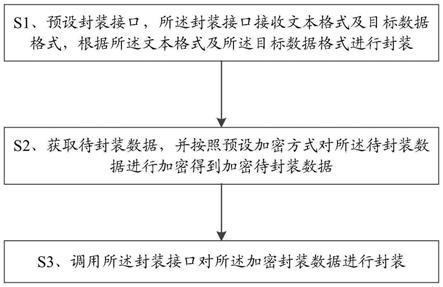
1.本发明涉及车辆轨迹数据挖掘技术领域,特别涉及一种车辆停靠点聚类的方法、装置、设备及存储介质。
背景技术:
2.在车联网技术中,车辆的停靠分析是一个重要的环节,准确地分析出车辆的停靠行为以及停靠地点有助于了解车辆的行驶行为。由于货车的停靠分析可以确定货车运营路线,经常停靠的物流园,加油站,维修点,企业等。所以货车的停靠分析对物流交易,货车供应链有重要价值。
3.现有技术中,常采用一些聚类算法对车辆的停靠点进行聚类,但在实际场景应用中,单纯使用聚类算法无法分割两个相邻的高密度区域,比如两个厂区挨着,货车停靠点数都很多,此时聚类算法会聚成一个簇,不满足实际需求。无法还原车辆常停靠区域及边界。
技术实现要素:
4.本技术实施例提供了一种车辆停靠点聚类的方法、装置、设备及存储介质。为了对披露的实施例的一些方面有一个基本的理解,下面给出了简单的概括。该概括部分不是泛泛评述,也不是要确定关键/重要组成元素或描绘这些实施例的保护范围。其唯一目的是用简单的形式呈现一些概念,以此作为后面的详细说明的序言。
5.第一方面,本技术实施例提供了一种车辆停靠点聚类的方法,包括:
6.根据车辆的历史轨迹数据提取车辆的停靠点数据;
7.通过密度峰值聚类算法对停靠点数据进行聚类,得到多个停靠点簇;
8.根据车辆的历史行驶轨迹,计算每个停靠点簇中网格之间的相似度;
9.根据网格之间的相似度对每个停靠点簇进行连通性分割,得到分割后的停靠点簇。
10.在一个可选地实施例中,根据车辆的历史轨迹数据提取车辆的停靠点数据之前,还包括:
11.获取预设时间段内车辆的历史轨迹数据。
12.在一个可选地实施例中,根据车辆的历史轨迹数据提取车辆的停靠点数据之后,还包括:
13.利用uberh3算法对车辆的停靠点数据进行网格化,得到网格化后的停靠点数据。
14.在一个可选地实施例中,通过密度峰值聚类算法对停靠点数据进行聚类,得到多个停靠点簇,包括:
15.根据预设的截断距离计算停靠点网格的局部密度;
16.计算停靠点网格与比起局部密度大的停靠点网格之间的距离,记为第一距离;
17.计算局部密度与第一距离的乘积,根据乘积确定出多个聚类中心;
18.根据确定出的多个聚类中心对停靠点网格进行聚类,得到多个停靠点簇。
19.在一个可选地实施例中,根据车辆的历史行驶轨迹,计算每个停靠点簇中网格之间的相似度,包括:
20.在每个停靠点簇中,计算停靠点网格与其预设范围内的停靠点网格之间的距离,记为第二距离;
21.根据车辆的历史行驶轨迹,计算车辆在该停靠点网格与其预设范围内的停靠点网格之间连续停靠的次数;
22.根据次数与第二距离的比值得到每两个停靠点网格之间的相似度。
23.在一个可选地实施例中,根据网格之间的相似度对每个停靠点簇进行连通性分割,得到分割后的停靠点簇,包括:
24.根据计算出来的网格之间的相似度确定连通阈值;
25.将相似度小于连通阈值的两个网格进行分割,得到分割后的停靠点簇。
26.在一个可选地实施例中,得到分割后的停靠点簇之后,还包括:
27.获取分割后的停靠点簇的边界信息以及poi信息;
28.根据边界信息自动标注poi的边界。
29.第二方面,本技术实施例提供了一种车辆停靠点聚类的装置,包括:
30.停靠点提取模块,用于根据车辆的历史轨迹数据提取车辆的停靠点数据;
31.第一聚类模块,用于通过密度峰值聚类算法对停靠点数据进行聚类,得到多个停靠点簇;
32.相似度计算模块,用于根据车辆的历史行驶轨迹,计算每个停靠点簇中网格之间的相似度;
33.第二聚类模块,用于根据网格之间的相似度对每个停靠点簇进行连通性分割,得到分割后的停靠点簇。
34.第三方面,本技术实施例提供了一种车辆停靠点聚类的设备,包括处理器和存储有程序指令的存储器,处理器被配置为在执行程序指令时,执行上述实施例提供的车辆停靠点聚类的方法。
35.第四方面,本技术实施例提供了一种计算机可读介质,其上存储有计算机可读指令,计算机可读指令被处理器执行以实现上述实施例提供的一种车辆停靠点聚类的方法。
36.本技术实施例提供的技术方案可以包括以下有益效果:
