用于地层的渗透率的监督学习的系统和方法
1.相关申请的交叉引用
2.本技术要求2019年3月8日提交的美国临时申请号62/815,714和2019年3月11日提交的美国临时申请号62/816,566的权益;这两个申请的内容在此引入作为参考。
技术领域
3.本公开涉及地层渗透率的监督学习,更具体地,涉及用于地层渗透率的监督学习的系统和方法。
背景技术:
4.在评价储层时,渗透率是地质岩层(也称为地层)的一个重要的必需岩石物理参数。具体而言,准确确定渗透率对于了解储层的价值非常重要。此外,它是预测油气产量的储层模型中的重要输入。虽然已经开发了多种利用不同测井和岩心测量来确定渗透率的方法,但围绕数据异方差的问题仍然是一个挑战。
技术实现要素:
5.提供本发明内容是为了介绍将在下面的详细描述中进一步描述的一些概念。本发明内容不旨在标识所要求保护的主题的基本特征,也不旨在用于帮助限制所要求保护的主题的范围。
6.在本公开的实施例中,提供了一种用于表征岩层样本的方法。用于表征岩层样本的方法可以包括获得表征岩层样本的多个数据集。用于表征岩层样本的方法还可以包括训练神经网络以生成计算模型。此外,用于表征岩层样本的方法可以另外包括使用多个数据集作为计算模型的输入,其中计算模型可以由处理器实现,该处理器导出岩层样本的渗透率的估计。
7.可以包括以下一个或多个特征。计算模型可以基于训练人工神经网络。计算模型可以进一步导出表示与岩层样本的渗透率的估计相关的不确定性的值。计算模型可以基于训练贝叶斯神经网络和/或采用使用舍弃的贝叶斯推断的人工神经网络。多个数据集可以包括从岩层样本的核磁共振(nmr)测量中导出的数据。多个数据集可以包括t2特征数据。t2特征数据可以通过使用基于奇异值分解(“svd”)的核对岩石样本的t2分布进行编码,然后将t2分布数据映射到降维空间中的t2特征来导出。多个数据集可以包括对应于岩层样本的矿物学数据。岩层样本可选自岩屑、岩芯、岩钻屑、岩石露头或钻孔周围的岩层和煤。
8.在本公开的另一实施例中,提供了一种用于表征岩层样本的系统。用于表征岩层系统的系统可以包括存储表征岩层样本的多个数据集的存储器。用于表征岩层的系统可以进一步包括处理器,该处理器配置为训练神经网络以生成计算模型,其中多个数据集被输入到计算模型,并且其中计算模型由处理器实现,该处理器导出岩层样本的渗透率的估计。
9.可以包括以下一个或多个特征。计算模型可以基于训练人工神经网络或贝叶斯神经网络中的至少一个。计算模型可以进一步导出表示与岩层样本的渗透率的估计相关的不
确定性的值。计算模型可以基于训练采用使用舍弃的贝叶斯推断的人工神经网络。
10.在本公开的另一实施例中,提供了一种用于地层的岩石物理参数的监督学习的方法。用于地层的岩石物理参数的监督学习的方法可以包括获得表征样本的多个数据集。用于地层的岩石物理参数的监督学习的方法可以进一步包括提供具有一个或多个舍弃的神经网络。与多个数据集相关的低保真度数据集可用于训练计算模型。
11.可以包括一个或多个以下特征。计算模型可以用高保真度数据集进行微调。神经网络可以是贝叶斯神经网络。可以使用低保真度数据集训练第一自动编码器。可以使用高保真度数据集训练第二自动编码器。与第一自动编码器或第二自动编码器相关的至少一个参数可被冻结。
附图说明
12.在附图中以示例而非限制的方式示出了本发明,其中相同的附图标记表示相似的元件,其中:
13.图1是描绘根据本公开的系统的实施例的图;
14.图2是表示根据本公开的岩石样本的渗透率的图;
15.图3是描绘根据本公开的方法的实施例的示意图;
16.图4是描绘根据本公开的系统的实施例的框图;
17.图5是描绘根据本公开的系统的实施例的图;
18.图6是描绘根据本公开的系统的实施例的图;
19.图7是描绘根据本公开的系统的实施例的图;
20.图8a-8d是表示根据本公开的监督学习过程的结果的曲线图;
21.图9a-9b是表示根据本公开的监督学习过程的结果的曲线图;
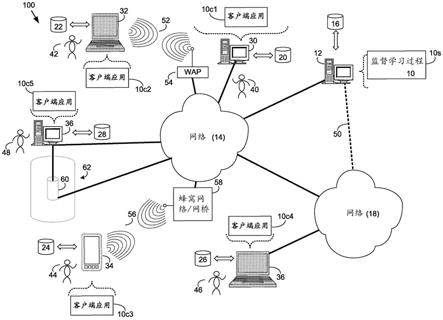
22.图10是描绘根据本公开的系统的实施例的图;以及
23.图11是描绘根据本公开的系统的实施例的图。
具体实施方式
24.下面的讨论针对某些实施方式和/或实施例。应当理解,下面的讨论可以用于使本领域普通技术人员能够制造和使用现在或以后由本文任何公开的专利中的专利“权利要求”定义的任何主题。
