本发明的一个方式涉及一种音响装置及其工作方法。本发明的一个方式涉及一种信息处理系统及信息处理方法。
背景技术
近年来,语音识别技术的研发已在开展。借助于语音识别,例如,如果智能手机等信息终端的使用者说话,信息终端就可以执行该说话内容所包含的命令。
为了提高语音识别的精度,优选消除噪声。专利文献1公开了能够消除语音信号所包含的噪声的头戴式耳机。
[先行技术文献]
[专利文献]
[专利文献1]日本PCT国际申请翻译第2017-513411号公报
技术实现要素:
发明所要解决的技术问题
在信息终端进行语音识别的情况下,例如有时信息终端识别使用者以外的人的说话,这可能会导致信息终端做使用者意图之外的工作。
本发明的一个方式的目的之一是提供一种能够抑制信息终端的误动作的音响装置。本发明的一个方式的目的之一是提供一种能够消除噪声的音响装置。本发明的一个方式的目的之一是提供一种能够使信息终端进行高精度语音识别的音响装置。本发明的一个方式的目的之一是提供一种新颖的音响装置。
本发明的一个方式的目的之一是提供一种抑制误动作的信息处理系统。本发明的一个方式的目的之一是提供一种能够消除噪声的信息处理系统。本发明的一个方式的目的之一是提供一种能够进行高精度语音识别的信息处理系统。本发明的一个方式的目的之一是提供一种新颖的信息处理系统。
本发明的一个方式的目的之一是提供一种能够抑制信息终端的误动作的音响装置的工作方法。本发明的一个方式的目的之一是提供一种能够消除噪声的音响装置的工作方法。本发明的一个方式的目的之一是提供一种能够使信息终端进行高精度语音识别的音响装置的工作方法。本发明的一个方式的目的之一是提供一种新颖的音响装置的工作方法。
本发明的一个方式的目的之一是提供一种抑制误动作的信息处理方法。本发明的一个方式的目的之一是提供一种能够消除噪声的信息处理方法。本发明的一个方式的目的之一是提供一种能够进行高精度语音识别的信息处理方法。本发明的一个方式的目的之一是提供一种新颖的信息处理方法。
注意,上述目的的记载并不妨碍其他目的的存在。本发明的一个方式不一定需要实现所有上述目的。可以从说明书、附图、权利要求书等的记载中抽出上述目的以外的目的。
解决技术问题的手段
本发明的一个方式是一种音响装置,包括声音检测部、声音分离部、声音判定部以及处理部,声音检测部具有检测出第一声音的功能,声音分离部具有将第一声音分为第二声音和第三声音的功能,声音判定部具有登录声音的特征量的功能,声音判定部具有利用机器学习模型判定第二声音的特征量是否有登录的功能,处理部具有在第二声音的特征量有登录的情况下分析第二声音所包含的命令来生成表示命令的内容的信号的功能,并且处理部具有对第三声音进行用来消除第三声音的处理来生成第四声音的功能。
此外,在上述方式中,机器学习模型的学习也可以通过以语音为学习数据且以表示是否进行登录的标签为导师数据的有导师学习来进行。
此外,在上述方式中,机器学习模型也可以为神经网络模型。
此外,在上述方式中,第四声音与第三声音也可以为反相的声音。
此外,本发明的一个方式是一种音响装置的工作方法,在该工作方法中,检测出第一声音,将第一声音分为第二声音和第三声音,利用机器学习模型判定第二声音的特征量是否有登录,在第二声音的特征量有登录的情况下分析第二声音所包含的命令来生成表示命令的内容的信号,并且对第三声音进行用来消除第三声音的处理来生成第四声音。
此外,在上述方式中,机器学习模型的学习也可以通过以语音为学习数据且以表示是否进行登录的标签为导师数据的有导师学习来进行。
此外,在上述方式中,机器学习模型也可以为神经网络模型。
此外,在上述方式中,第四声音与第三声音也可以为反相的声音。
发明效果
根据本发明的一个方式,可以提供一种能够抑制信息终端的误动作的音响装置。根据本发明的一个方式,可以提供一种能够消除噪声的音响装置。根据本发明的一个方式,可以提供一种能够使信息终端进行高精度语音识别的音响装置。根据本发明的一个方式,可以提供一种新颖的音响装置。
