1.本发明涉及乳腺癌预测领域,具体涉及图像处理技术,卷积神经网络技术,网格搜索技术,以及随机森林预测技术。涉及到机器学习和深度学习知识领域。
背景技术:
2.乳腺癌的发病率越来越高,呈现出年轻化的趋势,是当代女性的一大杀手,因此有必要提前预防。通过估计出自己得乳腺癌得概率,做好相应的防护。晚期的乳腺癌死亡率非常高,然而如果能较早的发现乳腺癌,可以通过手术治疗获得良好的生存期,乳腺癌的诊断主要通过乳腺ct。乳腺癌的诱因有家族遗传,是否熬夜,是否生气等因素。现在世界上关于乳腺癌治疗最复杂的问题就是乳腺癌早期往往没有症状,早期很难发现。乳腺癌一旦发现就是中晚期,造成了很高的死亡率。不仅造成了家庭治疗费用的压力,还会带给患者极大的身心疼痛折磨。因此在判断自己乳腺癌的概率需要获得直系亲属的乳腺ct图像,并了解有无家族乳腺癌遗传史。若有,自己患乳腺癌的风险就比较大,需要定期筛查。获得到的图像由于容易受到噪声的干扰,需要对图像进行预处理增强图像的效果,然后通过卷积神经网络提取有利于判断乳腺癌的特征值。然后把经过卷积神经网络训练的图像,家族遗传,是否熬夜,是否生气等因素构建决策树预测自己的乳腺癌概率。若预测自己得乳腺癌的几率比较大,那就需要每年定期复查。本发明解决了乳腺癌未能及时发现,错过良好治疗时期的问题。通过本发明,可以针对自己的患乳腺癌的预测概率,做好防护,避免乳腺癌带来人财两空的损失。
技术实现要素:
3.一种基于随机森林的乳腺癌预测发明,其步骤包括:采集直系亲属以及自己的乳腺ct图片由于在图像采集中不可避免受到噪声影响,因此需要增强图像效果。
4.图像增强技术有增强对比度,直方图均衡化,锐化滤波器。
5.通过增强对比度,可以增强原图之间的灰度反差。
6.通过直方图均衡化,可以,把原始的直方图变为均匀分布的形式,增加了灰度值的动态范围,从而增强了图像效果。
7.通过锐化滤波器消除图片噪声,增强被模糊的细节。
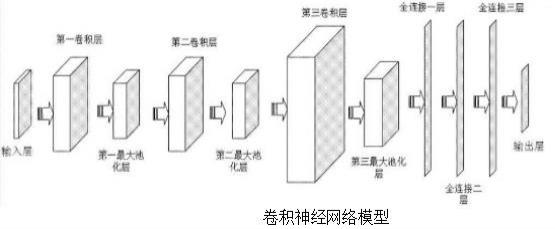
8.基于深度学习知识,设计卷积神经网络,提取图像的特征值。
9.卷积神经网络的激活函数选取relu函数,损失函数选取交叉熵损失函数,然后设置卷积层和池化层。
10.特征图是通过对输入图像进行卷积计算和激活函数计算得到的。
11.卷积过程就是用一个大小固定的卷积核按照一定步长扫描输入矩阵进行点积运算。
12.池化层在卷积层之后,池化操作将相似的特征合并起来,并选取区域的最大值和
平均值,池化操作的作用是缩小特征图的尺寸,减少计算量。
13.多次训练卷积神经网络模型,使它趋于稳定。
14.使用交叉验证和网格搜索选取模型参数。
15.随机森林是基于决策树的,由若干个决策树集成,因此避免了单个决策树的偶然性,并且有效地解决了过拟合问题。
16.随机森林的参数有决策树的数目,最大深度,最小样本树,最小分类样本树。
17.这些参数需要经过网格搜索的过程来选择。
18.网格搜索的主要函数是gridsearchcv。
19.网格搜索的主要步骤如下:4.1定义需要搜索的参数列表,这里需要定义的参数列表有决策树的数目,最大深度,最小样本数,最小分类样本数。
20.4.2使用gridsearchcv()函数,其中estimator指定模型,本发明中此处填写的是randomforestclassifier,param_grid定义参数搜索网格,cv用来指定交叉验证折树,这里指定cv=4。
21.4.3接下来使用属性best_params_属性提取最优的参数。
22.经过网格搜索后,选取的参数是整个模型最优的。
