基于bert隐藏层信息的案件判决预测方法、系统及介质
技术领域
1.本发明涉及法律服务技术领域,具体地,涉及一种基于bert隐藏层信息的刑事案件判决预测方法,尤其涉及一种基于bert隐藏层信息的案件判决预测方法、系统及介质。
背景技术:
2.在现有技术中对于刑事案件的判决预测和监督,多为法律专业人士逐案判断,这种判断形式效率较低,需要提供一种公正客观,效率高,且准确率高的判断方式。
3.公开号为cn110222866a的发明专利,公开了一种结合口语化描述与问答的智能民事案件预测系统及方法,包括以下步骤:s1.接收用户输入的口语化案情描述;s2.根据所述口语化案情描述确定用户的咨询意图;s3.根据所述咨询意图检测特征内容是否完整,若是,则执行步骤s4,否则提示用户补充相应的特征内容;s4.调用预测模型以根据完整的特征内容向用户输出相应的咨询结果。这种预测方法,虽然可以针对案件的部特征对案件进行预测,但是整个过程中含有人工参与,无法做到完全的公正客观,而且根据的特征数量有限。
4.公开号为cn110969276a的发明专利,公开了一种判决预测方法、判决预测模型获得方法及装置,获得待预测案件的案情描述文本;对所述案情描述文本进行分词,获得词汇序列;获得所述词汇序列中各词汇的词汇向量构成的矩阵;将所述矩阵输入预设的判决预测模型中,获得所述预设的判决预测模型输出的判决预测信息。这种方法虽然可以对法律判决进行预测,但是没有抓住多个子任务之间的相关性,并且使用的网络结构也比较简单,准确率也有待提高。
5.针对现有技术中的缺陷,本发明的目的是提供一种使用深度学习网络架构方法的刑事案件判决预测方法,做到公正客观,提高准确率。
技术实现要素:
6.针对现有技术中的缺陷,本发明提供一种基于bert隐藏层信息的案件判决预测方法、系统及介质。
7.根据本发明提供的一种基于bert隐藏层信息的案件判决预测方法、系统及介质,所述方案如下:
8.第一方面,提供了一种基于bert隐藏层信息的案件判决预测方法,所述方法包括:
9.步骤s1:获取案情文本原始数据,并对案情文本原始数据进行预处理,得到预处理后的案情文本;
10.步骤s2:将预处理后的案情文本进行分词,得到预处理后的分词案情文本;
11.步骤s3:预处理后的分词案情文本根据bert的中文词典进行编码,得到词编码,最终得到全文的词向量;
12.步骤s4:构建案件预测模型并对案件预测模型进行训练,得到训练后的案件预测模型;
13.步骤s5:将全文的词向量和词对的词向量输入训练后的案件预测模型,得到相关法条、罪行以及刑期的预测结果。
14.优选的,所述步骤s1包括:对案情文本原始数据进行去噪处理,得到去噪后的案情文本。
15.优选的,所述步骤s4中案件预测模型包括:深度学习网络模型;
16.所述深度学习网络模型包括:bert信息抽取单元、注意力机制信息生成单元、罪名预测单元、刑期预测单元和相关法律条款预测单元;
17.所述bert信息抽取单元将步骤s3得到的全文词向量按照先后顺序排列成矩阵,然后通过深度学习的词嵌入层后,再通过n层编码层,每个编码层的输出作为下一层的输出,最终得到n层的隐藏层输出,这些输出是向量的形式,这些向量包含全文的主要信息;
18.所述注意力机制信息生成单元通过注意力机制获取bert信息抽取单元得到的n层的隐藏层输出各自的权重,根据权重把隐藏层输出相加得到最终的信息生成向量;
19.所述罪名预测单元通过深度学习网络模型的线性层对注意力机制信息生成单元得到的信息生成向量进行罪名的预测,将信息生成向量通过线性层,转化为维度与罪名预测要求维度相同的新的特征向量,该特征向量的最大值所在位置即为罪名的预测值;
20.所述刑期预测单元通过深度学习网络模型的线性层对注意力机制信息生成单元得到的信息生成向量进行罪名的预测,将信息生成向量通过线性层,转化为维度与刑期预测要求维度相同的新的特征向量,该特征向量的最大值所在位置即为刑期的预测值;