根据本发明的一个方式,可以提供一种抑制误动作的信息处理系统。根据本发明的一个方式,可以提供一种能够消除噪声的信息处理系统。根据本发明的一个方式,可以提供一种能够进行高精度语音识别的信息处理系统。根据本发明的一个方式,可以提供一种新颖的信息处理系统。
根据本发明的一个方式,可以提供一种能够抑制信息终端的误动作的音响装置的工作方法。根据本发明的一个方式,可以提供一种能够消除噪声的音响装置的工作方法。根据本发明的一个方式,可以提供一种能够使信息终端进行高精度语音识别的音响装置的工作方法。根据本发明的一个方式,可以提供一种新颖的音响装置的工作方法。
根据本发明的一个方式,可以提供一种抑制误动作的信息处理方法。根据本发明的一个方式,可以提供一种能够消除噪声的信息处理方法。根据本发明的一个方式,可以提供一种能够进行高精度语音识别的信息处理方法。根据本发明的一个方式,可以提供一种新颖的信息处理方法。
注意,上述效果的记载并不妨碍其他效果的存在。本发明的一个方式不一定需要具有所有上述效果。可以从说明书、附图、权利要求书等的记载中抽出上述效果以外的效果。
附图简要说明
图1A是示出音响装置的结构例子的方框图。图1B1及图1B2是示出音响装置的具体例子的图。
图2A及图2B是示出音响装置的工作方法的一个例子的示意图。
图3是示出音响装置的工作方法的一个例子的流程图。
图4A至图4C是示出音响装置的工作方法的一个例子的示意图。
图5A及图5B是示出音响装置的工作方法的一个例子的示意图。
图6是示出音响装置的工作方法的一个例子的流程图。
图7A及图7B是示出音响装置的工作方法的一个例子的示意图。
图8是示出音响装置的工作方法的一个例子的流程图。
图9是示出音响装置的工作方法的一个例子的示意图。
图10是示出音响装置的工作方法的一个例子的流程图。
图11是示出音响装置的工作方法的一个例子的示意图。
实施发明的方式
以下参照附图详细地说明实施方式。注意,本发明不局限于以下说明,而所属技术领域的普通技术人员可以很容易地理解一个事实就是其方式及详细内容在不脱离本发明的宗旨及其范围的情况下可以被变换为各种各样的形式。因此,本发明不应该被解释为仅限定在以下所示的实施方式所记载的内容中。
注意,在下面说明的发明结构中,在不同的附图中共同使用相同的符号来表示相同的部分或具有相同功能的部分,而不反复说明。
此外,本说明书等所使用的“第一”、“第二”、“第三”等序数词是为了避免构成要素的混淆而附加的,而不是为了在数目方面上进行限定的。
(实施方式)
在本实施方式中,说明本发明的一个方式的音响装置及其工作方法。此外,还说明包括本发明的一个方式的音响装置的信息处理系统及使用该信息处理系统的信息处理方法。
<音响装置的结构例子>
本发明的一个方式的音响装置例如可以为耳机或头戴式耳机。本发明的一个方式的音响装置包括声音检测部、声音分离部、声音判定部、处理部、收发部以及声音输出部。在此,声音检测部例如可以包括麦克风。此外,声音输出部例如可以包括扬声器。
本发明的一个方式的音响装置与智能手机等信息终端电连接。在此,本发明的一个方式的音响装置与信息终端既可以有线方式连接又可以如Bluetooth(注册商标)、Wi-Fi(注册商标)等无线方式连接。本发明的一个方式的信息处理系统可以由本发明的一个方式的音响装置及信息终端构成。
在使用本发明的一个方式的音响装置之前,预先登录语音的特征量(声纹)。例如,登录本发明的一个方式的音响装置的使用者的语音的特征量。语音的特征量例如可以为该语音的频率特性。例如,可以为通过对表示语音的数据,即语音数据进行傅里叶变换而得到的频率特性。此外,作为语音的特征量,例如可以使用梅尔倒频谱系数(Mel-Frequency Cepstrum Coefficients:MFCC)。
在使用本发明的一个方式的音响装置时,如果声音检测部检测出声音,声音分离部就将该声音分为语音和语音以外的声音。在此,语音以外的声音例如是环境声音,例如可以说是噪声。
