1.本发明涉及人工智能技术驱动的计算机视觉技术领域,尤其涉及一种应用于航拍视频中的地面目标跟踪方法。
背景技术:
2.视觉目标跟踪是计算机视觉领域的基本任务之一,根据需要跟踪目标数量的不同,通常被分为多目标跟踪和单目标跟踪。多目标跟踪通常只针对特定的若干类物体,如车辆、行人等,即待跟踪的目标类别是固定的;而在通用单目标跟踪任务中,待跟踪的目标类别可以是任意的。
3.通用单目标跟踪任务的输入是持续性在线实时输入的帧序列或者一段离线缓存的视频。只需要在配备摄像头的端设备启动时或者离线视频的第一帧选定待跟踪的目标(常用的表示形式是矩形边界框),通用单目标跟踪算法将以边界框的形式,持续稳定高效地给出后续帧中待跟踪目标的精确位置。
4.tracking-by-detection机制使用目标检测的机制实施目标跟踪任务,通常被用于多目标跟踪领域。具体来说,首先使用一个目标检测方法检测出当前帧中所有目标,然后使用一种目标关联策略(比如:匈牙利比配算法)将当前帧和前一帧的目标关联起来。这种机制同样可以应用于通用单目标跟踪领域。对于给定的实时输入的帧序列或者一段离线缓存的视频的第一帧,以及对应的待跟踪目标的边界框,tracking-by-detection机制以待跟踪目标(为统一输入尺寸,通常会附加一定比例的邻近环境信息)为模板图像,在当前帧或者当前帧的某个局部区域内依次和每一块大小和模板图像相同的子区域匹配,匹配相似度最高的子区域即为待跟踪目标的位置。
5.siamfc(siamese fully-convolutional networks)是一种基于孪生神经网络的通用单目标跟踪方法,其主要思想是基于tracking-by-detection框架。首先,使用一个相同的特征空间嵌入(feature space embedding)把模板图像z和候选图像x映射到高维特征空间,分别表示为和然后,使用另一个相似性度量函数g计算出和的相似性,形式化表示如式(101)所示:
[0006][0007]
式(101)中,z表示模板图像,x表示候选图像,表示特征空间嵌入,为模板图像z的高维特征空间表示,为候选图像x的高维特征空间表示,g表示相似性度量函数,f表示整个通用单目标跟踪算法,即siamfc。
[0008]
在跟踪过程中,siamfc以前一帧的跟踪目标边界框为中心,加上一定的邻域空间信息,作为当前帧的搜索区域。然后将模板图像z的高维特征空间表示以滑窗(sliding window)的方式与搜索区域内每一个空间位置的候选图像x的高维特征空间表示
进行相似度度量,即执行式(101)。所有相似度度量结果组成一个置信分数图。分数越高,表示模板图像z和搜索区域中对应的候选图像x越相似。置信分数图中最大值的位置相对该图中心位置的偏移量,乘以特征空间嵌入网络的最大感受野,即为待跟踪目标的中心从前一帧到当前帧的位移。对于待跟踪目标的尺度估计,siamfc使用预定义的比例对搜索区域进行缩放,然后对不同尺度的搜索区域执行上述步骤。所有置信分数图的最大值中的最大者对应的搜索区域缩放比例,即为最终跟踪边界框的缩放比例。然而,预定义的缩放比例难以覆盖真实跟踪场景中由相机焦距、目标快速运动等因素引起的目标尺度变化。
[0009]
基于上述问题,在siamfc的基础上,siamrpn借鉴目标检测方法faster r-cnn,把rpn(region proposal network)思想引入到通用单目标跟踪领域。siamrpn对置信分数图中每一个空间位置预定义若干个不同尺度和不同长宽比的锚框(anchor box),使用卷积神经网络预测每一个锚框和待跟踪目标边界框的中心位置偏移和长宽偏差。siamrpn方法使得基于孪生神经网络的通用单目标跟踪方法的跟踪准确率得到了非常大的提高。
[0010]