23.因此本发明可以达到预测准确性。
24.确定每颗决策树的输入和输出。
25.每颗决策树的输入为家庭所有成员的乳腺ct图像,姓名,性别,年龄,是否经常熬夜,是否经常吃垃圾食品,是否经常生气。
26.随机森林的输出为是否是乳腺癌高危人群。
27.0表示不是乳腺癌高危人群,1表示是乳腺癌高危人群。
28.决策树上的非叶子结点代表实例的某个属性的测试,其后继分支代表该属性的可能值。
29.决策树上的叶子结点代表实例的类别。
30.信息增益用来衡量决策树区分训练的能力。
31.信息增益越大,说明分类效果越好。
32.在确定决策树的结点分裂时,按照信息增益来选择分裂结点,选取信息增益最大的。
33.当所有的叶子结点都为同一类型的时候,停止分裂,决策树构建完毕。
34.构建随机森林。
35.单个决策树容易出现过拟合的问题,因此在随机森林中选择属性时加入随机因素。
36.在每个决策树的输入结点中,先随机从输入的属性集中随机选取k个属性的子集,然后从这个子集中选取最优属性用于划分。
37.每颗决策树对输入项进行预测随机森林投票选取预测结果。
38.预测结果最多的类别确定为最后的类别。
39.其输出类别是所有决策树的输出类别的众数。
40.这样可以避免单个决策树的预测偶然性。
41.和现有技术相比,本发明具有以下优点:1.机器学习的分类预测方法主要有贝叶斯算法,支持向量机,决策树。本发明使用的是随机森林算法,与这些算法相比,解决了支持向量机算法的当数据量较大时运行效率不高的缺陷。贝叶斯算法的缺陷在于需要各个特征值之间相互独立,这个假设往往不成立。随机森林有效地避开了这个缺陷。随机森林通过随机选取参数解决了单个决策树的过拟合问题,通过集成多个决策树选择最多的预测类别作为最终类别,解决了单个决策树预测的偶然性问题。2.由于提取到的图像会受到噪声的干扰影响图像的效果,本发明使用直方图均衡化,增强图像对比度以及使用锐化滤波器增强图像的效果。解决图像不清晰的问题。3.模型通过网格搜索方法,选取的参数是最佳参数。
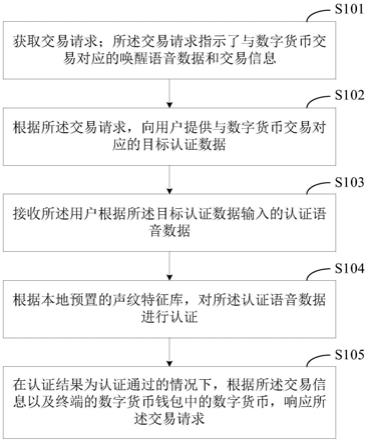
42.附图说明:图1为卷积神经网络的模型图2为图像预处理的流程图图3为随机森林构建的流程图具体实施方式:1. 一种基于随机森林的乳腺癌预测发明,其步骤包括:采集直系亲属以及自己的乳腺ct图片由于在图像采集中不可避免受到噪声影响,需要增强图像效果。因此需要对收集到的图片进行预处理操作,图像的预处理操作如图2所示。包括图像增强,特征提取,图像识别。采集到的乳腺ct图像由于可能会受到周围背景噪声的影响,图像的质量会下降,因此需要图像增强技术是为了增强图像的对比度,提高视觉效果,为后面的构建随机森林分类预测乳腺癌概率打好基础。本文采用锐化滤波器与增强图像对比度和直方图均衡化等技术相结合,对乳腺ct图像增强处理,增强被模糊的细节,增强了原图之间的灰度范畴以及动态范围,2.接着基于深度学习知识,设计卷积神经网络,提取图像的特征值。卷积神经网络的模型如图1所示。卷积神经网络的激活函数选取relu函数,损失函数选取交叉熵损失函数,然后设置卷积层和池化层。特征图是通过对输入图像进行卷积计算和激活函数计算得到的。卷积过程就是用一个大小固定的卷积核按照一定步长扫描输入矩阵进行点积运算。卷积核时一个权重矩阵,特征图通过将卷积计算结果输入到激活函数内得到,特征值的深度等于当前层设定的卷积核个数。本发明中家庭所有成员的乳腺ct图像共有7幅,7幅大小为m*n的输入图像为m*n的输入图像 ,卷积核w为m*n矩阵,偏置为b,则卷积层的计算公式为,卷积核w为m*n矩阵,偏置为b,则卷积层的计算公式为3.池化层在卷积层之后,池化操作将相似的特征合并起来,并选取区域的最大值和平均值,池化操作的作用是缩小特征图的尺寸,减少计算量。对于特征值多的图像,可以去除图像的冗余信息,提高图像处理效率,减少过拟合。