接着,声音判定部对声音分离部所分离出的语音进行特征量抽出,以判定所抽出的特征量是否有登录。在有登录的情况下,处理部分析语音所包含的命令来生成表示命令的内容的信号,即命令信号。此外,命令的分析例如可以通过语素分析等语言处理来进行。所生成的命令信号被输出到收发部。
另一方面,在声音判定部所抽出的特征量没有登录的情况下,不生成命令信号。
然后,处理部对声音分离部所分离出的语音以外的声音进行用来消除该声音的处理。例如,处理部生成与该声音反相的声音。
接着,收发部合成被处理部进行了处理的声音和信息终端所发出的声音,来将其输出到声音输出部。在此,例如在信息终端播放音乐时,信息终端所发出的声音可以为该音乐。
输出到声音输出部的声音向本发明的一个方式的音响装置的外部发出。本发明的一个方式的音响装置的使用者可以听声音检测部所检测出的声音和声音输出部所输出的声音的合成声音。如上所述,除了信息终端所发出的声音之外,声音输出部所输出的声音例如还可以包括与声音检测部所检测出的声音所包含的噪声反相的声音。如此,本发明的一个方式的音响装置的使用者例如可以听消除了噪声的声音。
此外,在处理部生成命令信号并将该信号输出到收发部的情况下,就是在声音分离部所分离出的语音的特征量有登录的情况下,收发部将命令信号输出到信息终端。信息终端执行命令信号所表示的命令。例如,在信息终端播放音乐且命令信号表示“更换音乐”的命令的情况下,可以将信息终端播放的音乐更换为指定的音乐。以上是本发明的一个方式的音响装置的工作方法的一个例子。
因为只在声音分离部所分离出的语音的特征量有登录的情况下处理部生成命令信号,所以例如与不管登录有无都生成命令信号的情况相比,可以抑制信息终端的误动作。例如,在将信息终端的使用者的语音的特征量登录在本发明的一个方式的音响装置中的情况下,可以抑制信息终端因收到使用者以外的语音而进行信息终端的使用者意图之外的工作。
在此,例如,通过利用机器学习模型,可以登录语音的特征量,并可以判定输入到声音判定部的语音的特征量是否有登录。作为机器学习模型,例如优选使用神经网络模型,由此可以进行高精度推理。作为神经网络模型,例如可以使用CNN(Convolutional Neural Network)、RNN(Recurrent Neural Network)等。作为机器学习模型的学习方法,例如可以使用有导师学习。
在使用有导师学习的情况下,例如,可以以语音的特征量为学习数据并以表示是否进行登录的标签为导师数据。
在使用有导师学习的情况下,可以以分为第一学习和第二学习的两个阶段的方式进行学习。也就是说,可以在进行第一学习之后追加进行第二学习。
在第一学习中,对所有学习数据赋予表示“不进行登录”的标签作为导师数据。在第一学习中,作为学习数据,优选使用多个人的语音的特征量。尤其是,特别优选例如均匀准备男声的学习数据、女声的学习数据、男声和女声中的高声、低声等各种声音质量的学习数据。由此,可以高精度地进行使用后述学习结果的推理,就是判定输入到声音判定部的语音的特征量是否有登录。
在第二学习中,对所有学习数据赋予表示“进行登录”的标签作为导师数据。也就是说,通过进行第二学习,可以登录语音的特征量。
在第二学习中,例如,以本发明的一个方式的音响装置的使用者的语音的特征量为学习数据。作为该学习数据,优选均匀使用同一人以各种发声方法发声的语音的特征量。此外,优选改变作为学习数据获得的语音数据的如声音高低等参数,以增加学习数据的数量。如此,可以高精度地进行使用学习结果的推理,就是判定输入到声音判定部的语音的特征量是否有登录。
例如,可以在本发明的一个方式的音响装置出货之前进行第一学习。另一方面,例如,可以在本发明的一个方式的音响装置出货之后进行第二学习。由此,例如,本发明的一个方式的音响装置的使用者自身可以进行第二学习。如此,在本发明的一个方式的音响装置中,使用者自身可以登录语音的特征量。
