技术特征:
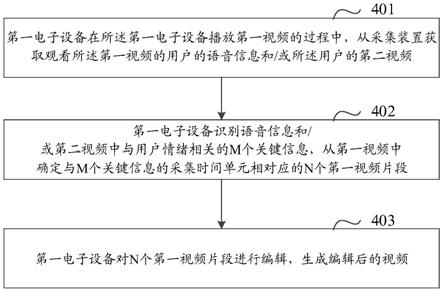
1.一种视频编辑方法,应用于第一电子设备,其特征在于,所述方法包括:在所述第一电子设备播放第一视频的过程中,从采集装置获取观看所述第一视频的用户的语音信息和/或所述用户的第二视频;识别所述语音信息和/或所述第二视频中与用户情绪相关的m个关键信息,在所述第一视频中确定与所述m个关键信息的采集时间单元相对应的n个第一视频片段;对所述n个第一视频片段进行编辑,生成编辑后的视频,其中,m和n为正整数。2.根据权利要求1所述的方法,其特征在于,所述方法还包括:确定所述n个第一视频片段相对应的所述第二视频的m个第二视频片段;其中,n个第一视频片段的播放时段与所述m个第二视频片段的采集时段相重叠;所述对所述n个第一视频片段进行编辑,生成编辑后的视频,包括:对所述n个第一视频片段和m个第二视频片段进行编辑,生成编辑后的视频。3.根据权利要求1或2所述的方法,其特征在于,所述方法还包括:将所述第一视频分割成l个第一视频片段;在所述第一视频中确定与所述m个关键信息的采集时间单元相对应的n个第一视频片段,包括:当识别到所述关键信息时,在所述l个第一视频片段中与所述关键信息的采集时间单元相对应的第一视频片段上打点;从所述第一视频中获取第一视频片段的打点信息,根据所述打点信息,从所述l个第一视频片段中确定与所述m个关键信息的采集时间单元相对应的n个第一视频片段。4.根据权利要求1至3任一项所述的方法,其特征在于,所述关键信息包括如下唤醒词或唤醒动作中的至少一个:所述唤醒词包括所述用户因情绪波动做出设定肢体动作所发出的声音、发出的设定语音信息;所述唤醒动作包括所述用户因情绪波动做出的设定肢体动作、设定面部表情。5.一种视频编辑方法,应用于第一电子设备,其特征在于,所述方法包括:在所述第一电子设备播放第一视频的过程中,从采集装置获取观看所述第一视频的用户的语音信息和/或所述用户的第二视频;将所述语音信息和/或第二视频按照采集时间单元进行划分,得到m个采集时间单元;根据所述m个采集时间单元对应的所述语音信息和/或第二视频中的关键信息,确定所述m个采集时间单元分别对应的用户情绪评分;根据所述用户情绪评分,在所述第一视频中确定与m个采集时间单元对应的l个第一视频片段的精彩度;对所述l个第一视频片段中的精彩度大于设定阈值的n个第一视频片段进行编辑,生成编辑后的视频,其中,m、l和n为正整数。6.根据权利要求5所述的方法,其特征在于,根据所述m个采集时间单元对应的所述语音信息和/或第二视频中的关键信息,确定所述m个采集时间单元分别对应的用户情绪评分,包括:按照预设的神经网络模型,识别所述m个采集时间单元对应的所述语音信息和/或第二视频中的关键信息;根据识别结果,确定所述m个采集时间单元分别对应的用户情绪评分。
7.根据权利要求5或6所述的方法,其特征在于,所述方法还包括:确定所述n个第一视频片段相对应的所述第二视频的m个第二视频片段;其中,n个第一视频片段的播放时段与所述m个第二视频片段的采集时段相重叠;所述对所述n个第一视频片段进行编辑,生成编辑后的视频,其中,n为正整数,包括:对所述n个第一视频片段和m个第二视频片段进行编辑,生成编辑后的视频,其中,m和n为正整数。8.根据权利要求5至7任一项所述的方法,其特征在于,所述关键信息包括如下唤醒词或唤醒动作中的至少一个:所述唤醒词包括所述用户因情绪波动做出设定肢体动作所发出的声音、发出的设定语音信息;所述唤醒动作包括所述用户因情绪波动做出的设定肢体动作、设定面部表情。9.一种视频编辑方法,应用第二电子设备,其特征在于,所述方法包括:在第一电子设备播放第一视频的过程中,从采集装置获取观看所述第一视频的用户的语音信息和/或所述用户的第二视频;识别所述语音信息和/或所述第二视频中与用户情绪相关的m个关键信息;从所述第一视频中获取与所述m个关键信息的采集时间单元相对应的n个第一视频片段;对所述n个第一视频片段进行编辑,生成编辑后的视频,其中,m和n为正整数。10.根据权利要求9所述的方法,其特征在于,所述方法还包括:确定所述n个第一视频片段相对应的所述第二视频的m个第二视频片段;其中,n个第一视频片段的播放时段与所述m个第二视频片段的采集时段相重叠;所述对所述n个第一视频片段进行编辑,生成编辑后的视频,包括:对所述n个第一视频片段和m个第二视频片段进行编辑,生成编辑后的视频。