由于siamfc和siamrpn使用的深度特征空间嵌入都是alexnet,网络层数少,深度较浅,特征表示能力不够丰富。为充分挖掘输入信息,使高维特征表示更加丰富,siamrpn 方法基于siamrpn架构,使用resnet-50作为深度特征空间嵌入网络。在resnet-50中,由于感受野变化大,因此不同深度的特征表示的意义更加丰富。较浅层的特征主要关注细节信息,如颜色、形状、纹理等,这些信息对于目标定位非常重要;而较深层的特征更加关注目标的语义信息,这些信息在目标发生运动模糊、大幅度形变时非常有帮助。因此,siamrpn 分别使用三个rpn模块接收来自resnet-50网络的block2、block3和block4的特征,最终通过线性加权平均的方式组合三个rpn模块的输出作为最终输出。然而,在航拍视频场景中,通常待跟踪目标的尺度比较小,空间分辨率低,判别性特征不足。siamrpn 使用离线训练的加权参数,难以自适应地强化目标的判别性特征。
[0011]
由于siamrpn和siamrpn 的rpn模块使用了大量的预定义的锚框,而这些锚框的尺度和长宽比等先验信息,既不容易获得,也难以准确表征任意应用场景。因此,基于siamfc,siamfc 无需依赖锚框,而是直接使用置信分数图的每一个空间位置回归该位置到目标边界框四个边距的距离。然而,由于siamfc 方法只利用了特征空间嵌入网络的最深层特征,而直接丢弃了较浅层的特征,使得该方法对小目标跟踪的性能欠佳。虽然深层特征的语义信息更加丰富,但最深层特征必然会丢失一些细节信息。而航拍数据中的目标通常比较小(相对整张图像),细节信息对于小目标的判别十分重要。
[0012]
由于航拍视频场景中的目标通常较小,外观、形状、纹理等细节信息容易被丢弃,因此待跟踪目标容易受其他与之特征相似的噪声或干扰物影响,导致跟踪器发生跟踪漂移。另外,基于运动平滑性假设,即目标在相邻两帧之间的位移差较小,上述基于孪生神经网络的通用单目标跟踪方法,采用局部搜索的方法确定目标在当前帧的位置,即当前帧的目标搜索区域是基于前一帧的跟踪边界框加上一定比例的上下文信息得到的,而不是直接使用整张图像作为搜索区域。由于航拍视野范围大,而真正感兴趣目标的分辨率相对偏小,因此导致目标搜索区域非常小,一旦真实待跟踪目标因噪声或者干扰物(和待跟踪目标相似的目标)影响发生跟踪漂移(算法跟踪边界框和待跟踪目标的真实边界框不完全重合)甚至跟踪丢失(算法跟踪边界框和待跟踪目标的真实边界框的重合度为0),后续帧的搜索区域将可能无法包含待跟踪目标,导致跟踪彻底失败。
技术实现要素:
[0013]
有鉴于此,本发明提供了一种应用于航拍视频中的地面目标跟踪方法,用以提高通用单目标跟踪方法在航拍视频场景中的跟踪性能。
[0014]
本发明提供的一种应用于航拍视频中的地面目标跟踪方法,包括如下步骤:
[0015]
s1:将siamfc 的特征空间嵌入网络由googlenet更改为resnet;
[0016]
s2:将搜索区域图像x输入特征空间嵌入网络resnet,将resnet的第2个block输出的深度特征输入到第一特征金字塔网络的最低层,将resnet的第3个block输出的深度特征输入到第一特征金字塔网络的中层,将resnet的第4个block输出的深度特征输入到第一特征金字塔网络的最高层;第一特征金字塔网络对输入到各层的深度特征进行处理后,在第一特征金字塔网络的最低层输出搜索区域图像x的深度特征在第一特征金字塔网络的中层输出搜索区域图像x的深度特征在第一特征金字塔网络的最高层输出搜索区域图像x的深度特征
[0017]
s3:将模板图像z输入和步骤s2中结构相同且参数共享的特征空间嵌入网络resnet,将resnet的第2个block输出的深度特征输入到和步骤s2中结构相同但参数不共享的第二特征金字塔网络的最低层,将resnet的第3个block输出的深度特征输入到第二特征金字塔网络的中层,将resnet的block4输出的深度特征输入到第二特征金字塔网络的最高层;第二特征金字塔网络对输入到各层的深度特征进行处理后,在第二特征金字塔网络的最低层输出模板图像z的深度特征在第二特征金字塔网络的中层输出模板图像z的深度特征在第二特征金字塔网络的最高层输出模板图像z的深度特征
[0018]
