1.本发明属于自然语言处理技术领域,尤其涉及一种基于生成对抗训练的嵌套命名实体识别方法。
背景技术:
2.命名实体识别(named entity recognition,ner)是自然语言处理的一项基础任务。它的目的是从文本中检测出实体的片段和语义类别。命名实体识别在整个自然语言处理领域都具有十分重要的意义,被广泛应用在知识图谱,机器问答系统和推荐系统中。ner在很多下游任务中都是非常重要的一环。比如电商行业可能需要从用户的查询中提取出品牌或商品,来针对性地给用户返回内容。
3.先前的工作通常把命名实体识别任务视为一个序列标注问题,给文本中的每个词元赋予一个标签(如b/i/e标记)。但是,通过序列标注方法进行命名实体识别,每个词元就最多只能在一个实体指称中。因此,无法处理“一个词元属于多个实体指称”的嵌套命名实体识别问题。如图1中的例子,一个loc(即location)实体”western canadian“嵌套在另一个gpe(即geo-political entity)实体”the western canadian province of british columbia“中。嵌套实体十分常见:在广泛使用的命名实体识别数据集genia中,17%的实体和其他实体都有重叠;在ace2005数据集中,30%的句子包含嵌套的命名实体。因此,开发一个有效的模型来解决嵌套命名实体识别问题对于后续的任务以及应用都是十分必要的。
4.现有的一些嵌套命名实体识别工作通常会调整传统的序列标注模型,改动模型的分类策略或者解码层,使之适合嵌套命名实体识别任务。然而,序列标注模型由于其适合赋予单标签的特性,天然的不适合需要为一个词元赋予多个标签的嵌套命名实体识别任务。鉴于此,一些研究转而采用两阶段框架,这些研究包括基于转移的方法、基于超图的方法和基于文段的方法。基于转移的方法通常通过状态转移构建解析树来抽取嵌套实体。其中每个实体被组织成子树,按照整个二叉树的结构。基于超图的方法根据嵌套实体的结构来构建超图,然后在超图上解码嵌套实体。基于文段的方法枚举所有可能的文段,然后对这些文段分类。尽管基于文段的方法有天然的能力能解决嵌套命名实体识别问题,这些方法仍然有一系列的缺点。首先,这种两阶段方法不可避免的面临误差传递的问题;第二,由于需要枚举大量的低质量候选文段,这些方法的计算开销非常大;第三,在这些方法中,实体的边界信息没有被充分利用,但是实体边界信息对于精确地识别实体文段很重要;第四,在基于文段的方法中,文段的长度是有限制的,因此这种方法也不能够识别长实体。
技术实现要素:
5.为了解决上述问题,本发明提出了一种新颖的嵌套命名实体识别方法,名字为extract-select。本发明首先提出了一种文段选择框架,目的是为每种实体类型都训练一个抽取器,用于抽取嵌套实体。如图1中的例子,嵌套实体“pebp2”(实体类型为protein)和“pebp2 site”(实体类型为dna)将分别由两个抽取器抽取出来,这两个抽取器是以不同的
实体类型作为先验输入信息。由此,嵌套命名实体识别问题可以被很自然地解决:两个嵌套的实体会被抽取器根据实体类型不同而分别抽取。同时,由于文段选择框架的特性,先前方法中存在的误差传递问题和计算开销大的问题都能够被自然地解决。
6.之后本发明结合所提的文段选择框架与生成对抗训练(generative adversarial training,gat),设计了名为extract-select的模型。生成对抗训练能够极大的减少本发明extract-select模型对于训练数据的依赖,使得模型在训练数据很少的情况下,也能够取得比较好的结果。而之前的方法,通常都十分依赖训练数据来对模型进行训练,对数据集的质量要求比较高。