25.具体而言,所要求保护的特征组合不限于本文所包含的实施方式和图示,而是包括包含在所附权利要求的范围内的部分实施方式和不同实施方式的元素组合的那些实施方式的修改形式。应当理解,在任何这种实际实施方式的开发中,如同在任何工程或设计项目中一样,可以做出许多实施方式特定的决定来实现开发者的特定目标,例如符合系统相关和商业相关的约束,这些约束可能因实施方式而异。此外,应当理解,这种开发努力可能复杂且耗时,但对于受益于本公开的普通技术人员来说,这仍是设计、制造和生产的常规任务。除非明确指出是“关键的”或“必不可少的”,否则本技术中没有任何内容被认为是所要求保护的发明的关键的或必不可少的。
26.还应当理解,尽管术语第一、第二等可以在本文用于描述各种元件,但这些元件不应该被这些术语所限制。这些术语可以用来区分各个元件。例如,第一对象或步骤可被称为
第二对象或步骤,类似地,第二对象或步骤可被称为第一对象或步骤,而不脱离本公开的范围。第一对象或步骤和第二对象或步骤分别是这两个对象或步骤,但它们不应被视为同一对象或步骤。
27.参考图1,示出了用于岩石物理参数的监督学习的方法和用于表征岩层样本的方法,这两者在本文中都被表示为监督学习过程10。对于下面的讨论,应当理解,监督学习过程10可以多种方式实现。例如,监督学习过程10可被实现为服务器端过程、客户端过程或服务器端/客户端过程。
28.例如,监督学习过程10可以经由监督学习过程10s实现为纯粹的服务器端过程。可替代地,监督学习过程10可以经由客户端应用10c1、客户端应用10c2、客户端应用10c3和客户端应用10c4中的一个或多个实现为纯客户端过程。仍可替代地,监督学习过程10可以经由服务器端监督学习过程10s结合客户端应用10c1、客户端应用10c2、客户端应用10c3、客户端应用10c4和客户端应用10c5中的一个或多个实现为服务器端/客户端过程。在这样的示例中,监督学习过程10的至少一部分功能可以由监督学习过程10s来执行,并且监督学习过程10的至少一部分功能可以由客户端应用10c1、10c2、10c3、10c4和10c5中的一个或多个来执行。
29.因此,本公开中使用的监督学习过程10可以包括监督学习过程10s、客户端应用10c1、客户端应用10c2、客户端应用10c3、客户端应用10c4和客户端应用10c5的任何组合。
30.监督学习过程10s可以是服务器应用,并且可以驻留在计算设备12上并且可以由计算设备12执行,计算设备12可以连接到网络14(例如互联网或局域网)。计算设备12的示例可以包括但不限于:个人计算机、服务器计算机、一系列服务器计算机、小型计算机、大型计算机或专用网络设备。
31.可以存储在耦合到计算设备12的存储设备16上的监督学习过程10s的指令集和子程序可以由计算设备12内包括的一个或多个处理器(未示出)和一个或多个存储器架构(未示出)来执行。存储设备16的示例可以包括但不限于:硬盘驱动器;磁带驱动器;光驱;raid设备;nas设备、存储区域网络、随机存取存储器(ram);只读存储器(rom);以及所有形式的闪存存储设备。
32.网络14可以连接到一个或多个次级网络(例如网络18),其示例可以包括但不限于例如:局域网;广域网;或者内部网。
33.客户端应用10c1、10c2、10c3、10c4、10c5的指令集和子程序可以(分别)存储在(分别)耦合到客户电子设备30、32、34、36、38的存储设备20、22、24、26、28上,可以由(分别)结合到客户电子设备30、32、34、36、38中的一个或多个处理器(未示出)和一个或多个存储器架构(未示出)来执行。存储设备20、22、24、26、28的示例可以包括但不限于:硬盘驱动器;磁带驱动器;光驱;raid设备;随机存取存储器(ram);只读存储器(rom)和所有形式的闪存存储设备。
34.客户电子设备30、32、34、36、38的示例可以包括但不限于个人计算机30、36、膝上型计算机32、移动计算设备34、笔记本计算机36、上网本计算机(未示出)、服务器计算机(未示出)、游戏控制台(未示出)、支持数据的电视控制台(未示出)和专用网络设备(未示出)。客户电子设备30、32、34、36、38可以各自执行操作系统。
35.用户40、42、44、46、48可以直接通过网络14或通过次级网络18访问监督学习过程
10。此外,监督学习过程10可以经由链路50通过次级网络18被访问。
36.各种客户电子设备(例如客户电子设备28、30、32、34)可以直接或间接耦合到网络14(或网络18)。例如,个人计算机28被示为直接耦合到网络14。此外,膝上型计算机30被示为经由在膝上型计算机30和无线接入点(wap)54之间建立的无线通信信道52无线耦合到网络14。类似地,移动计算设备32被示为经由在移动计算设备32和蜂窝网络/网桥58之间建立的无线通信信道56无线耦合到网络14,蜂窝网络/网桥58被示为直接耦合到网络14。例如,wap48可以是能够在膝上型计算机30和wap54之间建立无线通信信道52的ieee 802.11a、802.11b、802.11g、802.11n、wi-fi和/或蓝牙设备。此外,个人计算机34示出为通过硬连线网络连接直接耦合到网络18。