11.根据权利要求9或10所述的方法,其特征在于,所述方法还包括:将所述第一视频分割成l个第一视频片段;从所述第一视频中获取与所述m个关键信息的采集时间单元相对应的n个第一视频片段,包括:当识别到所述关键信息时,在所述l个第一视频片段中与所述关键信息的采集时间单元相对应的第一视频片段上打点;从所述第一视频中获取第一视频片段的打点信息,根据所述打点信息,从所述l个第一视频片段中确定与所述m个关键信息的采集时间单元相对应的n个第一视频片段。12.根据权利要求9至11任一项所述的方法,其特征在于,所述关键信息包括如下唤醒词或唤醒动作中的至少一个:所述唤醒词包括所述用户因情绪波动做出设定肢体动作所发出的声音、发出的设定语音信息;所述唤醒动作包括所述用户因情绪波动做出的设定肢体动作、设定面部表情。13.一种视频编辑方法,应用于第二电子设备,其特征在于,所述方法包括:在第一电子设备播放第一视频的过程中,从采集装置获取观看所述第一视频的用户的语音信息和/或所述用户的第二视频;将所述语音信息和/或第二视频按照采集时间单元进行划分,得到m个采集时间单元;根据所述m个采集时间单元对应的所述语音信息和/或第二视频中的关键信息,确定所
述m个采集时间单元分别对应的用户情绪评分;从所述第一视频中获取与所述m个采集时间单元对应的l个第一视频片段;根据所述用户情绪评分,确定所述l个第一视频片段的精彩度;对所述l个第一视频片段中的精彩度大于设定阈值的n个第一视频片段进行编辑,生成编辑后的视频,其中,m、l和n为正整数。14.根据权利要求13所述的方法,其特征在于,根据所述m个采集时间单元对应的所述语音信息和/或第二视频中的关键信息,确定所述m个采集时间单元分别对应的用户情绪评分,包括:按照预设的神经网络模型,识别所述m个采集时间单元对应的所述语音信息和/或第二视频中的关键信息;根据所述m个采集时间单元对应的所述语音信息和/或第二视频中的关键信息,确定m个采集时间单元分别对应的用户情绪评分。15.根据权利要求13或14所述的方法,其特征在于,所述方法还包括:确定所述n个第一视频片段相对应的所述第二视频的m个第二视频片段;其中,n个第一视频片段的播放时段与所述m个第二视频片段的采集时段相重叠;所述对所述n个第一视频片段进行编辑,生成编辑后的视频,其中,n为正整数,包括:对所述n个第一视频片段和m个第二视频片段进行编辑,生成编辑后的视频,其中,m和n为正整数。16.根据权利要求13至15任一项所述的方法,其特征在于,所述关键信息包括如下唤醒词或唤醒动作中的至少一个:所述唤醒词包括所述用户因情绪波动做出设定肢体动作所发出的声音、发出的设定语音信息;所述唤醒动作包括所述用户因情绪波动做出的设定肢体动作、设定面部表情。17.一种电子设备,其特征在于,所述电子设备包括处理器和存储器;所述存储器存储有程序指令;所述处理器用于运行所述存储器存储的所述程序指令,使得所述电子设备执行如权利要求1至16任一项所述的方法。18.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质包括程序指令,当所述程序指令在电子设备上运行时,使得所述电子设备执行如权利要求1至16任一项所述的方法。
技术总结
本申请提供了一种视频编辑方法及设备,该方法可以应用于具有视频播放功能的第一电子设备,也可以应用于具有视频处理功能的第二电子设备,示例性地,当方法由第一电子设备执行时,该方法包括:在第一电子设备播放第一视频的过程中,从语音采集装置或图像采集装置获取观看视频的用户的语音信息或第二视频;对语音信息中的唤醒词进行识别,或者对第二视频中的唤醒动作进行识别,从第一视频中确定与M个唤醒词或唤醒动作的采集时间单元对应的N个第一视频片段;对N个第一视频片段进行编辑,生成编辑后的视频。该方法基于观看视频的用户因情绪波动发出无意识发出的唤醒词或唤醒动作,实现从视频中剪辑出精彩视频片段。从视频中剪辑出精彩视频片段。从视频中剪辑出精彩视频片段。
技术研发人员:李国强 江英杰
受保护的技术使用者:华为技术有限公司
技术研发日:2020.09.02
技术公布日:2022/3/18
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。