1.本技术涉及终端技术领域,尤其涉及一种视频编辑方法及设备。
背景技术:
2.近年来,随着电子产业和通信技术的飞速发展,目前智能电子设备越来越多,例如手机、智能音箱、智能手环等,人们的生活变得越来越智能化。由于手机的便携性,且可以从应用商店上下载各种功能的应用软件,所以手机已经成为人们日常生活中必不可少的必备品。
3.基于互联网的发展,用户在智能电子设备上观看视频越来越方便,当用户看到比较精彩的视频内容,例如直播视频中精彩内容,用户通常希望把精彩的视频片段分享给朋友或分享至社交网络。通常视频平台会在视频中较为精彩在位置上进行标注,例如,在视频的进度条上进行打点,形成多个打点位置,用户在触动或点击某一个打点位置时,会在该打点位置处显示该打点位置处视频内容的文字信息,这样有利于用户可以在较短的时间内切换到想要观看的位置,也可以便于用户识别视频中较为精彩的部分,从而剪辑出精彩的视频片段分享给朋友或分享至社交网络。
4.然而,针对实时直播视频来说,由于内容的不可预知性,导致了用户在观看时无法预料到精彩的片段可能会出现的时机,因此很难从正在观看的实时直播视频中剪辑出精彩的视频片段。
技术实现要素:
5.本技术提供一种视频编辑方法及设备,用于实现基于观看视频的用户因情绪波动发出的唤醒词或唤醒动作,从实时直播视频中剪辑出精彩的视频片段。
6.第一方面,本技术实施例提供了一种视频编辑方法,该方法可以由第一电子设备执行,该方法包括:首先,在第一电子设备播放第一视频的过程中,第一电子设备从采集装置获取观看第一视频的用户的语音信息和/或用户的第二视频,第一电子设备识别语音信息和/或第二视频中与用户情绪相关的m个关键信息,在第一视频中确定与m个关键信息的采集时间单元相对应的n个第一视频片段,对n个第一视频片段进行编辑,生成编辑后的视频。其中,m和n为正整数,采集装置可以语音采集装置,也可以是图像采集装置,采集装置可以集成在第一电子设备中,也可以是与第一电子设备连接的设备。
7.其中,关键信息包括如下唤醒词或唤醒动作中的至少一个:唤醒词包括所述用户因情绪波动做出设定肢体动作所发出的声音、发出的设定语音信息;唤醒动作包括所述用户因情绪波动做出的设定肢体动作、设定面部表情。关键信息还可以是声音的分贝大小等自然界中存在的信息,本技术实施例对此并不作限定。
8.本技术实施例中,电子设备基于观看视频的用户的无意识发出的语音或做出的动作,触发视频剪辑,该方法并不需要用户的主动触发视频剪辑,就可以生成精彩视频片段,可有效地改善用户体验。
9.在一种可能的设计中,该方法还包括:第一电子设备确定n个第一视频片段相对应的第二视频的m个第二视频片段;其中,n个第一视频片段的播放时段与m个第二视频片段的采集时段相重叠;然后第一电子设备对n个第一视频片段和m个第二视频片段进行编辑,生成编辑后的视频。
10.本技术实施例中,通过多窗口播放精彩视频片段以及与用户相关的视频信息,有助于增加视频的趣味性,增加用户与电子设备的互动效果。
11.在一种可能的设计中,该方法还包括:将所述第一视频分割成l个第一视频片段。然后当识别到所述关键信息时,第一电子设备在l个第一视频片段中与关键信息的采集时间单元相对应的第一视频片段上打点;然后第一电子设备从第一视频中获取第一视频片段的打点信息,根据打点信息,从l个第一视频片段中确定与m个关键信息的采集时间单元相对应的n个第一视频片段。
12.本技术实施例中,按照上述方法可以从第一视频中获取精彩视频片段,还有助于后续直观的显示打点位置处的视频内容,可以有效改善用户体验。
13.第二方面,本技术实施例提供了一种视频编辑方法,该方法可以由第一电子设备执行,该方法包括:在第一电子设备播放第一视频的过程中,第一电子设备从采集装置获取观看所述第一视频的用户的语音信息和/或所述用户的第二视频;然后第一电子设备将语音信息和/或第二视频按照采集时间单元进行划分,得到m个采集时间单元。第一电子设备根据m个采集时间单元对应的所述语音信息和/或第二视频中的关键信息,确定所述m个采集时间单元分别对应的用户情绪评分;第一电子设备根据用户情绪评分,在第一视频中确定与m个采集时间单元对应的l个第一视频片段的精彩度;第一电子设备对l个第一视频片段中的精彩度大于设定阈值的n个第一视频片段进行编辑,生成编辑后的视频,其中,m、l和n为正整数。
14.本技术实施例中,电子设备基于观看视频的用户的无意识发出的语音或作出的动作,实现对用户的观影情绪的评分,从而评估视频片段的精彩度,完成视频剪辑,该方法并不需要用户的主动触发视频剪辑,就可以生成精彩视频片段,可有效地改善用户体验。
15.在一种可能的设计中,确定m个采集时间单元分别对应的用户情绪评分的具体方法包括:第一电子设备按照预设的神经网络模型,识别m个采集时间单元对应的语音信息和/或第二视频中的关键信息;根据识别结果,确定所述m个采集时间单元分别对应的用户情绪评分。
16.本技术实施例中,按照上述方法评估用户的情绪,有助于准确地获取精彩视频片段。
17.在一种可能的设计中,该方法还包括:确定所述n个第一视频片段相对应的所述第二视频的m个第二视频片段;其中,n个第一视频片段的播放时段与所述m个第二视频片段的采集时段相重叠。第一电子设备对n个第一视频片段和m个第二视频片段进行编辑,生成编辑后的视频,其中,m和n为正整数。
18.本技术实施例中,以用户情绪评分反映视频片段本身的精彩度,能够较为客观的反映所述视频片段的精彩程度。
19.第三方面,本技术实施例提供了一种视频编辑方法,该方法可以由第二电子设备执行,该方法包括:在第一电子设备播放第一视频的过程中,从采集装置获取观看第一视频
的用户的语音信息和/或用户的第二视频,识别语音信息和/或第二视频中的与用户情绪相关的m个关键信息,从第一电子设备的第一视频中获取与m个关键信息的采集时间单元相对应的n个第一视频片段,对n个第一视频片段进行编辑,生成编辑后的视频,其中,m和n为正整数。
20.本技术实施例中,第二电子设备可以基于观看视频的用户无意识发出的语音或作出的动作,触发剪辑第一电子设备所播放的视频,相比实施例1,该方法并不需要播放视频的设备具有视频编辑功能,通过分布式系统中多个设备合作完成视频剪辑,生成精彩视频片段,有效地改善用户体验。
21.在一种可能的设计中,该方法还可以包括:第二电子设备确定所述n个第一视频片段相对应的所述第二视频的m个第二视频片段;其中,n个第一视频片段的播放时段与所述m个第二视频片段的采集时段相重叠;具体地,第二电子设备可以对所述n个第一视频片段和m个第二视频片段进行编辑,生成编辑后的视频。
22.在一种可能的设计中,第二电子设备可以将所述第一视频分割成l个第一视频片段,当识别到所述关键信息时,在所述l个第一视频片段中与所述关键信息的采集时间单元相对应的第一视频片段上打点;从所述第一视频中获取第一视频片段的打点信息,根据所述打点信息,从所述l个第一视频片段中确定与所述m个关键信息的采集时间单元相对应的n个第一视频片段。
