1.本发明属于医学技术领域,具体涉及一种糖尿病肾病风险预测模型的构建方法及应用。
背景技术:
2.糖尿病肾病(dkd)是2型糖尿病(t2dm)的微血管并发症之一,包含了遗传和环境等多因素的复杂病理生理机制。dkd是一种慢性疾病,主要表现为蛋白尿、肾小球肥大、肾小球滤过率下降和肾脏纤维化,并伴有肾功能丧失。它已成为终末期肾病(esrd)的主要原因。现有研究表明,高达40%的糖尿病患者最终会发展成dkd。在发达国家,肾脏疾病主要是由糖尿病引起的,随着糖尿病患者人口的增加,糖尿病肾脏疾病的发病率可能会提高。
3.dkd的早期诊断取决于对微白蛋白尿的监测,微白蛋白尿表现为尿白蛋白与肌酐的比率(uacr),以及对糖尿病患者5年或更长时间的肾小球滤过率(egfr)的估计。在临床上,长期以来,微量白蛋白尿被认为是dkd的诊断标准。然而,微量白蛋白尿往往容易受到血糖波动、身体活动、药物治疗和其他因素的影响。因此,许多研究侧重于检测基因、蛋白质甚至临床指标,作为诊断或筛查dkd的新指标,并对其进行统计分析。
4.目前关于dkd风险预测模型的研究并不完全一致。关于dkd风险因素的研究涉及不同种族的遗传学与临床实践,而且样本量从一百到一千不等。探索适合2型糖尿病患者并与当地医疗条件相匹配的风险预测模型,可以早期发现和识别潜在的dkd患者。在发明的研究中,旨在通过常用的临床指标研究汉族t2dm人群的dkd风险,并构建t2dm患者的dkd风险预测模型。
技术实现要素:
5.为了解决上述技术问题,本发明提供一种糖尿病肾病风险预测模型的构建方法。
6.为实现上述目的,本发明采用以下的技术方案为:
7.一种糖尿病肾病风险预测模型的构建方法,其包括如下步骤:
8.s1、收集糖尿病患者的临床体检数据,并进行初步的数据筛选和过滤,确认受试者入选,构建数据集;
9.s2、利用信息熵方法对数据集进行特征筛选,将最终筛选出的指标作为风险因素;
10.s3、利用步骤s2最终筛选出的指标进行机器学习建模,并进行性能评估;
11.s4、构建危险因素对个人贡献的计算方法,用于进一步分析s3模型的结果;
12.s5、构建在线工具,利用s3、s4模型进行预测和解释。
13.如上所述的构建方法,优选地,在步骤s1中,所述糖尿病患者的临床数据包括身高、体重、身体质量指数(bmi)、腰围、臀围、腰臀比(w/h)、吸烟史、饮酒史、医疗史、高血压史和病程、2型糖尿病史、高脂血症史、白细胞计数、红细胞、血小板、甘油三酯、总胆固醇(tc)、低密度脂蛋白胆固醇(ldl-c)、高密度脂蛋白胆固醇(hdl-c)、空腹血糖(fbg)、糖化血红蛋白(hba1c)、血清肌酐(scr)、尿酸(ua)、促甲状腺激素(tsh)、三碘甲状腺原氨酸(t3)、游离
三碘甲状腺原氨酸(ft3)、四碘甲状腺原氨酸(t4)、游离四碘甲状腺原氨酸(ft4)、血沉(esr)、空腹血糖(fbg)。
14.如上所述的构建方法,优选地,在步骤s1中,确认受试者入选的标准为排除标准包括任何癌症、免疫疾病、怀孕或哺乳期的病史或积极治疗,且1)非dkd组:随机尿uacr《30mg/g;
15.2)dkd组:包括30mg/g≤uacr《300mg/g,定义为微量白蛋白尿噬菌体,uacr≥300mg/g,定义为巨蛋白尿噬菌体。
16.如上所述的构建方法,优选地,在步骤s2中,基于信息熵的特征选择模型采用随机森林模型,通过网格搜索策略搜索超参数,将信息熵函数设置为基尼不纯度函数,最终通过训练的随机森林模型的特征重要性排序进行特征筛选。
17.如上所述的构建方法,优选地,在步骤s2中,最终筛选出的指标包括血沉(esr)、肌酐、收缩压(sbp)、年龄、高血压病程、ft3和t3共7项。