37.大体如上所述,监督学习过程10的部分和/或全部功能可以由一个或多个客户端应用10c1-10c5提供。例如,在一些实施例中,监督学习过程10(和/或监督学习过程10的客户端功能)可被包括在客户端应用10c1-10c5内和/或与其交互,客户端应用10c1-10c5可以包括客户端电子应用、网络浏览器或其他应用。可以同等地利用各种附加/替代配置。
38.关于确定地质岩石的渗透率,多年来已经开发了多种模型。具体而言,已知模型包括测井和岩心数据的测量,以确定渗透率。例如,模型可能包括ksdr和timur-coates模型。基于对砂岩的早期研究,岩石样本渗透率的估计值,称为k
sdr
,可根据经验推导得出,如下面方程1所示:
[0039][0040]
在方程1中,是岩石样本的孔隙度,t
2,lm
是岩石样本t2分布的对数平均值,a是地层相关的标量因子。参数b和c可以通过岩心测量校准凭经验确定。此外,岩石样本渗透率的估计值,称为k
ρ
,可以通过包括岩石样本的表面弛豫率来导出,如下面方程1所示:
[0041][0042]
在方程2中,弛豫率ρ2可以通过扩散弛豫(d-t2)图或nmr和压汞法(micp)数据的比较来估计。不幸的是,用前面提到的任何一种方法来估计弛豫率都是耗时且具有挑战性的。从矿物学角度估算表面弛豫率也具有挑战性,因为即使弛豫率和顺磁元素(fe和mn)的浓度之间存在潜在的关系,这种关系的确切函数形式仍是未知的。
[0043]
岩石样本渗透率的timur-coates模型,称为k
tc
,如下面方程3所示:
[0044][0045]
在方程3中,b是标量因子,ffv和bfv分别代表岩石样本的自由流体体积和束缚流体体积。ffv和bfv可以从岩石样本的t2分布中获得,具有适当的矿物学相关截止值。此外,上述模型中的参数(比如a和b)可以通过实验室测试来计算,其中地面真实岩石渗透率是用岩心样本上的氦气或氮气流量测量来测量的,并且结果与岩心样本的测量t2分布相关。不同的研究还表明,不同岩石类型的孔隙度和渗透率之间有很强的相关性。图2说明了这一概
念,图2示出了不同岩石类型或矿物学的强渗透率-孔隙度相关性。具体地,图2是来自砂和砂岩的4个数据集的渗透率对孔隙度的图,说明了随着矿物的改变孔隙尺寸减小而出现的渗透率和孔隙度的降低。
[0046]
此外,关于以高精度捕获在关于地质岩石渗透率收集的数据中存在的高度复杂的潜在非线性,可以使用基于深度学习(dl)的回归方法。然而,基于dl的回归方法带来了挑战,特别是在工业应用中的大规模应用方面。例如,面临的一个挑战可能包括,在噪声保真度方面,一些(如果不是大多数的话)算法不能解决工业应用中常见的数据的高度异方差性质。现有的解决方案致力于根据输出标签中的噪声来处理低保真度和高保真度数据集,并将它们组合成更精确的模型。为了获得更好的精度,模型可以在低保真度数据上训练,然后在高保真度数据上微调。在机器学习工作流中加入有噪声的输出标签是另一种选择。然而,在使用已知的不确定性对训练数据进行抖动的情况下,引入输入噪声的方法似乎没有得到解决。
[0047]
使用基于dl的回归方法提出的挑战的另一示例包括常规算法在进行预测时可能缺乏信息值(voi)方面。他们通常提供点估计,但没有给出任何相关预测不确定性的指示。例如,已经提出了两种不同的深度学习方法来包含不确定性。一种方法包括通过贝叶斯推断合并一个或多个不确定性。基本思想是为神经网络中的每个权重参数分配均值和方差,然后基于变分推理执行反向传播,而不是通常的基于采样的方法,这允许在gpu上完成计算,从而显著提高其速度。第二种变分方法使用“舍弃(dropout)”的概念。传统上,舍弃已经被模型用来防止过度拟合。它们通过在神经网络的训练阶段基于某个伯努利参数随机关闭神经元来工作。这迫使神经元不相互依赖,并迫使它们学习独特可区分的特征。舍弃段在培训阶段仍然活跃,但在测试阶段不活跃。在测试阶段,它们的输出基本乘以取决于压差伯努利参数的因子,以保持激活预期与可能在训练阶段中的相同。通过在测试阶段保持不确定性的激活,可以进一步使用舍弃来估计不确定性。因此,这样的网络可以近似等同于深度高斯过程。然而,显著的缺点是,每个舍弃段的伯努利参数的选择是手动设置的,即它是超参数。优化超参数需要网格搜索,对于复杂的神经网络,计算成本可能高得令人望而却步。concrete dropout段本质上是用其连续松弛(即混凝土分布松弛)代替舍弃的离散伯努利分布。这种松弛允许分布的重新参数化,并且本质上使得参数是可学习的。当与异方差损失(而不是通常的mse)结合使用时,带有concrete dropout段的架构可能会产生校准良好的预测不确定性。此外,所有机器学习技术仅在测试数据集在训练数据集的分布内时才起作用。当这一假设被违反,并且输入测试数据点不符合分布(ood)时,常规方法会无声地失败,而不会发出模型可能失败的警报。
