件。
[0113]
iii.设计组件173:数据库存储器130的配置,包含由配置为自动软件设计器152的处理器150自动生成的设计组件。
[0114]
在使用上述系统时,本发明进行了图4中描述的阶段顺序,同时也进行了以下阶段:
[0115]
阶段a:使用输入/输出设备120将mas元模型161上传至静态数据库存储器160的mas元模型逻辑结构中。
[0116]
阶段b:使用显示设备120的语言用户界面121,输入符合条件的语言、每种符合条件的语言的语法和句法特征,并将这些数据存入静态数据库存储器160的语言、词和形态句法规则162的逻辑结构中。
[0117]
阶段c:使用显示设备120的案例用户界面122,将“案例”的描述作为从阶段b的合格语言列表中选择的一种自然语言的文本输入,识别“案例”的步骤,然后将它们存储在动态数据库存储器170的简单句和问题171的逻辑结构中。
[0118]
阶段d:根据阶段c识别与步骤相对应的“案例”的简单句和数学矩,并使用显示设备120的案例用户界面122将其上传,然后将其存储在动态数据库存储器170的简单句和问题的逻辑结构中。
[0119]
阶段e:根据阶段d自动识别简单句的功能和数学组件(应理解为一个功能组件,对应于由处理器150提取并自动表征的句子的每个单词),处理器150被配置为自动句子分析器151,它根据阶段a上传的mas元模型161中的逻辑结构发挥作用,处理器150继续在主存储
器140的fc矩阵143的逻辑结构中暂时存储所述功能组件。这些组件最终被存储在动态数据库存储器170的功能组件172的逻辑结构中。
[0120]
阶段f:根据来自阶段e的功能和数学组件自动识别“案例”的设计组件。应当理解,设计组件是指与由处理器150自动生成的功能和数学组件相对应的每个软件设计模型。设计组件是使用配置为自动软件设计器152的处理器150创建的,在本发明的一个实施例中,该处理器150根据在阶段a中上传的mas元模型161中的逻辑结构发挥作用,处理器150继续在主存储器140的dc矩阵144的逻辑结构中暂时存储所述设计组件。这些组件最终被存储在动态数据库存储器170的设计组件173的逻辑结构中。
[0121]
阶段g:使用(显示设备120的)格式、图形符号和std句子用户界面,输入业务、分析和设计文档的输出格式、需求的标准句子参数和设计图表的图形符号,并将它们存储在静态数据库存储器160的格式、图形符号和std句子163的逻辑结构中。
[0122]
阶段h:通过配置为文档生成器163的处理器150,使用阶段g中定义的格式、图形符号和std句子,从阶段d的简单句中自动生成业务文档(业务文档可以理解为用自然语言对要解决的问题进行分步描述,基于阶段e的功能和数学组件自动生成分析文档(分析文档可以理解为对要构建的软件的功能要求的描述),以及基于阶段f的设计组件自动生成设计文档(设计文档被理解为包含构建软件的说明的文档)。
[0123]
阶段i:通过配置为文档生成器163的处理器150,使用专门为这种类型的文档定义的图形符号,基于来自阶段e的功能和数学组件,自动生成功能架构文档(功能架构文档被理解为一种图形图表,通过表示意义的基本概念,以摘要形式构造自然语言文本的意义)。
[0124]
该过程的各个阶段将在下文中详细描述:
[0125]
阶段a:上传mas元模型
[0126]
在这个阶段,mas元模型及其公理原则被详细描述。该元模型被用来建立处理器150在配置为自动句子分析器151时的行为。
[0127]
图4a1示出了一个类模型,根据面向对象的范式,该模型表示该元模型定义的规则,以便为解释自然语言的逻辑建模。这些规则被用作处理器150(被配置为自动句子分析器151)用来生成阶段d的功能组件的基础形态句法规则。
[0128]
在这个阶段,mas元模型是由以下子阶段创建的(图4a):
[0129]
子阶段a1:储存mas元模型
[0130]
在这个子阶段中,mas元模型161的逻辑被上传到静态数据库存储器160。
[0131]
这个逻辑确定了自然语言描述中包含的每个词都是一个词161-1。当这个词是一个及物动词时,就会自动定义两个新词:一个执行者词161-2,其名称是及物动词加激动性后缀“er”;一个可执行词161-3,其名称是及物动词加后缀“ble”。该及物动词是一个执行词161-4,它与执行者词161-2之间存在关系161-5,并与可执行词161-3存在另一种关系。
[0132]
词161-1之间的关系是这样的:一个不是及物动词的词可以与执行者词161-2建立继承关系161-9和/或与可执行词161-3建立继承关系161-8。
[0133]
每个词161-1可以与另一个词161-1定义一个继承关系161-0。每个词161-1可以与另一个词161-1定义一个关联关系161-7。
[0134]
mas元模型所提供的选项的使用取决于阶段d中正在处理的句子的形态句法。
[0135]
如此,描述中的所有词,作为一个整体,都可以由这个元模型来表示,它为语言定
义了一个公理规则。鉴于该元模型在所有情况下都得到满足,它代表了对任何语言的任何形态句法规则进行建模的基础。
[0136]
子阶段a2:储存mas的形态句法规则的逻辑
[0137]
在这个子阶段中,mas元模型的逻辑被上传到静态数据库存储器161。上述逻辑定义了一种描述自然语言词汇的方法,以确定它们在不同功能应用背景下的意义。处理自然语言的形式和语法的结构被称为形态句法结构。
[0138]
在本发明中,处理自然语言的准则集合被认为是一种形态句法规则。这样的规则是由处理文本的准则组成的,它定义了:a)问题逻辑:在一个简单的句子中,这个词属于哪个问题(何时,何人,何事,如何,何处);b)步骤类型逻辑:“何事”问题由什么类型的动词组成(fx,cc,qs,l,f);c)单词逻辑:它是什么类型的单词。一个词的类型由其语法特征决定,如动词(verb)、名词(noun)、介词(prep)、冠词(art)、连词(conj)、副词(adv)。
[0139]
每条形态句法规则都有一个标识符。形态句法规则的标识符是由组成该句子的词的类型连接而成的,但执行者(performer)、可执行的(performable)和执行(performance)类型除外。例如,它可以是art-noun-verb-art-prep-noun,表示一个由以下类型的词序列组成的句子:冠词、名词、动词、冠词、介词、名词。这些类型的词可以笼统处理,也可以指代其类型的特定词。例如,规则verb(is)-prep-noun表明该规则适用的句子包含一个动词。具体地,单词verb类型中的“is”,后面是任何介词prep,然后是任何名词noun。这条规则适用于以下句子:是一只猴子(is a monkey),是一个月亮(is a moon)。
[0140]
这就是说,对于每一个简单句,都有一个形态句法规则,它将其结构定义为构成句子的词语类型的函数。
[0141]
给定一个简单句,在组成相应的形态句法规则标识符之前,被配置为自动句子分析器151的处理器150从句子中排除在阶段b2上传的特殊词,即文章连接词和介词。然后,它在静态数据库存储器160中搜索语言、词和形态句法规则162配置中的形态句法规则。一旦找到了具有相应标识符的规则,如果有一个以上具有相同相应标识符的规则,它就在这个集合中搜索在构成该句子的规则标识符时被排除的特定类型的词的匹配。如果有匹配的,就分配给与特定的排除词相匹配的规则。如果没有匹配,就分配一般的规则。
[0142]
mas元模型定义了以下基本规则,不同情况下的具体规则都来自于此。
[0143]
基本规则
[0144]
有两条基本规则,分别与“何事”问题相关联,有各自的专业性。
[0145]
·
verb-noun规则
[0146]
ο一般情况:verb-noun规则161-12:允许对具有动词、名词、名词结构的句子进行建模。
[0147]
ο特定情况:verb(is)-noun规则161-10:允许对具有动词、名词结构的句子进行建模,其中的动词是动词“to be”。从mas元模型应用的角度来看,这个动词是一个特殊的动词。
[0148]
·
verb-noun-prep-noun规则。
[0149]
ο一般情况:verb-noun-prep-noun规则161-11:允许对具有动词、名词、介词、名词结构的句子进行建模。
[0150]
ο具体情况:
[0151]
verb(hold responsible)-noun-prep-noun规则161-13:允许对具有动词、名词结构的句子进行建模,其中的动词是“to hold responsible”。从mas元模型应用的角度来看,这个动词是一个特殊的动词。
[0152]
ο具体情况:verb(link)-noun-prep-noun规则161-14:允许对具有动词、名词结构的句子进行建模,其中的动词是动词“to link”。从mas元模型应用的角度来看,这个动词是一个特殊的动词。
[0153]
同样地,在简单句中也有一个基础规则来模拟“何人”。
[0154]
·
noun规则:它存在于所有的简单句中,并允许对指代主语的主要名词的行为进行建模。
[0155]
对于不需要强制完成的“何时”、“如何”和“何处”问题,答案中出现的词的类型被识别出来,并生成必要的规则标识符。
[0156]
在本发明的一个实施例中,用户可以添加基本规则和形态句法规则,总是依赖于mas元模型的逻辑。
[0157]
给定一个自然语言的简单句,一旦找到形态句法规则,被配置为自动句子分析器151的处理器150通过应用所述规则定义的处理文本的准则来生成功能组件:a)问题逻辑;b)步骤类型逻辑和c)单词逻辑,如图4a2所示。
[0158]
(a)问题逻辑:确定应用该规则的词语的所属问题
[0159]
必须指出,描述是描述一个过程的简单句的集合。这种过程的每一步都与一个简单句相对应,这些句子是由何人、何事、何处、如何、何时这些问题的答案衍生出来的。
[0160]
(b)步骤类型逻辑:确定规则所适用的词语的所属步骤类型
[0161]
每个步骤都可以被归入一个步骤类型。在一条规则中,步骤类型是由“何事”问题中与动词相关的特定词决定的。每一个形态句法规则都是基于mas元模型的,根据与“何事”问题相关的特定动词,它可以被归入以下类型:检查/确认;查询/搜索;计算;关系;功能;通知/警告。
[0162]
cc步骤:(决定检查/确认行动的步骤)
[0163]
这些步骤中,动词定义了检查或确认动作,如:检查、确认、限制等。在这种情况下,动词是及物的,它后面的名词总是和一个表示系统的数学逻辑的句子相联系。
[0164]
这种步骤类型被分配了一个verb-noun形态句法规则标识符,它增加了检查/确认逻辑的数学描述。
[0165]
这种类型的句子的一些例子是:检查物品是否有积极的库存(verb-noun;“have positive inventory”(有积极的库存)是确认的数学逻辑),确认客户有税号(verb-noun;“has a tax id”(有税号)是确认的数学逻辑),限制过期商品的摄入(verb-noun;“expired merchandise”(过期商品)是确认的数学逻辑)。
[0166]
qs步骤:(包括查询/搜索动作的步骤)
[0167]
这些步骤中,动词定义了查询或搜索动作,如:搜索、定位、选择、查询、表示、显示、展示等。在这种情况下,动词是及物的,它后面的名词表示搜索/查询的对象。
[0168]