18.如上所述的构建方法,优选地,在步骤s3中,根据步骤s2最终筛选出的7种指标进行机器学习建模,机器学习模型采用随机森林模型,并将树数设置为200;在每一颗决策树的构建过程中,采用基尼不纯度函数作为分支标准;在数据集d上的基尼不纯度定义为
[0019][0020]
其中,pi是在数据集d中属于第i类的概率,c是类别的总数量;在一个决策树节点上,数据集d将依据最小基尼增益点标准a=a分割为d1和d
2 2个子集,其中,最小基尼增益点定义为
[0021][0022][0023]
其中,di是应用分割后的子集a=a(d1={d∈d|d≤a},d2={d∈d|d>a}),而2个子集d1和d2将递归地执行相同的过程;当递归达到收敛条件后,该决策树训练完成;当规定数量的决策树训练完成后,最终模型概率通过单个决策树投票生成,最终模型预测的样本k属于类别ci的概率,定义为rf(fk)=ni/n其中,fk代表第k个样本的指标,即代表第k个样本的指标,即是第k个样本的第i个特征的值,m是最终筛选出特征的总数,n为决策树的数量,ni为预测为类别ci的决策树数量;
[0024]
预测模型训练完成后,使用pickle持久化保存为可重复使用的二进制模型文件;使用时可通过先加载二进制模型文件,并输入特征向量fk,通过运算便可输出对应属于某一类别的概率。
[0025]
如上所述的构建方法,优选地,在步骤s4中,构建危险因素对个人贡献的计算方法是
[0026]ci
=rf(fk)-rf(f
ik
)
[0027]
其中,是第k个样本的第i个特征的值,m是最终筛选出特征的总数;因此,是虚拟特征向量,其中第i个特征为零,fk是原始特征向量,rf代表s3步骤中训练好的预测模
型;
[0028]
当计算危险因素贡献时,应先加载s3步骤中保存的二进制模型文件,再构建如上所述的特征向量和fk,将两个向量输入到加载的模型中即可得到对应于两个向量的患病概率,再相减得到风险贡献度ci。
[0029]
如上所述的构建方法,优选地,在步骤s5中,构建在线工具使用传统的网页构建框架,前端使用jquery、bootstrap、javascript、html编写了基本的交互逻辑和用户界面,使用echarts作图并可视化,后端使用python3的djiango框架编写了网络请求的预处理和模型的预测;其中,
[0030]
在模型训练过程中,数据使用pandas进行读取和预处理,使用scikit-leam进行特征筛选、预测模型构建和风险因素对个人贡献的计算,最终模型使用pickle模块进行持久化;
[0031]
在模型使用过程中,网络请求数据通过djiango接受和预处理,模型使用pickle加载,最终将得到的结果可视化返回前端。
[0032]
根据如上所述的构建方法构建的糖尿病肾病风险预测模型。
[0033]
根据如上所述的构建方法构建的模型在糖尿病肾病风险预测中的应用。本发明的有益效果在于:
[0034]
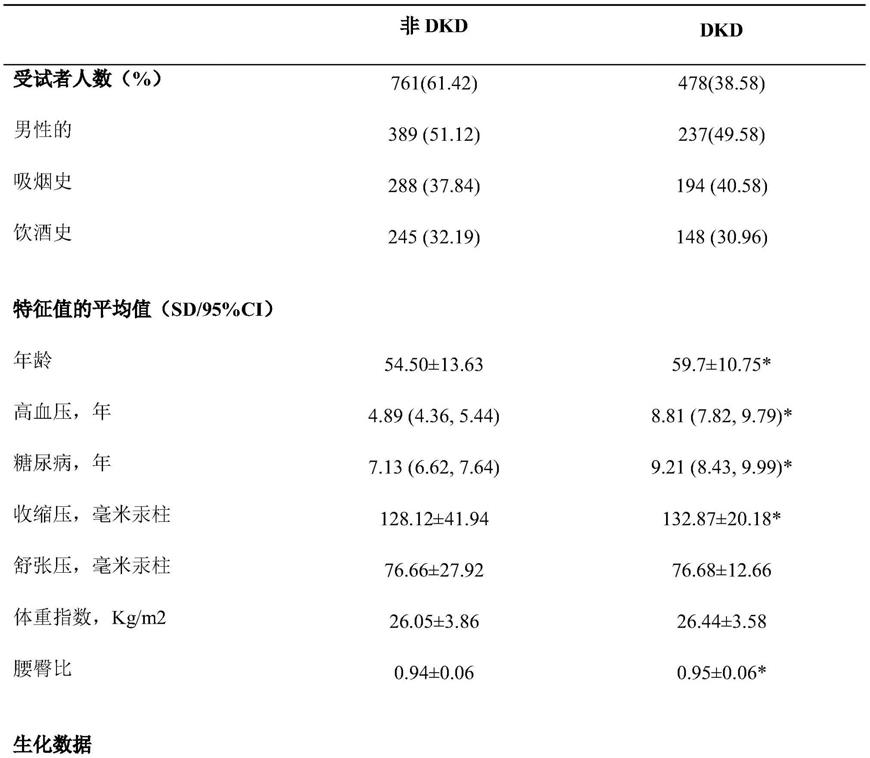
本发明提供的糖尿病肾病风险预测模型的构建方法,构建模型所筛选出的指标都是临床上十分容易获得的指标,简单易于使用,根据构建的预测模型可以提供个性化的治疗指导。通过本发明构建的模型,可以预测dkd的风险,并建议每个人的每个指标的风险贡献程度,这对早期干预和预防有一定的临床意义。
附图说明
[0035]
图1为从基于信息熵的特征选择模型中提取的前10个特征的特征重要性得分。
[0036]
图2为从整个数据集构建模型的预测模型效率。
[0037]
图3为从特征选择数据集构建模型的预测模型效率。
[0038]
图4为预测的dkd风险(红色条)或非dkd风险(绿色条)的结果。
[0039]
图5为输入个体的预测特征风险贡献。