[0048]
现在参考图3,提供了示出监督学习过程10的示例的流程图。在一些实施例中,监督学习过程10可以包括获得302表征岩层样本的多个数据集。监督学习过程10可以进一步包括训练304神经网络以生成计算模型。此外,监督学习过程10可以包括使用306多个数据集作为计算模型的输入,其中计算模型可以由处理器实现,该处理器导出岩层样本的渗透率的估计。监督学习过程10可以考虑数据的异方差性(即在一个或多个样本上噪声保真度的变化水平)。除了点估计之外,监督学习过程10还可以为预测测量提供一个或多个置信区间。监督学习过程10可以包括用于检查一个或多个不确定性的校准的度量。
[0049]
在一些实施例中,监督学习过程10可以使用一个或多个校准的不确定性来将测试
数据点分类为相对于训练数据点在内或odd,并且还可以提供用于测量预测不确定性的性能的度量作为odd数据的指标。一般来说,监督学习过程10可以给予所有输入数据点同等的重要性。例如,在油田应用中,不同的数据点可能来自不同的遗留工具,具有不同程度的不确定性。此外,监督学习过程10通常通过最小化一个或多个预测和地面真实之间的l2范数,可以提供期望输出的点估计。监督学习过程10可以提供预测测量的一个或多个点估计以及一个或多个置信区间,同时平衡输出的精度和精确度。此外,监督学习过程10可以包括一个或多个度量,其可以测量一个或多个置信区间的校准。另外,监督学习过程10可以使用一个或多个校准的不确定性来将测试数据点分类为相对于训练数据点在内或odd,并且还提供用于测量预测不确定性的性能的度量作为odd数据的指标。监督学习过程10可以确保以下三个要点:(1)尊重训练数据集中模型的输入和输出中存在的噪声信息;(2)为测试数据集上的每个预测输出提供一个或多个置信区间,并对获得的一个或多个不确定性执行质量检查;以及(3)有效地处理不平衡的多保真度数据集。
[0050]
在一些实施例中,监督学习过程10可以呈现新的概率编程管道,也称为计算工作流和计算模型,用于确定地质岩层的岩石物理参数(即渗透率)。监督学习过程10可以使用从地质岩层样本测量的nmr弛豫(t2)数据以及对应于地质岩层样本的矿物学数据。管道可以是灵活的,以基于其他测量来修改特征空间。在一些实施例中,监督学习过程10可以在编程管道中使用机器学习来学习一组输入特征x(即x1,x2,x3,
…
,x
p
)和实值输出y(即渗透率)之间的计算模型(即f的映射),其最小化均方误差(mse),如下面方程4所示:
[0051][0052]
在一些实施例中,监督学习过程10可以包括准备一组输入特征的数据的预处理阶段。例如,预处理阶段可以使用基于奇异值分解(svd)的核对样本的t2分布进行编码,然后将在更高维空间(即64维)中编码的t2分布数据映射到降维空间(即6维)中的t2特征。编程管道的一般工作流程如图4所示。首先,使用基于svd的编码器404对t2分布402进行编码。然后,样本406的nmr特征(即孔隙度、束缚自由体积比和从样本的nmr测量中导出的t2对数平均值)、降维空间中的t2特征408(即作为预处理阶段的输出)和对应于岩石样本的矿物学数据410(即地质岩石样本中常见的一组矿物成分的浓度)可被组合并输入到机器学习模型412,以预测岩石样本的渗透率414。计算模型的质量可以通过交叉验证来确定。
[0053]
在一些实施例中,nmr测量可以通过地面实验室或地面井场的nmr波谱仪在地质岩层的岩屑、岩芯、钻屑或其他样本上进行。可替代地,nmr测量可以通过nmr测井工具在钻孔周围的地质岩层的部分或样本上进行,作为井筒测井测量的一部分。
[0054]
在一些实施例中,矿物学数据可以从在地面实验室或地面井场对岩石样本进行的x光衍射或红外光谱测量中确定。这种光谱测量可以通过地面实验室或地面井场的nmr波谱仪在地质岩层的岩屑、岩芯、钻屑或其他样本上进行。这些方法可被认为是矿物学的“直接测量”,因为每种产生光谱,其中包含关于矿物特性(即光谱信号的位置,通常标在横轴上)和关于矿物成分浓度(光谱信号的强度,通常标在纵轴上)的信息。然而,这些方法通常在井筒内的井下不可用。
[0055]