通过进行上述学习,声音判定部可以判定声音分离部所分离出的语音的特征量是否有登录。具体而言,如果声音判定部被输入语音,声音判定部就可以根据学习结果而推理输入到声音判定部的语音的特征量是否有登录。
通过使用机器学习模型判定语音的特征量是否有登录,与不使用机器学习模型进行该判定的情况相比可以进行高精度判定。由此,例如可以抑制与本发明的一个方式的音响装置电连接的信息终端执行特征量没有登录的语音所包含的命令。此外,例如可以抑制与本发明的一个方式的音响装置电连接的信息终端未执行特征量有登录的语音所包含的命令。也就是说,与本发明的一个方式的音响装置电连接的的信息终端可以进行高精度语音识别。
图1A是示出作为本发明的一个方式的音响装置的音响装置10的结构例子的图。为了说明音响装置10的功能等,除了音响装置10之外,图1A还示出声音21、信息终端22及耳朵23。在此,信息终端22例如可以为智能手机。此外,信息终端22可以为平板终端、膝上型PC、便携式(可以携带的)游戏机等便携式电子设备。此外,信息终端22也可以为便携式电子设备以外的电子设备。
音响装置10包括声音检测部11、声音分离部12、声音判定部13、存储部14、处理部15、收发部16以及声音输出部17。
在此,收发部16与信息终端22电连接。音响装置10与信息终端22既可以有线方式连接又可以如Bluetooth(注册商标)、Wi-Fi(注册商标)等无线方式连接。本发明的一个方式的信息处理系统可以由音响装置10及信息终端22构成。
在图1A中,箭头表示数据、信号等的流动。但是,图1A所示的流动只是一个例子,而不局限于图1A所示的流动。其他附图也与此同样。
声音检测部11具有检测出声音的功能。例如,具有检测出包括人的语音的声音21的功能。声音检测部11例如可以包括麦克风。
声音分离部12具有根据特性而分离声音检测部11所检测出的声音的功能。例如,声音分离部12具有如下功能:如果声音检测部11检测出包括人的语音的声音21,就将声音21分为语音和语音以外的声音。在此,语音以外的声音例如是环境声音,例如可以说是噪声。
声音分离部12例如具有对声音检测部11所检测出的声音根据该声音的频率而进行分离的功能。例如,人的语音主要由0.2kHz以上且4kHz以下的频率成分构成。因此,例如通过将声音检测部11所检测出的声音分为0.2kHz以上且4kHz以下的频率的声音和该频率以外的声音,可以分为语音和语音以外的声音。此外,人的语音的中间频率被认为是1kHz左右。因此,例如通过将声音检测部11所检测出的声音分为1kHz左右的频率的声音和该频率以外的声音,也可以分为语音和语音以外的声音。例如,也可以分为0.5kHz以上且2kHz以下的频率的声音和该频率以外的声音。此外,例如也可以根据声音检测部11所检测出的声音的种类而改变进行声音分离的频率。例如,在声音检测部11检测出包含女声的声音的情况下,也可以分离出具有比检测出包含男声的声音的情况高的频率的声音作为语音。通过根据声音检测部11所检测出的声音的种类而改变进行声音分离的频率,例如可以将声音检测部11所检测出的声音高精度地分为语音和语音以外的声音。
声音判定部13具有对声音分离部12所分离出的声音进行特征量抽出的功能。具体而言,例如具有对声音分离部12所分离出的语音进行特征量抽出的功能。此外,语音的特征量可以说是声纹。
特征量例如可以为频率特性。例如,可以为通过对表示声音的数据,即声音数据进行傅里叶变换而得到的频率特性。此外,作为声音的特征量,例如可以使用MFCC。
可以登录所抽出的特征量。例如,可以登录声纹。如此,声音判定部13可以说是具有登录声音的特征量的功能。登录结果可以储存在存储部14中。
此外,声音判定部13具有判定所抽出的特征量是否有登录的功能。例如,可以使用机器学习模型进行特征量的登录及上述判定。作为机器学习模型,例如优选使用神经网络模型,由此可以进行高精度推理。作为神经网络模型,例如可以使用CNN、RNN等。作为机器学习模型的学习方法,例如可以使用有导师学习。