37.本技术实施例提供的车辆停靠点聚类的方法,主要通过对车辆历史上报的轨迹点做停靠判别,然后对所有车辆的停靠点做密度峰值聚类。在密度峰值聚类的基础上,结合实际业务场景,针对每个连通区域通过车辆的停靠序列计算网格之间的相似度,根据网格之间的相似度对聚类结果进一步分割,得到更贴近于真实情况的区域边界。省去了大量测绘及人工标注poi(point of interest,兴趣点)边界的复杂工作,对货车进出围栏及货车装卸判别有重要意义。
38.应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本发明。
附图说明
39.此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本发明的实施
例,并与说明书一起用于解释本发明的原理。
40.图1是根据一示例性实施例示出的一种车辆停靠点聚类的方法流程示意图;
41.图2是根据一示例性实施例示出的另一种车辆停靠点聚类的方法流程示意图;
42.图3是根据一示例性实施例示出的一种停靠点网格化的示意图;
43.图4是根据一示例性实施例示出的一种选取聚类中心的示意图;
44.图5是根据一示例性实施例示出的一种分割后的停靠点簇的示意图;
45.图6是根据一示例性实施例示出的另一种分割后的停靠点簇的示意图;
46.图7是根据一示例性实施例示出的一种车辆停靠点聚类的装置结构示意图;
47.图8是根据一示例性实施例示出的一种车辆停靠点聚类的设备结构示意图;
48.图9是根据一示例性实施例示出的一种计算机存储介质的示意图。
具体实施方式
49.以下描述和附图充分地示出本发明的具体实施方案,以使本领域的技术人员能够实践它们。
50.应当明确,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
51.下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本发明相一致的所有实施方式。相反,它们仅是如所附权利要求书中所详述的、本发明的一些方面相一致的系统和方法的例子。
52.通常,常采用一些聚类算法对车辆的停靠点进行聚类,但在实际场景应用中,单纯使用聚类算法无法分割两个相邻的高密度区域,比如两个厂区挨着,货车停靠点数都很多,此时聚类算法会聚成一个簇,不满足实际需求。无法还原车辆常停靠区域及边界。例如,一个车在某工厂100m处,但车是在场内还是场外无法确认。
53.基于此,本技术实施例提供了一种车辆的停靠点聚类方法,主要通过对车辆历史上报的轨迹点做停靠判别,然后对所有车辆的停靠点做空间聚类。由于停靠点数据量大,使用uberh3网格对停靠点进行统计后,基于网格做密度峰值聚类。然后对密度峰值中心做连通性分割,针对每个连通区域通过车辆的停靠序列计算网格之间的相似度,根据网格之间的相似度对聚类区域再次进行连通性分割,得到更贴近于真实情况的区域边界。省去了大量测绘及人工标注poi边界的复杂工作,对货车进出围栏及货车装卸判别有重要意义。
54.下面将结合附图对本技术实施例提供的车辆停靠点聚类的方法进行详细介绍。参见图1,该方法具体包括以下步骤。
55.s101根据车辆的历史轨迹数据提取车辆的停靠点数据。
56.在一种可能的实现方式中,首先获取预设时间段内车辆的历史轨迹数据,例如,获取近一个月内车辆的gps轨迹数据。其中,gps轨迹点是部署在车辆上的gps(globalpositioning system,全球定位系统)设备实时上报的车辆位置数据。通常,gps设备在实时上报时,上报的时间间隔可以根据实际情况进行设定,本技术优选时间间隔为10s。需要说明的是,本技术除了采用车辆安装gps设备实时上报车辆的轨迹数据之外,还可
以是由北斗设备定位车辆轨迹并进行上报。
57.进一步地,获取到轨迹点数据之后,还包括提取轨迹点数据中的异常数据。其中,异常数据包括速度错误数据、经纬度错误数据、掉线数据、未定位数据等信息错误数据。删除异常数据,得到预处理后的轨迹数据。
58.提取预处理后的车辆轨迹数据中车辆的停靠点数据。