21.所述相关法律条款预测单元通过深度学习网络模型的线性层对注意力机制信息生成单元得到的信息生成向量进行罪名的预测,将信息生成向量通过线性层,转化为维度与相关法律条款预测要求维度相同的新的特征向量,该特征向量的最大值所在位置即为相关法律条款的预测值。
22.优选的,所述注意力机制信息生成单元具体包括:
23.根据注意力机制求出bert信息抽取单元得到的第n层隐藏层输出和其他各层输出的矩阵q,k,v关系,其公式如下:
24.q=ywq25.k=xwk26.v=xwv27.其中,x为第n层隐藏层输出,y为其他层隐藏层输出,wq,wk,wv是初始化的矩阵,维度,隐藏层输出对应;
28.基于q,k,v矩阵,根据注意力机制计算各个隐藏层的权重,注意力机制公式如下:
[0029][0030]
其中,k
t
表示矩阵k的转置;d为矩阵q的维度;
[0031]
最后,根据softmax得出的权重,把隐藏层输出乘以对应权重求和,得出最终的信息生成向量。
[0032]
第二方面,提供了一种基于bert隐藏层信息的案件判决预测系统,所述系统包括:
[0033]
模块m1:获取案情文本原始数据,并对案情文本原始数据进行预处理,得到预处理后的案情文本;
[0034]
模块m2:将预处理后的案情文本进行分词,得到预处理后的分词案情文本;
[0035]
模块m3:预处理后的分词案情文本根据bert的中文词典进行编码,得到词编码,最终得到全文的词向量;
[0036]
模块m4:构建案件预测模型并对案件预测模型进行训练,得到训练后的案件预测模型;
[0037]
模块m5:将全文的词向量和词对的词向量输入训练后的案件预测模型,得到相关法条、罪行以及刑期的预测结果。
[0038]
优选的,所述模块m1包括:对案情文本原始数据进行去噪处理,得到去噪后的案情文本。
[0039]
优选的,所述模块m4中案件预测模型包括:深度学习网络模型;
[0040]
所述深度学习网络模型包括:bert信息抽取单元、注意力机制信息生成单元、罪名预测单元、刑期预测单元和相关法律条款预测单元;
[0041]
所述bert信息抽取单元将步骤s3得到的全文词向量按照先后顺序排列成矩阵,然后通过深度学习的词嵌入层后,再通过n层编码层,每个编码层的输出作为下一层的输出,最终得到n层的隐藏层输出,这些输出是向量的形式,这些向量包含全文的主要信息;
[0042]
所述注意力机制信息生成单元通过注意力机制获取bert信息抽取单元得到的n层的隐藏层输出各自的权重,根据权重把隐藏层输出相加得到最终的信息生成向量;
[0043]
所述罪名预测单元通过深度学习网络模型的线性层对注意力机制信息生成单元得到的信息生成向量进行罪名的预测,将信息生成向量通过线性层,转化为维度与罪名预测要求维度相同的新的特征向量,该特征向量的最大值所在位置即为罪名的预测值;
[0044]
所述刑期预测单元通过深度学习网络模型的线性层对注意力机制信息生成单元得到的信息生成向量进行罪名的预测,将信息生成向量通过线性层,转化为维度与刑期预测要求维度相同的新的特征向量,该特征向量的最大值所在位置即为刑期的预测值;
[0045]
所述相关法律条款预测单元通过深度学习网络模型的线性层对注意力机制信息生成单元得到的信息生成向量进行罪名的预测,将信息生成向量通过线性层,转化为维度与相关法律条款预测要求维度相同的新的特征向量,该特征向量的最大值所在位置即为相关法律条款的预测值。
[0046]
优选的,所述注意力机制信息生成单元具体包括:
[0047]
根据注意力机制求出bert信息抽取单元得到的第n层隐藏层输出和其他各层输出的矩阵q,k,v关系,其公式如下:
[0048]
q=ywq[0049]
k=xwk[0050]
v=xwv[0051]