23.在一种可能的设计中,关键信息可以包括如下唤醒词或唤醒动作中的至少一个:
24.所述唤醒词包括所述用户因情绪波动做出设定肢体动作所发出的声音、发出的设定语音信息;所述唤醒动作包括所述用户因情绪波动做出的设定肢体动作、设定面部表情。
25.第四方面,本技术实施例提供一种视频编辑方法,该方法可以由第二电子设备执行,该方法包括:在第一电子设备播放第一视频的过程中,从采集装置获取观看所述第一视频的用户的语音信息和/或所述用户的第二视频;第二电子设备将语音信息和/或第二视频按照采集时间单元进行划分,得到m个采集时间单元;第二电子设备根据m个采集时间单元对应的语音信息和/或第二视频中的关键信息,确定m个采集时间单元分别对应的用户情绪评分;第二电子设备从第一电子设备获取与m个采集时间单元对应的第一视频的l个第一视频片段;第二电子设备根据用户情绪评分,在第一视频中确定与m个采集时间单元对应的l个第一视频片段的精彩度;第二电子设备对l个第一视频片段中的精彩度大于设定阈值的n个第一视频片段进行编辑,生成编辑后的视频,其中,m、l和n为正整数。
26.本技术实施例中,电子设备基于观看视频的用户的无意识发出的语音或作出的动作,实现对用户的观影情绪的评分,从而评估视频片段的精彩度,完成视频剪辑,该方法并不需要用户的主动触发视频剪辑,就可以生成精彩视频片段,可有效地改善用户体验。
27.在一种可能的设计中,确定所述m个采集时间单元分别对应的用户情绪评分,包括:
28.第二电子设备按照预设的神经网络模型,识别所述m个采集时间单元对应的所述语音信息和/或第二视频中的关键信息;第二电子设备根据识别结果,确定m个采集时间单元分别对应的用户情绪评分。
29.在一种可能的设计中,方法还包括:第二电子设备确定所述n个第一视频片段相对应的所述第二视频的m个第二视频片段;其中,n个第一视频片段的播放时段与所述m个第二
视频片段的采集时段相重叠;具体地,可以对n个第一视频片段和m个第二视频片段进行编辑,生成编辑后的视频,其中,m和n为正整数。
30.在一种可能的设计中,关键信息可以包括如下唤醒词或唤醒动作中的至少一个:
31.所述唤醒词包括所述用户因情绪波动做出设定肢体动作所发出的声音、发出的设定语音信息;所述唤醒动作包括所述用户因情绪波动做出的设定肢体动作、设定面部表情。
32.第五方面,本技术实施例提供一种第一电子设备,包括处理器和存储器,其中,存储器用于存储一个或多个计算机程序;当存储器存储的一个或多个计算机程序被处理器执行时,使得该第一电子设备能够实现上述第一方面或第二方面的任意一种可能的设计的方法。
33.第六方面,本技术实施例提供一种第二电子设备,包括处理器和存储器,其中,存储器用于存储一个或多个计算机程序;当存储器存储的一个或多个计算机程序被处理器执行时,使得该第二电子设备能够实现上述第三方面或第四方面的任意一种可能的设计的方法。
34.第七方面,本技术实施例还提供一种装置,该装置包括执行上述第一方面或第二方面的任意一种可能的设计的方法的模块/单元。这些模块/单元可以通过硬件实现,也可以通过硬件执行相应的软件实现。
35.第八方面,本技术实施例还提供一种装置,该装置包括执行上述第三方面或第四方面的任意一种可能的设计的方法的模块/单元。这些模块/单元可以通过硬件实现,也可以通过硬件执行相应的软件实现。
36.第九方面,本技术实施例中还提供一种计算机可读存储介质,所述计算机可读存储介质包括计算机程序,当计算机程序在第一电子设备上运行时,使得所述第一电子设备执行上述第一方面或第二方面的任意一种可能的设计的方法。
37.第九方面,本技术实施例中还提供一种计算机可读存储介质,所述计算机可读存储介质包括计算机程序,当计算机程序在第二电子设备上运行时,使得所述第二电子设备执行上述第三方面或第四方面的任意一种可能的设计的方法。
38.第十方面,本技术实施例还提供一种包含计算机程序产品,当所述计算机程序产品在第一电子设备上运行时,使得所述第一电子设备执行上述第一方面或第二方面的任意一种可能的设计的方法。
39.第十一方面,本技术实施例还提供一种包含计算机程序产品,当所述计算机程序产品在第二电子设备上运行时,使得所述第二电子设备执行上述第三方面或第四方面的任意一种可能的设计的方法。
40.第十二方面,本技术实施例还提供一种芯片,所述芯片与存储器耦合,用于执行所述存储器中存储的计算机程序,以执行上述任一方面的任意一种可能的设计的方法。
41.以上第三方面至第十二方面中任一方面中的各种设计可以达到的技术效果,请参照上述第一方面或第二方面中各个设计分别可以达到的技术效果描述,这里不再重复赘述。
附图说明
42.图1为本技术实施例提供的一种应用场景示意图;
access,wcdma)通用分组无线业务(general packet radio service,gprs)系统、长期演进(long term evolution,lte)系统、lte频分双工(frequency division duplex,fdd)系统、lte时分双工(time division duplex,tdd)、通用移动通信系统(universal mobile telecommunication system,umts)、全球互联微波接入(worldwide interoperability for microwave access,wimax)等。其中,wi-fi direct,也可以被称为wi-fi点对点(wi-fi peer-to-peer),是一套软件协议,让wifi设备可以不必透过无线网络基地台(access point),以点对点的方式,直接与另一个wifi设备连线,进行高速数据传输。
60.应理解,图1所示的电子设备仅是一个范例,并且电子设备可以具有比图中所示出的更多的或者更少的部件,可以组合两个或更多的部件,或者可以具有不同的部件配置。图中所示出的各种部件可以在包括一个或多个信号处理和/或专用集成电路在内的硬件、软件、或硬件和软件的组合中实现。
61.本技术实施例中的电子设备可以是手机(mobile phone)、平板电脑(pad)、带无线收发功能的电脑、虚拟现实(virtual reality,vr)设备、增强现实(augmented reality,ar)设备、工业控制(industrial control)中的无线设备、无人驾驶(self driving)中的无线设备、远程医疗(remote medical)中的无线设备、智能电网(smart grid)中的无线设备、运输安全(transportation safety)中的无线设备、智慧城市(smart city)中的无线设备、智慧家庭(smart home)中的无线设备等等。参见图2,为本技术实施例提供的一种电子设备200的硬件结构示意图。
