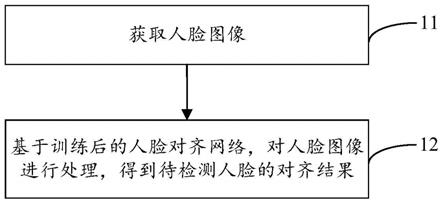
1.本技术涉及计算机视觉技术领域,具体涉及一种人脸对齐方法、训练方法、装置和存储介质。
背景技术:
2.现有的基于深度学习的人脸对齐方法,例如:eccn(extensive facial landmark)、dan-deep alignment network、深度卷积激活特征(deep convolutional activation feature,decafa)或du-net(quantized densely connected u-nets)等,在对人脸对齐网络进行模型训练的过程中,会因为训练图像的姿态角的分布不同而带来的样本不平衡问题,进而导致利用训练图像得到的模型的人脸对齐准确度较低。
技术实现要素:
3.本技术提供一种人脸对齐方法、训练方法、装置和存储介质,能够有效解决人脸对齐网络的训练样本不平衡问题,提高了人脸对齐的精度。
4.为解决上述技术问题,本技术采用的技术方案是:提供一种人脸对齐方法,该方法包括:获取人脸图像,人脸图像包括待检测人脸;基于训练后的人脸对齐网络,对人脸图像进行处理,得到待检测人脸的对齐结果;其中,训练后的人脸对齐网络是通过如下方式获得的:利用训练中的人脸对齐网络,对样本图像包含的人脸的关键点进行检测得到样本对齐结果,并对人脸的角度进行预测得到角度预测结果;基于角度预测结果,确定第一损失对应的惩罚权重;第一损失是人脸对齐网络的损失函数中对应样本对齐结果的损失;基于惩罚权重、第一损失以及第二损失,调整人脸对齐网络的模型参数,直至人脸对齐网络满足预设训练结束条件,得到训练后的人脸对齐网络;第二损失是损失函数中对应角度预测结果的损失。
5.为解决上述技术问题,本技术采用的另一技术方案是:提供一种人脸对齐装置,该人脸对齐装置包括互相连接的存储器和处理器,其中,存储器用于存储计算机程序,计算机程序在被处理器执行时,用于实现上述技术方案中的人脸对齐方法或人脸对齐网络的训练方法。
6.为解决上述技术问题,本技术采用的另一技术方案是:提供一种计算机可读存储介质,该计算机可读存储介质用于存储计算机程序,计算机程序在被处理器执行时,用于实现上述技术方案中的人脸对齐方法或人脸对齐网络的训练方法。
7.通过上述方案,本技术的有益效果是:在采用训练数据中的样本图像训练人脸对齐网络的过程中,利用人脸对齐网络检测样本图像中人脸的关键点得到样本对齐结果,且通过人脸对齐网络检测人脸的角度得到角度预测结果,并根据该角度预测结果来确定人脸对齐网络的损失函数中与样本对齐结果对应的第一损失的惩罚权重;然后基于第一损失、与角度预测结果对应的第二损失以及惩罚权重,计算出损失函数的值,以便调整人脸对齐网络的模型参数,最终得到一个训练后的人脸对齐网络;由于采用角度预测结果来确定第
shot multibox detector,ssd)或者多任务级联卷积网络(multitask cascaded convolutional network,mtcnn)等。
34.在其他实施方式中,在采用主网络对样本图像进行关键点检测处理,得到样本对齐结果之前,还可先对样本图像进行人脸检测处理,得到样本人脸框,然后对样本图像中样本人脸框对应的图像进行预处理,得到预处理后的样本图像,再将预处理后的样本图像输入主网络,以使得主网络对样本图像中人脸的关键点进行检测。
35.进一步地,预处理可包括图像裁剪、图像平移、图像旋转或者图像镜像等,如图3所示,可对如图3(a)所示的样本图像进行图像裁剪,例如:样本图像尺寸为640*480,可利用双线性插值将图像尺寸缩小,以将其裁剪为图像尺寸为112*112的图像,从而得到如图3(b)所示的裁剪后的图像,进行图像裁剪可降低输入至主网络的图像尺寸,大大减少主网络进行关键点检测时所需的参数数量以及计算量,能够优化训练速度和效果。或者,还可按照1:10的平移比例对裁剪后的人脸框进行图像平移,然后采用黑色像素补充平移后的留白位置;或者,还可对平移后的图像进行图像旋转或者图像镜像的操作,得到图3中最右侧所示的图像,图3(c)~图3(e)依次是镜像图、图像旋转图以及图像镜像后的旋转图,其中,图像旋转的角度一般在-30