其中,x为第n层隐藏层输出,y为其他层隐藏层输出,wq,wk,wv是初始化的矩阵,维度,隐藏层输出对应;
[0052]
基于q,k,v矩阵,根据注意力机制计算各个隐藏层的权重,注意力机制公式如下:
[0053][0054]
其中,k
t
表示矩阵k的转置;d为矩阵q的维度;
[0055]
最后,根据softmax得出的权重,把隐藏层输出乘以对应权重求和,得出最终的信息生成向量。
[0056]
第三方面,提供了一种存储有计算机程序的计算机可读存储介质,所述计算机程序被处理器执行时实现所述方法中的步骤。
[0057]
与现有技术相比,本发明具有如下的有益效果:
[0058]
1、本发明基于bert隐藏层信息、注意力机制算法对法律文本的案情描述进行判决的多个任务预测,旨在通过分析司法领域案件的案情描述文本,依照历史法院裁定、判决的案例对司法领域案件进行预测;
[0059]
2、本发明充分使用了目前该领域适用性广、准确率高的bert预训练网络结构,并且将每一层隐藏层输出充分利用,同时获取了文本的表层和深层的关键信息;
[0060]
3、本发明加入目前自然语言处理领域最热门的注意力机制,着重关注网络各个层之间的关系,解决了网络模型信息利用不充分的问题,大大提升了各项任务预测的准确率。
附图说明
[0061]
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
[0062]
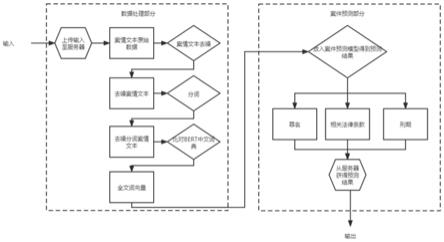
图1为刑事案件判决预测流程图;
[0063]
图2为本发明基于bert隐藏层信息的刑事案件判决网络的整体框架图;
[0064]
图3为bert网络结构示意图。
具体实施方式
[0065]
下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变化和改进。这些都属于本发明的保护范围。
[0066]
本发明实施例提供了一种基于bert隐藏层信息的案件判决预测方法,研究刑事案件判决预测技术,旨在通过分析司法领域案件的案情描述文本,依照历史法院裁定、判决的案例对司法领域案件进行预测。参照图1所示,该方法具体步骤如下:
[0067]
步骤s1:获取案情文本原始数据,并对案情文本原始数据进行预处理,得到预处理后的案情文本;该步骤中预处理为对案情文本原始数据进行去噪处理,得到去噪后的案情文本。
[0068]
步骤s2:将预处理后的案情文本进行分词,得到预处理后的分词案情文本;
[0069]
步骤s3:预处理后的分词案情文本根据bert的中文词典进行编码,得到词编码,最终得到全文的词向量;
[0070]
步骤s4:构建案件预测模型并对案件预测模型进行训练,得到训练后的案件预测模型;
[0071]
该步骤中案件预测模型包括:深度学习网络模型。深度学习网络模型包括:bert信息抽取单元、注意力机制信息生成单元、罪名预测单元、刑期预测单元和相关法律条款预测单元。
[0072]
bert信息抽取单元将步骤s3得到的全文词向量按照先后顺序排列成矩阵,然后通过深度学习的词嵌入层后,再通过12层编码层,每个编码层的输出作为下一层的输出,最终得到12层的隐藏层输出,这些输出是向量的形式,这些向量包含全文的主要信息。
[0073]
注意力机制信息生成单元通过注意力机制获取bert信息抽取单元得到的12层的隐藏层输出各自的权重,根据权重把隐藏层输出相加得到最终的信息生成向量。具体地,首先根据注意力机制求出bert信息抽取单元得到的第12层隐藏层输出和其他各层输出的矩阵q,k,v关系,其公式如下:
[0074]
q=ywq[0075]
k=xwk[0076]
v=xwv[0077]
其中,x为第n层隐藏层输出,y为其他层隐藏层输出,wq,wk,wv是初始化的矩阵,维度,隐藏层输出对应。
[0078]