在一些实施例中,可以采用方法根据井筒测井测量来确定钻孔周围的一个或多个地质岩层的一部分或样本中的矿物学。然而,这些方法更具挑战性,因为确定可能依赖于“间接测量”。通常用于推断矿物学的测井测量是感应中子伽马射线光谱学/光谱术。简而言之,由包含在测井探测器外壳内的天然放射性材料或脉冲中子发生器产生的快中子和热中子与地层中的元素核相互作用,并分别在测井探测器周围的局部体积中产生瞬发(即非弹性)和俘获伽马辐射。这些产生的伽马射线穿过地层,其中一部分被包含在测井探测器外壳内的闪烁探测器探测到。探测器信号产生的光谱包含代表地层中元素核的伽马射线的贡献。该光谱通常绘制为计数率(垂直轴)对能量(水平轴)的关系,并且包括关于元素同一性的信息(根据伽马射线的特征能量)和关于通常在储集岩中发现的某些元素(例如si,al,ca,mg,k,fe,s等)的元素丰度的信息(根据计数的数量)。元素丰度的这种测量不能提供矿物学的直接测量,因为同样有限数量的普通造岩元素包含在数量大得多的普通造岩矿物中。示例是元素硅(si),它存在于常见的含沉积矿物石英(sio2)、蛋白石(sio2.nh2o)、钾长石(kalsi3o8)、斜长石([na,ca]al[al,si]si2o8)和许多其他硅酸盐矿物中,包括粘土和云母族矿物。尽管如此,岩石样本的大量元素浓度与其矿物成分浓度之间必然存在关系,因为矿物通过其确定的晶体结构具有有限范围的化学成分。因此,岩石样本的大量元素浓度由岩石样本的矿物学决定。
[0056]
在一些实施例中,可以采用从大量元素浓度的测量中导出矿物学估计的方法。这些方法可能依赖于一个或多个映射函数的推导,以根据元素浓度对矿物成分浓度的预测进行正向建模。一组方法是基于一种或多种元素的浓度和一种或多种感兴趣的矿物之间的经验线性关系的线性回归模型。另一组方法是径向基函数,也称为最近邻映射函数。这种方法已被应用于根据从井筒中进行的伽马射线光谱测井测量中获得的元素浓度来确定地层矿物学。也可以使用确定岩石样本的矿物学数据的其他方法。
[0057]
在一些实施例中,监督学习过程10可以使用两种方法中的一种或两种,这两种方法考虑了输入数据的异方差性质(例如nmr测量中变化的不确定性水平和岩石样本的不同元素特征)、组合多保真度数据集(例如岩心和测井数据)的需要以及获得输出数据及其不确定性估计的需要。这两种方法是贝叶斯回归方法,即贝叶斯神经网络(bnn)和舍弃方法。
[0058]
现在参考图5,提供了示出了人工神经网络(ann)的一般结构的图,该ann可用于使用bnn方法或舍弃方法实现监督学习过程10。ann502可以配置成基于输入特征的高度非线性组合来确定岩石样本的渗透率。输入特征可以包括从使用基于svd的核确定的t2分布中减少的预定数量(例如6个)的t2特征。具体地,可以通过使用基于svd的核对岩石样本的t2分布进行编码,然后将t2分布数据映射到降维空间中的t2特征来导出t2特征数据。其他输入特征包括基于nmr的输入数据(比如孔隙度、束缚自由体积比、t2对数平均值)和矿物学输入数据。ann可以通过应用于ann的每个神经元的非线性或激活函数来引入非线性。可以通过固定核权重504和通过最小化mse损失函数来更新神经网络权重506来训练ann。为了提高性能,可以在ann的每一层执行批处理标准化步骤。
[0059]
在根据本公开的一些实施例中,监督学习过程10可以利用基于训练ann的计算模型。计算模型可以进一步导出表示与岩层样本的渗透率的估计相关的不确定性的值。
[0060]
在一些实施例中,根据本公开,监督学习过程10可以利用基于训练采用使用舍弃的贝叶斯推断的人工神经网络的计算模型。为了确定岩石样本渗透率预测中的不确定性,
与简单地确定渗透率的点估计相反,如图5所示,ann可被实现为贝叶斯神经网络或者采用使用舍弃的贝叶斯推断。
[0061]
在根据本公开的一些实施例中,监督学习过程10可以利用基于训练bnn的计算模型。对于bnn,可以假设bnn的每个权重遵循正态分布,由两个参数μ和σ表征,这两个参数在渗透率预测中引入了不确定性,如图6所示。总的来说,图6示出了简化的bnn架构。通过从bnn权重中取样,可以预测渗透率值k以及后验分布p(k)。bnn的训练过程可能不同,因为基于贝叶斯理论,称为证据下限(elbo)的不同损失函数可被最小化,该函数估计真实后验分布和它的近似值有多接近。
[0062]
在一些实施例中,获得渗透率不确定性的替代方式可以使用在训练和测试阶段都应用了舍弃的ann来实现,这是近似贝叶斯推断的过程。诸如concrete dropout之类的方法可以通过自动确定概率参数p来改善这一过程,概率参数p用于切断ann的每个神经元。