°
~30
°
之间。
36.可以理解地,本实施例所提供的方案并不仅限于对人脸进行处理,还可以对其他目标(比如:车辆或行人)进行对齐,本实施例对此不作限定。
37.在本实施例中由于采用角度预测结果来确定第一损失的惩罚权重,能够对损失函数的值进行自适应调整,进而实现样本均衡,避免出现因某些因导致的样本不平衡问题;在实际使用时,可采用训练完的人脸对齐网络对人脸图像进行处理,得到人脸图像中的待检测人脸的对齐结果,实现人脸对齐的效果;由于在训练过程中采用了惩罚权重调整策略对损失函数中样本对齐结果的惩罚权重进行了调整,提高了对人脸对齐网络的训练效果,提高人脸对齐的精度,进而提升人脸对齐网络的性能。
38.请参阅图4,图4是本技术提供的人脸对齐网络的训练方法一实施例的流程示意图,该方法包括:
39.步骤41:利用训练中的人脸对齐网络,对样本图像包含的人脸的关键点进行检测得到样本对齐结果。
40.获取训练数据,该训练数据包括多张样本图像,在采用训练数据中的样本图像训练人脸对齐网络时,采用该人脸对齐网络检测样本图像中人脸的关键点,得到样本对齐结果,该样本对齐结果包括多个样本关键点,样本关键点为样本图像中人脸的关键点;具体地,主网络可对人脸的五官以及面部轮廓进行检测,例如:眼睛、眉毛、鼻子、嘴巴和面部轮廓等,从而得到多个样本关键点。
41.步骤42:利用训练中的人脸对齐网络,对样本图像包含的人脸的角度进行预测得到角度预测结果,并基于角度预测结果确定第一损失对应的惩罚权重。
42.采用人脸对齐网络对样本图像中人脸的角度进行预测,生成角度预测结果,以便利用该角度预测结果确定损失函数中第一损失对应的惩罚权重,进而调整此次训练的损失值,该第一损失是人脸对齐网络的损失函数中对应样本对齐结果的损失。
43.步骤43:基于惩罚权重、第一损失以及第二损失,调整人脸对齐网络的模型参数,直至人脸对齐网络满足预设训练结束条件,得到训练后的人脸对齐网络。
44.在获取到样本对齐结果、与样本对齐结果对应的惩罚权重以及角度预测结果后,可进行处理,以便生成当前训练损失;具体地,可对样本对齐结果对应的损失(即第一损失)与损失函数中对应角度预测结果的损失(即第二损失)进行加权求和,得到当前训练损失。
45.在获取到当前训练损失之后,可判断人脸对齐网络是否满足预设训练结束条件;如果人脸对齐网络不满足预设训练结束条件,则继续采用样本图像对人脸对齐网络进行训练,且调整人脸对齐网络的模型参数,直至人脸对齐网络满足预设训练结束条件。可以理解地,对人脸对齐网络的模型参数进行调整的操作与相关技术中的模型参数调整的操作类似,在此不再赘述。
46.在一具体的实施例中,预设训练结束条件包括:判断损失值是否收敛,即上一训练损失与当前训练损失的差值是否小于设定值,若上一训练损失与当前训练损失的差值小于设定值,则确定达到预设训练结束条件;判定当前训练损失是否小于预设损失值,该预设损失值为预先设置的损失阈值,若当前损失值小于预设损失值,则确定达到预设训练结束条件;训练次数达到设定值(例如:训练10000次);或者使用测试集进行测试时获得的准确率达到设定条件(例如:超过预设准确率)等,在此不进行限定。
47.本实施例所提供的技术方案中基于人脸的角度预测结果设置样本对齐结果对应的惩罚权重,从而调整此次训练的损失值,能够解决不同姿态角引起的样本数量不平衡的问题,提升模型训练的效果,从而保证人脸对齐网络的性能。
48.请参阅图5,图5是本技术提供的人脸对齐网络的训练方法另一实施例的流程示意图,该方法包括:
49.步骤51:从训练数据中获取样本图像。
50.步骤52:利用主网络对样本图像包含的人脸的关键点进行检测,并基于检测出的样本图像中人脸的关键点,得到样本对齐结果。
51.主网络可包括特征图提取层,可采用特征图提取层对样本图像进行特征提取处理,得到训练特征图。可以理解地,训练特征图为样本图像中人脸的关键点的特征图,训练特征图的数量与样本图像中待检测人脸的关键点(即样本关键点)的数量相同,例如:样本图像中存在68个样本关键点,对应的训练特征图便有68个。
52.在一具体的实施例中,如图6所示,特征图提取层可包括第一特征提取层、结构感知层以及第二特征提取层,采用第一特征提取层对样本图像进行特征提取处理,得到第二特征信息;采用结构感知层对第二特征信息进行处理,得到第三特征信息;采用第二特征提取层对第三特征信息进行特征提取处理,得到训练特征图。
53.第一特征提取层可包含卷积层以及池化层(图中未示出),其可对样本图像进行卷积以及池化处理,从而对样本图像进行初步的特征提取,以得到第二特征信息。结构感知层可利用图卷积的方式对第二特征信息进行处理,获取全局信息和样本关键点之间的结构性关系,从而得到第三特征信息,具体地,如图7所示,结构感知层可以为基于图形的全局推理网络(graph-based global reasoning networks),结构感知层可先将第二特征信息中的特征空间转换为图空间,然后再将图空间转换为特征空间,其中,x表示第二特征信息,y表示第三特征信息,本实施例可为以轻量级网络mobilev2为基础进行的改进,通过增加结构感知层,能够再保证神经网络的轻量化设计,不会增加模型的复杂度以及计算量的同时,获取全局信息和样本关键点之间的结构性关系,从而提升特征提取的深度。
54.进一步地,第二特征提取层可包含至少一个深度的特征融合模块(图6中示出了3个特征融合模块),第二特征提取层的处理过程如图8以及图9所示,图8为深度的特征融合模块与普通的卷积融合模块的对比图,其中,图8(a)为深度的特征融合模块,图8(b)为普通的卷积融合模块,“concat”为特征融合操作,图9为在卷积步长分别为1和2时,深度的特征融合模块(如图9(a)所示)与一般的轻量级网络mobilev2中的卷积模块(如图9(b)所示)的操作对比图,其中,pointwise为点的卷积,depthwise为深度的卷积,“conv(p*p)”为卷积核大小为p*p的卷积操作,“relu6”为激活操作,“add”为特征叠加操作。
55.本实施例为了使模型轻量级,采用了特征融合模块去构建了主网络,深度的特征融合模块采用在深度空间中将多尺度信息进行融合的策略,可在通道空间内获取更多的空间相关性信息,能够更充分地对样本关键点进行特征提取,得到样本关键点的训练特征图,不需要通过调整网络结构的深度或宽度的方式来提高模型的特征提取的性能,能够缩减模型的尺寸,同时能够大大降低模型复杂性;相对深度可分离卷积,不仅控制了模型的参数数量,而且能够获取更加丰富的特征信息,有助于提升模型性能。
56.在另一具体的实施例中,继续参阅图6,主网络还包括dsnt层(differentiable spatial to numerical transform layer),可在特征图提取层对样本图像进行特征提取处理,得到训练特征图后,将提取出的训练特征图输入至dsnt层,然后采用dsnt层对训练特征图进行转换处理,根据训练特征图得到对应关键点的位置坐标,以基于训练特征图达到定位的效果,得到样本对齐结果。
57.具体地,采用dsnt层对训练特征图进行正则化处理,得到正则化结果,然后基于训练特征图的坐标信息,计算出第一矩阵与第二矩阵,再分别计算正则化结果与第一矩阵以及第二矩阵之间的哈达玛积(hadamard product),得到第三矩阵与第四矩阵;最后基于第三矩阵与第四矩阵,得到样本关键点的坐标。通过对训练特征图进行正则化处理,然后再利用正则化结果对第一矩阵以及第二矩阵进行运算,能够防止过拟合,提高模型泛化能力。
