line管理及根据取指令模块的地址取指令;
9.所述取指令模块用于根据bpu执行单元等条件选择取指令地址,并且根据地址偏移选择有效指令;
10.所述指令列队模块用于缓存宏指令,完成宏指令到uop翻译的前期检查;
11.所述解码器用于将宏指令翻译到uop;
12.所述uop队列模块用于缓存uop指令及loop指令的循环处理;
13.所述重命名寄存器用于把架构寄存器映射到物理寄存器,并且完成空闲物理寄存器的管理。
14.优选的,所述分配模块用于完成调度程序模块、重新排序缓冲区、下载区和store buffer分配与回收;
15.所述调度程序模块用于完成uop的唤醒、仲裁、发射、预测与重发等功能;
16.所述执行单元用于完成所有的uop执行过程,包括分支指令,加法,减法及所有微操作;
17.所述数据缓冲区用于完成数据的读和写,包括处理跨cache line和跨页的情况,且数据缓冲区与指令高速缓冲存储器共享cpu二级缓存模块;
18.所述重新排序缓冲区用于维护指令的按序提交,包括维护宏指令的原子性、事件的处理及uop状态的维护及重命名阶段的rat恢复的架构状态。
19.一种乱序提交指令的方法,包括以下步骤:
20.s1、判断任何长周期指令是否会产生异常,并且发送状态给重新排序缓冲区;
21.s2、在重新排序缓冲区中,允许提交还未执行完成指令之后的指令,即乱序提交指令;
22.s3、当长周期指令执行完成时,提交该指令。
23.优选的,还包括以下步骤:
24.(1)在重命名阶段,根据每条指令的目的寄存器,从物理寄存器管理队列中分配空闲的物理寄存器;
25.(2)在分派阶段,指令被分派到重新排序缓冲区,同时指令进入执行单元;
26.(3)指令在执行单元执行完成后,将指令的执行结果写到物理寄存器,并且更新执行完成状态到重新排序缓冲区;
27.(4)在重排序缓存中,根据指令的顺序提交指令,释放重排序缓存的entry,更新架构寄存器映射表,并且释放空闲的物理寄存器,写回到物理寄存器管理队列。
28.优选的,在重排序缓存中,需要判断需要提交的指令是否执行完成。当指令需要写目的寄存器时,需要取到目的寄存器数据,指令才执行完成。
29.优选的,当除法指令进行除法器执行时,如果除法指令不会产生异常,只是除法指令的执行还未结束。这种情况下,除法指令后续的指令可以先提交,并且释放物理寄存器。当除法指令执行完成后,再提交除法指令。当访存指令需要读l2时,如果当前指令不会产生异常,那么该指令也不阻挡该指令之后的指令,后续的指令提前提交。直到该访存指令执行完成后,提交该访存指令。
30.优选的,当除法指令进入除法器后,检查数据是否有溢出,或者除数为0等异常,如果除法指令不会产生异常,那么向rob发生不会产生异常报告。当load、amo,lr/sc类型等进
入执行单元后,先查询tlb信息,及判断指令地址是否非法等,如果该条指令不会产生异常,如果需要访问l2或者内存时,那么向rob发生不会产生异常报告。
31.本发明与现有技术相比,其有益效果是:本发明的方法能够乱序提交流水线中未执行完成之前的指令,降低由于指令本身或者l2/内存访问延时带来的性能损失,且不局限于任何指令集、架构及工艺等条件。
附图说明
32.图1为根据本发明的乱序提交指令的装置及其方法的cpu的流水线架构图;
33.图2为根据本发明的乱序提交指令的装置及其方法的rob乱序提交指令框图;
34.图3为根据本发明的乱序提交指令的装置及其方法的长时间执行指令执行流程图;
35.图4为根据本发明的乱序提交指令的装置及其方法的乱序提交指令图;
36.图5为根据本发明的乱序提交指令的装置及其方法的load,store及div指令提交处理流程。
具体实施方式
37.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
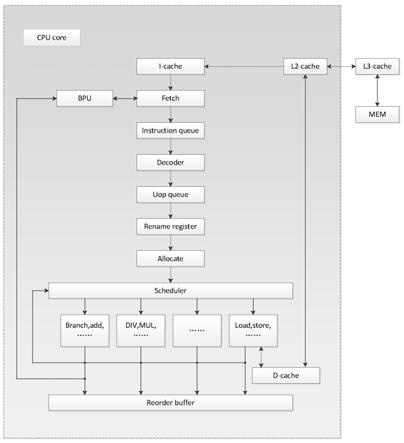