62.电子设200可包括处理器210、外部存储器接口220、内部存储器221、通用串行总线(universal serial bus,usb)接口230、充电管理模块240、电源管理模块241,电池242、天线1、天线2、移动通信模块250、无线通信模块260、音频模块270、扬声器270a、受话器270b、麦克风270c、耳机接口270d、传感器模块280、按键290、马达291、指示器292、摄像头293、显示屏294、以及用户标识模块(subscriber identification module,sim)卡接口295等。其中传感器模块280可以包括压力传感器280a、陀螺仪传感器280b、气压传感器280c、磁传感器280d、加速度传感器280e、距离传感器280f、接近光传感器280g、指纹传感器280h、温度传感器280j、触摸传感器280k、环境光传感器280l、骨传导传感器280m等。
63.可以理解的是,本技术实施例示意的结构并不构成对电子设备200的具体限定。在本技术另一些实施例中,电子设备200可以包括比图示更多或更少的部件,或者组合某些部件,或者拆分某些部件,或者不同的部件布置。图示的部件可以以硬件,软件或软件和硬件的组合实现。
64.处理器210可以包括一个或多个处理单元,例如:处理器210可以包括应用处理器(application processor,ap)、调制解调处理器、图形处理器(graphics processing unit,gpu)、图像信号处理器(image signal processor,isp)、控制器、视频编解码器、数字信号处理器(digital signal processor,dsp)、基带处理器、和/或神经网络处理器(neural-network processing unit,npu)等。其中,不同的处理单元可以是独立的器件,也可以集成在一个或多个处理器中。
65.电子设备200通过gpu,显示屏294,以及应用处理器等实现显示功能。gpu为图像处理的微处理器,连接显示屏294和应用处理器。gpu用于执行数学和几何计算,用于图形渲染。处理器210可包括一个或多个gpu,其执行程序指令以生成或改变显示信息。
66.电子设备200可以通过isp、摄像头293、视频编解码器、gpu、显示屏294以及应用处理器等实现拍摄功能。
67.sim卡接口295用于连接sim卡。sim卡可以通过插入sim卡接口295,或从sim卡接口295拔出,实现和电子设备200的接触和分离。电子设备200可以支持1个或n个sim卡接口,n为大于1的正整数。sim卡接口295可以支持nano sim卡、micro sim卡、sim卡等。同一个sim卡接口295可以同时插入多张卡。所述多张卡的类型可以相同,也可以不同。sim卡接口295也可以兼容不同类型的sim卡。sim卡接口295也可以兼容外部存储卡。电子设备200通过sim卡和网络交互,实现通话以及数据通信等功能。在一些实施例中,电子设备200采用esim,即:嵌入式sim卡。
68.电子设备200的无线通信功能可以通过天线1、天线2、移动通信模块250、无线通信模块260、调制解调处理器以及基带处理器等实现。天线1和天线2用于发射和接收电磁波信号。电子设备200中的每个天线可用于覆盖单个或多个通信频带。不同的天线还可以复用,以提高天线的利用率。例如:可以将天线1复用为无线局域网的分集天线。在另外一些实施例中,天线可以和调谐开关结合使用。
69.移动通信模块250可以提供应用在电子设备200上的包括2g/3g/4g/5g等无线通信的解决方案。移动通信模块250可以包括至少一个滤波器、开关、功率放大器、低噪声放大器(low noise amplifier,lna)等。移动通信模块250可以由天线1接收电磁波,并对接收的电磁波进行滤波,放大等处理,传送至调制解调处理器进行解调。移动通信模块250还可以对经调制解调处理器调制后的信号放大,经天线1转为电磁波辐射出去。在一些实施例中,移动通信模块250的至少部分功能模块可以被设置于处理器210中。在一些实施例中,移动通信模块250的至少部分功能模块可以与处理器210的至少部分模块被设置在同一个器件中。
70.无线通信模块260可以提供应用在电子设备200上的包括无线局域网(wireless local area networks,wlan)(如无线保真(wireless fidelity,wi-fi)网络)、蓝牙(bluetooth,bt)、全球导航卫星系统(global navigation satellite system,gnss)、调频(frequency modulation,fm)、近距离无线通信技术(near field communication,nfc)、红外线(infrared radiation,ir)技术等无线通信的解决方案。无线通信模块260可以是集成至少一个通信处理模块的一个或多个器件。无线通信模块260经由天线2接收电磁波,将电磁波信号调频以及滤波处理,将处理后的信号发送到处理器210。无线通信模块260还可以从处理器210接收待发送的信号,对其进行调频,放大,经天线2转为电磁波辐射出去。
71.在一些实施例中,电子设备200的天线1和移动通信模块250耦合,天线2和无线通信模块260耦合,使得电子设备200可以通过无线通信技术与网络以及其他设备通信。所述无线通信技术可以包括全球移动通讯系统(global system for mobile communications,gsm)、通用分组无线服务(general packet radio service,gprs)、码分多址接入(code division multiple access,cdma)、宽带码分多址(wideband code division multiple access,wcdma)、时分码分多址(time-division code division multiple access,td-scdma)、长期演进(long term evolution,lte)、bt、gnss、wlan、nfc、fm、和/或ir技术等。
72.电子设备200的结构也可参见图2电子设备200的结构,此处不再赘述。在本技术另一些实施例中,电子设备200可以包括比图示更多或更少的部件,或者组合某些部件,或者拆分某些部件,或者不同的部件布置。图示的部件可以以硬件,软件或软件和硬件的组合实
现。
73.电子设备200的软件系统可以采用分层架构,事件驱动架构,微核架构,微服务架构,或云架构。本技术实施例以分层架构的android系统为例,示例性说明电子设备200的软件结构。
74.图3是本发明实施例的电子设备的软件结构框图,该软件架构的软件模块和/或代码可以存储在内部存储器221中,当处理器210运行该软件模块或代码时,执行本技术实施例所提供的跑步姿态检测方法。
