技术特征:
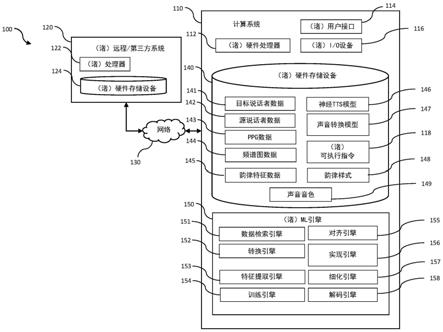
1.一种由计算系统实现的方法,所述方法用于生成针对目标说话者的采用源说话者的韵律样式的频谱图,所述方法包括:接收包括来自所述源说话者的源说话者数据的电子内容;通过将所述源说话者数据的波形与语音后验图(ppg)数据对齐来将所述源说话者数据的波形转换成ppg数据,其中所述ppg数据定义对应于所述源说话者数据的韵律样式的一个或多个特征;除了由所述ppg数据定义的所述一个或多个特征之外,从所述源说话者数据中提取一个或多个附加韵律特征;以及基于所述ppg数据、所提取的一个或多个附加韵律特征、以及所述目标说话者的声音音色来生成频谱图,其中所述频谱图由所述源说话者的韵律样式以及所述目标说话者的声音音色来表征。2.如权利要求1所述的方法,其特征在于,所述源说话者数据的波形按照比基于音素的粒度窄的一粒度与所述ppg数据对齐。3.如权利要求1所述的方法,其特征在于,所述源说话者数据的波形按照基于帧的粒度与所述ppg数据对齐。4.如权利要求1所述的方法,其特征在于,所述基于帧的粒度是基于多个帧的,每一帧包括12.5毫秒。5.如权利要求1所述的方法,其特征在于,从所述源说话者数据中提取的所述一个或多个附加韵律特征包括以下一者或多者:音高或能量。6.如权利要求5所述的方法,其特征在于,从所述源说话者数据中提取的所述一个或多个附加韵律特征包括所述能量,所述能量以所述源说话者数据的音量来被测量。7.如权利要求1所述的方法,其特征在于,所述一个或多个附加韵律特征是按照基于帧的粒度从所述源说话者数据的波形中被提取的。8.如权利要求1所述的方法,其特征在于,进一步包括:用所生成的频谱图来训练神经文本到语音(tts)模型,其中所述神经tts模型被配置成从任意文本生成语音数据,所述语音数据由所述源说话者的韵律样式以及所述目标说话者的声音音色来表征。9.如权利要求1所述的方法,其特征在于,所述方法包括所述计算系统定义所述源说话者的韵律样式,所述韵律样式包括以下之一:新闻播报员样式、讲故事样式、严肃样式、休闲样式、客服样式或基于情绪的样式,所述方法包括所述计算系统从多个可能的韵律样式中区分出所述韵律样式,所述多个可能的韵律样式包括所述新闻播报员样式、所述讲故事样式、所述严肃样式、所述休闲样式、所述客服样式以及所述基于情绪的样式。10.如权利要求1所述的方法,其特征在于,所述基于情绪的样式由所述计算系统检测为以下至少一者:快乐情绪、悲伤情绪、生气情绪、激动情绪或尴尬情绪,所述方法包括所述计算系统从多个可能的基于情绪的样式中区分出基于情绪的样式,所述多个可能的基于情绪的样式包括所述快乐情绪、所述悲伤情绪、所述生气情绪、所述激动情绪或所述尴尬情绪。11.一种由计算系统实现的方法,所述方法用于训练声音转换模块内的声音转换机器学习模型以生成针对目标说话者的具有源说话者的新韵律样式的频谱图,所述方法包括:
训练所述声音转换机器学习模型的语音后验图(ppg)到频谱图组件,其中所述声音转换机器学习模型的所述ppg到频谱图组件在训练期间最初在多说话者数据上被训练,并且被配置成用于将ppg数据转换成频谱图数据;用来自目标说话者的具有特定声音音色和特定韵律样式的目标说话者数据,通过将所述声音转换机器学习模型的所述ppg到频谱图组件适配成将ppg数据转换成具有所述目标说话者的特定韵律样式的频谱图数据,来细化所述ppg到频谱图组件;接收包括从源说话者数据的波形转换的新ppg数据的电子内容,其中所述新ppg数据与所述源说话者数据的波形对齐;接收从所述源说话者数据的波形中提取的一个或多个韵律特征;以及将所述源说话者数据应用于所述声音转换机器学习模型,其中所述声音转换机器学习模型的经细化的ppg到频谱图组件被配置成生成采用所述目标说话者的特定声音音色、但具有所述源说话者的所述新韵律样式而非所述目标说话者的特定韵律样式的频谱图。