38.参照图1-5,一种乱序提交指令的装置,包括:指令高速缓冲存储器、与所述指令高速缓冲存储器信号连接的取指令模块、与所述取指令模块信号连接的指令列队模块与cpu分支处理模块、与所述指令列队模块信号连接的解码器、与所述解码器信号连接的uop队列模块、与所述uop队列模块信号连接的重命名寄存器、与所述重命名寄存器信号连接的分配模块、与分配模块信号连接的调度程序模块及与所述调度程序模块信号连接的多个执行单元,多个所述执行单元信号连接有重新排序缓冲区,其中一执行单元信号连接有数据缓冲区。
39.进一步的,所述指令高速缓冲存储器信号连接有cpu二级缓存模块,所述cpu二级缓存模块信号连接有cpu三级缓存模块,所述cpu三级缓存模块信号连接有内存模块,且所述cpu二级缓存模块信号连接有重新排序缓冲区。
40.进一步的,所述指令高速缓冲存储器用于完成物理地址到虚拟地址翻译、cache line管理及根据取指令模块的地址取指令;
41.所述取指令模块用于根据bpu执行单元等条件选择取指令地址,并且根据地址偏移选择有效指令;
42.所述指令列队模块用于缓存宏指令,完成宏指令到uop翻译的前期检查;
43.所述解码器用于将宏指令翻译到uop;
44.所述uop队列模块用于缓存uop指令及loop指令的循环处理;
45.所述重命名寄存器用于把架构寄存器映射到物理寄存器,并且完成空闲物理寄存器的管理。
46.进一步的,所述分配模块用于完成调度程序模块、重新排序缓冲区、下载区和store buffer分配与回收;
47.所述调度程序模块用于完成uop的唤醒、仲裁、发射、预测与重发等功能;
48.所述执行单元用于完成所有的uop执行过程,包括分支指令,加法,减法及所有微操作;
49.所述数据缓冲区用于完成数据的读和写,包括处理跨cache line和跨页的情况,且数据缓冲区与指令高速缓冲存储器共享cpu二级缓存模块;
50.所述重新排序缓冲区用于维护指令的按序提交,包括维护宏指令的原子性、事件的处理及uop状态的维护及重命名阶段的rat恢复的架构状态。
51.一种乱序提交指令的方法,包括以下步骤:
52.s1、判断任何长周期指令是否会产生异常,并且发送状态给重新排序缓冲区;
53.s2、在重新排序缓冲区中,允许提交还未执行完成指令之后的指令,即乱序提交指令;
54.s3、当长周期指令执行完成时,提交该指令。
55.进一步的,还包括以下步骤:
56.(1)在重命名阶段,根据每条指令的目的寄存器,从物理寄存器管理队列中分配空闲的物理寄存器;
57.(2)在分派阶段,指令被分派到重新排序缓冲区,同时指令进入执行单元;
58.(3)指令在执行单元执行完成后,将指令的执行结果写到物理寄存器,并且更新执行完成状态到重新排序缓冲区;
59.(4)在重排序缓存中,根据指令的顺序提交指令,释放重排序缓存的entry,更新架构寄存器映射表,并且释放空闲的物理寄存器,写回到物理寄存器管理队列。
60.进一步的,在重排序缓存中,需要判断需要提交的指令是否执行完成。当指令需要写目的寄存器时,需要取到目的寄存器数据,指令才执行完成。
61.进一步的,当除法指令进行除法器执行时,如果除法指令不会产生异常,只是除法指令的执行还未结束。这种情况下,除法指令后续的指令可以先提交,并且释放物理寄存器。当除法指令执行完成后,再提交除法指令。当访存指令需要读l2时,如果当前指令不会产生异常,那么该指令也不阻挡该指令之后的指令,后续的指令提前提交。直到该访存指令执行完成后,提交该访存指令。
62.进一步的,当除法指令进入除法器后,检查数据是否有溢出,或者除数为0等异常,如果除法指令不会产生异常,那么向rob发生不会产生异常报告。当load、amo,lr/sc类型等进入执行单元后,先查询tlb信息,及判断指令地址是否非法等,如果该条指令不会产生异常,如果需要访问l2或者内存时,那么向rob发生不会产生异常报告。