58.基于训练特征图的坐标信息计算出第一矩阵与第二矩阵的步骤具体如下述公式所示:
59.x
i,j
=2*j-(n 1)/n 公式(1)
60.y
i,j
=2*i-(m 1)/m 公式(2)
61.其中,在公式(1)~(2)中,x
i,j
表示第一矩阵,y
i,j
表示第二矩阵,(i,j)为训练图的坐标信息,m和n表示训练特征图的分辨率大小,例如:训练特征图的分辨率为68*112,则m即为68,n即为112,分别将各个训练特征图的坐标以及分辨率代入上述公式(1)以及公式(2),便可得到各自对应的第一矩阵以及第二矩阵,然后再计算第一矩阵x
i,j
与第二矩阵y
i,j
分别与正则化结果的哈达玛积,从而分别得到第三矩阵以及第四矩阵,然后再将第三矩阵中的所有元素进行求和,将第四矩阵中的所有元素进行求和,得到最终的样本关键点的坐标。
62.具体地,样本关键点的坐标包括横坐标与纵坐标,可将第三矩阵中的所有元素进行求和,得到横坐标;将第四矩阵中的所有元素进行求和,得到纵坐标。正则化结果的数量与训练特征图的数量相同,若样本关键点为68个,则在特征图提取层提取出68个训练特征图时,可分别计算得到68个训练特征图分别对应的正则化结果,即68个正则化结果,然后将每个训练特征图对应的第一矩阵以及第二矩阵分别与68个正则化结果进行求哈达玛积计算,以得到分别包含68个元素的第三矩阵以及第四矩阵,然后再将第三矩阵中的68个元素
求和,得到该样本关键点对应的横坐标,将第四矩阵中的68个元素求和,得到该样本关键点对应的纵坐标。
63.步骤53:采用辅助网络对主网络输出的样本对齐结果进行处理,得到角度预测结果。
64.辅助网络输出的结果可包括角度预测结果与表情预测结果,主网络中的特征图提取层用于输出第一特征信息,可采用辅助网络基于第一特征信息对人脸的表情进行预测,得到表情预测结果,角度预测结果与表情预测结果分别为人脸的姿态角的预测结果以及表情的预测结果。可以理解地,在其他实施例中,辅助网络还可对样本的其他属性信息进行识别/分类,可实现多任务检测,能够辅助主网络进行关键点定位,从而提升主网络关键点定位的精确度。
65.进一步地,第一特征信息可为包含待检测人脸的二维图像,即二维的人脸图像,辅助网络可利用三维重建算法(例如:opencv软件中的pnp函数)将二维的人脸图像转换成三维图像,从而对三维图像进行分类得到角度预测结果,即该三维图像的姿态角(即欧拉角)。
66.在利用主网络输出样本关键的坐标以及辅助网络输出角度预测结果与表情预测结果之后,可利用对应的损失函数来计算本次训练所产生的当前训练损失,从而判断人脸对齐网络是否训练结束,计算当前训练损失的步骤如步骤54~步骤56所示:
67.步骤54:计算样本关键点与标签关键点之间的损失,得到第一损失。
68.训练数据包括与样本图像对应的标签关键点,标签关键点为样本图像中的参照关键点,可通过将主网络检测得到的样本关键点的坐标与标签关键点的坐标进行比较,以计算得到样本关键点与相应的标签关键点之间的损失,从而得到本次训练产生的定位误差,即第一损失。
69.步骤55:计算角度预测结果与姿态角标签之间的损失,得到第二损失。
70.训练数据还包括与样本图像对应的姿态角标签、表情标签,可分别计算姿态预测结果与姿态角标签的误差以及表情预测结果与表情标签的误差;具体地,计算角度预测结果与姿态角标签之间的误差,得到第二损失,同时计算表情预测结果与表情标签之间的误差,得到第三损失。
71.步骤56:基于第一损失与第二损失,计算出当前训练损失。
72.当前训练损失还包括第四损失,第四损失为训练特征图的正则化损失,具体地,可在获取训练特征图时得到训练特征图的正则化损失,然后对第一损失、第二损失、第三损失以及第四损失进行加权求和,从而得到当前训练损失,如下述公式所示:
[0073][0074]
其中,在公式(3)中,loss为当前训练损失,f(x)为第一损失,为第一损失的惩罚权重,g(y)为第二损失,h(z)为第三损失,μ1、μ2分别为第二损失与第三损失各自对应的惩罚权重,z
reg
为第四损失;具体地,可基于辅助结果确定样本对齐结果对应的惩罚权重,如图10所示,下面对基于角度预测结果与预设映射表,确定第一损失的惩罚权重的方法进行介绍:
[0075]
步骤61:将姿态角范围划分为多个子范围。
[0076]
在对人脸对齐网络进行训练过程中,存在样本不平衡的问题,具体体现在训练数据中的大姿态样本少,小姿态样本多,从而导致在网络训练时更侧重于对数量多的大姿态
样本的学习,而忽略了数量少的小姿态样本的学习,进而影响模型的泛化性,此时可按照姿态角的大小对样本对应结果进行加权设置,根据样本的姿态角对第一损失添加惩罚权重,从而解决样本不平衡问题,保证网络训练的效果。
[0077]
一般来说,大姿态样本为姿态角的绝对值在60
°
~90
°
范围内的样本,小姿态样本为姿态角的绝对值在0
°
~30
°
范围内的样本,姿态角的绝对值在30
°
~60
°
范围内的样本即为中间样本,则可对应将姿态角范围划分为三个子范围,即:0
°
~30
°
、30
°
~60
°
以及60
°
~90
°
。
[0078]
步骤62:对所有样本图像的姿态角进行统计,得到每个子范围对应的样本图像的数量。
[0079]
步骤63:基于子范围对应的样本图像的数量,设置子范围对应的惩罚权重,以构建预设映射表。
[0080]
预设映射表可包括子范围以及与子范围对应的惩罚权重,子范围对应的样本图像的数量越多,子范围对应的惩罚权重越小;具体地,可根据各个子范围的样本图像的数量比例来设置对应的惩罚权重,按照数量比例的反比来设置惩罚权重,例如:统计得到在所有样本图像中处于0
°
~30
°
子范围内的样本图像的数量为30个,在30
°
~60
°
子范围内的样本图像的数量为20个,在60
°
~90
°
子范围内的样本图像的数量为10个,即小姿态样本、中间样本以及大姿态样本的数量比例为3:2:1,则此时可选择设置小姿态样本的惩罚权重为1,中间样本的惩罚权重为2,大姿态样本的惩罚权重为3,可以理解地,具体的惩罚权重数值可根据实际的惩罚权重取值范围来进行设置,惩罚权重的数值范围还可为1~10、1~100或1~1000等,例如:在惩罚权重的数值范围为1~100时,还可对应设置小姿态样本的惩罚权重为10,中间样本的惩罚权重为20,大姿态样本的惩罚权重为30。
[0081]
步骤64:将角度预测结果与预设映射表进行匹配,得到第一损失的惩罚权重。
[0082]
第一损失的惩罚权重即为角度预测结果对应的惩罚权重,将角度预测结果与预设映射表机型进行匹配,能够得到第一损失对应的惩罚权重,例如:样本图像的角度预测结果为40
°
,则根据预设映射表中对40
°
进行匹配,可得到对应的惩罚权重为2,即设置为2。
[0083]
步骤57:基于当前训练损失判断人脸对齐网络是否满足预设训练结束条件。
[0084]
若人脸对齐网络不满足预设训练结束条件,则表明此时的人脸对齐网络的性能不符合要求,此时可调整人脸对齐网络的模型参数,并继续利用样本图像对人脸对齐网络进行训练,即返回从训练数据中获取样本图像的步骤,直至人脸对齐网络满足预设训练结束条件。
[0085]
步骤58:若人脸对齐网络满足预设训练结束条件,则得到训练后的人脸对齐网络。
[0086]
若人脸对齐网络满足预设训练结束条件,说明人脸对齐网络的训练完成,此时停止训练,得到训练后的人脸对齐网络。
[0087]
