1.本发明涉及一种脂肪肝患病风险预测方法,具体来说,是在纵向体检数据的基础上对脂 肪肝患病风险进行预测的方法。
背景技术:
2.纵向体检数据资料是对同一批体检者的多个指标,在不同时间,如年度内的多次体检结 果。多年来健康体检积累了大量的健康队列测量数据,由于数据不满足独立性假定,所以不 能使用常规统计分析方法进行建模分析。
3.近年来随着人们消费结构和生活习惯发生转变,糖尿病、超重肥胖等患病率上升,我国 脂肪肝患病率逐年升高,达到27%。目前我国脂肪肝患者近2.5亿人,由于人口老龄化的推 进及肥胖人群的增加,预计到2030年间国内脂肪肝患病率将持续升高至50%。脂肪肝具有潜 伏期长的特点,经资料调查发现脂肪肝患病初期临床表现并无明显症状,但重者可能会演变 成严重肝病,如肝硬化、肝癌等,临床和经济负担将变得巨大。脂肪肝属于可逆转疾病,而 目前尚无一种针对脂肪肝的较精确的预测方法,所以基于纵向数据进行脂肪肝预测具有巨大 的医疗价值和潜在经济价值。
技术实现要素:
4.本发明的目的在于提供一种脂肪肝患病风险预测方法及装置,以解决现有技术中存在的 健康纵向体检数据利用效率较低,且尚无针对脂肪肝患病风险预测的精确方法的问题。
5.为了解决上述问题,本发明提供如下技术方案:
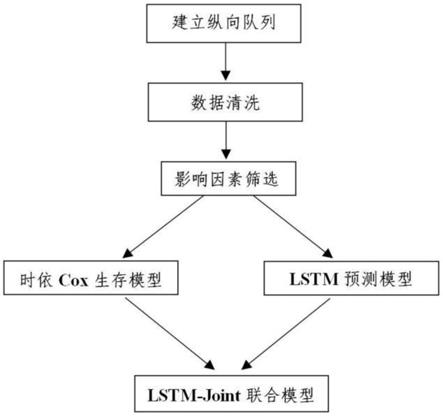
6.一种脂肪肝患病风险预测方法包括以下步骤:
7.s1、采集纵向体检数据,建立纵向队列,然后对纵向队列的数据进行清洗;通过对数据 的清洗提高数据质量;
8.s2、从步骤s1中清洗后的纵向队列中筛选出脂肪肝影响因素;可采用随机森林算法或 lasso-logistic回归模型筛选脂肪肝影响因素;
9.s3、根据步骤s2的脂肪肝影响因素建立lstm机器学习算法;
10.s4、将步骤s3的lstm机器学习算法与生存函数结合建立lstm-joint联合模型对脂肪 肝患病风险进行预测。
11.进一步的,步骤s1中纵向队列的数据中每个变量包含不同时间的检测数据;即包含患者 连续多次的体检数据。
12.进一步的,步骤s1中数据清洗的具体过程为:对异常值的处理方法为错误值采用记空值 法;离群值采用前后平均数替换法或四分位数盖帽法;对缺失值的处理方法为稳定指标采用 末次推进法;非稳定指标采用xgboost算法填补法;数据清洗一般多为异常值和缺失值的处 理,最终目的是让样本尽可能代表总体,减小样本偏差。
13.进一步的,步骤s2中脂肪肝影响因素筛选的方法为随机森林法;也可选用其他筛
选方法, 筛选方法的优劣比较中,将meta分析中已经确定的影响因素作为金标准,以错判率和正确选 入率为评价指标。
14.进一步的,步骤s4中lstm-joint联合模型通过模拟实验方法增加模型的稳定性和拟合 效果;模拟实验方法中为保证变量之间的协方差关系以及模拟数据与实际数据的一致性,所 以基于实际数据抽样产生模拟数据。
15.进一步的,步骤s3中将lstm机器学习算法用于预测纵向队列的纵向过程,通过纵向 队列建立纵向亚模型。
16.进一步的,步骤s4中生存函数为通过时依cox生存模型建立的生存亚模型。
17.一种脂肪肝患病风险预测装置包括存储器:用于存储可执行指令;处理器:用于执行所 述存储器中存储的可执行指令,实现一种脂肪肝患病风险预测方法。
18.与现有技术相比,本发明具有以下有益效果:
19.(1)本发明建立连续纵向队列的健康体检数据,对脂肪肝检出情况进行动态分析并进行 数据清洗,对于缺失数据,使用xgboost构建并训练模型,进行预测,使每个时间数据都具 备完整的数据,使得最终建模效果更理想。
20.(2)本发明将lstm机器学习算法与生存函数结合建立lstm-joint联合模型对脂肪肝 患病风险进行预测,将机器学习算法引入lstm-joint联合模型,通过模拟实验法使模型有更 好的稳定性和拟合效果。
21.(3)本发明通过对比筛选脂肪肝影响因素的方法,得出采用随机森林法为最合适的筛选 脂肪肝影响因素的方法,为脂肪肝风险预防提供科学依据,能有效的利用了数据,又适配了 后续的数据结构便于进行计算。
附图说明
22.为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方 式或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本 发明的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可 以根据这些附图获得其他的附图,其中:
23.图1为本发明的流程示意图。
具体实施方式