处理部15例如具有对声音分离部12所输出的声音进行处理的功能。例如,具有分析声音分离部12所输出的语音所包含的命令来生成表示命令的内容的信号,即命令信号的功能。此外,命令的分析例如可以通过语素分析等语言处理来进行。
此外,处理部15具有进行用来消除声音分离部12所输出的声音中的噪声等的处理的功能。例如,通过生成与该噪声等反相的声音,可以消除声音分离部12所输出的噪声等。
在此,处理部15具有根据声音判定部13的判定结果进行处理的功能。例如,在声音分离部12输出语音的情况下,只在该语音的特征量有登录时,可以生成命令信号。
收发部16具有合成被处理部15进行了处理的声音和信息终端22所发出的声音的功能。在此,例如在信息终端22播放音乐时,信息终端22所发出的声音可以为该音乐。
此外,在处理部15生成命令信号的情况下,该命令信号可以被收发部16接收。收发部16具有将所接收的命令信号输出到信息终端22的功能。信息终端22具有执行命令信号所表示的命令的功能。例如,在信息终端22播放音乐且命令信号表示“更换音乐”的命令的情况下,可以将信息终端22播放的音乐更换为指定的音乐。
如上所述,例如只在声音分离部12所分离出的语音的特征量有登录的情况下,处理部15生成命令信号,由此,例如与不管登录有无都生成命令信号的情况相比,可以抑制信息终端22的误动作。例如,在将信息终端22的使用者的语音的特征量登录在音响装置10中的情况下,可以抑制信息终端22因收到使用者以外的语音而进行信息终端22的使用者意图之外的工作。
声音输出部17具有向音响装置10的外部发出收发部16所合成的声音的功能。音响装置10的使用者的耳朵23可以听声音检测部11所检测出的声音和声音输出部17所输出的声音的合成声音。如上所述,除了信息终端22所发出的声音之外,声音输出部17所输出的声音例如还可以包括与声音检测部11所检测出的声音所包含的噪声等反相的声音。如此,音响装置10的使用者例如可以听消除了噪声等的声音。此外,声音输出部17例如可以包括扬声器。
图1B1及图1B2是示出音响装置10的具体例子的图。如图1B1所示,音响装置10可以为耳机。具体而言,可以为信息终端22的使用者所佩戴的耳机。此外,如图1B2所示,音响装置10可以为头戴式耳机。具体而言,可以为信息终端22的使用者所佩戴的头戴式耳机。
<音响装置的工作例子>
以下说明音响装置10的工作方法的一个例子。图2A及图2B示出声音的特征量的登录方法的一个例子,其中声音判定部13具有利用机器学习模型判定声音的特征量是否有登录的功能。具体而言,图2A及图2B示出利用有导师学习的声音的特征量的登录方法的一个例子。
首先,如图2A所示,声音判定部13对声音数据31进行特征量抽出。例如,以声音数据31所表示的声音的频率特性为特征量。例如,可以以对声音数据31进行傅里叶变换而得到的频率特性为特征量。此外,例如可以使用MFCC作为特征量。
然后,将对表示所抽出的特征量的数据赋予表示“不进行登录”的标签,即标签32的数据输入到设置在声音判定部13中的生成器30。生成器30是使用机器学习模型的程序。生成器30以表示从声音数据31中抽出的特征量的数据为学习数据并以标签32为导师数据进行学习,由此输出学习结果33。学习结果33可以储存在存储部14中。此外,在生成器30为使用神经网络模型的程序的情况下,学习结果33可以为权系数。
作为用作学习数据的声音数据31,优选使用多个人的语音。尤其是,特别优选例如均匀准备男声的声音数据、女声的声音数据、男声和女声中的高声、低声等各种声音质量的声音数据来进行学习。由此,可以高精度地进行后述使用学习结果的推理,就是判定输入到声音判定部13的语音的特征量是否有登录。
接着,如图2B所示,声音判定部13对声音数据41进行特征量抽出。该特征量优选为与在图2A中用作学习数据的特征量相同种类的特征量。例如,在从声音数据31抽出MFCC来用作学习数据的情况下,优选也对声音数据41进行MFCC抽出。