59.具体地,获取轨迹信息中速度为0的点,并按时间间隔阈值和偏移量阈值进行合并,例如,将10分钟之内的多个停靠点进行合并,将50米之内的多个停靠点进行合并,获得以质心表示的停靠点。通过该步骤,可以对小停靠做一定范围的聚合,然后计算停靠时间,筛选出大于预设停靠阈值的停靠点,从而确定车辆发生停靠行为。本技术中优选停靠阈值为5分钟,本领域技术人员可根据实际情况自行设定。
60.根据该步骤,可以对车辆的历史轨迹数据做停靠判别,得到车辆的历史停靠数据。
61.s102通过密度峰值聚类算法对停靠点数据进行聚类,得到多个停靠点簇。
62.在一种可能的实现方式中,由于停靠点数据量大,在通过密度峰值聚类算法对停靠点进行聚类之前,还包括利用uberh3算法对车辆的停靠点数据进行网格化,得到网格化后的停靠点数据。
63.uberh3是一个使用六边形网格的地理空间索引系统,通过uberh3对停靠点进行网格化,在一种可能的实现方式中,网格级别设置为9,计算每个网格内的停靠车辆数,作为该网格的密度,网格内所有停靠点的经纬度平均值作为该网格的经纬度。
64.图3是根据一示例性实施例示出的一种停靠点网格化的示意图,如图3所示,左半部分是网格化之前的停靠点数据,数据量大且较为密集,右半部分是网格化后的停靠点数据,较为清晰,方便后续对停靠数据进一步分析。
65.进一步地,通过密度峰值聚类算法对停靠点数据进行聚类,得到多个停靠点簇。
66.基于密度峰值的聚类算法全称为基于快速搜索和发现密度峰值的聚类算法(clustering by fast search and find of density peaks,dpc)。该算法能够自动地发现簇中心,实现任意形状数据的高效聚类。该算法基于两个基本假设:(1)簇中心(密度峰值点)的局部密度大于围绕它的邻居的局部密度;(2)不同簇中心之间的距离相对较远。为了找到同时满足这两个条件的簇中心,该算法引入了局部密度的定义。
67.首先,根据预设的截断距离计算停靠点网格的局部密度。
68.具体地,计算停靠点网格xi和停靠点网格xj之间的距离d
ij
。然后,获取预设的截断距离dc,截断距离可根据实际业务场景自行确定。到停靠点网格xi的距离小于截断距离的停靠点网格的个数即为停靠点网格xi的局部密度ρi。
[0069][0070]
其中,
[0071]
计算停靠点网格与比起局部密度大的停靠点网格之间的距离,记为第一距离δi。
[0072][0073]
计算局部密度与第一距离的乘积γi,根据乘积γi确定出多个聚类中心。
[0074]
γi=ρi*δi[0075]
在一种可能的实现方式中,局部密度和第一距离都较大的点为聚类中心,因此,可根据局部密度与第一距离的乘积确定聚类中心。对局部密度与第一距离的乘积从高到低进行排序,乘积较高的点为聚类中心点。
[0076]
图4是根据一示例性实施例示出的一种选取聚类中心的示意图,如图4所示,对γ值进行从高到低排序,通过γ降序图确定出聚类中心的分割点,称其为奇异点,奇异点之前的点为聚类中心,奇异点的确定通过寻找min(∠abic))得到。其中,局部密度较低但是第一距离较大的点为噪声点。
[0077]
得到多个聚类中心之后,将每个剩余点分配到他的最近邻且局部密度比他大的聚类中心所在的簇,得到聚类后的多个停靠点簇。
[0078]
s103根据车辆的历史行驶轨迹,计算每个停靠点簇中网格之间的相似度。
[0079]
根据上述方法进行聚类之后,能够自动地发现簇中心,实现任意形状数据的高效聚类,但在实际场景应用中,单纯使用密度峰值聚类无法分割两个相邻的高密度区域,比如两个厂区挨着,货车停靠点数都很多,此时dpc会聚成一个簇,不满足实际需求。因此,对聚类后的簇继续进行分割。
[0080]
具体地,在每个停靠点簇中,计算停靠点网格与其预设范围内的停靠点网格之间的距离,记为第二距离。在一种可能的实现方式中,由于两个网格之间的距离较远,无需进行连通性分析,只计算某停靠点网格与其外围三圈内的网格之间的第二距离d
ij
。
[0081]
然后获取车辆的行驶轨迹,计算车辆在该停靠点网格与其预设范围内的停靠点网格之间连续停靠的次数c
ij
。c
ij