75.分层架构将软件分成若干个层,每一层都有清晰的角色和分工。层与层之间通过软件接口通信。在一些实施例中,将android系统分为四层,从上至下分别为应用程序层,应用程序框架层,安卓运行时(android runtime)和系统库,以及内核层。
76.应用程序层可以包括一系列应用程序包。
77.如图3所示,应用程序包可以包括电话、相机,图库,日历,通话,地图,导航,wlan,蓝牙,音乐,视频,短信息等应用程序。
78.应用程序框架层为应用程序层的应用程序提供应用编程接口(application programming interface,api)和编程框架。应用程序框架层包括一些预先定义的函数。
79.如图3所示,应用程序框架层可以包括窗口管理器,内容提供器,视图系统,电话管理器,资源管理器,通知管理器等。
80.窗口管理器用于管理窗口程序。窗口管理器可以获取显示屏大小,判断是否有状态栏,锁定屏幕,截取屏幕等。
81.内容提供器用来存放和获取数据,并使这些数据可以被应用程序访问。所述数据可以包括视频,图像,音频,拨打和接听的电话,浏览历史和书签,电话簿等。
82.视图系统包括可视控件,例如显示文字的控件,显示图片的控件等。视图系统可用于构建应用程序。显示界面可以由一个或多个视图组成的。例如,包括短信通知图标的显示界面,可以包括显示文字的视图以及显示图片的视图。
83.电话管理器用于提供电子设备的通信功能。例如通话状态的管理(包括接通,挂断等)。
84.资源管理器为应用程序提供各种资源,比如本地化字符串,图标,图片,布局文件,视频文件等等。
85.通知管理器使应用程序可以在状态栏中显示通知信息,可以用于传达告知类型的消息,可以短暂停留后自动消失,无需用户交互。比如通知管理器被用于告知下载完成,消息提醒等。通知管理器还可以是以图表或者滚动条文本形式出现在系统顶部状态栏的通知,例如后台运行的应用程序的通知,还可以是以对话窗口形式出现在屏幕上的通知。例如在状态栏提示文本信息,发出提示音,电子设备振动,指示灯闪烁等。
86.android runtime包括核心库和虚拟机。android runtime负责安卓系统的调度和管理。
87.核心库包含两部分:一部分是java语言需要调用的功能函数,另一部分是安卓的核心库。
88.应用程序层和应用程序框架层运行在虚拟机中。虚拟机将应用程序层和应用程序框架层的java文件执行为二进制文件。虚拟机用于执行对象生命周期的管理,堆栈管理,线
程管理,安全和异常的管理,以及垃圾回收等功能。
89.系统库可以包括多个功能模块。例如:表面管理器(surface manager),媒体库(media libraries),三维图形处理库(例如:opengl es),2d图形引擎(例如:sgl)等。
90.表面管理器用于对显示子系统进行管理,并且为多个应用程序提供了2d和3d图层的融合。
91.媒体库支持多种常用的音频,视频格式回放和录制,以及静态图像文件等。媒体库可以支持多种音视频编码格式,例如:mpeg4,h.264,mp3,aac,amr,jpg,png等。
92.三维图形处理库用于实现三维图形绘图,图像渲染,合成,和图层处理等。
93.2d图形引擎是2d绘图的绘图引擎。
94.内核层是硬件和软件之间的层。内核层至少包含显示驱动,摄像头驱动,音频驱动,传感器驱动。其中,硬件可以指的是各类传感器,例如本技术实施例中涉及的加速度传感器、陀螺仪传感器、触摸传感器、压力传感器等。
95.现有技术中,虽然在用户主动发出预设唤醒词“小艺小艺”或者“开始剪辑视频”时,会触发设备进行剪辑视频,但是,考虑到用户一旦沉浸观看视频程,很可能会忘记主动发出上述唤醒词相关的语音指令,导致用户错过视频剪辑时机,无法生成精彩视频片段。而当用户沉浸于观看视频时,更容易因为情绪被感染,用户无意识的发出“太美了”、“太壮观了”等语气词,或者用户有鼓掌、跺脚等行为。基于这一发现,因此本技术提供一种视频剪辑方法,该方法利用图像采集装置所采集到的观看视频的用户的视频,或利用语音采集装置所采集到的用户发出的与用户情绪相关的语音、肢体动作或面部表情,触发电子设备从用户观看的视频中截取出精彩视频片段。这样,用户不用主动发出固定的唤醒词,就可以完成视频剪辑,提升用户体验。
96.实施例1
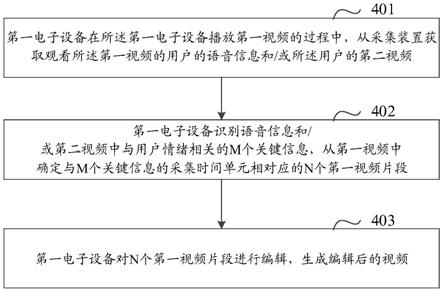
97.参见图4,为本技术实施例提供的一种视频剪辑方法流程示意图。该方法可以由图1所示的电子设备实现。以下以第一电子设备执行该方法为例进行说明,如图4所示,该流程包括:
98.步骤401,第一电子设备在所述第一电子设备播放第一视频的过程中,从采集装置获取观看所述第一视频的用户的语音信息和/或所述用户的第二视频。
99.其中,采集装置可以包括语音采集装置和图像采集装置等。语音采集装置可以是第一电子设备中音频模块,例如受话器、麦克风等。语音采集装置也可以是与第一电子设备连接的外设设备,如第一电子设备外接的麦克风,或者与第一电子设备无线连接的智能音箱等设备。也就是说,在用户观看第一视频的过程中,语音采集装置会实时地采集用户的语音信息。这样的话,语音采集装置能够采集到用户发出“太棒了”、“太精彩了”等语音信息,或者用户发出鼓掌的声音。另外,语音采集装置还能够采集到第一视频播放过程中,第一视频的语音信息。以足球比赛的直播视频播放过程为例,在一个足球比较中较为精彩的部分通常是进球场面,这时比赛视频中通常播放观众欢呼鼓掌的声音,若第一电子设备采用扬声器播放视频,则语音采集装置可以采集到观众欢呼鼓掌的声音。
100.示例性地,如图5a所示,用户在观看智能电视播放的足球比赛的直播视频过程中,可能发出“太棒了!”等感叹语句,这时,智能电视的音频模块(如麦克风)或智能音箱可以采集到用户在视频播放时段所发出的语音信息。
101.步骤402,第一电子设备识别语音信息和/或第二视频中与用户情绪相关的m个关键信息,从第一视频中确定与m个关键信息的采集时间单元相对应的n个第一视频片段。
102.其中,关键信息可以包括关键词和关键动作中的至少一个。
103.一种可能的实施例中,第一电子设备从语音采集装置获取到语音信息之后,第一电子设备基于预设的语音识别模型,对语音信息进行识别,例如通过声纹识别,从中识别出用户的语音信息,并将识别出来的用户的语音信息与预设语音模板进行匹配,从而确定出该语音信息中是否存在与用户相关的唤醒词,以及用户发出该唤醒词对应的语音的采集时间单元,继而,第一电子设备确定该采集时间单元对应的第一视频的第一视频片段。其中,唤醒词包括所述用户因情绪波动做出设定肢体动作所发出的声音(如鼓掌的声音)、用发出的设定语音信息(如各种感叹词)。预设语音模板可以是预先训练生成的与用户情绪相关的语音信息,利用鼓掌的声音,庆祝的声音、各种感叹词等。需要说明的是,关键信息还可以是声音的分贝大小等自然界中存在的信息,本技术实施例对此并不作限定。