然后,将对表示所抽出的特征量的数据赋予表示“进行登录”的标签,即标签42的数据输入到已读取学习结果33的生成器30。生成器30以表示从声音数据41中抽出的特征量的数据为学习数据并以标签42为导师数据进行学习,由此输出学习结果43。学习结果43可以储存在存储部14中。此外,在生成器30为使用神经网络模型的程序的情况下,学习结果43可以为权系数。
在图2A及图2B中,将表示“进行登录”的标签记为“登录○”,并且将表示“不进行登录”的标签记为“登录×”。其他附图也同样记载。
用作学习数据的声音数据41例如为音响装置10的使用者的语音。在使用语音作为声音数据41的情况下,优选均匀使用同一人以各种发声方法发声的语音的特征量来进行学习。此外,优选改变作为声音数据41获得的语音数据的如声音高低等参数,以增加声音数据41的数量来进行学习。如此,可以高精度地进行后述使用学习结果的推理,就是判定输入到声音判定部13的语音的特征量是否有登录。
如上所述,声音判定部13可以在如图2A所示那样以不进行登录的声音的特征量为学习数据来进行学习之后如图2B所示那样以进行登录的声音的特征量为学习数据来进行学习。也就是说,可以分为第一学习和第二学习这两个阶段来进行学习。具体而言,可以在进行图2A所示的第一学习之后追加进行图2B所示的第二学习。
例如,可以在音响装置10出货之前进行第一学习。另一方面,例如,可以在音响装置10出货之后进行第二学习。由此,例如,音响装置10的使用者自身可以进行第二学习。如此,在音响装置10中,使用者自身可以登录声音的特征量。
通过进行上述学习,声音判定部13例如可以判定声音分离部12所分离出的声音的特征量是否有登录。具体而言,如果声音判定部13被输入声音,声音判定部13就可以根据学习结果43而推理所输入的声音的特征量是否有登录。
通过使用机器学习模型判定声音的特征量是否有登录,与不使用机器学习模型进行该判定的情况相比可以进行高精度判定。由此,例如可以抑制与音响装置10电连接的信息终端22执行特征量没有登录的声音所包含的命令。此外,例如可以抑制与音响装置10电连接的信息终端22未执行特征量有登录的声音所包含的命令。也就是说,与音响装置10电连接的的信息终端22可以进行高精度语音识别。
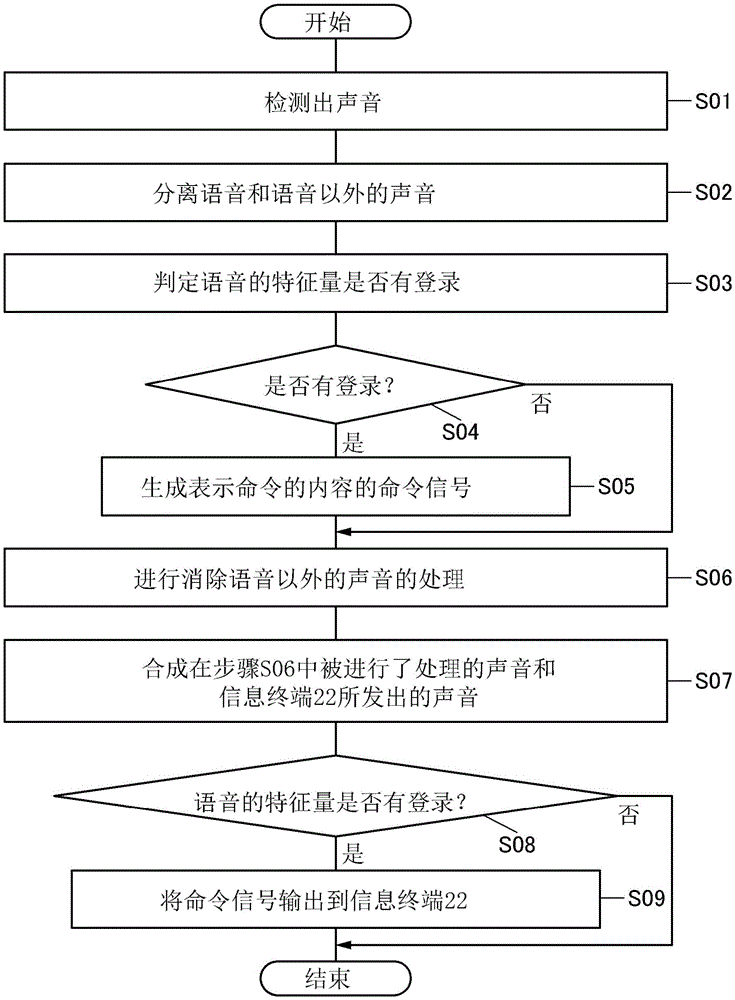
接着,说明使用音响装置10时的工作方法的一个例子。图3是示出使用音响装置10时的工作方法的一个例子的流程图。图4A至图4C、图5A及图5B是说明图3所示的各步骤的详细内容的示意图。以下假设通过图2A及图2B所示的方法等已登录声音的特征量的情况来进行说明。
如果声音检测部11检测出声音(步骤S01),声音分离部12就根据特性分离所检测出的声音。例如,在声音检测部11检测出包含人的语音的声音的情况下,声音分离部12将所检测出的声音分为语音和语音以外的声音(步骤S02)。如上所述,语音以外的声音例如是环境声音,例如可以说是噪声。
图4A示出步骤S02的具体例子。如上所述,声音分离部12例如具有对声音检测部11所检测出的声音根据该声音的频率而进行分离的功能。图4A示出根据频率将被声音检测部11检测出且输入到声音分离部12的声音21分为声音21a和声音21b的例子。
如上所述,人的语音例如主要由0.2kHz以上且4kHz以下的频率成分构成。因此,例如通过将声音检测部11所检测出的声音分为0.2kHz以上且4kHz以下的频率的声音和该频率以外的声音,可以分为语音和语音以外的声音。此外,人的语音的中间频率被认为是1kHz左右。因此,例如通过将声音检测部11所检测出的声音分为1kHz左右的频率的声音和该频率以外的声音,也可以分为语音和语音以外的声音。例如,也可以分为0.5kHz以上且2kHz以下的频率的声音和该频率以外的声音。此外,例如也可以根据声音检测部11所检测出的声音的种类而改变进行声音分离的频率。例如,在声音检测部11检测出包含女声的声音的情况下,也可以分离出具有比检测出包含男声的声音的情况高的频率的声音作为语音。通过根据声音检测部11所检测出的声音的种类而改变进行声音分离的频率,例如可以将声音检测部11所检测出的声音高精度地分为语音和语音以外的声音。