[0063]
在一些实施例中,除了在岩石样本的渗透率的输出预测中提供不确定性之外,渗透率确定可以从异方差、多保真度数据集获得,例如来自不同测井和岩心测量的数据集。为了在输入特征中包含不同的不确定性,可以通过使用每个特征中噪声的标准偏差围绕其平均值对每个数据点进行采样来扩充初始数据集。通过这样做,网络可以对输入噪声数据更加稳健。此外,如果一个或多个数据流来自不同源(即测井和岩心),并且假设一个源提供比另一个更准确的数据,则网络可以如图7所示以两个连续的步骤来训练。通常,低保真度数据是具有较低信噪比的数据,例如井下测井数据,而高保真度数据是具有较高信噪比的数据,通常是实验室数据或具有台站测量的现场数据。这里,信噪比是保真度的主要驱动因素之一。
[0064]
图7示出了对低保真度数据的输入和输出的采样702,其中有神经网络应用704。然后可以应用转移学习706,并且可以微调708高保真度数据,以提供渗透率的答案产品预测710。具体地,图7示出了在两个单独面板中使用bnn或dropout方法确定渗透率的工作流程。使用异方差噪声适当采样的“低保真度”数据可以首先用于训练网络。该操作允许网络达到良好的局部最小值,这将是第二步的起点。在第二操作中,转移学习可用于初始化神经网络的参数,以便使用“高保真度”数据进行训练,该数据也可针对特征中的噪声进行采样,以确定用于预测渗透率的最终网络,表示为最终mse,以及岩石样本的相关不确定性。对于每种方法,每种方法包括对低保真度数据的训练、传递权重和对高保真度数据的训练,以获得用于渗透率预测的最终模型。在该示例中,n可以指为每个时期获得的新训练数据集。具体地,低保真度数据可以通过ann或舍弃来训练。然后,bnn或舍弃的权重可被传送到可以训练高保真度数据的地方。然后可以预测最终渗透率,表示为最终mse。
[0065]
现在参考图8a-8d,展示了上述渗透率预测技术的应用。具体地,图8a示出了基于方程1的模型的真实渗透率(x轴)对预测渗透率(y轴)的图。该图的对数mse值为0.55。图8b示出了基于方程3的timur-coates模型的真实渗透率(x轴)对预测渗透率(y轴)的图。该图的对数mse值为0.49。图8c是基于图4和5的ann模型的真实渗透率(x轴)对预测渗透率(y轴)的图。该图的对数mse值为0.16。图8d是基于图6和7的bnn模型的真实渗透率(x轴)对预测渗透率(y轴)的曲线图。该图的对数mse值为0.15。注意,与图8a所示的ksdr模型、图8b所示的timur-coates模型或图8c所示的简单人工神经网络模型相比,图8d的贝叶斯神经网络(即较低mse值)显示出更好的渗透率预测,其还可以额外提供渗透率不确定性。
[0066]
在一些实施例中,可以引入评估度量来评估渗透率的一个或多个预测不确定性值。不确定性校准度量可以评估每个渗透率点的预测标准偏差是否显著接近真实渗透率值的距离。这些结果总结在图9a和9b的图中,其中通过观察两条线之间的接近度来评估渗透率不确定性预测的质量。此外,图9a和9b表示围绕预测的可预知性(x轴)的%置信区间对置信区间包含真值(y轴)的%预测的图。对于连续的z∈[0,100]值,计算一个百分点,预测周围的z%置信区间包含真实渗透率值。
[0067]
在根据本公开的一些实施例中,多个数据集可以包括从岩层样本的nmr测量导出的数据以及对应于岩层样本的矿物学数据。岩层样本可包括但不限于岩屑、岩芯、岩钻屑、岩石露头或围绕钻孔和煤的岩层。
[0068]
在根据本公开的一些实施例中,监督学习过程10引入了面向工业应用的回归问题的基于概率编程的监督机器学习工作流程。该工作流程解决了石油物理应用中面临的各种挑战,例如地下多物理测量的解释。
[0069]
在根据本公开的一些实施例中,监督学习过程10可以包括获得表征样本的多个数据集。用于地层的岩石物理参数的监督学习的方法可以进一步包括提供具有一个或多个舍弃的神经网络。与多个数据集相关的低保真度数据集可用于训练计算模型。
[0070]
在一些实施例中,测量的保真度可以在其已知的概率密度函数中被捕获,通常在相关硬件的校准期间被计算。例如,当概率密度函数是多变量高斯函数时,这种保真度可以在协方差矩阵中被充分捕获。为了尊重输入和输出中存在的噪声信息,可以从输入特征空间和输出变量空间中的已知概率密度函数进行采样。本文称为“采样”方法的一种方法是直接用该采样数据集动态(即在每个训练时期)训练神经网络模型,神经网络将在训练样本数据集的不同噪声实现上反向传播。另一种方法,本文称为“自动编码器”方法,是在数据集上训练自动编码器,其中输出可以是纯数据集,输入可以是动态生成的被噪声破坏的数据集。一旦针对该自动编码器的训练已经收敛,并且数据的噪声模型已经被自动编码器捕获,那么与第一自动编码器或第二自动编码器相关的至少一个参数可被冻结,并且编码器可被用作任何输入-输出对的去噪器,该去噪器然后可被用于训练神经网络模型以学习从输入到输出的映射。然而,一旦去噪,就不需要像“采样”方法中提到的那样,用动态采样的数据来训练神经网络模型。