7.本发明提出的extract-select模型如下:首先,为每个实体类型都设计了一个实体标记,实体标记蕴含了丰富的关于实体类型的先验信息。然后,本发明设计了一个抽取器,抽取器的作用是抽取(extract)出特定于某个实体标记的所有实体文段,组成实体文段候选集。之后,引入一个判别器来评估抽取器抽取出的实体文段候选集,并给候选集打分。抽取器和判别器通过生成对抗训练来迭代地进行训练,使得抽取器能够抽取出更加准确的实体文段候选集合。最后,在推理阶段,迭代训练后的抽取器将挑选(select)出某一实体类型的所有实体文段。对于每种实体类型都进行抽取-挑选,可以抽取出输入文本中的所有嵌套和非嵌套实体。最初,实体标记是通过实体类别的信息进行构建的,编码了丰富的实体类别的先验信息。以实体标记作为额外输入,抽取器能够更加清楚要去抽取出来什么。与本发明的方法相比,先前的方法仅仅使用实体类别作为实体分类的类别索引,在实体识别时缺少语义信息的指导,命名实体识别的效果会差一些。
8.在抽取器中,本发明需要设计一个文段抽取策略。传统的文段抽取方法,有基于文段边界的抽取和基于文段内容的抽取,这两种方法都不适合本发明的抽取器。因为上述两种方法预测出来的实体文段都是离散的,不能用在之后的生成对抗训练的梯度反向传播中。为了使得梯度可以从判别器传至抽取器,本发明提出了一个新的混合选择策略。这个策略既考虑了文段的边界,又考虑了文段的内容,用它们生成的实体文段的候选,可以被用作之后判别器的输入。同时考虑文段的边界信息和内容信息,混合选择策略能够将实体文段候选集表示为一个连续隐变量。由此,梯度反向传播在生成对抗训练过程中可以实现。另外,这种新颖的混合选择策略能够充分利用文段的边界信息,实现更加准确的文段抽取。这种策略也有益于长实体识别,因为它在实体文段识别中没有对实体文段长度进行限制。
9.具体的,本发明公开的基于生成对抗训练的嵌套命名实体识别方法,包括以下步骤:
10.获取输入序列;
11.为每个实体类型设计一个实体标记,所述实体标记蕴含了关于实体类型的先验信息;
12.使用抽取器抽取出特定于某个实体标记的所有实体文段,组成实体文段候选集;
13.通过评估器评估抽取出的所述实体文段候选集,并给所述实体文段候选集打分;
14.所述抽取器和判别器通过生成对抗训练来迭代地进行训练,使得所述抽取器抽取出准确的所述实体文段候选集合;
15.迭代训练后所述抽取器挑选出某一实体类型的所有实体文段;
16.对每种实体类型都进行抽取-挑选,直到抽取出输入序列中的所有嵌套和非嵌套
实体,并输出所有嵌套和非嵌套实体的片段和语义类别。
17.进一步的,所述使用抽取器抽取出特定于某个实体标记的所有实体文段,包括:输入序列表示;实体标记表示和候选实体文段抽取。
18.进一步的,所述输入序列表示包括:
19.将输入序列s的所有词元表示为嵌入序列,所述嵌入序列中的每个嵌入表示是字符向量、词向量、上下文词向量和词性向量的连接,所述字符向量是由词元表示输入到第一bi-lstm网络产生;所述上下文词向量通过为每个词元生成上下文依赖的上下文嵌入得到;
20.所述字符向量、词向量、上下文词向量和词性向量的连接输入到第二bi-lstm网络中,以获取最终的词元表示。
21.进一步的,所述实体标记是实体类型的细粒度表示,每种实体类型对应一个实体标记,所述实体标记表示包括:
22.使用实体类型的关键词与同义词的连接作为实体标记,所述关键词是描述实体类型的词,所述同义词指从牛津词典摘出的与所述关键词含义相同的词或者短语;
23.连接关键词与同义词的词向量得到实体标记y
*
的表示向量,然后把所述表示向量输入到第二bi-lstm网络,获得实体标记的最终表示:
[0024][0025]
其中,hi是隐层状态向量,编码了词元xi的上下文信息;
[0026]
使用自注意力机制集成所述实体标记的最终表示:
[0027][0028][0029]
其中,αj是uj的注意力权重,wa是可学习的参数,m是实体标记的最终表示。
[0030]
进一步的,所述候选实体文段抽取使用混合选择策略,所述混合选择策略首先预测每个词元是实体文段开始和结束索引的概率,然后用概率来生成实体文段候选集,计算候选集的表示。
[0031]
进一步的,所述混合选择策略具体包括:
[0032]
给定序列和实体标记的表示向量,抽取器首先预测词元i是实体文段的开始索引和结束索引的概率:
[0033][0034][0035]
其中,ws和we是要学习的参数,hi是第i个词元的隐层状态向量,hk是第k个词元的隐层状态向量,m是实体标记的表示;
[0036]