s4:将深度特征与组合后输入到第一跟踪头部网络中,将深度特征与组合后输入到第二跟踪头部网络中,将深度特征与组合后输入到第三跟踪头部网络中;其中,所述第一跟踪头部网络、所述第二跟踪头部网络和所述第三跟踪头部网络结构相同但参数不共享,三个跟踪头部网络均与siamfc 的跟踪头部网络的结构相同;
[0019]
s5:每个跟踪头部网络接收对应的深度特征和作为输入,输出第一分类置信分数图和目标边界框回归响应图;其中,k∈{2,3,4};
[0020]
s6:选择三个跟踪头部网络输出的第一分类置信分数图中分类置信分数最大值所在位置,目标边界框回归响应图在该位置的向量为待跟踪目标的边界框预测结果。
[0021]
在一种可能的实现方式中,在本发明提供的上述应用于航拍视频中的地面目标跟踪方法中,步骤s5,每个跟踪头部网络接收对应的深度特征和作为输入,输出第一分类置信分数图和目标边界框回归响应图,具体包括:
[0022]
每个跟踪头部网络包括用于空间位置分类的分类分支和用于目标边界框回归的回归分支,将组合后的深度特征和分别输入对应的跟踪头部网络的分类分支和回归分支;
[0023]
对于分类分支,使用一个结构相同但参数不共享的多层卷积层分别处理深度特征和后做互相关操作,将互相关操作的结果分别输送到分类分支的分类子分支和中心度子分支中;分类子分支使用一个1
×
1卷积处理互相关操作的结果,输出第二分类置信分数图;中心度子分支使用一个1
×
1卷积处理互相关操作的结果,输出每一个空间位置的中心度置信概率图;在测试阶段,将中心度置信概率图作为权重与第二分类置信分数图相乘,生成第一分类置信分数图;
[0024]
对于回归分支,使用一个结构相同但参数不共享的多层卷积层分别处理深度特征和后做互相关操作;回归分支使用一个1
×
1卷积处理互相关操作的结果,输出目标边界框回归响应图;
[0025]
步骤s5形式化表示为:
[0026][0027]
其中,表示特征空间嵌入网络resnet,表示模板图像z经过特征空间嵌入网络resnet的前k个block和第二特征金字塔网络处理后的深度特征,表示模板图像x经过特征空间嵌入网络resnet的前k个block和第一特征金字塔网络处理后的深度特征,k表示特征空间嵌入网络resnet的索引编号;i表示跟踪头部网络的索引编号,i∈{1,2,3},ζi表示第i个跟踪头部网络;fi表示从输入到第i组输出的映射,数学化表示为:
[0028][0029]
其中,和分别表示第i个跟踪头部网络输出的第一分类置信分数图和目标边界框回归响应图,和分别表示第i个跟踪头部网络输出结果的高和宽。
[0030]
在一种可能的实现方式中,在本发明提供的上述应用于航拍视频中的地面目标跟踪方法中,步骤s6,选择三个跟踪头部网络输出的第一分类置信分数图中分类置信分数最大值所在位置,目标边界框回归响应图在该位置的向量为待跟踪目标的边界框预测结果,具体包括:
[0031]
选择三个跟踪头部网络输出的第一分类置信分数图中分类置信分数最大值所在位置,形式化表示为:
[0032][0033]
其中,p表示所有分类置信分数最大值所在位置,
[0034]
目标边界框回归响应图在该位置的向量为待跟踪目标的边界框预测结果,形式化表示为:
[0035][0036]
其中,表示第p1个跟踪头部网络输出的目标边界框回归响应图中第p2行第p3列的向量b,p1∈{1,2,3},
[0037]
在一种可能的实现方式中,在本发明提供的上述应用于航拍视频中的地面目标跟踪方法中,步骤s2中,搜索区域大小自适应调整策略,具体包括:
[0038]
搜索区域图像为航拍视频中每一帧图像的一部分;在跟踪时,设置初始的搜索区域图像的大小为d0,以三个跟踪头部网络的第一分类置信分数图中分类置信分数的最大值代表对航拍视频中当前帧图像的跟踪质量θ,设置稳定阈值τ1、丢失阈值τ2以及跟踪质量类别数目m,m=3;则下一帧图像中的搜索区域图像的大小为:
[0039][0040][0041]
其中,μ表示特征空间嵌入网络resnet的最大感受野大小的3倍,函数max表示取集合中元素的最大值。
[0042]