[0040]
图6为糖尿病肾病风险预测模型的构建过程的示意图。
具体实施方式
[0041]
以下实施例用于进一步说明本发明,但不应理解为对本发明的限制。在不背离本发明精神和实质的前提下,对本发明所作的修饰或者替换,均属于本发明的范畴。
[0042]
若未特别指明,实施例中所用的技术手段为本领域技术人员所熟知的常规手段,除另有规定,本方法所用试剂均为分析纯或以上规格。
[0043]
实施例1
[0044]
一种糖尿病肾病风险预测模型的构建方法,其包括如下步骤:
[0045]
s1、收集糖尿病患者的健康数据,并进行初步的数据筛选和过滤,确认受试者入选,构建数据集;
[0046]
具体操作:
[0047]
在2017年2月至2019年4月,从北京潞河医院内分泌科收集1378名患者,经完全知情同意后,排除标准包括任何癌症、免疫疾病、怀孕或哺乳期的病史或积极治疗,也包括那些根据采访者判断患有认知障碍或有任何严重疾病,可能会阻碍参与的受试者,最终纳入1239名受试者。包括478名dkd患者和761名非dkd患者,定量地预测dkd的发病风险。从患者访谈中获得临床数据。收集吸烟史、饮酒史、医疗史、高血压史和病程、2型糖尿病史、高脂血症史。还进行了身高、体重、体重指数(bmi)、腰围、臀围、腰臀比(w/h)的体检。使用pandas 2.4加载和预处理数据,pandas 2.4是python 3.7中的一个包。遗漏值和明显错误数据被替换为平均值。将数据集按4:1的比例划分为训练集和测试集,并对训练集进行5次交叉验证,以构建更稳健的模型。采用基于信息熵的特征选择方法,筛选出dkd的风险因素。
[0048]
诊断标准:排除标准包括任何癌症、免疫疾病、怀孕或哺乳期的病史或积极治疗,符合中国2型糖尿病防治指南的2型糖尿病诊断标准。高血压被诊断为至少两倍的血压,收缩压大于或等于140mmhg,舒张压大于或等于90mmhg,或使用抗高血压药物。dkd的诊断和分类基于uacr的比率。指南中建议对uacr进行随机尿液测量。根据以下诊断标准对dkd进行分级,最后接受2组:1)非dkd组:随机尿uacr《30mg/g;2)dkd组:包括30mg/g≤uacr《300mg/g,定义为微量白蛋白尿噬菌体,uacr≥300mg/g,定义为巨蛋白尿噬菌体。
[0049]
生化测量:所有受试者在采集血样前均需进行夜间禁食。采集血样测定指标有:白细胞计数、红细胞、血小板、甘油三酯、总胆固醇(tc)、低密度脂蛋白胆固醇(ldl-c)、高密度脂蛋白胆固醇(hdl-c)、空腹血糖(fbg)、糖化血红蛋白(hba1c)、血清肌酐(scr)、尿酸(ua)、促甲状腺激素(tsh)、三碘甲状腺原氨酸(t3)、游离三碘甲状腺原氨酸(ft3)、四碘甲状腺原氨酸(t4)、游离四碘甲状腺原氨酸(ft4)、血沉(esr)、空腹血糖(fbg),均通过中心实验室统一检测获得结果。在内分泌实验室通过生化测试评估患者口服葡萄糖耐量试验(ogtt)时0、1、2、3小时的胰岛素和c肽水平。通过随机收集尿液,通过电化学发光检测uacr。
[0050]
获得的数据,集中全体人口的所有特征如表1所示。t检验适用于正态分布特征(表1中的项目包含
±
表示95%ci),wilcoxon/kruskal-wallis秩和检验适用于非正态分布特征(表1中的平均值(第一个四分位,第三个四分位)。研究人群在性别、吸烟史和饮酒史方面没有差异。糖尿病、高血压病程、腰臀比、t3、ft3、esr、胰岛素0h、c肽0h、2h、3h积分差异有统计学意义(p《0.05)。
[0051]
表1 数据集在不同功能和不同组中的一般描述
[0052]
[0053][0054]
s2、利用信息熵方法对数据集(s1)进行特征筛选,最终筛选出7项风险因素;