这种步骤类型被赋予verb-noun形态句法规则标识符,其中名词描述搜索的对象,这意味着动词适用于名词实例的集合。
[0169]
这类句子的一些例子有:查询项目(verb-noun),显示余额(verb-noun),显示数据
(verb-noun),显示结果(verb-noun),搜索项目(verb-noun),定位备件(verb-noun),选择客户(verb-noun)。
[0170]
fx步骤:(包括明确的计算动作的步骤)
[0171]
这些步骤中,动词明确定义了计算动作,例如:计算、分组、平均、添加等。在这种情况下,动词总是与代表系统的数学逻辑的句子相联系。
[0172]
这种步骤类型被分配了一个verb-noun形态句法规则标识符,其中的名词描述了动词所表示的计算的逻辑。
[0173]
这种类型的句子的一些例子是:计算总销售额(verb-noun),按颜色分组(verb-noun),平均上个月的成本(verb-noun)。
[0174]
l步骤:(包含连接动作的步骤)
[0175]
这些步骤中,动词定义了链接动作,如:相关,链接,关联,组合等。在这种情况下,动词后面至少有两个名词。
[0176]
动词可以代表以下任何一种模式:
[0177]
模式1:
[0178]
这种步骤类型被分配了verb(link)-noun-prep-noun形态句法规则标识符,其中具体的动词可以是“link”或任何同义词,介词一般是“with”,但也可能有所不同。
[0179]
这种类型的句子的一些例子是:
[0180]
将物品与价格联系起来(verb(link)-noun-prep-noun),将设备与备件联系起来(verb(link)-noun-prep-noun),将税收与股份联系起来(verb(link)-noun-prep-noun),将产品与投入组成(verb(link)-noun-prep-noun)。
[0181]
模式2:
[0182]
这种步骤类型被分配了verb(hold responsible)-noun-prep-noun形态句法规则标识符,其中具体的动词可以是“hold responsible”或任何同义词,介词一般为“for”,但也可能有所不同。
[0183]
这种类型的句子的一些例子有:让客户对支付负责(verb(hold responsible)-noun-prep-noun),让雇员对库存控制负责(verb(hold responsible)-noun-prep-noun)。
[0184]
模式3:
[0185]
这种步骤类型被分配了verb-noun-prep(a)-noun形态句法规则标识符,其中具体的介词可以是a、an或任何其他介词。
[0186]
这种类型的句子的一些例子是:用测量单位来测量物品(verb-noun-prep(a)-noun),用价格列表来评价物品(verb-noun-prep(a)-noun)。
[0187]
f步骤:(与前面任何类型都不对应的步骤)
[0188]
这些步骤中的动词不符合前面的任何类型,因为它指的是“案例”所特有的动作。
[0189]
动词可以呈现以下任何一种模式:
[0190]
模式1:
[0191]
这种步骤类型被分配了verb-noun形态句法规则标识符,用于所有未被列为cc、qs或fx步骤类型中的特定词的动词,也未被用于这种相同类型的任何模型。
[0192]
及物动词后面有一个或多个名词。例如。购买物品(verb-noun),出售水果(verb-noun),修理工具(verb-noun),解决问题(verb-noun)。
[0193]
模式2:
[0194]
这种步骤类型被分配了verb(is)-noun形态句法规则标识符,其中的具体动词是“to be”。这是一个非常特殊的动词,描述了名词的性质。
[0195]
这种类型的句子的一些例子是:是水果(verb(is)-noun),是一家公司(verb(is)-noun)。
[0196]
(c)词的逻辑:确定所分析的句子和问题的所属词类型结构
[0197]
被配置为自动句子分析器151(图4e1)的处理器150进行以下操作,以便从每个简单句的词语中获得相关的功能组件。
[0198]-对于“案例”的语言,并从静态数据库存储器160的语言、词和形态句法规则162的逻辑结构中,它取动词词尾(ve)和特殊词列表(sw),其中包括分组词列表(grw)和排除词列表(exw)。它还采用了定义了从逻辑结构中应用的准则的形态句法规则。
[0199]-它从动态数据库存储器170的简单句和问题171的逻辑结构中提取“案例”的简单句,并将其结构化为相应的问题。
[0200]-它为“案例”的每个简单句分配一个顺序号。
[0201]-对于“案例”的每个简单句和每个问题,它逐一取词,并根据词的类型对其进行描述,如下:
[0202]
如果问题是“如何”,它将问题中每个词的词尾与动词词尾ve进行比较,以确定动词。一旦确定了动词,它将剩余的词与特殊词列表sw进行比较,以确定介词、冠词、连词和副词。跟在动词后面且不属于sw的词是名词。名词后面的词可以是属于分组词grw列表的sw,在这种情况下,grw加上紧跟在它前面和后面的词构成一个分组名词。其余不属于sw的词是形容词。
[0203]
如果问题是“何事”,第一个词就是动词。一旦确定了动词,它就会将剩余的词与特殊词列表进行比较,以确定介词、冠词、连词和副词。如果动词是及物的,那么紧跟在动词后面的词就不是sw;它是一个表现为直接宾语(do)的名词。名词后面的词可以是属于分组词grw列表的sw,在这种情况下,grw加上紧跟在它前面和后面的词构成了一个分组名词。其余不属于sw的词是形容词。
[0204]
如果问题是“何人”,它将剩余的词与特殊词列表进行比较,以确定介词、冠词和连词。名词后面的词可以是属于分组词grw列表的sw,在这种情况下,grw加上紧跟在它前面和后面的词构成一个分组名词。其余不属于sw的词是形容词。
[0205]
mas元模型和形态句法规则结构在子阶段e4中被应用于识别对创建功能架构文档有用的功能组件,在子阶段g6中生成软件设计组件,在子阶段h4中定义与软件设计mas元模型相关的图形符号。这些子阶段代表了本发明的优选实施例,其中“案例”文本的转折动词按子阶段a1中的定义处理。
[0206]
阶段b:输入语言的特征和结构
[0207]
在这个阶段(图4b),将用于描述自然语言中的“案例”的语言及其形态句法特征是通过以下子阶段来定义的:
[0208]
子阶段b1:定义形容词的顺序
[0209]
形容词的顺序指的是形容词相对于语言中的名词的位置。
[0210]
在配置为语言用户界面121的输入/输出设备120中,从可用的形容词顺序列表中
定义语言的适当形容词顺序。顺序1:名词 形容词;顺序2:形容词 名词;顺序3:修正的形容词 修正的名词,顺序4:形容词 修正的名词,顺序5:修正的形容词 名词。例如,对于英语来说,形容词的适当顺序是形容词 名词。
[0211]
子阶段b2:上传特殊词
[0212]
在配置为语言用户界面121的输入/输出设备120中,上传子阶段b1中定义的语言的特殊词。这些特殊词被配置为自动句子分析器151的处理器150用来确定哪些词将被排除在句子分析之外。在本发明的背景下,冠词(art)、介词(prep)、连词(conj)和副词(adv)被认为是语言的特殊词。在英语中,“a”和“the”是冠词的例子,“for”和“with”是介词的例子,“and”和“or”是连接词的例子,而“how”和“where”是副词的例子。
[0213]
子阶段b3:上传分组词
[0214]
在被配置为语言用户界面121的输入/输出设备120中,上传子阶段b1中定义的语言的分组词。在本发明中,分组词是子阶段b2中定义的特殊的词,它们可以连接两个其他的词来构成一个复合词。例如,“list of prices”(价格列表)这个词,两个名词通过“of”组合在一起。
[0215]
子阶段b4:上传动词词尾
[0216]
在配置为语言用户界面121的输入/输出设备120中,上传来自b1子阶段的语言的适当动词词尾,这些词尾与常规动词词尾的最后音节相对应。动词结尾
“‑
ing”是英语语言的一个例子。
[0217]
阶段c:输入“案例”的描述
[0218]
在这个阶段(图4c),通过以下子阶段用自然语言描述案例:
[0219]
子阶段c1:选择用于描述案例的语言
[0220]
在配置为案例用户界面122的输入/输出设备120中,选择描述“案例”所使用的语言。该语言从阶段b上传的合格语言列表中选择。
[0221]
子阶段c2:识别构建“案例”上下文的组件
[0222]
在本发明的一个实施例中,确定构建“案例”背景的组件。
[0223]
这个阶段涉及“案例”宇宙的静态视野和时间上的动态视野。在静态视野中,“案例”的概念结构是从全局角度观察的,没有考虑到随着时间的流逝会发生什么,将概念划分为维度或构成它的主要方面:层和资源。在动态视野中,它是从随着时间的推移而发生的事件(时间活动)的角度来观察的,并按照它们发生的顺序:过程、时刻和步骤。
[0224]
在本发明的一个实施例中,为了组织对“案例”的描述,确定了层、资源、过程、子过程和时刻。
[0225]
(a)识别“案例”的层
[0226]
层被理解为参加过程的信息的层次,可以独立于其他的信息进行处理,这些信息可以单独运作,有很好的输入和输出区别。例如,这两层被确定为:数据层(一个过程的输入数据被结构化和访问)和计算层(使用所述数据进行计算)。
[0227]
(b)识别“案例”中使用的资源
[0228]
资源是指在整个过程中受到转化的组件,并允许访问其他资源,如转化过程的结果。例如,库存物品是受制于销售过程的资源。
[0229]
(c)识别“案例”中的过程
[0230]
过程是转化资源的行动或行动组。例如,“销售库存物品”的过程。
[0231]
(d)识别“案例”中每个过程的子过程
[0232]
子过程是过程的一部分,可以按片段分析该过程。例如,“提供报价”和“销售”可以是包含在“销售库存物品”过程中的子过程。
[0233]
(e)识别“案例”的时刻
[0234]
在本发明中,时刻是子过程的分区,宣布与该子过程有关的事件的发生。例如,“当客户感兴趣时”是发生在“提供报价”的子过程中的时刻。
[0235]
子阶段c3:确定“案例”的步骤
[0236]
步骤是指在任何特定时刻进行的活动。例如:“当这个人进入测试办公室”时的活动可能是:询问他的身份证明文档,记录上述身份证明文档的数据,对他的家庭群体进行搜索,询问他目前的工作。
[0237]
为了确保对“案例”的描述是完整的,所有的步骤,甚至那些因为看起来很明显而被省略的步骤,都必须包括在内。
[0238]
由于步骤是句子,其动词决定了要执行的行动,因此可以根据动词所表示的行动类型,并通过分析动词后面的名词(不包括子阶段b2中定义的特殊词:冠词、连词、命题和介词)对其进行分类。
[0239]
按步骤类型对句子进行分类的准则被称为步骤类型逻辑,是子阶段a2中定义的形态句法规则的一部分,下面将进行描述。
[0240]
cc步骤:(包含检查/确认动作的步骤)
[0241]
这些步骤中,动词定义了检查或确认动作,如:检查、确认、限制等。在这种情况下,动词总是与代表系统的数学逻辑的句子相联系。这种类型的句子的一些例子是:检查物品是否有正库存,确认客户是否有税号,限制过期商品的摄入。
[0242]
qs步骤:(包括查询/搜索动作的步骤)
[0243]