本发明提供的上述应用于航拍视频中的地面目标跟踪方法,属于通用单目标跟踪方法。将siamfc 的特征空间嵌入网络由googlenet更改为resnet;将搜索区域图像x和模板图像z输入resnet,提取搜索区域图像x和模板图像z的深度特征;使用两个特征金字塔网络强化搜索区域图像x和模板图像z的深度特征;将深度特征输入跟踪头部网络,输出第一分类置信分数图和目标边界框回归响应图;选择第一分类置信分数图中分类置信分数最大值所在位置,目标边界框回归响应图在该位置的向量为待跟踪目标的边界框预测结果。在提取深度特征的过程中,利用特征金字塔网络,自适应地融合特征空间嵌入网络的浅层和深层特征,使得特征表示既有丰富的表观、形状和纹理等细节信息,也有强大的语义信息,从而可以达到强化小目标的判别性特征表示的效果,进而可以避免由于航拍视野范围大而目标偏小所导致的跟踪漂移甚至跟踪丢失等问题。并且,提出一种搜索区域大小自适应调整策略,用于增强跟踪器抵抗跟踪丢失风险能力。多方面评测的实验结果表明,本发明提供的上述应用于航拍视频中的地面目标跟踪方法,可以提高通用单目标跟踪方法在航拍视频场景中的跟踪性能。
附图说明
[0043]
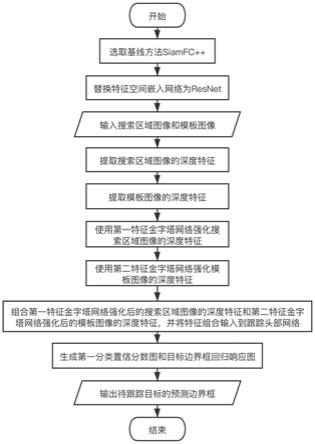
图1为本发明实施例1提供的一种应用于航拍视频中的地面目标跟踪方法的流程图;
[0044]
图2为本发明实施例1提供的一种应用于航拍视频中的地面目标跟踪方法的整体框架图;
[0045]
图3为本发明实施例1中使用的特征金字塔网络的结构框架图;
[0046]
图4为本发明实施例1中搜索区域大小自适应调整策略的流程图。
具体实施方式
[0047]
下面将结合本发明实施方式中的附图,对本发明实施方式中的技术方案进行清楚、完整的描述,显然,所描述的实施方式仅仅是作为例示,并非用于限制本发明。
[0048]
本发明提供的一种应用于航拍视频中的地面目标跟踪方法,包括如下步骤:
[0049]
s1:将siamfc 的特征空间嵌入网络由googlenet更改为resnet;
[0050]
s2:将搜索区域图像x输入特征空间嵌入网络resnet,将resnet的第2个block输出的深度特征输入到第一特征金字塔网络(feature pyramid network,fpn)的最低层,将resnet的第3个block输出的深度特征输入到第一特征金字塔网络的中层,将resnet的第4个block输出的深度特征输入到第一特征金字塔网络的最高层;第一特征金字塔网络对输入到各层的深度特征进行处理后,在第一特征金字塔网络的最低层输出搜索区域图像x的深度特征在第一特征金字塔网络的中层输出搜索区域图像x的深度特征在第一特征金字塔网络的最高层输出搜索区域图像x的深度特征
[0051]
s3:将模板图像z输入和步骤s2中结构相同且参数共享的特征空间嵌入网络resnet,将resnet的第2个block输出的深度特征输入到和步骤s2中结构相同但参数不共享的第二特征金字塔网络的最低层,将resnet的第3个block输出的深度特征输入到第二特征金字塔网络的中层,将resnet的block4输出的深度特征输入到第二特征金字塔网络的最高层;第二特征金字塔网络对输入到各层的深度特征进行处理后,在第二特征金字塔网络的最低层输出模板图像z的深度特征在第二特征金字塔网络的中层输出模板图像z的深度特征在第二特征金字塔网络的最高层输出模板图像z的深度特征
[0052]
s4:将深度特征与组合后输入到第一跟踪头部网络中,将深度特征与组合后输入到第二跟踪头部网络中,将深度特征与组合后输入到第三跟踪头部网络中;其中,第一跟踪头部网络、第二跟踪头部网络和第三跟踪头部网络结构相同但参数不共享,三个跟踪头部网络均与siamfc 的跟踪头部网络的结构相同;
[0053]
s5:每个跟踪头部网络接收对应的深度特征和作为输入,输出第一分类置信分数图和目标边界框回归响应图;其中,k∈{2,3,4};
[0054]
s6:选择三个跟踪头部网络输出的第一分类置信分数图中分类置信分数最大值所在位置,目标边界框回归响应图在该位置的向量为待跟踪目标的边界框预测结果。
[0055]