[0055]
基于信息熵的特征选择模型采用随机森林模型,例如可优选使用scikit-learn 0.22实现,通过网格搜索策略搜索超参数,发现将信息熵函数设置为基尼不纯度函数,并将树数设置为200时,效果最优,最终通过训练的随机森林模型的特征重要性排序进行特征筛选。
[0056]
具体地:基于信息熵的特征选择方法
[0057]
信息熵是信息论中的一个概念,它可以定量地定义一系列数据所具有的信息,信息熵得分可以用于特征选择。也就是说,熵分数越高的特征包含更多关于正确分类样本的信息。在本发明中使用了基尼杂质函数,它是信息熵函数的一个变体,并为评估数据中包含的信息熵提供了近似的结果。
[0058]
为了使最终预测模型更简洁易于使用,并且避免数据集中的噪声,申请人使用全数据集按照上述方法进行了特征筛选。在训练完成后,使用了scikit-learn中的feature_importance函数查看了各个特征对于预测性能的贡献程度,如图1所示。其中数值越大代表其更有可能为风险因素。
[0059]
为了更好地权衡模型的复杂性和诊断的准确性,申请人测试了模型测试的前几个特征变量,发现当模型使用前7个特征进行训练时,测试auc达到峰值。因此,本发明选择了前7个特征,即血沉(esr)、肌酐、收缩压(sbp)、年龄、高血压病程、ft3和t3(三碘甲状腺原氨酸)。每个特征都能解释总信息的2.7%以上。也就是说,这些特征是影响dkd的主要特征,其他特征可能包含更多的噪声或受dkd的影响较小。
[0060]
s3、利用筛选出的7项指标进行机器学习建模,并进行性能评估;
[0061]
在比较了多层感知器、逻辑回归、支持向量机、随机森林等的性能之后,通过使用筛选出的7个指标特征选择模型,根据所选择的特征来选择和重新训练随机森林模型,以构建更稳健和精确的预测分类器。
[0062]
随机森林预测法
[0063]
随机森林模型是一个决策树袋式集合模型。它使用数据集的信息熵来对不同的样本进行分类。在这里,使用python 3.7中的scikit-learn 0.22构建了这个模型。通过对超参数使用网格搜索策略,将信息熵函数设置为基尼杂质函数,并将树的数量设置为200棵,以达到准确性和效率的平衡。具有数据集的决策树节点的基尼杂质函数d定义为
[0064][0065]
其中,pi是在数据集中属于类的概率,i是在数据集中属于d和c是类的总数。数据集d将根据标准在树节点上分为2组,即d1和d2,a=a是定义为的最小基尼增益点,定义为
[0066][0067][0068]
其中,di是应用除法后的子集a=a(d1={d∈d|d≤a},d2={d∈d|d>a}).及2个子集d1和d2将递归地执行相同的过程。
[0069]
当递归达到收敛条件后,该决策树训练完成;当规定数量的决策树训练完成后,最终模型概率通过单个决策树投票生成,最终模型预测的样本k属于类别ci的概率,定义为
[0070]
rf(fk)=ni/n
[0071]
其中,fk代表第k个样本的7个指标,即代表第k个样本的7个指标,即是第k个样本的第i个特征的值,m是所选特征的总数,n为决策树的数量,ni为预测为类别ci的决策树数量;
[0072]
预测模型训练完成后,使用pickle持久化保存为可重复使用的二进制模型文件;
使用时可通过先加载二进制模型文件,并输入特征向量fk,通过运算便可输出对应属于某一类别的概率。采用auc值、准确率(acc)、真阳性率(tpr)、假阳性率(fpr)、精确率(prec)和f1分数等进行性能评估。
[0073]
随机森林模型在验证集上的平均auc为0.72,在测试集上的平均auc为0.71,与图2中验证集上的auc为0.73的全特征模型相比略有下降。结果见图2和图3。