12.如权利要求11所述的方法,其特征在于,所述新ppg数据按照比基于音素的粒度窄的一粒度与所述源说话者数据的波形对齐。13.如权利要求11所述的方法,其特征在于,所述新ppg数据按照基于帧的粒度与所述源说话者数据的波形对齐。14.如权利要求13所述的方法,其特征在于,所述基于帧的粒度是基于多个帧的,每一帧包括约12.5毫秒。15.如权利要求11所述的方法,其特征在于,从所述源说话者数据的波形中提取的所述一个或多个韵律特征包括以下至少一者:音高轮廓、能量轮廓、说话历时或说话速率。16.如权利要求15所述的方法,其特征在于,所述声音转换机器学习模型的经细化的ppg到频谱图组件被配置成基于以下至少一者来生成采用所述目标说话者的特定声音音色、但具有所述源说话者的所述新韵律样式而非所述目标说话者的特定韵律样式的频谱图:从所述源说话者数据中提取的所述音高轮廓、能量轮廓、说话历时或说话速率。17.如权利要求15所述的方法,其特征在于,所述音高轮廓和/或所述能量轮廓是按照基于帧的粒度从所述源说话者数据的波形中被提取的。18.一种由计算系统实现的用于生成训练数据的方法,所述训练数据用于训练被配置成从任意文本生成语音数据的神经文本到语音(tts)模型,所述方法包括:接收包括来自源说话者的源说话者数据的电子内容;将所述源说话者数据的波形转换成语音后验图(ppg)数据;从所述源说话者数据中提取一个或多个韵律特征;将至少所述ppg数据和一个或多个所提取的韵律特征应用于声音转换模块的经预训练的ppg到频谱图组件,所述经预训练的ppg到频谱图组件被配置成生成采用目标说话者的特定声音音色、但具有所述源说话者的新韵律样式而非所述目标说话者的特定韵律样式的频谱图;以及生成被配置成用于训练神经tts模型的训练数据,所述训练数据包括由所述目标说话者的特定声音音色以及所述源说话者的新韵律样式来表征的多个频谱图。19.如权利要求18所述的方法,其特征在于,进一步包括:在所生成的训练数据上训练所述神经tts模型,以使得所述神经tts模型被配置成通过
执行跨说话者样式传递来从任意文本生成语音数据,其中所述语音数据由所述源说话者的韵律样式以及所述目标说话者的声音音色来表征。20.如权利要求19所述的方法,其特征在于,进一步包括:接收包括任意文本的电子内容;将所述任意文本作为输入应用于经训练的神经tts模型;以及生成包括基于所述任意文本的语音数据的输出,其中所述语音数据由所述源说话者的韵律样式以及所述目标说话者的声音音色来表征。
技术总结
各系统被配置成用于通过以下操作来生成由目标说话者的声音音色以及源说话者的韵律样式所表征的频谱图数据:将源说话者数据的波形转换成语音后验图(PPG)数据,从源说话者数据中提取附加韵律特征,以及基于PPG数据和所提取的韵律特征来生成频谱图。各系统被配置成利用/训练机器学习模型以用于生成频谱图数据以及用于用所生成的频谱图数据来训练神经的、文本到语音的模型。文本到语音的模型。文本到语音的模型。
技术研发人员:潘诗锋 何磊 李玉林 赵晟 马春玲
受保护的技术使用者:微软技术许可有限责任公司
技术研发日:2020.08.28
技术公布日:2022/3/18
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。