获得可能的开始索引或者结束索引:
[0037]is
={i|argmax(ps(i|y,s))=1,i=1,...,n}
[0038]
ie={j|argmax(pe(j|y,s))=1,j=1,...,n}
[0039]
然后,对于每个给定的开始索引is∈is和结束索引je∈ie,且is≤je,使用一个二元分类器来预测实体文段候选的概率:
[0040][0041]
其中wc是要学习的参数,是开始词元的隐层状态向量,是结束词元的隐层状态向量。
[0042]
通过一个概率阈值来抽取实体文段候选,所有可能的实体文段候选构成了实体文段候选集合c;
[0043]
计算pc(i|y,s)作为第i个词元出现在候选集合c中的概率,以这种方式,用连续向量pc来表示c。
[0044]
进一步的,判别器的评估包括候选文段集合表示和候选集合打分:
[0045]
所述候选文段集合表示将实体类型y和序列s编码进实体文段候选集合的表示pc,具体包括以下步骤:用match-lstm网络构建实体感知的序列表示:
[0046][0047]
其中,hi是隐层状态向量,编码了词元xi的丰富的上下文信息,是实体标记的最终表示,|y
*
|是实体标记的长度,|s|表示序列的长度。
[0048]
所述实体文段候选集合的表示pc通过加权和用ri和概率pc(i|y,s)计算:
[0049][0050][0051]
其中rc是实体文段候选集合的表示,βi是权重系数,rk是序列s中第k个词元的表示,pc(i|y,s)是第i个词元出现在候选集合c中的概率,
[0052]
所述候选集合打分包括:抽取器抽取出来的实体文段候选集合的分数通过sigmoid函数计算:
[0053]
score=sigmoid(wbrc)
[0054]
其中,wb是可学习的参数,分数用于在生成对抗训练过程中迭代地训练抽取器和判别器。
[0055]
进一步的,所述所述抽取器和判别器通过生成对抗训练来迭代地进行训练包括包括三个任务,其中第一个任务是训练抽取器来正确预测实体文段的开始和结束索引;第二个任务是训练抽取器更好地进行开头-结尾索引的匹配;第三个任务是通过生成对抗训练联合训练抽取器和判别器,其中抽取器被视为生成器,并被训练以从判别器获得更高的分数;在迭代训练之后,使用抽取器选出实体文段的最终结果。
[0056]
进一步的,所述第一个任务具体为最小化黄金实体文段真正的开始和结束索引的负对数概率,损失函数如下:
[0057]
l
′e=-logps(s|y,s)-logpe(e|y,s)
[0058]
其中s和e表示序列s中黄金实体文段的开始和结束索引,ps(s|y,s)是黄金实体文段真正的开始索引的概率,pe(s|y,s)是黄金实体文段真正的结束索引的概率;
[0059]
所述第二个任务具体为最小化黄金实体文段真实的开头-结尾索引匹配的负对数概率,损失函数如下:
[0060]
l
″e=-logp
s,e
[0061]
其中p
s,e
是黄金实体文段真实的开头-结尾索引匹配的概率;
[0062]
所述第三个任务具体为训练抽取器从判别器获得更高的分数,损失函数如下:
[0063]
l
″′e=log(1-fd(y,s))
[0064]
其中fd(y,s)为所述抽取器抽取出来的实体文段候选集合的分数;
[0065]
抽取器的总体训练目标函数为:
[0066]
le=γ1l
′e γ2l
″e (1-γ
1-γ2)l
″′e[0067]
其中γ1,γ2∈[0,1]是超参数,平衡各个部分对总体目标函数的贡献,所述三个损失函数通过端到端的方式联合训练;
[0068]
所述使用抽取器选出实体文段的最终结果包括:在推理阶段,给定序列和实体标记y
*
,训练好的抽取器分别基于is和ie选择出开始和结束索引;然后进行开始和结束索引的匹配,得到特定实体类别的实体文段。
[0069]
本发明的有益效果如下:
[0070]