104.在一种可能的实施例中,第一电子设备从图像采集装置获取到第二视频之后,第一电子设备基于预设的图像识别模型,对图像信息进行识别,从中识别出用户的肢体动作或表情等,并将识别出来的用户的肢体动作和表情与预先存储的设定肢体动作模板或设定面部表情模板进行匹配,从而确定出该第二视频中是否存在与用户相关的唤醒动作,以及用户作出该唤醒动作对应的采集时间单元,继而,第一电子设备确定该采集时间单元对应的第一视频的第一视频片段。需要说明的是,本技术实施例还可以将上述两种可能的实施例进行结合,从而确定出n个第一视频片段。
105.其中,第一电子设备确定采集时间单元对应的第一视频的第一视频片段的一种可能的方式是:第一电子设备可以预先将第一视频分割成l个第一视频片段,可以在关键信息的采集时间单元对应的第一视频的第一视频片段上打点;然后第一电子设备可以第一视频播放结束后,或者在第一视频的部分视频播放结束后,从第一视频中获取第一视频片段的打点信息,根据打点信息,从l个第一视频片段中确定与m个唤醒词的采集时间单元对应的所述第一视频的n个第一视频片段。也就是说,第一电子设备以固定时长(例如10秒)分割第一视频,这样,第一视频就被分割成多个第一视频片段,因此,第一电子设备就可以唤醒词的采集时间单元对应的第一视频的第一视频片段上打点。
106.示例性地,用户在足球比赛的直播视频播放过程中,当观看到进球画面时,发出“太棒了!”这一感叹语句,智能电视对获取的语音信息识别后,确定在北京时间9点45分10秒至北京时间9点45分11秒这一时间段内存在用户的该唤醒词,从而智能电视对北京时间9点45分11秒之前的10秒内智能电视所播放的足球比赛的直播视频片段打点,之后智能电视根据打点信息确定出被打点的第一视频片段。因为在进球之前,也就是在北京时间9点45分11秒之前的10秒内,很可能中锋逐个突围对方阻扰后,最后一脚射门的精彩时段。所以按照上述方法可以剪辑出足球比赛的直播视频的精彩视频片段。
107.需要说明的是,本技术实施例中并不限定所述打点信息中包括的打点位置的数量,可以是一个也可以是多个。另外,需要说明的是,关键信息的采集时间单元与第一视频片段的时间单元之间的对应关系可能存在多种情况:第一种可能的情况,关键信息的采集时间单元与视频片段的时间单元相同,例如,在北京时间9点45分10秒至北京时间9点45分11秒检测的唤醒词“太棒了”,智能电视可以剪辑北京时间9点45分10秒至北京时间9点45分
11秒这一秒内的视频片段;第二种可能的情况,视频片段的时间单元包含关键信息的采集单元,也就是说,在北京时间9点45分10秒至北京时间9点45分11秒检测的唤醒词“太棒了”,智能电视可以剪辑出北京时间9点45分11秒之前的10秒内的视频片段。或者,在北京时间11点30分10秒至北京时间11点30分11秒检测的唤醒词“开始了”,智能电视可以剪辑出北京时间11点30分11秒之后的10秒内的视频片段。本技术实施例对此并不作具体限定,可以根据实际经验确定关键信息的采集时间单元与视频片段的时间单元之间的关系。
108.步骤403,第一电子设备对n个第一视频片段进行编辑,生成编辑后的视频,其中,m和n为正整数。
109.可选地,在第一电子设备生成剪辑后的视频之后,用户可以将第一电子设备上的该视频分享至其他用户的电子设备,也可以分享至社交网络,如朋友圈等。
110.具体地,一种可能的方式是:第一电子设备可以将全部或者部分关键信息的采集时间单元对应的第一视频的第一视频片段进行拼接组合,合成精彩的视频片段。
111.在另一种可能的方式是:第一电子设备还可以确定n个第一视频片段相对应的所述第二视频的m个第二视频片段;其中,n个第一视频片段的播放时段与m个第二视频片段的采集时段相重叠,然后第一电子设备对n个第一视频片段和m个第二视频片段进行编辑,生成编辑后的视频,其中,m和n为正整数。其中,图像采集装置可以是第一电子设备中摄像头。图像采集装置也可以是与第一电子设备连接的外设设备,如第一电子设备外接的摄像头,或者与第一电子设备无线连接的智能摄像头等设备。也就是说,在用户观看第一视频的过程中,图像采集装置会实时地采集用户的图像信息。这样的话,图像采集装置能够采集到用户鼓掌的动作等图像信息,从而生成第二视频。
112.示例性地,用户在足球比赛的直播视频播放过程中,智能电视对获取的语音信息识别后,确定在北京时间9点45分10秒至北京时间9点45分11秒这一时间段内存在用户的唤醒词,从而智能电视不仅确定在北京时间9点45分10秒至北京时间9点45分11秒这一时段内,或者北京时间9点45分10秒之后的10秒内,智能电视所播放的足球比赛的直播视频片段,而且智能电视还确定在北京时间9点45分10秒至北京时间9点45分11秒这一时段,第二视频中的第二视频片段,最终,智能电视可以将第一视频中的第一视频片段和第二视频中的第二视频片段进行拼接组合,合成可以多窗口播放的精彩视频片段,示例性地,最终合成的可以多窗口播放的精彩视频片段可以如图5b所示。该方法通过多窗口播放精彩视频片段,有助于增加视频的趣味性。
113.结合图5c来说,用户发出设定语音信息或作出设定肢体动作时,会触发第一电子设备执行如下步骤:步骤501,第一电子设备识别到采集装置所采集到的语音或图像信息中的关键信息;步骤502,第一电子设备一方面从摄像头所采集的图像信息中获取摄像头缓存数据(即上文中的第二视频中的10s长度的第二视频片段),另一方面,第一电子设备获取缓存直播数据(即上文中的第一视频中的10s长度的第一视频片段);步骤503,第一电子设备生成精彩的视频片段文件,或者生成多个图片;步骤504,第一电子设备获取关联设备信息,例如用户的朋友的设备信息;步骤505,第一电子设备向关联设备分享链接。
114.本技术实施例中,电子设备基于观看视频的用户的无意识发出的语音或做出的动作,触发视频剪辑,该方法并不需要用户的主动触发视频剪辑,就可以生成精彩视频片段,有效地改善了用户体验。
115.实施例2
116.参见图6,为本技术实施例提供的一种视频剪辑方法流程示意图。该方法可以由图1所示的至少两个电子设备共同实现。以下以第一电子设备和第二电子设备执行该方法为例进行说明,如图6所示,该流程包括:
117.步骤601,第二电子设备在第一电子设备播放第一视频的过程中,从采集装置获取观看第一视频的用户的语音信息。
118.其中,该采集装置可以包括语音采集装置和图像采集装置等。其中,语音采集装置可以是二电子设备中音频模块,也可以是通过有线或无线连接的外部设备,图像采集装置也可以是与第二电子设备连接的外设设备,如第二电子设备外接的摄像头,或者与第二电子设备无线连接的智能摄像头等设备,具体参见上述实施例1的描述。
119.示例性地,如图7所示,用户在观看智能电视播放的足球比赛的直播视频过程中,可能发出“太棒了!”等感叹语句,这时,智能电视的音频模块(如麦克风)或智能音箱可以采集到用户在视频播放时段所发出的语音信息,用户的手机可以从语音采集装置获取该语音信息。