表示车辆在网格i停靠后又停靠在网格j的次数,若车辆在网格i和网格j之间连续停靠,中间没有经过其他网格,说明这两个网格之间的连通性较大,可能位于同一个厂区。
[0082]
根据次数与第二距离的比值得到每两个停靠点网格之间的相似度。在一种可能的实现方式中,根据如下公式计算某两个网格之间的相似度:
[0083]wij
=c
ij
/d
ij
[0084]
其中,w
ij
表示停靠点网格之间的相似度,c
ij
表示在网格i和网格j之间连续停靠的次数,d
ij
表示网格i和网格j之间的距离。
[0085]
根据该步骤,可以基于车辆的停靠序列,分析网格之间的连通性。
[0086]
s104根据网格之间的相似度对每个停靠点簇进行连通性分割,得到分割后的停靠点簇。
[0087]
根据计算出来的网格之间的相似度确定连通阈值,例如,取计算出来的相似度的八分位数作为连通阈值,本技术实施例对阈值的取值不做具体限定,可根据实际情况自行设定。将相似度小于连通阈值的两个网格进行分割,得到分割后的停靠点簇。
[0088]
图5和图6是分割后的停靠点簇的示意图,如图5和图6所示,即使停靠点比较密集,也能基于网格的连通性分割出符合真实情况的停靠点簇。
[0089]
根据该步骤,在传统的dpc聚类基础上,结合实际业务场景,引入了基于车辆停靠序列的网格间相似度,对聚类结果进一步划分,得到更贴近于真实情况的区域边界。
[0090]
通常,地图中poi包含名称、类别、经纬度信息,如学校,餐馆,企业等都是一个poi,poi在日常的生产生活中有重要作用。但由于poi只是一个点,只能判断靠近而不能判断进
出,比如一个车在某工厂100m处,但车是在厂内还是厂外无法确认。需要人工标注poi的边界,判断车辆是否进出围栏。
[0091]
在本技术实施例中,得到分割后的停靠点簇之后,还包括获取分割后的停靠点簇的边界信息以及poi信息,根据停靠点簇中边界网格的经纬度信息,可以自动标注poi的边界。省去了大量测绘及人工标注poi边界的复杂工作,对货车进出围栏及货车装卸判断有重要意义。
[0092]
为了便于理解本技术实施例提供的车辆停靠点聚类的方法,下面结合附图2进行说明。如图2所示,该方法包括如下步骤。
[0093]
首先,获取车辆的原始轨迹点数据,然后进行停靠点识别,根据车辆的轨迹数据提取出车辆的停靠点数据。
[0094]
进一步地,由于停靠点数据量大,通过uberh3算法对停靠点数据进行网格化,得到网格化后的停靠点数据。
[0095]
采用密度峰值聚类算法对停靠点网格进行聚类,得到多个聚类中心,根据聚类中心进行连通性分割,得到聚类后的多个停靠点簇。
[0096]
根据车辆的历史停靠序列,计算每个停靠点簇中网格之间的相似度,根据网格之间的相似度再次进行连通性分割,得到分割后的停靠点簇。
[0097]
根据本技术实施例提供的车辆停靠点聚类的方法,主要通过对车辆历史上报的轨迹点做停靠判别,然后对所有车辆的停靠点做密度峰值聚类。在密度峰值聚类的基础上,结合实际业务场景,针对每个连通区域通过车辆的停靠序列计算网格之间的相似度,根据网格之间的相似度对聚类结果进一步分割,得到更贴近于真实情况的区域边界。省去了大量测绘及人工标注poi边界的复杂工作,对货车进出围栏及货车装卸判别有重要意义。
[0098]
本技术实施例还提供一种车辆停靠点聚类的装置,该装置用于执行上述实施例的车辆停靠点聚类的方法,如图7所示,该装置包括:
[0099]
停靠点提取模块701,用于根据车辆的历史轨迹数据提取车辆的停靠点数据;
[0100]
第一聚类模块702,用于通过密度峰值聚类算法对停靠点数据进行聚类,得到多个停靠点簇;
[0101]
相似度计算模块703,用于根据车辆的历史行驶轨迹,计算每个停靠点簇中网格之间的相似度;
[0102]
第二聚类模块704,用于根据网格之间的相似度对每个停靠点簇进行连通性分割,得到分割后的停靠点簇。
[0103]
需要说明的是,上述实施例提供的车辆停靠点聚类的装置在执行车辆停靠点聚类的方法时,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将设备的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。另外,上述实施例提供的车辆停靠点聚类的装置与车辆停靠点聚类的方法实施例属于同一构思,其体现实现过程详见方法实施例,这里不再赘述。