24.为了使本发明的目的、技术方案和优点更加清楚,下面将结合图1对本发明作进一步地 详细描述,所描述的实施例不应视为对本发明的限制,本领域普通技术人员在没有做出创造 性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
25.实施例1
26.如图1,一种脂肪肝患病风险预测方法,包括以下步骤:
27.s1:采集纵向体检数据,建立健康体检队列,根据不同变量的数据情况采用不同方式完 成数据清洗,提升数据质量。
28.在步骤s1中所述的准备被分析数据中数据应当是纵向队列数据,数据变量和纵向过程应 当清晰、有效。具体实施方法如下,建立纵向队列,假设年份依次为{c1,c2,c3,c4
…
..cn}共 计n个字段,整个数据的结构应当是:
29.[{c11,c12,c13,c14
…
..c1n},
[0030]
{c21,c22,c23,c24
…
..c2n},
[0031]
{c31,c32,c33,c34
…
..c3n},
[0032]
…
[0033]
{cm1,cm2,cm3,cm4
…
..cmn}]
[0034]
其中c12的含义是第1年数据中的第2个变量。所述的数据清洗中,对异常值的处理方 法为错误值采用记空值法,离群值采用前后平均数替换法或四分位数盖帽法。对缺失值的处 理方法为稳定指标采用末次推进法,其他指标采用xgboost算法填补法。
[0035]
s2:探讨随机森林算法、lasso-logistic回归模型等算法筛选慢性病影响因素的效果,并 筛选出脂肪肝影响因素。
[0036]
在步骤s2中所述的筛选影响因素的方法比较中,将meta分析中已经确定的影响因素作 为金标准,以错判率和正确选入率为评价指标;
[0037]
s3:比较机器学习算法建立慢性病预测模型的效果,选择出适合用于慢性病动态过程预 测的机器学习算法。
[0038]
循环神经网络对具有序列特性的数据非常有效,它能挖掘数据中的时序信息,因为循环 神经网络的这种能力,利用lstm建立预测模型来描述纵向队列数据的纵向过程。
[0039]
s4:将lstm算法与生存函数结合建立lstm-joint联合模型,通过模拟实验探究在不 同样本量情况下模型的稳定性和拟合效果。
[0040]
(1)在步骤s4中,纵向队列数据通常无法完全满足ph假设,采用时依cox风险模型 建立生存分析亚模型。xj为时依协变量,g(t)为xj随t变化的函数,时依cox风险模型如下:
[0041][0042]
其中h0(
·
)表示基础风险函数,xj为时依协变量,g(t)为xj随t变化的函数,β为系数向量。
[0043]
(2)在步骤s4中,lstm-joint联合模型中的生存亚模型的作用是考虑纵向标记水平特 殊性,度量纵向标记水平与事件发生风险的关联程度。用示第i个个体事件发生的真实时 间,ti表示观测时间,ci表示删失时间,即δi是示性删失指数, yi(t)表示个体i在t时刻的纵向数值,即在t时刻观测到的包含测量误差的结果。若每个对象有 ni个观测值:
[0044]yij
={yi(t
ij
),j=1
…
nj}
[0045]
以mi(t)表示t时刻未被观测到的真实发生纵向数值,为了量化mi(t)与事件发生风险的关 联强度,mi(t)={mi(s),0≤s<t}表示mi(t)的历史过程。lstm-joint联合模型:
[0046][0047]
其中h0(
·
)表示基础风险函数,ωi为自变量,γ
t
是与之对应的回归系数向量。而α则是纵 向结果对事件发生风险潜在影响的量化参数,代表纵向亚模型与生存亚模型的关联性,也就 是说α的大小代表纵向结果与生存子模型中危险函数的关联性的强弱。通过mi(t)将两个亚模 型联系起来,若α=0,联合模型并无优势;若α显著,表示纵向测量指标与结局事件发生之 间相关。本研究采用时依cox风险模型建立生存分析亚模型,lstm-joint联合模型表达式为:
[0048]hi
(t|mi(t),ωi)=h0(vi(t))exp{γ
t
ωi αmi(t)},t>0
[0049]
其中是某种加速机制,利用yi(t)来估计mi(t)及mi(t)。
[0050]
(3)在步骤s4中所述的模拟实验方法,为保证变量之间的协方差关系以及模拟数据与 实际数据的一致性,所以基于实际数据抽样产生模拟数据,在由少到多不同样本量情况下, 分别模拟10000次,得到较为稳定的模拟比较结果。模拟实验包括以下步骤:
[0051]
a.提取观察对象一一对应的id号作为抽样号码集;
[0052]
b.提取数据中的检测指标数据和时间作为自变量数据集;