120.步骤602,第二电子设备识别所述语音信息和/或所述第二视频中与用户情绪相关的m个关键信息。
121.具体识别m个关键信息的方式可以参见上述步骤402,在此不再重复赘述。
122.示例性地,用户在足球比赛的直播视频播放过程中,发出“太棒了!”这一感叹语句,智能电视对获取的语音信息识别后,确定在北京时间9点45分10秒至北京时间9点45分11秒这一时间段内存在用户的唤醒词。
123.步骤603,第二电子设备从第一电子设备的第一视频中获取与m个关键信息的采集时间单元相对应的n个第一视频片段。
124.具体地,第二电子设备确定采集时间单元对应的第一视频的第一视频片段的一种可能的方式是:第二电子设备可以预先将第一视频分割成l个第一视频片段,可以在关键信息的采集时间单元对应的第一视频的第一视频片段上打点;然后第二电子设备可以第一视频播放结束后,或者在第一视频的部分视频播放结束后,从第一视频中获取第一视频片段的打点信息,根据打点信息,从l个第一视频片段中确定与m个唤醒词的采集时间单元对应的所述第一视频的n个第一视频片段。也就是说,第二电子设备以固定时长(例如10秒)分割第一视频,这样,第一视频就被分割成多个第一视频片段,因此,第二电子设备就可以唤醒词的采集时间单元对应的第一视频的第一视频片段上打点。
125.需要说明的是,本技术实施例中并不限定所述打点信息中包括的打点位置的数量,可以是一个也可以是多个。
126.示例性地,如图7所示,用户在足球比赛的直播视频播放过程中,发出“太棒了!”这一感叹语句,手机对获取的语音信息识别后,确定在北京时间9点45分10秒至北京时间9点45分11秒这一时间段内存在用户的唤醒词,从而手机从智能电视获取足球比赛的直播视频,并且手机在北京时间9点45分10秒至北京时间9点45分11秒这一时段内,或者北京时间9点45分10秒之后的10秒内,智能电视所播放的足球比赛的直播视频片段上打点,之后手机根据打点信息确定出被打点的第一视频片段。
127.步骤604,第二电子设备对n个第一视频片段进行编辑,生成编辑后的视频,其中,m
和n为正整数。
128.可选地,在第二电子设备生成剪辑后的视频之后,用户可以将第二电子设备上的该视频分享至其他用户的电子设备,也可以分享至社交网络,如朋友圈等。
129.具体地,一种可能的方式是:第二电子设备可以将全部或者部分关键信息的采集时间单元对应的第一视频的第一视频片段进行拼接组合,合成精彩的视频片段。
130.在另一种可能的方式是:第二电子设备还可以确定n个第一视频片段相对应的所述第二视频的m个第二视频片段;其中,n个第一视频片段的播放时段与所述m个第二视频片段的采集时段相重叠;第二电子设备对n个第一视频片段和m个第二视频片段进行编辑,生成编辑后的视频,其中,m和n为正整数。
131.示例性地,用户在足球比赛的直播视频播放过程中,手机对获取的语音信息识别后,确定在北京时间9点45分10秒至北京时间9点45分11秒这一时间段内存在用户的唤醒词,从而手机不仅确定在北京时间9点45分10秒至北京时间9点45分11秒这一时段内,智能电视所播放的足球比赛的直播视频片段,而且手机还从智能摄像头采集的第二视频中确定在北京时间9点45分10秒至北京时间9点45分11秒这一时段内,或者北京时间9点45分10秒之后的10秒内,第二视频中的第二视频片段,最终,手机可以将第一视频中的第一视频片段和第二视频中的第二视频片段进行拼接组合,合成可以多窗口播放的精彩视频片段,示例性地,最终合成的可以多窗口播放的精彩视频片段可以如图5b所示。
132.本技术实施例中,第二电子设备可以基于观看视频的用户的无意识发出的语音或作出的动作,触发剪辑第一电子设备所播放的视频,相比实施例1,该方法并不需要播放视频的设备具有视频编辑功能,通过分布式系统中多个设备合作完成视频剪辑,生成精彩视频片段,有效地改善用户体验。
133.实施例3
134.参见图8,为本技术实施例提供的另一种视频剪辑方法流程示意图。该方法可以由图1所示的电子设备实现。以下以第一电子设备执行该方法为例进行说明,如图8所示,该流程包括:
135.步骤801,在第一电子设备播放第一视频的过程中,第一电子设备从采集装置获取观看所述第一视频的用户的语音信息和/或所述用户的第二视频。
136.其中,该采集装置可以包括语音采集装置和图像采集装置等。其中,语音采集装置可以是二电子设备中音频模块,也可以是通过有线或无线连接的外部设备,图像采集装置也可以是与第二电子设备连接的外设设备,如第二电子设备外接的摄像头,或者与第二电子设备无线连接的智能摄像头等设备,具体参见上述实施例1的描述。
137.步骤802,第一电子设备将语音信息和/或第二视频按照采集时间单元进行划分,识别m个采集时间单元对应的语音信息和/或第二视频中的关键信息,确定m个采集时间单元分别对应的用户情绪评分。
138.具体地,第一电子设备确定m个采集时间单元分别对应的用户情绪评分的方法可以采用如下任意一下方式:
139.方式一,第一电子设备对语音信息中的唤醒词进行识别,根据识别结果,确定m个采集时间单元分别对应的用户情绪评分。
140.也就是说,第一电子设备从语音采集装置获取到语音信息之后,第一电子设备基
于预设的语音识别模型,对语音信息进行识别,例如声纹识别,从中识别出用户的语音信息,第一电子设备在基于预设的神经网络模型,确定每个采集时间单元所对应的用户情绪评分。
141.示例性地,若第一电子设备识别出第一采集时间单元(如北京时间9点45分10秒至北京时间9点45分20秒)内包括用户发出的语音信息“太棒了!”,则该第一采集时间单元的用户情绪评分为9分;若第一电子设备识别出第二采集时间单元(北京时间9点45分20秒至北京时间9点45分30秒)内不包括用户发出的语音信息,则该第二采集时间单元的用户情绪评分为0分。再比如,若第一电子设备识别出第三采集时间单元(如北京时间10点45分10秒至北京时间10点45分20秒)内,智能电视的扬声器发出欢呼鼓掌的声音,则该第三采集时间单元的用户情绪评分为9分;若第一电子设备识别出第四采集时间单元(北京时间10点45分20秒至北京时间10点45分30秒)内不包括任何语音信息,则该第四采集时间单元的用户情绪评分为0分。
142.方式二,第一电子设备对第二视频中关键动作进行识别;根据识别结果,确定m个采集时间单元分别对应的用户情绪评分。
143.也就是说,如图9,第一电子设备从图像采集装置获取到第二视频之后,第一电子设备基于预设的图像识别模型,对第二视频进行识别,从中识别出用户的表情、动作或语言中至少一个,第一电子设备在基于预设的神经网络模型,确定每个采集时间单元所对应的用户情绪评分。示例性地,若第一电子设备识别出第一采集时间单元(如北京时间9点45分10秒至北京时间9点45分20秒)内包括用户大笑的表情,则该第一采集时间单元的用户情绪评分为9分;若第一电子设备识别出第二采集时间单元(北京时间9点45分20秒至北京时间9点45分30秒)内用户表情平淡,则该第二采集时间单元的用户情绪评分为0分。