这些步骤中,动词定义了查询或搜索动作,如:搜索、定位、选择、查询、指示、显示、展示等。在这种情况下,动词后面总是跟着一个名词或一个直接宾语。这种类型的句子的一些例子是:查询项目,显示余额,显示数据,显示结果,搜索项目,找到备件,选择客户。
[0244]
fx步骤:(包括明确的计算动作的步骤)
[0245]
这些步骤中,动词专门定义了计算动作,如:计算,分组,平均,添加等。在这种情况下,动词总是与代表系统的数学逻辑的句子相联系。这种类型的句子的一些例子是:计算总销售额,按颜色对物品进行分组,平均上个月的成本。
[0246]
l步骤:(包括连接动作的步骤)
[0247]
这类步骤中,动词定义了链接动作,如:相关,链接,关联,组合等。在这种情况下,动词后面至少有两个名词。这种类型的句子的一些例子是:将物品与价格联系起来,将设备与备件联系起来,将税收与股份联系起来,将产品与投入组合起来。
[0248]
f步骤:(与前面任何类型都不对应的步骤)
[0249]
这些步骤中的动词不对应于前面的任何类型,因为它指的是“案例”所特有的动作。动词可以代表以下任何一种模式。模式1:动词后面跟着一个或多个名词。例如:购买物品,出售水果,修理工具,解决问题。模式2:动词后面不跟名词。例如:进入,退出。
[0250]
这些步骤一般按以下顺序描述:1)f步骤,2)cc步骤,3)qs步骤,4)fx步骤,5)l步
骤。
[0251]
阶段d:识别和存储“案例”的简单句和数学矩
[0252]
在这个阶段,“案例”的简单句被列出,取“案例”描述的每一段,提取只有一个动词的句子,以便上传到输入/输出设备120的案例用户界面122。例如,如果描述的段落是:“该物品是一个库存物品。该人用一个计量单位测量该物品并下订单,他对该订单负责,并将其链接到一个订单类型”,相应的简单句子是:“这个人用一个计量单位测量物品”,“这个人下了订单”,“组织让这个人对订单负责”,“这个物品是一个库存物品”,“这个人把订单与一个订单类型联系起来”。
[0253]
在自由写作的文本中,同一段中有的句子有隐含的主语,一般由连词分开。在这种情况下,为了形成一个完整的句子,主语就会暴露出来,目的是将有隐含主语的句子转换成有显性主语的简单句子。例如,在下面这个由连词“和”分隔的句子中,有一个隐含的主语:“这个人用一个计量单位测量物品,并把订单放好”。可以将其变成两个简单的句子:“这个人用一个测量单位测量了物品”,“这个人下了订单”。
[0254]
在这个步骤中,必须注意到,描述是描述“案例”的简单句的集合。一个由“何人”、“何事”、“何处”、“如何”和“何时”等问题的答案衍生出来的简单句,对应于该过程的每一步。
[0255]
关于数学组件,本发明能够识别所输入文本的数学功能,本方法为所需功能的每个组件识别句子。也就是说,每个数学功能被分解成几个简单句。如图4g2所示,用五个简单的问题句子来识别一个数学功能的简单句。例如:允许在支付中计算预扣税款的数学功能,由5个简单句组成。
[0256]
一旦简单句被识别出来,那些有隐含主题的句子被完成,它们就被上传到输入/输出设备120的案例用户界面122。
[0257]
在这个阶段(图4d),“案例”的简单句由以下子阶段确定:
[0258]
子阶段d1:回答l和f类步骤的“案例”的每个步骤的问题
[0259]
在这个阶段,“案例”的每一个简单句都被用来回答问题:何时、何处、何事、如何和何时。
[0260]
对于存储在简单句和问题动态数据库存储器171中的每个简单句,处理器150在输入/输出设备120的案例用户界面122中显示每个句子,询问何人、何事、何处、如何和何时等问题。对于显示的每个句子,用户输入答案,同时确保每个答案是句子含义的构成部分。在某些情况下,可能无法回答其中一个或几个问题。
[0261]
上述问题的答案明确了简单句子的每一部分,在本发明的一个优选实施例中,必须用现在时态来写。
[0262]
按问题类型对句子进行分类的准则被称为问题逻辑,是子阶段a2中定义的形态句法规则的一部分。
[0263]
子阶段d2:将每一l和f类的步骤的答案串联起来
[0264]
一旦问题的答案被上传,每个答案都会按以下顺序串联起来。何时,何人,何事,如何,哪何处。通过这种方式,答案的文本被连接成简单句,并存储在动态数据库存储器170的简单句和问题171的逻辑结构中。
[0265]
上述问题的答案明确了简单句的每一部分,必须用现在时态来写。
[0266]
例如,对于不完整的句子:“询问他的身份证件”,如果采用前面描述的方法,结果就是一个简单句。当该人进入时,系统操作员会记录身份证件的号码。
[0267]
子阶段d3:识别案例的数学矩
[0268]
为了构建案例描述的概念性数学逻辑,这一阶段要确定案例中所用短语的数学组件。例如:
[0269]
时刻:计算预扣税款。
[0270]
第一步:检查支付(类型qa)
[0271]
第2步:添加已付金额(类型fx)
[0272]
第3步:查阅费率(类型qs)
[0273]
第4步:计算税款(类型fx)
[0274]
第5步:验证结果(类型cc)
[0275]
图4g2和图4g3示出了每个步骤的结构,以及案例用户界面122是如何为每种类型的步骤呈现的。
[0276]
子阶段d4:为qs、fx和cc类型的步骤回答“案例”的每个步骤的问题
[0277]
在这个阶段,本发明的方法将每个简单句对应于“案例”的一个数学矩,对于提到这些类型的步骤的案例,应该回答何时、何人、何事、如何和何处的问题。
[0278]
对于存储在简单句和问题动态数据库存储器171中的每个简单句。处理器150在输入/输出设备120的案例用户界面122中显示每个句子,询问何人、何事、何处、如何和何时的问题。对于显示的每个句子,用户输入答案,同时根据步骤的数学内容,确保每个答案是句子意义的构成部分。在某些情况下,有可能有一个或多个问题不能被回答。
[0279]
当上述问题得到回答时,简单句的所有部分都被明确,在本发明的一个优选实施例中,必须用现在时态来写。除了对每个问题的回答外,对于数学案例,每个问题中所要求的规范必须针对每一种类型的步骤完成。该规范将每个问题的答案的含义与从以前的步骤中创建的功能组件联系起来,因此,当子阶段g2和g3被执行时,与数学步骤相关的功能模型具有自动创建类formulafx和dominiodx的所有必要元素。
[0280]
在案例用户界面122-1中,为fx步骤类型输入简单句。
[0281]
在案例用户界面122-2中,为cc步骤类型输入简单句。
[0282]
在案例用户界面122-3中,为qs步骤类型输入简单句。
[0283]
作为qs、fx和cc各步骤类型的一个例子,下面描述了以下情况:
[0284]
qs步骤类型的例子:
[0285]
在这个例子中,对于步骤qs的类型,根据图4g3的表示和图4g3a的细节,描述案例用户界面122中的每一句话。
[0286]
[0287]
[0288][0289]
fx步骤类型的例子:
[0290]
在这个例子中,对于步骤fx的类型,根据图4g2的表示,描述案例用户界面122中的每一句话。
[0291]
[0292][0293]
cc步骤类型的例子:
[0294]
在这个例子中,对于步骤cc的类型,根据图4g2的表示,描述案例用户界面122中的每一句话。
[0295]
[0296][0297]
按问题对句子进行分类的准则,被称为“问题逻辑”,是子阶段a2中定义的形态句法规则的一部分。
[0298]
子阶段d5:将qs、fx和cc类型的每个步骤的答案串联起来
[0299]
一旦问题的答案被加载,每个答案将按以下顺序串联起来:何时、何人、何事、如何、何处。通过这种方式,答案的文本被串联成简单句,并存储在动态数据库存储器170的简单句和问题171逻辑结构中。
[0300]
通过对上述问题的回答,简单句的所有部分都明确地暴露出来,必须用现在时态来写。
[0301]
在qs、fx和cc类型的步骤中,每个简单句在串联中增加了一系列额外的词,以便为每个句子提供意义。这种串联的一个例子用粗体字说明如下:
[0302]
步骤qs类型案例的简单句的构造是:
[0303]
系统检查支付(日期,概念,金额),条件是有效的和非豁免的,并将它们存储在适用的支付中(日期,概念,金额)。
[0304]
步骤fx类型案例的简单句的构造是:
[0305]
系统计算税款,加上适用的金额,并将结果存储在发票中(税额)。
[0306]
步骤cc类型案例的简单句的构造是:
[0307]
系统验证结果,比较发票和支付总额,并将结果存储在属性rdovalido中(checkvalid)。
[0308]
阶段e:识别和存储功能和数学组件
[0309]
在本发明的背景下,必须理解的是:根据功能组件表达的语言的语法和句法结构,该功能组件对应于由处理器150自动提取和分类的句子中的每个词。
[0310]
在这个阶段(图4e),描述了识别句子的功能组件的子阶段。
[0311]
子阶段e1:将简单句解构为单词并识别这些单词
[0312]
由处理器150生成的功能组件分为以下类型:
[0313]
·
名词功能组件
[0314]
ο在“何事”中识别-》名词-直接宾语(do)
[0315]
ο在“何人”中识别-》名词-人(per)
[0316]
ο在“何时”中识别-》名词(noun)
[0317]
ο在“如何”中识别-》名词(noun)
[0318]
·
形容词的功能组件
[0319]
ο在任何问题中识别-》形容词(adj)
[0320]
·
动词的功能组件
[0321]
ο在“何事”中识别-》动词(verb)
[0322]
ο在“如何”中识别-》动词(verb)
[0323]
·
副词的功能组件
[0324]
ο在“如何”中识别-》副词(adv)
[0325]
结构化词语的准则被称为词语逻辑,是子阶段a2定义的形态句法规则的一部分。
[0326]
在这个子阶段,被配置为自动句子分析器151的处理器150对“案例”的每个简单句进行以下操作:
[0327]
(a)列出单词
[0328]
对于每一个句子,列出其每个单词。
[0329]
(b)识别要排除的词
[0330]
从功能组件选择中排除那些在子阶段b2中定义的要排除的词;除非这些词是分组名词的一部分,如:价格列表、饼干盒。
[0331]
(c)识别动词
[0332]
通过比较每个词的词尾与子阶段b4定义的动词词尾列表或作为简单句中“何事”问题的答案的第一个词来识别动词。
[0333]
(d)识别名词
[0334]
将不属于动词且未被排除的词识别为名词。
[0335]
(e)将名词标记为&attribute
[0336]
有些名词的行为像&attribute(&属性)。&attribute被理解为另一个名词的特征名称,它不是一个形容词。关于已识别的名词列表,在本发明的一个实施例中,&attributes是手动选择的。在另一个实施例中,当名词被列在文本的括号内时,处理器会自动识别它
们。例如:在“上传客户的文档号”这句话中,
‘
文档号’是
‘
客户’的&attribute。
[0337]
(f)识别分组名词
[0338]
当有两个连续的名词,中间有一个特殊的词作为链接时,将分组名词识别为名词。
[0339]
(g)根据单词识别功能组件
[0340]
从分类词的列表中,将名词和动词确定为功能组件,并相应地分类为verb、do、noun、person。
[0341]
(h)逐一检查每个功能组件以前是否存在
[0342]
当一个新的任何类型的功能组件被识别时,检查它以前是否存在。如果不存在,就创建它。如果存在,则继续。