以下假设声音21a为语音且声音21b为语音以外的声音的情况来进行说明。
在声音分离部12将声音21分为语音,即声音21a和语音以外的声音,即声音21b之后,声音判定部13对声音21a进行特征量抽出以判定所抽出的特征量是否有登录(步骤S03)。具体而言,如图4B所示,通过将声音21a输入到例如已读取学习结果43的生成器30,并且生成器30输出表示登录有无的数据24,可以判定从声音21a抽出的特征量是否有登录。
在从声音21a抽出的特征量有登录的情况下,处理部15分析声音21a所包含的命令来生成表示命令的内容的信号,即命令信号(步骤S04及步骤S05)。命令的分析例如可以通过语素分析等语言处理来进行。另一方面,在从声音21a抽出的特征量没有登录的情况下,不分析命令也不生成命令信号(步骤S04)。
图4C示出声音21a所包含的命令为“更换音乐”的情况作为步骤S05所示的处理的具体例子。如图4C所示,如果包含“更换音乐”的命令的声音21a输入到处理部15,就输出表示“更换音乐”的命令的命令信号25。命令信号25输出到收发部16。此外,在图4C中,例如“更换音乐To:xxxxx”表示“音乐更换为xxxxx”的意思。其他附图也与此同样。
例如,为了使声音21a包含“更换音乐”的命令,例如其声纹有登录的人说出表示“更换音乐”的短语即可。通过声音检测部11检测出包含该短语的声音作为声音21,并且声音分离部12分离出声音21所包含的语音作为声音21a,可以使声音21a包含“更换音乐”的命令。由此,音响装置10可以说是具有语音识别的功能。
接着,处理部15对声音分离部12所分离出的语音以外的声音,即声音21b进行消除声音21b的处理(步骤S06)。例如,如图5A所示,将声音21b输入到处理部15,以输出与声音21b反相的声音26。
然后,收发部16合成被处理部15进行了处理的声音26和信息终端22所发出的声音,来将其输出到声音输出部17(步骤S07)。在此,例如在信息终端22播放音乐时,信息终端22所发出的声音可以为该音乐。
此外,在处理部15生成命令信号25并将该信号输出到收发部16的情况下,就是在声音分离部12所分离出的语音,即声音21a的特征量有登录的情况下,收发部16将命令信号25输出到信息终端22(步骤S08、步骤S09)。
图5B示出步骤S07至步骤S09的具体例子。在图5B中,示出与声音21b反相的声音,即声音26、表示“更换音乐”的命令的命令信号25以及从信息终端22发出的声音27输入到收发部16的例子。收发部16合成声音26和声音27,并将其输出到声音输出部17。输入到声音输出部17的声音向音响装置10的外部发出。音响装置10的使用者的耳朵23可以听声音检测部11所检测出的声音21和声音输出部17所输出的声音26及声音27的合成声音。
如上所述,声音26是分离出声音21所包含的噪声等成分,即声音21b的声音,例如是与声音21b反相的声音。由此,音响装置10的使用者例如可以听消除了噪声的声音。
此外,在命令信号25输入到收发部16的情况下,收发部16将命令信号25输出到信息终端22。信息终端22执行命令信号25所表示的命令。例如,在信息终端22播放音乐且命令信号25表示“更换音乐”的命令的情况下,可以将信息终端22播放的音乐更换为指定的音乐。以上是音响装置10的工作方法的一个例子。
只在声音分离部12所分离出的语音等声音的特征量有登录的情况下,处理部15生成命令信号25,由此,例如与不管登录有无都生成命令信号25的情况相比,可以抑制信息终端22的误动作。例如,在将信息终端22的使用者的语音的特征量登录在音响装置10中的情况下,可以抑制信息终端22因收到使用者以外的语音而进行信息终端22的使用者意图之外的工作。