本发明提出了一个新颖extract-select模型,来解决嵌套命名实体识别问题。extract-select模型采用文段选择框架,能够用抽取器为每个实体类别分别抽取(extract)出所有可能的实体文段,并且用判别器来评估抽取出的文段并打分,能够很自然地解决嵌套命名实体识别问题。抽取器和判别器通过生成对抗训练来共同训练,使得抽取器能够从判别器得到更高的分数。在推理阶段,训练好的抽取器被用来选出(select)特定于每种实体类型的实体文段,也就是命名实体。本发明extract-select模型减少了对于训练数据的依赖,使得模型在训练数据很少的情况下,也能够取得比较好的结果。
[0071]
本发明提出了一个混合选择策略来抽取实体文段候选,并且将它们表示为一个连续隐变量。这种混合选择策略同时使用了文段的边界信息和文段内容信息用于抽取。通过这个策略,实体文段候选集的表示能够被传播到判别器,并被打分。抽取器和判别器可以在生成对抗训练过程中被一起训练优化。
[0072]
本发明充分利用了实体类别信息,为每种实体类别设计实体标记。通过把命名实体识别任务视为为每种实体进行的文段选择任务,本发明的extract-select模型使用实体标记作为抽取器的额外输入,以指导抽取器抽取出更加准确的结果。并且,在判别器评估抽取器抽取的结果时,实体标记也被用作额外的输入来增强实体文段候选集的表示。
[0073]
本发明在四个广泛使用的嵌套命名实体识别数据集上进行了实验,并且将extract-select模型与目前最先进的一系列模型进行比较。实验结果表明,extract-select模型在四个数据集上都一致地优于目前最先进的模型。
附图说明
[0074]
图1嵌套命名实体识别问题例子示意图;
[0075]
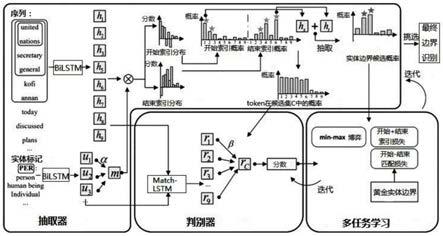
图2本发明的extract-select模型和训练过程框架图。
具体实施方式
[0076]
下面结合附图对本发明作进一步的说明,但不以任何方式对本发明加以限制,基于本发明教导所作的任何变换或替换,均属于本发明的保护范围。
[0077]
文段选择框架的输入是一个序列s={x1,x2,...,x
|s|
},其中|s|表示序列的长度。可能的实体文段s
s,e
={xs,x
s 1
,
…
,x
e-1
,xe}是序列s的一个连续子集,并且满足s≤e。令y表示预定义好的所有实体类别集合,y∈y是其中一种实体类别,y
*
是特定于实体类型y的实体标记,y
*
被设计用于表示实体类型y的先验信息。文段选择框架的任务是,对于每种实体类型y,训练一个抽取器来找到序列s中匹配y
*
的实体文段。通过文段选择框架,传统的基于文段的方法中存在的误差传递和计算开销大的问题自然就不存在了。
[0078]
生成对抗训练是学习任意复杂数据分布的生成模型的一种新颖的方式。生成对抗训练包含一个生成器g,将从随机隐分布pz(z)采样的样本映射至数据空间g(z);也包含一个对抗的判别器d,尽可能准确地区分真实样本和生成样本。生成器的目的是通过学习一个尽可能接近真实数据分布的生成分布p
g(x)
来欺骗判别器。生成器和判别器通过min-max博弈来训练(min-max为本领域现有技术,不再赘述)。也就是说,要最小化log(1-d(g(z)))并且最大化log d(x):
[0079][0080]
生成对抗训练使用判别器来优化生成器,避免了额外的损失函数设计。
[0081]
本发明提出了名为extract-select的模型,模型包含一个抽取器遵循文段选择框架来进行抽取,也包含一个判别器,目的是评估抽取结果并打分。然后本发明用生成对抗训练来一起训练抽取器和判别器。生成对抗训练的使用可疑极大减少模型对于训练数据规模的要求。
[0082]
本部分是对本发明提出的extract-select模型的详细介绍。如图2,extract-select包含两个主要部分:一个抽取器和一个判别器。具体来说,抽取器采用文段混合选择策略,基于输入序列s和实体类型y,来抽取实体文段候选集合c,并将它表示为pc,也就是(c,pc)=fe(y,s)。随后,pc被输入判别器,以评估文段候选集c的正确性,并打分,也就是score=fd(y,s,pc)。在抽取器和判别器经过迭代训练后(也就是学习如何选出正确的实体文段的过程),抽取器将选出最终的结果(一个实体文段集合),也就是文段的过程),抽取器将选出最终的结果(一个实体文段集合),也就是