[0104]
本技术实施例还提供一种与前述实施例所提供的车辆停靠点聚类的方法对应的电子设备,以执行上述车辆停靠点聚类的方法。
[0105]
请参考图8,其示出了本技术的一些实施例所提供的一种电子设备的示意图。如图8所示,电子设备包括:处理器800,存储器801,总线802和通信接口803,处理器800、通信接
口803和存储器801通过总线802连接;存储器801中存储有可在处理器800上运行的计算机程序,处理器800运行计算机程序时执行本技术前述任一实施例所提供的车辆停靠点聚类的方法。
[0106]
其中,存储器801可能包含高速随机存取存储器(ram:random access memory),也可能还包括非不稳定的存储器(non-volatile memory),例如至少一个磁盘存储器。通过至少一个通信接口803(可以是有线或者无线)实现该系统网元与至少一个其他网元之间的通信连接,可以使用互联网、广域网、本地网、城域网等。
[0107]
总线802可以是isa总线、pci总线或eisa总线等。总线可以分为地址总线、数据总线、控制总线等。其中,存储器801用于存储程序,处理器800在接收到执行指令后,执行程序,前述本技术实施例任一实施方式揭示的车辆停靠点聚类的方法可以应用于处理器800中,或者由处理器800实现。
[0108]
处理器800可能是一种集成电路芯片,具有信号的处理能力。在实现过程中,上述方法的各步骤可以通过处理器800中的硬件的集成逻辑电路或者软件形式的指令完成。上述的处理器800可以是通用处理器,包括中央处理器(central processing unit,简称cpu)、网络处理器(network processor,简称np)等;还可以是数字信号处理器(dsp)、专用集成电路(asic)、现成可编程门阵列(fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。可以实现或者执行本技术实施例中的公开的各方法、步骤及逻辑框图。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。结合本技术实施例所公开的方法的步骤可以直接体现为硬件译码处理器执行完成,或者用译码处理器中的硬件及软件模块组合执行完成。软件模块可以位于随机存储器,闪存、只读存储器,可编程只读存储器或者电可擦写可编程存储器、寄存器等本领域成熟的存储介质中。该存储介质位于存储器801,处理器800读取存储器801中的信息,结合其硬件完成上述方法的步骤。
[0109]
本技术实施例提供的电子设备与本技术实施例提供的车辆停靠点聚类的方法出于相同的发明构思,具有与其采用、运行或实现的方法相同的有益效果。
[0110]
本技术实施例还提供一种与前述实施例所提供的车辆停靠点聚类的方法对应的计算机可读存储介质,请参考图9,其示出的计算机可读存储介质为光盘900,其上存储有计算机程序(即程序产品),计算机程序在被处理器运行时,会执行前述任意实施例所提供的车辆停靠点聚类的方法。
[0111]
需要说明的是,计算机可读存储介质的例子还可以包括,但不限于相变内存(pram)、静态随机存取存储器(sram)、动态随机存取存储器(dram)、其他类型的随机存取存储器(ram)、只读存储器(rom)、电可擦除可编程只读存储器(eeprom)、快闪记忆体或其他光学、磁性存储介质,在此不再一一赘述。
[0112]
本技术的上述实施例提供的计算机可读存储介质与本技术实施例提供的车辆停靠点聚类的方法出于相同的发明构思,具有与其存储的应用程序所采用、运行或实现的方法相同的有益效果。
[0113]
以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
[0114]
以上实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。