144.方式三,第一电子设备对语音信息中的唤醒词进行识别和对所述第二视频中关键动作中至少一个信息进行识别,根据识别结果,确定m个采集时间单元分别对应的用户情绪评分。
145.也就是说,第一电子设备结合上述实施例1和实施例2中的方式对语音信息和第二视频进行识别,综合识别结果,确定每个采集时间单元分别对应的用户情绪评分。
146.步骤803,第一电子设备根据与m个采集时间单元对应的用户情绪评分,从第一视频中确定l个第一视频片段分别对应的精彩度。
147.具体地,第一电子设备可以通过预设的函数,将m个采集时间单元对应的用户情绪评分转换为精彩度,本技术实施例并不限定函数的表征方式,凡是可以用户情绪评分转换为精彩度的函数均适用于本技术实施例。
148.示例性地,用户在足球比赛的直播视频播放过程中,发出“太棒了!”这一感叹语句,智能电视对获取的语音信息识别后,确定在北京时间9点45分10秒至北京时间9点45分11秒这一时间段内用户情绪情绪评分9分,从而智能电视确定在北京时间9点45分10秒至北京时间9点45分11秒这一时段内,或者北京时间9点45分10秒之后的10秒内,智能电视所播放的足球比赛的直播视频片段的精彩度为9分。
149.步骤804,第一电子设备对第一视频的l个第一视频片段中的精彩度大于设定阈值的n个第一视频片段进行编辑,生成编辑后的视频,其中,m、l和n为正整数。
150.可选地,在第一电子设备生成剪辑后的视频之后,用户可以将第一电子设备上的
该视频分享至其他用户的电子设备,也可以分享至社交网络,如朋友圈等。
151.具体地,第一电子设备可以采用以下任意一种方式剪辑视频:
152.一种可能的方式是:第一电子设备可以将全部或者部分精彩度大于设定阈值的第一视频片段进行拼接组合,合成精彩的视频片段。
153.在另一种可能的方式是:第一电子设备还可以确定n个第一视频片段相对应的第二视频的m个第二视频片段;其中,n个第一视频片段的播放时段与m个第二视频片段的采集时段相重叠,然后第一电子设备对n个第一视频片段和m个第二视频片段进行编辑,生成编辑后的视频,其中,m和n为正整数。具体示例可以参见上述实施例1。
154.本技术实施例中,电子设备基于观看视频的用户的无意识发出的语音或作出的动作,实现对用户的观影情绪的评分,从而评估视频片段的精彩度,完成视频剪辑,该方法并不需要用户的主动触发视频剪辑,就可以生成精彩视频片段,有效地改善了用户体验。
155.实施例4
156.参见图10,为本技术实施例提供的另一种视频剪辑方法流程示意图。该方法可以由图1所示的至少两个电子设备共同实现。以下以第一电子设备和第二电子设备执行该方法为例进行说明,如图10所示,该流程包括:
157.步骤1001,第二电子设备在第一电子设备播放第一视频的过程中,从采集装置获取观看第一视频的用户的语音信息和/或用户的第二视频。
158.其中,语音采集装置可以是第二电子设备中音频模块,也可以是通过有线或无线连接的外部设备,具体参见上述步骤401的描述。也就是说,在用户观看第一电子设备播放的第一视频的过程中,第二电子设备可以从语音采集装置获取用户的语音信息或第一视频的音频信息。
159.另外,图像采集装置可以是第二电子设备中摄像头。图像采集装置也可以是与第二电子设备连接的外设设备,如第二电子设备外接的摄像头,或者与第二电子设备无线连接的智能摄像头等设备。也就是说,在用户观看第一视频的过程中,图像采集装置可以实时地采集用户的图像信息。这样的话,图像采集装置能够采集到用户鼓掌的动作等图像信息,从而生成第二视频。
160.示例性地,如图7所示,用户在观看智能电视播放的足球比赛的直播视频过程中,可能发出“太棒了!”等感叹语句,这时,智能电视的音频模块(如麦克风)或智能音箱可以采集到用户在视频播放时段所发出的语音信息,用户的手机可以从语音采集装置获取该语音信息。
161.步骤1002,第二电子设备将语音信息和/或第二视频按照采集时间单元进行划分,识别m个采集时间单元对应的语音信息和/或第二视频中的关键信息,确定m个采集时间单元分别对应的用户情绪评分。
162.具体地,第二电子设备确定m个采集时间单元分别对应的用户情绪评分的方法可以采用如下任意一下方式:
163.方式一,第二电子设备对语音信息中的唤醒词进行识别,根据识别结果,确定m个采集时间单元分别对应的用户情绪评分。
164.方式二,第二电子设备对第二视频中用户的语言、表情和肢体动作中至少一个信息进行识别;根据识别结果,确定m个采集时间单元分别对应的用户情绪评分。
165.方式三,第二电子设备对语音信息中的唤醒词进行识别和对所述第二视频中用户的语言、表情和肢体动作中至少一个信息进行识别,根据识别结果,确定m个采集时间单元分别对应的用户情绪评分。
166.上述方式和具体示例可以参见上述步骤802。
167.步骤1003,第二电子设备从第一电子设备的第一视频中获取与m个采集时间单元对应的l个第一视频片段。
168.步骤1004,第二电子设备根据与m个采集时间单元对应的用户情绪评分,确定所述第一视频的l个第一视频片段分别对应的精彩度。
169.具体地,第二电子设备可以通过预设的函数,将m个采集时间单元对应的用户情绪评分转换为精彩度,本技术实施例并不限定函数的表征方式,凡是可以用户情绪评分转换为精彩度的函数均适用于本技术实施例。
170.步骤1005,第二电子设备对第一视频的l个第一视频片段中的精彩度大于设定阈值的n个第一视频片段进行编辑,生成编辑后的视频,其中,m、l和n为正整数。
171.第一视频片段进行编辑,生成编辑后的视频,其中,m、l和n为正整数。
172.可选地,在第二电子设备生成剪辑后的视频之后,用户可以将第二电子设备上的该视频分享至其他用户的电子设备,也可以分享至社交网络,如朋友圈等。
173.具体地,第二电子设备可以采用上述步骤804提供的任意一种方式剪辑视频,在此不再重复描述。
174.本技术实施例中,电子设备基于观看视频的用户的无意识发出的语音或作出的动作,实现对用户的观影情绪的评分,从而评估视频片段的精彩度,完成视频剪辑,该方法并不需要用户的主动触发视频剪辑,就可以生成精彩视频片段,有效地改善了用户体验。相比实施例3,该方法并不需要播放视频的设备具有视频编辑功能,通过分布式系统中多个设备合作完成视频剪辑,生成精彩视频片段,有效地改善了用户体验。
175.基于与方法实施例1和实施例3的同一发明构思,本发明实施例提供一种第一电子设备,具体用于实现上述实施例1和实施例3中第一电子设备执行的方法,该第一电子设备的结构如图11所示,包括播放单元1101、获取单元1102、确定单元1103和剪辑单元1104.