根据q,k,v矩阵,可以根据注意力机制计算各个隐藏层的权重,注意力机制公式如下:
[0079][0080]
其中,k
t
表示矩阵k的转置;d为矩阵q的维度;
[0081]
最后,根据softmax得出的权重,把隐藏层输出乘以对应权重求和,得出最终的信息生成向量。
[0082]
罪名预测单元通过深度学习网络模型的线性层对注意力机制信息生成单元得到的信息生成向量进行罪名的预测。将信息生成向量通过线性层,转化为维度与罪名预测要求维度相同的新的特征向量,该特征向量的最大值所在位置即为罪名的预测值。
[0083]
刑期预测单元通过深度学习网络模型的线性层对注意力机制信息生成单元得到的信息生成向量进行罪名的预测。将信息生成向量通过线性层,转化为维度与刑期预测要求维度相同的新的特征向量,该特征向量的最大值所在位置即为刑期的预测值。
[0084]
相关法律条款预测单元通过深度学习网络模型的线性层对注意力机制信息生成单元得到的信息生成向量进行罪名的预测。将信息生成向量通过线性层,转化为维度与相关法律条款预测要求维度相同的新的特征向量,该特征向量的最大值所在位置即为相关法律条款的预测值。
[0085]
步骤s5:将全文的词向量和词对的词向量输入训练后的案件预测模型,得到相关法条、罪行以及刑期的预测结果。
[0086]
本发明实施例还提供了一种基于bert隐藏层信息的案件判决预测系统,该系统具体如下:
[0087]
模块m1:获取案情文本原始数据,并对案情文本原始数据进行预处理,得到预处理后的案情文本;该步骤中预处理为对案情文本原始数据进行去噪处理,得到去噪后的案情文本。
[0088]
模块m2:将预处理后的案情文本进行分词,得到预处理后的分词案情文本;
[0089]
模块m3:预处理后的分词案情文本根据bert的中文词典进行编码,得到词编码,最终得到全文的词向量;
[0090]
模块m4:构建案件预测模型并对案件预测模型进行训练,得到训练后的案件预测模型;
[0091]
该步骤中案件预测模型包括:深度学习网络模型。深度学习网络模型包括:bert信息抽取单元、注意力机制信息生成单元、罪名预测单元、刑期预测单元和相关法律条款预测单元。
[0092]
bert信息抽取单元将步骤s3得到的全文词向量按照先后顺序排列成矩阵,然后通过深度学习的词嵌入层后,再通过12层编码层,每个编码层的输出作为下一层的输出,最终得到12层的隐藏层输出,这些输出是向量的形式,这些向量包含全文的主要信息。
[0093]
注意力机制信息生成单元通过注意力机制获取bert信息抽取单元得到的12层的隐藏层输出各自的权重,根据权重把隐藏层输出相加得到最终的信息生成向量。具体地,首先根据注意力机制求出bert信息抽取单元得到的第12层隐藏层输出和其他各层输出的矩阵q,k,v关系,其公式如下:
[0094]
q=ywq[0095]
k=xwk[0096]
v=xwv[0097]
其中,x为第n层隐藏层输出,y为其他层隐藏层输出,wq,wk,wv是初始化的矩阵,维度,隐藏层输出对应。
[0098]
根据q,k,v矩阵,可以根据注意力机制计算各个隐藏层的权重,注意力机制公式如下:
[0099][0100]
其中,k
t
表示矩阵k的转置;d为矩阵q的维度;
[0101]
最后,根据softmax得出的权重,把隐藏层输出乘以对应权重求和,得出最终的信息生成向量。
[0102]
罪名预测单元通过深度学习网络模型的线性层对注意力机制信息生成单元得到的信息生成向量进行罪名的预测。将信息生成向量通过线性层,转化为维度与罪名预测要求维度相同的新的特征向量,该特征向量的最大值所在位置即为罪名的预测值;
[0103]
刑期预测单元通过深度学习网络模型的线性层对注意力机制信息生成单元得到的信息生成向量进行罪名的预测。将信息生成向量通过线性层,转化为维度与刑期预测要求维度相同的新的特征向量,该特征向量的最大值所在位置即为刑期的预测值;