[0074]
这里,通常定义一个典型的度量列联表来度量分类模型。真阳性(tp)和真阴性(tn)分别被正确分类为dkd和正常;假阴性(fn)表示被错误分类为非dkd的dkd;被错误分类为dkd的正常样本被定义为假阳性(fp)。然后应用几个标准性能指标来描述以下基于之前指标的模型性能,包括准确率(acc)、真阳性率(tpr)也称为召回率、假阳性率(fpr)、精确率(prec)和f1分数,定义如下等式。
[0075][0076][0077][0078][0079][0080]
通过使用这些指标,表2中列出了具有不同阈值的预测模型的各种得分情况。
[0081]
表2
[0082][0083][0084]
s4、构建危险因素对个人贡献的计算方法,用于进一步分析s3模型的结果;
[0085]
风险贡献模型
[0086]
风险特征贡献法,明确规定了每个特征对糖尿病肾病的贡献。每个贡献率都是用以下公式计算的
[0087]
[0088]ci
=rf(fk)-rf(f
ik
)
[0089]
其中是第k个样本的第i个特征的值,m是所选特征的总数。因此,是虚拟特征向量,其中第i个特征为零,fk是原始特征向量,rf代表s3步骤中训练好的预测模型。
[0090]
当计算危险因素贡献时,应先加载s3步骤中保存的二进制模型文件,再构建如上所述的特征向量和fk,将两个向量输入到加载的模型中即可得到对应于两个向量的患病概率,再相减得到风险贡献度ci。
[0091]
需要注意的是,每个特征的贡献可以是负的,也就是说,这个特征在诊断中产生了积极的作用。
[0092]
s5、构建在线工具,利用s3、s4模型进行预测和解释。
[0093]
在线工具使用传统的网页构建框架,前端使用jquery、bootstrap、javascript、html编写了基本的交互逻辑和用户界面,使用echarts作图并可视化,后端使用python3的djiango框架编写了网络请求的预处理和模型的预测。在模型训练过程中,数据使用pandas进行读取和预处理,使用scikit-learn进行特征筛选(即步骤s2)、预测模型构建(即步骤s3)和风险因素对个人贡献(即步骤s4)的计算,最终模型使用pickle模块进行持久化。在模型使用过程中,筛选出患者的7项的特征通过网络请求的方式发送至服务器端的djiango并进行预处理,构建出患者的特征向量fk;预测模型使用pickle加载后,按照步骤s3构建的模型预测出该患者的发病概率;按照步骤s4预测出7项筛选出的特征的风险贡献度,最终将得到的结果返回前端并可视化展示。
[0094]
风险贡献是基于预测模型而应用的,它可以很容易地分析一个特定特征的风险贡献。例如一名2型糖尿病患者的血沉为95mm/h,肌酐为237umol/l,收缩压(sbp)为145mmhg,年龄为58岁,高血压病程为5年,每年体检的tf3为1.66pg/ml,t3为0.5ng/ml。将这些指标输入构建的预测模型中,这人将被预测为患有dkd的高风险,概率为97%,按模型给出的每个特征的风险贡献分数计算如下:血沉:0.045,肌酐:0.05,收缩压:0.0,年龄:-0.005,高血压病程:0.0,tf3:0.095,t3:0.07。因此,所有的结果都将在网络服务器上以文字和数字的形式进行说明结果见图4和图5。图4为预测的dkd风险(左侧的为红条)或非dkd风险(右侧的为绿条)。图5为预测输入个体的特征风险贡献。
[0095]
结果说明预测结果与风险与实际情况相符合,说明本模型构建成功,构建模型的过程如图6所示。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。