[0071]
在根据本公开的一些实施例中,监督学习过程10可以利用计算模型,其包括bnn或具有舍弃计算模块的标准神经网络。在该示例中,在训练期间最小化的成本函数可被设计用于特定应用。根据基于领域专业知识为数据集的后验分布提供的智能猜测,所得似然性的分布可以形成选择成本函数的基础。例如,一些最常见的成本函数是由高斯和拉普拉斯似然性假设(即mse和平均绝对误差)产生的。此外,可以生成新的成本函数,例如假设标准高斯似然中的异方差可能引起的异方差损失。目前,对于具有concrete dropout的神经网络,可以使用异方差损失来获得校准良好的预测不确定性。
[0072]
在一些实施例中,监督学习过程10可以分别假设高保真度和低保真度数据集(x
hf
,y
hf
)和(x
lf
,y
lf
)。为了处理不平衡的多保真度数据集,可以首先训练(x
lf
,y
lf
)上的ann/bnn。此外,使用(x
hf
,y
hf
)得到的神经网络的权重可以被微调。
[0073]
关于上面提到的“采样”方法,可以使用具有一个或多个舍弃的标准神经网络在低保真度数据集上训练计算模型,然后用高保真度数据集对其进行微调。当使用bnn作为神经
网络时,可以通过“采样”方法在低保真度数据集上训练标准神经网络模型,可以将学习的参数传送到贝叶斯架构,然后可以使用高保真度数据集微调贝叶斯模型。在这两种方法中,可以通过在神经网络的每一层中动态地使用输入数据的不同噪声实现来更新计算模型。
[0074]
在一些实施例中,并且还参考图10,监督学习过程10可以利用“自动编码器”方法。例如,可以使用低保真度数据集来训练第一自动编码器。此外,可以使用高保真度数据集训练第二自动编码器。例如,当使用具有舍弃的标准神经网络时,可以分别在低保真度和高保真度数据集上训练两个不同的自动编码器,如图10所示。低保真度输入数据可以通过低保真度训练的编码器,并用于训练计算模型。可以使用从高保真度训练的编码器获得的去噪高保真度来进一步微调计算模型。自动编码器内的神经网络也可以是dropout或bnn的,或者也可以由基于应用的可变自动编码器代替。当使用bnn时,监督学习过程10保持与使用具有舍弃的标准神经网络时相同。唯一的区别在于,标准神经网络用去噪的低保真度输入来训练,学习的参数被传送到贝叶斯模型,并且贝叶斯模型可以用去噪的高保真度输入来微调。再次参考图10,对于bnn和dropout,训练的第一步可以包括使用低保真度数据和冻结的低保真度编码器。类似地,训练的第二即最后一步可以包括使用高保真度数据和冻结的高保真度编码器,以便微调bnn或dropout模型的权重。然后可以预测最终渗透率,分别表示为最终mse和最终mse。
[0075]
此外,关于测量模型稳健性的方法,可以使用精度r2以及mse,这取决于应用领域。对于不确定性,可以使用负对数似然。在根据本公开的一些实施例中,可以在两个方面评估不确定性。首先,可以确定一个或多个不确定性的绝对值的稳健性。这可以通过确定x%测试用例的地面真实是否在x%置信区间内来测量。此外,一个或多个不确定性值有多好可以根据它们彼此之间的相对程度来确定。理想地,由分布内(id)数据集产生的预测可能需要低不确定性,而对于ood数据集则需要较高不确定性。为此,可以使用auc分数。当使用auc分数时,监督学习过程10可被修改以在回归设置中工作。例如,一个或多个预测不确定性可以用作异常检测器,以区分好的预测和坏的预测,好的预测通常出现在id数据集,坏的预测通常出现在ood数据集。为了评估auc,可能需要一个或多个地面真实二进制标签以及分类器的分数。在回归设置中,地面真实二进制标签对于所有id数据点可以是1,对于所有ood数据点可以是0。此外,分类器的分数可以是模型为每个id和ood预测输出的不确定性。此外,自动编码器技术的使用以及与不确定性度量的集成可以使该工作流程与工业问题非常相关。
[0076]
本文已经描述和说明了学习和应用计算模型的方法和系统的多个实施例,该计算模型将一组输入特征映射到岩层样本的渗透率的估计。虽然已经描述了本发明的特定实施例,但这并不意味着本发明局限于此,因为这意味着本发明在本领域允许的范围内是广泛的,并且说明书同样被阅读。因此,虽然已经公开了特定的神经网络架构和工作流程,但应当理解,也可以使用其他特定的神经网络架构和工作流程。因此,本领域技术人员将理解,在不偏离所要求保护的精神和范围的情况下,可以对所提供的发明进行其他修改。