[0104]
相关法律条款预测单元通过深度学习网络模型的线性层对注意力机制信息生成单元得到的信息生成向量进行罪名的预测。将信息生成向量通过线性层,转化为维度与相关法律条款预测要求维度相同的新的特征向量,该特征向量的最大值所在位置即为相关法律条款的预测值。
[0105]
模块m5:将全文的词向量和词对的词向量输入训练后的案件预测模型,得到相关法条、罪行以及刑期的预测结果。
[0106]
接下来,对本发明进行更详细的叙述。
[0107]
如图1所示,本实施例提供的一种基于bert隐藏层信息的案件判决预测方法。包含网络模型结构、输入输出等方面。
[0108]
如图2所示,已经编码好的全文词向量放入bert网络当中,得到每层输出再根据注意力机制进行加权相加,最后通过线性层得出最终的预测结果。
[0109]
注意力机制操作示意意图如图3所示,目的是获取bert信息抽取单元得到的12层的隐藏层输出各自的权重,并且根据权重把隐藏层输出相加得到最终的信息生成向量。具体的,首先根据注意力机制求出bert信息抽取单元得到的第12层隐藏层输出和其他各层输出的q,k,v关系,其公式如下:
[0110]
q=ywq[0111]
k=xwk[0112]
v=xwv[0113]
其中,x为第十二层隐藏层输出,y为其他层隐藏层输出,wq,wk,wv是初始化的矩阵,维度和隐藏层输出对应。
[0114]
根据q,k,v矩阵,可以根据注意力机制计算各个隐藏层的权重,注意力机制公式如下:
[0115][0116]
其中,d为矩阵q的维度。
[0117]
根据softmax得出的权重,把隐藏层输出乘以对应权重求和,得出最终的信息生成向量。最后通过线性层得出最终的关于法律罪名、相关法律条款、刑期预测结果。
[0118]
本实施例选择了目前比较通用的中文法律文本数据集cail-2108来生成数据集,作为本文提出的网络的训练数据。实验结果表明对各项任务预测的准确率均达到业界sota水平。
[0119]
通过本实施例测试结果表明,本发明在具有网络设计简单,无需复杂手工特征的选择的基础上,也具有很强的商用价值。
[0120]
本发明实施例提供了一种基于bert隐藏层信息的案件判决预测方法、系统及介质,基于bert隐藏层信息、注意力机制算法对法律文本的案情描述进行判决的多个任务预测,旨在通过分析司法领域案件的案情描述文本,依照历史法院裁定、判决的案例对司法领域案件进行预测;充分使用目前该领域适用性广、准确率高的bert预训练网络结构,并且将每一层隐藏层输出充分利用,同时获取了文本的表层和深层的关键信息;本发还明加入目前自然语言处理领域最热门的注意力机制,着重关注网络各个层之间的关系,解决了网络模型信息利用不充分的问题,大大提升了各项任务预测的准确率。
[0121]
本领域技术人员知道,除了以纯计算机可读程序代码方式实现本发明提供的系统及其各个装置、模块、单元以外,完全可以通过将方法步骤进行逻辑编程来使得本发明提供的系统及其各个装置、模块、单元以逻辑门、开关、专用集成电路、可编程逻辑控制器以及嵌入式微控制器等的形式来实现相同功能。所以,本发明提供的系统及其各项装置、模块、单元可以被认为是一种硬件部件,而对其内包括的用于实现各种功能的装置、模块、单元也可以视为硬件部件内的结构;也可以将用于实现各种功能的装置、模块、单元视为既可以是实现方法的软件模块又可以是硬件部件内的结构。
[0122]
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变化或修改,这并不影
响本发明的实质内容。在不冲突的情况下,本技术的实施例和实施例中的特征可以任意相互组合。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