下面通过两个具体的实施例对本发明提供的上述应用于航拍视频中的地面目标跟踪方法的具体实施进行详细说明。
[0056]
实施例1:流程图如图1所示,整体框图如图2所示。
[0057]
第一步:选取siamfc 通用单目标跟踪方法作为基线方法,将siamfc 的特征空间嵌入网络由googlenet更改为resnet。
[0058]
第二步:将搜索区域图像x输入特征空间嵌入网络resnet,使用特征空间嵌入网络resnet提取搜索区域图像x的深度特征,然后使用第一特征金字塔网络处理搜索区域图像x的深度特征。
[0059]
具体地,将resnet的第2个block输出的深度特征输入到第一特征金字塔网络的最低层,将resnet的第3个block输出的深度特征输入到第一特征金字塔网络的中层,将resnet的第4个block输出的深度特征输入到第一特征金字塔网络的最高层。如图3所示,在第一特征金字塔网络中,三层输入的特征均使用1
×
1卷积把通道数调整为256,分别表示为为256,分别表示为和已知resnet较深层的深度特征相比于较浅层的深度特征具有更强的语义信息,而resnet较浅层的深度特征相比于较深层的深度特征具有更强的细节信息,因此,输入到第一特征金字塔网络的最高层且经通道数调整后的深度特征会经过一个上采样模块,分辨率扩大为原来的2倍,再与输入到第一特征金字塔网络的中层且经通道数调整后的深度特征融合,得到深度特征同样地,融合后得到的深度特征会经过另一个上采样模块,分辨率扩大为原来的2倍,再与输入到第一特征金字塔网络的最低层且经通道数调整后的深度特征融合,得到深度特征最后,在第一特征金字塔网络的最低层输出深度特征在第一特征金字塔网络的中层输出深度特征在第一特征金字塔网络的最高层输出输入到第一特征金字塔网络的最高层且经通道数调整后的深度特征表示为
[0060]
第三步:将模板图像z输入和步骤s2中结构相同且参数共享的特征空间嵌入网络resnet,使用特征空间嵌入网络resnet提取模板图像z的深度特征,然后使用第二特征金字塔网络处理模板图像z的深度特征。
[0061]
具体地,将resnet的第2个block输出的深度特征输入到和步骤s2中结构相同但参数不共享的第二特征金字塔网络的最低层,将resnet的第3个block输出的深度特征输入到第二特征金字塔网络的中层,将resnet的block4输出的深度特征输入到第二特征金字塔网络的最高层。如图3所示,在第二特征金字塔网络中,三层输入的特征均使用1
×
1卷积把通道数调整为256,分别表示为和已知resnet较深层的深度特征相比于较浅层的深度特征具有更强的语义信息,而resnet较浅层的深度特征相比于较深层的深度特征具有更强的细节信息,因此,输入到第二特征金字塔网络的最高层且经通道数调整后的深度特征会经过一个上采样模块,分辨率扩大为原来的2倍,再与输入到第一特征金字塔网络的中层且经通道数调整后的深度特征融合,得到深度特征同样地,融合后得到的深度特征会经过另一个上采样模块,分
辨率扩大为原来的2倍,再与输入到第一特征金字塔网络的最低层且经通道数调整后的深度特征融合,得到深度特征最后,在第二特征金字塔网络的最低层输出模板图像z的深度特征在第二特征金字塔网络的中层输出模板图像z的深度特征在第二特征金字塔网络的最高层输出输入到第一特征金字塔网络的最高层且经通道数调整后的深度特征表示为深度特征
[0062]
第四步:将深度特征与组合后输入到第一跟踪头部(tracking head)网络中,将深度特征与组合后输入到第二跟踪头部网络中,将深度特征与组合后输入到第三跟踪头部网络中;其中,第一跟踪头部网络、第二跟踪头部网络和第三跟踪头部网络结构相同但参数不共享,三个跟踪头部网络均与siamfc 的跟踪头部网络的结构相同,如图2中大括号所示出的结构。
[0063]
第五步:每个跟踪头部网络接收对应的深度特征和作为输入,输出第一分类置信分数图和目标边界框回归响应图。
[0064]