[0343]
(i)将功能组件与它们所回答的问题联系起来
[0344]
根据该词所属的问题,按类型对功能组件进行分类:
[0345]
i.如果属于“何时”:与动词组合的词是副词(adv)类型的功能组件。
[0346]
ii.如果属于“何事”:跟在动词后面的名词是直接宾语(do)类型的功能组件。
[0347]
iii.如果属于“何人”:第一个名词是人(pers)类型的功能组件。
[0348]
被配置为自动句子分析器151的处理器150执行以下动作,如图4e1所示,以便从每个简单句的词语中获得相关的功能组件:
[0349]
·
对于“案例”的语言,从静态数据库存储器160的语言、词和形态句法规则162的逻辑结构中获取动词词尾(ve)、特殊词列表(sw),其中包括分组词列表(grw)、排除词列表(exw)。
[0350]
·
从动态数据库存储器170的简单句和问题171的逻辑结构中提取“案例”的简单句,并将其结构化为相应的问题。
[0351]
·
为“案例”的每个简单句分配顺序号。
[0352]
·
对于“案例”的每个简单句,对于每个问题:逐一取词,并根据词的类型进行定性:
[0353]
如果问题是“如何”,将问题中每个词的词尾与动词词尾ve进行比较,以确定动词。一旦确定了动词,将剩余的词与特殊词列表sw进行比较,以确定介词、冠词、连词和副词。跟在动词后面且不属于sw的词是名词。名词后面的词可以是属于分组词grw列表的sw,在这种情况下,grw加上紧跟在它前面和后面的词构成一个分组名词。其余不属于sw的词是形容词。
[0354]
如果问题是“何事”,第一个词就是动词。一旦确定了动词,将剩余的词与特殊词列表进行比较,以确定介词、冠词、连词和副词。如果动词是及物的,那么紧跟在动词后面的词就不是sw;它是一个表现为直接宾语(do)的名词。名词后面的词可以是属于分组词grw列表的sw,在这种情况下,grw加上紧跟在它前面和后面的词构成了一个分组名词。其余不属于sw的词是形容词。
[0355]
如果问题是“何人”,将剩余的词与特殊词列表进行比较,以确定介词、冠词和连词。名词后面的词可以是属于分组词grw列表的sw,在这种情况下,grw加上紧跟在它前面和后面的词构成一个分组名词。其余不属于sw的词是形容词。
[0356]
子阶段e2:添加未包括在描述中的功能组件
[0357]
在本发明的一个实施例中,用户添加未出现在自动识别的功能组件列表中的功能
组件。以同样的例子继续进行:
[0358]
·
识别文档的号码是一个从句子中自动检测到的&attribute。
[0359]
·
这个人的年龄是由用户添加的&attribute。
[0360]
在本发明的一个实施例中,相应的步骤和简单句是为每个被添加的功能组件自动创建的。
[0361]
子阶段e3:识别与步骤fx、cc和qs的类型相关的功能组件
[0362]
从在子阶段d3、d4和d5中表示的数学矩和步骤中,被配置为自动句子分析器151的处理器150确定与步骤fx、cc和qs的类型相对应的补充功能组件,如下所示:
[0363]
子阶段e3.a——对应于fx步骤类型的句子的数学组件
[0364]
a.将文字逻辑应用于界面组件122-12中输入的文本,以确定noun(发票)和括号中的属性(taxedamount)。这些属性构成{enumeration of attributes&}({属性的枚举&})。
[0365]
b.定义122-13的内容是一个功能组件{fx expression}({fx表达式}),与子阶段e3.a的a项中确定的noun(发票)、属性(taxedamount)相链接。
[0366]
子阶段e3.b——对应于cc步骤类型的句子的数学组件
[0367]
a.将文字逻辑应用于界面组件122-22中输入的文本,以确定noun(结果)和括号中的属性(validcheck)。这些属性构成{enumeration of attributes&}({属性的枚举&})。
[0368]
b.定义122-23的内容是一个功能组件{fx expression}({fx表达式}),与子阶段e3.b的a项中确定的noun(结果)、属性(validcheck)相链接。
[0369]
子阶段e3.c——对应于qs步骤类型的句子的数学组件
[0370]
a.将文字逻辑应用于界面组件122-31中输入的文本,以确定noun(支付)和括号中的属性(日期、概念、金额)。这些属性构成{enumeration of attributes&}({属性的枚举&})。
[0371]
b.定义122-32的内容是一个功能组件{fx expression}({fx表达式}),与子阶段e3.b,c项中确定的noun(适用的支付)、属性(日期、概念、金额)相链接。
[0372]
c.对界面组件122-33中输入的文本应用文字逻辑,以确定noun(适用的支付)和括号中的属性(日期、概念、金额)。这些属性构成了{enumeration of attributes&}({属性的枚举&})。
[0373]
子阶段e4:对功能组件应用形态句法规则
[0374]
在本发明的一个实施例中,用户可以启用形态句法规则,从而使处理器150符合子阶段a2中定义的逻辑。
[0375]
在这个实施例中,根据图4a1中的mas元模型,简单句的每个词都被分类为词161-1,并被分配为以下词的类型之一:verb(动词)、noun(名词)、art(冠词)、conj(连词)、adv(副词)。执行者词161-2和可执行词161-3也被创建,将执行词161-4类分配给及物动词。所有按类型分类的词161-1都是功能组件。如图4d所示,一旦每个功能组件被创建,它就被链接到它所产生的句子、它所属的问题、相应的词类、以及代表构成问题的词类序列的形态句法规则标识符,如子阶段a2所示。
[0376]
在功能组件选择过程中,子阶段b2定义特殊词,除非相应的形态句法规则将其标记为特殊词。
[0377]
在本实施例中,处理器150为每个及物动词创建两个新的功能组件。一个被命名为
动词加激动性后缀“er”的功能组件(执行者161-2)和一个被命名为动词加后缀“ble”的功能组件(可执行161-3)。及物动词是执行161-4词。对于执行及物动词的名词,处理器150创建动词“is”(是),与动词的er相关联。对于目标名词(句子的直接宾语),处理器创建动词“is”,它与动词的ble相关联。
[0378]
阶段f:生成功能架构文档
[0379]
在这个阶段(图4f),被配置为文档生成器153的处理器150,使用存储在静态数据库存储器160的格式、图形符号和std句子163的逻辑结构中的格式和符号,生成功能架构文档,并在输入/输出设备120的文档显示用户界面124中显示它们。
[0380]
在这个阶段(图4f),功能架构文档是由以下子阶段生成的:
[0381]
子阶段f1:建立功能架构的形态句法规则
[0382]
正如在阶段a中所建立的,对于每个由介词“to”或“to the”跟随的及物动词,处理器为执行动词的名词创建以下内容:句法组件,其名称为动词加激动性后缀“er”(以下称为动词的er);并为接受动词动作的名词创建以下内容:句法组件,其名称为动词加后缀“ble”(以下称为动词的ble)。处理器在源名词和动词的er之间创建一个新的名词,称为“动词的执行”。对于源名词,处理器创建一个动词“is”,与动词的ble相关联。对于目标名词,处理器创建一个动词“is”,与该动词的er相关联。
[0383]
子阶段f2:定义功能架构文档中使用的图形符号
[0384]
在这个阶段,使用输入/输出设备120的格式、图形符号和std句子用户界面123,定义将在功能架构图中使用的图形符号,根据相应的单词类型,指出每个功能和数学组件在图表中使用的图形组件。将定义的图形符号存储在数据库存储器130中。这样,用户在视觉网格中输入图形符号,该网格由格式、图形符号和std句子用户界面123显示,如图6所示。
[0385]
子阶段f3:生成功能架构文档
[0386]
被配置为文档生成器153的处理器150,将存储在动态数据库存储器170的功能组件逻辑配置172中的功能和数学组件,应用静态数据库存储器160的mas元模型161逻辑结构中的mas元模型,使用子阶段f2中定义的符号,构建功能架构文档。为了生成功能架构图,处理器扫描功能组件的列表,并应用以下规则,直到产生如图4f1所示的图表:
[0387]
规则1:对于每个noun类型的功能组件,绘制fnoun图形元素,在其内部有fc标签。
[0388]
规则2:对于每个verb型功能组件,在verb前面的noun和后面的noun之间绘制线,要考虑到:i)如果verb是“to be或其任何变体”,从verb之前的noun到紧跟verb的noun绘制ftobe图形元素;ii)如果verb是任何其他及物动词,从verb之前的noun到紧跟verb的noun绘制ferble图形元素;iii)如果verb不是及物的,从verb之前的noun到同一noun绘制fverb图形元素。
[0389]
规则3:对于每个prep类型的功能组件,但仅对于介词“of”和“of the”,在介词之前的noun和介词之后的noun之间绘制fprep图形元素。
[0390]
规则4:对于每个及物动词,绘制与根据子阶段a1定义的mas元模型创建的词相对应的图形组件:ferble图形元素用于执行者词,ferble用于可执行词,以及fperf用于执行词。
[0391]
处理器150在输入/输出设备120上显示功能架构文档。
[0392]
阶段g:识别和储存设计组件
[0393]
在本发明中,“案例”的设计文档由以下图表组成:概念设计图、用例图、类图、实体关系图、屏幕设计图和报告设计图。
[0394]
每个“案例”的设计文档都显示图形。具体来说,类图在本发明中被使用。根据面向对象(oo)范式,作为类图一部分的每个图形元素将被称为设计组件(dc)。例如:类关系、属性、方法。
[0395]
为了本发明的目的,应该理解类、属性、关系和方法是面向对象(oo)范式中定义的设计组件。
[0396]
在这个阶段(图4g),配置为自动软件设计器152的处理器150,通过以下子阶段自动设计软件:
[0397]
子阶段g1:将功能和数学组件分组,创建它们的类和继承关系
[0398]
在这个子阶段中,被配置为自动软件设计器152的处理器150,根据其属性的相似性创建类和继承关系,执行以下动作:
[0399]
(a)选择功能组件
[0400]
采取在阶段e创建的功能和数学组件的列表,这些组件存储在动态数据库存储器170的功能组件172的逻辑结构中,除了标记为“is attribute”(是属性)的功能组件和verb字型的功能组件。
[0401]
删除那些名字非常相似的功能组件和数学组件(例如,使用列文斯坦距离算法,相似度为90%),如“person”和“persons”这两个词就是如此,其中“person”被认为是一个单一的功能组件。
[0402]
(b)将相似的功能组件分组
[0403]
使用{list of&attributes}({属性列表})对上一步中包含的功能组件进行分组,将具有相同{list of&attributes}的功能组件放在同一组中。为那些有多个功能组件的组分别赋予名称,例如,word01、word02。
[0404]
(c)按组创建类
[0405]