176.当第一电子设备拥有实现上述实施例1中第一电子设备执行的方法时,第一电子设备中各个模块单元执行如下动作:
177.所述播放单元1101,用于播放第一视频。
178.所述获取单元1102,用于在所述第一电子设备播放第一视频的过程中,从采集装置获取观看所述第一视频的用户的语音信息和/或所述用户的第二视频。
179.所述确定单元1103,用于识别所述语音信息和/或所述第二视频中与用户情绪相关的m个关键信息,确定与所述m个关键信息的采集时间单元相对应的所述第一视频的n个第一视频片段。
180.所述剪辑单元1104,用于对所述n个第一视频片段进行编辑,生成编辑后的视频,其中,m和n为正整数。
181.在一种可能的实施例中,所述确定单元1103,还用于确定所述n个第一视频片段相对应的所述第二视频的m个第二视频片段;其中,n个第一视频片段的播放时段与所述m个第二视频片段的采集时段相重叠;
182.所述剪辑单元1104,还用于对所述n个第一视频片段和m个第二视频片段进行编辑,生成编辑后的视频,其中,m和n为正整数。
183.在一种可能的实施例中,所述确定单元1103,具体用于:将所述第一视频分割成l个第一视频片段;当识别到所述关键信息时,在与所述关键信息的采集时间单元相对应的所述第一视频的第一视频片段上打点;
184.从所述第一视频中获取第一视频片段的打点信息,根据所述打点信息,从所述l个第一视频片段中确定与所述m个关键信息的采集时间单元相对应的n个第一视频片段。
185.其中,关键信息包括如下唤醒词或唤醒动作中的至少一个:
186.所述唤醒词包括所述用户因情绪波动做出设定肢体动作所发出的声音、发出的设定语音信息;所述唤醒动作包括所述用户因情绪波动做出的设定肢体动作、设定面部表情。
187.当第一电子设备用于实现上述实施例3中第一电子设备执行的方法时,第一电子设备中各个模块单元执行如下动作:
188.所述播放单元1101,用于播放第一视频。
189.所述获取单元1102,用于在第一电子设备播放第一视频的过程中,从采集装置获取观看所述第一视频的用户的语音信息和/或所述用户的第二视频。
190.所述确定单元1103,用于将所述语音信息和/或第二视频按照采集时间单元进行划分,识别所述m个采集时间单元对应的所述语音信息和/或第二视频中的关键信息,确定m个采集时间单元分别对应的用户情绪评分;根据与m个采集时间单元对应的用户情绪评分,确定所述第一视频的l个第一视频片段分别对应的精彩度。
191.所述剪辑单元1104,用于对第一视频的l个第一视频片段中的精彩度大于设定阈值的n个第一视频片段进行编辑,生成编辑后的视频,其中,m、l和n为正整数。
192.在一种可能的实施例中,所述确定单元1103,用于按照预设的神经网络模型,识别所述m个采集时间单元对应的所述语音信息和/或第二视频中的关键信息;
193.根据识别结果,确定m个采集时间单元分别对应的用户情绪评分。
194.在一种可能的实施例中,所述确定单元1103,用于确定所述n个第一视频片段相对应的所述第二视频的m个第二视频片段;其中,n个第一视频片段的播放时段与所述m个第二视频片段的采集时段相重叠;对n个第一视频片段和m个第二视频片段进行编辑,生成编辑后的视频,其中,m和n为正整数。
195.其中,关键信息包括如下唤醒词或唤醒动作中的至少一个:
196.所述唤醒词包括所述用户因情绪波动做出设定肢体动作所发出的声音、发出的设定语音信息;所述唤醒动作包括所述用户因情绪波动做出的设定肢体动作、设定面部表情。
197.基于与方法实施例2和实施例4的同一发明构思,本发明实施例还提供一种第二电子设备,具体用于实现上述实施例2和实施例4中第二电子设备执行的方法,该第二电子设备的结构如图12所示,包括获取单元1201、确定单元1202和剪辑单元1203,其中:
198.当第二电子设备用于实现上述实施例2中第二电子设备执行的方法时,第二电子设备中各个模块单元执行如下动作:
199.所述获取单元1201,用于在第一电子设备播放第一视频的过程中,从采集装置获取观看所述第一视频的用户的语音信息和/或所述用户的第二视频。
200.所述确定单元1202,用于识别所述语音信息和/或所述第二视频中与用户情绪相
关的m个关键信息。
201.所述获取单元1201,还用于从所述第一电子设备获取与所述m个关键信息的采集时间单元相对应的所述第一视频的n个第一视频片段。
202.所述剪辑单元1203,用于对所述n个第一视频片段进行编辑,生成编辑后的视频,其中,m和n为正整数。
203.在一种可能的实施例中,所述确定单元1202,还用于确定所述n个第一视频片段相对应的所述第二视频的m个第二视频片段;其中,n个第一视频片段的播放时段与所述m个第二视频片段的采集时段相重叠;所述剪辑单元1203,还用于对所述n个第一视频片段和m个第二视频片段进行编辑,生成编辑后的视频。
204.在一种可能的实施例中,所述确定单元1202,还用于将所述第一视频分割成l个第一视频片段;当识别到所述关键信息时,在与所述关键信息的采集时间单元相对应的所述第一视频的第一视频片段上打点;从所述第一视频中获取第一视频片段的打点信息,根据所述打点信息,从所述l个第一视频片段中确定与所述m个关键信息的采集时间单元相对应的n个第一视频片段。
205.当第二电子设备用于实现上述实施例4中第二电子设备执行的方法时,第二电子设备中各个模块单元执行如下动作:
206.所述获取单元1201,用于在第一电子设备播放第一视频的过程中,从采集装置获取观看所述第一视频的用户的语音信息和/或所述用户的第二视频。
207.所述确定单元1202,用于将所述语音信息和/或第二视频按照采集时间单元进行划分,识别所述m个采集时间单元对应的所述语音信息和/或第二视频中的关键信息,确定m个采集时间单元分别对应的用户情绪评分。
208.所述获取单元1201,还用于从所述第一电子设备获取与所述m个采集时间单元对应的所述第一视频的l个第一视频片段。
209.所述确定单元1202,还用于根据与m个采集时间单元对应的用户情绪评分,确定所述第一视频的l个第一视频片段分别对应的精彩度。
210.所述剪辑单元1203,用于对所述第一视频的l个第一视频片段中的精彩度大于设定阈值的n个第一视频片段进行编辑,生成编辑后的视频,其中,m、l和n为正整数。
211.在一种可能的实施例中,所述确定单元1202,用于,按照预设的神经网络模型,识别所述m个采集时间单元对应的所述语音信息和/或第二视频中的关键信息;
212.根据识别结果,确定m个采集时间单元分别对应的用户情绪评分。
213.在一种可能的实施例中,所述确定单元1202,还用于确定所述n个第一视频片段相对应的所述第二视频的m个第二视频片段;其中,n个第一视频片段的播放时段与所述m个第二视频片段的采集时段相重叠;所述剪辑单元1203,还用于对所述n个第一视频片段和m个第二视频片段进行编辑,生成编辑后的视频,其中,m和n为正整数。
214.其中,关键信息包括如下唤醒词或唤醒动作中的至少一个:
215.所述唤醒词包括所述用户因情绪波动做出设定肢体动作所发出的声音、发出的设定语音信息;所述唤醒动作包括所述用户因情绪波动做出的设定肢体动作、设定面部表情。
216.本实施例还提供一种计算机存储介质,该计算机存储介质中存储有计算机指令,当该计算机指令在电子设备上运行时,使得电子设备执行上述实施例所执行的一个或多个
步骤,以实现上述实施例中的方法。
217.本实施例还提供了一种程序产品,当该程序产品在计算机上运行时,使得计算机执行上述实施例中的一个或多个步骤,以实现上述实施例中的方法。
218.另外,本技术的实施例还提供一种装置,这个装置具体可以是芯片系统,组件或模块,该装置可包括相连的处理器和存储器;其中,存储器用于存储计算机执行指令,当装置运行时,处理器可执行存储器存储的计算机执行指令,以使芯片执行上述实施例中的一个或多个步骤,以实现上述实施例中的方法。
219.通过以上的实施方式的描述,所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将装置的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。上述描述的系统,装置和单元的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
220.在本技术实施例各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
221.所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本技术实施例的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)或处理器执行本技术各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:快闪存储器、移动硬盘、只读存储器、随机存取存储器、磁碟或者光盘等各种可以存储程序代码的介质。
222.以上所述,仅为本技术实施例的具体实施方式,但本技术实施例的保护范围并不局限于此,任何在本技术实施例揭露的技术范围内的变化或替换,都应涵盖在本技术实施例的保护范围之内。因此,本技术实施例的保护范围应以所述权利要求的保护范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。