[0083]
对于训练过程,抽取器是通过多任务学习来训练。具体来说,第一个任务是要训练抽取器来正确预测实体文段的开始和结束索引;第二个任务是训练抽取器更好地进行开头-结尾索引的匹配;第三个任务是通过生成对抗训练联合训练抽取器和判别器,其中抽取器被视为生成器,并被训练以从判别器获得更高的分数。在迭代训练之后,本发明使用抽取器选出实体文段的最终结果。
[0084]
给定实体类型y和输入序列抽取器的目标是从s中抽取出特定于实体标记y
*
的实体文段候选集c={c1,c2,...,ci}。同时,抽取器需要计算一个连续隐变量pc来表示c。
[0085]
(1)输入序列表示:本发明首先将输入序列s的所有词元表示为嵌入序列这个序列中的每个嵌入表示wi是字符向量、词向量、上下文词向量和词性(pos)向量的连接。字符向量是由词元表示输入到一个双向长短期记忆网络(bi-lstm)产生;对于上下文词向量,本发明为每个词元生成上下文依赖的上下文嵌入。之后,这四个向量的连接被输入到另一个bi-lstm网络中,以获取最终的词元表示:
[0086][0087]
其中,输出hi是隐层状态向量,编码了词元xi的丰富的上下文信息。
[0088]
(2)实体标记表示:本发明中,实体类型是一个重要的信息,作为抽取器的输入能够给抽取器提供先验知识,指导抽取器的抽取。因此,本发明提出为每种实体类型设计一个实体标记,其中实体标记是实体类型更加细粒度的表示。实体标记将作为抽取器的额外输入特征。本发明实验了几种不同类型的实体标记,最终选择了使用实体类型的关键词与同义词的连接作为最终的实体标记。具体来说,关键词就是描述实体类型的词,例如,类型“org”的实体标记是“organization”;同义词指实体标记是从牛津词典摘出的与关键词含义完全或者近似相同的词或者短语,例如,实体类型“org”的实体标记是“institution body group company firm business corporation”。
[0089]
本发明连接关键词与同义词的词向量得到实体标记y
*
的表示向量然后把这个向量输入到一个双向长短期记忆网络(bi-lstm),获得实体标记的最终表示其中|y
*
|是实体标记的长度。然后,
[0090]
本发明使用自注意力机制来集成实体标记的信息:
[0091][0092][0093]
其中αj是uj的注意力权重,wa是可学习的参数。
[0094]
(3)候选实体文段抽取:当前有两种方法可以用来从文本中抽取文段。第一种方法更关注文段的边界信息,分别用两个多类分类器来预测文段的开始和结束索引;第二种方法考虑的是文段的内容,用n个二分类器来预测每个词元是否在文段内。然而,尽管这两种方法能够得到候选文段,它们仍然不适合于本发明的抽取器。原因如下,第一种方法在整个上下文使用softmax多分类器,只能预测出单个文段,不适合于找出嵌套实体;这两种方法把识别出的文段视为离散变量,不能作为之后判别器的输入,由判别器进一步优化。
[0095]
鉴于此,本发明提出了一种混合选择策略,是这两种方法的结合,同时考虑文段的边界信息和文段的内容来生成实体文段候选。混合选择策略首先预测每个词元是实体文段开始和结束索引的概率,然后,用概率来生成实体文段候选集,计算候选集的表示(这个表示是一个连续隐变量)。因此,在生成对抗训练过程中,抽取器可以通过反向传播来训练。
[0096]
混合选择策略进行如下。给定序列和实体标记的表示向量,抽取器首先预测词元i是实体文段的开始索引和结束索引的概率:
[0097][0098][0099]
其中,ws和we是要学习的参数。
[0100]
在输入序列s中,可能有多个相同类别的实体。这意味着可能会预测出多个开始和多个结束索引。因此,传统的简单地将开始索引和它最近的结束索引匹配的方法在这里不合适。为了匹配开始索引和它对应的结束索引,本发明首先获得可能位于开始或者结束的索引:
[0101]is
={i|argmax(ps(i|y,s))=1,i=1,...,n},
[0102]
ie={j|argmax(pe(j|y,s))=1,j=1,...,n}.