具体地,每个跟踪头部网络包括用于空间位置分类的分类分支和用于目标边界框回归的回归分支,将组合后的深度特征和分别输入对应的跟踪头部网络的分类分支和回归分支。例如,将组合后的深度特征和分别输入第一跟踪头部网络的分类分支和回归分支,将组合后的深度特征和分别输入第二跟踪头部网络的分类分支和回归分支,将组合后的深度特征和分别输入第三跟踪头部网络的分类分支和回归分支。
[0065]
对于分类分支,使用一个结构相同但参数不共享的多层卷积层分别处理深度特征和后做互相关操作,将互相关操作的结果分别输送到分类分支的分类子分支和中心度子分支中;分类子分支使用一个1
×
1卷积处理互相关操作的结果,输出第二分类置信分数图;中心度子分支使用一个1
×
1卷积处理互相关操作的结果,输出每一个空间位置的中心度置信概率图;在测试阶段,将中心度置信概率图作为权重与第二分类置信分数图相乘,生成第一分类置信分数图。
[0066]
对于回归分支,使用一个结构相同但参数不共享的多层卷积层分别处理深度特征和后做互相关操作;回归分支使用一个1
×
1卷积处理互相关操作的结果,输出目标边界框回归响应图。
[0067]
上述过程形式化表示为:
[0068][0069]
其中,表示特征空间嵌入网络resnet,表示模板图像z经过特征空间嵌入
网络resnet的前k个block和第二特征金字塔网络处理后的深度特征,表示模板图像x经过特征空间嵌入网络resnet的前k个block和第一特征金字塔网络处理后的深度特征,k表示特征空间嵌入网络resnet的索引编号;i表示跟踪头部网络的索引编号,i∈{1,2,3},ζi表示第i个跟踪头部网络;fi表示从输入到第i组输出的映射,数学化表示为:
[0070][0071]
其中,和分别表示第i个跟踪头部网络输出的第一分类置信分数图和目标边界框回归响应图,和分别表示第i个跟踪头部网络输出结果的高和宽。
[0072]
第六步:选择三个跟踪头部网络输出的第一分类置信分数图中分类置信分数最大值所在位置,目标边界框回归响应图在该位置的向量为待跟踪目标的边界框预测结果。
[0073]
具体地,选择三个跟踪头部网络输出的第一分类置信分数图中分类置信分数最大值所在位置,形式化表示为:
[0074][0075]
其中,p表示所有分类置信分数最大值所在位置,
[0076]
目标边界框回归响应图在该位置的向量为待跟踪目标的边界框预测结果,形式化表示为:
[0077][0078]
其中,表示第p1个跟踪头部网络输出的目标边界框回归响应图中第p2行第p3列的向量b,p1∈{1,2,3},
[0079]
综上,为本发明实施例1提供的一种应用于航拍视频中的地面目标跟踪方法的具体实施过程,是一套具有强判别能力的小目标感知的通用单目标跟踪模型框架。
[0080]
实施例2:实施例1 搜索区域大小自适应调整策略。
[0081]
首先需要说明的是,搜索区域图像为航拍视频中每一帧图像的一部分。本发明实施例2是在本发明实施例1提供的上述应用于航拍视频中的地面目标跟踪方法的基础上,再提出一种搜索区域大小自适应调整策略,如图4所示,具体可以采用如下方式:在跟踪时,设置初始的搜索区域图像的大小为d0,以三个跟踪头部网络的第一分类置信分数图中分类置信分数的最大值代表对航拍视频中当前帧图像的跟踪质量θ,设置稳定阈值τ1、丢失阈值τ2以及跟踪质量类别数目m;具体地,当θ≥τ1时,表示当前帧图像的跟踪结果是“稳定可靠的”,因此,下一帧图像无需扩大搜索区域大小;当θ《τ2时,表示当前帧图像的跟踪结果是“丢失的”,即预测的目标边界框已完全偏离真实的目标边界框,需要使用尽可能大的搜索区域,以确保下一帧图像可以找回待跟踪目标;当τ2≤θ《τ1时,表示当前帧图像的跟踪结果是“不完全可靠的”,预测的目标边界框已发生一定幅度的跟踪漂移,为了防范跟踪丢失的风险,下一帧图像可以按照“自适应增长策略(即)”扩大搜索区域大小。综上,下一帧图像中的搜索区域图像的大小可以形式化表示为:
[0082][0083][0084]
其中,μ表示特征空间嵌入网络resnet的最大感受野大小的3倍,函数max表示取集合中元素的最大值。
[0085]