为每个有一个以上功能组件的组创建一个类,将{list of&attributes}中的每个元素表示为一个属性,并为该类指定与该组相对应的词的名称。
[0406]
(d)为组创建继承关系
[0407]
对于那些属于有一个以上元素的组的功能组件,根据其所属的{list of&attributes}组,在该功能组件所属的每个类和其各自的组类之间创建继承关系。也就是说,继承关系存在于具有相同{list of&attributes}的类之间,这些类被概括在上一步的同一个组类中。
[0408]
子阶段g2:创建基于fx和cc类型步骤的公式类
[0409]
在这个子阶段,被配置为自动软件设计器152的处理器150对“案例”的简单句按问题类型划分,执行以下操作:
[0410]
(a)列出属于fx和cc步骤的verb和do功能组件
[0411]
列出所有verb型和do型的功能组件,并识别相应的步骤类型,如在子阶段c3中所定义的那样。
[0412]
(b)为fx和cc步骤创建类
[0413]
基于属于fx和cc类型步骤的功能和数学组件,创建具有verb定义的行为的类。对
于每个verb,创建类并添加方法,称为公式,负责计算由{fx expression}({fx表达式})表示的表达式,在子阶段e3.a和子阶段e3.b中确定。
[0414]
对于在上一步中创建的每个类,执行以下操作:
[0415]
a.如果do“is attribute”(是属性),就在该类中创建一个名为do的属性。
[0416]
b.如果do“is attribute”,就在上一步的类和包含do作为其属性的类(称为targetclass)之间建立关系。将这种关系命名为targetclass_movement。
[0417]
子阶段g3:基于qs类型步骤创建域类
[0418]
在这个子阶段,被配置为自动软件设计器152的处理器150执行以下操作:
[0419]
(a)列出属于qs步骤的verb和do功能组件
[0420]
列出所有verb和do类型的功能组件,并确定其相应的步骤类型,如在子阶段c3中定义的那样。
[0421]
(b)为qs步骤创建类
[0422]
基于属于qs类型步骤的功能组件,创建了具有verb所定义的行为的类。对于每个verb,创建名为verb do的类,并添加一个名为fxdomain的方法,该方法负责搜索由{fx expression}定义的数据,在子阶段e3.c中确定。如果属性列表与之前创建的一个类的属性相匹配,就在它们之间建立一个相应方向的继承关系。
[0423]
fxdomain方法调用“domain” verb do。
[0424]
g4子阶段:基于l类型步骤创建域类
[0425]
在这个子阶段中,被配置为自动软件设计器152的处理器150进行以下操作:
[0426]
(a)列出属于l步骤的verb和do功能组件
[0427]
列出所有verb型和do型的功能组件,并确定其相应的步骤类型,如在子阶段c3中定义的那样。
[0428]
(b)为l步骤创建类
[0429]
基于l类型功能组件,在do和noun之间创建了一种关系,称为do “for” noun。
[0430]
子阶段g5:基于f类型步骤创建操作类
[0431]
在这个子阶段中,被配置为自动软件设计器152的处理器150进行以下操作:
[0432]
(a)列出属于f步骤的verb和do功能组件
[0433]
列出所有verb型和do型的功能组件,并确定其相应的步骤类型,如在子阶段c3中定义的那样。
[0434]
(b)为f步骤创建类
[0435]
基于f型功能组件,根据do是否“is attribute”,创建以下类:
[0436]
a.如果do“is attribute”:不创建类。
[0437]
b.如果do“is attribute”:
[0438]
i.创建类,称为:verb do,这将被称为class_cab
[0439]
ii.来自f类型步骤的do类将被称为class_rec
[0440]
iii.在class_cab和class_rec之间建立了一个1比n的关系。
[0441]
将这种关系命名为“movement” do。
[0442]
子阶段g6:将形态句法规则应用于设计组件
[0443]
在本发明的一个实施例中,用户可以启用形态句法规则的使用,以便处理器150符
合子阶段a2中定义的逻辑。
[0444]
根据在子阶段a2定义的并存储在静态数据库存储器160的语言、词和形态句法规则162的逻辑结构中的形态句法规则,处理器150确定哪些软件设计组件(dc)是由存储在动态数据库存储器172的功能组件逻辑结构172中的每个功能组件(fc)衍生出来的。
[0445]
它列出问题,并根据构成答案的单词类型为每个问题创建规则标识符。然后,它在静态数据库存储器160的语言、词和形态句法规则162的逻辑结构中搜索所述规则标识符,并通过匹配标识符找到基础规则。可能有一个以上的具有相同基本规则标识符的形态句法规则,在这种情况下,选择与问题、f类型步骤以及在文本中发现的并在形态句法规则中指明的特定词相匹配的规则。在标识符不匹配任何基本规则的情况下,处理器150会忽略该问题。
[0446]
在本实施例中,对于在前面的子阶段中确定的和在子阶段a1中定义的每个及物verb,处理器150创建与该动词相关的词161-4和执行者161-2和可执行者161-3词。
[0447]
对于l类型步骤的情况,用户可以创建一个依赖于基本规则verb-noun-prep-noun的形态句法规则,其中动词“to link”(链接)可以被当作一个特定的词处理。在这种情况下,步骤类型将是l,处理器150将在do和noun之间建立一种叫做do “for” noun的关系。
[0448]
对于fx类型步骤的情况,处理器150为在子阶段e3.a中确定的每个数学组件创建一个formulafx类型的词,并在界面122-13中输入{fx expression},与子阶段e3.a中确定的属性(taxedamount)相链接。
[0449]
对于cc类型步骤的情况,处理器150为子阶段e3.b中确定的每个数学组件创建一个formulafx类型的字,其{fx expression}在界面122-23中输入,与子阶段e3.b中确定的属性(validcheck)链接。
[0450]
对于qs类型步骤的情况,处理器150为子阶段e3.c中确定的每个数学组件创建一个类型为fxdomain的字,其{fx expression}在界面122-32中输入,还创建一个类型为fxformula的字,与前一个fxdomain链接。这个公式fx与{enumeration of attributes&}(日期、概念、金额)相链接,其在子阶段e3.b,c项中确定。
[0451]
图4a3显示了一个具有应用实例的软件设计类模型,该模型描述了基于mas元模型161的软件设计的形态句法规则。这些形态句法规则产生了“案例”的句子的建模。为了从自然语言中设计软件,为每一个描述简单句的问题(何时,何人,何事,如何,何处)定义了软件设计的形态句法规则。这些存储在词语、规则和形态句法规则静态数据库存储器162中的规则与为每个简单句计算的规则标识符进行比较,如子阶段2a所示。并根据匹配情况,定义被配置为自动软件设计器152的处理器150的逻辑,以生成软件设计组件。
[0452]
阶段h:定义格式、图形符号和std句子
[0453]
在这个阶段(图4h),业务、分析和设计文档的格式,以及生成这些文档所需的参数,通过以下步骤来定义:
[0454]
子阶段h1:定义文档的输出格式
[0455]
在这个子阶段,使用输入/输出设备120的格式、图形符号和std句子用户界面123,定义业务文档、分析文档和设计文档的显示或打印格式。
[0456]
这些定义包括定义页边距、字体和每个文档的内容将被显示的顺序排序。
[0457]
对于业务文档,定义了层、资源、过程、子过程、时刻和步骤的展示顺序和次序。
[0458]
对于分析文档,定义了全局和细节要求的显示顺序和次序。
[0459]
在本发明的一个实施例中,用户可以使用输入/输出设备120的格式、图形符号和std句子用户界面123来修改在子阶段f1、f2、f3和f4上传的格式、图形符号和标准句子。
[0460]
h2子阶段:定义需求的标准句子
[0461]
在这个子阶段,使用输入/输出设备120的格式、图形符号和std句子用户界面123,输入描述需求的标准句子,用将被用来生成需求的一种或几种语言来写。这些标准句子被存储在输入/输出设备160的语言、词和形态句法规则162的逻辑结构中。生成需求所需的标准句子描述如下:这些句子必须被翻译并存储在需要生成文档需求的每种语言中。
[0462]
(a)全局需求的标准句子:
[0463]
为了生成全局需求,定义了以下标准句子,适用于英语:
[0464]
oracionstd_abm_sust:“create,read,update and delete”(创建、读取、更新和删除)
[0465]
oracionstd_abm_pers:“create,read,update and delete entities with role”(创建、读取、更新和删除有角色的实体)
[0466]
oracionstd_verbo_f:“create transaction record”(创建交易记录)
[0467]
oracionstd_verbo_r:“create rule that”(创建规则)
[0468]
oracionstd_verbo_conector_r:“with”(与)
[0469]
oracionstd_verbo:“create rule that”(创建规则)
[0470]
(b)noun和do组件的详细需求的标准句子
[0471]
为了生成noun和do功能组件的详细需求,定义了以下标准句子,适用于英语:
[0472]
oracionstd_crear:“create a new element”(创建新元素)
[0473]
oracionstd_agregar_atributos:oracionstd_agregar_atributos
[0474]
oracionstd_agregar_controles:“perform the following control swhen an element is created”(当一个元素被创建时,执行以下控制)
[0475]
oracionstd_baja:“exclude a”(排除)
[0476]
oracionstd_edicion:“update a”(更新)
[0477]
oracionstd_consulta:“search the transaction records of”(搜索
…
的交易记录)
[0478]
oracionstd_complemento_control:“performing the following controls”(执行以下控制)
[0479]
oracionstd_complemento_b
ú
squeda:“performing the following searches”(执行下列搜索)
[0480]
oracionstd_crear_atributo:“create the attribute”(创建属性)
[0481]
oracionstd_validacion_atributo:“perform the following controls when the datum is completed”(在基准面完成后执行以下控制)