ꢀꢀꢀ
(6)
[0103]
然后,对于每个给定的开始索引is∈is和结束索引je∈ie(is≤je),本发明使用一个二元分类器来预测实体文段候选的概率:
[0104][0105]
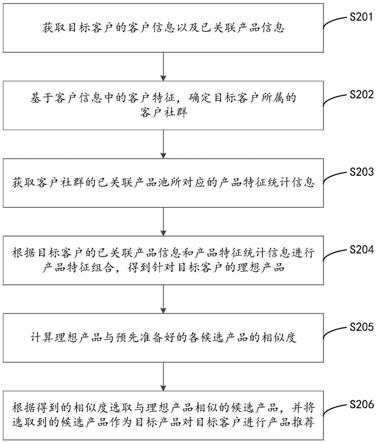
其中wc是要学习的参数。实体文段候选是通过一个概率阈值来抽取,所有可能的实体文段候选构成了实体文段候选集合c。显而易见地,这个策略在抽取实体文段时,没有设置最大文段长度。因此,长实体也可以被本发明的方法识别出来。
[0106]
然后,为了表示实体文段候选集合c,本发明首先计算pc(i|y,s)作为第i个词元出现在集合c中的概率。这个概率也能够被视为第i个词元在类型为y的实体文段边界之内的概率。具体来说,pc(i|y,s)能用ps和pe计算得到:
[0107][0108]
其中,pc(i|y,s)也意味着第i个词元出现在候选集合c中的频率。换句话说,第i个词元越频繁地出现在c中,pc(i|y,s)就会越大。
[0109]
以这种方式,本发明能够用连续向量pc来表示c,并且把它输入到之后的判别器。由此,梯度可以在生成对抗训练过程中由判别器反向传播到抽取器。
[0110]
在抽取器基于输入序列s和实体标记y
*
获得实体文段候选集合c之后,判别器目的是去评估c,并且给c打分。为了更好地进行评估,本发明首先用pc来表示实体文段候选集合c。
[0111]
(1)候选文段集合表示:本发明提出将实体类型y和序列s编码进pc。具体地,本发明用match-lstm网络构建实体感知的序列表示。match-lstm最初被提出用于在机器阅读理解中增强文本表示。这里本发明用实体标记来增强文本表示:
[0112][0113]
然后实体文段候选集合的表示通过加权和用ri和概率pc(i|y,s)计算:
[0114]
[0115][0116]
(2)候选集合打分:抽取器抽取出来的实体文段候选集合的分数可以通过sigmoid函数计算:
[0117]
score=fd(pc|y,s)=sigmoid(wbrc),
ꢀꢀꢀ
(11)
[0118]
其中,wb是可学习的参数。分数fd将被用于在生成对抗训练过程中迭代地训练抽取器和判别器。
[0119]
在训练过程中,本发明通过多任务学习训练抽取器和判别器,并且用生成对抗训练一起训练抽取器和判别器。训练过程的算法如表1中算法中所示。
[0120]
表1 extract-select模型的训练算法
[0121][0122]
本发明详细介绍抽取器和判别器的训练过程如下:
[0123]
第一个任务是通过最小化黄金实体(golden entity)文段真正的开始和结束索引的负对数概率:
[0124]
l
′e=-logps(s|y,s)-logpe(e|y,s),
ꢀꢀꢀ
(12)
[0125]
其中s和e表示序列s中黄金实体文段的开始和结束索引。
[0126]
第二个任务是通过最小化黄金实体文段真实的开头-结尾索引匹配的负对数概率:
[0127]
l
″e=-logp
s,e
.
ꢀꢀꢀ
(13)
[0128]
第三个任务是用生成对抗训练一起训练抽取器和判别器。具体来说,本发明训练抽取器来从判别器获得更高的分数:
[0129]
l
″′e=log(1fd(y,s)).