63.表格1执行单元产生异常检查报告控制信号
[0064][0065]
rob收到执行单元发送的报告后,比较报告与rob的entry,当lu_rob_index命中了rob的entry,rob判断当前执行单元发送的报告是否是指令还未执行完成,但是不会产生异常的指令。rob置lu_rob_index位置的pending_val为1。如果iu_rob_ie_n_val为0,表示当前指令是已经执行完成,置lu_rob_index位置的pending_val为0,并且置rob中的status为done状态。当提交指针commit_ptr指向rob中pending_val为1的指令时,释放rob entry,该entry之后的指令越过当前指令,进行乱序提交。被提交的指令根据架构寄存器编号dst_index去更新架构寄存器的寄存器映射表,并且释放空闲的物理寄存器。如果被更新的架构寄存器的pending_val有效,那么架构寄存器的寄存器映射表也置pending_val标记。当空闲物理寄存器从架构寄存器映射表释放时,pending_val也更新到空闲物理寄存器管理队列。当指令在重命名阶段需要分配目的寄存器的空闲物理寄存器时,如果pending_val为1的物理寄存器不进行分配,因为该条指令还未执行完成即指令还未提交。只有当pending_val为0的空闲物理寄存器才可以分配。当长周期执行指令执行完成时,提交指令,并且将重排序缓存、架构寄存器映射表和空闲物理寄存器管理队列中的pending_val置0,此时指令提交完成。在图5中,空闲物理寄存器中k个寄存器;架构寄存器映射表有m个entry;重排序缓存有n个entry。执行单元判断重排序缓存第9个entry的指令为长周期指令,重排序缓存收到执行单元的报告后,置第9个entry的pending_val为1。指令提交之后,架构寄存器映射表的对应的entry 2的pending_val也置为1,即为重排序缓存中dst_index为2的寄存器的entry。寄存器释放回空闲物理寄存器管理队列时,物理寄存器17的pending_val为1。物理寄存器17对应的指令还未执行完成,其实并未正真的提交,所以在执行单元返回这条指令的数据之前,物理寄存器17都不允许分配给指令,进行重命名。当执行单元执行完时,同时更新重排序缓存、架构寄存器映射表和空闲物理寄存器的pending_val为0,此时该条指令才正真的提交,物理寄存器17可以分配给申请空闲物理寄存器重命名的指令。
[0066]
假设有risc v指令集的指令序列如下表所示,所有的指令分配了重排序缓存entry、根据指令类型分配了load指令缓存entry、store指令缓存entry及指令目的寄存器。空闲物理寄存器有k个寄存器;load指令缓存有p个entry;store指令缓存有q个entry;重排序缓存为n个entry及架构寄存器有m个entry。
[0067]
表格2指令例子序列
[0068][0069]
编号为2和3的2条load指令在lsu执行时,当这2条指令都判断指令本身不会产生异常,比如已经得到pa,并且指令pa权限也没有产生异常,即使load指令没有在dc3取到数据,发生了dcache miss事件,需要去l2/内存读取数据,load指令更新执行状态到重排序缓存,重排序缓存的pending_val置为1,同时释放load指令缓存的entry 1和entry 2,load指令缓存entry的pending_val置为1。当重排序缓存中的提交指针commit_ptr指向rob中entry 1时,这2条load指令释放重排序缓存entry,并且允许load之后的指令进行提交。这2条load指令并没有真正的提交,而是允许这2条load指令之后的指令进行乱序提交。这2条load指令还在lsu执行,2条load指令的状态位pending_val也更新到架构寄存器映射表和空闲物理寄存器堆。