[0482]
(c)person组件的详细需求的标准句子
[0483]
为了生成person功能组件的详细需求,定义了以下标准句子,适用于英语:
[0484]
oracionstd_permitirque:“allow”(允许)
[0485]
oracionstd_acciones_persona:“to perform the following actions”(执行以
下行动)
[0486]
oracionstd_afectacion_persona:“to be subject to the following actions”(受到以下行动的影响)
[0487]
oracionstd_responsabilidad_persona:“to be performed under the responsibility of”(由
…
负责执行)
[0488]
(d)verb组件的详细需求的标准句子
[0489]
为了生成与cc类型步骤或fx类型步骤相关的verb功能组件的详细需求,定义了以下标准句子,适用于英语:
[0490]
oracionstd_crear_fx:“create a formula for”(创建公式,用于)
[0491]
oracionstd_argumentos:“using the following data as arguments”(使用以下数据作为参数)
[0492]
oracionstd_expresion:“in the following expression”(在下面的表达式中)
[0493]
oracionstd_msj_error_fx:“if the formula returns an error,display the following message”(如果公式返回一个错误,显示以下消息)
[0494]
oracionstd_msj_ok_fx:“if the formula returns a valid result,display the following message”(如果公式返回一个有效的结果,显示以下消息)
[0495]
oracionstd_msj_advertencia_fx:“"if the formula returns a warning,display the following message”(如果该公式返回一个警告,显示以下消息)
[0496]
为了生成与qs类型步骤相关的verb功能组件的详细需求,定义了以下标准句子,适用于英语:
[0497]
oracionstd_crear_busqueda:“create a rule for”(创建规则,用于)
[0498]
oracionstd_exponer_atributos:“displaying the following data”(显示以下数据)
[0499]
oracionstd_definir_b
ú
squeda:“allow searching for the data of”(允许搜索
…
的数据)
[0500]
oracionstd_conector_orden:“by”(通过)
[0501]
oracionstd_definir_filtro:“allow filtering the data of”(允许过滤
…
的数据)
[0502]
oracionstd_definir_orden:“allow sorting the data of”(允许对
…
的数据进行排序)
[0503]
oracionstd_definir_agrupamiento:“allow grouping for the data of”(允许对
…
的数据进行分组)
[0504]
oracionstd_definir_total:“display the following summarized data”(显示以下总结的数据)
[0505]
为了生成与l类型步骤相关的verb功能组件的详细需求,定义了以下标准句子,适用于英语:
[0506]
oracionstd_crear_regla:“"create a rule that”(创建规则)
[0507]
oracionstd_condicion:“as long as the following condition is met”(只要满足以下条件)
[0508]
oracionstd_vincular:“link”(链接)
[0509]
oracionstd_conector_vincular:“with”(与)
[0510]
oracionstd_complemento_control:“performing the following controls”(执行以下控制)
[0511]
oracionstd_des vincular:“unlink”(解除链接)
[0512]
oracionstd_consultar:“search”(搜索)
[0513]
oracionstd_complemento_relacionar:“in a relationship with”(与
…
有关系)
[0514]
oracionstd_complemento_criteriobusqueda:“using the following search criteria”(使用以下搜索标准)
[0515]
为了生成与f型步骤相关的verb功能组件的详细需求,定义了以下标准句子,适用于英语:
[0516]
oracionstd_permitir:“allow”(允许)
[0517]
oracionstd_habilitar_persona:“enable”(启用)
[0518]
oracionstd_complemento_accionpersona:“to decide on the action”(决定行动)
[0519]
oracionstd_movimientos:“allow the movements of”(允许
…
的动作)
[0520]
oracionstd_complemento_acargode:“to affect”(影响)
[0521]
oracionstd_control_nuevo:“perform the following controls when creating a new transaction record of”(在创建一个新的
…
的交易记录时,执行以下控制)
[0522]
oracionstd_control_eliminar:“perform the following controls when deleting the transaction record of”(在删除
…
的交易记录时,执行以下控制)
[0523]
oracionstd_control_modificar:“perform the following controls when updating the transaction record of”(在更新
…
的交易记录时,执行以下控制)
[0524]
oracionstd_precedencia:“based on the following existing records:”(基于以下现有记录:)
[0525]
oracionstd_nuevo_movimiento:“record n movements of”(记录
…
的n个动作)
[0526]
oracionstd_control_nuevo_movimiento:“perform the following controls when creating a new movement of”(在创建新的
…
的运动时,执行以下控制)
[0527]
oracionstd_control_eliminar_movimiento:“perform the following controls when deleting the movement of”(在删除
…
的运动时,执行以下控制)
[0528]
oracionstd_control_modificar_movimiento:“perform the following controls when updating the movement of”(在更新
…
的运动时,执行以下控制)
[0529]
oracionstd_buscar_elemento:“search for the elements of”(搜索
…
的元素)
[0530]
oracionstd_complemento_buscarelemento:“to create a movement,performing the following searches”(创建运动,执行以下搜索)
[0531]
子阶段h3:定义软件设计中要使用的图形符号
[0532]
在这个阶段,使用输入/输出设备120的格式、图形符号和std句子用户界面123来
定义软件设计图中使用的图形符号。
[0533]
设计图可以用各种图形符号显示,其中之一是uml符号,但也可以定义图形元素来表示设计文档。
[0534]
子阶段h4:定义与mas元模型相关的图形符号
[0535]
为子阶段a1中定义的mas元模型的每个元素指出在软件设计图中要使用的图形组件。通过这种方式,用户在由格式、图形符号和std句子用户界面123显示的视觉网格中输入图形符号。
[0536]
设计图可以用各种图形符号显示,其中之一是uml符号,但也可以定义图形元素来表示设计文档,如图7所示。
[0537]
阶段i:自动生成业务、分析和设计文档
[0538]
在此阶段(图4i),配置为文档生成器153的处理器150,使用存储在静态数据库存储器160的格式、图形符号和std句子163中的格式和符号,生成业务、分析和设计文档,并通过以下子阶段在输入/输出设备120的文档显示用户界面124中显示它们:
[0539]
子阶段i1:生成业务文档
[0540]
在这个阶段,被配置为文档生成器153的处理器150将文本编入业务文档。在本发明中,业务文档是一个分析文档,通过执行以下动作,它显示了存储在动态数据库存储器170的简单句和问题171的逻辑结构中的简单句:
[0541]
a).对维度、时间性活动和简单句进行排序
[0542]
对文本进行分层排序,层在层次的顶部,步骤在层次的底部,如图4i2所示,因此:
[0543]-层310包含资源320
[0544]-资源320包含过程330
[0545]-过程330包含子过程340
[0546]-子过程340包含时刻350
[0547]-时刻350包含步骤360,如前所述,这些步骤最多可以有五种类型
[0548]-步骤360包含简单句370及其相应的完成问题。
[0549]
b).连续连接先前的有序组件
[0550]
在一个优选的实施例中(图5),通过将每个问题的答案按优选的顺序连接起来得到简单句,因此:何时,何人,何事,如何,何处,这并不意味着顺序不能改变。
[0551]
当所有的过程都用这种方法描述时,一个用自然语言表达的完整而详细的“案例”构成就实现了。
[0552]
子阶段i2:生成分析文档
[0553]
在这个阶段,被配置为文档生成器153的处理器150将功能需求结构化,并自动生成分析文档。在本发明中,通过执行以下动作,分析文档显示了从存储在动态数据库存储器170的简单句和问题172的逻辑结构中的功能组件中得到的需求:
[0554]
a)组装全局功能需求
[0555]“案例”的功能全局需求是指那些按照必须执行的顺序描述过程的动作,以便从构建软件应用程序所需的功能需求的角度来解释这些动作并确定要执行的动作。
[0556]
处理器150利用存储在动态数据库存储器170的功能组件逻辑结构172中的功能组件,只选择以下内容:noun,person,do和verb。对于上述每个功能组件,产生一个全局需求,
作为“案例”范围的一部分,定义noun组件(noun、do、per)的全局需求,并定义verb组件的全局需求。
[0557]
noun组件的全局需求
[0558]
全局需求是为每个名词功能组件(noun,person和do)组装的,只要它不是一个属性。通过使用子阶段f2中定义的标准句子,创建一个有标签和顺序编号的句子,如表1中所示。
[0559]
表1
[0560][0561]
verb组件的全局需求
[0562]
全局需求是通过创建有标签和顺序编号的句子来为每个verb功能组件组装的。
[0563]
在这种情况下,句子是根据verb为每个步骤类型生成的,并使用在“何事”问题中与之耦合的do和noun来组成,如表3所示。
[0564]
表2
[0565][0566]
单一的全局需求是由不同的步骤和通过单一的功能组件写成的。在这种情况下,全局需求只写一次,以避免重复,并根据需要与相应的步骤链接。
[0567]
b)组装详细的功能需求
[0568]
在这个阶段,“案例”的详细需求被描述为每个全局需求:明确的详细需求,即那些
在句子中明确表示的需求,以及隐含的详细需求,即那些已知是必要的,但没有被明确描述的需求。
[0569]
在本发明的背景下,引号中显示的句子是首选的句子,取自静态数据库存储器160的语言、词和形态句法规则162的逻辑结构。然而,这些句子可以用具有同等意义且适合于案例所选语言的句子来代替,如在子阶段f2中提出的实施方案。
[0570]
对于每一种类型的功能组件,基于其全局需求的定义,使用子阶段f2中定义的标准句子来定义“案例”的详细需求。
[0571]
为了更好地理解本发明,应该注意到,为了产生详细的需求,按照以下标准替换了这些词:
[0572]-noun:子阶段d2中定义的该类型的功能组件。
[0573]-person:子阶段d2中定义的该类型的功能组件。
[0574]-do:子阶段d2中定义的该类型的功能组件。
[0575]-verb:子阶段d2中定义的该类型的功能组件。
[0576]-{list of&attributes}:描述noun的属性列表,由子阶段d2中被标记为属性的noun,加上子阶段d3中增加的属性组成。
[0577]-{list of*attributes}:在子阶段d2中定义的&attributes列表的一部分,用于搜索、过滤、排序、分组或添加搜索或查询的结果。
[0578]-{list of do&attributes}:在子阶段d2定义的&attributes列表中的&attributes集合,由通过在子阶段g3创建的详细需求与do组件相关的元素组成。
[0579]-{list of noun&attributes}:从子阶段d2定义的&attributes列表中收集&attributes,通过在子阶段g3创建的详细需求,由与noun组件相关的元素组成。
[0580]-{list of person&attributes}:从子阶段d2定义的&attributes列表中收集&attributes,通过在子阶段g3创建的详细需求,由与person组件相关的元素组成。
[0581]-{list of cc-type global requirements}:全局需求的集合,由基于noun成分或属于子阶段e2中确定的cc类型步骤的do组件的全局需求组成。这个列表包含从0到n个全局需求。如果列表中包含0个全局要求,则不会生成引用cc类型全局需求的详细需求。
[0582]-{list of qs-type global requirements}:基于子阶段e3中确定的qs类型步骤产生的全局需求列表。这个列表包含从0到n个全局需求。如果列表中包含0个全局要求,则不生成引用qs类型全局需求的详细需求。
[0583]-{list of f-type global requirements}:基于子阶段e5中确定的f类型步骤产生的全局需求列表。这个列表包含从0到n个全局需求。如果列表中包含0个全局需求,则不生成引用f类型全局需求的详细需求。
[0584]-{fx expression}:公式的表达式,以列出的数据为参数,在子阶段d3中被确认为fx、cc或qs类型的一些步骤。
[0585]-{error message}:如果在执行公式时出现错误,将在系统中显示的消息文本,这是在子阶段d3中为任何qs类型的阶段所定义的。
[0586]-{ok message}:如果检查或确认的结果是正确的,系统将显示该消息的文本,这是在子阶段d3中为任何qs类型的阶段所定义的。
[0587]-{warning message}:如果检查或确认的结果不正确,将在系统中显示的消息文
本,这是在d3子阶段为qs种类的任何阶段定义的。
[0588]
定义noun组件的详细需求
[0589]
基于存储在动态数据库存储器170的功能组件172的逻辑结构中的noun类型功能组件,以及它们各自的全局需求,产生了以下详细需求:
[0590]
定义person组件的详细需求
[0591]
基于存储在动态数据库存储器170的功能组件172的逻辑结构中的person类型的功能组件,以及它们各自的全局需求,产生了以下详细需求:
[0592][0593]
定义verb组件的详细需求
[0594]
基于存储在动态数据库存储器170的功能组件172的逻辑结构中的verb型功能组件,以及它们各自的全局需求,产生了以下详细需求:
[0595]
[0596]
[0597][0598]
定义do组件的详细需求
[0599]
基于存储在动态数据库存储器170的功能组件172的逻辑结构中的do型功能组件,以及它们各自的全局需求,产生了以下详细需求:
[0600]
[0601][0602]
子阶段i3:生成软件设计文档
[0603]
按照子阶段f4中定义的图形符号,处理器150被配置为文档生成器153,生成xml文档,其中每个设计组件的名称和其相应的图形符号代码被存储在标签之间。
[0604]
对于选择uml图形符号的本发明的实施方案,使用xmi标准,并生成代表类图的xml。
[0605]
配置为文档生成器153的处理器150,根据在子阶段f4中选择的图形符号的定义,生成设计文档,取存储在数据库存储器中与设计相对应的数据,并以特定的xml格式导出内容。
[0606]
7.该方法的应用实例
[0607]
基于自然语言的过程描述,该系统自动产生“案例”的业务文档、分析文档和设计文档。
[0608]
该系统的组件是那些能够产生上述文档的组件(图3)。
[0609]
1.输入/输出设备120:通过该设备输入自然语言文本,使用以下配置:
[0610]
a.语言用户界面121
[0611]
b.案例用户界面122
[0612]
c.格式、图形符号和std句子用户界面123
[0613]
d.文档显示用户界面124
[0614]
2.cpu 110:系统100的处理装置,由以下组成:
[0615]
a.主存储器140:根据其配置执行以下功能:
[0616]
i.图表141
[0617]
ii.句子矩阵142
[0618]
iii.fc矩阵143
[0619]
iv.dc矩阵144
[0620]
b.处理器150:根据其配置执行以下功能:
[0621]
i.自动句子分析器151
[0622]
ii.自动软件设计器152
[0623]
iii.文档生成器153
[0624]
3.数据库存储器130:
[0625]
a.静态数据库存储器160
[0626]
i.mas元模型161
[0627]
ii.语言、词和形态句法规则162
[0628]
iii.格式、图形符号和std句子163
[0629]
b.动态数据库存储器170
[0630]
i.简单句问题171
[0631]
ii.功能组件172
[0632]
iii.设计组件173
[0633]
输入/输出设备
[0634]
这种工具是由能够在显示器上产生屏幕的永久存储器组成的,其中有用户可以输入数据或进行操作的区域。
[0635]
案例用户界面122
[0636]
案例用户界面允许用户输入所要求的数据并执行操作,将其保存在数据库存储器中。
[0637]
为了使该工具发挥作用,用户必须用自然语言输入数据(层、资源、过程、子过程、时刻、步骤),正如该方法所确定的那样。
[0638]
为此,它提出了这个上传界面,允许用户输入这些字段,并使用该方法建立的顺序在它们之间建立关系,其中每个组成部分(、时间活动和简单句子)都需要上传以下数据字段:
[0639]-名称
[0640]-描述
[0641]-相关的从属元素
[0642]
这些数据字段显示在界面中。维度和时间活动上传界面,其中{text1}和{text2}被相应的组件名称所取代,因为用户按照既定顺序填写数据字段。
[0643]-首先,{text1}=“layer”和{text2}=“resource”[0644]-当编辑动作被执行时,维度和时间活动的上传界面再次显示,但这一次,{text1}=“resource”和{text2}=“process”[0645]
o当编辑动作被执行时,维度和时间活动上传界面再次显示,但这次,{text1}=“process”和{text2}=“subprocess”[0646]
·
当编辑动作被执行时,维度和时间活动上传界面再次显示,但这次,{text1}=“subprocess”和{text2}=“moment”[0647]
当编辑动作被执行时,维度和时间活动上传界面再次显示,但这次,{text1}=“moment”和{text2}=“step”[0648]
一旦该步骤完成,句子界面显示出来。在这个界面中,用户必须回答问题,以便创建完整的、有结构的简单句,其结构是在方法中定义的。用户还必须从步骤类型列表中选择以下选项之一:
[0649]-f:功能性
[0650]-cc:检查/控制
[0651]-qs:查询/搜索
[0652]-fx:计算
[0653]-l:链接
[0654]
当用户回答问题时,该工具会完成句子,按照界面显示的顺序将问题中输入的文本串联起来。
[0655]
一旦数据上传任务完成,用户可以执行以下操作:
[0656]-保存:在数据库内存中保存上传的数据。
[0657]-取消:丢弃数据库内存中的上传数据。
[0658]
分析显示
[0659]
显示在显示器上的分析显示由屏幕组成,显示上传的数据,其组织方式使工具的用户能够阅读和理解“案例”,指导用户进行准确的分析,以正确生成全局和详细的功能需求。这些需求是由该工具自动生成的,通过提示用户确认和选择一些数据。
[0660]
文字分析显示
[0661]
这个界面以结构化的形式向用户展示简单句(单词分析界面)。使用这个界面,该工具使用户能够执行分析处理器和分析文档处理器。
[0662]
用户会看到一个表格,上面有全部上传的简单句,用户可以对每个句子执行分析操作。这个动作会触发分析处理器,其结果是返回句子中包含的单词列表。
[0663]
每个词的特征是:
[0664]-word:分析处理器检测到的词