ꢀꢀꢀ
(14)
[0130]
同时,本发明的训练判别器如下:本发明最小化log(1-fd(y,s))并且最大化log fd(y,s):
[0131]
ld=zlogfd(y,s) (1-z)log(1-fd(y,s)),
ꢀꢀꢀ
(15)
[0132]
其中z∈{1,0}表示黄金实体是否出现在实体文段候选集合中。
[0133]
抽取器的总体训练目标函数为:
[0134]
le=γ1l
′e γ2l
″e (1-γ
l-γ2)l
″′e,
ꢀꢀꢀ
(16)
[0135]
其中γ1,γ2∈[0,1]是超参数,平衡各个部分对总体目标函数的贡献。三个损失通过端到端的方式联合训练。
[0136]
在推理阶段,给定序列s和实体标记y
*
,训练好的抽取器分别基于is和ie选择出开始和结束索引。然后进行开始和结束索引的匹配,得到特定实体类别的实体文段。
[0137]
本发明将extract-select模型在标准的嵌套命名实体识别数据集上进行实验,数据集包括ace04,ace05,kbp17和genia。实验结果显示,本发明的extract-select模型能够有效地检测出嵌套命名实体,并且在四个数据集上都获得了最优的效果。另外,本发明也选择了两个非嵌套命名实体识别数据集进行了实验,包括conll2003和weibo数据集,在这两个数据集上也都取得了最优的效果。
[0138]
本发明的有益效果如下:
[0139]
本发明提出了一个新颖extract-select模型,来解决嵌套命名实体识别问题。extract-select模型采用文段选择框架,能够用抽取器为每个实体类别分别抽取(extract)出所有可能的实体文段,并且用判别器来评估抽取出的文段并打分,能够很自然地解决嵌套命名实体识别问题。抽取器和判别器通过生成对抗训练来共同训练,使得抽取器能够从判别器得到更高的分数。在推理阶段,训练好的抽取器被用来选出(select)特定于每种实体类型的实体文段,也就是命名实体。本发明extract-select模型减少了对于训练数据的依赖,使得模型在训练数据很少的情况下,也能够取得比较好的结果。
[0140]
本发明提出了一个混合选择策略来抽取实体文段候选,并且将它们表示为一个连续隐变量。这种混合选择策略同时使用了文段的边界信息和文段内容信息用于抽取。通过这个策略,实体文段候选集的表示能够被传播到判别器,并被打分。抽取器和判别器可以在生成对抗训练过程中被一起训练优化。
[0141]
本发明充分利用了实体类别信息,为每种实体类别设计实体标记。通过把命名实体识别任务视为为每种实体进行的文段选择任务,本发明的extract-select模型使用实体标记作为抽取器的额外输入,以指导抽取器抽取出更加准确的结果。并且,在判别器评估抽取器抽取的结果时,实体标记也被用作额外的输入来增强实体文段候选集的表示。
[0142]
本发明在四个广泛使用的嵌套命名实体识别数据集上进行了实验,并且将extract-select模型与目前最先进的一系列模型进行比较。实验结果表明,extract-select模型在四个数据集上都一致地优于目前最先进的模型。
[0143]
本文所使用的词语“优选的”意指用作实例、示例或例证。本文描述为“优选的”任意方面或设计不必被解释为比其他方面或设计更有利。相反,词语“优选的”的使用旨在以具体方式提出概念。如本技术中所使用的术语“或”旨在意指包含的“或”而非排除的“或”。即,除非另外指定或从上下文中清楚,“x使用a或b”意指自然包括排列的任意一个。即,如果x使用a;x使用b;或x使用a和b二者,则“x使用a或b”在前述任一示例中得到满足。
[0144]
而且,尽管已经相对于一个或实现方式示出并描述了本公开,但是本领域技术人员基于对本说明书和附图的阅读和理解将会想到等价变型和修改。本公开包括所有这样的修改和变型,并且仅由所附权利要求的范围限制。特别地关于由上述组件(例如元件等)执行的各种功能,用于描述这样的组件的术语旨在对应于执行所述组件的指定功能(例如其在功能上是等价的)的任意组件(除非另外指示),即使在结构上与执行本文所示的本公开的示范性实现方式中的功能的公开结构不等同。此外,尽管本公开的特定特征已经相对于
若干实现方式中的仅一个被公开,但是这种特征可以与如可以对给定或特定应用而言是期望和有利的其他实现方式的一个或其他特征组合。而且,就术语“包括”、“具有”、“含有”或其变形被用在具体实施方式或权利要求中而言,这样的术语旨在以与术语“包含”相似的方式包括。
[0145]
本发明实施例中的各功能单元可以集成在一个处理模块中,也可以是各个单元单独物理存在,也可以多个或多个以上单元集成在一个模块中。上述集成的模块既可以采用硬件的形式实现,也可以采用软件功能模块的形式实现。所述集成的模块如果以软件功能模块的形式实现并作为独立的产品销售或使用时,也可以存储在一个计算机可读取存储介质中。上述提到的存储介质可以是只读存储器,磁盘或光盘等。上述的各装置或系统,可以执行相应方法实施例中的存储方法。
[0146]
综上所述,上述实施例为本发明的一种实施方式,但本发明的实施方式并不受所述实施例的限制,其他的任何背离本发明的精神实质与原理下所做的改变、修饰、代替、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。