[0077]
上面描述的一些方法和过程可以实现为与计算机处理器一起使用的计算机程序逻辑。计算机程序逻辑可以各种形式体现,包括源代码形式或计算机可执行形式。源代码可以包括各种编程语言(例如目标代码、汇编语言或诸如c、c
或java的高级语言)的一系列计算机程序指令。这种计算机指令可以存储在非暂时性计算机可读介质(例如存储器)中,并由计算机处理器执行。计算机指令可以任何形式作为带有附带的印刷或电子文档(例如收
缩包装软件)的可移动存储介质来分发,预载有计算机系统(例如在系统rom或固定盘上),或者通过通信系统(例如因特网或万维网)从服务器或电子公告板分发。
[0078]
可替代地或另外,处理器可以包括耦合到印刷电路板、集成电路(例如专用集成电路(asic))和/或可编程逻辑器件(例如现场可编程门阵列(fpga))的分立电子部件。上述任何方法和过程都可以使用这样的逻辑设备来实现。
[0079]
在一方面,如上所述的方法和过程的任何一个或任何部分或全部步骤或操作可以由处理器执行。术语“处理器”不应被解释为将本文公开的实施例限制于任何特定的设备类型或系统。处理器可以包括计算机系统。计算机系统还可以包括用于执行上述任何方法和过程的计算机处理器(例如微处理器、微控制器、数字信号处理器或通用计算机)。
[0080]
计算机系统还可以包括存储器,例如半导体存储设备(例如ram,rom,prom,eeprom或闪存可编程ram)、磁存储设备(例如磁盘或固定盘)、光存储设备(例如cd-rom)、pc卡(例如pcmcia卡)或其他存储设备。存储器可用于存储上述方法和过程的任何或所有数据集,例如包含岩石样本的nmr衍生输入特征的数据集、岩石样本的t2分布和岩石样本的矿物学数据。
[0081]
附图中的流程图和框图图示了根据本公开的各种实施例的系统和方法的可能实施方式的架构、功能和操作。在这点上,流程图或框图中的每个框可以代表代码的模块、段或部分,其包括用于实现指定逻辑功能的一个或多个可执行指令。还应该注意的是,在一些替代实施方式中,框中提到的功能可以不按图中提到的顺序发生。例如,连续示出的两个框实际上可以基本同时执行,或者这些框有时可以相反的顺序执行,这取决于所涉及的功能。还将注意到,框图和/或流程图图示的每个框以及框图和/或流程图图示中的框的组合可以由执行指定功能或动作的基于专用硬件的系统或者专用硬件和计算机指令的组合来实现。
[0082]
本文使用的术语是为了描述特定的实施例,而不是为了限制本公开。如本文所用,单数形式“一”、“一个”和“该”旨在也包括复数形式,除非上下文清楚地另外指出。将进一步理解,当在本说明书中使用时,术语“包括”和/或“包含”指定所陈述的特征、整数、步骤、操作、元件和/或部件的存在,但不排除存在或添加一个或多个其他特征、整数、步骤、操作、元件、部件和/或其组合。
[0083]
以下权利要求中的相应结构、材料、动作以及装置或步骤加功能元件的等同物旨在包括用于结合具体要求保护的其他要求保护的元件来执行功能的任何结构、材料或动作。出于说明和描述的目的,已经呈现了本公开的描述,但并不旨在穷尽或局限于所公开形式的公开。在不脱离本公开的范围和精神的情况下,许多修改和变化对于本领域普通技术人员来说是显而易见的。选择和描述该实施例是为了最好地解释本公开的原理和实际应用,并且使本领域的其他普通技术人员能够理解具有各种修改的各种实施例的公开内容,这些修改适合于预期的特定用途。
[0084]
尽管上面已经详细描述了多个示例性实施例,但本领域技术人员将容易理解,在示例性实施例中许多修改是可能的,而不会实质上脱离本文描述的本公开的范围。因此,这样的修改旨在包括在如以下权利要求所定义的本公开的范围内。在权利要求中,装置加功能条款旨在覆盖在此描述的执行所述功能的结构,并且不仅是结构等同物,而且是等同结构。因此,尽管钉子和螺钉可能不是结构上的等同物,因为钉子采用圆柱形表面将木制部件固定在一起,而螺钉采用螺旋表面,但在紧固木制部件的环境中,钉子和螺钉可能是等同结
构。申请人的明确意图是不援引35 u.s.c.
§
112第6款对本技术中的任何权利要求进行任何限制,除非权利要求明确使用“用于
…
的装置”一词以及相关功能。
[0085]
因此已经通过参考本技术的实施例详细描述了其公开,很明显,在不脱离所附权利要求中限定的公开的范围的情况下,修改和变化是可能的。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。