[0053]
c.从抽样号码集中随机抽取n(100,200,500,1000,2000)个样本;
[0054]
d.对bradley p.carlin的lstm-joint模拟方案进行改造,抽取实际数据生成自变量矩阵。 给定偏回归系数向量在logistic模型框架下生成因变量,组合构成模拟数据集;
[0055]
e.重复上述过程10000次,得到10000个模拟数据集分别模拟10000次建立lstm-joint 联合模型并评价其稳定低和预测效果。
[0056]
(4)lstm-joint联合模型预测准确性的评价指标为偏倚均值、一致性指数、cox-snell 残差的km估计曲线应与参数为1的指数分布函数曲线越相近,模拟拟合效果越好。
[0057]
实施例2
[0058]
一种脂肪肝患病风险预测装置包括存储器:用于存储可执行指令;处理器:用于执行所 述存储器中存储的可执行指令,实现一种脂肪肝患病风险预测方法。
[0059]
在本技术所提供的几个实施例中,应该理解到,所揭露的装置和方法,也可以通过其它 的方式实现。以上所描述的装置实施例仅仅是示意性的,例如,附图中的流程图和框图显示 了根据本发明的多个实施例的装置、方法和计算机程序产品的可能实现的体系架构、功能和 操作。在这点上,流程图或框图中的每个方框可以代表一个模块、程序段或代码的一部分, 所述模块、程序段或代码的一部分包含一个或多个用于实现规定的逻辑功能的可执行指令。 也应当注意,在有些作为替换的实现方式中,方框中所标注的功能也可以以不同于附图中所 标注的顺序发生。例如,两个连续的方框实际上可以基本并行地执行,它们有时也可以按相 反的顺序执行,这依所涉及的功能而定。也要注意的是,框图和/或流程图中的每个方框、以 及框图和/或流程图中的方框的组合,可以用执行规定的功能或动作的专用的基于硬件的系统 来实现,或者可以用专用硬件与计算机指令的组合来实现。
[0060]
另外,在本发明各个实施例中的各功能模块可以集成在一起形成一个独立的部分,也可 以是各个模块单独存在,也可以两个或两个以上模块集成形成一个独立的部分。
[0061]
所述功能如果以软件功能模块的形式实现并作为独立的产品销售或使用时,可以存储在 一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技 术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产 品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服 务器,或者网络设备等)执行本发明各个实施例所述方法的全部或部分步
骤。需要说明的是, 在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或 操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺 序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使 得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列 出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多 限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括所述要素的过程、方 法、物品或者设备中还存在另外的相同要素。
[0062]
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员 来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等 同替换、改进等,均应包含在本发明的保护范围之内。应注意到:相似的标号和字母在下面 的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对 其进行进一步定义和解释。
[0063]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉 本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本 发明的保护范围之内。因此,本发明的保护范围应所述以权利要求的保护范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。