本实施例在轻量级网络mobilev2的基础上,在进行样本关键点定位的主网络中增加结构感知层、深度的特征融合模块以及dsnt层,利用结构感知层获取全局信息和样本关键点之间的空间结构关系;通过设置深度的特征融合模块能够多尺度地对样本图像进行特征提取,不仅能够缩减模型的尺寸(即模型为轻量级模型),还能够在通道空间内获取丰富的特征信息和空间相关性;通过dsnt层将生成的训练特征图转换为对应的样本关键点的坐标,使得模型可微分(即本实施例的人脸对齐网络为全微分模型),由于全微分模型利用输
入直接优化人脸的关键点的位置坐标,而不是对热图进行优化,避免了人脸不一致造成的误差;同时保持特征图回归的空间泛化能力,有助于获得更好的定位效果,并且是在小分辨率的特征图上使用,可以减少内存的占用和加速推理的速度,且优化人脸和所求人脸一致,不存在误差下界的问题;另外,设置辅助网络对样本图像的姿态角以及表情等属性信息进行检测,能够实现多任务检测,同时辅助主网络的关键点定位,使得样本关键点的定位更加精准;此外,基于姿态角预测结果设置对样本对齐结果对应的惩罚权重,通过样本加权策略解决不同姿态角的样本数量不平衡的问题,提升模型训练的效果,从而保证人脸对齐网络的性能。
[0088]
请参阅图11,图11是本技术提供的人脸对齐装置一实施例的结构示意图,人脸对齐装置110包括互相连接的存储器111和处理器112,存储器111用于存储计算机程序,计算机程序在被处理器112执行时,用于实现上述实施例中的人脸对齐方法或上述实施例中的人脸对齐网络的训练方法。
[0089]
本实施例中的方案在模型训练时,采用样本加权策略和对应的损失设计,有效缓解了样本不平衡的问题;还采用了深度的特征融合策略,使得模型不仅轻量级,而且能够获取丰富的特征信息和空间相关性,更加适合用于构建轻量级网络模型;此外,对于轻量级网络来说,由于轻量级网一般比较浅,缺乏人脸关键点之间的信息,本方案在轻量级网络的靠前层位置添加结构感知层,能够获取人脸关键点之间的联系并融合到网络中;另外地,相关技术中的轻量级网络由于模型尺度小,定位精度相对大模型来说会有损失,为了兼顾基于特征图回归的模型的高泛化性的优势,并克服特征图的缺点,本方案在轻量级网络中加入dsnt层,使得模型可微,且模型所占用的存储减小。
[0090]
请参阅图12,图12是本技术提供的计算机可读存储介质一实施例的结构示意图,计算机可读存储介质120用于存储计算机程序121,计算机程序121在被处理器执行时,用于实现上述实施例中的人脸对齐方法或上述实施例中的人脸对齐网络的训练方法。
[0091]
计算机可读存储介质120可以是服务端、u盘、移动硬盘、只读存储器(rom,read-only memory)、随机存取存储器(ram,random access memory)、磁碟或者光盘等各种可以存储程序代码的介质。
[0092]
在本技术所提供的几个实施方式中,应该理解到,所揭露的方法以及设备,可以通过其它的方式实现。例如,以上所描述的设备实施方式仅仅是示意性的,例如,模块或单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。
[0093]
作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施方式方案的目的。
[0094]
另外,在本技术各个实施方式中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
[0095]
以上所述仅为本技术的实施例,并非因此限制本技术的专利范围,凡是利用本技术说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技
术领域,均同理包括在本技术的专利保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。