当新的指令在重命名阶段重命名时,空闲物理寄存器队列中寄存器状态位pending_val为1的寄存器不能分配给新的指令,因为该寄存器的指令还未执行完成,也还没有真正的提交。同理,空闲load指令管理队列和空闲store指令管理队列中状态位pending_val为1的entry不能分配给新的指令。只有等到lsu中的load指令取到数据后,lsu发出指令执行完成信号,清除物理寄存器、重排序缓存、load指令缓存entry、store指令缓存entry及架构寄存器映射表的pending_val的为0。当物理寄存器、load指令缓存entry及store指令缓存entry的pending_val的为0后,又可以分配给新的指令。
[0070]
编号6的amo类型指令amoxor,需要先从内存读数据,然后进行“异或”运算,然后再写内存。当amo的load和store属性都判断不会产生异常时,也支持后续指令乱序提交,处理流程与load指令类似。编号为9的除法指令divw执行周期比较长,risc v指令集定义的除法指令不会产生异常,因此,divw指令在进入除法器流水线时,发送指令执行状态给重排序缓存。除法指令的处理流程也与load指令的处理流程类似。
[0071]
当lsu执行完成load指令之后,发出指令执行完成信号,也是load指令提交指示信号。load指令更新数据到物理寄存器及forward数据给依赖该数据的指令。
[0072]
指令在执行单元执行完成,并且产生指令执行完成信号,如下表所示。
[0073]
表格3执行单元产生指令执行完成信号
[0074]
信号名称描述iu_cmt_val执行单元发送指令执行完成信号iu_cmt_dst_val指令存在目的寄存器指示
iu_cmt_dst_index目的寄存器编码iu_cmt_dst_phy目的寄存器的架构寄存器编码iu_cmt_load_indexload指令在load缓存中的位置编码iu_cmt_load_valload指令执行完成指示iu_cmt_store_indexstore指令在store缓存中的位置编码iu_cmt_store_valstore指令执行完成指示iu_cmt_index指令在rob的位置编码iu_cmt_data执行单元返回数据
[0075]
比较重排序缓存的第iu_cmt_index项entry中dst_phy和iu_cmt_dst_phy,如果相等,那么将pending_val清为0。比较架构寄存器映射表的第lu_cmt_dst_index项entry中dst_phy和iu_cmt_dst_phy,如果相等,那么将pending_val清为0。将空闲物理寄存器管理队列的第lu_cmt_dst_phy项的pending_val清为0。将空闲load指令管理队列的第lu_cmt_load_index项的pending_val清为0。将空闲strore指令管理队列的第lu_cmt_store_index项的pending_val清为0。比较流水线中的物理寄存器,将数据iu_cmt_data forward到依赖的指令。并且物理寄存器管理队列的第lu_cmt_dst_phy项的数据更新为iu_cmt_data,此时该指令执行完成。
[0076]
除法指令只需要比较物理寄存器,也同时完成指令的提交.
[0077]
这里说明的设备数量和处理规模是用来简化本发明的说明的,对本发明的应用、修改和变化对本领域的技术人员来说是显而易见的。
[0078]
尽管本发明的实施方案已公开如上,但其并不仅限于说明书和实施方式中所列运用,它完全可以被适用于各种适合本发明的领域,对于熟悉本领域的人员而言,可容易地实现另外的修改,因此在不背离权利要求及等同范围所限定的一般概念下,本发明并不限于特定的细节和这里示出与描述的图例。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