在图3等所示的工作方法中,收发部16不管命令信号25所表示的命令的内容如何都将命令信号25输出到信息终端22,但是本发明的一个方式不局限于此。收发部16也可以根据命令的内容而将命令信号25输出到信息终端22以外的对象。
图6是示出使用音响装置10时的工作方法的一个例子的流程图,也是图3所示的工作方法的变形例子。图6所示的工作方法与图3所示的工作方法不同之处在于:图6所示的工作方法采用步骤S05a和步骤S09a分别代替步骤S05和步骤S09。
在步骤S05a中,分析声音分离部12所分离出的语音,即声音21a所包含的命令来生成表示命令的内容及命令输出对象的命令信号25。命令输出对象例如可以取决于命令种类。此外,在步骤S09a中,收发部16将命令信号25输出到指定的输出对象。
图7A及图7B示出图6所示的步骤S07、步骤S08及步骤S09a的具体例子。图7A示出命令信号25表示“更换音乐”的命令的情况。在此情况下,收发部16将命令信号25输出到信息终端22,信息终端22可以将所播放的音乐更换为指定的音乐。
图7B示出命令信号25表示“改变音量”的命令的例子。在此情况下,收发部16将命令信号25输出到声音输出部17,由此声音输出部17可以改变从信息终端22发出的声音27的大小。
例如,音响装置10的使用者也可以指定命令信号25的输出对象。例如,通过其声纹有登录的人说出指定命令信号25的输出对象的短语,也可以指定命令信号25的输出对象。
在图3等所示的工作方法中,在声音分离部12所分离出的声音21包含语音,即声音21a的情况下,即使从声音21a抽出的特征量没有登录,处理部15也不进行消除声音21a的处理,但是本发明的一个方式不局限于此。在从声音21a抽出的特征量没有登录的情况下,处理部15可以进行不仅消除语音以外的声音21b也消除语音,即声音21a的处理。
图8是示出使用音响装置10时的工作方法的一个例子的流程图,也是图3所示的工作方法的变形例子。图8所示的工作方法与图3所示的工作方法不同之处在于:在从声音21a抽出的特征量没有登录的情况(步骤S04)下,图8所示的工作方法进行步骤S06a代替步骤S06。图9是说明步骤S06a的详细内容的示意图。
在步骤S06a中,处理部15进行消除声音检测部11所检测出的所有声音21的处理。例如,如图9所示,将声音21输入到处理部15,来输出与声音21反相的声音作为声音26。
此外,在从声音21a抽出的特征量没有登录的情况下,处理部15也可以进行减小声音21a的大小的处理。
图10是示出使用音响装置10时的工作方法的一个例子的流程图,也是图8所示的工作方法的变形例子。图10所示的工作方法与图8所示的工作方法不同之处在于:图10所示的工作方法采用步骤S06b代替步骤S06a。
图11是说明步骤S06b的详细内容的示意图。在步骤S06b中,处理部15进行减小声音分离部12所分离出的声音21中的语音,即声音21a的大小并消除语音以外的声音,即声音21b的处理。例如,如图11所示,将声音21a及声音21b输入到处理部15。然后,处理部15进行使声音21a反相并减小振幅的处理。此外,进行使声音21b反相的处理。将处理部15所处理的声音作为声音26输出。
通过使用本实施方式所示的方法,可以抑制信息终端22的误动作。此外,因为可以消除噪声等,所以信息终端22可以进行高精度的语音识别。
[符号说明]
10:音响装置、11:声音检测部、12:声音分离部、13:声音判定部、14:存储部、15:处理部、16:收发部、17:声音输出部、21:声音、21a:声音、21b:声音、22:信息终端、23:耳朵、24:数据、25:命令信号、26:声音、27:声音、30:生成器、31:声音数据、32:标签、33:学习结果、41:声音数据、42:标签、43:学习结果。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。