为了更好地验证本发明实施例1和实施例2的有效性,下面利用实际测试结合上述两个实施例进行描述,其中的测试过程相当于实际应用中的跟踪过程,测试跟踪视频相当于实际应用中在线实时输入的帧序列或者离线缓存的视频。
[0086]
在目标跟踪领域,一般利用uav123数据集对跟踪质量进行评价。uav123是一个大规模航拍视频单目标跟踪数据集,它包括123个高清无人机航拍视频,平均每个视频长度为915帧,数据集总帧数量超过100,000。该数据集覆盖了行人、小汽车、大卡车、自行车、船只及建筑等多种常见类别,涵盖了实际应用中大多数应用场景,因此,基于该数据集的评测指标,具有很强的泛化性和通用性。具体地,该数据集对目标跟踪方法的主要评价指标是成功图的曲线覆盖面积(success plot area under curve,success auc)。success auc的数值范围为[0,1],success auc的数值越大,表示被评测的目标跟踪方法的鲁棒性越强,实际应用价值越高。
[0087]
下面基于uav123数据集,对比现有的siamfc 方法、本发明实施例1、搜索区域大小自适应调整策略以及本发明实施例2的success auc指标,来验证本发明的两个技术点(1、具有强判别能力的小目标感知的通用单目标跟踪模型框架,即本发明实施例1;2、本发明实施例2中的搜索区域大小自适应调整策略)的有效性。如表1所示,siamfc 方法的success auc指标为0.631;若仅使用本发明的技术点1,一套具有强判别能力的小目标感知的通用单目标跟踪模型框架(即本发明实施例1),success auc指标可以达到0.660,超出siamfc 方法2.9个点;若仅使用本发明的技术点2,搜索区域大小自适应调整策略,设置初始搜索区域大小d0=447,τ1=0.8,τ2=0.4,m=3,success auc指标可以达到0.646,超过siamfc 方法1.5个点;综合本发明的两个技术点(即本发明实施例2),success auc指标可达到0.672,超过siamfc 方法4.1个点;这充分验证了本发明两个技术点的有效性。
[0088]
表1
[0089][0090]
下面基于uav123数据集,对比本发明实施例2提供的上述应用于航拍视频中的地
面目标跟踪方法与现有的siamrpn方法、siamrpn 方法和siamfc 方法的success auc指标,如表2所示,本发明实施例2提供的上述用于航拍视频中的地面目标跟踪方法,在uav123数据集上的success auc指标为0.672,超过了现有的siamrpn方法、siamrpn 方法和siamfc 方法,这表明本发明实施例2提供的上述用于航拍视频中的地面目标跟踪方法具有更强的有效性和通用性。
[0091]
表2
[0092][0093]
本发明提供的上述应用于航拍视频中的地面目标跟踪方法,属于通用单目标跟踪方法。将siamfc 的特征空间嵌入网络由googlenet更改为resnet;将搜索区域图像x和模板图像z输入resnet,提取搜索区域图像x和模板图像z的深度特征;使用两个特征金字塔网络强化搜索区域图像x和模板图像z的深度特征;将深度特征输入跟踪头部网络,输出第一分类置信分数图和目标边界框回归响应图;选择第一分类置信分数图中分类置信分数最大值所在位置,目标边界框回归响应图在该位置的向量为待跟踪目标的边界框预测结果。在提取深度特征的过程中,利用特征金字塔网络,自适应地融合特征空间嵌入网络的浅层和深层特征,使得特征表示既有丰富的表观、形状和纹理等细节信息,也有强大的语义信息,从而可以达到强化小目标的判别性特征表示的效果,进而可以避免由于航拍视野范围大而目标偏小所导致的跟踪漂移甚至跟踪丢失等问题。并且,提出一种搜索区域大小自适应调整策略,用于增强跟踪器抵抗跟踪丢失风险能力。多方面评测的实验结果表明,本发明提供的上述应用于航拍视频中的地面目标跟踪方法,可以提高通用单目标跟踪方法在航拍视频场景中的跟踪性能。
[0094]
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