43.多次训练卷积神经网络模型,使它趋于稳定,以便它提取更加精确的特征值。
44.随机森林是基于决策树的,由若干个决策树集成,因此避免了单个决策树的偶然性,并且有效地解决了过拟合问题。随机森林的参数有决策树的数目,最大深度,最小样本树,最小分类样本树。这些参数需要经过网格搜索的过程来选择。网格搜索在模型的构建中至关重要,若参数选择不恰当,就会导致模型的欠拟合或者过拟合。网格搜索的基本思想是
首先在验证集上构建参数的合理取值,然后参数合理的范围内,逐渐按照步长搜寻参数,不断循环反复,直到找到精确度最高的参数。通过网格搜索选择参数,是个反复比较和选择的过程,选取的是最优参数,因此可以增强模型预测的准确度,避免参数选择不当造成的过拟合或欠拟合的缺陷。网格搜索的主要函数是gridsearchcv,具体操作步骤如下: 5.1定义需要搜索的参数列表,这里需要定义的参数列表有决策树的数目,最大深度,最小样本数,最小分类样本数。
[0045] 5.2定义需要搜索的参数列表,这里需要定义的参数列表有决策树的数目,最大深度,最小样本数,最小分类样本数。
[0046]
5.3定义需要搜索的参数列表,这里需要定义的参数列表有决策树的数目,最大深度,最小样本数,最小分类样本数。接下来使用属性best_params_属性提取最优的参数。
[0047]
确定每颗决策树的输入和输出。每颗决策树的输入为家庭所有成员的乳腺ct图像,姓名,性别,年龄,是否经常熬夜,是否经常吃垃圾食品,是否经常生气。随机森林的输出为是否是乳腺癌高危人群。输出0表示不是乳腺癌高危人群,输出1表示是乳腺癌高危人群。
[0048]
7. 构建随机森林。构建随机森林的前提是先构建决策树,随机森林是多个决策树的集成。随机森林的集成。构建随机森林的具体流程如图3所示。随机森林中选择属性时加入随机因素,在每个决策树的输入结点中,先随机从输入的属性集中随机选取k个属性的子集,然后从这个子集中选取最优属性用于划分。决策树上的非叶子结点代表实例的某个属性的测试,其后继分支代表该属性的可能值。决策树上的叶子结点代表实例的类别。信息增益用来衡量决策树区分训练的能力。信息增益越大,说明分类效果越好。在确定决策树的结点分裂时,按照信息增益来选择分裂结点,选取信息增益最大的。这里引入信息熵的概念以及信息增熵的计算公式。信息熵是样本纯度的一种指标,通常信息熵越小,说明数据样本的纯度越高。假设当前样本中d中第k类的比例为纯度越高。假设当前样本中d中第k类的比例为(k=1,2,
…
|y|)信息熵的计算公式为:ent(d)=
‑‑‑‑‑‑
。信息增益为分类前的信息熵减去分类后的信息熵。信息增益越大,说明属性分裂的纯度提升越大。因此选用信息增益大的为分裂属性。当所有的叶子结点都为同一类型的时候,停止分裂,决策树构建完毕。
[0049]
8.集成单个决策树9.每颗决策树对输入项进行预测,随机森林投票选取预测结果,其输出类别是所有决策树预测的众数,预测结果最多的类别确定为最后的类别。这样可以避免单个决策树的预测偶然性。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。