[0665]-word:该词在句子中属于哪个问题:何时、何人、何事、如何、何处
[0666]-component type:分析处理器自动分配给每个词的类型:noun、
[0667]
adv、verb、do、adj
[0668]-in scope:如果需要的话,该栏允许工具的使用者标记有关的词是否会成为要设计的“案例”的范围的一部分。用户可以从以下选项中选择:是/否
[0669]-is attribute:如果需要的话,该栏允许工具的使用者指出该词是否应该像一个&attribute(属性)一样行事。用户可以从以下选项中进行选择:是/否
[0670]
一旦词的分析任务完成,用户可以执行以下操作。
[0671]-保存:在数据库内存中保存上传的数据。
[0672]-取消:丢弃数据库内存中的上传数据。
[0673]
在这个界面中,可以对分析处理器识别的每个词执行分析动作。在这种情况下,分析文档处理器将被执行,然后显示需求分析显示。
[0674]
需求分析显示
[0675]
这个界面(需求分析显示)向用户展示由分析文档处理器产生的全局和详细需求。
[0676]
用户会看到一个生成的全局需求的表格,和一个对应于每个全局需求的详细需求的嵌套表格。
[0677]
每个全局需求的特征是:
[0678]-word:由分析处理器检测到的词
[0679]-component type:分析处理器自动分配给每个词的类型:noun、
[0680]
adv、verb、do、adj
[0681]-step type:用户在上传界面选择的值
[0682]-globalreqnum:由工具生成的相关数字
[0683]-global requirement:由分析处理器产生的句子,与全局需求相对应。
[0684]
每个详细需求的特征是:
[0685]-detreqnum:一个由工具生成的相关数字
[0686]-detailed requirement:由分析处理器产生的句子,与详细需求相对应
[0687]-&attributes:描述该词的属性列表。它们必须由用户从以下产生的列表中选择:
[0688]
用户手动输入
[0689]
自动生成,对于被用户标记为“is attribute”的词
[0690]-message:用户希望指定的信息列表,作为对错误,正确行动和不正确行动情况的反应,作为需求执行的结果。这个列表可以通过以下方式产生:
[0691]
由用户手动输入
[0692]-expression:用户为步骤类型cc或fx指定的要计算的表达式
[0693]-associated globalreq:全局需求的列表,允许用户从这个列表中引用一个globalreq,并将其与一个详细的需求关联。这发生在范围的描述不包括这类特征的描述(这使系统不能自动生成关系),在这种情况下,用户会添加它。
[0694]
一旦单词分析任务完成,用户可以进行以下操作:
[0695]-保存:在数据库内存中保存上传的数据。
[0696]-取消:丢弃数据库内存中的上传数据。
[0697]
设计显示
[0698]
这个界面向用户展示分析处理器检测到的词,以便于根据分析结果设计“案例”。
[0699]
用户看到的是一个包含全部分析词的表格,每个词都有一个嵌套的表格,包含基于相关要求的相关词。
[0700]
每个词的特点是由分析阶段得出的以下数据组成:
[0701]-word:包含在要设计的范围内的词
[0702]-word:该词在句子中属于哪个问题:何时、何人、何事、如何、何处
[0703]-component type:分析处理器分配给每个词的类型:noun、adv、verb、do、adj
[0704]-step type:用户在上传界面选择的值
[0705]-is&attribute:用户在分析阶段表示的特征;可以是yes或no
[0706]
在这个界面中,可以对列出的每个词执行设计动作。在这种情况下,设计处理器被执行,然后显示设计显示,其中包括为该词及其相关词生成的类列表。
[0707]
每个类的特征是:
[0708]-class:由设计处理器设计的类的名称
[0709]-classtype:可以是l或nonl
[0710]-&attributes:分配给该类的&attributes的列表。在任何情况下,它们都属于分析阶段的&attributes状态列表
[0711]-methods:分配给该类的方法列表。这些方法是由设计处理器生成的
[0712]
一旦类被设计出来,就可以执行see diagram(查看图表)动作,它将在屏幕上呈现出类图。
[0713]
一旦单词分析任务完成,用户可以执行以下动作:
[0714]-保存:在数据库内存中保存上传的数据。
[0715]-取消:丢弃数据库内存中的上传数据。
[0716]
主存储器
[0717]
处理器
[0718]
为了自动生成“案例”的分析和设计文档,该工具提供了一个具有三种功能的处理器:执行分析动作的分析处理,执行设计动作的设计处理,以及生成结果文档的文档处理。
[0719]
自动句子分析器
[0720]
分析处理器接收由用户上传到数据库内存的完整的简单句集合。基于所述句子,它执行三种算法:
[0721]-识别与构建“案例”有关的词语的算法(图4e1),这是阶段e中描述的本发明的组成方法。
[0722]-生成“案例”的全局需求的算法,这是阶段f中描述的本发明的组成方法。
[0723]-产生“案例”的详细需求的算法,这是阶段f中描述的本发明的组成方法。
[0724]
字算法
[0725]
该算法(图4e1)对每个现有的句子执行所述的例程,并要求将以下两个列表上传到数据库:
[0726]-grw={grouping words}({分组词}):建立分组的词的集合,例如:当“list of prices”(价格的清单)中出现“of”(的)这个词时,它就是一个分组词
[0727]-pex={excluded words}({排除词}):分析中要排除的词的集合。
[0728]
它通常由介词、连接词和冠词组成
[0729]
一旦这个算法被执行,所有的词都将被转换为“案例”的功能组件,并按组件的类型进行分类,通过问题的方式进行相互关联。
[0730]
组件类型描述:
[0731]-noun:名词
[0732]-per:人名词
[0733]-adv:副词结构
[0734]-verb:动词
[0735]-do:直接宾语名词
[0736]-adj:形容词
[0737]
全局需求算法
[0738]
这个算法对范围内确定的每个词执行描述的例程,并要求将以下列表上传到数据库:
[0739]-reqgl_abm_sust:每次在范围中识别出noun组件时,将用于组成全局需求的句子。该方法建议类似于:“create,read,update and delete” {nounword}。(“创建、读取、更新和删除” {名词})
[0740]-reqgl_abm_pers:每次在范围内确定per组件时,将用来组成全局需求的句子。该方法建议类似于:“create,read,update and delete entities with role” {personword}。(“创建、读取、更新和删除有角色的实体” {人名词})
[0741]-reqgl_verbof:每次在范围中确定一个与f类型步骤相关的verb时,将用来组成全局需求的句子。该方法建议类似于:“create transaction record” {verbword} {doword}。(“创建交易记录” {动词} {直接宾语})
[0742]-reqgl_verbof:每次在范围内确定一个与l类型步骤相关的verb时,将用来组成全局需求的句子。该方法建议类似于:“create rule that” {verbword} {doword}“with” {nounword}。(“创建规则” {动词} {直接宾语}“与” {名词})
[0743]-reqgl_verbo:每次在范围中发现与非f类型或非l类型步骤相关的verb时,将用来组成全局需求的句子。该方法建议类似于:“create rule that” {verbword} {doword}。(“创建规则” {动词} {直接宾语})
[0744]
一旦这个算法被执行,“案例”的所有全局需求都被存储在数据库中。
[0745]
详细需求算法
[0746]
该算法对范围内确定的每个词执行描述的例程,并要求将为描述该案例而选择的语言中的标准句子上传到数据库。
[0747]
设计处理
[0748]
设计处理器利用功能组件的集合和分析阶段中添加的补充物:
[0749]-属性
[0750]-信息
[0751]-表达式
[0752]-相关的要求
[0753]
所有这些都与作为“案例”范围一部分的功能组件相关联。
[0754]
执行设计处理器算法(图4g1),该算法实现了阶段g并自动生成了构成“案例”的结果设计图的类和关系。
[0755]
文档处理
[0756]
该工具由能够自动生成文档的永久存储器组成,这些文档显示在显示器上,用户可以在其中查看来自上传存储器的数据的区域。
[0757]
业务文档处理
[0758]
业务文档生成器把在上传界面上传的数据,存储在数据库中,并应用以下算法来生成业务文档(图4i2):
[0759]
a)按照访问数据库的方法所指示的顺序,以用户上传的以下列和行数,取存储的全部上传数据:层、资源、过程、子过程、时刻、步骤、何时、何人、何事、如何、何处、句子。
[0760]
b)在标题变量中串联layer&resource&process。
[0761]
c)在副标题变量中连接子过程和时刻。
[0762]
d)以较大的缩进呈现每个步骤。
[0763]
e)以较大的缩进呈现每一句话。
[0764]
将产生的文档命名为“业务文档”(图4i2),该工具允许用户将其存储在document file(文档文件)中,用打印设备(打印机、绘图仪等)打印,用显示设备(显示器、屏幕、投影仪等)显示。
[0765]
分析文档处理
[0766]
分析文档处理器接收所有上传的数据和生成的需求,包括全局的以及详细的,并应用以下算法来生成分析文档(图4i3):
[0767]
a)使用与业务文档相同的算法来生成标题、副标题和步骤。
[0768]
b)提出每个与步骤相关的全局需求,其缩进量大于前一个步骤的缩进量。
[0769]
c)呈现每个与全局需求相关的详细需求,其缩进程度大于前一个全局需求。
[0770]
将产生的文档命名为“分析文档”(图4i3),该工具允许用户将其存储在document file中,用打印设备(打印机、绘图仪等)打印,用显示设备(显示器、屏幕、投影仪等)显示。
[0771]
设计文档处理
[0772]
文档处理器获取由设计处理器识别的类的数据,并使用读取uml图的xmi标准来创建xml文档。
[0773]
将生成的文档命名为class design document(类设计文档)(图5)。
[0774]
这个生成的文档被存储在document file中。
[0775]
数据库存储器
[0776]
该工具是由能够存储工具产生的结果的永久存储器组成的。
[0777]
数据库
[0778]
储存由工具产生的上传、分析和设计数据的数据库。它由数据库引擎管理。
[0779]
document file
[0780]
存储生成的文档的数据库。它是一个设置在硬盘上的结构,由操作系统的文档服务器管理。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。